Contenido
La mnemotecnia es una palabra o frase que nos ayuda a recordar algo. La mnemotecnia más famosa es "cada cazador quiere saber dónde se sienta el faisán". A quien le preguntes, todos la conocen.
Pero en el ámbito profesional, todo es un poco más triste. Pregúnteles a sus camaradas si saben qué es SPDFOT o RCRCRC. Lejos de ser un hecho ... Pero la mnemotécnica nos ayuda a ejecutar las pruebas, sin olvidar comprobar lo más importante. Lista de verificación se derrumbó en una frase!
Los colegas de prueba de habla inglesa utilizan activamente la mnemotecnia Un amigo que lee blogs extranjeros dice que a los estadounidenses se les ocurren casi todos los estornudos.
Y creo que eso es genial. La mnemotecnia extranjera puede no ser adecuada específicamente para su sistema o sus procesos. Y el suyo, querido, le recordará "no esperar para comprobar esto y aquello" y limitará la cantidad de errores en la producción.
Hoy quiero compartir con ustedes mis mnemotécnicos BMW para el estudio de los valores límite. Puede ser:
- dar junior para desarrollo general en diseño de prueba;
- uso en la entrevista: el candidato generalmente resuelve la tarea "encontrar el borde en número", pero ¿encontrará el borde en la línea o para descargar el archivo?
BMW Mnemonics
B - grande
M - pequeño
B - justo

Es fácil de recordar. ¡Solo recuerda este coche genial e inmediatamente el descifrado está listo! Pero, ¿qué significa y cómo ayudará en las entrevistas?
Justo

En principio, "justo" está probando sin ningún tipo de mnemotecnia. Siempre comenzamos con pruebas positivas para verificar que el sistema funciona en principio.
Si el campo es numérico, ingrese el valor común. Digamos que tenemos una tienda minorista en línea. En la cantidad de bienes podemos verificar 1 o 2.
Una prueba positiva: esto es "justo". Mostré mnemotécnicos en forma de ratón. Aquí es un tamaño estándar.
Grande
Luego decimos que el mouse debe estar inflado a un tamaño increíble, para que no encaje directamente en la imagen. Y vea cómo funcionará el sistema con él.

En este caso, simplemente vamos "muy por delante". MUY LEJOS El mouse grande representa una búsqueda de un límite tecnológico en algún lugar, fuera de uno arbitrario.
Para ingresar la cantidad de bienes, será "999999999999999999999999999999999999999999999999999999999999 ...". No solo un gran valor (9999), sino MUY grande. Recuerde el mouse: estaba tan explotado que ni siquiera encajaba en la imagen.
La diferencia es importante, una gran importancia ayudará a encontrar un borde arbitrario, y uno enorme ayudará a encontrar uno tecnológico. La prueba para "grande" a menudo se lleva a cabo, para "enorme" - no. Mnemonics recuerda precisamente sobre él.
Pequeño
Perforamos el mouse, y se vuela a un tamaño microscópico.

El ratoncito es una búsqueda de valores cercanos a cero. El valor positivo más pequeño.
¿Qué pasa con la prueba de "0.00000001"? Verificado para cero, pero no olvides cavar lado a lado.
Y que hay
Parece estar diciendo cosas obvias. Parece que todos ya lo saben. Simplemente dé una entrevista sobre una tarea numérica, el mismo triángulo (una
tarea de Myers ), y comprende que esto no es así ... Muy pocas personas irán a buscar un límite tecnológico o intentarán ingresar un valor fraccional cercano a cero. Máximo cero y se ofrecerá a verificar.
Y si propone probar NO un número, entonces este es un estupor aún mayor. Con el número, de acuerdo, verificamos cero y el borde de acuerdo con la declaración de trabajo, ya no está mal. ¿Y en la línea qué probar? ¿Y en el archivo?
Quiero hablar de esto en el artículo. ¿Cómo puedes usar la mnemotecnia en la vida real y al mismo tiempo atrapar errores? Comencemos con ejemplos comunes, que se encuentran en cada proyecto. Y que se puede dar en la entrevista en forma de una pequeña tarea.
Y luego contaré ejemplos de mi trabajo. Sí, son específicos. Sí, se trata de tecnologías específicas. ¿Y qué? Pero muestran cómo puedes aplicar la mnemotecnia en lugares más complejos.
El significado es el mismo: las fronteras están en casi todas partes. Solo encuentra el número y experimenta con él. Y no te olvides de la mnemotecnia de BMW, porque es en B y M que a menudo encontramos errores.
Ejemplos comunes
Ejemplos que están en cualquier proyecto: un campo numérico, una cadena, una fecha ... Consideraremos en este orden:
Numero
- 10
- 0.00000001
- 999999999999999999999999 ....
Digamos una caja con la cantidad de libros, vestidos o paquetes de jugo. Como prueba positiva, elegimos una cantidad adecuada: 3, 5, 10.
Como un valor pequeño, seleccione lo más cerca posible de cero. Recuerde que el mouse debe ser muy pequeño. Esto no es solo una unidad, sino el enésimo lugar decimal. ¿De repente se redondeará a cero y en algún lugar de las fórmulas se bloqueará? Además, en el número "1" todo funcionará bien.
Bueno, el máximo se logra ingresando 10 millones de nueves. ¡Genere una cadena de este tipo utilizando herramientas como Perlclip y continúe, pruebe MUY mucho!
Ver también:Clases de equivalencia para una cadena que denota un número , incluso más ideas para pruebas de cadena numérica
Cómo generar una cadena grande, herramientas : asistentes para generar un gran valor
Fecha
- 26/05/2017
- 01/01/1900
- 21/12/003
Una fecha positiva es "hoy" si enviamos el informe en alguna fecha. O su propia fecha de nacimiento, si estamos hablando de DR, o alguna otra que se adapte a su proceso comercial.
Como una fecha pequeña, tomamos la fecha mágica "01/01/1900", en la que las aplicaciones a menudo se desmoronan. A partir de esta fecha, el tiempo comienza en Excel. También se arrastra a las aplicaciones. Expones este número mágico, y el informe se desmorona, incluso si hay protección contra los tontos a ceros. Por lo tanto, lo recomiendo para su verificación.
