En un artículo anterior, analizamos los patrones y las topologías utilizadas en RabbitMQ. En esta parte, recurriremos a Kafka y lo compararemos con RabbitMQ para obtener algunas ideas sobre sus diferencias. Debe tenerse en cuenta que las arquitecturas de aplicaciones orientadas a eventos se compararán en lugar de las canalizaciones de procesamiento de datos, aunque la línea entre estos dos conceptos será bastante borrosa en este caso. En general, esto es más un espectro que una separación clara. Nuestra comparación se centrará simplemente en la parte de este espectro relacionada con las aplicaciones basadas en eventos.

La primera diferencia que viene a la mente es que el reintento de mensajes y los mecanismos de repetición utilizados por RabbitMQ para trabajar con mensajes de letra muerta en Kafka no tienen sentido. En RabbitMQ, los mensajes son temporales, se transmiten y desaparecen. Por lo tanto, volver a agregarlos es un caso de uso absolutamente real. Y en Kafka, la revista ocupa un lugar central. Resolver problemas de entrega reenviando un mensaje a la cola no tiene sentido y solo daña el diario. Una de las ventajas es la distribución clara y garantizada de mensajes entre las particiones de la revista, los mensajes repetidos confunden un esquema bien organizado. En RabbitMQ, ya puede enviar mensajes a la cola con la que trabaja un destinatario, y en la plataforma Kafka hay un diario para todos los destinatarios. Las demoras en la entrega y los problemas con la entrega de mensajes no representan mucho daño para el funcionamiento de la revista, pero Kafka no contiene mecanismos de demora incorporados.
En la sección sobre esquemas de mensajería se discutirá cómo reenviar mensajes en la plataforma Kafka.
La segunda gran diferencia que afecta los posibles esquemas de mensajería es que RabbitMQ almacena mensajes mucho menos que Kafka. Cuando un mensaje ya se entregó al destinatario en RabbitMQ, se elimina sin dejar rastro de su existencia. En Kafka, cada mensaje se mantiene en un registro hasta que se borra. La frecuencia de la limpieza depende de la cantidad de datos disponibles, la cantidad de espacio en disco que planea asignar para ellos y los esquemas de mensajería que desea garantizar. Puede usar la ventana de tiempo en la que almacenamos los mensajes durante un período de tiempo determinado: los últimos días / semanas / meses.
De esta forma, Kafka permite al destinatario volver a ver o recuperar mensajes anteriores. Parece una tecnología para enviar mensajes, aunque no funciona exactamente igual que en RabbitMQ.
Si RabbitMQ mueve mensajes y proporciona elementos poderosos para crear esquemas de enrutamiento complejos, Kafka guarda el estado actual y anterior del sistema. Esta plataforma se puede utilizar como fuente de datos históricos confiables, ya que RabbitMQ no.
Ejemplo de esquema de mensajería en la plataforma Kafka
El ejemplo más simple de usar tanto RabbitMQ como Kafka es la difusión de información de acuerdo con el esquema "editor-suscriptor". Uno o más publicadores agregan mensajes al registro particionado, y estos mensajes son recibidos por el suscriptor de uno o más grupos de suscriptores.

Figura 1. Varios editores envían mensajes al registro particionado y varios grupos de destinatarios los reciben.
Si no entra en detalles sobre cómo el editor envía mensajes a las secciones necesarias de la revista, y cómo los grupos de destinatarios se coordinan entre sí, este esquema no difiere de la topología de fanout (intercambio bifurcado) que se utiliza en RabbitMQ.
En un artículo anterior, se discutieron todos los esquemas y topologías de mensajería RabbitMQ. Quizás en algún momento pensaste "No necesito todas estas dificultades, solo quiero enviar y recibir mensajes en la cola", y el hecho de que puedes rebobinar la revista a posiciones anteriores hablaba de las ventajas obvias de Kafka.
