Hola Mi nombre es Konstantin Evteev, trabajo en Avito como líder de la unidad DBA. Nuestro equipo desarrolla sistemas de almacenamiento Avito, ayuda en la selección o emisión de bases de datos y la infraestructura relacionada, es compatible con el objetivo de nivel de servicio para servidores de bases de datos, y también somos responsables de la eficiencia y el monitoreo de los recursos, asesorar sobre el diseño y posiblemente desarrollar microservicios, vinculado a sistemas de almacenamiento o servicios para el desarrollo de la plataforma en el contexto del almacenamiento.
Quiero contarles cómo resolvimos uno de los desafíos de la arquitectura de microservicios: realizar transacciones comerciales en la infraestructura de servicios creados utilizando la base de datos por patrón de servicio. Hice una presentación sobre este tema en la conferencia Highload ++ Siberia 2018 .

Teoría Lo más corto posible
No describiré en detalle la teoría de las sagas. Te daré solo una breve introducción para que entiendas el contexto.
Como era antes (desde el comienzo de Avito hasta 2015 - 2016): vivíamos en un monolito, con bases monolíticas y aplicaciones monolíticas. En algún momento, estas condiciones comenzaron a impedirnos crecer. Por un lado, nos encontramos con el rendimiento de un servidor con una base de datos principal, pero esta no es la razón principal, ya que el problema de rendimiento se puede resolver, por ejemplo, mediante el uso de fragmentos. Por otro lado, el monolito tiene una lógica muy compleja, y en una determinada etapa de crecimiento, la entrega de cambios (lanzamientos) se vuelve muy larga e impredecible: hay muchas dependencias no obvias y complejas (todo está estrechamente conectado), también es difícil de probar, en general hay muchos problemas. La solución es cambiar a la arquitectura de microservicios. En esta etapa, teníamos una pregunta con las transacciones comerciales fuertemente ligadas a los ACID proporcionados por una base monolítica: no está claro cómo migrar esta lógica comercial. Cuando se trabaja con Avito, hay muchos escenarios diferentes implementados por varios servicios, cuando la integridad y la consistencia de los datos es muy importante, por ejemplo, comprar una suscripción premium, debitar dinero, solicitar servicios a un usuario, comprar paquetes VAS; en caso de circunstancias imprevistas o accidentes, todo puede no ir inesperadamente De acuerdo al plan. Encontramos la solución en las sagas.
Me gusta la descripción técnica de las sagas en 1987 por Kenneth Salem y Héctor García Molina, uno de los miembros actuales de la junta directiva de Oracle. Cómo se formuló el problema: hay un número relativamente pequeño de transacciones de larga duración que durante mucho tiempo impiden la ejecución de operaciones pequeñas, menos demandantes de recursos y más frecuentes. Como resultado deseado, puede dar un ejemplo de la vida: seguramente, muchos de ustedes hicieron cola para copiar documentos, y el operador de la copiadora, si tenía la tarea de copiar un libro completo o solo muchas copias, hacía copias de otros miembros de la cola de vez en cuando. Pero disponer de recursos es solo una parte del problema. La situación se ve agravada por bloqueos a largo plazo cuando se realizan tareas intensivas en recursos, cuya cascada se construirá en su DBMS. Además, pueden ocurrir errores durante una transacción larga: la transacción no se completará y comenzará la reversión. Si la transacción fue larga, entonces la reversión también tomará mucho tiempo, y probablemente habrá un reintento desde la aplicación. En general, "todo es bastante interesante". La solución propuesta en la descripción técnica de SAGAS es dividir una transacción larga en partes.
Me parece que muchos se acercaron a esto sin siquiera leer este documento. Hemos hablado repetidamente sobre nuestro defproc (procedimientos diferidos implementados usando pgq). Por ejemplo, cuando bloqueamos a un usuario por fraude, realizamos rápidamente una transacción corta y respondemos al cliente. En esta breve transacción, que incluye, colocamos la tarea en una cola transaccional, y luego de forma asíncrona, en pequeños lotes, por ejemplo, diez anuncios bloquean sus anuncios. Lo hicimos implementando colas transaccionales desde Skype .
Pero nuestra historia de hoy es un poco diferente. Necesitamos ver estos problemas desde el otro lado: aserrando un monolito en microservicios creados usando la base de datos por patrón de servicio.
Uno de los parámetros más importantes para nosotros es lograr la máxima velocidad de corte. Por lo tanto, decidimos transferir la funcionalidad anterior y toda la lógica tal como es a los microservicios, sin cambiar nada en absoluto. Requisitos adicionales que necesitábamos cumplir:
- Proporcionar cambios de datos dependientes para datos críticos del negocio.
- ser capaz de establecer un orden estricto;
- observar un cien por ciento de consistencia: coordinar los datos incluso en caso de accidentes;
- Garantizar el funcionamiento de las transacciones a todos los niveles.
Según los requisitos anteriores, la solución en forma de saga orquestada es la más adecuada.
Implementación de una saga orquestada como un servicio PG Saga
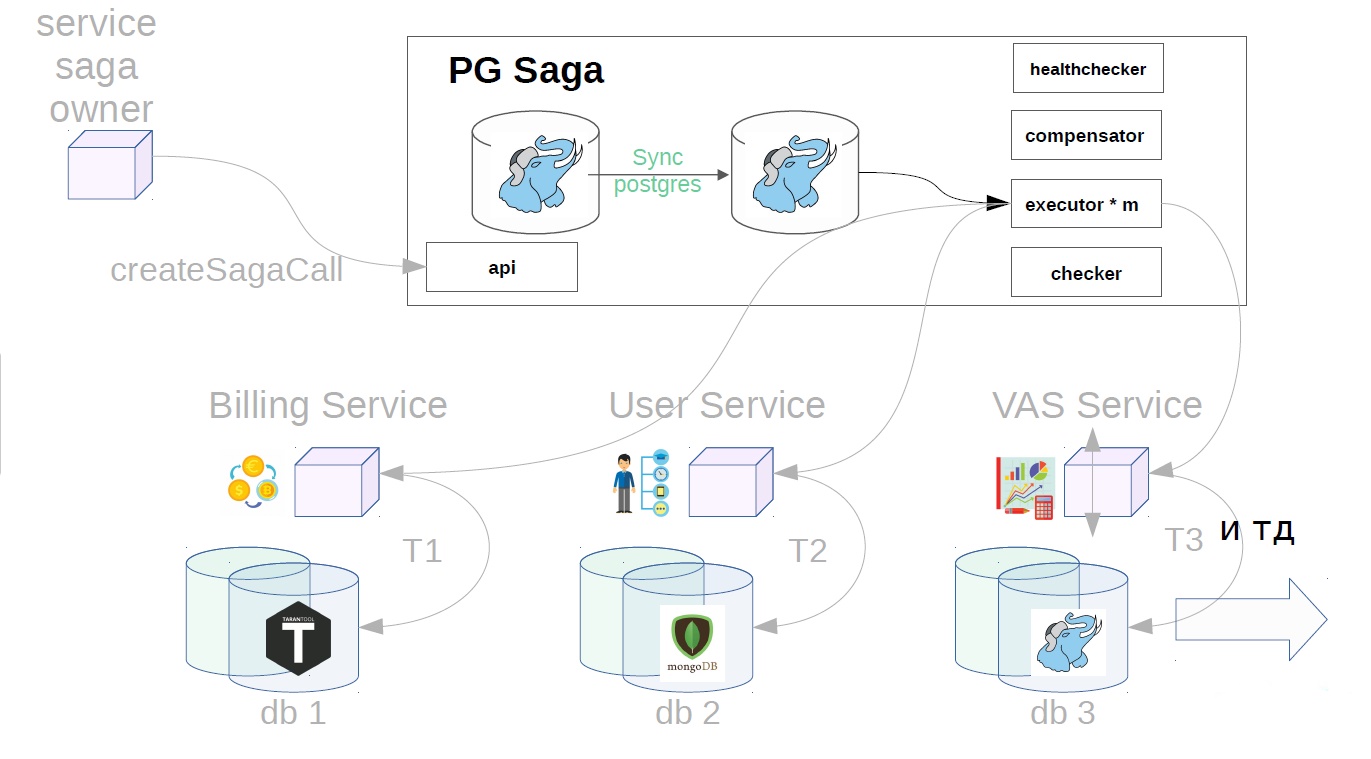
Así es como se ve el servicio PG Saga.
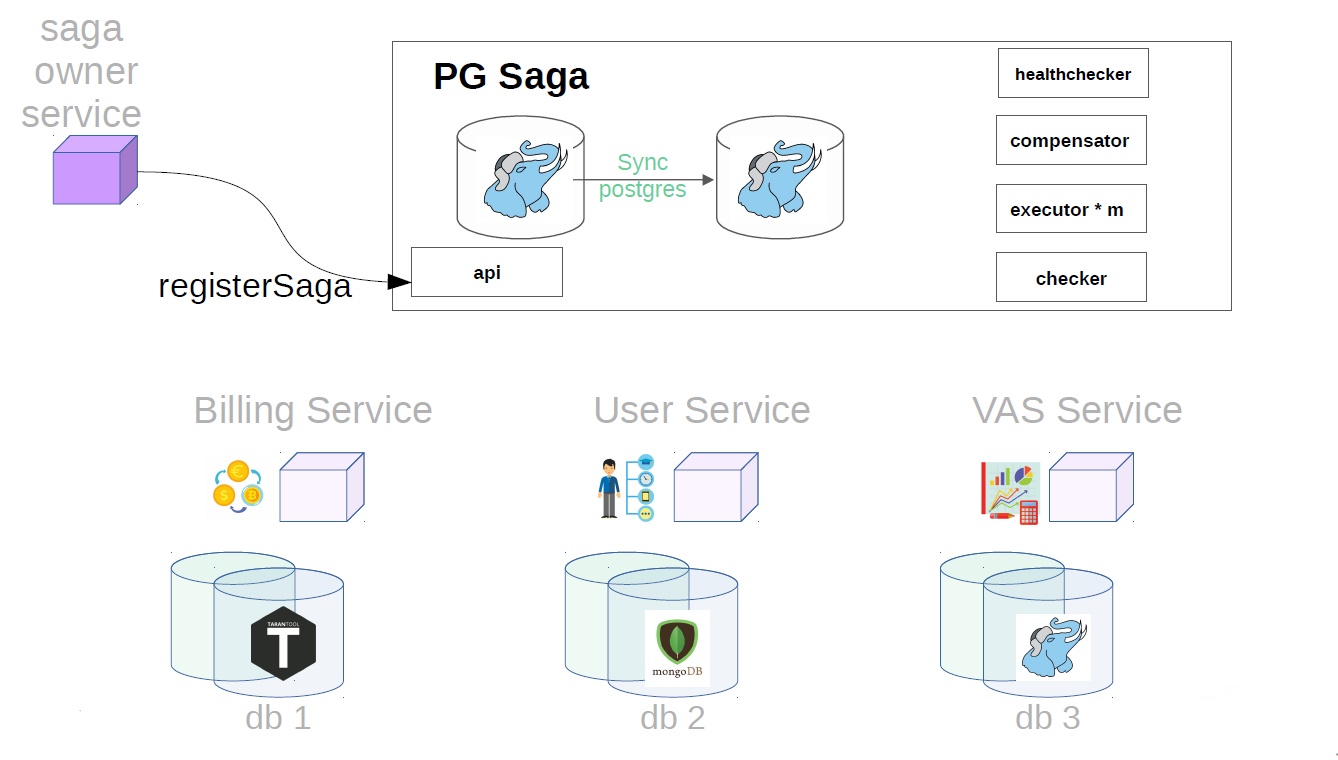
PG en el nombre, porque PostgreSQL síncrono se usa como un repositorio de servicios. ¿Qué más hay dentro?