Si hablamos de un mouse muy pequeño, aún puede marcar "00.00.0000". Esta será una verificación cero, que también es importante. Pero los desarrolladores están protegidos con mayor frecuencia de un tonto que desde el 01/01/1900.
Far Ahead también puede ser diferente. Puede ir a un negativo y verificar una fecha o mes que realmente no existe: 40/05/2018. O busque en la frontera tecnológica utilizando la fecha 99.99.9999. Y puede tomar un poco más de valor real, que simplemente no llegará pronto: 2400 o 3000.
Ver también:Clases de equivalencia para una cadena que denota una fecha , incluso más ideas para probar una fecha

Cadena
- Vasya
- (un espacio)
- (Había mucho texto)
Digamos que al registrarse hay un campo con un nombre. Una prueba positiva es un nombre común: Olga, Vasya, Peter ...
Cuando buscamos un ratoncito, tomamos una línea vacía o un truco de vida: uno o dos espacios. En este caso, la línea permanece vacía (no hay caracteres allí), pero parece estar llena.
¿Cuál es el enfoque cuando se busca un mouse grande? Cuando probamos una cadena grande, ¡necesitamos probar la cadena GRANDE! Recuerde que el mouse debe ser GRANDE. Porque generalmente les explico a los estudiantes cómo funciona todo esto, cómo buscar una frontera tecnológica, etc. Y luego me dan DZ y escriben "Verifiqué 1000 caracteres, no hay límite tecnológico".
Siglo 21 en el patio, bueno, ¿qué son 1000 personajes? Tomamos cualquier herramienta que nos permita generar 10 millones e insertar 10 millones, ahora será la búsqueda de una frontera tecnológica. Y ya hay errores en esto, en esto el sistema puede interrumpirse. ¿Pero 1000 personajes? No
Ver también:Cómo generar una cadena grande, herramientas : asistentes para generar un gran valor
Pero bueno, todo está claro aquí también. ¿Y qué pasará si probamos el archivo?
Archivo
¿Dónde puedo encontrar un número en un archivo?
En primer lugar, el archivo tiene su tamaño:
Cuando prueban un archivo grande, generalmente intentan algo como 30Mb, y se calman con esto. Y luego carga 1 GB, y eso es todo, el servidor se congela.
Por supuesto, si es un principiante y está probando un sitio real para obtener experiencia, no debe cargarlo sin el conocimiento del propietario. Pero cuando realice la prueba en el trabajo, asegúrese de revisar el mouse grande.
En segundo lugar, el archivo tiene un nombre → y esta es la longitud de la línea que acabamos de comentar.
¡Pero el archivo también tiene su contenido! Hay varias columnas (columnas) y filas. Pruebas de línea:
- 5 lineas
- 1 fila
- 1,000,000,000 filas
Y aquí comienza la diversión. Porque incluso en el mismo Excel en diferentes versiones hay diferentes restricciones en el número de líneas que admite:
- Excel debajo de 97-16384
- Excel 97-2003 - 65 536
- Excel 2007 - 1,048,576
Pero aún así los números son bastante grandes, no es interesante. Pero el antiguo exel no abrió más de 256 en las columnas, y esta es una limitación seria:
- Excel 2003 - 256
- Excel 2007 - 16,385
Su hermano libre, LibreOffice, no puede abrir más de 1024 columnas.

Historia de vida
Escribimos algunas pruebas automáticas en formato CSV. A la entrada de la mesa, a la salida de la mesa. Abra y edite en LibreOffice para ver dónde está la columna. Todo es genial, todo funciona. Mientras que el número de columnas no sale para 1024.
Aquí es donde comienza el dolor # vida. La prueba LibreOffice ya no se abrirá, en el formato CSV es inconveniente, porque es difícil de entender dónde está la columna 555. Abre la prueba en Excel, edita, guarda, ejecuta la prueba ... Se ubica en 10 lugares nuevos: el TIN se ha estropeado. Es largo, por ejemplo, 7710152113. Excel felizmente lo traduce al formato 1.2E + 5.
Otros números largos también se pierden.
Si el valor estaba entre comillas, se incluye entre comillas adicionales que la prueba no espera.
Y corrige estas pequeñas cosas que ya están en formato CSV, regañando mentalmente Excel a sí mismo ... Así que hay una limitación, ¡debe ser recordado! Aunque no aparece en el sistema en sí, simplemente puede complicar la vida del probador.
Tabla en Oracle (base de datos)
Y como estamos hablando de 1024 columnas, recordaremos sobre Oracle (una base de datos popular). Existe la misma restricción: en una tabla puede haber un máximo de 1024 columnas.
¡Es mejor recordar esto de antemano! Teníamos una tabla en la que había alrededor de 1000 columnas, pero la mitad estaba reservada para el futuro: "algún día será útil, esto será suficiente para nosotros por mucho tiempo". Suficiente, pero no por mucho tiempo ...
En ningún lugar para expandir la tabla, se encontró con una limitación. Entonces, divida la tabla en dos, o empaquete el contenido en un BLOB: esto es algo que un archivo zip con datos resulta ocupar una columna, pero dentro contiene tantos como desee.
Pero en cualquier caso, esta es la migración de datos. Y la migración de datos siempre es una molestia. En una base grande, lleva mucho tiempo, trae nuevos problemas que solo se pueden disparar en seis meses ... ¡Brrr! Si puede prescindir de la migración, entonces es mejor hacerlo.
Si tiene una tabla con MUCHOS datos, piense en el futuro. ¿Siempre cabe en 1024 columnas? ¿Tendrás que migrar más tarde? Después de todo, cuanto más viva el sistema, más difícil será la transferencia. Y "suficiente para 5 años" significa que habrá que migrar un volumen de cinco años.
¿Cómo probarlo? Sí, por código, evalúe sus tablas de datos, eche un vistazo a dónde está. Presta atención al mouse grande: esas tablas que ya tienen muchas columnas. ¿Habrá problemas con ellos en el futuro?