Para las personas que están acostumbradas a las características tradicionales de los sistemas de colas, el hecho de la posibilidad de retroceder el reloj y rebobinar el registro de eventos en el pasado es sorprendente. Esta propiedad (disponible mediante el uso del registro en lugar de la cola) es muy útil para recuperarse de fallas. Yo (el autor del artículo en inglés) comencé a trabajar para mi cliente actual hace 4 años como gerente técnico del grupo de soporte del sistema del servidor. Teníamos más de 50 aplicaciones que recibían información en tiempo real sobre eventos comerciales a través de MSMQ, y lo habitual era que cuando se producía un error en la aplicación, el sistema lo detectaba solo al día siguiente. Desafortunadamente, a menudo los mensajes desaparecieron como resultado, pero usualmente pudimos obtener los datos iniciales de un sistema de terceros y reenviar mensajes solo al "suscriptor" que tenía el problema. Esto nos obligó a crear una infraestructura de mensajería para los destinatarios. Y si tuviéramos la plataforma Kafka, no sería más difícil hacer ese trabajo que cambiar el enlace a la ubicación del último mensaje recibido para la aplicación en la que ocurrió el error.
Integración de datos en aplicaciones y sistemas orientados a eventos
Este esquema es, en muchos sentidos, un medio para generar eventos, aunque no está relacionado con una sola aplicación. Hay dos niveles de generación de eventos: software y sistema. El presente esquema está asociado con este último.
Generación de eventos a nivel de programa
La aplicación gestiona su propio estado a través de una secuencia inmutable de eventos de cambio que se almacenan en el almacén de eventos. Para obtener el estado actual de la aplicación, debe jugar o combinar sus eventos en la secuencia correcta. Por lo general, en dicho modelo, el modelo CQRS Kafka se puede usar como este sistema.
Interacción entre aplicaciones a nivel de sistema.
Las aplicaciones o servicios pueden administrar su estado de cualquier manera que su desarrollador quiera administrar, por ejemplo, en una base de datos relacional regular.
Pero las aplicaciones a menudo necesitan datos unos de otros, esto conduce a arquitecturas subóptimas, por ejemplo, bases de datos comunes, desenfoque de los límites de la entidad o API REST inconvenientes.
Yo (el autor del artículo en inglés) escuché el podcast " Software Engineering Daily ", que describe un escenario orientado a eventos para los perfiles de servicio en las redes sociales. Hay una serie de servicios relacionados en el sistema, como la búsqueda, un sistema de gráficos sociales, un motor de recomendaciones, etc., todos ellos necesitan saber acerca de un cambio en el estado de un perfil de usuario. Cuando yo (el autor del artículo en inglés) trabajé como arquitecto de la arquitectura para un sistema relacionado con el transporte aéreo, teníamos dos grandes sistemas de software con una miríada de pequeños servicios relacionados. Los servicios de soporte requerían datos de pedidos y vuelos. Cada vez que se creaba o cambiaba un pedido, cuando un vuelo se retrasaba o cancelaba, estos servicios tenían que activarse.
Se requería una técnica para generar eventos. Pero primero, veamos algunos problemas comunes que surgen en los grandes sistemas de software, y veamos cómo la generación de eventos puede resolverlos.
Un gran sistema corporativo integrado generalmente se desarrolla orgánicamente; Se realizan migraciones a nuevas tecnologías y nuevas arquitecturas, que pueden no afectar al 100% del sistema. Los datos se distribuyen a diferentes partes de la institución, las aplicaciones divulgan bases de datos para uso público de modo que la integración se produce lo más rápido posible, y nadie puede predecir con certeza cómo interactuarán todos los elementos del sistema.
Distribución aleatoria de datos
Los datos se distribuyen en diferentes lugares y se administran en diferentes lugares, por lo que es difícil de entender:
- cómo se mueven los datos en los procesos comerciales;
- cómo los cambios en una parte del sistema pueden afectar a otras partes;
- qué hacer con los conflictos de datos que surgen debido al hecho de que hay muchas copias de datos que se propagan lentamente.
Si no hay límites claros de las entidades de dominio, los cambios serán costosos y riesgosos, ya que afectan a muchos sistemas a la vez.