- API
- albacea
- corrector
- chequeador de salud;
- compensador
El diagrama también muestra al propietario del servicio de las sagas, y a continuación se muestran los servicios que realizarán los pasos de la saga. Pueden tener diferentes repositorios.
Como funciona
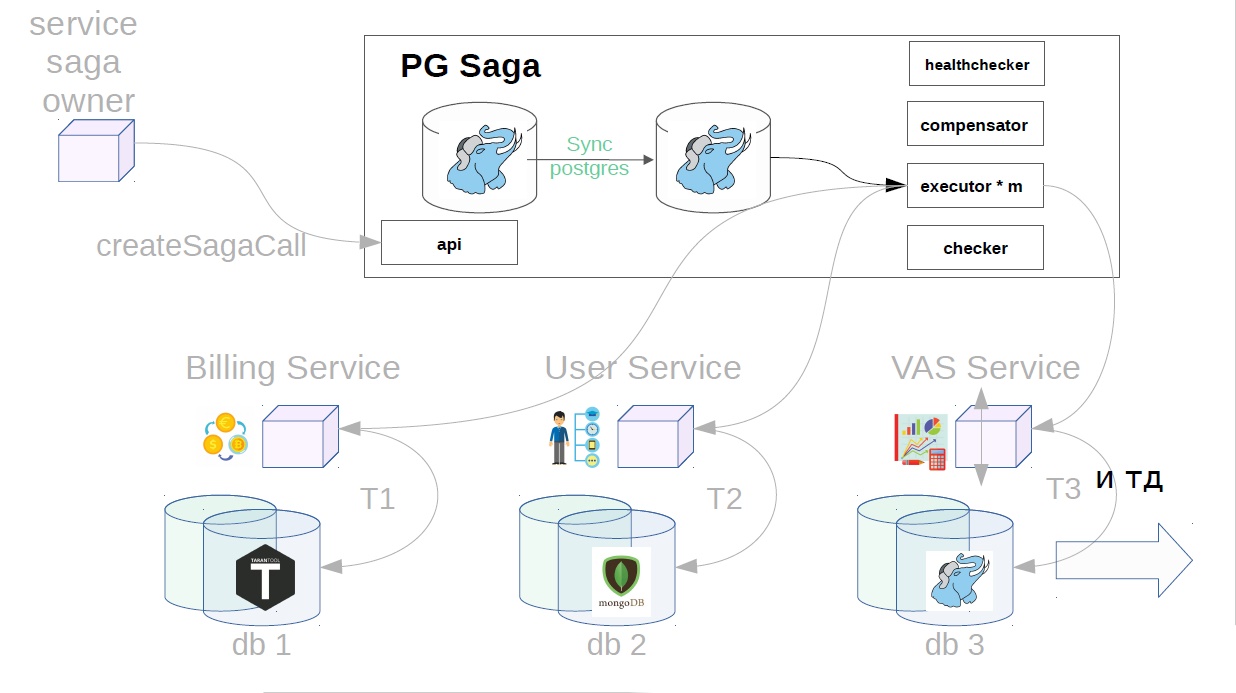
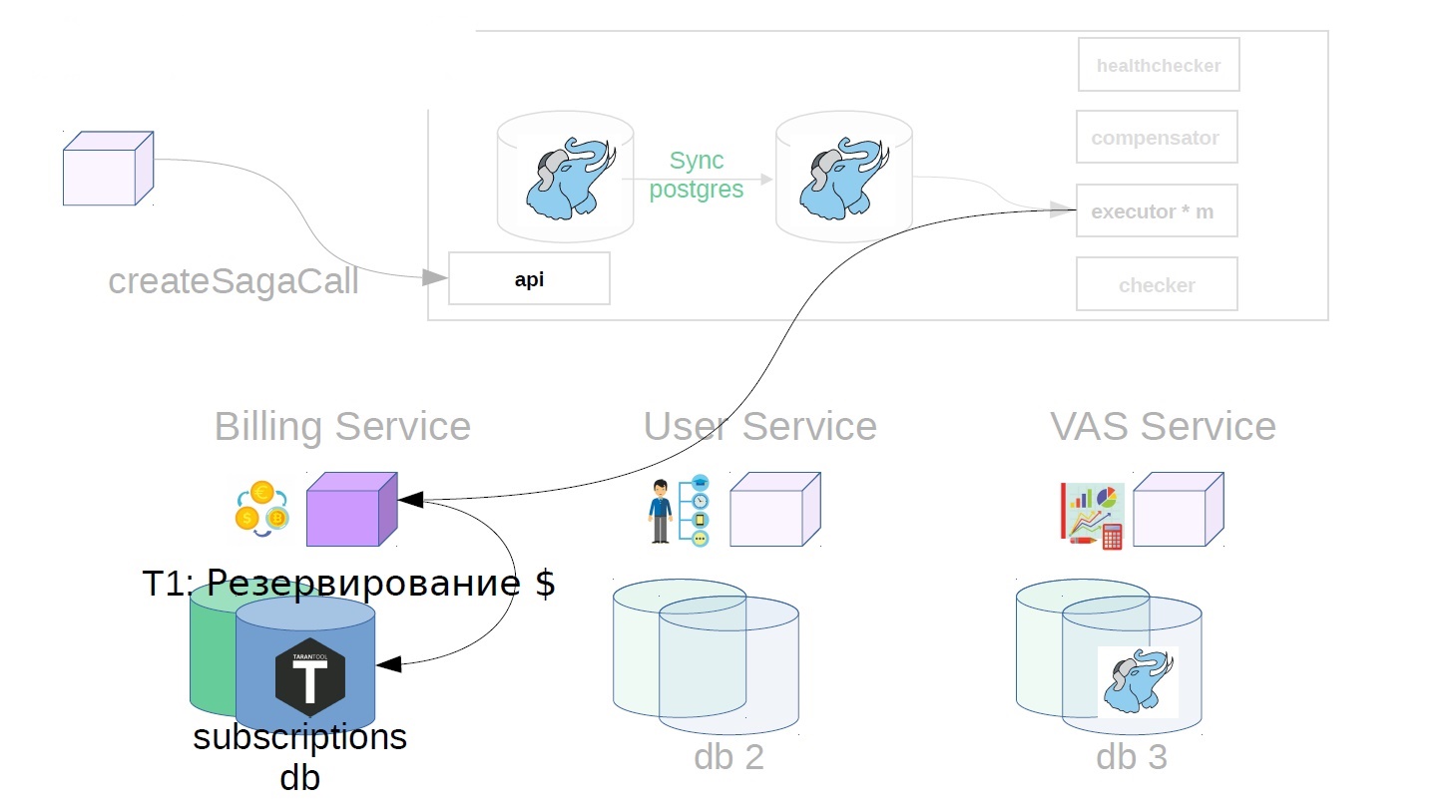
Considere el ejemplo de comprar paquetes VAS. VAS (servicios de valores agregados): servicios pagados para la promoción de anuncios.
Primero, el propietario del servicio de la saga debe registrar la creación de la saga en el servicio de saga
Después de eso, genera una clase de saga ya con Payload.