Informar en el sistema
Pero, ¿por qué cargamos archivos al sistema o bombeamos datos desde Oracle? Muy probablemente para construir algún tipo de informe. Y aquí también puedes aplicar esta mnemotecnia.
¡Los datos pueden estar tanto en la entrada (mucho, un poco, justo) como en la salida! Y esto también es importante, ya que estas son diferentes clases de equivalencia.
Como resultado, probamos la cantidad:
- columnas de informes
- lineas
- datos de entrada;
- datos de salida (en el propio informe).
Estructura (columnas y filas)¿Podemos influir en el número de filas o columnas? A veces sí, podemos. En el segundo trabajo, probé el diseñador de informes: a la izquierda tiene cubos con los nombres de los parámetros que puede arrojar horizontal o verticalmente en el informe. Es decir, usted decide cuántas filas serán y cuántas columnas.
Aplica mnemotecnia. Después de un informe estándar (prueba positiva, ratón "justo") intentamos hacer un poco:
- 1 columna, 0 filas;
- 0 columnas, 1 fila;
- 1 columna, 1 fila.
Entonces mucho:
- columnas máximas, 1 fila (todos los cubos se arrojan en columnas);
- filas máximas, 1 columna;
- si los cubos pueden duplicarse, entonces allí y allá al máximo, pero esto es dudoso;
- máximo de niveles anidados (esto es cuando otros dos están dentro de una columna de agregador).
A continuación, probamos los datos de entrada y salida. Podemos influir en ellos en cualquier informe, incluso si no hay un constructor y el número de filas y columnas es siempre el mismo.
Datos de entradaDescubrimos cómo se forma el informe. Supongamos que todos los días se completan algunos datos, por ejemplo, la cantidad de vestidos vendidos, vestidos de verano, camisetas. Y en el informe vemos una agrupación de datos por categorías, colores, tamaños. Cuánto se vende por día / mes / hora.
Creamos un informe y nosotros mismos influimos en los datos de entrada:
- El número habitual (5 vestidos por día, aunque en lugares enormes este número puede ser 2000 o más, debe aclarar qué será más positivo para su sistema).
- Vacío, no vendió / vendió 1 artículo por mes.
- El volumen es irrealmente grande, con un máximo de cada producto, cada color, cada tamaño. Establecemos el máximo "mentiras en el almacén" y vendemos todo: dentro de un mes o incluso un día. ¿Qué dirá el informe?
Datos de salidaEn teoría, los datos de salida se correlacionan con los datos de entrada. En la entrada un poco → a la salida habrá un poco. En la entrada hay muchos, en la salida hay muchos.
Pero esto no siempre funciona. En ocasiones, los datos de entrada pueden eliminarse o, por el contrario, multiplicarse. Y luego podemos jugar de alguna manera con él.
Por ejemplo, el sistema
Dadat . Subes un archivo con una columna de nombre completo, en la salida obtienes varios a la vez:
- Nombre original, lo que estaba en el archivo;
- Nombre desmontado (si pudiste distinguirlo);
- Vara caso
- Dat caso
- Creat. caso
- Apellido
- Nombre
- Segundo nombre
- Estado de análisis: reconocimiento seguro por un mecanismo o verificado por una persona;

Tenemos 9. De una celda. Y esto es solo por nombre, y el sistema también puede analizar direcciones. Allí, se obtienen casi 50 de una celda: además de los componentes granulares, hay todo tipo de códigos KLADR, FIAS, OKATO ...
Y aquí es interesante. Resulta que podemos tener pocos datos en la entrada, pero muchos en la salida. Y si examinamos el máximo en columnas, entonces tenemos dos opciones:
- 500 columnas en la salida (que son aproximadamente 10 direcciones en la entrada);
- 500 columnas en la entrada (y un montón en la salida).
El principio también funciona en la dirección opuesta. ¿Qué pasa si la entrada es un montón de datos y la salida es cero? Si en lugar de un nombre completo hay algún tipo de tontería como "op34e8n8pe"? Luego resulta que todas las columnas adicionales están vacías, solo el estado del análisis "me enviaste basura". Entonces obtenemos un mínimo en la salida (un pequeño mouse), que también vale la pena verificar.
¡Y si los altavoces pueden ser excluidos! Es posible verificar la clase de equivalencia "cero" cuando el cero está en la salida, el archivo fuente no está vacío. Puede verificar al menos cuando salieron 1 columna de un centenar.
Lo principal aquí es recordar que, además de los datos de entrada, tenemos datos de salida. Y a veces en ellos puede verificar los límites, que no dependerán de los datos de entrada. Y entonces esto debe hacerse.
Aplicaciones móviles
Comunicación
Existen diferentes opciones de comunicación:
- Normal
- Muy higo (ratón pequeño);
- Súper rápido (grande).
Además, la comunicación deficiente puede ser parcial: si se encuentra en un área con Wi-Fi normal y una red celular deficiente. Internet funciona bien, pero el SMS es malo.
Cantidad de memoria
También es importante la cantidad de memoria que tiene la aplicación:
- Cantidad normal;
- Muy pocos;
- Mucho
Y si en este caso se pueden combinar las pruebas primera y tercera en este caso, entonces el ratoncito es muy interesante. Y hay diferentes opciones:
- ejecute la aplicación en el teléfono, que ya tiene poca memoria;
- ejecutar cuando la memoria es normal, colapsar, desplegar algo grande, intentar regresar a la primera aplicación.
Ahora, si la aplicación no sabe cómo reservar memoria normalmente, en el segundo caso simplemente se bloqueará, entonces la memoria ya se ha eliminado.
Dispositivo diagonal
- Estándar (estudiamos el mercado, mira qué es más popular entre nuestros usuarios).
- Mínimo (teléfono).
- Máximo (tableta grande).
Resolución de pantalla
- Estándar;
- El mas pequeño;
- El mas grande;
No confunda resolución y diagonal, estas son dos cosas diferentes. Es posible que tenga un dispositivo antiguo con una pantalla grande, pero tengo un nuevo teléfono inteligente de moda, donde la resolución es 5 veces mejor. Y lo que sucederá en 20 años es aterrador de imaginar.
