
En los últimos años, el tema de la inteligencia artificial y el aprendizaje automático ha dejado de ser algo para las personas del mundo de la ficción y ha entrado firmemente en la vida cotidiana. Las redes sociales ofrecen asistir a eventos que nos interesan, los autos en las carreteras aprendieron a moverse sin conductor, y un asistente de voz en el teléfono le dice cuándo es mejor salir de casa para evitar atascos y si llevar un paraguas con usted.
En este artículo, consideraremos las herramientas de aprendizaje automático que ofrecen los desarrolladores de Apple, analizaremos lo que la compañía mostró como nuevo en esta área en WWDC18 e intentaremos entender cómo poner todo esto en práctica.
Aprendizaje automático
Entonces, el aprendizaje automático es un proceso durante el cual un sistema, usando ciertos algoritmos de análisis de datos y procesando una gran cantidad de ejemplos, identifica patrones y los usa para predecir las características de los nuevos datos.
El aprendizaje automático nació de la teoría de que las computadoras pueden aprender por sí mismas, aún no programadas para realizar ciertas acciones. En otras palabras, a diferencia de los programas convencionales con instrucciones predefinidas para resolver problemas específicos, el aprendizaje automático le permite al sistema aprender a reconocer patrones y hacer predicciones de manera independiente.
BNNS y CNN
Apple ha estado utilizando la tecnología de aprendizaje automático en sus dispositivos durante bastante tiempo: Mail identifica correos electrónicos no deseados, Siri lo ayuda a encontrar rápidamente respuestas a sus preguntas, Photos reconoce los rostros en las imágenes.
En WWDC16, la compañía introdujo dos API basadas en redes neuronales: subrutinas básicas de redes neuronales (BNNS) y redes neuronales convolucionales (CNN). BNNS es parte del sistema Accelerate, que es la base para realizar cálculos rápidos en la CPU, y CNN es la biblioteca Metal Performance Shaders que utiliza la GPU. Puede obtener más información sobre estas tecnologías, por ejemplo, aquí .
Core ML y Turi Create
El año pasado, Apple anunció un marco que facilita enormemente el trabajo con tecnologías de aprendizaje automático: Core ML. Se basa en la idea de tomar un modelo de datos previamente capacitado e integrarlo en su aplicación en solo unas pocas líneas de código.
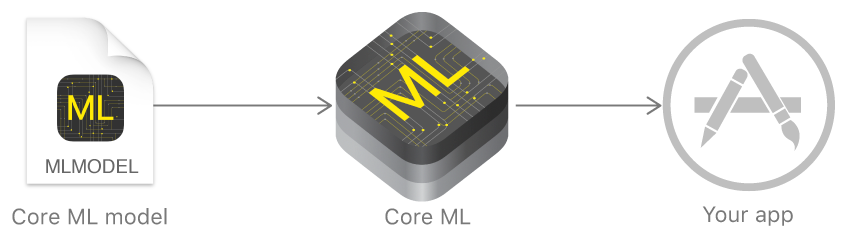
Con Core ML, puede implementar muchas funciones:
- definición de objetos en una foto y video;
- ingreso de texto predictivo;
- seguimiento y reconocimiento de rostros;
- análisis de movimiento;
- definición de código de barras;
- comprensión y reconocimiento de texto;
- reconocimiento de imágenes en tiempo real;
- estilización de imagen;
- y mucho mas
Core ML, a su vez, utiliza Metal de bajo nivel, Acelerar y BNNS, y por lo tanto los resultados de los cálculos son muy rápidos.
El núcleo admite redes neuronales, modelos lineales generalizados, ingeniería de características, algoritmos de toma de decisiones basados en árboles (conjuntos de árboles), métodos de máquinas de vectores de soporte, modelos de tuberías.
Pero Apple no mostró inicialmente sus propias tecnologías para crear y entrenar modelos, sino que solo hizo un convertidor para otros marcos populares: Caffe, Keras, scikit-learn, XGBoost, LIBSVM.
El uso de herramientas de terceros a menudo no era la tarea más fácil, los modelos entrenados eran bastante grandes y la capacitación en sí misma requería mucho tiempo.
A finales de año, la compañía presentó Turi Create, un marco de aprendizaje modelo cuya idea principal era la facilidad de uso y el soporte para una gran cantidad de escenarios: clasificación de imágenes, definición de objetos, sistemas de recomendación y muchos otros. Pero Turi Create, a pesar de su relativa facilidad de uso, solo era compatible con Python.
Crear ML
Y este año, Apple, además de Core ML 2, finalmente mostró su propia herramienta para entrenar modelos: el marco Create ML usando las tecnologías nativas de Apple: Xcode y Swift.
Funciona rápido, y crear modelos de modelos con Create ML es realmente fácil.
En WWDC, se anunció el impresionante rendimiento de Create ML y Core ML 2 utilizando la aplicación Memrise como ejemplo. Si antes tomó 24 horas entrenar un modelo con 20 mil imágenes, entonces Crear ML reduce este tiempo a 48 minutos en el MacBook Pro y hasta 18 minutos en el iMac Pro. El tamaño del modelo entrenado disminuyó de 90 MB a 3 MB.
Create ML le permite usar imágenes, textos y objetos estructurados como tablas, por ejemplo, como datos de origen.
