Si está familiarizado con C #, lo más probable es que sepa que siempre debe anular
Equals , así como
GetHashCode , para evitar la
GetHashCode rendimiento. Pero, ¿qué pasará si esto no se hace? Hoy, comparamos el rendimiento con dos opciones de ajuste y consideramos herramientas para ayudar a evitar errores.

¿Qué tan serio es este problema?
No todos los posibles problemas de rendimiento afectan el tiempo de ejecución de la aplicación. El método
Enum.HasFlag no
Enum.HasFlag muy eficiente (*), pero si no lo utiliza en un código de uso intensivo de recursos, no habrá problemas serios en el proyecto. Este también es el caso de
las copias protegidas creadas por tipos de estructura no solo de lectura en el contexto de solo lectura. El problema existe, pero es poco probable que se note en aplicaciones ordinarias.
(*) Se corrigió en .NET Core 2.1 y, como mencioné en una publicación anterior , ahora las consecuencias pueden mitigarse utilizando el HasFlag autoconfigurado para versiones anteriores.Pero el problema del que hablaremos hoy es especial. Si los métodos
Equals y
GetHashCode no se crean en la estructura,
System.ValueType sus versiones estándar de
System.ValueType . Y pueden reducir significativamente el rendimiento de la aplicación final.
¿Por qué las versiones estándar son lentas?
Los autores de CLR hicieron todo lo posible para que las versiones estándar de Equals y GetHashCode fueran lo más eficientes posible para los tipos de valor. Pero hay varias razones por las cuales estos métodos pierden en la efectividad de la versión del usuario, escrita para cierto tipo manualmente (o generada por el compilador).
1. Distribución de la conversión de envases. El CLR está diseñado de tal manera que cada llamada a un elemento definido en los tipos
System.ValueType o
System.Enum desencadena una transformación de
System.ValueType (**).
(**) Si el método no admite la compilación JIT. Por ejemplo, en Core CLR 2.1, el compilador JIT reconoce el método Enum.HasFlag y genera un código adecuado que no comienza a ajustarse.2. Posibles conflictos en la versión estándar del método
GetHashCode . Cuando implementamos una función hash, nos enfrentamos a un dilema: hacer que la distribución de la función hash sea buena o rápida. En algunos casos, puede hacer ambas cosas, pero en el tipo
ValueType.GetHashCode , esto suele ser difícil.
Una función hash tradicional de tipo struct "combina" los códigos hash de todos los campos. Pero la única forma de obtener el código hash de campo en el método
ValueType es usar la reflexión. Es por eso que los autores de CLR decidieron sacrificar la velocidad por el bien de la distribución, y la versión estándar de
GetHashCode solo devuelve el código hash del primer campo distinto de cero y lo
"estropea" con un identificador de tipo (***) (para más detalles, consulte
RegularGetValueTypeHashCode en coreclr repo en github).
(***) A juzgar por los comentarios en el repositorio de CoreCLR, la situación puede cambiar en el futuro. public readonly struct Location { public string Path { get; } public int Position { get; } public Location(string path, int position) => (Path, Position) = (path, position); } var hash1 = new Location(path: "", position: 42).GetHashCode(); var hash2 = new Location(path: "", position: 1).GetHashCode(); var hash3 = new Location(path: "1", position: 42).GetHashCode();
Este es un algoritmo razonable hasta que algo sale mal. Pero si no tiene suerte y el valor del primer campo de su tipo de estructura es el mismo en la mayoría de los casos, entonces la función hash siempre producirá el mismo resultado. Como habrás adivinado, si guardas estas instancias en un conjunto de hash o una tabla de hash, entonces el rendimiento caerá en picado.
3. La velocidad de implementación basada en la reflexión es baja. Muy bajo La reflexión es una herramienta poderosa si se usa correctamente. Pero las consecuencias serán terribles si lo ejecuta en un código de uso intensivo de recursos.
Veamos cómo una función hash fallida, que puede resultar de (2) y la implementación basada en la reflexión, afecta el rendimiento:
public readonly struct Location1 { public string Path { get; } public int Position { get; } public Location1(string path, int position) => (Path, Position) = (path, position); } public readonly struct Location2 {
Method | NumOfElements | Mean | Gen 0 | Allocated | -------------------------------- |------ |--------------:|--------:|----------:| Path_Position_DefaultEquality | 1 | 885.63 ns | 0.0286 | 92 B | Position_Path_DefaultEquality | 1 | 127.80 ns | 0.0050 | 16 B | Path_Position_OverridenEquality | 1 | 47.99 ns | - | 0 B | Path_Position_DefaultEquality | 10 | 6,214.02 ns | 0.2441 | 776 B | Position_Path_DefaultEquality | 10 | 130.04 ns | 0.0050 | 16 B | Path_Position_OverridenEquality | 10 | 47.67 ns | - | 0 B | Path_Position_DefaultEquality | 1000 | 589,014.52 ns | 23.4375 | 76025 B | Position_Path_DefaultEquality | 1000 | 133.74 ns | 0.0050 | 16 B | Path_Position_OverridenEquality | 1000 | 48.51 ns | - | 0 B |
Si el valor del primer campo es siempre el mismo, de manera predeterminada la función hash devuelve un valor igual para todos los elementos y el conjunto hash se convierte efectivamente en una lista vinculada con operaciones de inserción y búsqueda O (N). El número de operaciones para llenar la colección se convierte en O (N ^ 2) (donde N es el número de insertos con complejidad O (N) para cada inserto). Esto significa que insertar en un conjunto de 1000 elementos producirá casi 500,000 llamadas a
ValueType.Equals . ¡Aquí están las consecuencias de un método que usa la reflexión!
Como muestra la prueba, el rendimiento será aceptable si tiene suerte y el primer elemento de la estructura es único (en el caso de
Position_Path_DefaultEquality ). Pero si esto no es así, entonces la productividad será extremadamente baja.
Problema real
Creo que ahora puedes adivinar qué problema encontré recientemente. Hace un par de semanas recibí un mensaje de error: el tiempo de ejecución de la aplicación en la que estoy trabajando aumentó de 10 a 60 segundos. Afortunadamente, el informe fue muy detallado y contenía un rastro de eventos de Windows, por lo que el punto del problema se descubrió rápidamente:
ValueType.Equals cargó 50 segundos.
Después de un rápido vistazo al código, quedó claro cuál era el problema:
private readonly HashSet<(ErrorLocation, int)> _locationsWithHitCount; readonly struct ErrorLocation {
Usé una tupla que contenía un tipo de estructura personalizada con la versión estándar de
Equals . Y desafortunadamente, tenía un primer campo opcional, que casi siempre equivalía a
String.equals . La productividad se mantuvo alta hasta que el número de elementos en el conjunto aumentó significativamente. En cuestión de minutos, se inicializó una colección con decenas de miles de elementos.
¿La ValueType.Equals/GetHashCode predeterminada de ValueType.Equals/GetHashCode siempre se ejecuta lentamente?
Tanto
ValueType.Equals como
ValueType.GetHashCode tienen métodos de optimización especiales. Si el tipo no tiene "punteros" y está correctamente empaquetado (mostraré un ejemplo en un minuto), entonces se usan versiones optimizadas: las iteraciones
GetHashCode se realizan en bloques de instancias, se usa XOR de 4 bytes, el método
Equals compara dos instancias usando
memcmp .
La comprobación en sí se realiza en
ValueTypeHelper::CanCompareBits , se llama tanto por la iteración de
ValueType.Equals como por la iteración de
ValueType.GetHashCode .
Pero la optimización es una cosa muy insidiosa.
En primer lugar, es difícil de entender cuando está encendido; Incluso pequeños cambios en el código pueden activarlo y desactivarlo:
public struct Case1 {
Para obtener más información sobre la estructura de la memoria, consulte mi blog,
"Elementos internos de un objeto administrado, Parte 4. Estructura del campo" .
En segundo lugar, comparar la memoria no necesariamente te da el resultado correcto. Aquí hay un ejemplo simple:
public struct MyDouble { public double Value { get; } public MyDouble(double value) => Value = value; } double d1 = -0.0; double d2 = +0.0;
-0,0 y
+0,0 son iguales, pero tienen diferentes representaciones binarias. Esto significa que
Double.Equals es verdadero y
MyDouble.Equals es falso. En la mayoría de los casos, la diferencia no es significativa, pero imagine cuántas horas pasará solucionando el problema causado por esta diferencia.
¿Cómo evitar un problema similar?
¿Puedes preguntarme cómo puede suceder lo anterior en una situación real? Una forma obvia de ejecutar los métodos
Equals y
GetHashCode en los tipos de estructura es usar la
regla FxCop
CA1815 . Pero hay un problema: este es un enfoque demasiado estricto.
Una aplicación para la que el rendimiento es crítico puede tener cientos de tipos de estructura que no se usan necesariamente en conjuntos hash o diccionarios. Por lo tanto, los desarrolladores de aplicaciones pueden deshabilitar la regla, lo que causará consecuencias desagradables si el tipo de estructura utiliza funciones modificadas.
Un enfoque más correcto es advertir al desarrollador si la estructura de tipo "inapropiada" con los mismos valores predeterminados de elementos (definidos en la aplicación o una biblioteca de terceros) se almacena en un conjunto hash. Por supuesto, estoy hablando de
ErrorProne.NET y la regla que agregué allí tan pronto como me encontré con este problema:

La versión ErrorProne.NET no es perfecta y "culpará" al código correcto si se utiliza un solucionador de igualdad personalizado en el constructor:
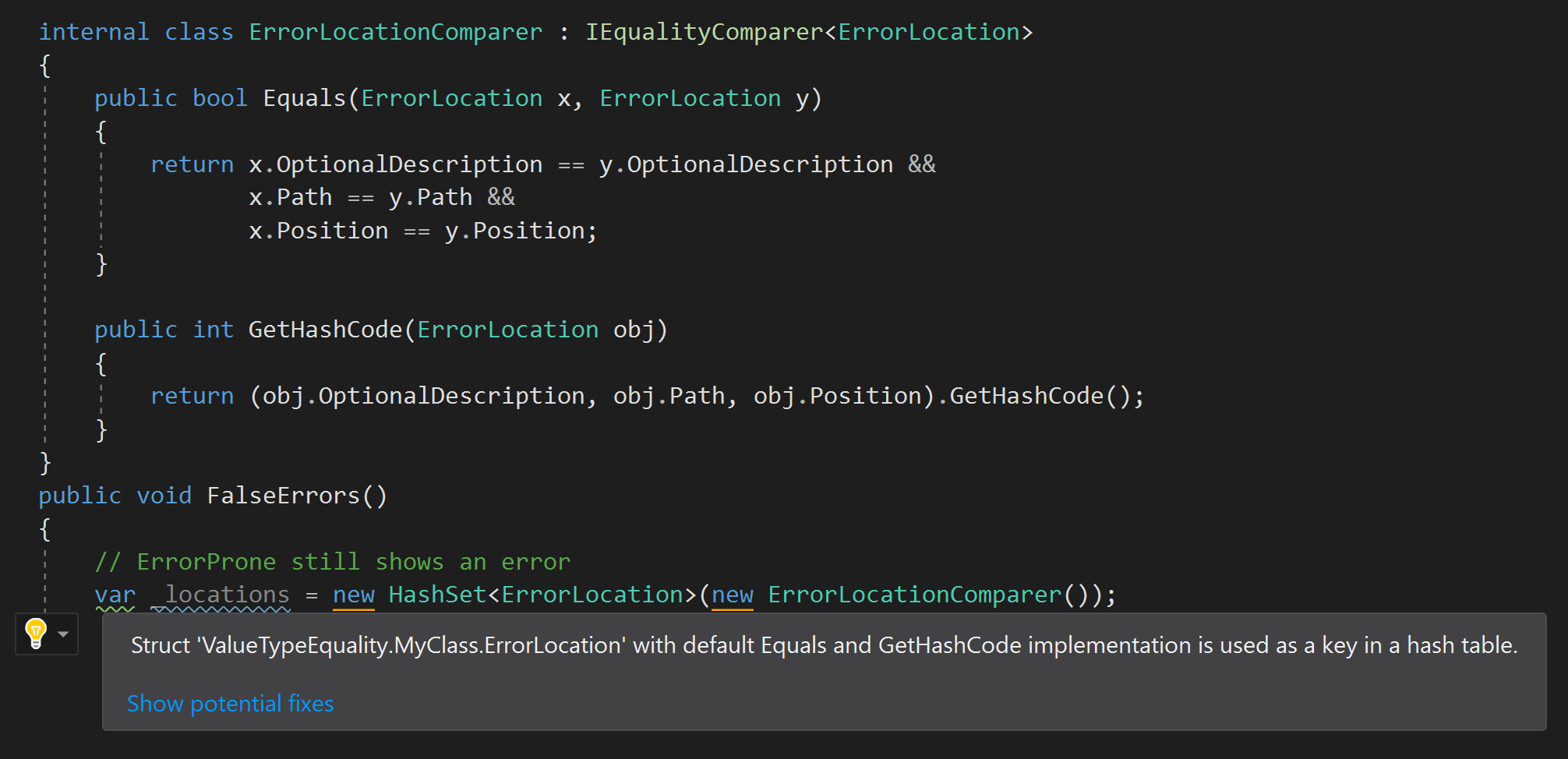
Pero sigo pensando que vale la pena advertir si una estructura con elementos iguales por defecto no se usa cuando se está produciendo. Por ejemplo, cuando revisé mi regla, me di cuenta de que la estructura
System.Collections.Generic.KeyValuePair <TKey, TValue> definida en mscorlib no sobrescribe
Equals y
GetHashCode . Es poco probable que alguien defina una variable como
HashSet <KeyValuePair<string, int>> hoy, pero creo que incluso BCL puede romper la regla. Por lo tanto, es útil descubrir esto antes de que sea demasiado tarde.
Conclusión
- La implementación de la igualdad predeterminada para los tipos de estructura puede tener serias consecuencias para su aplicación. Este es un problema real, no teórico.
- Los elementos de igualdad predeterminados para los tipos de valor se basan en la reflexión.
- La distribución realizada por la versión estándar de
GetHashCode será muy mala si el primer campo de muchas instancias tiene el mismo valor. - Existen versiones optimizadas para los métodos estándar
Equals y GetHashCode , pero no debe confiar en ellos porque incluso un pequeño cambio de código puede desactivarlos. - Use la regla FxCop para asegurarse de que cada tipo de estructura anula los elementos de igualdad. Sin embargo, es mejor evitar el problema con el analizador si la estructura "inapropiada" se almacena en un conjunto hash o en una tabla hash.
Recursos Adicionales