Caminos GPX
Las rutas GPX son archivos XML con coordenadas secuenciales. Se pueden descargar en emuladores móviles para que el teléfono piense que se mueve en el espacio a cierta velocidad.
Útil si la aplicación lee las coordenadas GPS para algunos de sus propósitos. Por lo tanto, determina si vas, corres o montas. Y no puede correr, solo alimente las coordenadas de la aplicación, establezca el coeficiente de su aprobación y pruebe mientras está sentado en la oficina.
¿Qué probabilidades vale la pena ver? Todo según la mnemotecnia:
- 1 - coeficiente normal, reemplaza caminar simple;
- 0,01 - como si estuviera arrastrando meeeeeeeeeeeeeeeeeeeeeballyly;
- 200 - ni siquiera corras, ¡pero vuela!
¿Por qué debería verificarse todo esto? ¿Qué errores se pueden encontrar?
Por ejemplo, la aplicación puede estrellarse en el avión; se lanzó, pero se colapsó de inmediato. Ya que lee las coordenadas y trata de determinar tu velocidad. ¿Pero quién sabía que la velocidad estaría por encima de 130?
A baja velocidad, la aplicación puede bloquearse. Se fijará un millón de puntos intermedios y no podrá mantenerlos en su memoria. ¡Y eso es todo!
Ver también:¿Qué son las rutas GPX y por qué necesitan un probador? - Más información sobre las rutas de gpx y un ejemplo de dicho archivo
Resumen de ejemplos comunes
¡Quiero mostrar aquí que parece que "grande, pequeño" es un campo numérico y eso es todo!
Pero, de hecho, la mnemotecnia se puede usar en todas partes, ya sean archivos, juguetes, informes ... Y realmente nos ayuda a encontrar errores. Aquí hay algunos ejemplos de mi práctica:Ratoncito (límite inferior)- Fecha 01/01/1900Cuando trabajé en freelance, esta fecha arruinó todos los informes para mí. Porque incluso si el desarrollador estableció la protección del tonto, estableció la protección desde 0000. Pero no estableció la protección desde 1900.- Un personaje solitario al final de una línea.Esta prueba me la sugirió un colega más experimentado cuando discutimos ejemplos de uso de mnemotécnicos. Si el sistema verifica que el archivo esté vacío, es necesario verificar que no esté completamente vacío.Recomiendo esta prueba: agregue un terminador de línea al archivo. Ni siquiera un espacio, sino un personaje especial. Y vea cómo responde el sistema. Y ella no siempre responde bien =)Ratón grande (límite superior)Si hablamos de un ratón grande, generalmente hay un número infinito de errores:- Guerra y paz;- Una gran cantidad de datos;- 2 GB.Puede cargar guerra y paz en un campo de texto, cargar un archivo enorme en el sistema, obtener muchos datos de entrada o salida. Todos estos son errores comunes que he encontrado en mi práctica. Y no solo yo, el límite superior a menudo se verifica solo porque saben que puede haber errores. Más bien, se olvidan del pequeño ratón.Otro ejemplo de un mouse grande es la prueba de esfuerzo. Oh! Tengo esos ejemplos, así que vamos al hardcore.Si conoce el contexto, si sabe cómo funciona su aplicación en su interior, en qué lenguaje de programación está escrita, en qué base de datos usa, también puede usar este mnemotécnico. Y quiero mostrar esto con ejemplos concretos.Mis ejemplos de práctica
Ratón grande
Linux, Lucene, Mmap
En el sistema operativo Linux, hay una configuración para el número máximo de descriptores de archivo abiertos:- redhat-6 - /etc/security/limits.conf
- redhat-7 - / etc / systemd / system / [nombre del servicio] .service.d / limits.conf (para cada servicio propio)
Se abre un descriptor de archivo para cualquier acción con archivos:- crear una conexión de base de datos;
- lee el archivo;
- escribir en un archivo
- ...
Si su sistema trabaja activamente con archivos y realiza muchas operaciones, es necesario aumentar la configuración. De lo contrario, la menor carga lo pondrá.Nuestro sistema utiliza el índice de búsqueda Lucene. Esto es cuando tomamos algunos datos de la base de datos y los cargamos en el disco, para que luego podamos buscarlos más rápido. Y si creamos el índice usando la tecnología mmap, entonces crea muchos archivos para escribir durante la construcción del índice.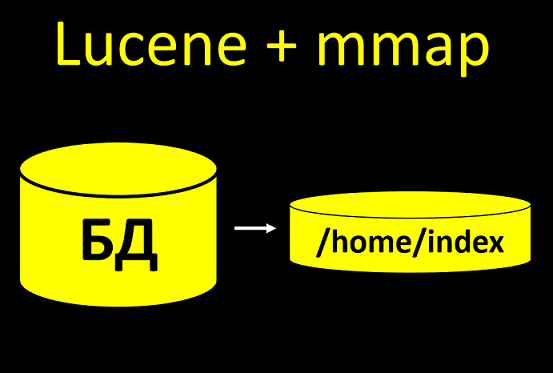 La base de prueba generalmente tiene 100 clientes, bueno, 1000. No tantos. La reconstrucción se ejecuta sin problemas, incluso si no configura los descriptores.Y en el sistema real habrá más de 10 millones de clientes. Y si no configura el número de descriptores de archivo allí, cuando comience a crear índices, todo se bloqueará.Necesita saber sobre esto e inmediatamente escribir una instrucción: configure el sistema operativo en el servidor, de lo contrario habrá tales y tales consecuencias. Y por su parte, es importante realizar no solo pruebas funcionales, sino también pruebas de estrés, en una cantidad real de datos.
