Coautor del artículo: Mike Cheng
Google Cloud Platform ahora tiene imágenes de máquinas virtuales en su cartera, diseñadas específicamente para aquellos involucrados en Deep Learning. Hoy hablaremos sobre lo que representan estas imágenes, las ventajas que brindan a los desarrolladores e investigadores y, por supuesto, cómo crear una máquina virtual basada en ellas.
Digresión de letras: al momento de escribir, el producto todavía estaba en Beta, respectivamente, no se aplican SLAs.
¿Qué tipo de bestia es esta, imágenes de máquinas virtuales para Deep Learning de Google?
Las imágenes de máquinas virtuales para Deep Learning de Google son imágenes de Debian 9 que, desde el primer momento, tienen todo lo que Deep Learning necesita. Actualmente, hay versiones de imágenes con TensorFlow, PyTorch e imágenes de uso general. Cada versión existe en la edición solo para instancias de CPU y GPU. Para comprender mejor qué imagen necesitas, dibujé una pequeña hoja de trucos:
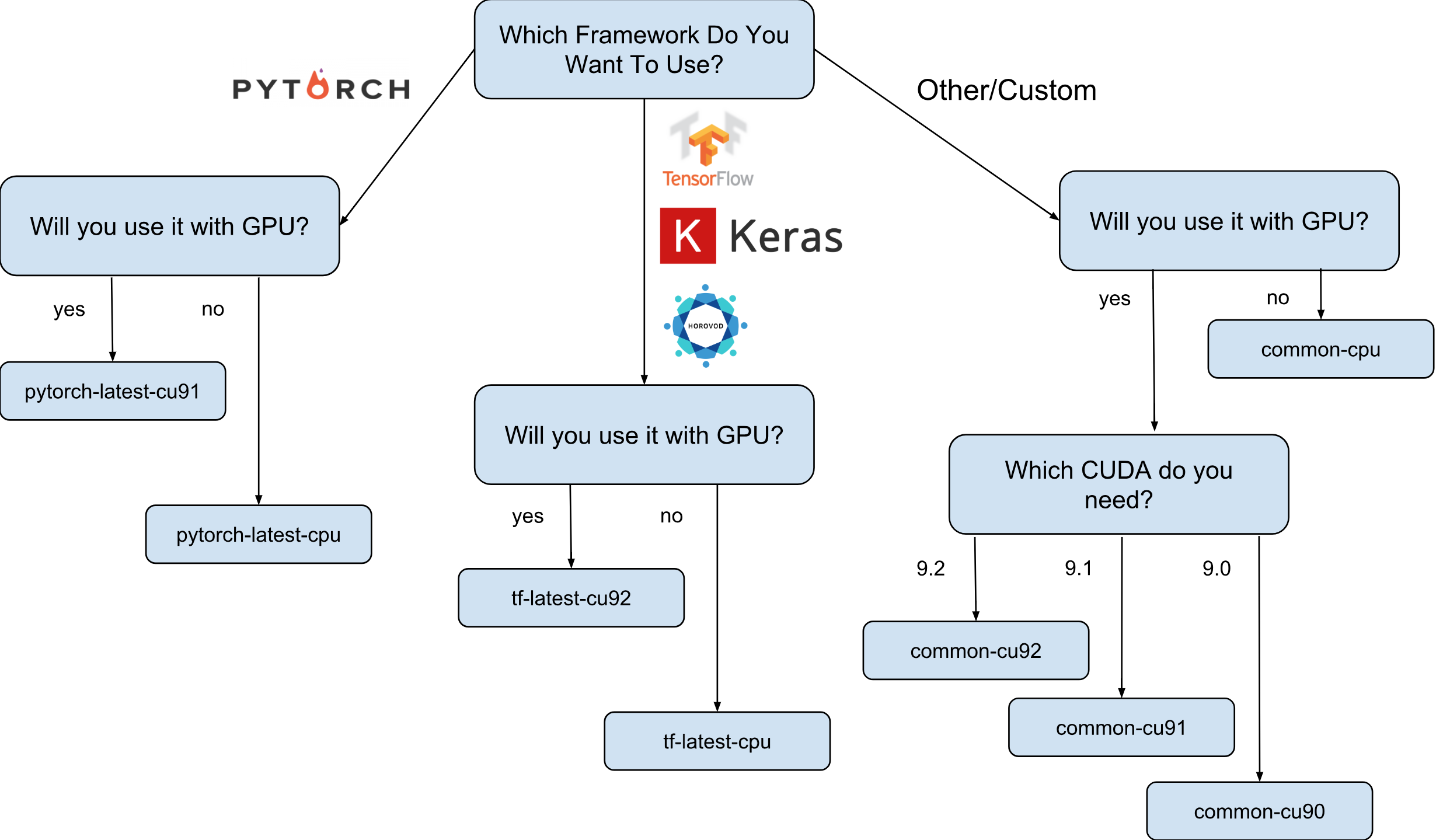
Como se muestra en la hoja de trucos, hay 8 familias de imágenes diferentes. Como ya se mencionó, todos están basados en Debian 9.
