Hola Habr! Más recientemente, hablamos
brevemente sobre las interfaces de lenguaje natural. Bueno, hoy no tenemos brevemente. Debajo del corte, encontrará una historia completa sobre la creación de NL2API para la API web. Nuestros colegas de Research han intentado un enfoque único para recopilar datos de capacitación para el marco. Únete ahora!

Anotación
A medida que Internet evoluciona hacia una arquitectura orientada a servicios, las interfaces de software (API) son cada vez más importantes como una forma de proporcionar acceso a datos, servicios y dispositivos. Estamos trabajando en el tema de crear una interfaz de lenguaje natural para la API (NL2API), centrándonos en los servicios web. Las soluciones NL2API tienen muchos beneficios potenciales, por ejemplo, ayudan a simplificar la integración de servicios web en asistentes virtuales.
Ofrecemos la primera plataforma integral (marco) que le permite crear NL2API para una API web específica. La tarea clave es recopilar datos para el entrenamiento, es decir, los pares "comando NL - llamada API", lo que permite a NL2API estudiar la semántica de ambos comandos NL que no tienen un formato estrictamente definido y llamadas API formalizadas. Ofrecemos nuestro propio enfoque único para recopilar datos de capacitación para NL2API utilizando crowdsourcing, atrayendo a muchos trabajadores remotos para generar varios equipos de NL. Optimizamos el proceso de crowdsourcing para reducir costos.
En particular, ofrecemos un modelo probabilístico jerárquico fundamentalmente nuevo que nos ayudará a distribuir el presupuesto para el crowdsourcing, principalmente entre las llamadas API que son de alto valor para aprender NL2API. Aplicamos nuestro marco a API reales y mostramos que le permite recopilar datos de capacitación de alta calidad a un costo mínimo, así como crear NL2API de alto rendimiento desde cero. También demostramos que nuestro modelo de crowdsourcing mejora la eficiencia de este proceso, es decir, los datos de capacitación recopilados dentro de su marco proporcionan un mayor rendimiento de NL2API, que supera significativamente la línea de base.
Introduccion
Las interfaces de programación de aplicaciones (API) desempeñan un papel cada vez más importante tanto en el mundo virtual como en el físico, gracias al desarrollo de tecnologías como la arquitectura orientada a servicios (SOA), la computación en la nube y el Internet de las cosas (IoT). Por ejemplo, los servicios web alojados en la nube (clima, deportes, finanzas, etc.) a través de la API web proporcionan datos y servicios a los usuarios finales, y los dispositivos IoT permiten que otros dispositivos de red utilicen su funcionalidad.
 Figura 1. Los pares "comando NL (izquierda) y llamada API (derecha)" ensamblados
Figura 1. Los pares "comando NL (izquierda) y llamada API (derecha)" ensamblados
nuestro marco y comparación con IFTTT. GET-Messages y GET-Events son dos API web para encontrar correos electrónicos y eventos de calendario, respectivamente. Se puede llamar a API con varios parámetros. Nos centramos en llamadas API completamente parametrizadas, mientras que IFTTT se limita a API con parámetros simples.Por lo general, las API se utilizan en una variedad de software: aplicaciones de escritorio, sitios web y aplicaciones móviles. También sirven a los usuarios a través de una interfaz gráfica de usuario (GUI). La GUI ha hecho una gran contribución a la popularización de las computadoras, pero a medida que la tecnología informática ha evolucionado, sus muchas limitaciones se manifiestan cada vez más. Por un lado, a medida que los dispositivos se vuelven más pequeños, más móviles e inteligentes, los requisitos para la visualización gráfica en la pantalla aumentan constantemente, por ejemplo, con respecto a los dispositivos portátiles o dispositivos conectados a IoT.
Por otro lado, los usuarios tienen que adaptarse a varias GUI especializadas para diversos servicios y dispositivos. A medida que aumenta el número de servicios y dispositivos disponibles, también aumenta el costo de la capacitación y la adaptación del usuario. Las interfaces de lenguaje natural (NLI), como los asistentes virtuales Apple Siri y Microsoft Cortana, también llamadas interfaces conversacionales o de diálogo (CUI), demuestran un potencial significativo como una herramienta inteligente única para una amplia gama de servicios y dispositivos de servidor.
En este artículo, consideramos el problema de crear una interfaz de lenguaje natural para la API (NL2API). Pero, a diferencia de los asistentes virtuales, estos no son NLI de propósito general,
estamos desarrollando enfoques para crear NLI para API web específicas, es decir, API de servicios web como el servicio multideporte ESPN1. Tales NL2API pueden resolver el problema de escalabilidad de las NLI de propósito general al permitir el desarrollo distribuido. La utilidad de un asistente virtual depende en gran medida de la amplitud de sus capacidades, es decir, de la cantidad de servicios que admite.