La base de prueba generalmente tiene 100 clientes, bueno, 1000. No tantos. La reconstrucción se ejecuta sin problemas, incluso si no configura los descriptores.Y en el sistema real habrá más de 10 millones de clientes. Y si no configura el número de descriptores de archivo allí, cuando comience a crear índices, todo se bloqueará.Necesita saber sobre esto e inmediatamente escribir una instrucción: configure el sistema operativo en el servidor, de lo contrario habrá tales y tales consecuencias. Y por su parte, es importante realizar no solo pruebas funcionales, sino también pruebas de estrés, en una cantidad real de datos.Redhat 6 ≠ Redhat 7
Cuando pruebe un mouse grande (carga), no olvide que en diferentes configuraciones la aplicación funcionará de manera diferente. Si toma las instrucciones del último párrafo, no solo debe escribirse, sino también marcarse. Y verifique en el entorno del cliente.Porque los diferentes sistemas operativos funcionan de manera diferente. Y tuvimos una situación tal que todo parece estar configurado, pero el sistema se bloquea y dice "No tengo suficientes descriptores de archivos abiertos". Decimos:- Verifique el parámetro.- Está configurado, ¡todo está de acuerdo con tus instrucciones!¿Cómo es eso?
¡Resulta que tenemos instrucciones para Redhat 6, y tienen Redhat 7, donde la configuración está en un lugar completamente diferente! Como resultado, lo hicieron de acuerdo con instrucciones que no funcionan y como si no lo hicieran en absoluto.Entonces, si está trabajando con diferentes versiones de distribuciones de Linux, debe verificarlas todas. Y no solo implementa los servicios en una máquina, sino que también realiza pruebas de carga al menos una vez: asegúrese de que todo funcione. Después de todo, es mejor detectar un error en un entorno de prueba que comprender la producción más adelante.Java y recolección de basura
Usamos el lenguaje java, que tiene un recolector de basura incorporado ... A veces parece que si la aplicación usa mucha memoria y está al borde de OOM (Memoria insuficiente) para una operación compleja, puede resolver este problema fácilmente simplemente aumentando la cantidad de memoria disponible ! ¿Por qué probar?En realidad no Dale mucho Xmx: la aplicación se colgará en el recolector de basura ... Y se manifiesta de repente para el usuario. Aquí por la noche archivaron una gran carga, descargaron una gran cantidad de datos, especialmente después de horas, para no molestar a nadie. Por la mañana llega el usuario, aunque es el único que trabaja con el sistema, casi no hay carga y todo se está congelando. Y él ni siquiera entiende por qué.Pero, de hecho, la carga ha pasado, la carga se ha ido y el recolector de basura ha salido a limpiar todo, debido a este friso. Y aunque ahora no hay carga y un usuario solitario está trabajando, está triste.Por lo tanto, solo asignando mucha memoria a la aplicación "y no puede probarla", esto no funciona. Mejor cheque.
Y se manifiesta de repente para el usuario. Aquí por la noche archivaron una gran carga, descargaron una gran cantidad de datos, especialmente después de horas, para no molestar a nadie. Por la mañana llega el usuario, aunque es el único que trabaja con el sistema, casi no hay carga y todo se está congelando. Y él ni siquiera entiende por qué.Pero, de hecho, la carga ha pasado, la carga se ha ido y el recolector de basura ha salido a limpiar todo, debido a este friso. Y aunque ahora no hay carga y un usuario solitario está trabajando, está triste.Por lo tanto, solo asignando mucha memoria a la aplicación "y no puede probarla", esto no funciona. Mejor cheque.Mosca salvaje
El servidor de aplicaciones WildFly java no permitirá descargar archivos grandes si no está configurado en consecuencia. Utilizamos el servidor de aplicaciones Jboss, también conocido como Wildfly. Y resulta que, de forma predeterminada, no puede cargar archivos grandes en él. Y recordamos que el mouse debe ser GRANDE. Si probamos 5mb o 50, todo funciona, todo está bien.Pero si intenta descargar 2GB, el sistema da un error 404 y no puede entender nada de los registros: los registros de la aplicación están vacíos. Debido a que esta aplicación no puede descargar un archivo, Wildfly mismo lo corta.Si no realiza pruebas de su lado, el cliente puede encontrar esto. Y será muy desagradable, vendrá con la pregunta "¿Por qué no está cargado?", Y sin el desarrollador no se puede decir nada. Por lo tanto, es mejor no olvidarse de probar los límites, incluidos los archivos grandes que se insertarán en el sistema. Al menos sabrás el resultado de tales acciones.Y aquí lo arreglamos aumentando el parámetro max-post-size, o damos información sobre la restricción y la prescribimos en la declaración de trabajo.