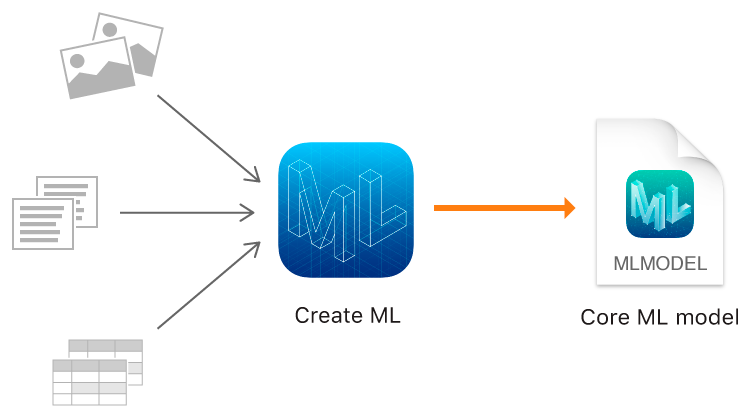
Clasificación de la imagen
Primero, veamos cómo funciona la clasificación de imágenes. Para entrenar el modelo, necesitamos un conjunto de datos inicial: tomamos tres grupos de fotos de animales: perros, gatos y pájaros y los distribuimos en carpetas con los nombres correspondientes, que se convertirán en los nombres de las categorías del modelo. Cada grupo contiene 100 imágenes con una resolución de hasta 1920 × 1080 píxeles y un tamaño de hasta 1Mb. Las fotografías deben ser lo más diferentes posible para que el modelo entrenado no se base en signos como el color de la imagen o el espacio circundante.
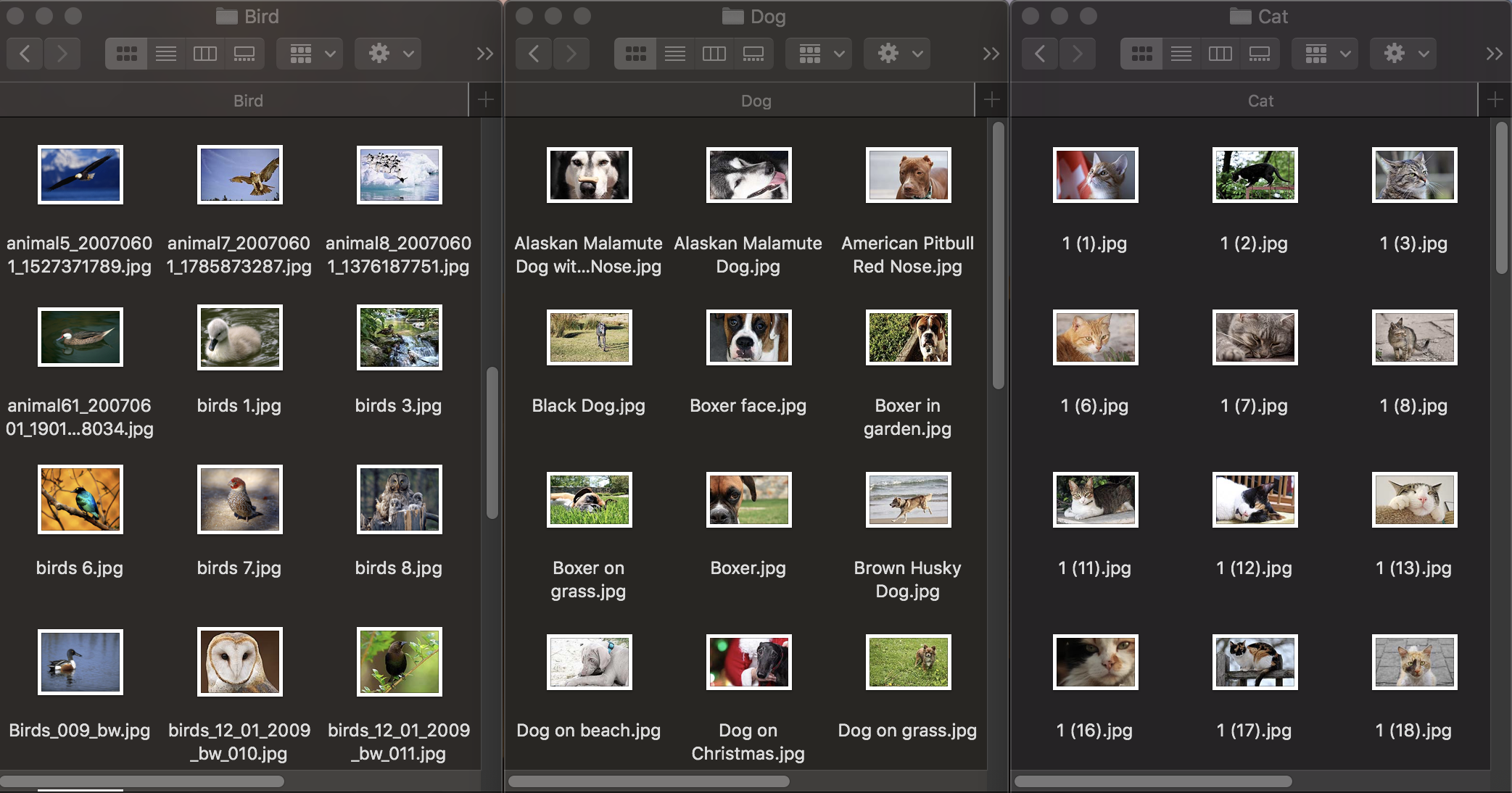
Además, para verificar qué tan bien un modelo entrenado maneja el reconocimiento de objetos, necesita un conjunto de datos de prueba: imágenes que no están en el conjunto de datos original.
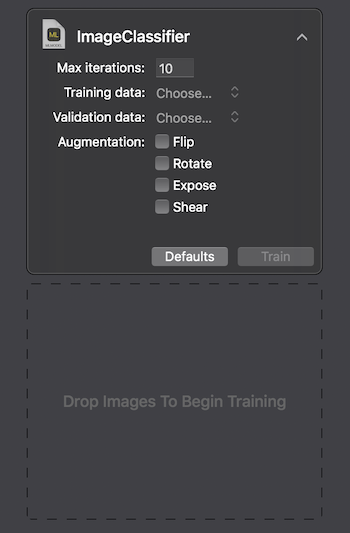
Apple proporciona dos formas de interactuar con Create ML: usando la interfaz de usuario en MacOS Playground Xcode y programáticamente usando CreateMLUI.framework y CreateML.framework. Usando el primer método, es suficiente escribir un par de líneas de código, transferir las imágenes seleccionadas al área especificada y esperar mientras el modelo aprende.

