En esta parte del artículo, continuaremos considerando varios tipos de pruebas en producción. Los que se saltaron la primera parte pueden leerla
aquí . Por lo demás, bienvenido a cat.
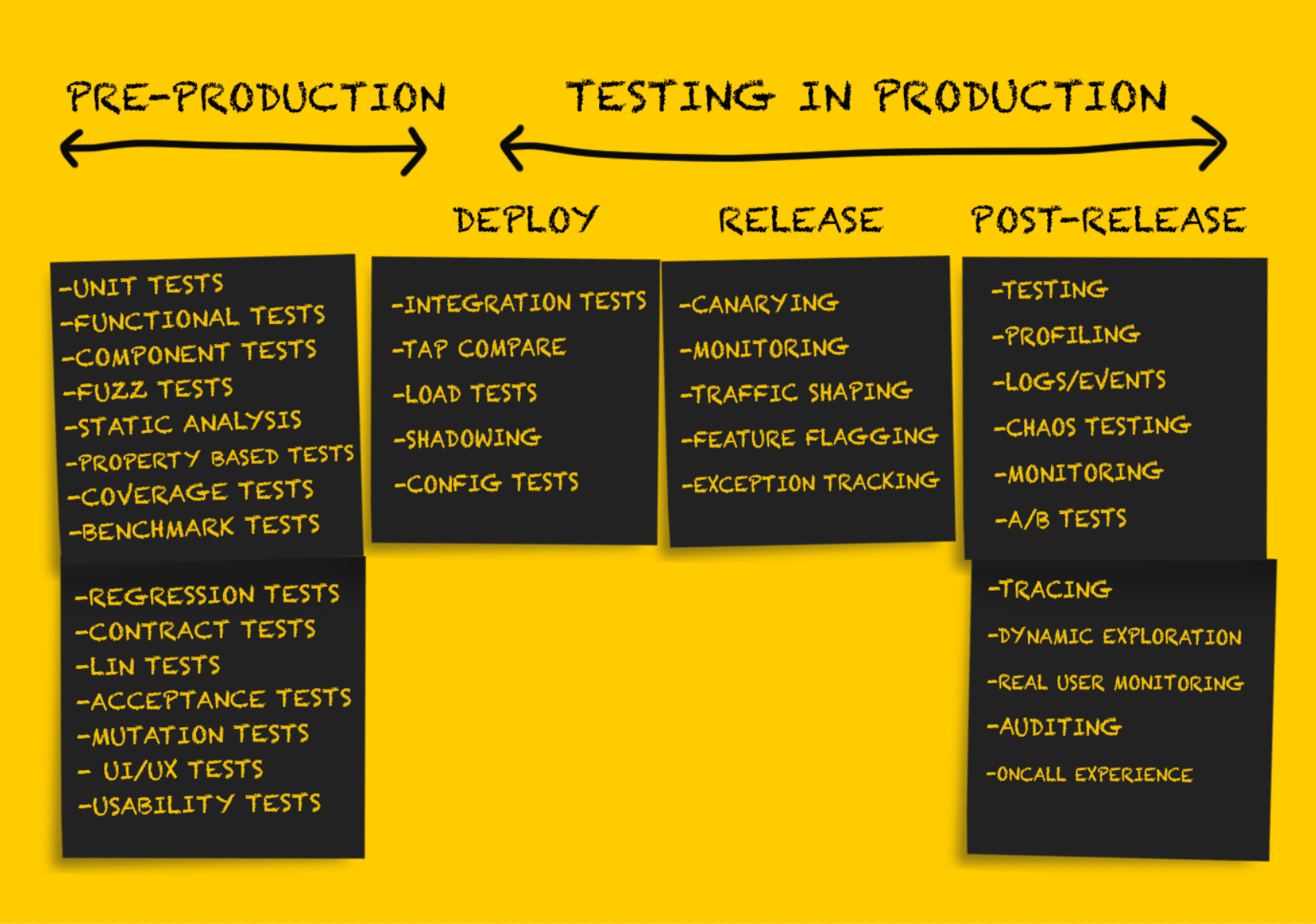
Pruebas de producción: lanzamiento
Después de probar el servicio después de la
implementación , debe estar preparado para su
lanzamiento .