Utilizamos el servidor de aplicaciones Jboss, también conocido como Wildfly. Y resulta que, de forma predeterminada, no puede cargar archivos grandes en él. Y recordamos que el mouse debe ser GRANDE. Si probamos 5mb o 50, todo funciona, todo está bien.Pero si intenta descargar 2GB, el sistema da un error 404 y no puede entender nada de los registros: los registros de la aplicación están vacíos. Debido a que esta aplicación no puede descargar un archivo, Wildfly mismo lo corta.Si no realiza pruebas de su lado, el cliente puede encontrar esto. Y será muy desagradable, vendrá con la pregunta "¿Por qué no está cargado?", Y sin el desarrollador no se puede decir nada. Por lo tanto, es mejor no olvidarse de probar los límites, incluidos los archivos grandes que se insertarán en el sistema. Al menos sabrás el resultado de tales acciones.Y aquí lo arreglamos aumentando el parámetro max-post-size, o damos información sobre la restricción y la prescribimos en la declaración de trabajo.Registro
Otro ejemplo para probar el mouse "grande". Sí, recuerda de alguna manera más ejemplos ... ¡La mayoría de las veces, atrapa insectos!Digamos que verificamos el registro de errores. Que el error se escriba en el seguimiento de la pila en el registro. Así que lo comprobamos, somos geniales: sí, todo está bien, ¡todo está grabado! Y entendí todo, desde la pila en el texto de error. Si el cliente se cae, inmediatamente entenderé por qué. ¿Y qué sucederá si no tenemos un error, sino varios? ¡Todo está bien también, todo está registrado, todo está bien! Pero recordamos que el mouse debe ser GRANDE:
¿Y qué sucederá si no tenemos un error, sino varios? ¡Todo está bien también, todo está registrado, todo está bien! Pero recordamos que el mouse debe ser GRANDE: ¿Qué sucederá si tenemos MUCHOS errores? Acabamos de tener esta situación. El sistema de origen carga datos a la tabla de búfer en la base de datos. Nuestro sistema toma estos datos desde allí y de alguna manera luego trabaja con ellos.El sistema de origen se bloqueó y cargó un incremento incorrecto, donde todos los datos eran erróneos. Nuestro sistema tomó el incremento, y hay 13,600 errores. Y cuando Java intentó generar un seguimiento de pila para errores de 13k, se comió toda la memoria que se le asignó, y luego dijo "Oh, espacio de almacenamiento dinámico de Java".¿Cómo arreglarlo? Agregamos el parámetro maxStoredErrors (predeterminado 100) a la tarea de carga: el número máximo de errores almacenados en la memoria para una secuencia. Al alcanzar esta cantidad, se registran los errores y se borra la lista.También eliminamos la duplicación de mensajes de error sobre la ejecución de una tarea por nuestra Tarea y Quarz RunShell, aumentando el nivel de registro de este último para advertir (el mensaje se muestra en la información). Debido a la duplicación, la pila se duplicó ...¿Y cuál es la conclusión de esta historia? No es suficiente marcar "justo". Esta es una prueba importante y útil, sí, nadie discute. Observamos si el error se registra en principio, en qué prueba, etc. Pero entonces es muy importante verificar el GRAN mouse. ¿Qué pasa si hay muchos errores?Y debe comprender que "mucho", esto significa mucho. Si carga un incremento de 10 errores y dice "10 errores también son normales, el sistema muestra todos los rastros de la pila", entonces parece que hicieron la prueba, pero no revelaron el problema. Si vemos que el sistema muestra todos los mensajes, debemos pensar con anticipación: ¿qué sucederá si hay MUCHOS de ellos? Y echa un vistazo.
¿Qué sucederá si tenemos MUCHOS errores? Acabamos de tener esta situación. El sistema de origen carga datos a la tabla de búfer en la base de datos. Nuestro sistema toma estos datos desde allí y de alguna manera luego trabaja con ellos.El sistema de origen se bloqueó y cargó un incremento incorrecto, donde todos los datos eran erróneos. Nuestro sistema tomó el incremento, y hay 13,600 errores. Y cuando Java intentó generar un seguimiento de pila para errores de 13k, se comió toda la memoria que se le asignó, y luego dijo "Oh, espacio de almacenamiento dinámico de Java".¿Cómo arreglarlo? Agregamos el parámetro maxStoredErrors (predeterminado 100) a la tarea de carga: el número máximo de errores almacenados en la memoria para una secuencia. Al alcanzar esta cantidad, se registran los errores y se borra la lista.También eliminamos la duplicación de mensajes de error sobre la ejecución de una tarea por nuestra Tarea y Quarz RunShell, aumentando el nivel de registro de este último para advertir (el mensaje se muestra en la información). Debido a la duplicación, la pila se duplicó ...¿Y cuál es la conclusión de esta historia? No es suficiente marcar "justo". Esta es una prueba importante y útil, sí, nadie discute. Observamos si el error se registra en principio, en qué prueba, etc. Pero entonces es muy importante verificar el GRAN mouse. ¿Qué pasa si hay muchos errores?Y debe comprender que "mucho", esto significa mucho. Si carga un incremento de 10 errores y dice "10 errores también son normales, el sistema muestra todos los rastros de la pila", entonces parece que hicieron la prueba, pero no revelaron el problema. Si vemos que el sistema muestra todos los mensajes, debemos pensar con anticipación: ¿qué sucederá si hay MUCHOS de ellos? Y echa un vistazo.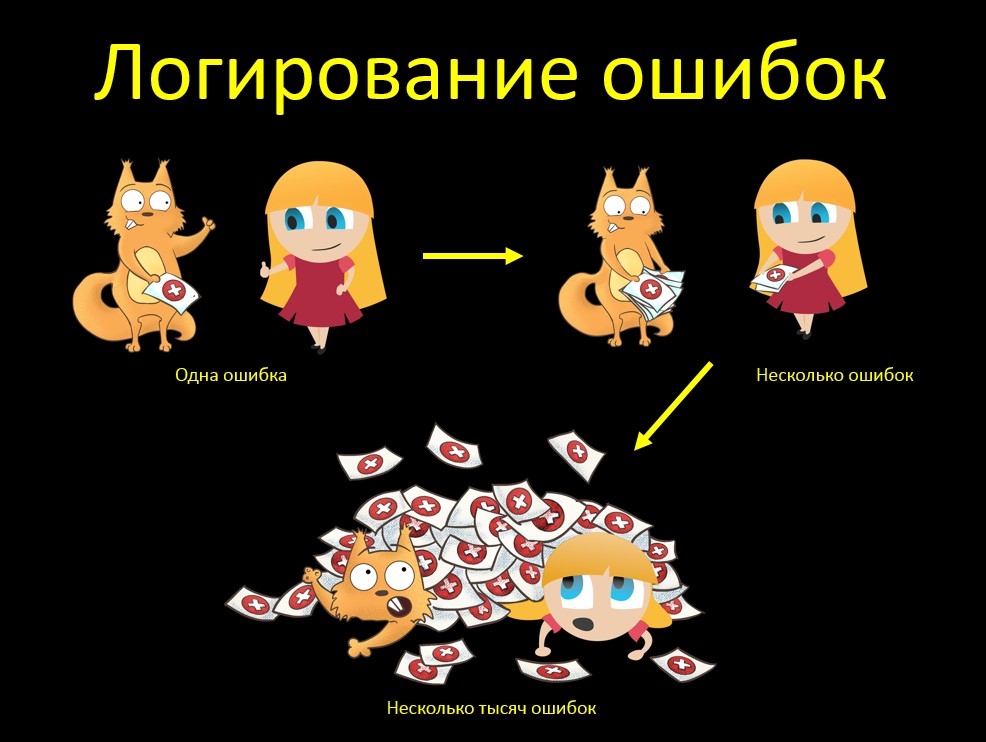
Transliteración
- , , ? , , ?