En el Macbook Pro 2017 en la configuración máxima, el entrenamiento tomó 29 segundos para 10 iteraciones, y el tamaño del modelo entrenado fue de 33Kb. Se ve impresionante.
Tratemos de descubrir cómo logramos alcanzar esos indicadores y qué es "bajo el capó".
La tarea de clasificar imágenes es uno de los usos más populares de las redes neuronales convolucionales. Primero, vale la pena explicar cuáles son.
Una persona, al ver una imagen de un animal, puede atribuirla rápidamente a una determinada clase en función de cualquier característica distintiva. Una red neuronal actúa de manera similar al buscar características básicas. Tomando la matriz inicial de píxeles como entrada, pasa información secuencialmente a través de grupos de capas convolucionales y construye abstracciones cada vez más complejas. En cada capa posterior, ella aprende a resaltar ciertas características: primero son líneas, luego conjuntos de líneas, formas geométricas, partes del cuerpo, etc. En la última capa obtenemos la conclusión de una clase o grupo de clases probables.
En el caso de Create ML, el entrenamiento de redes neuronales no se realiza desde cero. El marco utiliza una red neuronal previamente entrenada en un gran conjunto de datos, que ya incluye una gran cantidad de capas y tiene una alta precisión.
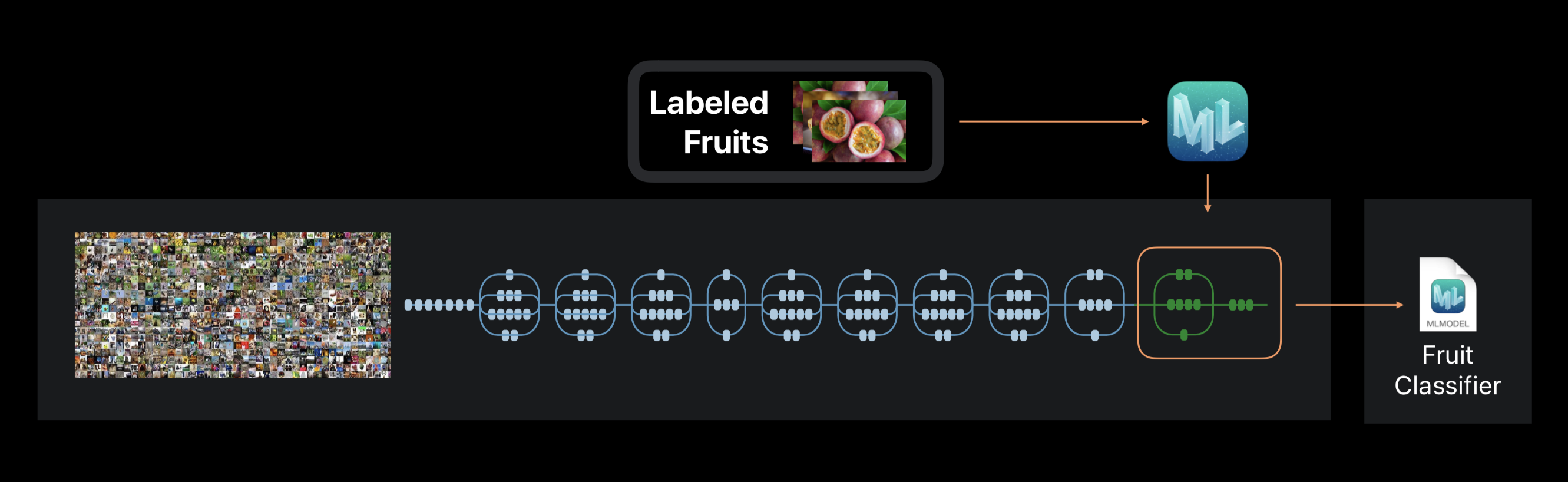
Esta tecnología se llama transferencia de aprendizaje. Con él, puede cambiar la arquitectura de una red previamente capacitada para que sea adecuada para resolver un nuevo problema. La red modificada se entrena en un nuevo conjunto de datos.
Crea ML durante los extractos de entrenamiento de la foto sobre 1000 características distintivas. Esta puede ser la forma de los objetos, el color de las texturas, la ubicación de los ojos, los tamaños y muchos otros.
Cabe señalar que el conjunto de datos inicial en el que se entrena la red neuronal utilizada, como la nuestra, puede contener fotografías de gatos, perros y pájaros, pero estas categorías no están asignadas específicamente. Todas las categorías forman una jerarquía. Por lo tanto, es simplemente imposible aplicar esta red en su forma pura: es necesario volver a entrenarla en nuestros datos.
Al final del proceso, vemos cuán exactamente nuestro modelo fue entrenado y probado después de varias iteraciones. Para mejorar los resultados, podemos aumentar el número de imágenes en el conjunto de datos original o cambiar el número de iteraciones.
A continuación, podemos probar el modelo nosotros mismos en un conjunto de datos de prueba. Las imágenes deben ser únicas, es decir. No ingrese el conjunto fuente.