Sin embargo, la integración de servicios web en un asistente virtual de uno en uno es un trabajo increíblemente laborioso. Si los proveedores de servicios web individuales tuvieran una forma económica de crear NLI para sus API, los costos de integración se reducirían significativamente. Un asistente virtual no tendría que procesar diferentes interfaces para diferentes servicios web. Sería suficiente para él simplemente integrar NL2API individuales, que logran uniformidad gracias al lenguaje natural. Por otro lado, NL2API también puede simplificar el descubrimiento de servicios web y sistemas de recomendación y asistencia de programación para API, eliminando la necesidad de recordar la gran cantidad de API web disponibles y su sintaxis.
Ejemplo 1. En la Figura 1 se muestran dos ejemplos. Se puede llamar a la API con varios parámetros. En el caso de la API de búsqueda de correo electrónico, los usuarios pueden filtrar el correo electrónico por propiedades específicas o buscar correos electrónicos por palabras clave. La tarea principal de NL2API es asignar comandos NL a las llamadas API correspondientes.
Desafío La recopilación de datos de capacitación es una de las tareas más importantes asociadas con la investigación en el desarrollo de interfaces NLI y su aplicación práctica. Las NLI utilizan datos de entrenamiento controlados, que en el caso de NL2API consisten en pares de "comando NL - llamada API" para estudiar la semántica y asignar inequívocamente comandos NL a las representaciones formalizadas correspondientes. El lenguaje natural es muy flexible, por lo que los usuarios pueden describir la llamada a la API de formas sintácticamente diferentes, es decir, se lleva a cabo la parafraseación.
Considere el segundo ejemplo en la Figura 1. Los usuarios pueden reformular esta pregunta de la siguiente manera: "¿Dónde se llevará a cabo la próxima reunión?" O "Encuentre un lugar para la próxima reunión". Por lo tanto, es extremadamente importante recopilar suficientes datos de capacitación para que el sistema reconozca aún más esas opciones. Las NLI existentes generalmente se adhieren al principio de "mejor posible" en la recopilación de datos. Por ejemplo, el análogo más cercano de nuestra metodología para comparar comandos NL con llamadas API utiliza el concepto de IF-This-Then-That (IFTTT) - "si es así, entonces" (Figura 1). Los datos de capacitación provienen directamente del sitio web de IFTTT.
Sin embargo, si la API no es compatible o no es totalmente compatible, no hay forma de solucionar la situación. Además, los datos de entrenamiento recopilados de esta manera no son aplicables para admitir comandos avanzados con varios parámetros. Por ejemplo, analizamos registros de llamadas anónimos de API de Microsoft para buscar correos electrónicos durante el mes y descubrimos que aproximadamente el 90% de ellos usan dos o tres parámetros (aproximadamente la misma cantidad), y estos parámetros son bastante diversos. Por lo tanto, nos esforzamos por proporcionar soporte completo para la parametrización de la API e implementar comandos avanzados de NL. El problema de implementar un proceso activo y personalizable de recopilación de datos de entrenamiento para una API específica actualmente sigue sin resolverse.
Los problemas del uso de NLI en combinación con otras representaciones formalizadas, como bases de datos relacionales, bases de conocimiento y tablas web, se han resuelto bastante bien, mientras que casi no se prestó atención al desarrollo de NLI para API web. Ofrecemos la primera plataforma integral (marco) que le permite crear NL2API para una API web específica desde cero. En la implementación de la API web, nuestro marco incluye tres etapas: (1) Presentación. El formato original de la API web HTTP contiene muchos detalles redundantes y, por lo tanto, que distraen desde el punto de vista de la NLI.
Sugerimos utilizar una representación semántica intermedia para la API web, para no sobrecargar el NLI con información innecesaria. (2) Un conjunto de datos de entrenamiento. Ofrecemos un nuevo enfoque para obtener datos de entrenamiento controlados basados en crowdsourcing. (3) NL2API. También ofrecemos dos modelos NL2API: un modelo de extracción basado en lenguaje y un modelo de red neuronal recurrente (Seq2Seq).
Uno de los resultados técnicos clave de este trabajo es un enfoque fundamentalmente nuevo para la recopilación activa de datos de capacitación para NL2API basada en crowdsourcing: utilizamos ejecutivos remotos para anotar llamadas de API al compararlas con comandos de NL. Esto le permite alcanzar tres objetivos de diseño al proporcionar: (1) Personalización. Debe poder especificar qué parámetros para qué API usar y cuántos datos de capacitación recopilar. (2) Bajo costo. Los servicios de los trabajadores de crowdsourcing son un orden de magnitud más barato que los servicios de especialistas especializados, por lo que deberían ser contratados. (3) de alta calidad. La calidad de los datos de entrenamiento no debe reducirse.