=
=?

, ? , , . :
, «»

Oracle RAC
Oracle es una base de datos popular. Oracle RAC es cuando tiene varias instancias de base de datos. Es necesario garantizar el buen funcionamiento de los sistemas críticos del negocio: incluso si una instancia se rompe, el resto continúa funcionando, el usuario ni siquiera lo sabrá.
Si utiliza Oracle RAC, es OBLIGATORIO realizar pruebas de carga en él. Si no lo tiene, debe pedirle al cliente con quién se encuentra que realice la carga de lado.
Aquí puede surgir la pregunta: ¿por qué entonces no la tiene? Es simple, el hardware para las pruebas suele ser siempre peor. Y si el sistema se centra únicamente en Oracle y RAC usa un cliente de cada veinte, entonces comprarlo para probar no será rentable, ya que RAC es muy costoso. Es más fácil negociar con un cliente y ayudarlo a realizar pruebas.
¿Qué sucede si no se realizan pruebas de carga? Aquí hay un ejemplo de la vida.
En la base de datos existe la oportunidad de crear una columna y decir que es un campo de incremento automático. Esto significa que no completa el campo en absoluto; la base de datos lo genera. ¿Hay una nueva línea? Grabé el valor "1". ¿Otra nueva línea? Ella tendrá un valor de "2". Y cada nuevo valor será más y más.
Entonces, por ejemplo, es muy conveniente generar identificadores. Siempre sabes que tu identificación es única. Y para cada nueva línea es más que para la anterior. En teoría ...
Tenemos dos identificadores de entidad en nuestro sistema:
- id: identificador de una versión específica, campo de incremento automático;
- hid es un identificador histórico; para una entidad siempre es constante y no cambia.
Como resultado, puede seleccionar de acuerdo con una versión específica, o puede seleccionar oculto de una entidad y ver su historial completo.
Cuando se crea una entidad, id = hid. Y luego la identificación crece, siempre es mayor para las nuevas versiones que hid. Por lo tanto, la fórmula para determinar la versión:
version = (id - hid) + 1No puede ser negativo, ya que la propia base de datos crea la identificación.
Pero aquí vienen a nosotros con una pregunta en esencia y muestran registros de la base de datos. No recuerdo de qué se trataba esa pregunta, y no importa. Miro los registros y no puedo creer lo que veo: allí la versión tiene valores negativos. ¿Cómo es eso? Esto es imposible Resultó ser posible.
En RAC, cada nodo tiene su propia caché. Y puede suceder que los nodos no tengan tiempo para notificarse entre sí, y que tenga el mismo número dos veces en la tableta:
- Crea una entidad. Noda busca en el caché, ¿cuál es el último valor del campo de incremento automático? Sí, 10. Entonces le daré el identificador 11.
- Inmediatamente, una nueva entidad llega al segundo nodo (las solicitudes llegaron simultáneamente y el equilibrador arrojó una en el nodo 1 y la segunda en el nodo 2).
- El segundo nodo se ve en su caché, ¿cuál es el último valor del campo? Sí, 10 (el primer nodo aún no ha logrado informar al segundo que tomó este número). Entonces le daré el identificador 11.
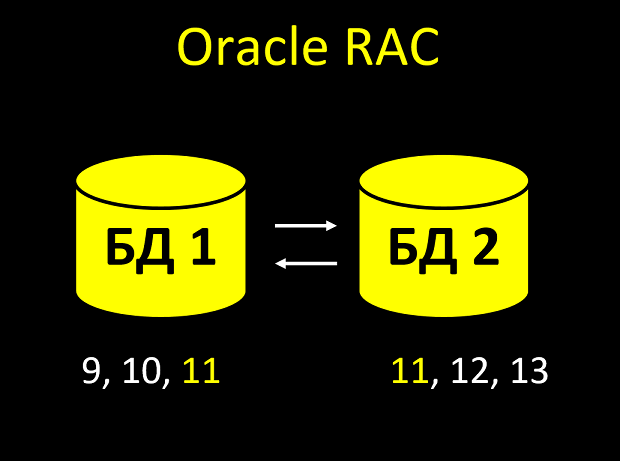
Total recibimos un valor no único de un campo único. Y después de todo, con una gran carga de tales intersecciones de identificadores, no habrá uno o incluso dos ... Si tiene toda la lógica de negocios vinculada al hecho de que la identificación siempre es única y siempre aumenta, será OU.
En nuestro caso, no ocurrió nada catastrófico, y las pruebas de carga en el banco de pruebas del cliente ayudaron. Encontramos el problema temprano, ya que resultó que las versiones negativas del sistema no interfieren con la vida. Pero agregamos secuenciación secuencial a los scripts de creación de bases de datos, solo para tales casos.
La moraleja de esta fábula es esta: es MUY importante realizar pruebas de carga en el mismo hardware que estará en PROD. Todo puede afectar el resultado: la configuración del sistema operativo en sí, la configuración de la base de datos, sí, cualquier cosa. Lo que ni siquiera sospechaste.
Prueba por adelantado. Y recuerde que no todos los problemas se pueden encontrar mediante pruebas funcionales. En este ejemplo, una prueba simple no encontraría errores. De hecho, si crea entidades manualmente, es decir, lentamente, todos los nodos de la base de datos tendrán tiempo para notificar a los nodos vecinos, por lo que no obtendremos inconsistencias.
Ratoncito
Json vacío
Si usa la biblioteca Axis abierta, intente enviar un JSON vacío a la aplicación. Es muy posible que lo cuelgue por completo.
Y lo más importante: ¡no puedes hacer nada al respecto de tu lado! Este es un error en una biblioteca de terceros. Así que aquí, ya sea esperando una corrección oficial o cambiando la biblioteca, lo que puede ser muy difícil.