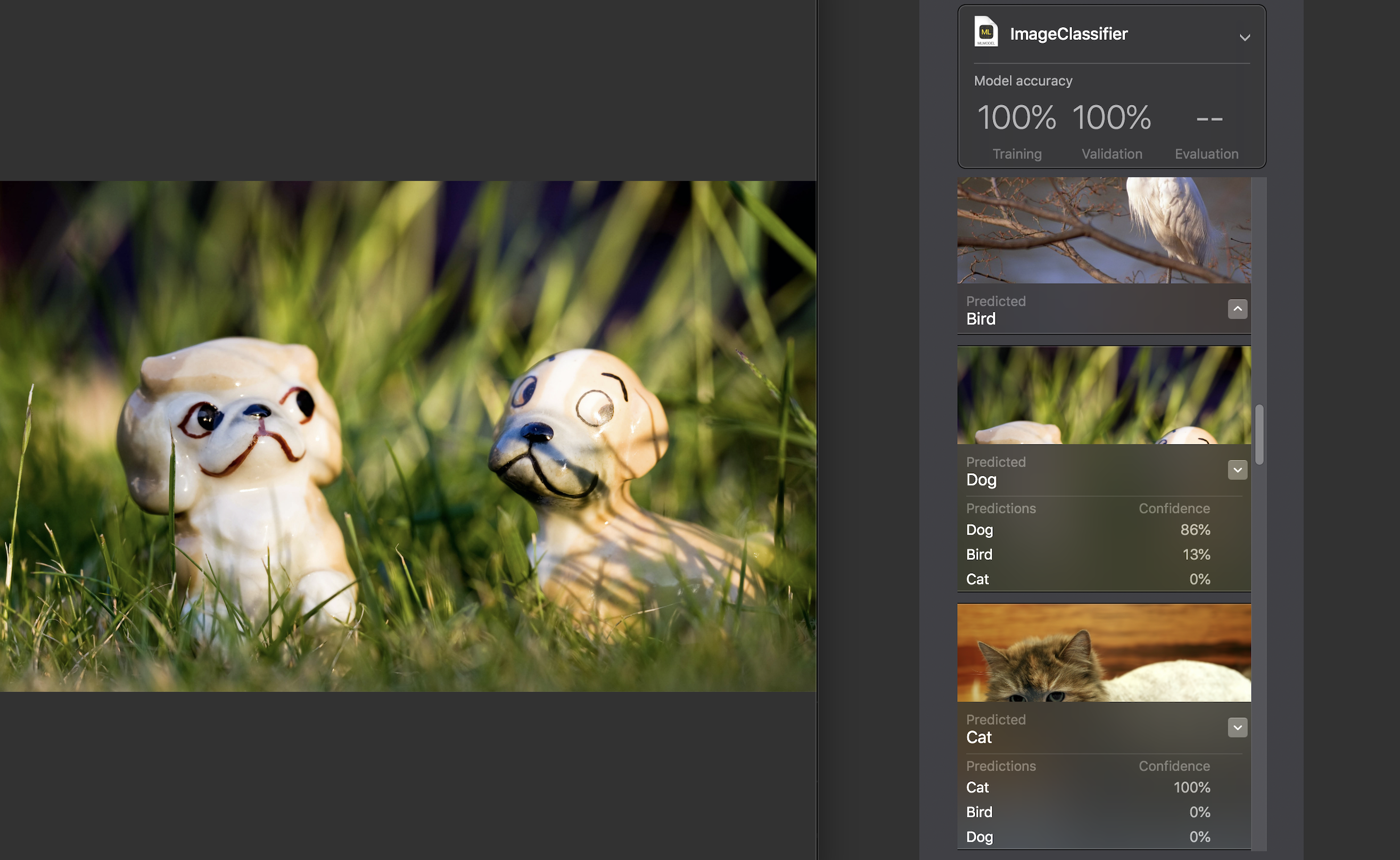
Para cada imagen, se muestra un indicador de confianza : con qué precisión, con la ayuda de nuestro modelo, se reconoció la categoría.
Para casi todas las fotos, con raras excepciones, esta cifra fue del 100%. Agregué específicamente la imagen que ves arriba al conjunto de datos de prueba y, como puedes ver, Create ML reconoció en ella el 86% del perro y el 13% del ave.
Se completa la capacitación modelo, y todo lo que nos queda es guardar el archivo * .mlmodel y agregarlo a su proyecto.
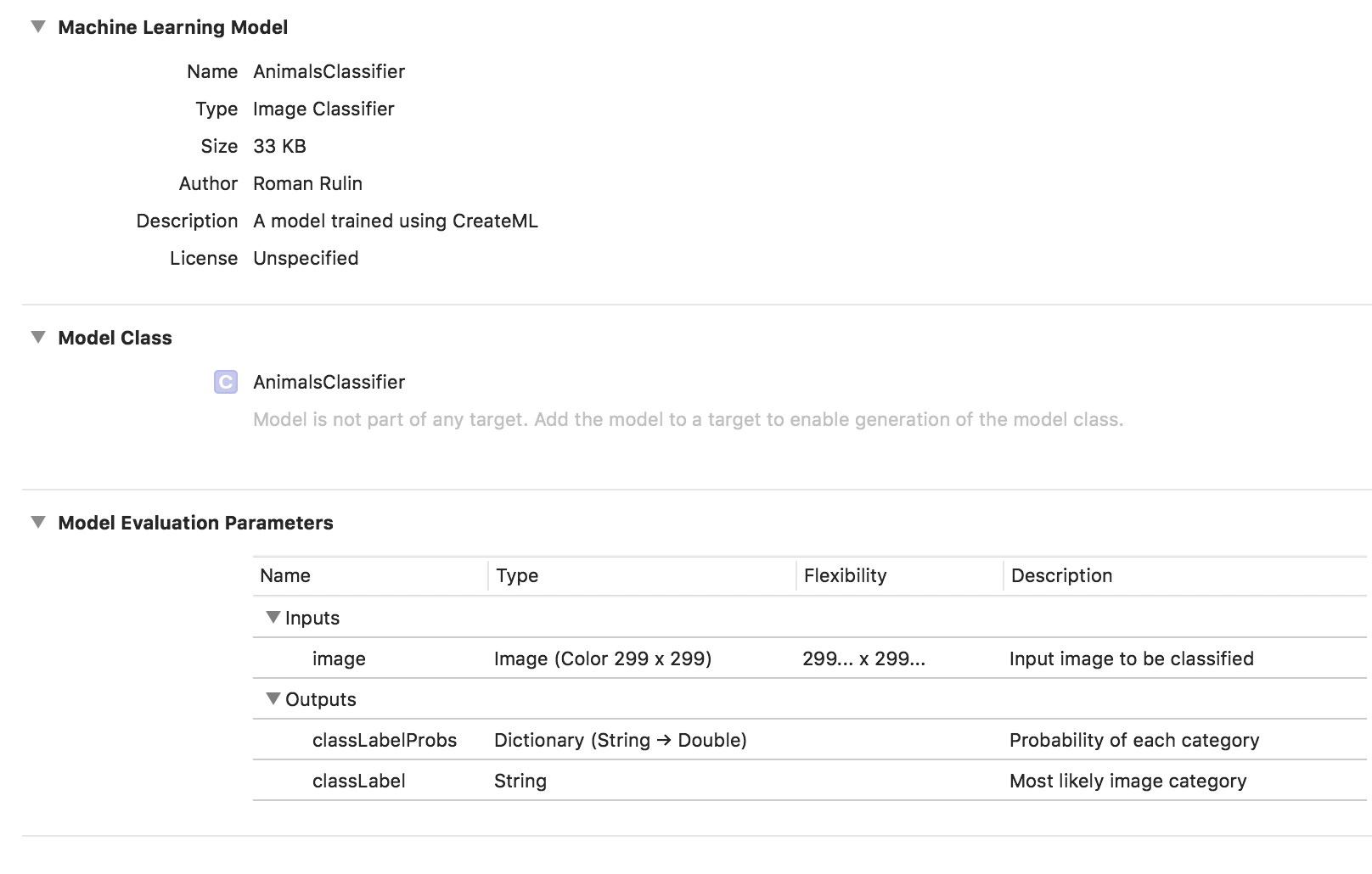
Para probar el modelo, escribí una aplicación simple usando el marco Vision. Le permite trabajar con modelos Core ML y resolver problemas al usarlos, como la clasificación de imágenes o la detección de objetos.
Nuestra aplicación reconocerá la imagen de la cámara del dispositivo y mostrará la categoría y el porcentaje de confianza en la clasificación.
Inicializamos el modelo Core ML para trabajar con Vision y configuramos la consulta:
func setupVision() { guard let visionModel = try? VNCoreMLModel(for: AnimalsClassifier().model) else { fatalError("Can't load VisionML model") } let request = VNCoreMLRequest(model: visionModel) { (request, error) in guard let results = request.results else { return } self.handleRequestResults(results) } requests = [request] }
Agregue un método que procesará los resultados de VNCoreMLRequest. Solo mostramos aquellos con un indicador de confianza de más del 70%:
func handleRequestResults(_ results: [Any]) { let categoryText: String? defer { DispatchQueue.main.async { self.categoryLabel.text = categoryText } } guard let foundObject = results .compactMap({ $0 as? VNClassificationObservation }) .first(where: { $0.confidence > 0.7 }) else { categoryText = nil return } let category = categoryTitle(identifier: foundObject.identifier) let confidence = "\(round(foundObject.confidence * 100 * 100) / 100)%" categoryText = "\(category) \(confidence)" }
Y el último: agregaremos el método de delegado AVCaptureVideoDataOutputSampleBufferDelegate, que se llamará con cada nuevo fotograma de la cámara y ejecutaremos la solicitud:
