Nota perev. : Este artículo fue publicado en el blog oficial de Kubernetes y fue escrito por dos empleados de Intel que están directamente involucrados en el desarrollo de CPU Manager, una nueva característica en Kubernetes sobre la que escribimos en la revisión de la versión 1.8 . En este momento (es decir, para K8s 1.11), esta característica tiene estado beta y más información sobre su propósito más adelante en la nota.La publicación habla sobre el
Administrador de CPU , una función beta en Kubernetes. CPU Manager le permite distribuir mejor las cargas de trabajo en Kubelet, es decir en el agente host de Kubernetes, asignando CPU dedicadas a contenedores de un hogar específico.
Suena genial! ¿Pero el CPU Manager me ayudará?
Depende de la carga de trabajo. El único nodo de cómputo en el clúster de Kubernetes puede ejecutar muchos hogares, y algunos de ellos pueden ejecutar cargas que están activas en el consumo de CPU. En este escenario, los hogares pueden competir por los recursos de proceso disponibles en este nodo. Cuando esta competencia se intensifica, la carga de trabajo puede cambiar a otras CPU dependiendo de si se
estranguló y qué CPU estaban disponibles en el momento de la planificación. Además, puede haber casos en los que la carga de trabajo sea sensible a los cambios de contexto. En todos estos escenarios, el rendimiento de la carga de trabajo puede verse afectado.
Si su carga de trabajo es sensible a tales escenarios, puede habilitar CPU Manager para proporcionar un mejor aislamiento del rendimiento al asignar CPU específicas a la carga.
CPU Manager puede ayudar con cargas con las siguientes características:
- Sensible a los efectos de aceleración de la CPU
- sensible a los cambios de contexto;
- el caché del procesador falla;
- Beneficiarse de dividir los recursos del procesador (por ejemplo, caché de datos e instrucciones);
- memoria sensible a la memoria entre los zócalos del procesador (se proporciona una explicación detallada de lo que los autores tienen en mente en el Unix Stack Exchange - traducción aprox. ) ;
- hyperthreads sensibles o que requieren el mismo núcleo físico de la CPU.
Ok! ¿Cómo usarlo?
Usar CPU Manager es fácil. Primero,
habilítelo utilizando la Política estática en Kubelet que se ejecuta en los nodos de proceso del clúster. Luego configure la clase
de Calidad de servicio garantizada (QoS) para el hogar. Solicite un número entero de núcleos de CPU (por ejemplo,
1000m o
4000m ) para contenedores que necesitan núcleos dedicados. Cree bajo el método anterior (por ejemplo,
kubectl create -f pod.yaml ) ... y listo, el Administrador de CPU asignará núcleos de procesador dedicados a cada contenedor de solera según sus necesidades de CPU.
apiVersion: v1 kind: Pod metadata: name: exclusive-2 spec: containers: - image: quay.io/connordoyle/cpuset-visualizer name: exclusive-2 resources: # Pod is in the Guaranteed QoS class because requests == limits requests: # CPU request is an integer cpu: 2 memory: "256M" limits: cpu: 2 memory: "256M"
Especificación de un hogar que solicita 2 CPU dedicadas.¿Cómo funciona el Administrador de CPU?
Consideramos tres tipos de control de recursos de CPU disponibles en la mayoría de las distribuciones de Linux, que serán relevantes para Kubernetes y los propósitos de esta publicación. Los dos primeros son recursos compartidos de CFS (cuál es mi parte "honesta" ponderada del tiempo de CPU en el sistema) y la cuota de CFS (cuál es el tiempo máximo de CPU que me asignaron para el período). CPU Manager también usa un tercero, que se llama afinidad de CPU (en las cuales las CPU lógicas me permiten realizar cálculos).
De forma predeterminada, todos los pods y contenedores que se ejecutan en el nodo del clúster de Kubernetes pueden ejecutarse en cualquier núcleo del sistema disponible. El número total de recursos compartidos y la cuota asignada está limitado por los recursos de CPU reservados para
Kubernetes y los demonios del sistema . Sin embargo, los límites en el tiempo de CPU utilizado pueden determinarse utilizando
límites en la CPU en la especificación de hogar . Kubernetes usa la
cuota CFS para imponer los límites de CPU en los contenedores de hogar.