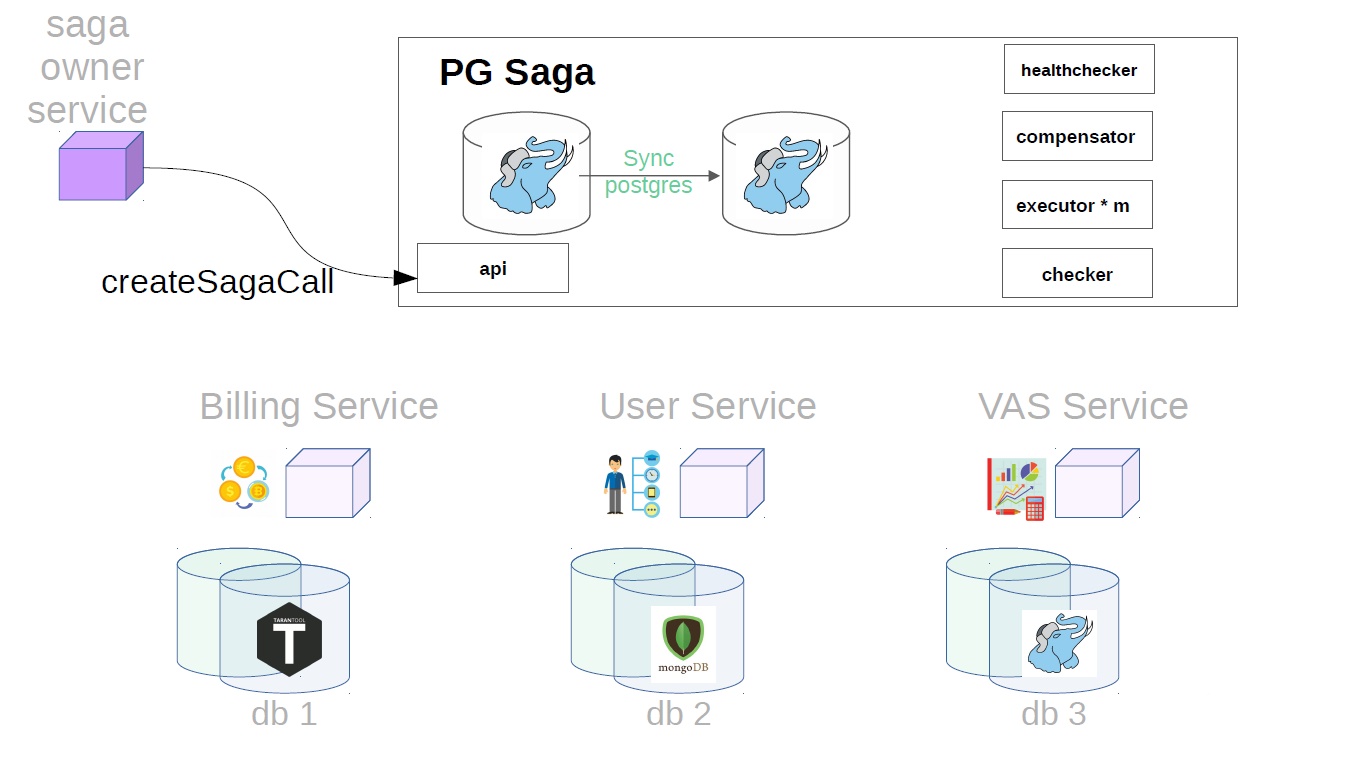
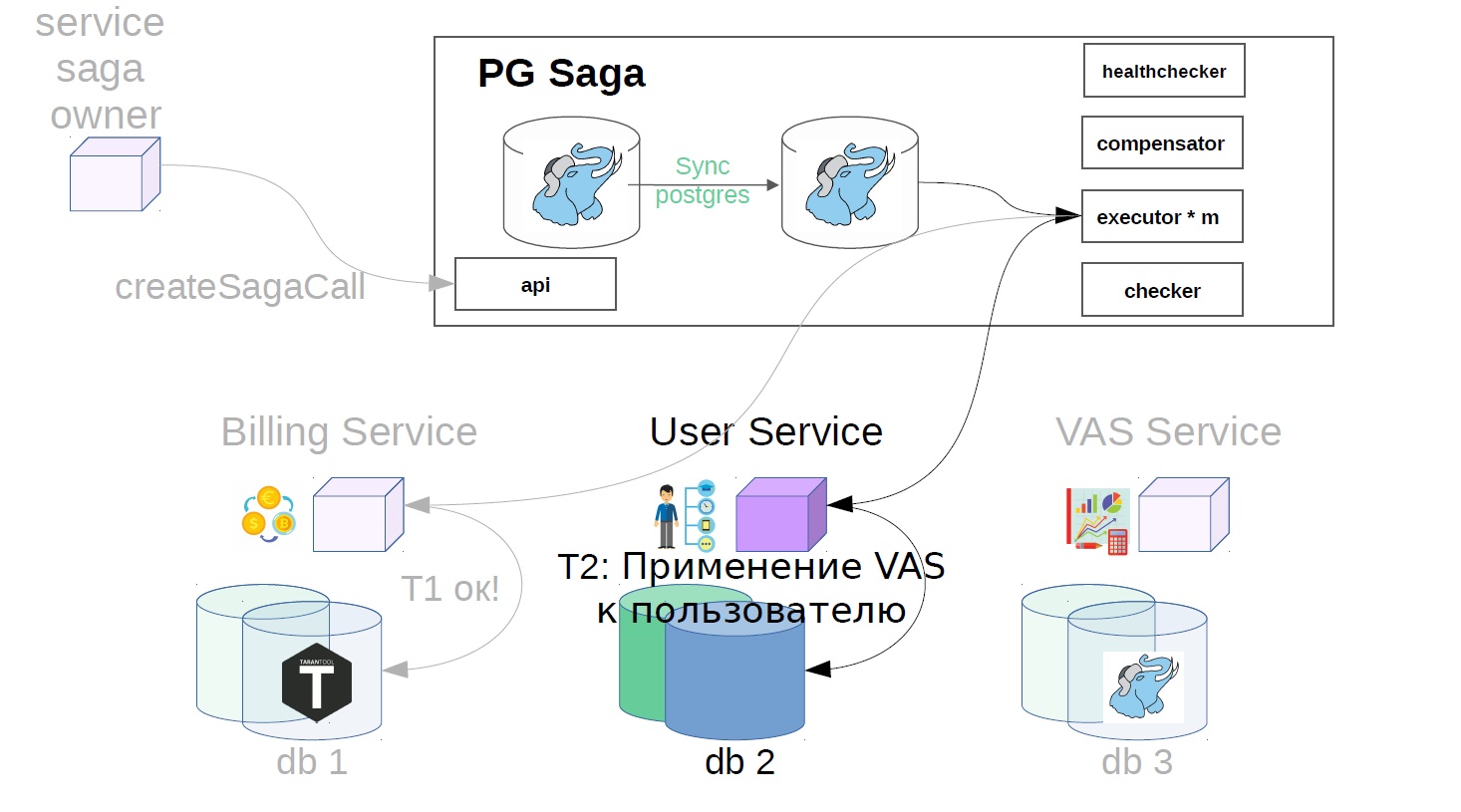
Además, ya en el servicio de hundimiento, el ejecutor recoge la llamada de saga creada previamente de la tienda y comienza a ejecutarla en pasos. El primer paso en nuestro caso es comprar una suscripción premium. En este momento, el dinero está reservado en el servicio de facturación.

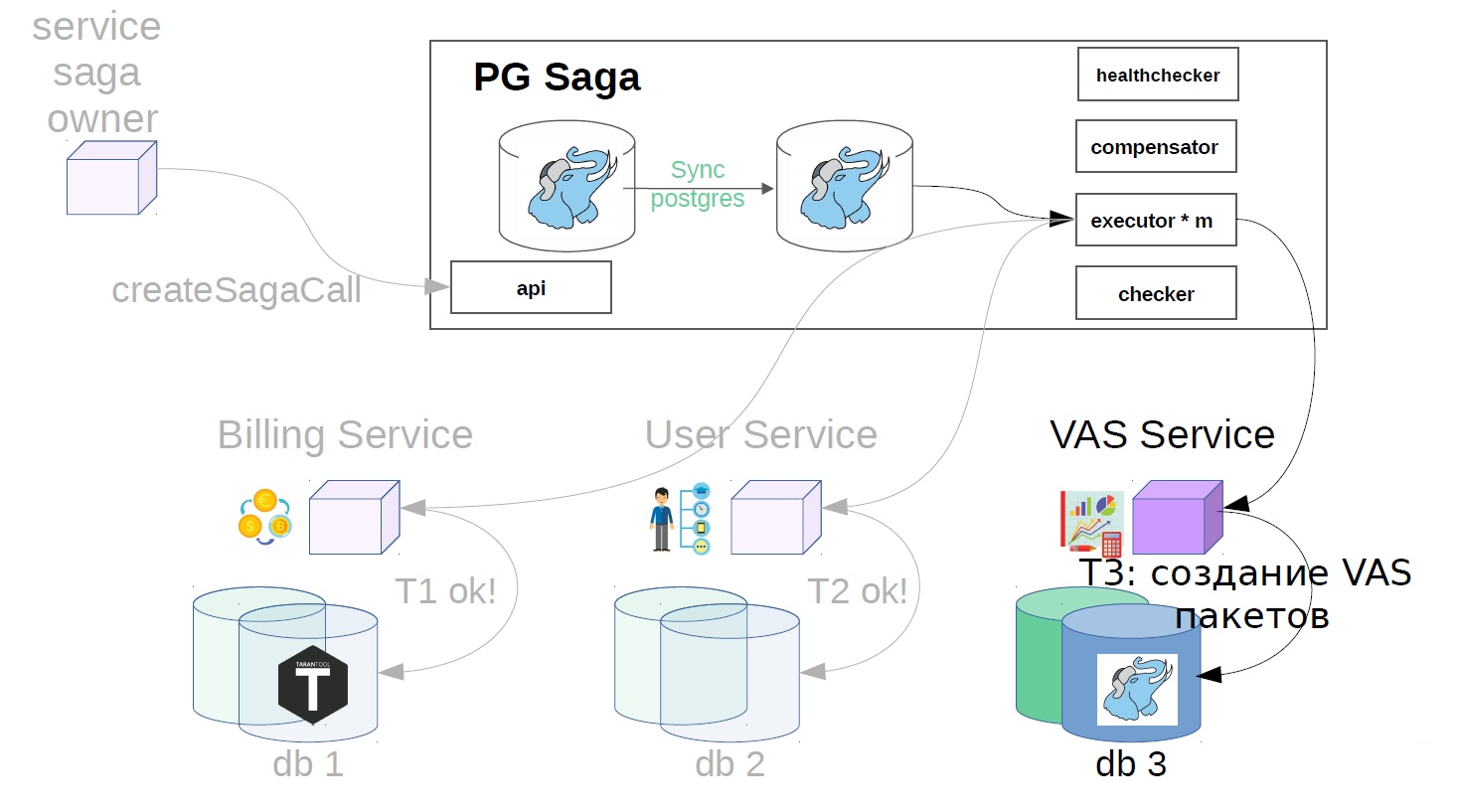
Luego, en el servicio del usuario, se aplican las operaciones VAS.
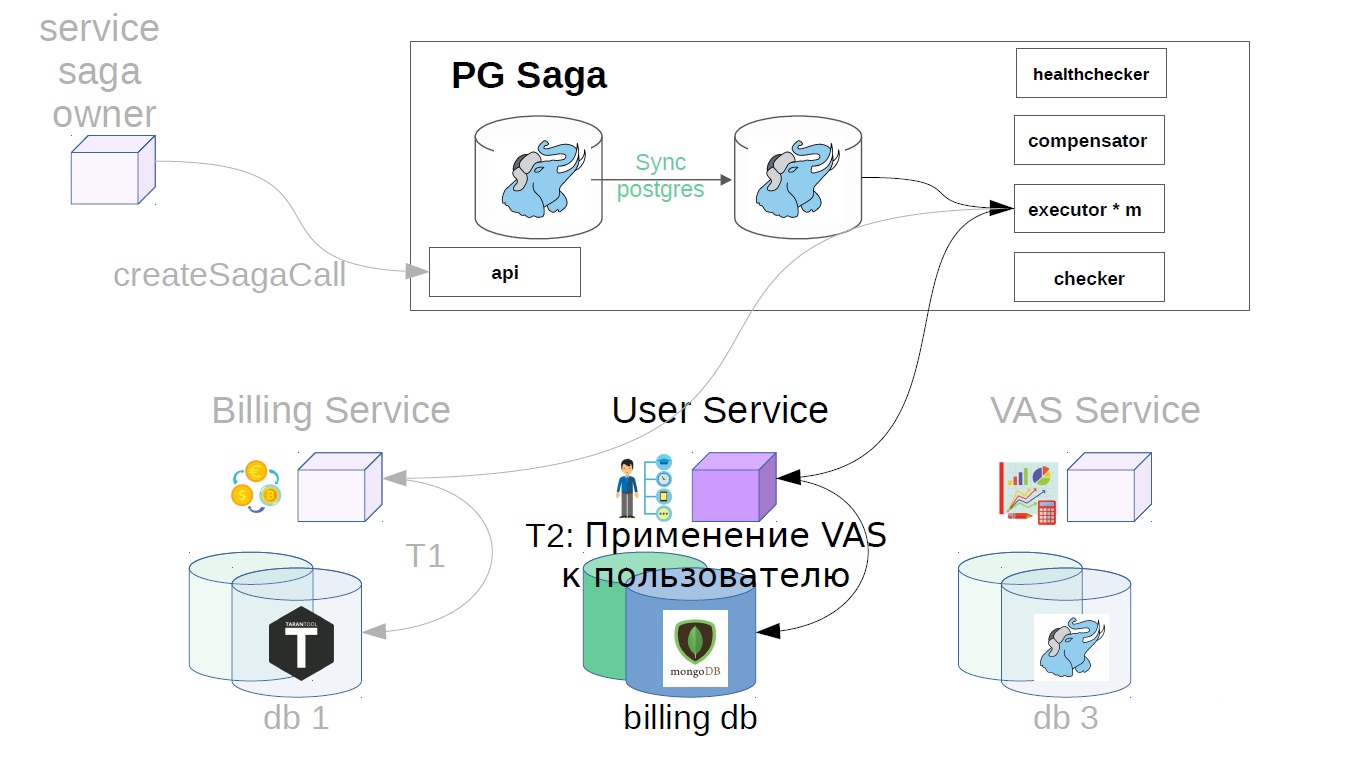
Luego, los servicios VAS ya están en su lugar y se crean sus paquetes. Otros pasos son posibles aún más, pero no son tan importantes para nosotros.