func captureOutput( _ output: AVCaptureOutput, didOutput sampleBuffer: CMSampleBuffer, from connection: AVCaptureConnection) { guard let pixelBuffer = CMSampleBufferGetImageBuffer(sampleBuffer) else { return } var requestOptions: [VNImageOption: Any] = [:] if let cameraIntrinsicData = CMGetAttachment( sampleBuffer, key: kCMSampleBufferAttachmentKey_CameraIntrinsicMatrix, attachmentModeOut: nil) { requestOptions = [.cameraIntrinsics:cameraIntrinsicData] } let imageRequestHandler = VNImageRequestHandler( cvPixelBuffer: pixelBuffer, options: requestOptions) do { try imageRequestHandler.perform(requests) } catch { print(error) } }
Veamos qué tan bien el modelo hace frente a su tarea:

La categoría se determina con una precisión bastante alta, y esto es especialmente sorprendente cuando se considera cuán rápido fue el entrenamiento y cuán pequeño era el conjunto de datos original. Periódicamente, contra un fondo oscuro, el modelo revela pájaros, pero creo que esto se puede resolver fácilmente aumentando el número de imágenes en el conjunto de datos original o aumentando el nivel mínimo aceptable de confianza.
Si queremos volver a entrenar el modelo para clasificar otra categoría, simplemente agregue un nuevo grupo de imágenes y repita el proceso; tomará unos minutos.
Como experimento, hice otro conjunto de datos, en el que cambié todas las fotos de gatos en la foto de un gato desde diferentes ángulos, pero en el mismo fondo y en el mismo entorno. En este caso, el modelo casi siempre cometió errores y reconoció la categoría en una habitación vacía, aparentemente confiando en el color como una característica clave.
Otra característica interesante introducida en Vision solo este año es la capacidad de reconocer objetos en la imagen en tiempo real. Está representado por la clase VNRecognizedObjectObservation, que le permite obtener la categoría de un objeto y su ubicación: boundingBox.

Ahora Crear ML no permite crear modelos para implementar esta funcionalidad. Apple sugiere usar Turi Create en este caso. El proceso no es mucho más complicado que el anterior: debe preparar carpetas de categorías con fotos y un archivo en el que para cada imagen se indicarán las coordenadas del rectángulo donde se encuentra el objeto.
Procesamiento del lenguaje natural
La siguiente función Create ML es entrenar modelos para clasificar textos en lenguaje natural, por ejemplo, para determinar el color emocional de las oraciones o detectar spam.