Cuando habilita el Administrador de CPU con una política
estática , administra un grupo dedicado de CPU. Inicialmente, este grupo contiene toda la CPU del nodo de proceso. Cuando Kubelet crea un contenedor en el hogar con un número garantizado de núcleos de procesador dedicados, las CPU asignadas a este contenedor se le asignan durante toda su vida útil y se eliminan del grupo compartido. Las cargas de los contenedores restantes se transfieren de estos núcleos dedicados a otros.
Todos los contenedores sin CPU dedicadas (
Burstable ,
BestEffort y
Garantizado con CPU no enteras ) se ejecutan en los núcleos que quedan en el grupo compartido. Cuando un contenedor con CPU dedicadas deja de funcionar, sus núcleos regresan al grupo compartido.
Más detalles, por favor ...

El diagrama de arriba muestra la anatomía del Administrador de CPU. Utiliza el método
UpdateContainerResources de la Interfaz de tiempo de ejecución de contenedor (CRI) para cambiar las CPU en las que se ejecutan los contenedores.
El administrador hace
cgroupfs periódicamente
cgroupfs con el estado actual de los recursos de la CPU para cada contenedor en ejecución.
El Administrador de CPU utiliza
políticas para decidir la asignación de núcleos de CPU. Se implementan dos políticas:
Ninguna y
Estática . Por defecto, comenzando con Kubernetes versión 1.10, está habilitado con la política
Ninguno .
La política
estática asigna contenedores de pod asignados a la CPU a la clase de QoS garantizada, que solicita un número entero de núcleos. La política
estática intenta designar la CPU de la mejor manera topológica y en el siguiente orden:
- Asigne todas las CPU a un zócalo de procesador, si está disponible y el contenedor requiere una CPU en la cantidad de al menos un zócalo de CPU completo.
- Asigne todas las CPU lógicas (hyperthreads) de un núcleo de CPU físico, si está disponible, y el contenedor requiere una CPU de al menos todo el núcleo.
- Asigne cualquier CPU lógica disponible con preferencia para CPU de un solo socket.
¿Cómo CPU Manager mejora el aislamiento de cómputo?
Con la política
estática habilitada en el Administrador de CPU, las cargas de trabajo pueden funcionar mejor por uno de los siguientes motivos:
- Las CPU dedicadas se pueden asignar a un contenedor con una carga de trabajo, pero no a otros contenedores. Estos (otros) contenedores no usan los mismos recursos de CPU. Como resultado, esperamos un mejor rendimiento debido al aislamiento en casos de aparición de un "agresor" (procesos exigentes de la CPU - aprox. Transl. ) O carga de trabajo adyacente.
- Hay menos competencia por los recursos utilizados por la carga de trabajo, ya que podemos dividir la CPU por la carga de trabajo misma. Estos recursos pueden incluir no solo la CPU, sino también jerarquías de caché y ancho de banda de memoria. Esto mejora el rendimiento general de la carga de trabajo.
- El Administrador de CPU asigna la CPU en un orden topológico basado en las mejores opciones disponibles. Si todo el socket está libre, asignará todas sus CPU a la carga de trabajo. Esto mejora el rendimiento de la carga de trabajo debido a la falta de tráfico entre sockets.
- Los contenedores en cápsulas con QoS garantizada están sujetos al límite de cuota CFS. Las cargas de trabajo propensas a explosiones repentinas pueden planificarse y exceder su cuota antes del final de su período asignado, como resultado de lo cual se estrangulan . Las CPU involucradas en este momento pueden tener un trabajo significativo y no muy útil. Sin embargo, dichos contenedores no estarán sujetos a la limitación de CFS cuando la CPU de cuota se complementa con una política de asignación de CPU dedicada.
Ok! ¿Tienes algún resultado?
Para ver las mejoras de rendimiento y el aislamiento proporcionados por la inclusión del Administrador de CPU en Kubelet, realizamos experimentos en un nodo de cómputo con dos sockets (Intel Xeon CPU E5-2680 v3) y hyperthreading habilitado. El nodo consta de 48 CPU lógicas (24 núcleos físicos, cada uno con hyperthreading). A continuación se muestran los beneficios de rendimiento y aislamiento del Administrador de CPU capturados por las cargas de trabajo de referencia y de la vida real en tres escenarios diferentes.
¿Cómo interpretar gráficos?