¿Qué es exactamente preinstalado en las imágenes?
Todas las imágenes tienen Python 2.7 / 3.5 con los siguientes paquetes preinstalados:
- numpy
- sklearn
- escoria
- pandas
- nltk
- almohada
- Entornos Jupyter (laboratorio y cuaderno)
- y mucho mas
Pila configurada desde Nvidia (solo en imágenes de GPU):
- CUDA 9. *
- CuDNN 7.1
- NCCL 2. *
- último controlador de nvidia
La lista se actualiza constantemente, así que estad atentos en la página oficial .
¿Y por qué son realmente necesarias estas imágenes?
Digamos que necesita entrenar un modelo de red neuronal usando Keras (con TensorFlow). La velocidad de aprendizaje es importante para usted y decide usar la GPU. Para usar la GPU, deberá instalar y configurar la pila Nvidia (controlador Nvidia + CUDA + CuDNN + NCCL). Este proceso no solo es bastante complicado en sí mismo (especialmente si no es un ingeniero de sistemas, sino un investigador), es aún más complicado por el hecho de que debe tener en cuenta las dependencias binarias de su versión de la biblioteca TensorFlow. Por ejemplo, la distribución oficial TensorFlow 1.9 se compila con CUDA 9.0 y no funcionará si tiene una pila con CUDA 9.1 o 9.2 instalado. Configurar esta pila puede ser un proceso "divertido", creo que nadie puede discutir esto (especialmente aquellos que lo hicieron).
Ahora supongamos que después de varias noches de insomnio todo está configurado y funcionando. Pregunta: esta configuración, que pudo configurar, ¿es la más óptima para su hardware? Por ejemplo, ¿es cierto que el CUDA 9.0 instalado y el paquete binario oficial TensorFlow 1.9 muestran la velocidad más rápida en una instancia con un procesador SkyLake y una GPU Volta V100?
Es casi imposible responder sin probar con otras versiones de CUDA. Para responder con seguridad, necesita reconstruir manualmente TensorFlow en diferentes configuraciones y ejecutar sus pruebas. Todo esto debe llevarse a cabo en ese hardware costoso, en el que está previsto entrenar el modelo posteriormente. Bueno, y lo último, todas estas medidas se pueden tirar tan pronto como se lance la nueva versión de TensorFlow o la pila de Nvidia. Se puede afirmar con seguridad que la mayoría de los investigadores simplemente no harán esto y simplemente usarán el conjunto estándar TensorFlow, que no tiene una velocidad óptima.
Aquí es donde aparecen las imágenes de Deep Learning de Google en la escena. Por ejemplo, las imágenes con TensorFlow tienen su propio ensamblaje TensorFlow, que está optimizado para el hardware que está disponible en Google Cloud Engine. Se prueban con una configuración diferente de la pila de Nvidia y se basan en la que mostró el mayor rendimiento (spoiler: esto no siempre es el más nuevo). Bueno y lo más importante: ¡casi todo lo que necesita para la investigación ya está preinstalado!
¿Cómo puedo crear una instancia basada en una de las imágenes?
Hay dos opciones para crear una nueva instancia basada en estas imágenes:
- Uso de la interfaz de usuario web de Google Cloud Marketplace
- Usando gcloud
Como soy un gran admirador de las utilidades de terminal y CLI, en este artículo hablaré sobre esta opción. Además, si le gusta la interfaz de usuario, hay una documentación bastante buena que describe cómo crear una instancia utilizando la interfaz de usuario web .
Antes de continuar, instale (si aún no lo ha hecho) la herramienta gcloud. Opcionalmente, puede usar Google Cloud Shell , pero tenga en cuenta que la función WebPreview en Google Cloud Shell no es compatible actualmente y, por lo tanto, no puede usar Jupyter Lab o Notebook allí.
El siguiente paso es seleccionar una familia de imágenes. Me permitiré una vez más traer la hoja de trucos con la elección de una familia de imágenes.
Por ejemplo, suponemos que su elección recayó en tf-latest-cu92, y la usaremos más adelante en el texto.