Para crear un modelo, debemos recopilar una tabla con el conjunto de datos original: oraciones o textos completos asignados a una determinada categoría, y entrenar el modelo con el objeto MLTextClassifier:
let data = try MLDataTable(contentsOf: URL(fileURLWithPath: "/Users/CreateMLTest/texts.json")) let (trainingData, testingData) = data.randomSplit(by: 0.8, seed: 5) let textClassifier = try MLTextClassifier(trainingData: trainingData, textColumn: "text", labelColumn: "label") try textClassifier.write(to: URL(fileURLWithPath: "/Users/CreateMLTest/TextClassifier.mlmodel"))
En este caso, el modelo entrenado es del tipo Clasificador de texto:
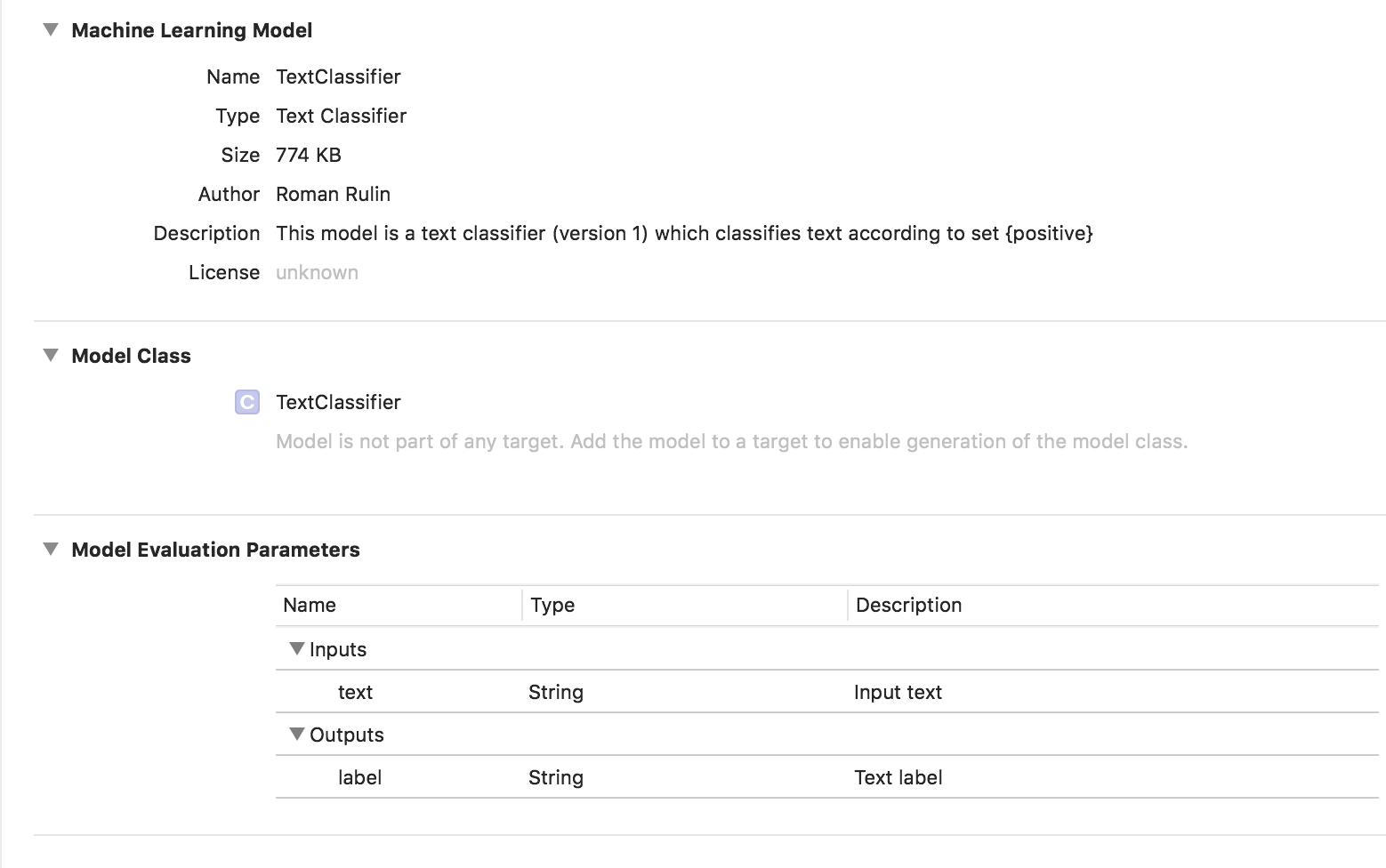
Datos tabulares
Echemos un vistazo más de cerca a otra característica de Create ML: entrenar un modelo utilizando datos estructurados (tablas).
Escribiremos una aplicación de prueba que prediga el precio de un apartamento en función de su ubicación en el mapa y otros parámetros especificados.
Entonces, tenemos una tabla con datos abstractos sobre apartamentos en Moscú en forma de archivo csv: se conoce el área de cada apartamento, piso, número de habitaciones y coordenadas (latitud y longitud). Además, se conoce el costo de cada apartamento. Cuanto más cerca del centro o mayor sea el área, mayor será el precio.
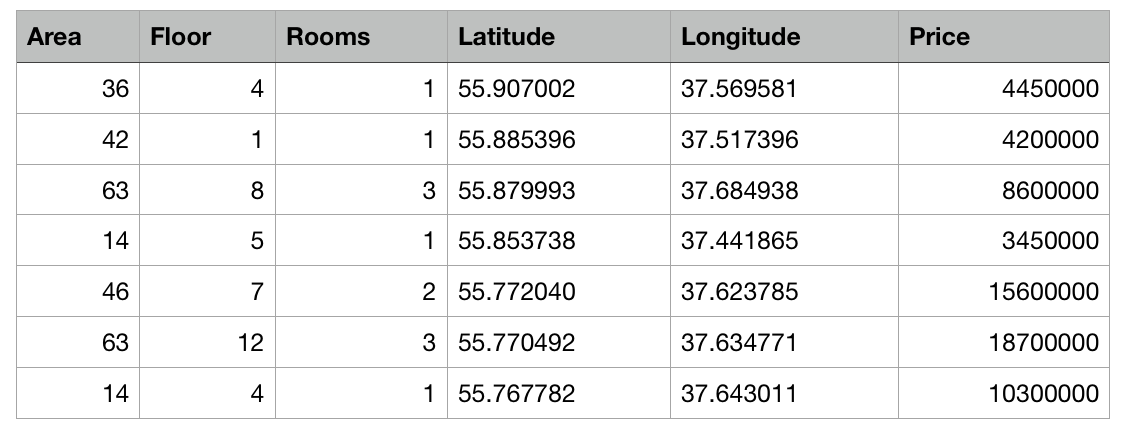
La tarea de Create ML será construir un modelo capaz de predecir el precio de un apartamento basado en estas características. Tal tarea en el aprendizaje automático se llama tarea de regresión y es un ejemplo clásico de aprendizaje con un maestro.