Para cada escenario, se muestran gráficos (
diagramas de tramo ,
diagramas de caja) que ilustran el tiempo de ejecución normalizado y su variabilidad al iniciar un punto de referencia o una carga real con el Administrador de CPU encendido y apagado. El tiempo de ejecución se normaliza a los mejores lanzamientos (1.00 en el eje Y representa el mejor tiempo de inicio: cuanto menor sea el valor del gráfico, mejor). La altura del gráfico en el gráfico muestra la variabilidad en el rendimiento. Por ejemplo, si el sitio es una línea, entonces no hay variación en el rendimiento de estos lanzamientos. En estas áreas, la línea media es la mediana, la superior es el percentil 75 y la inferior es el percentil 25. La altura del gráfico (es decir, la diferencia entre los percentiles 75 y 25) se define como el rango intercuartil (IQR). "Bigote" muestra datos fuera de este intervalo, y los puntos muestran valores atípicos. Las emisiones se definen como cualquier dato que difiere del IQR en 1,5 veces, menos o más que el cuartil correspondiente. Cada experimento se llevó a cabo 10 veces.
Protección agresiva
Lanzamos seis benchmark'ov desde un
conjunto de PARSEC (cargas de trabajo - "víctimas")
[se puede leer más sobre las cargas de trabajo de las víctimas, por ejemplo, aquí - aprox. perev. ] junto al contenedor que carga la CPU (carga de trabajo "agresor") con el Administrador de CPU activado y desactivado.
El contenedor del agresor se inicia
como debajo con la clase de QoS de
Burstable que solicita el indicador de CPU 23
--cpus 48 . Los puntos de referencia se ejecutan
como pods con la clase QoS
garantizada , que requiere un conjunto de CPU de un socket completo (es decir, 24 CPU en este sistema). Los gráficos a continuación muestran el tiempo de inicio del pod normalizado con un punto de referencia junto al agresor del pod, con la política
estática de CPU Manager y sin ella. En todos los casos de prueba, puede ver un rendimiento mejorado y una variabilidad de rendimiento reducida con la política habilitada.

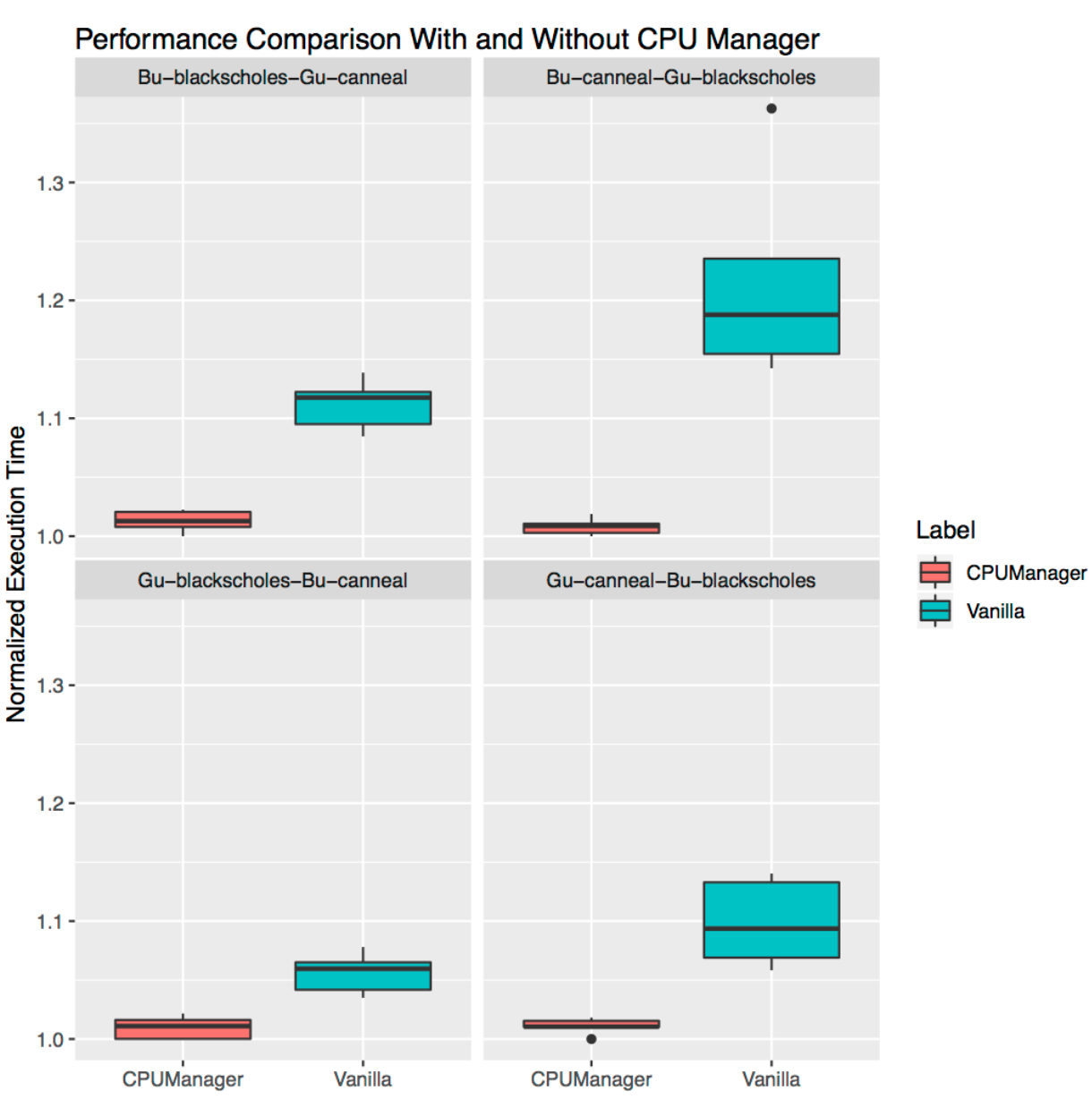
Aislamiento para cargas adyacentes.
