Python es asombroso. Decimos "instalación de pip" y muy probablemente se entregará la biblioteca necesaria. Pero a veces la respuesta será: "error de compilación", porque hay módulos binarios. Sufren algún tipo de dolor en casi todos los lenguajes modernos, porque hay muchas arquitecturas, algo debe ensamblarse para una máquina específica, algo debe vincularse con otras bibliotecas. En general, una pregunta interesante pero poco estudiada: ¿cómo se pueden hacer y qué problemas hay? Dmitry Zhiltsov (
zaabjuda ) intentó responder esta pregunta en MoscowPython Conf el año pasado.
Debajo del corte está la versión de texto del informe de Dmitry. Consideremos brevemente cuándo se necesitan módulos binarios y cuándo es mejor abandonarlos. Analicemos las reglas que deben seguirse al escribirlas. Considere cinco posibles opciones de implementación:
- Extensión nativa C / C ++
- Swig
- Cython
- Tipos
- Herrumbre
Sobre el orador : Dmitry Zhiltsov se ha desarrollado durante más de 10 años. Trabaja en CIAN como arquitecto de sistemas, es decir, es responsable de soluciones técnicas y control de tiempos. En mi vida logré probar ensamblador, Haskell, C, y durante los últimos 5 años he estado programando activamente en Python.
Acerca de la empresa
Muchos de los que viven en Moscú y alquilan viviendas probablemente conocen CIAN. CYAN es de 7 millones de compradores e inquilinos por mes. Todos estos usuarios cada mes, utilizando nuestro servicio, encuentran un lugar para vivir.
Alrededor del 75% de los moscovitas conocen nuestra empresa, y esto es muy bueno. En San Petersburgo y Moscú, somos prácticamente considerados monopolistas. En este momento, estamos tratando de ingresar a las regiones y, por lo tanto, el desarrollo ha crecido 8 veces en los últimos 3 años. Esto significa que el equipo aumentó 8 veces, la velocidad de entrega de valores al usuario aumentó 8 veces, es decir de una idea de producto a cómo la mano de un ingeniero desplegó una construcción a producción. Aprendimos en nuestro gran equipo a desarrollarnos muy rápidamente y a comprender muy rápidamente lo que está sucediendo en este momento, pero hoy hablaremos un poco sobre otra cosa.
Hablaré sobre módulos binarios. Ahora casi el 50% de las bibliotecas de Python tienen algún tipo de módulos binarios. Y resultó que muchas personas no están familiarizadas con ellos y creen que esto es algo trascendental, algo oscuro e innecesario. Y otras personas sugieren escribir mejor un microservicio separado y no usar módulos binarios.
El artículo constará de dos partes.
- Mi experiencia: por qué son necesarios, cuándo se usan mejor y cuándo no.
- Herramientas y tecnologías con las que puede implementar un módulo binario para Python.
¿Por qué se necesitan módulos binarios?
Todos sabemos perfectamente que Python es un lenguaje interpretado. Es casi el más rápido de los idiomas interpretados, pero, desafortunadamente, su
velocidad no siempre es suficiente para cálculos matemáticos pesados. Inmediatamente surge el pensamiento de que C será más rápido.
Pero Python tiene un dolor más: es
GIL . Se ha escrito una gran cantidad de artículos sobre él y se han realizado informes sobre cómo evitarlo.
También necesitamos extensiones binarias para
reutilizar la lógica . Por ejemplo, encontramos una biblioteca que tiene toda la funcionalidad que necesitamos y por qué no usarla. Es decir, no necesita volver a escribir el código, solo tomamos el código terminado y lo reutilizamos.
Mucha gente cree que al usar extensiones binarias puede
ocultar el código fuente . La pregunta es muy, muy controvertida, por supuesto, con la ayuda de algunas perversiones salvajes esto se puede lograr, pero no hay una garantía del 100%. Lo máximo que puede obtener es no dejar que el cliente se descompile y vea qué sucede en el código que pasó.