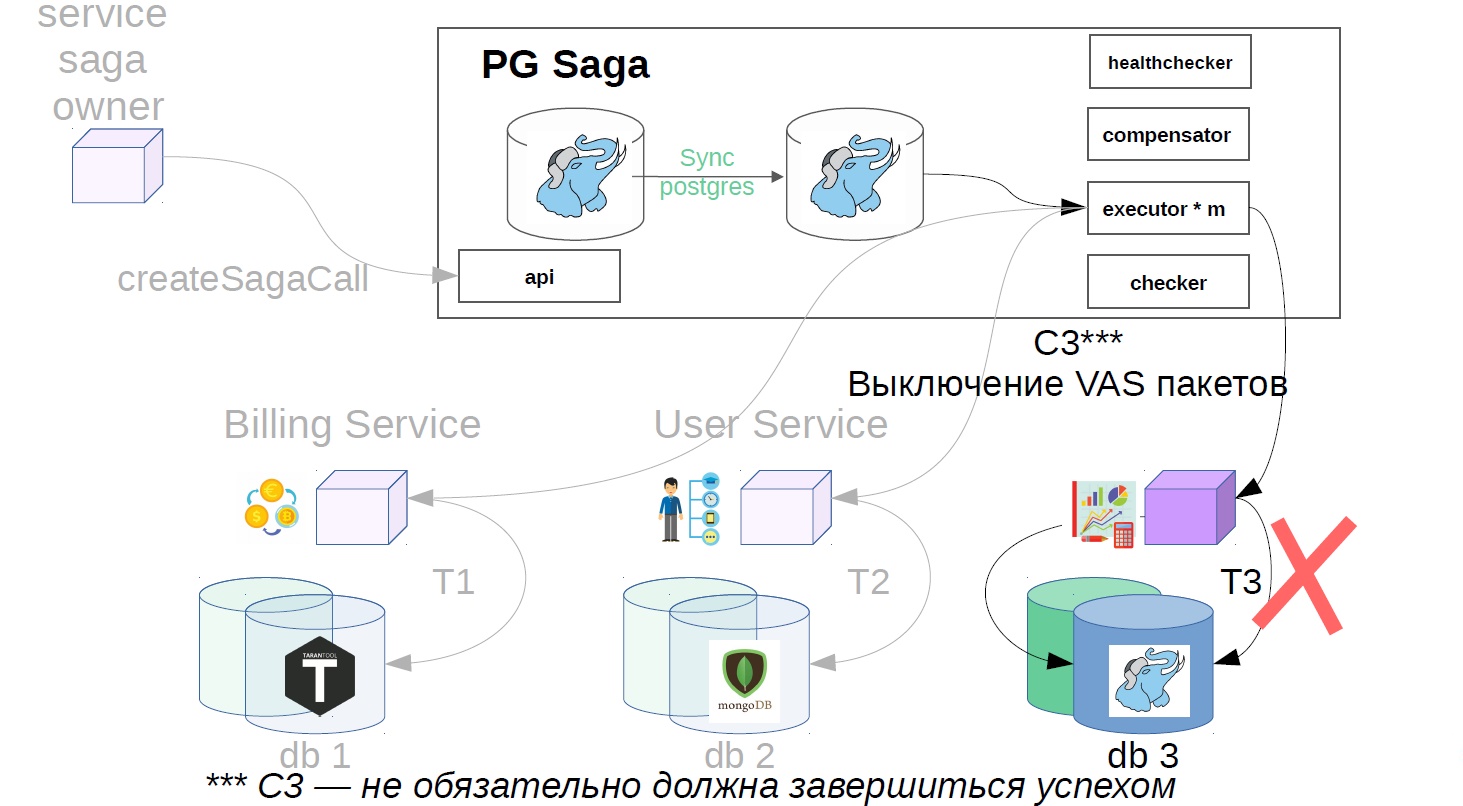
Choques
Los accidentes pueden ocurrir en cualquier servicio, pero hay trucos bien conocidos sobre cómo prepararse para ellos. En un sistema distribuido, es importante conocer estas técnicas. Por ejemplo, una de las limitaciones más importantes es que la red no siempre es confiable. Enfoques que resolverán los problemas de interacción en sistemas distribuidos:
- Intentamos nuevamente.
- Marcamos cada operación con una clave idempotente. Esto es necesario para evitar la duplicación de operaciones. Más información sobre las claves idempotentes se puede encontrar en este artículo.
- Compensamos las transacciones, una acción característica de las sagas.
Compensación de transacciones: cómo funciona
Para cada transacción positiva, debemos describir las acciones inversas: un escenario comercial del paso en caso de que algo salga mal.
En nuestra implementación, ofrecemos el siguiente escenario de compensación:
Si algún paso de la saga no tuvo éxito, e hicimos muchos intentos, entonces existe la posibilidad de que la última repetición de la operación haya sido exitosa, pero simplemente no obtuvimos una respuesta. Intentaremos compensar la transacción, aunque este paso no es necesario si el ejecutor del servicio del paso del problema realmente se ha averiado y es completamente inaccesible.
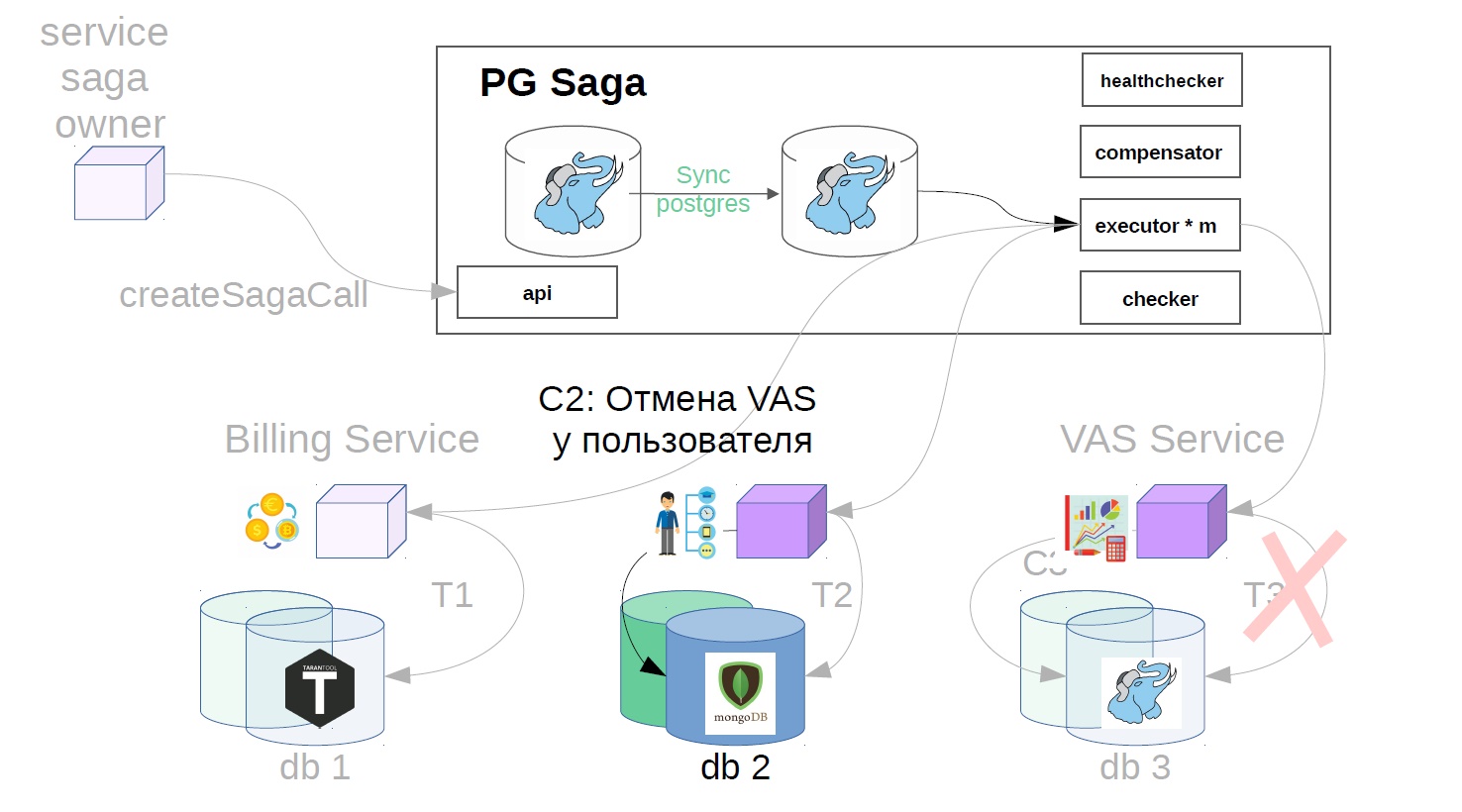
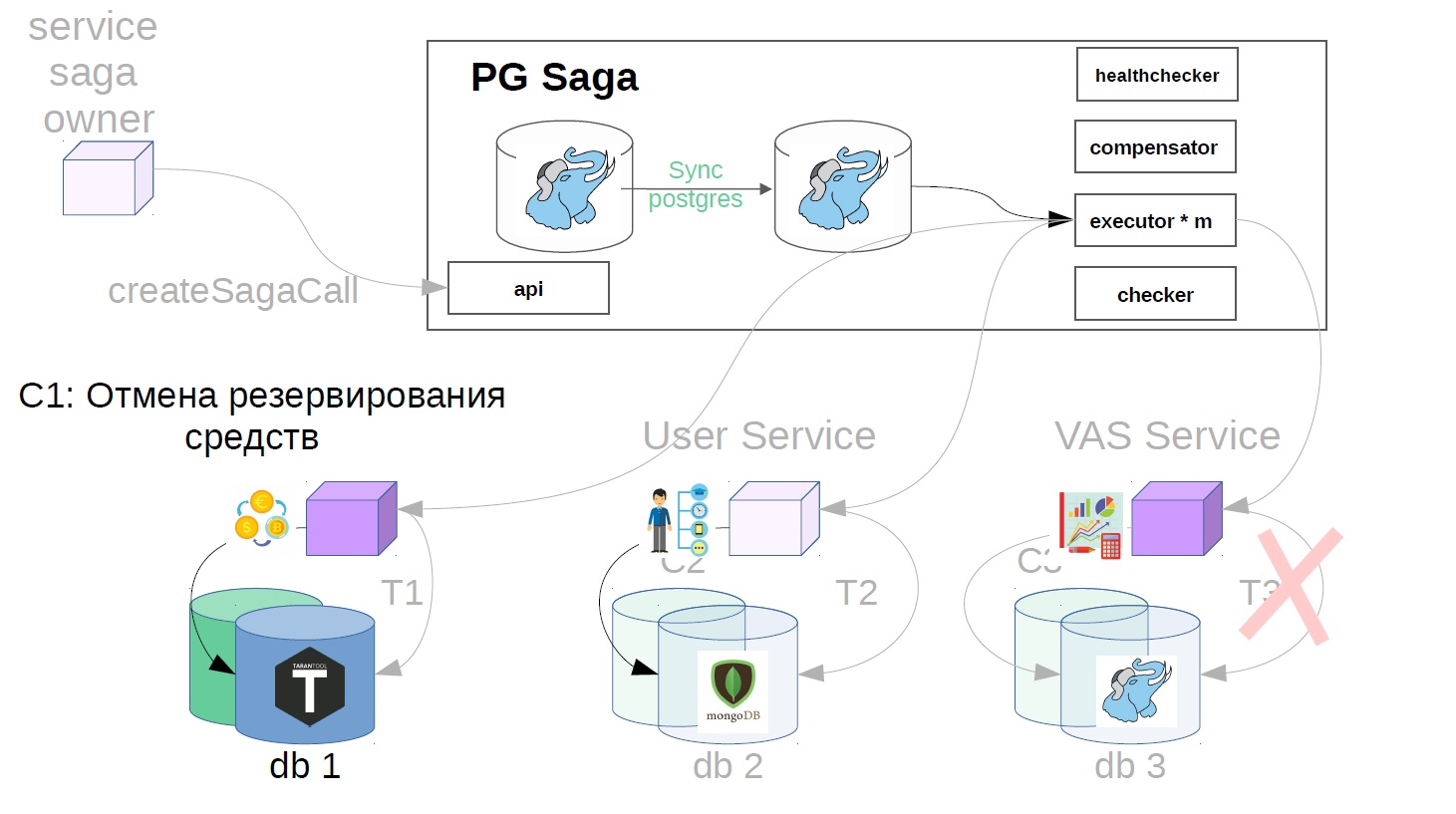
En nuestro ejemplo, se verá así:
- Apague los paquetes VAS.