De hecho, este error ya se ha solucionado en la nueva versión de Axis. Parece que solo se actualiza, ¡y eso es todo! Pero ... El sistema rara vez usa una biblioteca de terceros. Por lo general, hay varios de ellos, están atados uno encima del otro. Para actualizarlos, debe actualizar todo de una vez. Es necesario llevar a cabo la refactorización, porque ahora funcionan de manera diferente. Los recursos del desarrollador deben ser asignados.
En general, solo actualizar la versión de la biblioteca a veces requiere una versión completa de un desarrollador genial. Entonces, por ejemplo, cuando nos mudamos a la nueva versión de Lucene, pasamos 56 horas en la tarea, esto es 7 días-hombre, una semana del desarrollador a tiempo completo y más pruebas. La tarea en sí se parece a esto, el arquitecto lo dice:
Lucene Cambie a usar PointValues en lugar de Long / IntegerField
El muelle Lucene Migration 5 -> 6 tiene una cláusula sobre dejar caer el campo largo (entero / doble) a favor de PointValues.
Al cambiar a Lucene 6.3.1, dejé los campos antiguos (todas las clases fueron renombradas con la adición del prefijo Legacy), porque la traducción pasa a una tarea separada.
Debe abandonar los campos antiguos y usar las clases de punto largo (entero / doble), que son más rápidas y menos ponderadas en el índice por pruebas. Hay que reescribir mucho código.
Claro! La transición debe ser compatible con versiones anteriores para que la búsqueda (al menos las funciones clave) no se interrumpa con la actualización de la versión. Debería funcionar en el índice anterior (antes de la reconstrucción), y después de la reconstrucción (en un momento conveniente para el cliente), deberían seleccionarse nuevos campos.
¡Y esto es solo una actualización de la biblioteca! Y abandonar una biblioteca debido a un error en ella generalmente da miedo imaginar cuánto tiempo llevará ...
Por lo tanto, es muy posible que durante algún tiempo simplemente viva con un error. Sepa sobre él, pero no cambie nada. Al final, "no hay nada para enviar solicitudes tontas".
Pero en cualquier caso, al menos debe saber sobre la presencia de un error. Porque si un usuario viene a ti y te dice: "Todo te ha colgado", debes entender por qué. Dado que los registros están vacíos. Debido a que esta no es la congelación de su aplicación, todo se bloquea en la etapa de conversión JSON.
Al parecer, ¡una solicitud vacía! Y aquí puede conducir a ... Es decir, incluso si no sabe que Axis tiene ese error, simplemente puede verificar si hay JSON vacío, una solicitud SOAP vacía. Al final, este es un gran ejemplo de una prueba de cero en el contexto de una solicitud JSON.
Recuerda probar cero. Y el menor valor es el ratoncito, porque también trae errores, a veces tan aterradores.
Ver también:La clase de equivalencia "Cero-no cero" - más sobre probar cero
"Moscú" en el campo de dirección
El servicio
de Dadat puede estandarizar direcciones:
diseñe la dirección en una línea en componentes granulares + determine el área del apartamento, si está en el directorio.
Durante las pruebas, se encontró un error divertido: si ingresa la palabra "Moscú" en la dirección, el sistema determina el área del apartamento. Aunque, al parecer, ¿dónde está el apartamento en esta "dirección"?

Creo que este es un gran ejemplo de un "ratoncito". Porque lo que generalmente se verifica? La dirección habitual, la dirección de la calle, de la casa ... Un campo vacío. Cualquier carácter individual: esto se considera una prueba unitaria.
Pero si ingresa una letra, el sistema determinará la entrada como una papelera completa y borrará la dirección. Se comporta correctamente, pero este es un caso negativo por unidad. Esta es una verificación de la longitud exclusiva del campo.
Y aquí vale la pena pensar más: ¿hay una unidad positiva? Hay Una palabra, tal sistema determinará. Y aquí, también, hay diferentes clases de equivalencia: puede ser una palabra desde el principio de la dirección (ciudad), o puede ser desde el medio (calle). Vale la pena probar ambos. Pero si se limita solo a "unidad en el campo de texto = un carácter", nunca encontrará este error.
Total
Mnemónico hay muchos. Y usarlos puede ayudarte. Debido a que ya está viendo su solicitud por décima, centésima vez ... Ya ha perdido la vista, puede omitir el error obvio. Y si toma alguna mnemotecnia existente, mire la aplicación de una manera nueva. Lo que ayudará a detectar nuevos errores.
E incluso una mnemotecnia tan simple como BMW ayuda mucho. Pero, parece ... ¡Grande, pequeño, piensa! Valores límite simples. ¡Pero siempre deben ser recordados y siempre controlados! Trae frutas y una variedad de insectos.
Utilizando mis ejemplos, quería mostrar que puede buscar bordes no solo en un campo de texto o numérico. Mnemonics funciona en todas partes: en Oracle RAC, Java, Wildfly, en cualquier lugar. Aprenda a mirar los límites más allá de la comprensión habitual de "ingresar Guerra y Paz en el cuadro de texto".
Por supuesto, el énfasis principal está en el "ratón grande", que trae la mayoría de los errores. Son precisamente esos casos los que se recuerdan cuando cree que se ha reunido en su proyecto.
Pero no debes olvidarte del "ratoncito". Sí, pude recordar solo un par de ejemplos específicos de mi trabajo. Pero esto no significa que no encuentre errores en un mouse pequeño. Lo encuentro! Los que están en la sección de ejemplos generales: 01.01.1900 fecha, archivo de 1 kb, informe vacío cuando se completan los datos ...
Las fronteras son muy importantes. Recuerda probarlos. Espero que mis ejemplos te inspiren, y los mnemotécnicos de BMW siempre aparecerán en mi cabeza al resaltar las clases de equivalencia.
O tal vez se te ocurra tu propia mnemotecnia. Lo que será para usted, para su equipo, para sus funciones, para sus procesos. Y también es genial, también es éxito. ¡Lo principal es que ayuda!
PS es un extracto de
mi libro para evaluadores principiantes. También hablé sobre mnemotecnia en un informe sobre SQA Days,
video aquí .