¿Cuándo se necesitan realmente las extensiones binarias?
Sobre la velocidad y Python está claro: cuando alguna función funciona muy lentamente y ocupa el 80% del tiempo de ejecución de todo el código, comenzamos a pensar en escribir una extensión binaria. Pero para tomar tales decisiones, debe comenzar, como dijo un famoso orador, pensar con el cerebro.
Para escribir extensiones de extensión, se debe tener en cuenta que esto, en primer lugar, será largo. Primero necesitas "lamer" tus algoritmos, es decir ver si hay jambas.
En el 90% de los casos, después de una verificación exhaustiva del algoritmo, la necesidad de escribir algunas extensiones desaparece.
El segundo caso donde realmente se necesitan extensiones binarias es el
uso de subprocesos múltiples para operaciones simples . Ahora, esto no es tan relevante, pero aún permanece en la empresa sangrienta, en algunos integradores de sistemas, donde Python 2.6 todavía está escrito. No hay asincronía, e incluso para cosas simples, por ejemplo, subir un montón de imágenes, aumenta el subprocesamiento múltiple. Parece que inicialmente esto no incurre en ningún gasto de red, pero cuando cargamos la imagen en el búfer, llega el malogrado GIL y comienzan algunos tipos de frenos. Como muestra la práctica, tales cosas se resuelven mejor usando bibliotecas de las que Python no sabe nada.
Si necesita implementar algún protocolo específico, puede ser conveniente crear un código C / C ++ simple y deshacerse de mucho dolor. Lo hice en mi tiempo en un operador de telecomunicaciones, ya que no había una biblioteca preparada, tuve que escribirla yo mismo. Pero repito, ahora esto no es muy relevante, porque hay asincio, y para la mayoría de las tareas es suficiente.
Sobre
operaciones obviamente
difíciles, ya dije de antemano. Cuando tiene bloqueos, matrices grandes y similares, tiene sentido que necesite hacer una extensión a C / C ++. Quiero señalar que algunas personas piensan que no necesitamos extensiones binarias aquí, es mejor hacer un microservicio en algún "
lenguaje súper rápido " y transferir matrices enormes a través de la red. No, es mejor no hacer eso.
Otro buen ejemplo cuando pueden e incluso deben tomarse es cuando tiene una
lógica establecida del módulo . Si tiene algún tipo de módulo Python en su empresa o si ya existe una biblioteca durante 3 años, hay cambios en ella una vez al año y luego 2 líneas, entonces ¿por qué no convertirla en una biblioteca C normal si hay recursos y tiempo libres? Como mínimo, obtenga un aumento en la productividad. Y también se entenderá que si se necesitan algunos cambios cardinales en la biblioteca, entonces esto no es tan simple y, tal vez, valga la pena pensar de nuevo con el cerebro y usar esta biblioteca de una manera diferente.
5 reglas de oro
Derivé estas reglas en mi práctica. Se refieren no solo a Python, sino también a otros lenguajes para los que puede usar extensiones binarias. Puedes discutir con ellos, pero también puedes pensar y traer los tuyos.
- Solo funciones de exportación . Crear clases en Python en bibliotecas binarias lleva bastante tiempo: debe describir muchas interfaces, debe revisar mucha integridad de referencia en el módulo en sí. Es más fácil escribir una pequeña interfaz para la función.
- Use clases de envoltura . Algunos son muy aficionados a la POO y realmente quieren clases. En cualquier caso, incluso si estas no son clases, es mejor simplemente escribir un contenedor Python: crear una clase, definir un método de clase o un método regular, llamar a funciones nativas de C / C ++. Como mínimo, esto ayuda a mantener la integridad de la arquitectura de datos. Si usa algún tipo de extensión de terceros C / C ++ que no puede arreglar, entonces en el contenedor puede hackearlo para que todo funcione.