Esto demuestra cuán útil puede ser el Administrador de CPU para muchas cargas de trabajo ubicadas conjuntamente. Los diagramas de intervalo a continuación muestran el rendimiento de dos puntos de referencia del conjunto PARSEC (
Blackscholes y
Canneal ) lanzado para las clases de QoS
Garantizadas (Gu) y
Burstable (Bu) adyacentes entre sí, con la política
estática activada y desactivada.
Siguiendo en el sentido de las agujas del reloj desde el gráfico superior izquierdo, vemos el rendimiento de
Blackscholes para Bu QoS (arriba a la izquierda),
Canneal para Bu QoS (arriba a la derecha),
Canneal para Gu QoS (abajo a la derecha) y
Blackscholes para Gu QoS (abajo a la izquierda). En cada gráfico, se ubican (en sentido horario nuevamente) junto con
Canneal para Gu QoS (arriba a la izquierda),
Blackscholes para Gu QoS (arriba a la derecha),
Blackscholes para Bu QoS (abajo a la derecha) y
Canneal para Bu QoS (abajo a la izquierda) en consecuencia Por ejemplo, el
gráfico Bu-blackscholes-Gu-canneal (arriba a la izquierda) muestra el rendimiento de
Blackscholes con Bu QoS y ubicado junto a
Canneal con la clase Gu QoS. En cada caso, debajo de la clase Gu QoS requiere un núcleo de socket completo (es decir, 24 CPU), y debajo de la clase Bu QoS - 23 CPU.
Hay un mejor rendimiento y menos variación en el rendimiento para ambas cargas de trabajo adyacentes en todas las pruebas. Por ejemplo, mire
Bu-blackscholes-Gu-canneal (arriba a la izquierda) y
Gu-canneal-Bu-blackscholes (abajo a la derecha). Muestran el rendimiento de ejecutar
Blackscholes y
Canneal con el Administrador de CPU activado y desactivado. En este caso,
Canneal recibe más núcleos dedicados del Administrador de CPU, ya que pertenece a la clase Gu QoS y solicita un número entero de núcleos de CPU. Sin embargo,
Blackscholes también obtiene un conjunto dedicado de CPU, ya que esta es la única carga de trabajo en el grupo compartido. Como resultado, tanto
Blackscholes como
Canneal aprovechan el aislamiento de carga cuando usan CPU Manager.