- Cancele la operación del usuario.
- Cancelamos la reserva de fondos.
Qué hacer si la compensación no funciona
Obviamente, debemos actuar aproximadamente en el mismo escenario. Nuevamente, vuelva a intentar, claves idempotentes para compensar las transacciones, pero si no sale nada esta vez, por ejemplo, el servicio no está disponible, debe comunicarse con el propietario del servicio de la saga, informándole que la saga ha fallado. Además, acciones más serias: escalar el problema, por ejemplo, para una prueba manual o iniciar la automatización para resolver tales problemas.
Lo que es más importante: imagine que algún paso del servicio de saga no está disponible. Seguramente el iniciador de estas acciones volverá a intentarlo. Y al final, su servicio de saga da el primer paso, el segundo paso, y su ejecutor no está disponible, cancela el segundo paso, cancela el primer paso y también puede haber anomalías asociadas con la falta de aislamiento. En general, el servicio de saga en esta situación se dedica a un trabajo inútil, que aún genera una carga y errores.
Como hacerlo Healthchecker debe entrevistar los servicios que completan los pasos caídos y ver si funcionan. Si el servicio no está disponible, entonces hay dos formas: para compensar las sagas que están en funcionamiento, y para evitar que nuevas sagas creen nuevas instancias (llamadas), o para crear sin llevarlas a trabajar como un ejecutante, para que el servicio no acciones innecesarias
Otro escenario de accidente
Imagine que estamos haciendo la misma suscripción premium nuevamente.
- Compramos paquetes VAS y reservamos dinero.
- Aplicamos servicios al usuario.
- Creamos paquetes VAS.
Parece estar bien Pero de repente, cuando se completó la transacción, resulta que la replicación asincrónica se utiliza en el servicio de usuario y se ha producido un accidente en la base maestra. Puede haber varias razones para un retraso de la réplica: una carga específica en la réplica que ralentiza la velocidad de reproducción de la réplica o bloquea la reproducción de la réplica. Además, la fuente (maestra) se puede sobrecargar y aparece un retraso en el envío de cambios en el lado de la fuente. En general, por alguna razón, la réplica estaba retrasada y los cambios del paso completado con éxito después del accidente desaparecieron repentinamente (resultado / estado).
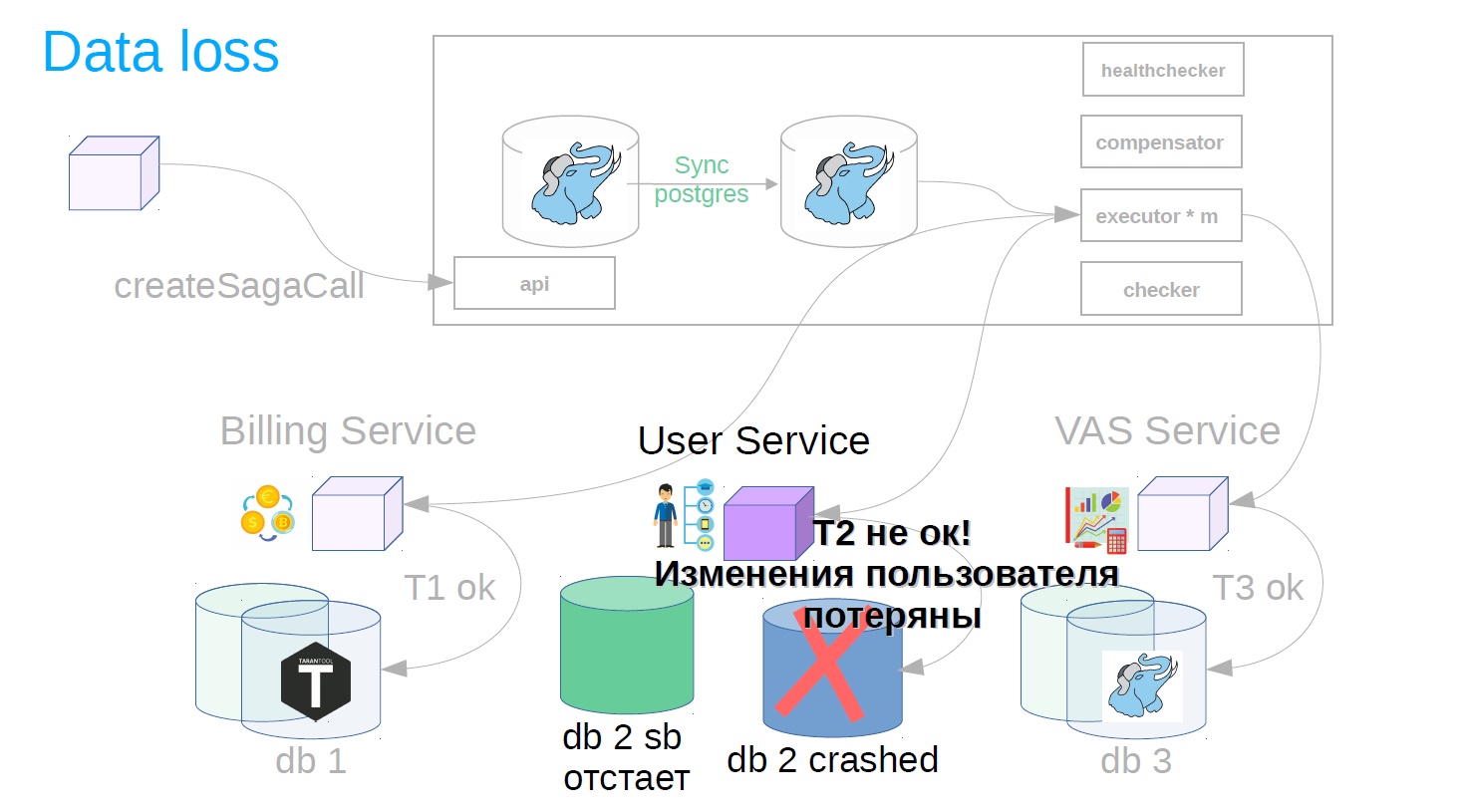
Para hacer esto, implementamos otro componente en el sistema: utilizamos el verificador. Checker pasa por todos los pasos de las sagas exitosas a través de un tiempo que se sabe que es mayor que todos los retrasos posibles (por ejemplo, después de 12 horas), y verifica si todavía se completaron con éxito. Si el paso falla repentinamente, la saga retrocede.