- No puede pasar argumentos de Python a una extensión; esto ni siquiera es una regla, sino un requisito. En algunos casos, esto puede funcionar, pero generalmente es una mala idea. Por lo tanto, en su código, primero debe hacer un controlador que convierta el tipo de Python a tipo C. Y solo después de eso llame a cualquier función nativa que ya funcione con el tipo s. El mismo controlador recibe una respuesta de una función ejecutable y la transforma en tipos de datos Python, y la arroja en código Python.
- Tener en cuenta la recolección de basura . Python tiene un GC bien conocido, y no debes olvidarte de él. Por ejemplo, pasamos un gran texto por referencia e intentamos encontrar alguna palabra en la biblioteca. Queremos paralelizar esto, pasamos el enlace a esta área de memoria y al lanzamiento de varios hilos. En este momento, el GC simplemente toma y decide que nada más se refiere a este objeto y lo elimina del área de memoria. En el mismo código, solo obtenemos una referencia nula, y esto generalmente es un error de segmentación. No debemos olvidarnos de tal característica del recolector de basura y pasar los tipos de datos más simples a las bibliotecas de caracteres: char, integer, etc.
Por otro lado, el idioma en el que se escribe la extensión puede tener su propio recolector de basura. La combinación de Python y la biblioteca de C # es un dolor en este sentido.
- Defina explícitamente los argumentos de la función exportada . Con esto, quiero decir que estas funciones deberán ser anotadas cualitativamente. Si aceptamos la función PyObject, y en cualquier caso la aceptaremos en nuestra biblioteca, entonces necesitaremos indicar explícitamente qué argumentos pertenecen a qué tipos. Esto es útil porque si pasamos el tipo de datos incorrecto, obtendremos un error en la biblioteca. Es decir, lo necesita para su conveniencia.
Arquitectura de extensión binaria

En realidad, no hay nada complicado en la arquitectura de las extensiones binarias. Hay Python, hay una función de llamada que aterriza en un contenedor que llama de forma nativa al código. Esta llamada a su vez aterriza en una función que se exporta a Python y que puede llamar directamente. Es en esta función que necesita convertir los tipos de datos a los tipos de datos de su idioma. Y solo después de que esta función nos haya traducido todo, llamamos a la función nativa, que hace la lógica principal, devuelve el resultado en la dirección opuesta y lo arroja a Python, traduciendo los tipos de datos nuevamente.
Tecnologia y Herramientas
La forma más famosa de escribir extensiones binarias es la extensión Native C / C ++. Solo porque es la tecnología estándar de Python.
Extensión nativa C / C ++
Python se implementa en C, y los métodos y estructuras de python.h se usan para escribir extensiones. Por cierto, esto también es bueno porque es muy fácil implementarlo en un proyecto existente. Es suficiente especificar xt_modules en setup.py y decir que para compilar el proyecto necesita compilar tales fuentes con tales indicadores de compilación. A continuación se muestra un ejemplo.
name = 'DateTime.mxDateTime.mxDateTime' src = 'mxDateTime/mxDateTime.c' extra_compile_args=['-g3', '-o0', '-DDEBUG=2', '-UNDEBUG', '-std=c++11', '-Wall', '-Wextra'] setup ( ... ext_modules = [(name, { 'sources': [src], 'include_dirs': ['mxDateTime'] , extra_compile_args: extra_compile_args } )] )
Ventajas de la extensión nativa C / C ++
- Tecnología nativa
- Se integra fácilmente en el ensamblaje del proyecto.
- La mayor cantidad de documentación.
- Le permite crear sus propios tipos de datos.
Contras de la extensión nativa C / C ++
- Alto umbral de entrada.
- Se requiere conocimiento de C.
- Boost.Python.
- Falla de segmentación.
- Dificultades en la depuración.
Según esta tecnología, se escribe una gran cantidad de documentación, tanto en publicaciones estándar como en publicaciones de blog. Una gran ventaja es que podemos hacer nuestros propios tipos de datos de Python y construir nuestras clases.