Create ML admite muchos modelos: regresión lineal, regresión de árbol de decisión, clasificador de árbol, regresión logística, clasificador de bosque aleatorio, regresión de árboles potenciados, etc.
Utilizaremos el objeto MLRegressor, que seleccionará la mejor opción en función de los datos de entrada.
Primero, inicialice el objeto MLDataTable con el contenido de nuestro archivo csv:
let trainingFile = URL(fileURLWithPath: "/Users/CreateMLTest/Apartments.csv") let apartmentsData = try MLDataTable(contentsOf: trainingFile)
Dividimos el conjunto de datos inicial en datos para capacitación y pruebas de modelos en un porcentaje de 80/20:
let (trainingData, testData) = apartmentsData.randomSplit(by: 0.8, seed: 0)
Creamos el modelo MLRegressor, que indica los datos para el entrenamiento y el nombre de la columna cuyos valores queremos predecir. El tipo de regresor específico de la tarea (lineal, árbol de decisión, árbol impulsado o bosque aleatorio) se seleccionará automáticamente en función del estudio de los datos de entrada. También podemos especificar columnas de características: columnas de parámetros específicos para el análisis, pero en este ejemplo esto no es necesario, utilizaremos todos los parámetros. Al final, guarde el modelo entrenado y agregue al proyecto:
let model = try MLRegressor(trainingData: apartmentsData, targetColumn: "Price") let modelPath = URL(fileURLWithPath: "/Users/CreateMLTest/ApartmentsPricer.mlmodel") try model.write(to: modelPath, metadata: nil)
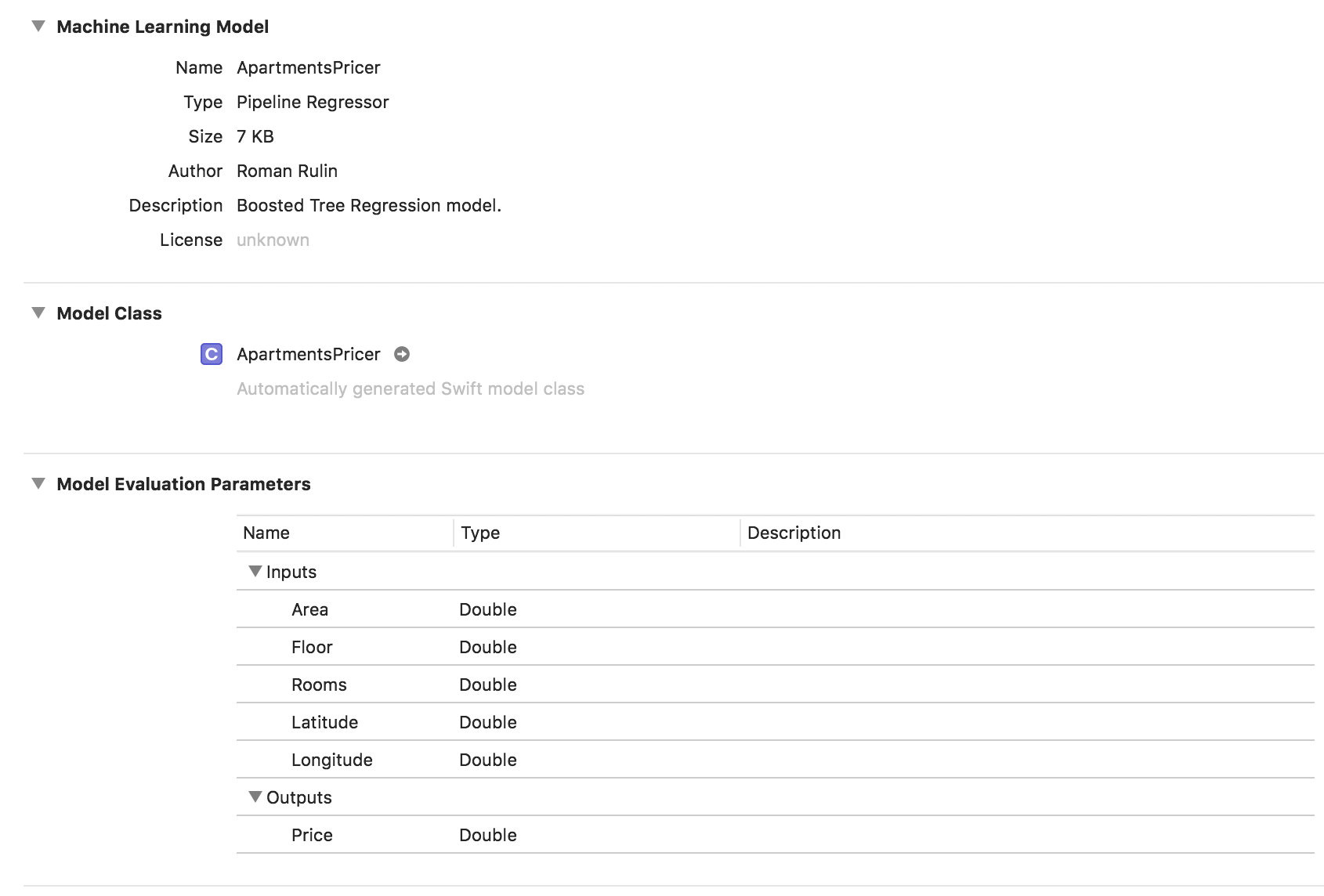
En este ejemplo, vemos que el tipo de modelo ya es un regresor de tubería, y el campo Descripción contiene el tipo de regresor seleccionado automáticamente - Modelo de regresión de árbol impulsado. Los parámetros de Entradas y Salidas corresponden a las columnas de la tabla, pero su tipo de datos se ha convertido en Doble.