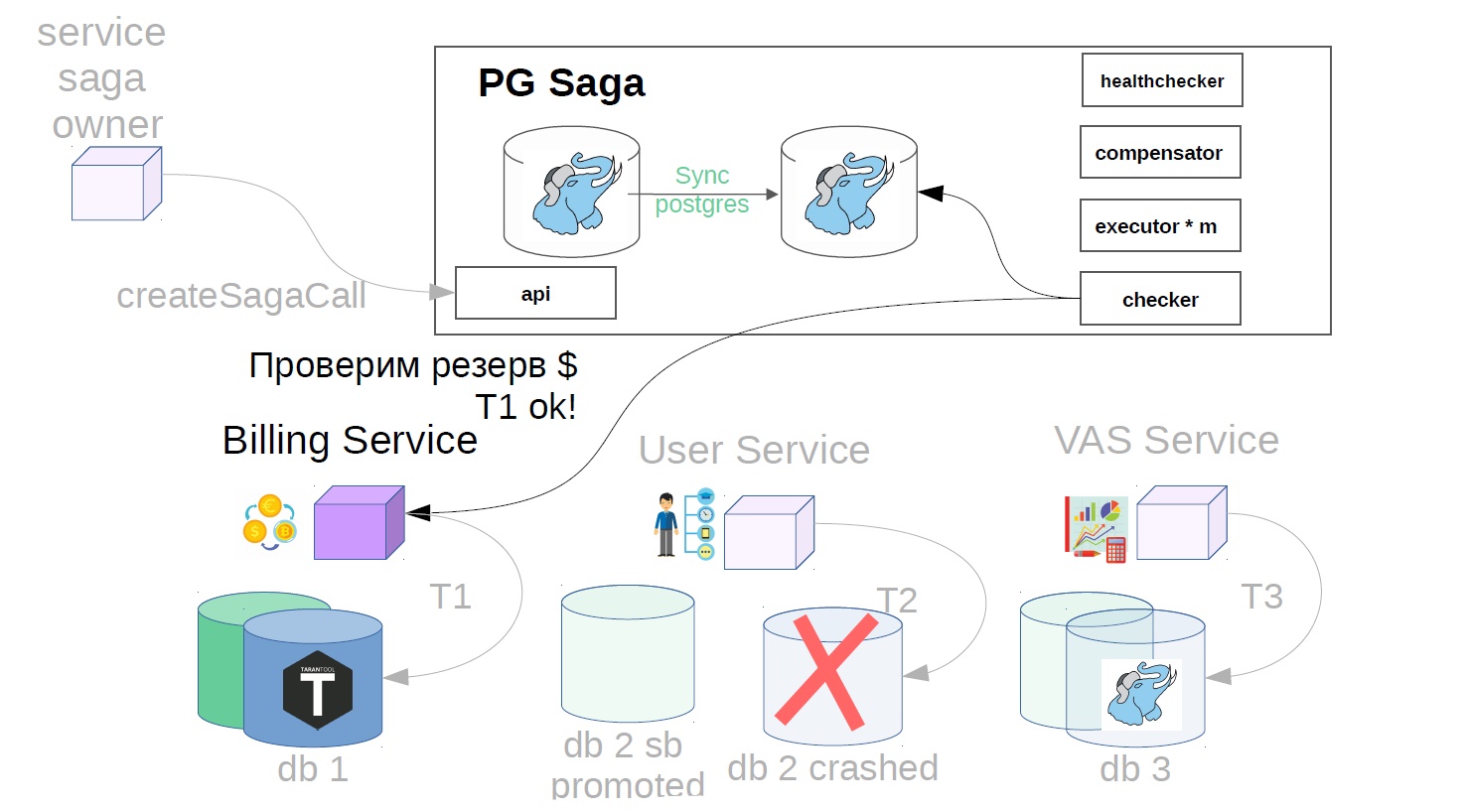
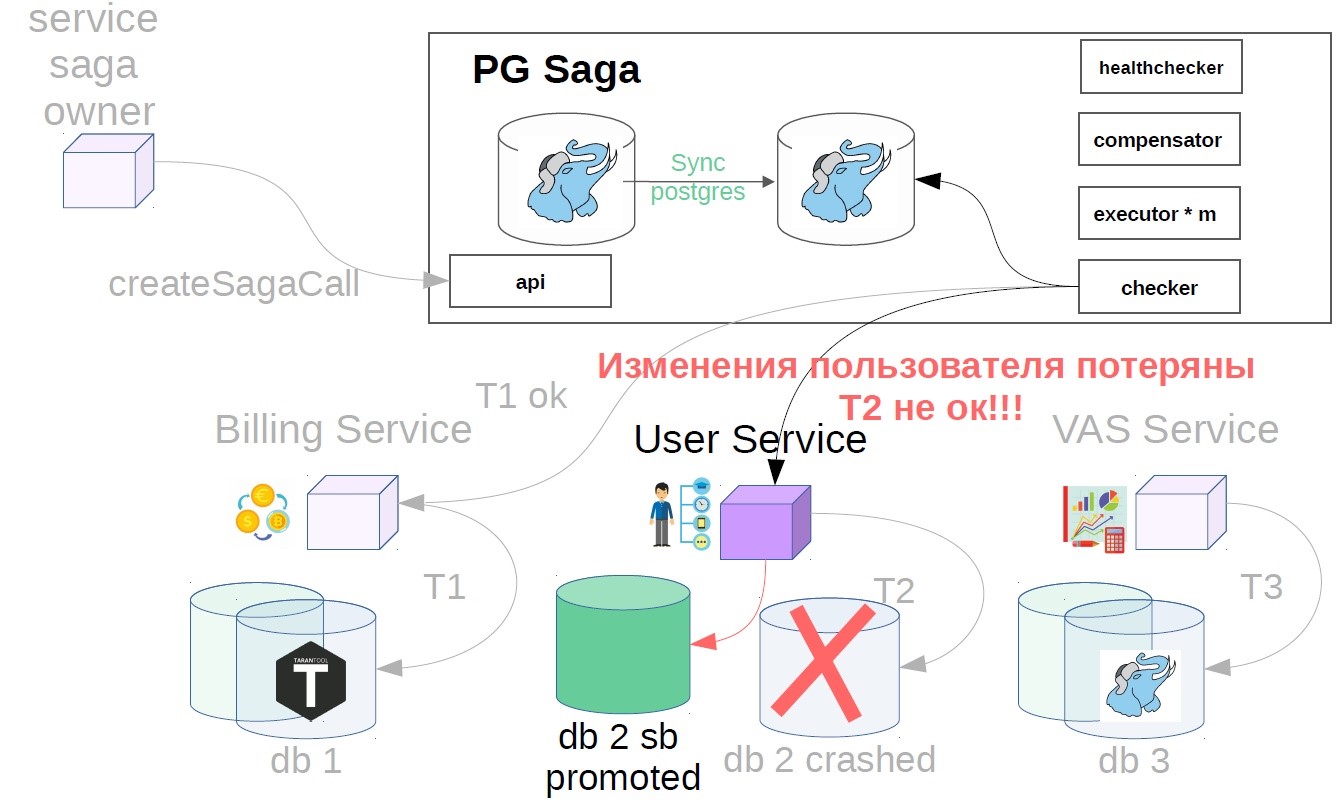
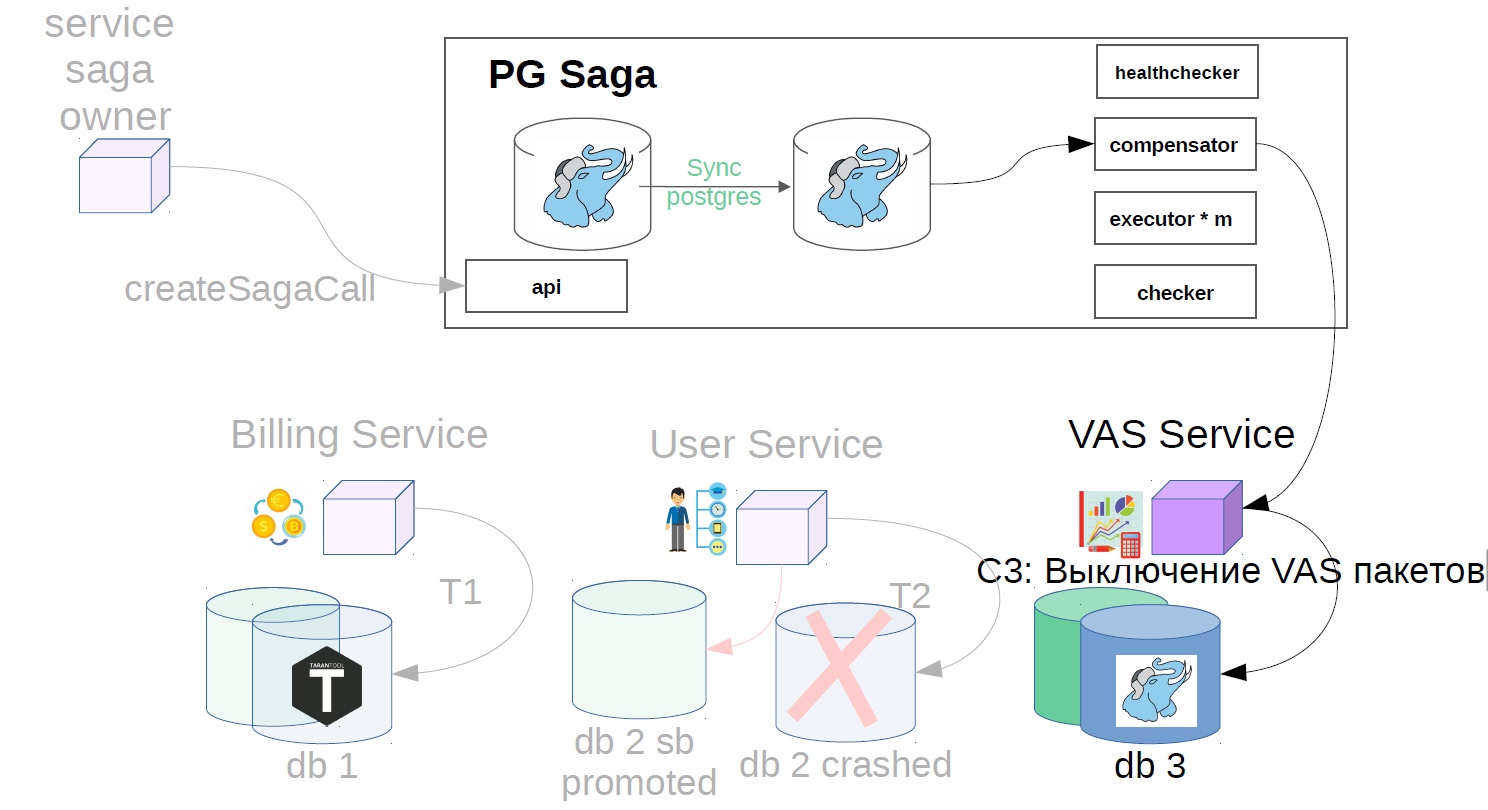
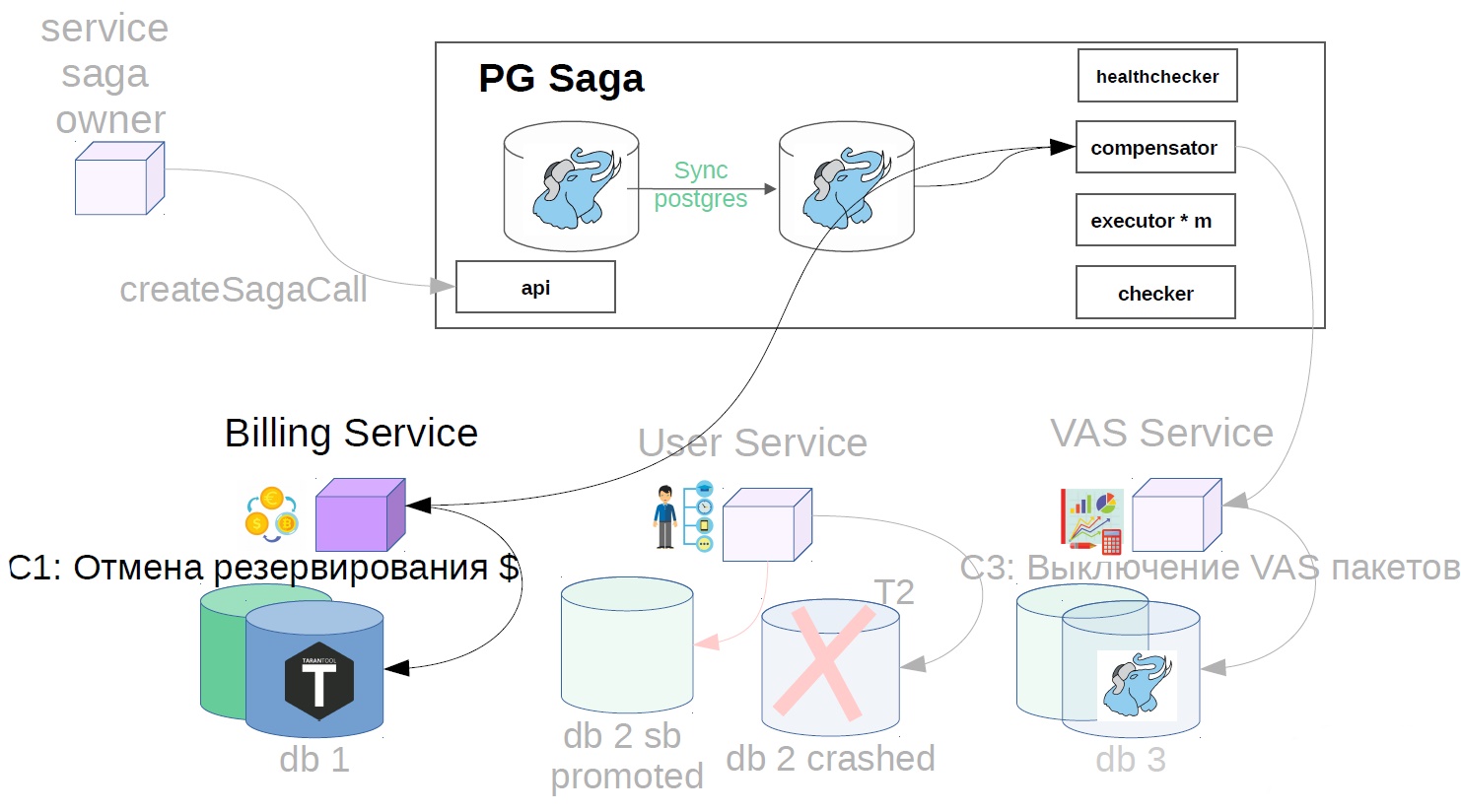
También puede haber situaciones en las que después de 12 horas ya no hay nada que cancelar: todo cambia y se mueve. En este caso, en lugar del escenario de cancelación, la solución puede ser indicarle al servicio del propietario de la saga que esta operación no se ha completado. Si la operación de cancelación no es posible, por ejemplo, debe realizar una cancelación después de cobrarle al usuario, y su saldo ya es cero, y el dinero no puede cancelarse. Tenemos tales escenarios que siempre se resuelven en la dirección del usuario. Es posible que tenga un principio diferente, esto es consistente con los representantes del producto.