Este enfoque tiene grandes desventajas. En primer lugar, es el umbral de entrada: no todos conocen C lo suficiente como para codificar la producción. Debe comprender que para esto no es suficiente leer el libro y ejecutarlo para escribir extensiones nativas. Si quieres hacer esto, entonces: primero, aprende C; luego comience a escribir utilidades de comando; solo después de eso proceda a escribir extensiones.
Boost.Python es muy bueno para C ++, le permite abstraer casi por completo de todos estos contenedores que usamos en Python. Pero el inconveniente, creo, es que debes sudar mucho para tomar parte e importarlo al proyecto sin descargar todo el Boost.
Al enumerar las dificultades en la depuración en las desventajas, quiero decir que ahora todos están acostumbrados a usar un depurador gráfico, y con los módulos binarios, tal cosa no funcionará. Lo más probable es que necesite instalar GDB con un complemento para Python.
Veamos un ejemplo de cómo creamos esto.
#include <Python.h> static PyObject*addList_add(Pyobject* self, Pyobject* args){ PyObject * listObj; if (! PyARg_Parsetuple( args, "", &listObj)) return NULL; long length = PyList_Size(listObj) int i, sum =0; // return Py_BuildValue("i", sum); }
Para comenzar, incluimos los archivos de encabezado de Python. Después de eso, describimos la función addList_add que usará Python. Lo más importante es nombrar la función correctamente, en este caso addList es el nombre del módulo, _add es el nombre de la función que se utilizará en Python. Pasamos el módulo PyObject y pasamos los argumentos usando PyObject también. Después de eso, realizamos verificaciones estándar. En este caso, estamos tratando de analizar el argumento de la tupla y decir que es un objeto; la "O" literal debe especificarse explícitamente. Después de eso, sabemos que pasamos listObj como un objeto, e intentamos averiguar su longitud utilizando métodos estándar de Python: PyList_Size. Tenga en cuenta que aquí todavía no podemos usar llamadas de llamada para averiguar la longitud de este vector, sino usar la funcionalidad de Python. Omitimos la implementación, después de lo cual es necesario devolver todos los valores a Python. Para hacer esto, llame a Py_BuildValue, especifique qué tipo de datos estamos devolviendo, en este caso "i" es un número entero y la variable suma en sí.
En este caso, todos entienden: encontramos la suma de todos los elementos de la lista. Vamos un poco más allá.
for(i = 0; i< length; i++){
Esto es lo mismo; por el momento, listObj es un objeto Python. Y en este caso, estamos tratando de tomar los elementos de la lista. Python.h tiene todo lo que necesitas para esto.
Después de que tenemos temperatura, tratamos de lanzarlo demasiado. Y solo después de eso puedes hacer algo en C.
Después de haber implementado toda la función, es necesario escribir documentación.
La documentación siempre es buena , y este kit de herramientas tiene todo para un mantenimiento conveniente. Después de la convención de nomenclatura, nombramos el módulo addList_docs y guardamos la descripción allí. Ahora necesita registrar el módulo, para esto hay una estructura especial PyMethodDef. Al describir las propiedades, decimos que la función se exporta a Python con el nombre "add", que esta función llama PyCFunction. METH_VARARGS significa que una función puede tomar cualquier cantidad de variables. También escribimos líneas adicionales y describimos una verificación estándar, en caso de que solo importáramos el módulo, pero no utilizáramos ningún método para que no se cayera.
Después de anunciar todo esto, intentamos hacer un módulo. Creamos un módulo de definición y ponemos todo lo que hemos hecho allí.
static struct PyModuleDef moduledef = { PyModuleDef_HEAD_INIT, "addList example module", -1, adList_funcs, NULL, NULL, NULL, NULL };
PyModuleDef_HEAD_INIT es una constante estándar de Python que siempre debe usar. -1 indica que no es necesario asignar memoria adicional en la etapa de importación.