Es importante tener en cuenta que en esta etapa la reversión de los cambios solo es posible en situaciones de falla
sostenible , por ejemplo:
- falla de servicio en bucle;
- exceder el tiempo de espera para un número significativo de conexiones en el flujo ascendente, lo que provoca un fuerte aumento en la frecuencia de errores;
- cambio de configuración inaceptable, por ejemplo, la falta de una clave secreta en una variable de entorno que causa un mal funcionamiento del servicio (las variables de entorno generalmente son mejores para evitar, pero este es un tema para otra discusión).
Las pruebas exhaustivas en la etapa de
implementación me permiten minimizar idealmente o evitar por completo sorpresas desagradables en la etapa de
lanzamiento . Sin embargo, hay una serie de recomendaciones para liberar de forma segura el nuevo código.
Despliegue de Canarias
El despliegue de Canary es un
lanzamiento parcial
de un servicio en producción. A medida que pasa la comprobación de estado básica, las pequeñas partes del tráfico del entorno de producción actual se envían a las partes liberadas. Los resultados de las partes del servicio se supervisan a medida que se procesa el tráfico, los indicadores se comparan con los de referencia (no relacionados con los canarios), y si caen fuera de los valores de umbral aceptables, se realiza una reversión al estado anterior. Aunque este enfoque se usa generalmente cuando se lanza el software del servidor, las
pruebas canarias del software del cliente también se están volviendo más comunes.
Varios factores influyen en el tráfico que se utilizará para el despliegue canario. En varias compañías, las partes lanzadas del servicio primero reciben solo tráfico interno de usuarios (lo que se conoce como alimentación de perros). Si no se observan errores, se agrega una pequeña parte del tráfico del entorno de producción, después de lo cual se realiza una implementación completa. Se
recomienda que regrese al estado anterior en caso de resultados de implementación canarios no válidos
automáticamente , y las herramientas como
Spinnaker tienen soporte incorporado para análisis automatizado y funciones de reversión.
Hay algunos problemas con las pruebas canarias, y
este artículo proporciona una descripción bastante completa de ellos.
Monitoreo
El monitoreo es un procedimiento absolutamente necesario en
cada etapa del despliegue del producto en producción, pero esta función será especialmente importante en la etapa de
lanzamiento . La supervisión es adecuada para obtener información sobre el nivel general de rendimiento del sistema. Pero monitorear todo en el mundo puede no ser la mejor solución.
El monitoreo
efectivo se realiza puntualmente, lo que le permite identificar un pequeño conjunto de modos de falla sostenible del sistema o un conjunto básico de indicadores. Ejemplos de tales modos de falla pueden ser:
- aumento en la tasa de error;
- una disminución en la velocidad general de procesamiento de solicitudes en todo el servicio, en un punto final específico, o, peor aún, un cese completo del trabajo;
- mayor retraso
La observación de cualquiera de estos modos de falla sostenible es la base para una reversión inmediata a un estado anterior o la reversión de nuevas versiones de software
lanzadas . Es importante recordar que es poco probable que el monitoreo en esta etapa sea completo e indicativo. Muchos creen que el número ideal de señales monitoreadas durante el monitoreo es de 3 a 5, pero
definitivamente no más de 7-10. El libro blanco de Kraken en Facebook ofrece la siguiente solución:
"El problema se resuelve con la ayuda de un componente de monitoreo fácilmente configurable, que se informa de dos indicadores básicos (el percentil 99 del tiempo de respuesta del servidor web y la frecuencia de ocurrencia de errores HTTP fatales) que describen objetivamente la calidad de la interacción del usuario".El conjunto de indicadores del sistema y de la aplicación que se monitorean durante la fase de lanzamiento se determina mejor durante el diseño del sistema.
Seguimiento de excepciones
Estamos hablando de rastrear excepciones en la etapa de lanzamiento, aunque podría parecer que en las etapas de
implementación y después del lanzamiento esto no sería menos útil. Las herramientas de seguimiento de excepciones a menudo no garantizan la misma minuciosidad, precisión y cobertura masiva que otras herramientas de monitoreo del sistema, pero aún pueden ser muy útiles.
Las herramientas de código abierto (como
Sentry ) muestran información avanzada sobre las solicitudes entrantes y crean pilas de datos de rastreo y variables locales, lo que simplifica enormemente el proceso de depuración, que generalmente consiste en ver registros de eventos. El seguimiento de excepciones también es útil al ordenar y priorizar problemas que no requieren una reversión completa a un estado anterior (por ejemplo, un caso límite que arroja una excepción).
Conformación del tráfico
La configuración del tráfico (redistribución del tráfico) no es tanto una forma independiente de prueba como una herramienta para apoyar el enfoque canario y la liberación por fases del nuevo código. De hecho, se garantiza la configuración del tráfico actualizando la configuración del equilibrador de carga, lo que le permite redirigir gradualmente más tráfico a la nueva versión
lanzada .
Este método también es útil para la implementación por fases del nuevo software (aparte de la implementación regular). Considera un ejemplo. Imgix necesitaba implementar una arquitectura de infraestructura fundamentalmente nueva en junio de 2016. Después de la primera prueba de la nueva infraestructura con una cierta cantidad de tráfico oscuro, comenzaron a desplegarse en producción, inicialmente redirigiendo aproximadamente el 1% del tráfico del entorno de producción a una nueva pila. Luego, en el transcurso de varias semanas, se aumentó el volumen de datos que llegaban a la nueva pila (resolviendo problemas en el camino), hasta que comenzó a procesar el 100% del tráfico.
La popularidad de la arquitectura de malla de servicios ha provocado un nuevo aumento en el interés en los servidores proxy. Como resultado, tanto los servidores proxy antiguos (nginx, HAProxy) como los nuevos (Envoy, Conduit) agregaron soporte para nuevas funciones en un intento de superar a los competidores. Me parece que el futuro, en el que la redistribución del tráfico del 0 al 100% en la etapa de lanzamiento del producto se lleva a cabo automáticamente, está a la vuelta de la esquina.
Pruebas de producción: después del lanzamiento
Las pruebas posteriores al lanzamiento se realizan como una verificación realizada
después de un lanzamiento exitoso
del código. En esta etapa, puede estar seguro de que el código en su conjunto es correcto, se ha
lanzado con éxito en producción y procesa el tráfico correctamente. El código implementado se usa directa o indirectamente en condiciones reales, sirviendo a clientes reales o realizando tareas que tienen un impacto significativo en el negocio.
El objetivo de cualquier prueba en esta etapa es principalmente verificar la operabilidad del sistema, teniendo en cuenta varias posibles cargas y patrones de tráfico. La mejor manera de hacer esto es recopilar evidencia documental de todo lo que sucede en la producción y usarla tanto para la depuración como para obtener una imagen completa del sistema.
Marcado de funciones o lanzamiento oscuro
La publicación más antigua sobre el uso exitoso de las banderas de características que encontré fue publicada hace casi diez años.
Featureflags.io proporciona la guía más completa para esto.
“La marcación de características es un método utilizado por los desarrolladores para marcar una nueva función utilizando sentencias if-then, que permite un mayor control sobre su lanzamiento. Al marcar una función y aislarla de esta manera, el desarrollador tiene la capacidad de activar y desactivar esta función independientemente del estado de implementación. Esto efectivamente separa el lanzamiento de la función del despliegue del código ".Al marcar el nuevo código, puede probar su rendimiento y rendimiento en producción según sea necesario. El marcado de características es uno de los tipos de pruebas generalmente aceptados en producción, es bien conocido y a menudo se
describe en
varias fuentes . Es mucho menos conocido el hecho de que este método puede usarse en el proceso de probar la
transferencia de bases de datos o software para sistemas personales.
De lo que los autores de artículos rara vez escriben es sobre los mejores métodos para desarrollar y usar indicadores de función. El uso incontrolado de banderas puede ser un problema grave. La falta de disciplina en términos de eliminar las banderas no utilizadas después de un período específico a veces lleva al hecho de que debe realizar una auditoría completa y eliminar las banderas obsoletas acumuladas durante meses (si no durante años) de trabajo.
Pruebas A / B
Las pruebas A / B a menudo se realizan como parte de un análisis experimental y no se consideran pruebas en producción. Por esta razón, las pruebas A / B no solo se usan ampliamente (a veces incluso de una manera
dudosa ), sino que también
se estudian y
describen activamente (incluidos artículos sobre
lo que determina un cuadro de
mando eficaz para experimentos en línea). Con mucha menos frecuencia, las pruebas A / B se utilizan para probar varias configuraciones de hardware o máquinas virtuales. A menudo se les llama "sintonización" (por ejemplo, sintonización JVM), pero no se clasifican como pruebas A / B típicas (aunque la sintonización se puede considerar como un tipo de prueba A / B realizada con el mismo nivel de rigor cuando se trata de mediciones) .
Registros, eventos, indicadores y seguimiento.
Puede
leer sobre las llamadas "tres ballenas de observabilidad": registros, indicadores y rastreo distribuido
aquí .
Perfilado
En algunos casos, para diagnosticar problemas de rendimiento, es necesario utilizar la creación de perfiles de aplicaciones en la producción. Dependiendo de los idiomas y tiempos de ejecución admitidos, la creación de perfiles puede ser un procedimiento bastante simple, que implica agregar solo una línea de código a la aplicación (
import _ "net/http/pprof" en el caso de Go). Por otro lado, puede requerir el uso de muchas herramientas o probar el proceso mediante el método de recuadro negro y verificar los resultados utilizando herramientas como los
gráficos de llama .
Prueba de tee
Muchas personas consideran que tales pruebas son algo así como la duplicación de datos, ya que en ambos casos el tráfico del entorno de producción se envía a grupos o procesos que no son de producción. En mi opinión, la diferencia es que el uso del tráfico para fines de
prueba es algo diferente de su uso para fines de
depuración .
Etsy escribió en su blog sobre el uso de tee-tests como herramienta de verificación (este ejemplo realmente se parece a la duplicación de datos en la sombra).
“Aquí tee puede entenderse como el comando tee en la línea de comando. Escribimos una regla iRule basada en un equilibrador de carga F5 existente para clonar el tráfico HTTP dirigido a uno de los grupos y redirigirlo a otro grupo. Por lo tanto, pudimos utilizar el tráfico del entorno de producción dirigido a nuestro clúster API y enviar una copia del mismo al clúster experimental HHVM, así como a un clúster PHP aislado para comparar.
Esta técnica ha demostrado ser muy efectiva. Nos permitió comparar el rendimiento de las dos configuraciones utilizando perfiles de tráfico idénticos ".Sin embargo, a veces se requiere una prueba de salida basada en el tráfico del entorno de producción en un sistema autónomo para la
depuración . En tales casos, el sistema autónomo se puede cambiar para configurar la salida de información de diagnóstico adicional u otro procedimiento de compilación (por ejemplo, utilizando la herramienta de limpieza de flujo), lo que simplifica enormemente el proceso de solución de problemas. En tales casos, las pruebas de tee deben considerarse, más bien,
herramientas de depuración , en lugar de
verificación .
Anteriormente, tales tipos de depuración eran relativamente raros en
imgix , pero todavía se usaban, especialmente cuando se trataba de problemas con las aplicaciones de depuración que son sensibles al retraso.
Por ejemplo, la siguiente es una descripción analítica de uno de estos incidentes que ocurrieron en 2015. El error 400 ocurrió tan raramente que casi no se vio al intentar reproducir el problema. Ella apareció en unos pocos casos de un billón. Había muy pocos durante el día. Como resultado, resultó que era simplemente imposible reproducir de manera confiable el problema, por lo que era necesario realizar una depuración utilizando el tráfico de trabajo para tener la oportunidad de rastrear la ocurrencia de este error. Esto es lo que mi antiguo colega escribió sobre esto:
“Elegí una biblioteca que se suponía que era interna, pero finalmente tuve que crear la mía basada en la biblioteca proporcionada por el sistema. En la versión proporcionada por el sistema, se produjo un error periódicamente que no apareció de ninguna manera mientras la cantidad de tráfico era pequeña. Sin embargo, el nombre truncado en el título fue el verdadero problema.
Durante los siguientes dos días, estudié en detalle el problema asociado con la mayor frecuencia de errores falsos 400. El error se manifestó en un número muy pequeño de solicitudes, y los problemas de este tipo son difíciles de diagnosticar. Todo esto parecía la aguja notoria en un pajar: el problema se encontró en un caso por mil millones.
El primer paso para localizar el origen de los errores fue obtener todos los datos de solicitud HTTP sin procesar que dieron como resultado una respuesta incorrecta. Para realizar una prueba en T del tráfico entrante cuando está conectado a un socket, agregué el punto final del socket de dominio Unix al servidor de renderizado. La idea era permitirnos activar y desactivar rápida y fácilmente el flujo de tráfico oscuro y realizar pruebas directamente en la computadora del desarrollador. Para evitar problemas en la producción, era necesario romper la conexión si había un problema de contrapresión. Es decir si el duplicado no pudo hacer frente a la tarea, se desconectó. Este socket fue muy útil en algunos casos durante el desarrollo. Esta vez, sin embargo, lo usamos para recopilar tráfico entrante en los servidores seleccionados, con la esperanza de obtener suficientes solicitudes para revelar el patrón que condujo a la aparición de errores falsos 400. Utilizando dsh y netcat, pude generar el tráfico entrante con relativa facilidad en un archivo local. .
La mayor parte del entorno se gastó recopilando estos datos. Tan pronto como tuvimos suficientes datos, pude usar netcat para reproducirlo en el sistema local, cuya configuración se modificó para mostrar una gran cantidad de información de depuración. Y todo salió a la perfección. El siguiente paso es reproducir los datos a la mayor velocidad posible. En este caso, el bucle con la verificación de condición envió las solicitudes sin procesar de una en una. Después de aproximadamente dos horas, logré lograr el resultado deseado. ¡Los datos en los registros mostraron la falta de un encabezado!
Utilizo madera roja y negra para transmitir los encabezados. Dichas estructuras consideran la comparabilidad como identidad, que en sí misma es muy útil cuando existen requisitos especiales para las claves: en nuestro caso, los encabezados HTTP no distinguen entre mayúsculas y minúsculas. Al principio pensamos que el problema estaba en el nodo hoja de la biblioteca utilizada. El orden de adición realmente afecta el orden de construcción del árbol base, y equilibrar el árbol rojo-negro es un proceso bastante complicado. Y aunque esta situación era poco probable, no era imposible. Me cambié a otra implementación de red-ebony. Se solucionó hace varios años, así que decidí incrustarlo directamente en la fuente para obtener exactamente la versión que se necesitaba. Sin embargo, el ensamblaje eligió una versión diferente, y como contaba con una nueva, al final tuve un comportamiento incorrecto.
Debido a esto, el sistema de visualización generó 500 errores, lo que condujo a la interrupción del ciclo. Es por eso que el error solo ocurrió con el tiempo. Después del procesamiento cíclico de varios ensamblajes, el tráfico de ellos se redirigió a una ruta diferente, lo que aumentó la escala del problema en este servidor. Mi suposición de que el problema estaba en la biblioteca resultó ser incorrecta, y el interruptor inverso resolvió 500 errores.
Regresé a 400 errores: todavía había un problema con el error, que tardó aproximadamente dos horas en detectarse. Cambiar la biblioteca, obviamente, no resolvió el problema, pero estaba seguro de que la biblioteca seleccionada era lo suficientemente confiable. Sin darme cuenta de la falacia de la elección, no cambié nada. Después de estudiar la situación con más detalle, me di cuenta de que el valor correcto estaba almacenado en un encabezado de un solo carácter (por ejemplo, "h: 12345"). Finalmente me di cuenta de que h era el carácter final del encabezado Content-Length. Al mirar los datos nuevamente, me di cuenta de que el encabezado Content-Length estaba vacío.
Como resultado, todo fue un error de sesgo de uno al leer los encabezados. El analizador HTTP nginx / joyent crea datos parciales, y cada vez que el campo de encabezado parcial resultó ser un carácter más corto de lo necesario, envié el encabezado sin un valor y posteriormente recibí un campo de encabezado de un carácter que contenía el valor correcto. Esta es una combinación bastante rara, por lo que su funcionamiento lleva mucho tiempo. Así que aumenté la cantidad de recopilación de datos cada vez que apareció un encabezado de un carácter, apliqué la solución propuesta y ejecuté el script con éxito durante varias horas.
Por supuesto, se pudieron detectar algunos otros problemas con el mal funcionamiento de la biblioteca mencionado, pero ambos errores fueron corregidos ".
Los ingenieros involucrados en el desarrollo de aplicaciones sensibles al retraso necesitan la capacidad de depurar usando tráfico dinámico capturado, porque a menudo ocurren errores que no pueden reproducirse durante la prueba de la unidad o detectarse usando una herramienta de monitoreo (especialmente si hay un retraso grave en el registro).
Enfoque de ingeniería del caos
Chaos Engineering es un enfoque basado en experimentos en un sistema distribuido para confirmar su capacidad de soportar las condiciones caóticas del entorno de producción.El método Chaos Engineering, que se hizo famoso por
Chaos Monkey de Netflix, ahora se ha convertido en una disciplina independiente. El término Ingeniería del Caos apareció recientemente, pero la prueba de fallas es una práctica de larga data.
El término "prueba caótica" se refiere a las siguientes técnicas:
- deshabilitar nodos arbitrarios para determinar qué tan resistente es el sistema al fracaso;
- introducir errores (por ejemplo, aumentar el retraso) para confirmar que el sistema los procesa correctamente;
- violación forzada de la red para determinar la respuesta del servicio.
La mayoría de las empresas utilizan un entorno operativo por niveles y poco complejo para realizar pruebas caóticas de manera efectiva. Es importante enfatizar que la introducción de fallas en el sistema se realiza mejor después de configurar las funciones básicas de tolerancia a fallas.
Este documento técnico de Gremlin proporciona una descripción bastante completa de los principios de pruebas caóticas, así como instrucciones para prepararse para este procedimiento.
“Especialmente importante es el hecho de que Chaos Engineering se considera una disciplina científica. Dentro de esta disciplina, se aplican procesos de ingeniería de alta precisión.
La tarea de Chaos Engineering es decirles a los usuarios algo nuevo sobre las vulnerabilidades del sistema mediante la realización de experimentos en él. Es necesario identificar todos los problemas ocultos que podrían surgir en la producción, incluso antes de que causen una falla masiva. Solo después de eso podrá eliminar de manera efectiva todas las debilidades del sistema y hacerlo verdaderamente tolerante a fallas ”.Conclusión
El propósito de las pruebas en producción no es
eliminar completamente todas las fallas posibles en el sistema.
John Allspaw dice:
“ Vemos que los sistemas son cada vez más tolerantes a fallas, y eso es genial. Pero debemos admitir: "más y más" no es igual a "absolutamente". En cualquier sistema complejo, una falla puede suceder (y sucederá) de la manera más impredecible ".
Las pruebas en producción a primera vista pueden parecer una tarea bastante complicada, que va mucho más allá de la competencia de la mayoría de las empresas de ingeniería. Y aunque dicha prueba
no es una tarea
fácil , asociada con algunos riesgos, si la sigue todas las reglas, ayudará a lograr la confiabilidad de los sistemas distribuidos complejos que se encuentran en todas partes en la actualidad.