Como resultado, como habrás notado, en diferentes lugares para la integración con el servicio sag necesitas implementar mucha lógica diferente. Por lo tanto, cuando los equipos de clientes quieran crear una saga, tendrán un conjunto muy grande de tareas muy obvias. En primer lugar, creamos una saga para que la duplicación no funcione, para esto estamos trabajando con una operación idempotente de crear una saga y su seguimiento. Además, en los servicios, se requiere darse cuenta de la capacidad de rastrear cada paso de cada saga, para no realizarla dos veces, por un lado, y, por otro lado, para poder responder si realmente se completó. Y todos estos mecanismos deben ser atendidos de alguna manera para que los repositorios de servicios no se desborden. Además, hay muchos idiomas en los que se pueden escribir los servicios y una gran selección de repositorios. En cada etapa, debe comprender la teoría e implementar toda esta lógica en diferentes partes. Si no lo hace, puede cometer muchos errores.
Hay muchas formas correctas, pero no hay menos situaciones en las que puedas "dispararte una extremidad". Para que las sagas funcionen correctamente, debe encapsular todos los mecanismos anteriores en las bibliotecas de clientes que los implementarán de forma transparente para sus clientes.
Un ejemplo de lógica de generación de saga que puede ocultarse en la biblioteca del cliente
Se puede hacer de manera diferente, pero propongo el siguiente enfoque.
- Obtenemos el ID de solicitud por el cual debemos crear la saga.
- Vamos al servicio de hundimiento, obtenemos su identificador único, lo guardamos en el almacenamiento local junto con el ID de solicitud del punto 1.
- Ejecute la saga con carga útil en el servicio de hundimiento. Un matiz importante: propongo operaciones locales del servicio que crea la saga, para diseñar, como el primer paso de la saga.
- Hay una cierta carrera cuando el servicio de saga puede realizar este paso (punto 3), y nuestro backend, que inicia la creación de la saga, también lo realizará. Para hacer esto, hacemos operaciones idempotentes en todas partes: una persona lo realiza, y la segunda llamada simplemente recibe "OK".
- Llamamos al primer paso (punto 4) y solo después de eso respondemos al cliente que inició esta acción.
En este ejemplo, trabajamos con la saga como una base de datos. Puede enviar una solicitud y luego la conexión puede interrumpirse, pero la acción se realizará. Este es el mismo enfoque.
Cómo comprobarlo todo
Es necesario cubrir todo el servicio de pruebas de pandeo. Lo más probable es que realice cambios, y las pruebas escritas al comienzo ayudarán a evitar sorpresas inesperadas. Además, es necesario verificar las sagas por sí mismas. Por ejemplo, cómo organizamos la prueba del servicio de hundimiento y la secuencia de hundimiento en una transacción. Hay diferentes bloques de prueba. Si hablamos del servicio de hundimiento, él sabe cómo realizar transacciones positivas y de compensación, si la compensación no funciona, informa al propietario del hundimiento del servicio. Escribimos pruebas de manera general para trabajar con una saga abstracta.
Por otro lado, las transacciones positivas y las transacciones de compensación en servicios que realizan pasos caídos son una API simple, y las pruebas de esta parte son responsabilidad del equipo propietario de este servicio.
Y luego, el equipo propietario de la saga escribe pruebas de extremo a extremo, donde verifica que toda la lógica de negocios funcione correctamente cuando se ejecuta la saga. La prueba de extremo a extremo se ejecuta en un entorno de desarrollo completo, se generan todas las instancias de servicio, incluido el servicio de hundimiento, y ya se está probando un escenario empresarial.
Total:
- escribir más pruebas unitarias;
- escribir pruebas de integración;
- escribir pruebas de punta a punta.
El siguiente paso es CDC. La arquitectura de microservicios afecta los detalles de las pruebas. En Avito, adoptamos el siguiente enfoque para probar la arquitectura de microservicios: contratos dirigidos por el consumidor. Este enfoque ayuda, en primer lugar, a resaltar los problemas que pueden identificarse en las pruebas de punta a punta, pero la prueba de punta a punta es "muy costosa".
¿Cuál es la esencia de los CDC? Hay un servicio que proporciona un contrato. Él tiene una API, este es un proveedor. Y hay otro servicio que llama a la API, es decir, utiliza el contrato: consumidor.
El servicio al consumidor escribe pruebas para el contrato del proveedor, y las pruebas que solo el contrato verificará no son pruebas funcionales. Es importante para nosotros asegurarnos de que al cambiar la API, los pasos en este contexto no se rompan. Después de que escribimos las pruebas, aparece otro elemento del agente de servicio: la información sobre las pruebas de los CDC se registra en él. Cada vez que se cambia el servicio del proveedor, se generará un entorno aislado y se ejecutarán las pruebas que escribió el consumidor. Cuál es el resultado final: el equipo que genera las sagas escribe pruebas para todos los pasos de la saga y las registra.
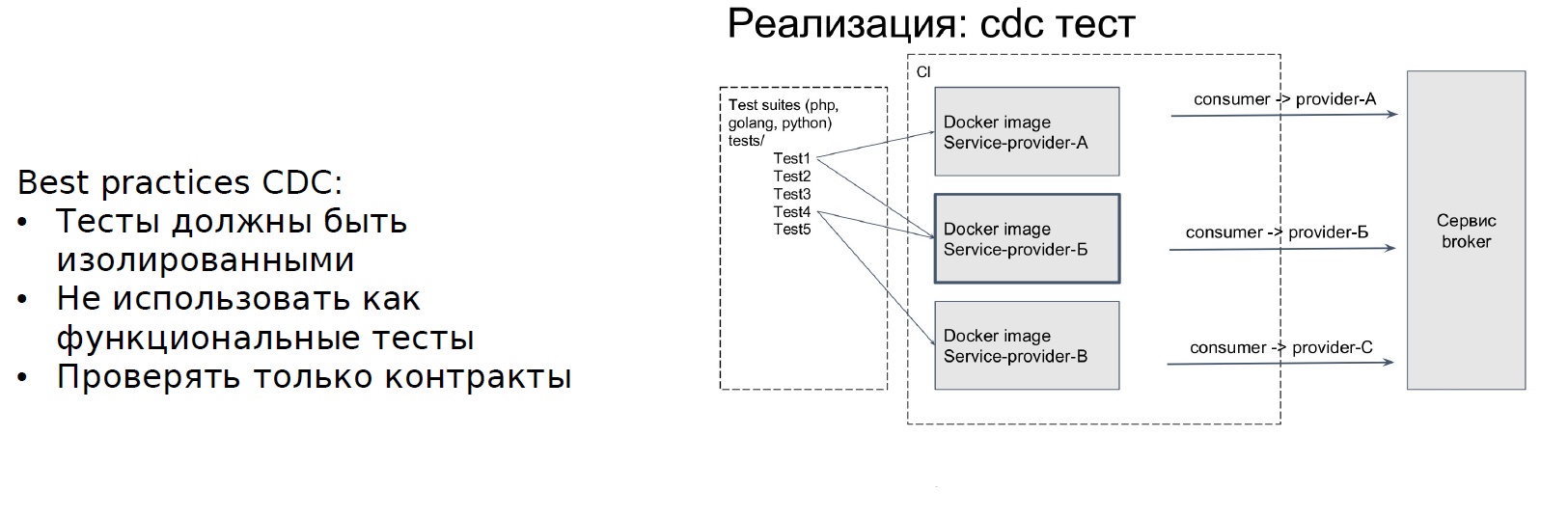
Acerca de cómo Avito implementó el enfoque CDC para probar microservicios Frol Kryuchkov habló en RIT ++. Los resúmenes se pueden encontrar en el sitio web Backend.conf : le recomiendo que se familiarice.