Cuando creamos el módulo en sí, necesitamos inicializarlo. Python siempre está buscando init, así que cree una PyInit_addList para addList. Ahora desde la estructura ensamblada, puede llamar a PyModule_Create y finalmente crear el módulo en sí. A continuación, agregue la metainformación y devuelva el módulo en sí.
PyInit_addList(void){ PyObject *module = PyModule_Create(&mdef); If (module == NULL) return NULL; PyModule_AddStringConstant(module, "__author__", "Bruse Lee<brus@kf.ch>:"); PyModule_addStringConstant (Module, "__version__", "1.0.0"); return module; }
Como ya habrás notado, hay muchas cosas por transformar. Siempre debe recordar Python cuando escribimos en C / C ++.
Es por eso que, para facilitar la vida de un programador mortal común, hace unos 15 años, apareció la tecnología SWIG.
Swig
Esta herramienta le permite abstraer de enlaces de Python y escribir código nativo. Tiene los mismos pros y contras que Native C / C ++, pero hay excepciones.
SWIG Pros:
- Tecnología estable
- Una gran cantidad de documentación.
- Resúmenes de enlace a Python.
Contras de SWIG:
- Configuración larga
- Conocimiento C.
- Falla de segmentación.
- Dificultades en la depuración.
- La complejidad de la integración en el montaje del proyecto.
El primer inconveniente es que
mientras lo configura, perderá la razón . Cuando lo configuré por primera vez, pasé un día y medio incluso para lanzarlo. Entonces, por supuesto, es más fácil. SWIG 3.x se ha vuelto más fácil.
Para no entrar más en el código, considere el esquema general de SWIG.
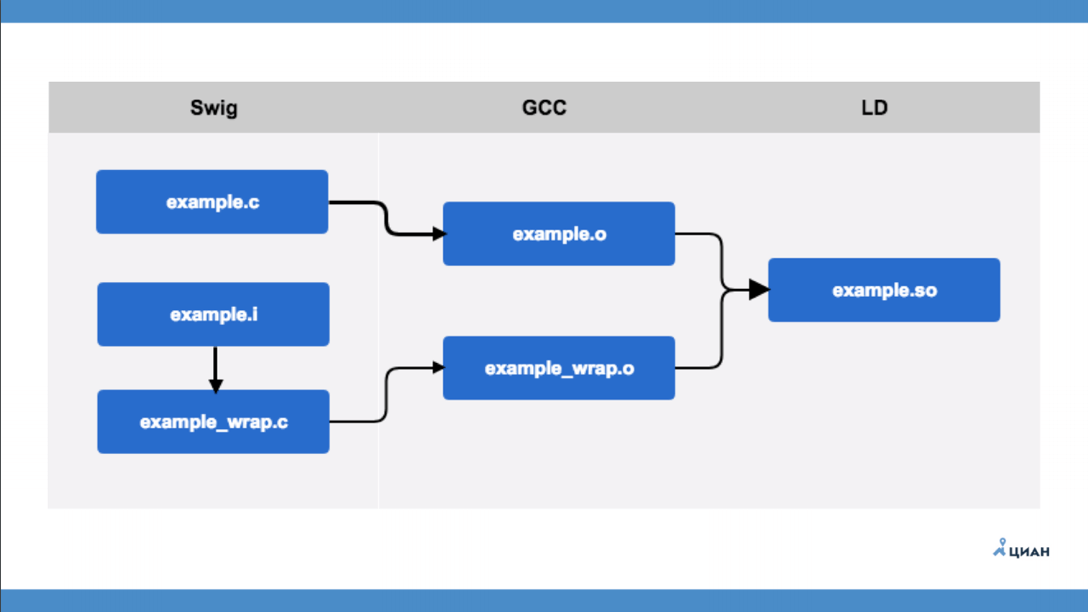
example.c es un módulo C que no sabe nada sobre Python. Hay un archivo de interfaz example.i, que se describe en el formato SWIG. Después de eso, ejecute la utilidad SWIG, que crea example_wrap.c desde el archivo de interfaz; este es el mismo contenedor que solíamos hacer con nuestras manos. Es decir, SWIG simplemente crea un contenedor de archivos para nosotros, el llamado puente. Después de eso, usando GCC, compilamos dos archivos y obtenemos dos archivos de objeto (example.o y example_wrap.o) y solo entonces creamos nuestra biblioteca. Todo es simple y claro.
Cython
Andrey Svetlov hizo un excelente
informe en MoscowPython Conf, así que solo diré que esta es una tecnología popular con buena documentación.
Cython Pros:
- Tecnología popular
- Bastante estable
- Se integra fácilmente en el ensamblaje del proyecto.
- Buena documentación
Contras de Cython:
- Sintaxis propia
- Conocimiento C.
- Falla de segmentación.
- Dificultades en la depuración.
Contras, como siempre, es. La principal es su propia sintaxis, que es similar a C / C ++, y muy similar a Python.
Pero quiero señalar que el código Python se puede acelerar usando Cython escribiendo código nativo.

Como puede ver, hay muchos decoradores, y esto no es muy bueno. Si desea utilizar Cython, consulte el informe de Andrei Svetlov.
CTypes
CTypes es la biblioteca estándar de Python que funciona con la interfaz de función externa. FFI es una biblioteca de bajo nivel. Esta es una tecnología nativa, se usa terriblemente a menudo en código, con su ayuda es fácil de implementar multiplataforma.
Pero FFI conlleva muchos gastos generales porque todos los puentes, todos los controladores en tiempo de ejecución se crean dinámicamente. Es decir, cargamos la biblioteca dinámica, y Python en este momento no sabe qué es la biblioteca. Solo cuando se llama a una biblioteca en la memoria, estos puentes se construyen dinámicamente.
Pros de CTypes:
- Tecnología nativa
- Fácil de usar en código.
- Fácil de implementar multiplataforma.
- Puedes usar casi cualquier idioma.
Contras CTypes:
- Lleva por encima.
- Dificultades en la depuración.
from ctypes import *
Tomaron adder.so y lo llamaron en tiempo de ejecución. Incluso podemos pasar los tipos nativos de Python.
Después de todo esto, la pregunta es: "¿De alguna manera es complicado, en todas partes C, qué hacer?".
Herrumbre
Hubo un tiempo en que no le presté la atención adecuada al idioma, pero ahora prácticamente recurro a él.
Pros de óxido:
- Lenguaje seguro
- Potentes garantías estáticas de comportamiento correcto.
- Se integra fácilmente en las compilaciones de proyectos ( PyO3 ).
Contras de óxido:
- Alto umbral de entrada.
- Configuración larga
- Dificultades en la depuración.
- Hay poca documentación.
- En algunos casos, gastos generales.
Rust es un lenguaje seguro con prueba automática de trabajo. La sintaxis en sí y el preprocesador del lenguaje en sí no permiten que se cometa un error explícito. Al mismo tiempo, se centra en la variabilidad, es decir, debe procesar cualquier resultado de la ejecución de la rama de código.
Gracias al equipo de PyO3, hay buenas carpetas de Python para Rust y herramientas para integrarse en el proyecto.
En el lado negativo, supongo que para un programador no preparado, lleva mucho tiempo configurarlo. Poca documentación, pero en lugar de contras, no tenemos una falla de segmentación. En Rust, en el buen sentido, en el 99% de los casos, un programador puede obtener una falla de segmentación solo si indica explícitamente desempaquetado y simplemente lo calificó.
Un pequeño ejemplo de código, el mismo módulo que examinamos antes.