Base de datos distribuida centralizada
Una base de datos abierta públicamente puede causar varios problemas:
- No está lo suficientemente optimizado para cada aplicación por separado. Lo más probable es que esta base de datos contenga un conjunto de datos excesivamente completo para la aplicación, además, está normalizada de tal manera que las aplicaciones tendrán que ejecutar consultas muy complejas para recibirlas.
- Usando una base de datos común, las aplicaciones pueden afectar el trabajo de los demás.
- Los cambios en la estructura lógica de la base de datos requieren coordinación a gran escala y trabajo en la migración de datos, y el desarrollo de servicios individuales se detendrá durante todo este proceso.
- Nadie quiere cambiar la estructura de almacenamiento. Los cambios que todos esperan son demasiado dolorosos.
Usando la inconveniente API REST
Obtener datos de otros sistemas a través de la API REST, por un lado, agrega conveniencia y aislamiento, pero aún así no siempre es exitoso. Cada interfaz de este tipo puede tener su propio estilo especial y sus propias convenciones. Obtener los datos necesarios puede requerir muchas solicitudes HTTP y ser bastante complicado.
Nos estamos moviendo cada vez más hacia la céntrica API, y tales arquitecturas brindan muchas ventajas, especialmente cuando los servicios están fuera de nuestro control. Hay tantas maneras convenientes de crear una API en este momento que no tenemos que escribir tanto código como necesitábamos antes. Sin embargo, esta no es la única herramienta disponible, y existen alternativas para la arquitectura interna del sistema.
Kafka como repositorio de eventos
Damos un ejemplo. Hay un sistema que gestiona las reservas en una base de datos relacional. El sistema utiliza todas las garantías de atomicidad, consistencia, aislamiento y durabilidad que ofrece la base de datos para administrar sus características de manera efectiva y todos están contentos. La división de la responsabilidad en equipos y solicitudes, la generación de eventos, los microservicios están ausentes, en general, un monolito tradicionalmente construido. Pero hay una gran cantidad de servicios de soporte (posiblemente microservicios) relacionados con las reservas: notificaciones push, distribución de correo electrónico, sistema antifraude, programa de fidelización, facturación, sistema de cancelación, etc. La lista sigue y sigue. Todos estos servicios requieren detalles de reserva, y hay muchas maneras de obtenerlos. Estos servicios producen datos que pueden ser útiles para otras aplicaciones.

Figura 2. Diversos tipos de integración de datos.
Arquitectura alternativa basada en Kafka. Cada vez que realiza una nueva reserva o cambia una reserva anterior, el sistema envía datos completos sobre el estado actual de esta reserva a Kafka. Al consolidar el diario, puede acortar los mensajes para que solo quede información sobre el último estado de reserva. En este caso, el tamaño de la revista estará bajo control.
Figura 3. Integración de datos basada en Kafka como base para la generación de eventos.
Para todas las aplicaciones para las que esto es necesario, esta información es la fuente de la verdad y la única fuente de datos. De repente, nos estamos moviendo de una red integrada de dependencias y tecnologías para enviar y recibir datos a / desde los temas de Kafka.
Kafka como repositorio de eventos:
- Si no hay ningún problema con el espacio en disco, Kafka puede almacenar todo el historial de eventos, es decir, se puede implementar una nueva aplicación y descargar toda la información necesaria del diario. Los registros de eventos que reflejan completamente las características de los objetos se pueden comprimir compilando el registro, lo que hará que este enfoque esté más justificado para muchos escenarios.
- ¿Qué pasa si los eventos deben jugarse en el orden correcto? Mientras los registros de eventos se distribuyan correctamente, puede establecer el orden de su reproducción y aplicar filtros, herramientas de conversión, etc., para que la reproducción de datos siempre termine con la información necesaria. Dependiendo de la posibilidad de distribución de datos, es posible asegurar su procesamiento altamente paralelo en el orden correcto.
- Puede ser necesario un cambio de modelo de datos. Al crear una nueva función de filtro / transformación, puede ser necesario reproducir registros de todos los eventos o eventos durante la semana pasada.
Los mensajes pueden llegar a Kafka no solo desde aplicaciones de su organización que envían mensajes sobre todos los cambios en sus características (o los resultados de estos cambios) sino también desde servicios de terceros integrados con su sistema. Esto sucede de las siguientes maneras:
- Exportación periódica, transferencia, importación de datos recibidos de servicios de terceros y su descarga a Kafka.
- Descarga de datos de servicios de terceros en Kafka.
- Los datos de CSV y otros formatos cargados desde servicios de terceros se cargan a Kafka.
Volvamos a las preguntas que consideramos anteriormente. La arquitectura basada en Kafka simplifica la distribución de datos. Sabemos dónde está la fuente de la verdad, sabemos dónde están sus fuentes de datos y todas las aplicaciones de destino funcionan con copias derivadas de estos datos. Los datos van del remitente a los destinatarios. Los datos de origen pertenecen solo al remitente, pero otros son libres de trabajar con sus proyecciones. Pueden filtrar, transformar, complementarlos con datos de otras fuentes, guardarlos en sus propias bases de datos.
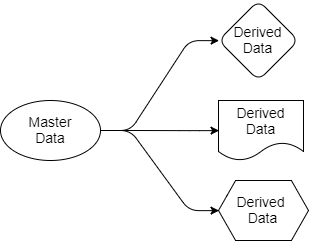
Fig. 4. Fuente y datos de salida.
Toda aplicación que necesite datos de reserva y de vuelo los recibirá por sí misma, ya que está "suscrita" a las secciones de Kafka que contienen estos datos. Para esta aplicación, pueden usar SQL, Cypher, JSON o cualquier otro lenguaje de consulta. Una aplicación puede guardar datos en su sistema como mejor le parezca. El esquema de distribución de datos se puede cambiar sin afectar el funcionamiento de otras aplicaciones.
Puede surgir la pregunta: ¿por qué no se puede hacer todo esto usando RabbitMQ? La respuesta es que RabbitMQ puede usarse para procesar eventos en tiempo real, pero no como base para generar eventos. RabbitMQ es una solución completa solo para responder a eventos que están sucediendo ahora. Cuando se agrega una nueva aplicación que necesita su propia parte de los datos de reserva presentados en un formato optimizado para las tareas de esta aplicación, RabbitMQ no podrá ayudar. Con RabbitMQ, volvemos a las bases de datos compartidas o la API REST.
En segundo lugar, el orden en que se procesan los eventos es importante. Si trabaja con RabbitMQ, cuando agrega un segundo destinatario a la cola, se pierde la garantía de cumplimiento del pedido. Por lo tanto, el orden correcto de envío de mensajes se observa solo para un destinatario, pero esto, por supuesto, no es suficiente.
Kafka, por el contrario, puede proporcionar todos los datos que esta aplicación necesita para crear su propia copia de los datos y mantenerlos actualizados, mientras que Kafka sigue el orden en que se envían los mensajes.
Ahora volvamos a las arquitecturas centradas en API. ¿Estas interfaces serán siempre la mejor opción? Cuando desee abrir el acceso de datos de solo lectura, preferiría una arquitectura de emisión de eventos. Evitará fallas en cascada y acortará la vida útil asociada con un aumento en el número de dependencias de otros servicios. Habrá más oportunidades para una organización de datos creativa y eficiente dentro de los sistemas. Pero a veces necesita cambiar los datos de forma sincronizada tanto en su sistema como en otro sistema, y en tal situación, los sistemas centrados en API serán útiles. Muchos los prefieren a otros métodos asincrónicos. Creo que esto es cuestión de gustos.
Aplicaciones sensibles de alto tráfico y procesamiento de eventos.
No hace mucho tiempo, surgió un problema con uno de los receptores de RabbitMQ, que recibió archivos en cola de un servicio de terceros. El tamaño total del archivo era grande y la aplicación se configuró específicamente para recibir ese volumen de datos. El problema fue que los datos llegaron de manera inconsistente, esto creó muchos problemas.
Además, a veces había un problema en el hecho de que a veces dos archivos estaban destinados al mismo destino, y su hora de llegada difería en varios segundos. Ambos pasaron por el procesamiento y tuvieron que cargarse en un servidor. Y después de que el segundo mensaje se grabó en el servidor, el primer mensaje que le sigue sobrescribe el segundo. Por lo tanto, todo terminó con el almacenamiento de datos no válidos. RabbitMQ cumplió su función y envió mensajes en el orden correcto, pero de todos modos, todo terminó en el orden incorrecto en la aplicación misma.
Este problema se resolvió leyendo la marca de tiempo de los registros existentes y la falta de respuesta si el mensaje era antiguo. Además, se aplicó hashing constante durante el intercambio de datos, y la cola se dividió, al igual que con la misma partición en la plataforma Kafka.
Como parte de la partición, Kafka almacena los mensajes en el orden en que fueron enviados. El orden del mensaje existe solo dentro de la partición. En el ejemplo anterior, usando Kafka, tuvimos que aplicar la función hash al id del destino para seleccionar la partición deseada. Tuvimos que crear un conjunto de particiones, debería haber más de las que requirió el cliente. El orden de procesamiento de mensajes debería haberse logrado debido al hecho de que cada partición está destinada a un solo destinatario. Simple y efectivo.
Kafka, en comparación con RabbitMQ, tiene algunas ventajas asociadas con la división de mensajes mediante hashing. No hay nada en la plataforma RabbitMQ que pueda evitar conflictos de destinatarios dentro de la misma cola que se genera como parte del intercambio de datos utilizando hashing consistente. RabbitMQ no ayuda a coordinar los destinatarios para que solo un destinatario de toda la cola use el mensaje. Kafka proporciona todo esto mediante el uso de grupos de destinatarios y un nodo coordinador. Esto le permite asegurarse de que solo un destinatario de la sección tenga garantizado el uso del mensaje y que el orden de procesamiento de datos esté garantizado.
Localidad de datos
Utilizando una función hash para distribuir datos entre particiones, Kafka proporciona la localidad de datos. Por ejemplo, los mensajes del usuario con ID 1001 siempre deben ir al destinatario 3. Dado que los eventos del usuario 1001 siempre van al destinatario 3, el destinatario 3 puede realizar efectivamente algunas operaciones que serían mucho más difíciles si fuera necesario recibir un acceso regular a una base de datos externa u otros sistemas datos Podemos leer datos, realizar agregaciones, etc. directamente con información en la memoria del destinatario. Este es el lugar donde las aplicaciones orientadas a eventos y la transmisión de datos comienzan a combinarse.
¿Cómo proporciona Kafka la localidad de datos? Para empezar, es importante tener en cuenta que Kafka no permite aumentar y disminuir elásticamente el número de particiones. En primer lugar, no puede reducir el número de particiones: si hay 10, no puede reducir el número a 9. Pero, por otro lado, esto no es obligatorio. Cada destinatario puede usar 1 o varias particiones, por lo tanto, apenas es necesario reducir su número. La creación de particiones adicionales en Kafka lleva a un retraso en el momento del reequilibrio, por lo que intentamos escalar el número de particiones teniendo en cuenta las cargas máximas.
Pero si aún necesitamos aumentar el número de particiones y destinatarios para escalar, solo necesitaremos costos indirectos únicos si es necesario reequilibrar. Cabe señalar que, al escalar, los datos antiguos permanecen en las mismas particiones donde estaban. Pero los nuevos mensajes entrantes ya se enrutarán de manera diferente, y las nuevas particiones comenzarán a recibir nuevos mensajes. Los mensajes del usuario 1001 ahora pueden ir al destinatario 4 (porque los datos sobre el usuario 1001 ahora están en dos secciones).
Además, compararemos y compararemos la semántica de entrega de los mensajes de entrega en ambos sistemas. El tema del reequilibrio y la partición merece un artículo separado, que discutiremos en la siguiente parte.