Tipos de sagas
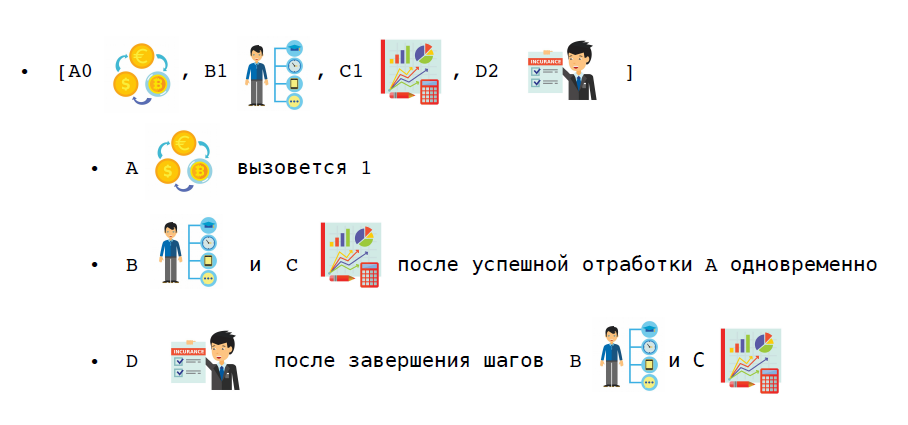
En el orden de las llamadas a funciones
a) desordenada: las funciones de la saga se llaman en cualquier orden y no esperan que se completen entre sí;
b) ordenado: las funciones de la saga se llaman en el orden dado, una tras otra, la siguiente no se llama hasta que se completa la anterior;
c) mixto: para parte de las funciones se establece el orden, pero para la parte no, pero se establece antes o después de las etapas para realizarlas.
Considere un escenario específico. En el mismo escenario de compra de una suscripción premium, el primer paso es reservar dinero. Ahora podemos hacer cambios al usuario y crear paquetes premium en paralelo, y notificaremos al usuario solo cuando estos dos pasos hayan terminado.
Al obtener el resultado de la llamada a la función
a) síncrono: el resultado de la función se conoce de inmediato;
b) asíncrono: la función devuelve "OK" inmediatamente y el resultado se devuelve más tarde, a través de una devolución de llamada a la API del servicio sag del servicio del cliente.
Quiero advertirle contra un error: es mejor no hacer pasos sincrónicos de las sagas, especialmente al implementar una saga orquestada. Si realiza pasos de caída sincrónica, el servicio de caída esperará a que se complete este paso. Esta es una carga adicional, problemas adicionales en el servicio de sagas, ya que es uno, y hay muchos participantes en sagas.
Descamación
El escalado depende del tamaño del sistema que planifique. Considere la opción con una sola instancia de almacenamiento:
- un controlador de paso de saga, procese los pasos con lotes;
- n manejadores, implementamos un "peine": tomamos medidas para el resto de la división: cuando cada ejecutor obtiene sus propios pasos.
- n controladores y saltos bloqueados: serán aún más eficientes y más flexibles.
Y solo entonces, si sabe de antemano que se encontrará con el rendimiento de un servidor en un DBMS, necesitará particionar: n instancias de bases de datos que funcionarán con su conjunto de datos. El fragmentación se puede ocultar detrás de la API del servicio de hundimiento.
Mayor flexibilidad
Además, en este patrón, al menos en teoría, el servicio al cliente (realizar el paso de la saga) puede acceder y encajar en el servicio de sag, y la participación en la saga también puede ser opcional. También puede haber otro escenario: si ya ha enviado un correo electrónico, es imposible compensar la acción; no puede devolver la carta. Pero puede enviar una nueva carta que indique que la anterior estaba equivocada, y parece ser así. Es mejor usar un escenario en el que la saga se juegue solo hacia adelante, sin compensación alguna. Si no avanza, es necesario informar al servicio del propietario de la saga sobre el problema.
¿Cuándo necesitas un candado?
Una pequeña digresión sobre las sagas en general: si puedes hacer tu lógica sin la saga, entonces hazlo. Las sagas son difíciles. Con el bloqueo, es casi lo mismo: es mejor evitar siempre los bloqueos.
Cuando vine al equipo de facturación para hablar sobre sagas, me dijeron que necesitaban un candado. Logré explicarles por qué es mejor prescindir de él y cómo hacerlo. Pero si aún necesita un candado, esto debe preverse con anticipación. Antes del servicio de hundimiento, ya implementamos bloqueos dentro del marco de un DBMS. Un ejemplo con defproc y un script para bloquear anuncios asincrónicamente y bloquear una cuenta sincrónicamente, cuando primero hacemos parte de la operación sincrónicamente y configuramos el bloqueo, y luego de forma asíncrona en segundo plano terminamos el resto del trabajo con lotes.
Como hacerlo , , , , , - , . . . : , , .
-, , . , , . , , . . — , , .
ACID —
, , . . — durability. . . , . - , - - ,
— - , - , , - , . , - , - .
— .
:
- , , , , .
- , . , , , , , .
- .
- payload . eventual consistency — , , , . , , , -.
Monitoreo
. , . . checker. . , .
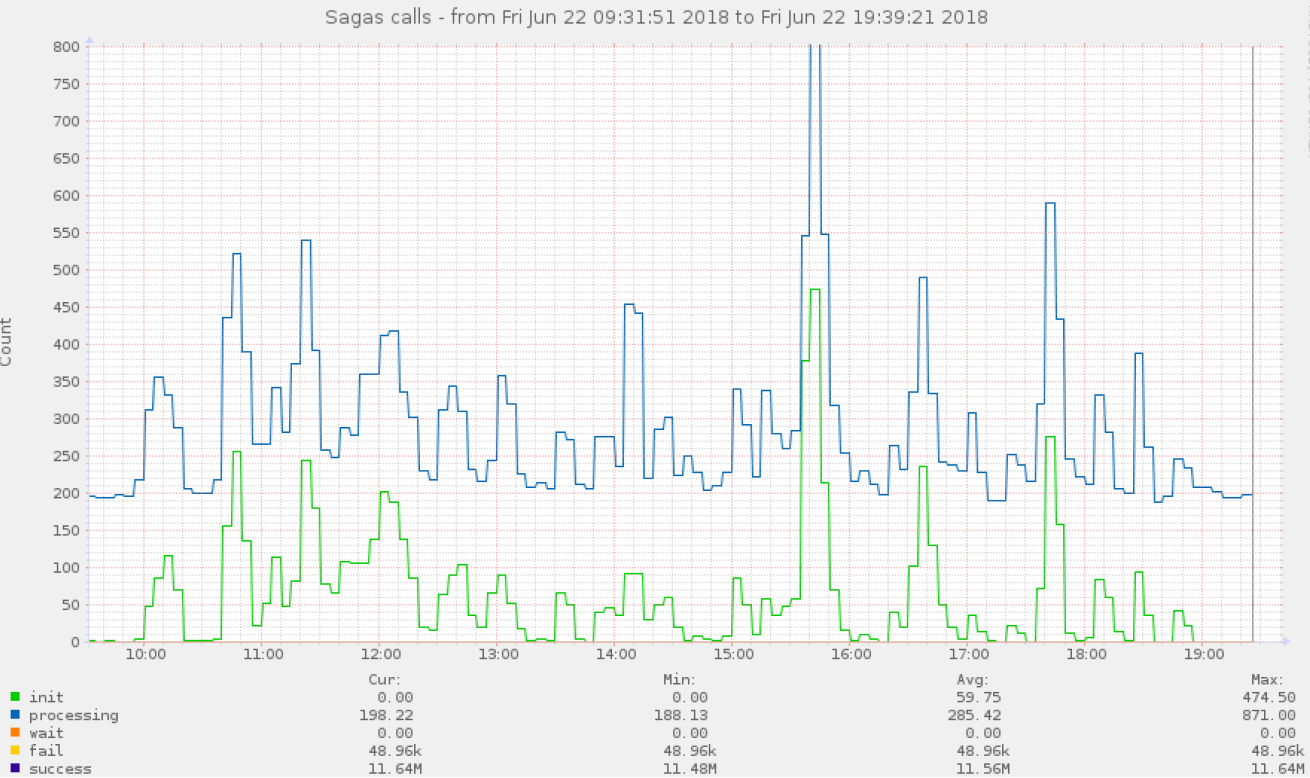
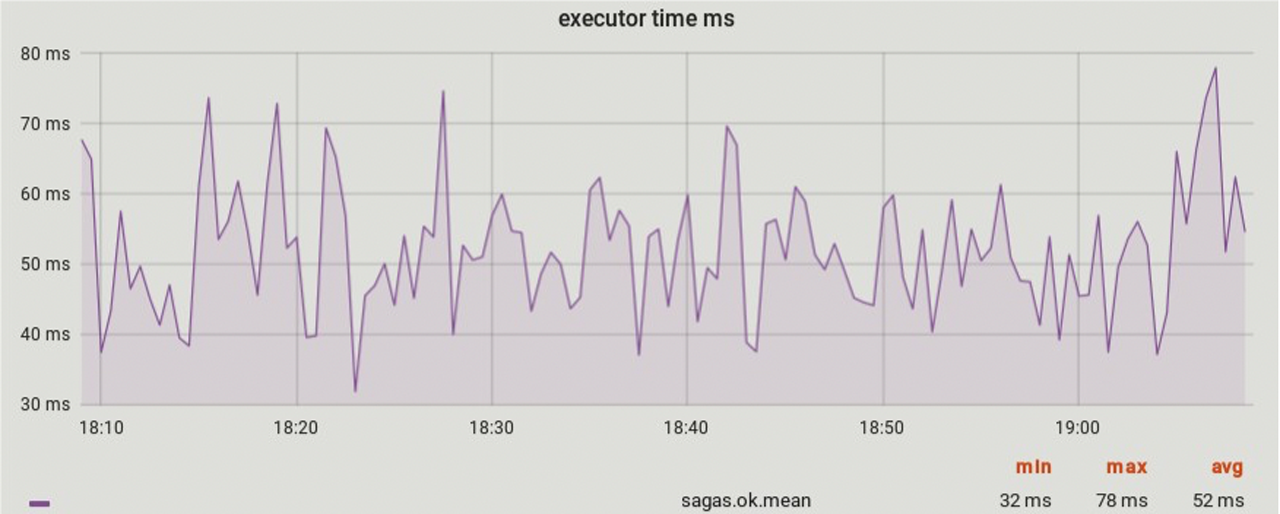
(50%, 75%, 95%, 99%), , - .
, — , . . , - . , — .
. , - ( ) . healthchecker endpoint' info (keep-alive) .
. -. -, - , - . , , , end-to-end. - . , , — .
. .
:
, healthchecker, - , . , . .
, . , , . . choreography — - . , choreography- , . choreography , . , . , , , .
. , , . , + .
API
, - - ( API ), , API. API . — . API , , 100% .
, , , , . — , , . .
, , , . ( ) .
, , , , .
. , , .
saga call ID
. API , .
—
- legacy . , ( «» ). « »? - , , , , - , . , , , . , « », , -. . — . , .
Estoy a favor de un enfoque pragmático para el desarrollo, por lo que para escribir un servicio de saga, una inversión en la escritura de dicho servicio debería estar justificada. Además, lo más probable es que muchas personas necesiten solo una parte de lo que describí, y esta parte resolverá las necesidades actuales. Lo principal es comprender de antemano qué se necesita exactamente de todo esto. Y cuantos recursos tienes.
Si tiene preguntas o está interesado en aprender más sobre las sagas, escriba los comentarios. Estaré encantado de responder.