#![feature(proc_macro)] #[macro_use] extern crate pyo3; Use pyo3::prelude::*;
El código tiene una sintaxis específica, pero te acostumbras muy rápidamente. De hecho, todo es igual aquí. Usando macros hacemos modinit, que para nosotros hace todo el trabajo adicional de generar todo tipo de aglutinantes para Python. Recuerda que dije, debes hacer un envoltorio de controlador, aquí es lo mismo. run_py convierte tipos, luego llamamos al código nativo.
Como puede ver, para exportar alguna función, hay azúcar sintáctico. Simplemente decimos que necesitamos la función add y no describimos ninguna interfaz. Aceptamos list, que es exactamente py_list, no Object, porque Rust en sí mismo configurará las carpetas necesarias en el momento de la compilación. Si pasamos el tipo de datos incorrecto, como en las extensiones de extensión, se producirá un TypeError. Después de obtener la lista, comenzamos a procesarla.
Veamos con más detalle lo que está empezando a hacer.
#[pyfn(m, "add", py_list="*")] fn add(_py: Python, py_list: &PyList) -> PyResult<i32> { match py_list.len() { 0 =>Err(EmptyListError::new("List is empty")), _ => { let mut sum : i32 = 0; for item in py_list.iter() { let temp:i32 = match item.extract() { Ok(v) => v, Err(_) => { let err_msg: String = format!("List item {} is not int", item); return Err(ItemListError::new(err_msg)) } }; sum += temp; } Ok(sum) } } }
El mismo código que estaba en C / C ++ / Ctypes, pero solo en Rust. Allí intenté lanzar PyObject a algún tipo de largo. ¿Qué pasaría si pudiéramos hacer una lista, a excepción de los números, obtendríamos una cadena? Sí, obtendríamos un SystemEerror. En este caso, a través de
let mut sum
: i32 = 0; También estamos tratando de obtener un valor de la lista y enviarlo a i32. Es decir, no podremos escribir este código sin item.extract (), inconscientemente y emitirlo al tipo deseado. Cuando escribimos i32, en el caso de un error Rust, en la etapa de compilación dirá: "Manejar el caso cuando no sea i32". En este caso, si tenemos i32, devolvemos un valor, si es un error, lanzamos una excepción.
Que elegir
Después de este breve recorrido, ¿qué elegir al final?
La respuesta realmente es a su gusto y color.
No promoveré ninguna tecnología específica.

Simplemente resuma lo que se dijo:
- En el caso de SWIG y C / C ++, debe conocer muy bien C / C ++, comprender que el desarrollo de este módulo generará una sobrecarga adicional. Pero se utilizará un mínimo de herramientas, y trabajaremos en la tecnología nativa de Python, que es compatible con los desarrolladores.
- En el caso de Cython, tenemos un pequeño umbral de entrada, tenemos una alta velocidad de desarrollo, y también este es un generador de código ordinario.
- A expensas de CTypes, quiero advertirle sobre la sobrecarga relativamente grande. La carga dinámica de bibliotecas, cuando no sabemos qué tipo de biblioteca es, puede generar muchos problemas.
- Aconsejaría a Rust que tome a alguien que no conozca bien C / C ++. El óxido en la producción realmente conlleva los menores problemas.
Llamada para papeles
Aceptamos aplicaciones para Moscow Python Conf ++ hasta el 7 de septiembre: escriba de esta forma simple que sepa sobre Python que realmente necesita compartir con la comunidad.
Para aquellos que están más interesados en escuchar, puedo hablar sobre informes geniales.
- A Donald Whyte le encanta hablar sobre acelerar las matemáticas en Python y está preparando una nueva historia para nosotros: cómo hacer que las matemáticas sean 10 veces más rápidas utilizando bibliotecas populares, trucos e insidiosidad, y el código es claro y compatible.
- ¡Artyom Malyshev ha reunido todos sus muchos años de experiencia en el desarrollo de Django y está presentando una guía de informes sobre el marco! Todo lo que sucede entre recibir una solicitud HTTP y enviar una página web terminada: exponer magia, un mapa de los mecanismos internos del marco y muchos consejos útiles para sus proyectos.