Espere, pero ¿qué pasa si necesito una versión específica de TensorFlow, en lugar de la "última"?
Supongamos que tenemos un proyecto que requiere TensorFlow 1.8, pero al mismo tiempo 1.9 ya se ha lanzado y las imágenes de la familia tf-latest ya tienen 1.9. Para este caso, tenemos una familia de imágenes, que siempre tiene una versión específica del marco (en nuestro caso, tf-1-8-cpu y tf-1-8-cu92). Estas familias de imágenes se actualizarán, pero la versión de TensorFlow no cambiará en ellas.
Dado que esta es solo una versión Beta, ahora solo admitimos TensorFlow 1.8 / 1.9 y PyTorch 0.4. Planeamos admitir versiones futuras, pero en la etapa actual no podemos responder claramente a la pregunta de cuánto tiempo se admitirán las versiones antiguas.
¿Qué sucede si quiero crear un clúster o usar la misma imagen?
De hecho, puede haber muchos casos en los que es necesario reutilizar la misma imagen una y otra vez (en lugar de una familia de imágenes). Estrictamente hablando, usar imágenes directamente es casi siempre la opción preferida. Bueno, por ejemplo, si ejecuta un clúster con varias instancias, no se recomienda en ese caso especificar familias de imágenes directamente en sus scripts, ya que si la familia se actualiza en el momento en que se ejecuta el script, es probable que se creen diferentes instancias de clúster a partir de diferentes imágenes (¡y puede tener diferentes versiones de bibliotecas!). En tales casos, es preferible obtener primero un nombre específico para la imagen de su familia, y solo luego usar un nombre específico.
Si está interesado en este tema, puede consultar mi artículo "Cómo usar las familias de imágenes correctamente".
Puede ver el nombre de la última imagen de la familia con un comando simple:
gcloud compute images describe-from-family tf-latest-cu92 \ --project deeplearning-platform-release
Supongamos que el nombre de una imagen en particular es tf-latest-cu92-1529452792, ya puede usarlo en cualquier lugar:
¡Es hora de crear nuestra primera instancia!
Para crear una instancia de una familia de imágenes, simplemente ejecute un comando simple:
export IMAGE_FAMILY="tf-latest-cu92"
Si usa el nombre de la imagen y no la familia de la imagen, debe reemplazar “- image-family = $ IMAGE_FAMILY” con “- image = $ IMAGE-NAME”.
Si está utilizando una instancia con una GPU, debe prestar atención a las siguientes circunstancias:
Necesita seleccionar la zona correcta . Si crea una instancia con una GPU específica, debe asegurarse de que este tipo de GPU esté disponible en la zona en la que crea la instancia. Aquí puede encontrar la correspondencia de zonas con los tipos de GPU. Como puede ver, us-west1-b es la única zona en la que hay los 3 tipos posibles de GPU (K80 / P100 / V100).
Asegúrese de tener suficientes cuotas para crear una instancia con la GPU . Incluso si ha elegido la región correcta, esto no significa que tenga una cuota para crear una instancia con una GPU en esta región. De forma predeterminada, la cuota de GPU se establece en cero en todas las regiones, por lo que todos los intentos de crear una instancia con la GPU fallarán. Una buena explicación de cómo aumentar la cuota se puede encontrar aquí .
Asegúrese de que haya suficientes GPU en la zona para satisfacer su solicitud . Incluso si ha elegido la región correcta y tiene una cuota para GPU en esta región, esto no significa que haya una GPU de interés para usted en esta zona. Desafortunadamente, no sé cómo más puede verificar la disponibilidad de la GPU, excepto como un intento de crear una instancia y ver qué sucede =)
Elija el número correcto de GPU (según el tipo de GPU) . El hecho es que la bandera de "acelerador" en nuestro equipo es responsable del tipo y la cantidad de GPU que estarán disponibles para la instancia: es decir “- accelerator = 'type = nvidia-tesla-v100, count = 8'” creará una instancia con ocho GPU Nvidia Tesla V100 (Volta) disponibles. Cada tipo de GPU tiene una lista válida de valores de conteo. Aquí está la lista para cada tipo de GPU:
- nvidia-tesla-k80, puede tener recuentos: 1, 2, 4, 8
- nvidia-tesla-p100, puede tener recuentos: 1, 2, 4
- nvidia-tesla-v100, puede tener recuentos: 1, 8
Otorgue permiso a Google Cloud para instalar el controlador de Nvidia en su nombre al momento de iniciar la instancia . El conductor de Nvidia es imprescindible. Por razones más allá del alcance de este artículo, las imágenes no tienen un controlador Nvidia preinstalado. Sin embargo, puede otorgar a Google Cloud el derecho de instalarlo en su nombre la primera vez que inicie la instancia. Esto se hace agregando el indicador "- metadata = 'install-nvidia-driver = True'". Si no especifica este indicador, la primera vez que se conecte a través de SSH, se le solicitará que instale el controlador.