Aislamiento para cargas independientes
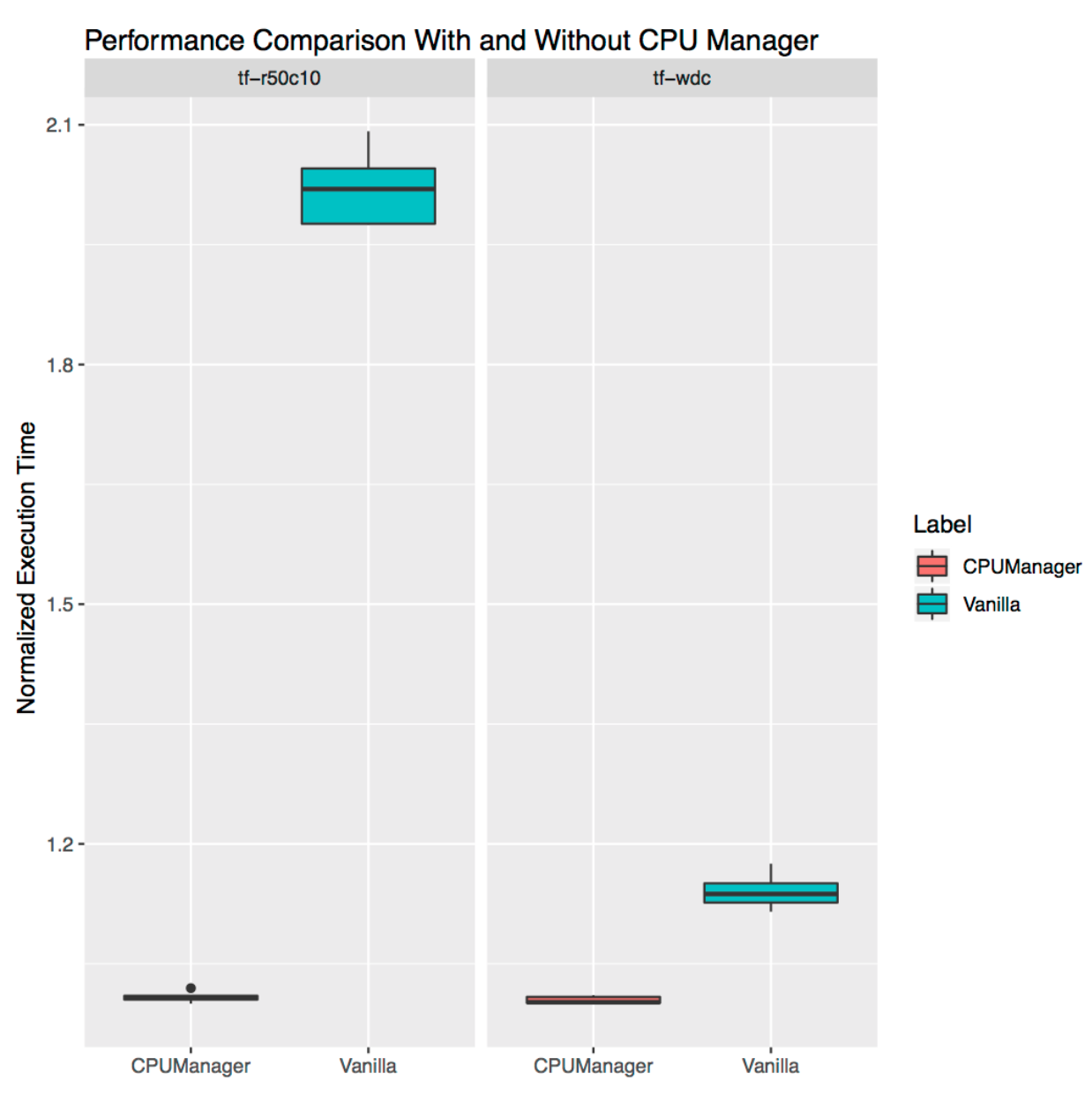
Demuestra cuán útil puede ser CPU Manager para cargas de trabajo independientes de la vida real. Tomamos dos cargas de los
modelos oficiales de TensorFlow :
ancho y profundo y
ResNet . Se utilizan conjuntos de datos típicos para ellos (censo y CIFAR10, respectivamente). En ambos casos, los
hogares (
ancho y profundo ,
ResNet ) requieren 24 CPU, que corresponde a un zócalo completo. Como se muestra en los gráficos, en ambos casos el Administrador de CPU proporciona un mejor aislamiento.
Limitaciones
Los usuarios pueden querer que las CPU se asignen en un zócalo cercano al bus que se conecta a un dispositivo externo, como un acelerador o una tarjeta de red de alto rendimiento para evitar el tráfico entre los zócalos. Este tipo de configuración aún no es compatible con el Administrador de CPU. Dado que el Administrador de CPU proporciona la mejor asignación posible de CPU que pertenecen a un socket o núcleo físico, es sensible a casos extremos y puede conducir a la fragmentación. El Administrador de CPU no tiene en cuenta el parámetro de arranque del kernel
isolcpus Linux, aunque se usa como práctica popular en algunos casos
(para obtener más detalles sobre este parámetro, consulte, por ejemplo, aquí , aprox. Transl. ) .
PD del traductor
Lea también en nuestro blog: