Hola a todos, mi nombre es Semyon Levenson, trabajo como líder de equipo en el proyecto Stream de Rambler Group y quiero hablar sobre nuestra experiencia con Apollo.
Explicaré qué es el "Stream". Este es un servicio automatizado para emprendedores, que le permite atraer clientes desde Internet a su negocio sin involucrarse en publicidad, y crear rápidamente sitios simples sin ser un experto en diseño.
La captura de pantalla muestra uno de los pasos para crear una página de destino.
¿Cuál fue el comienzo?
Y al principio había MVP, muchos Twig, jQuery y plazos muy ajustados. Pero seguimos un camino no estándar y decidimos hacer un rediseño. El rediseño no tiene el sentido de "estilos parcheados", pero decidió revisar completamente el sistema. Y esta fue una buena etapa para nosotros para armar la interfaz perfecta. Después de todo, nosotros, el equipo de desarrollo, deberíamos continuar apoyando esto e implementar otras tareas sobre la base de esto, para lograr nuevas metas establecidas por el equipo del producto.
Nuestro departamento ya ha acumulado suficiente experiencia en el uso de React. No quería pasar 2 semanas configurando el paquete web, así que decidí usar CRA (Crear aplicación de reacción). Para los estilos, se tomaron Componentes con estilo , y donde sin escribir, tomaron Flow . Tomaron Redux para la Gestión del Estado, pero como resultado resultó que no lo necesitamos en absoluto, pero más sobre eso más adelante.
Armamos nuestra interfaz perfecta y nos dimos cuenta de que nos habíamos olvidado de algo. Al final resultó que, nos olvidamos del backend, o más bien de la interacción con él. Cuando pensó en lo que podemos usar para organizar esta interacción, lo primero que se le ocurrió, por supuesto, es Descansar. No, no fuimos a descansar (sonríe), sino que comenzamos a hablar sobre la API RESTful. En principio, la historia es familiar, se extiende por mucho tiempo, pero también sabemos sobre los problemas con ella. Hablaremos de ellos.
El primer problema es la documentación. RESTful, por supuesto, no dice cómo organizar la documentación. Aquí hay una opción para usar el mismo swagger, pero de hecho es la introducción de una entidad adicional y la complicación de los procesos.
El segundo problema es cómo organizar el soporte para versionar la API.
El tercer problema importante es una gran cantidad de consultas o puntos finales personalizados que podemos recompensar. Supongamos que necesitamos solicitar publicaciones, para estas publicaciones: comentarios y más autores de estos comentarios. En el clásico Rest, tenemos que hacer al menos 3 consultas. Sí, podemos recompensar puntos finales personalizados, y todo esto se puede reducir a 1 solicitud, pero esto ya es una complicación.
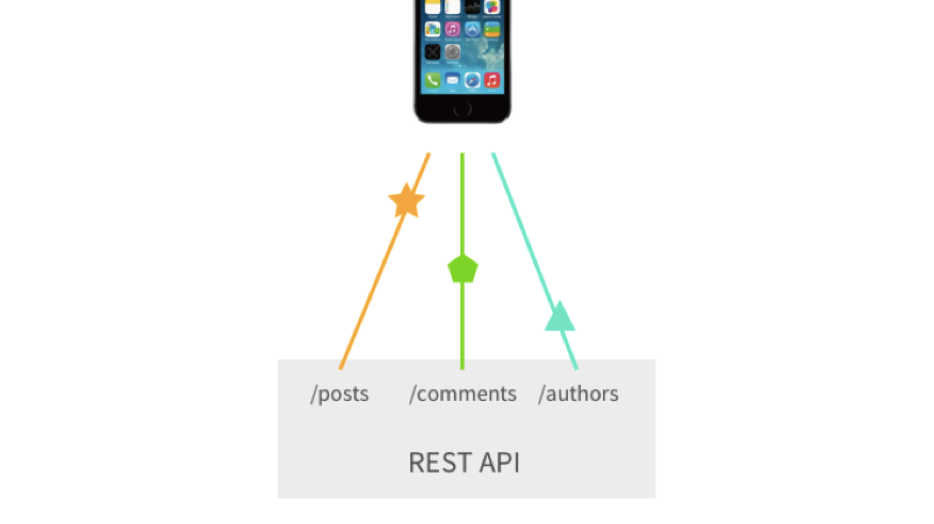
Gracias Sashko Stubailo por la ilustración .
Solución
Y en este momento, Facebook viene en nuestra ayuda con GraphQL. ¿Qué es GraphQL? Esta es una plataforma, pero hoy veremos una de sus partes: este es el lenguaje de consulta para su API, solo un idioma y bastante primitivo. Y funciona de la manera más simple posible: a medida que solicitamos algún tipo de entidad, también lo obtenemos.
Solicitud:
{ me { id isAcceptedFreeOffer balance } }
La respuesta es:
{ "me": { "id": 1, "isAcceptedFreeOffer": false, "balance": 100000 } }
Pero GraphQL no solo se trata de leer, también se trata de cambiar los datos. Para hacer esto, hay mutaciones en GraphQL. Las mutaciones son notables porque podemos declarar la respuesta deseada desde el backend, con un cambio exitoso. Sin embargo, hay algunos matices. Por ejemplo, si nuestra mutación afecta datos fuera de los límites del gráfico.
Un ejemplo de una mutación en la que utilizamos una oferta gratuita:
mutation { acceptOffer (_type: FREE) { id isAcceptedFreeOffer } }
En respuesta, obtenemos la misma estructura solicitada
{ "acceptOffer": { "id": 1, "isAcceptedFreeOffer": true } }
La interacción con el backend GraphQL se puede hacer usando fetch regular.
fetch('/graphql', { method: 'POST', headers: { 'Content-Type': 'application/json' }, body: JSON.stringify({ query: '{me { id balance } }' }) });
¿Cuáles son las ventajas de GraphQL?
La primera y muy buena ventaja que se puede apreciar cuando comienzas a trabajar con él es que este lenguaje está fuertemente tipado y autodocumentado. Al diseñar el esquema GraphQL en el servidor, podemos describir inmediatamente los tipos y atributos directamente en el código.

Como se mencionó anteriormente, RESTful tiene un problema de versiones. GraphQL implementó una solución muy elegante para esto: en desuso.
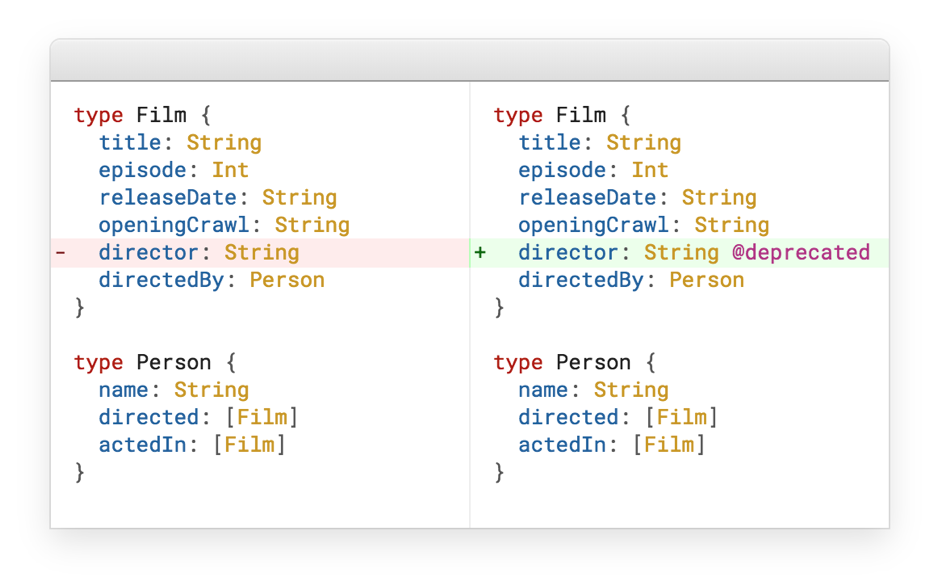
Supongamos que tenemos una película, la ampliamos y tenemos un director. Y en algún momento simplemente hacemos del director un tipo separado. La pregunta es, ¿qué hacer con el último campo de director? Hay dos respuestas: eliminamos este campo o lo marcamos como obsoleto y desaparece automáticamente de la documentación.
Decidimos independientemente lo que necesitamos.
Recordamos la imagen anterior, donde todo fue con REST, pero aquí todo se combina en una solicitud y no requiere ninguna personalización del desarrollo del backend. Una vez que todos lo describieron, y giramos, giramos, hacemos malabares.
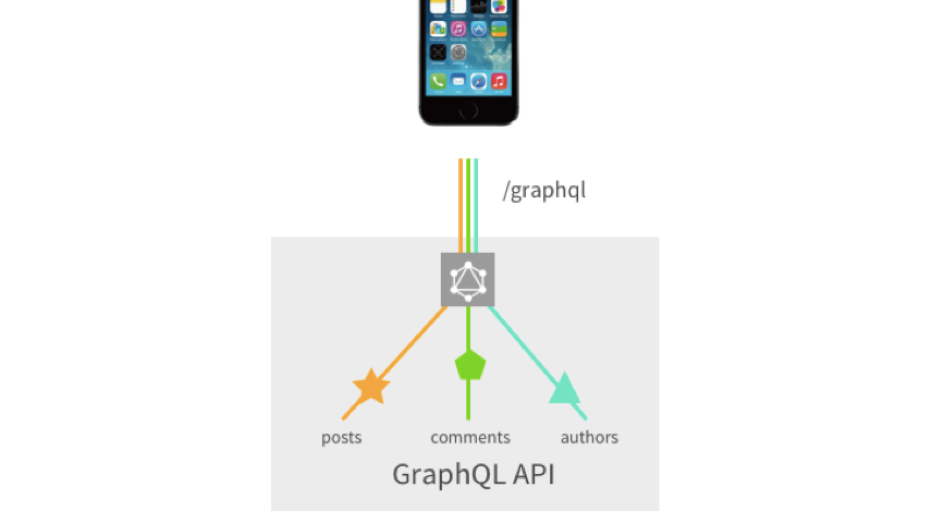
Pero no sin una mosca en la pomada. En principio, no hay tantos inconvenientes para GraphQL en la interfaz, porque se desarrolló originalmente para resolver problemas de interfaz. Pero el backend no funciona tan bien ... Tienen un problema como N + 1. Tome la consulta como ejemplo:
{ landings(_page: 0, limit: 20) { nodes { id title } totalCount } }
Una solicitud simple, solicitamos 20 sitios y la cantidad de sitios que tenemos. Y en el backend, esto puede convertirse en 21 consultas de bases de datos. Este problema es conocido, resuelto. Para Node JS hay un paquete de carga de datos de Facebook. Para otros idiomas, puede encontrar sus propias soluciones.
También existe el problema de la anidación profunda. Por ejemplo, tenemos álbumes, estos álbumes tienen canciones y, a través de la canción, también podemos obtener álbumes. Para hacer esto, realice las siguientes consultas:
{ album(id: 42) { songs { title artists } } }
{ song(id: 1337) { title album { title } } }
Por lo tanto, obtenemos una consulta recursiva, que también nos sirve de base.
query evil { album(id: 42) { songs { album { songs { album {
Este problema también es conocido, la solución para Node JS es el límite de profundidad de GraphQL, para otros idiomas también hay soluciones.
Por lo tanto, nos decidimos por GraphQL. Es hora de elegir una biblioteca que funcione con la API GraphQL. El ejemplo en un par de líneas con fetch, que se muestra arriba, es solo un transporte. Pero gracias al esquema y la capacidad de declaración, también podemos almacenar en caché las consultas en el frente y trabajar con un mayor rendimiento con el backend GraphQL.
Entonces tenemos dos jugadores principales: Relay y Apollo.
Relé
Relay es un desarrollo de Facebook, lo usan ellos mismos. Como Oculus, Circle CI, Arsti y Friday.
¿Cuáles son las ventajas de Relay?
La ventaja inmediata es que el desarrollador es Facebook. React, Flow y GraphQL son desarrollos de Facebook, todos los cuales son rompecabezas diseñados entre sí. Dónde estamos sin estrellas en Github, Relay tiene casi 11,000, Apollo tiene 7600 en comparación. Lo bueno que tiene Relay es Relay-compiler, una herramienta que optimiza y analiza sus consultas GraphQL en el nivel de construcción de su proyecto . Podemos suponer que esto es uglify solo para GraphQL:
# Relay-compiler foo { # type FooType id ... on FooType { # matches the parent type, so this is extraneous id } } # foo { id }
¿Cuáles son los contras de Relay?
El primer menos * es la falta de SSR fuera de la caja. Github todavía tiene un problema abierto. Por qué bajo el asterisco, porque ya hay soluciones, pero son de terceros y, además, bastante ambiguas.
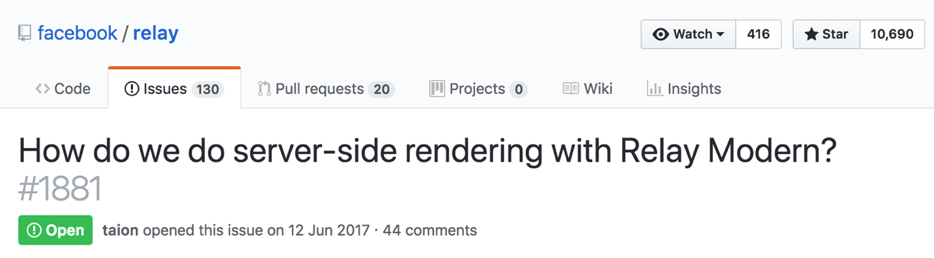
Nuevamente, Relay es una especificación. El hecho es que GraphQL ya es una especificación, y Relay es una especificación sobre una especificación.
Por ejemplo, la paginación de retransmisión se implementa de manera diferente, aquí aparecen los cursores.
{ friends(first: 10, after: "opaqueCursor") { edges { cursor node { id name } } pageInfo { hasNextPage } } }
Ya no usamos las compensaciones y límites habituales. Para los feeds en el feed, este es un gran tema, pero cuando comenzamos a hacer todo tipo de cuadrículas, entonces hay dolor.
Facebook resolvió su problema escribiendo una biblioteca para React. Hay soluciones para otras bibliotecas, para vue.js, por ejemplo, vue-relay . Pero si prestamos atención a la cantidad de estrellas y commits, entonces aquí también, no todo es tan suave y puede ser inestable. Por ejemplo, la aplicación Crear Reacción fuera del cuadro CRA le impide usar el compilador de retransmisión. Pero puede sortear esta limitación con react-app-rewired .
Apolo
Nuestro segundo candidato es Apolo . Desarrollado por su equipo Meteor . Apollo utiliza comandos tan conocidos como: AirBnB, ticketmaster, Opentable, etc.
¿Cuáles son las ventajas de Apollo?
La primera ventaja importante es que Apollo se desarrolló como una biblioteca agnóstica de framework. Por ejemplo, si ahora queremos reescribir todo en Angular, entonces esto no será un problema, Apollo trabaja con esto. E incluso puedes escribir todo en Vanilla.
Apollo tiene buena documentación, hay soluciones listas para problemas comunes.

Otra ventaja de Apollo: una potente API. En principio, aquellos que trabajaron con Redux encontrarán enfoques comunes aquí: hay ApolloProvider (como Provux para Redux), y en lugar de almacenar para Apollo, esto se llama cliente:
import { ApolloProvider } from 'react-apollo'; import { ApolloClient } from './ApolloClient'; const App = () => ( <ApolloProvider client={ApolloClient}> ... </ApolloProvider> );
A nivel del componente en sí, tenemos Graphql HOC proporcionado como conexión. Y escribimos la consulta GraphQL ya dentro, como MapStateToProps en Redux.
import { graphql } from 'react-apollo'; import gql from 'graphql-tag'; import { Landing } from './Landing'; graphql(gql` { landing(id: 1) { id title } } `)(Landing);
Pero cuando hacemos MapStateToProps en Redux, recogemos los datos locales. Si no hay datos locales, el propio Apollo va al servidor a buscarlos. Los accesorios muy convenientes caen en el componente mismo.
function Landing({ data, loading, error, refetch, ...other }) { ... }
Esto es:
• datos;
• estado de descarga;
• un error si ocurrió;
funciones auxiliares como refetch para recargar datos o fetchMore para paginar. También hay una gran ventaja tanto para Apollo como para Relay, que es la interfaz de usuario optimista. Le permite confirmar deshacer / rehacer en el nivel de solicitud:
this.props.setNotificationStatusMutation({ variables: { … }, optimisticResponse: { … } });
Por ejemplo, el usuario hizo clic en el botón "me gusta", y el "me gusta" contó inmediatamente. En este caso, se enviará una solicitud al servidor en segundo plano. Si se produce algún error durante el proceso de envío, los datos mutables volverán a su estado original por sí solos.
La representación del lado del servidor está bien implementada, configuramos un indicador en el cliente y todo está listo.
new ApolloClient({ ssrMode: true, ... });
Pero aquí me gustaría hablar sobre el estado inicial. Cuando Apolo lo cocina para sí mismo, todo funciona bien.
<script> window.__APOLLO_STATE__ = client.extract(); </script> const client = new ApolloClient({ cache: new InMemoryCache().restore(window.__APOLLO_STATE__), link });
Pero no tenemos renderizado del lado del servidor, y el backend empuja una consulta GraphQL específica a la variable global. Aquí necesita una pequeña muleta, debe escribir una función Transformar para que la respuesta GraphQL del backend ya se convierta en el formato necesario para Apollo.
<script> window.__APOLLO_STATE__ = transform({…}); </script> const client = new ApolloClient({ cache: new InMemoryCache().restore(window.__APOLLO_STATE__), link });
Otra ventaja de Apollo es que es muy personalizable. Todos recordamos el middleware de Redux, aquí todo es igual, solo que esto se llama enlace.

Me gustaría señalar por separado dos enlaces: apollo-link-state , que es necesario para almacenar el estado local en ausencia de Redux, y apollo-link-rest , si queremos escribir consultas GraphQL en la API Rest. Sin embargo, con este último debe ser extremadamente cuidadoso, porque Pueden surgir ciertos problemas.
Apolo también tiene contras
Veamos un ejemplo. Hubo un problema de rendimiento inesperado: se solicitaron 2.000 elementos en la interfaz (era un directorio) y comenzaron los problemas de rendimiento. Después de verlo en el depurador, resultó que Apollo consume muchos recursos mientras lee, el problema está básicamente cerrado, ahora todo está bien, pero hubo un pecado.
Además, la refetch resultó ser muy obvia ...
function Landing({ loading, refetch, ...other }) { ... }
Parece que cuando hacemos una nueva solicitud de datos, además, si la solicitud anterior terminó con un error, la carga debería ser verdadera. Pero no!
Para que esto suceda, debe especificar notifyOnNetworkStatusChange: true en el HOC graphql, o almacenar localmente el estado de recuperación.
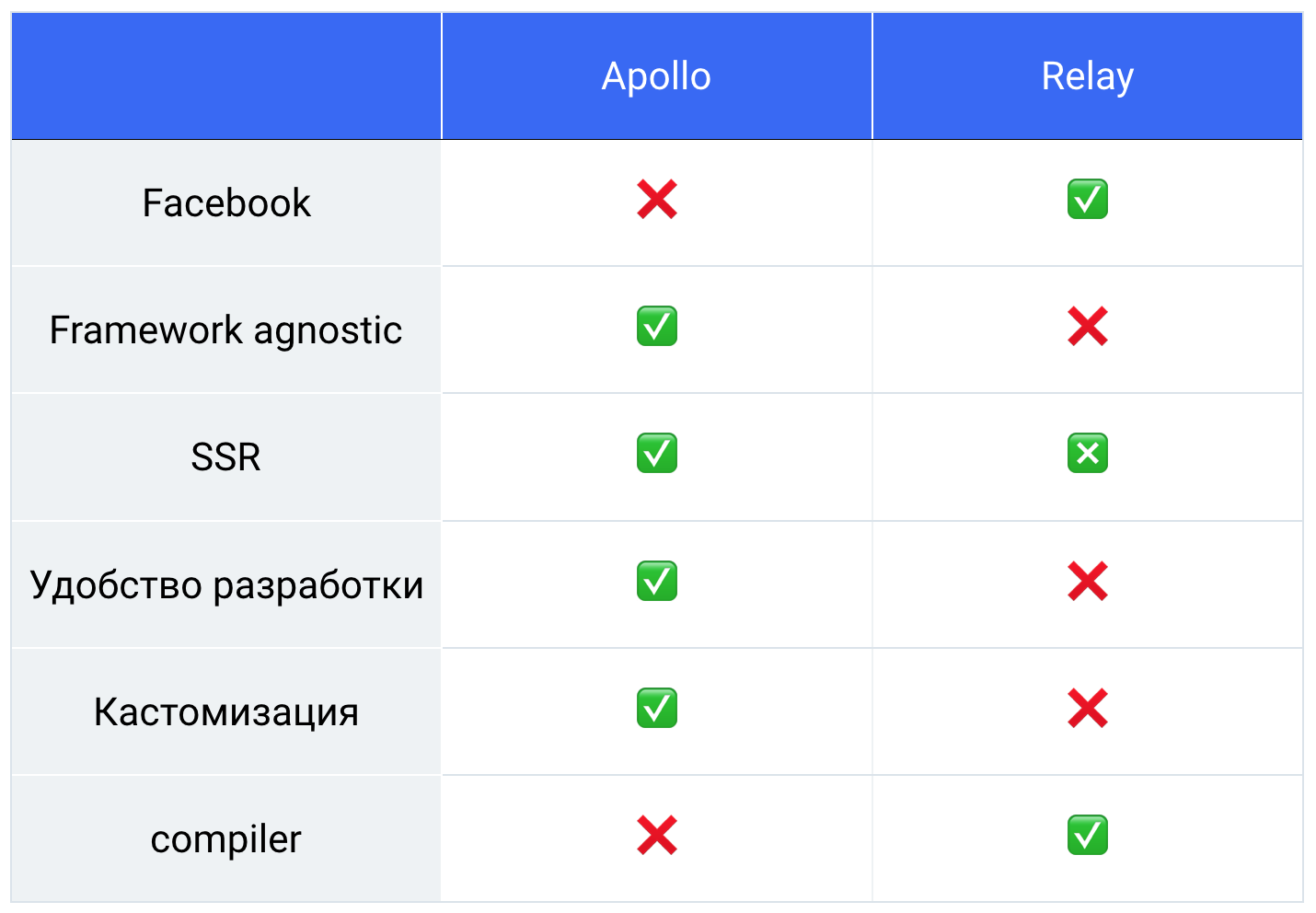
Apolo vs. Relé
Por lo tanto, obtuvimos dicha tabla, todos pesamos, contamos y teníamos un 76% detrás de Apolo.
Así que elegimos la biblioteca y nos pusimos a trabajar.
Pero me gustaría decir más sobre la cadena de herramientas.
Aquí todo es muy bueno, hay varios complementos para editores, en algún lugar mejor, en algún lugar peor. También hay apollo-codegen, que genera archivos útiles, por ejemplo, tipos de flujo, y básicamente extrae el esquema de la API GraphQL.
El título "Manos locas" o lo que hicimos en casa
Lo primero que encontramos fue que básicamente necesitamos solicitar datos de alguna manera.
graphql(BalanceQuery)(BalanceItem)
Tenemos condiciones comunes: carga, manejo de errores. Escribimos nuestro propio halcón (asyncCard), que está conectado a través de la composición de graqhql y asyncCard.
compose( graphql(BalanceQuery), AsyncCard )(BalanceItem)
También me gustaría hablar sobre fragmentos. Hay un componente LandingItem y sabe qué datos necesita de la API GraphQL. Establecemos la propiedad del fragmento, donde especificamos los campos de la entidad de aterrizaje.
const LandingItem = ({ content }: Props) => ( <LandingItemStyle> … </LandingItemStyle> ); LandingItem.fragment = gql` fragment LandingItem on Landing { ... } `;
Ahora, en el nivel de uso de componentes, usamos su fragmento en la solicitud final.
query LandingsDashboard { landings(...) { nodes { ...LandingItem } totalCount } ${LandingItem.Fragment} }
Y supongamos que una tarea vuela para agregar estado a esta página de destino, no es un problema. Agregamos una propiedad al render y al fragmento. Y todo está listo. Principio de responsabilidad única en todo su esplendor.
const LandingItem = ({ content }: Props) => ( <LandingItemStyle> … <LandingItemStatus … /> </LandingItemStyle> ); LandingItem.fragment = gql` fragment LandingItem on Landing { ... status } `;
¿Qué otro problema tuvimos?
Tenemos una serie de widgets en nuestro sitio que hicieron sus solicitudes individuales.
Durante las pruebas, resultó que todo esto se ralentiza. Tenemos controles de seguridad muy largos y cada solicitud es muy costosa. Esto también resultó no ser un problema, hay Apollo-link-batch-http
new BatchHttpLink({ batchMax: 10, batchInterval: 10 });
Se configura de la siguiente manera: pasamos el número de solicitudes que podemos combinar y cuánto tiempo esperará este enlace después de que aparezca la primera solicitud.
Y resultó así: al mismo tiempo, todo se está cargando, y al mismo tiempo todo llega. Vale la pena señalar que si durante esta fusión cualquiera de las subconsultas regresa con un error, entonces el error solo estará con él, y no con toda la solicitud.
Me gustaría decir por separado que el otoño pasado hubo una actualización del primer Apolo al segundo
Al principio era Apolo y Redux.
'react-apollo' 'redux'
Luego, Apollo se volvió más modular y expandible, estos módulos se pueden desarrollar de forma independiente. El mismo apollo-cache-inmemory.
'react-apollo' 'apollo-client' 'apollo-link-batch-http' 'apollo-cache-inmemory' 'graphql-tag'
Vale la pena señalar que Redux no lo es, y resultó que, en principio, no es necesario.
Conclusiones:
- El tiempo de entrega de funciones ha disminuido, no perdemos el tiempo describiendo acciones, reducimos en Redux y tocamos menos el backend
- La antifragilidad apareció porque El análisis estático de la API le permite anular los problemas cuando el frontend espera una cosa y el backend devuelve uno completamente diferente.
- Si comienza a trabajar con GraphQL, pruebe Apollo, no se decepcione.
PD: También puedes ver un video de mi presentación en Rambler Front & Meet up # 4