Desafortunadamente, el proceso de instalación del controlador lleva tiempo en el primer arranque, ya que necesita descargar e instalar este controlador (y esto también implica reiniciar la instancia). En total, esto no debería tomar más de 5 minutos. Hablaremos un poco más adelante sobre cómo puede reducir el primer tiempo de arranque.
Conéctese a una instancia a través de SSH
Esto es más simple que un nabo y se puede hacer con un comando:
gcloud compute ssh $INSTANCE_NAME
gcloud creará un par de claves y las cargará automáticamente a la instancia recién creada, así como también creará su usuario en ella. Si desea simplificar aún más este proceso, puede usar una función que también lo simplifique:
function gssh() { gcloud compute ssh $@ } gssh $INSTANCE_NAME
Por cierto, puedes encontrar todas mis funciones de gcloud bash aquí . Bueno, antes de llegar a la pregunta de qué tan rápido son estas imágenes, o qué se puede hacer con ellas, déjenme aclarar el problema con la velocidad de lanzamiento de las instancias.
¿Cómo puedo reducir el tiempo del primer inicio?
Técnicamente, el momento del primer lanzamiento no es nada. Pero puedes:
- cree la instancia más barata n1-standard-1 con un K80;
- espere hasta que se complete la primera descarga;
- verifique que el controlador Nvidia esté instalado (esto se puede hacer ejecutando "nvidia-smi");
- Detener la instancia
- Crea tu propia imagen desde una instancia detenida
- Beneficio: todas las instancias creadas a partir de su imagen derivada tendrán un legendario tiempo de lanzamiento de 15 segundos.
Entonces, de esta lista ya sabemos cómo crear una nueva instancia y conectarnos a ella, también sabemos cómo verificar la operatividad de los controladores. Solo queda hablar sobre cómo detener la instancia y crear una imagen a partir de ella.
Para detener la instancia, ejecute el siguiente comando:
function ginstance_stop() { gcloud compute instances stop - quiet $@ } ginstance_stop $INSTANCE_NAME
Y aquí está el comando para crear la imagen:
export IMAGE_NAME="my-awesome-image" export IMAGE_FAMILY="family1" gcloud compute images create $IMAGE_NAME \ --source-disk $INSTANCE_NAME \ --source-disk-zone $ZONE \ --family $IMAGE_FAMILY
Felicitaciones, ahora tiene su propia imagen con los controladores Nvidia instalados.
¿Qué tal Jupyter Lab?
Una vez que su instancia se esté ejecutando, el siguiente paso lógico sería iniciar Jupyter Lab para ponerse manos a la obra directamente :) Con nuevas imágenes, es muy simple. Jupyter Lab ya se ha estado ejecutando desde que se lanzó la instancia. Todo lo que necesita hacer es conectarse a la instancia y reenviar el puerto en el que Jupyter Lab está escuchando. Y este es el puerto 8080. Esto se hace con el siguiente comando:
gssh $INSTANCE_NAME -- -L 8080:localhost:8080
Todo está listo, ahora simplemente puede abrir su navegador favorito e ir a http: // localhost: 8080
¿Cuánto más rápido es TensorFlow de las imágenes?
Una pregunta muy importante, ya que la velocidad de entrenamiento del modelo es dinero real. Sin embargo, la respuesta completa a esta pregunta será la más larga que ya está escrita en este artículo. Entonces tienes que esperar al próximo artículo :)
Mientras tanto, te mimaré con algunos números obtenidos en mi pequeño experimento personal. Entonces, la velocidad de entrenamiento en ImageNet fue de 6100 imágenes por segundo (red ResNet-50). Mi presupuesto personal no me permitió terminar de entrenar el modelo por completo, sin embargo, a esta velocidad, supongo que es posible lograr un 75% de precisión en 5 horas con un poco.
¿Dónde conseguir ayuda?
Si necesita información sobre nuevas imágenes, puede:
- haga una pregunta sobre stackoverflow, con la etiqueta google-dl-platform;
- escribir al grupo público de Google ;
- puede escribirme por correo o en twitter .
Sus comentarios son muy importantes, si tiene algo que decir sobre las imágenes, no dude en ponerse en contacto conmigo de cualquier manera conveniente para usted o dejar un comentario en este artículo.