Ahora verifique el resultado.
Inicialice el objeto modelo:
let model = ApartmentsPricer()
Llamamos al método de predicción, pasándole los parámetros especificados:
let area = Double(areaSlider.value) let floor = Double(floorSlider.value) let rooms = Double(roomsSlider.value) let latitude = annotation.coordinate.latitude let longitude = annotation.coordinate.longitude let prediction = try? model.prediction( area: area, floor: floor, rooms: rooms, latitude: latitude, longitude: longitude)
Mostramos el valor predicho del costo:
let price = prediction?.price priceLabel.text = formattedPrice(price)
Al cambiar un punto en el mapa o los valores de los parámetros, obtenemos el precio del apartamento muy cerca de nuestros datos de prueba:
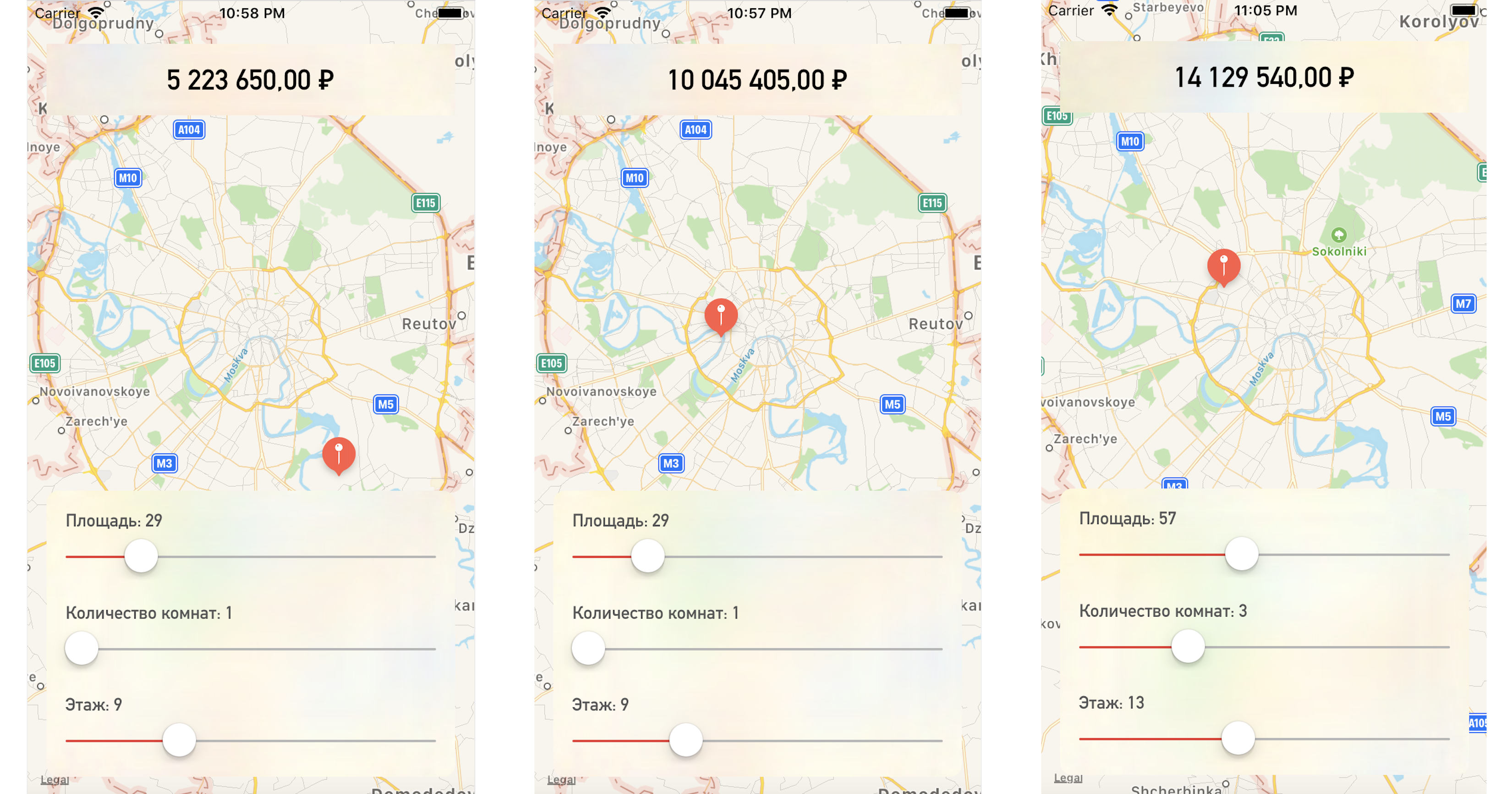
Conclusión
El marco Crear ML es ahora una de las formas más fáciles de trabajar con tecnologías de aprendizaje automático. Todavía no permite crear modelos para resolver algunos problemas: reconocimiento de objetos en una imagen, estilización de una foto, determinación de imágenes similares, reconocimiento de acciones físicas basadas en datos de un acelerómetro o giroscopio, que Turi Create, por ejemplo, maneja.
Pero vale la pena señalar que Apple ha hecho un progreso bastante serio en esta área durante el año pasado y, seguro, pronto veremos el desarrollo de las tecnologías descritas.