Al diseñar este enfoque, surgen dos problemas principales. Primero, las llamadas API con parametrización avanzada, como en la Figura 1, son incomprensibles para el usuario promedio, por lo que debe decidir cómo formular el problema de anotación para que los empleados de crowdsourcing puedan lidiar fácilmente con él. Comenzamos desarrollando una representación semántica intermedia para la API web (ver sección 2.2), que nos permite generar llamadas API sin problemas con los parámetros requeridos.
Luego, pensamos en la gramática para convertir automáticamente cada llamada de API en un comando NL canónico, que puede ser bastante engorroso, pero será claro para el empleado promedio de crowdsourcing (consulte la sección 3.1). Los artistas solo tendrán que reformular el equipo canónico para que suene más natural. Este enfoque le permite evitar muchos errores en la recopilación de datos de capacitación, ya que la tarea de reformulación es mucho más simple y más comprensible para el empleado promedio de crowdsourcing.
En segundo lugar, debe comprender cómo definir y anotar solo aquellas llamadas API que son de valor real para aprender NL2API. La "explosión combinatoria" que surge durante la parametrización conduce al hecho de que el número de llamadas incluso para una API puede ser bastante grande. No tiene sentido anotar todas las llamadas. Ofrecemos un modelo probabilístico jerárquico fundamentalmente nuevo para la implementación del proceso de crowdsourcing (ver sección 3.2). Por analogía con el modelado de lenguaje con el fin de obtener información, asumimos que los comandos NL se generan en función de las llamadas API correspondientes, por lo que el modelo de lenguaje debe usarse para cada llamada API para registrar este proceso "generativo".
Nuestro modelo se basa en la naturaleza compositiva de las llamadas API o representaciones formalizadas de la estructura semántica en su conjunto. En un nivel intuitivo, si una llamada API consiste en llamadas más simples (por ejemplo, "correos electrónicos no leídos sobre un candidato para el título de ciencias" = "correos electrónicos no leídos" + "correos electrónicos para un candidato a un título de ciencias", podemos construirlo modelo de idioma a partir de llamadas API simples, incluso sin anotaciones, por lo tanto, al anotar una pequeña cantidad de llamadas API, podemos calcular el modelo de idioma para todos los demás.
Por supuesto, los modelos de lenguaje calculados están lejos de ser ideales, de lo contrario ya habríamos resuelto el problema de crear NL2API. Sin embargo, tal extrapolación del modelo de lenguaje a llamadas API sin anotar nos da una visión holística de todo el espacio de llamadas API, así como la interacción del lenguaje natural y las llamadas API, lo que nos permite optimizar el proceso de crowdsourcing. En la Sección 3.3, describimos un algoritmo para anotar selectivamente las llamadas API para ayudar a que las llamadas API sean más distinguibles, es decir, para maximizar la discrepancia entre sus modelos de lenguaje.
Aplicamos nuestro marco a dos API implementadas desde el paquete Microsoft Graph API2. Demostramos que se pueden recopilar datos de capacitación de alta calidad a un costo mínimo si se utiliza el enfoque propuesto3. También mostramos que nuestro enfoque mejora el crowdsourcing. A costos similares, recopilamos mejores datos de capacitación, superando significativamente la línea de base. Como resultado, nuestras soluciones NL2API proporcionan una mayor precisión.
En general, nuestra contribución principal incluye tres aspectos:
- Fuimos uno de los primeros en estudiar los problemas de NL2API y propusimos un marco integral para crear NL2API desde cero.
- Propusimos un enfoque único para la recopilación de datos de capacitación utilizando crowdsourcing y un modelo probabilístico jerárquico fundamentalmente nuevo para optimizar este proceso.
- Aplicamos nuestro marco a API web reales y demostramos que se puede crear una solución NL2API suficientemente efectiva desde cero.
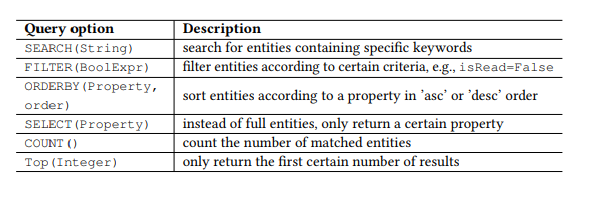 Tabla 1. Parámetros de consulta de OData.
Tabla 1. Parámetros de consulta de OData.Preámbulo
API RESTful
Recientemente, las API web que cumplen con el estilo arquitectónico REST, es decir, la API RESTful, se están volviendo cada vez más populares debido a su simplicidad. Las API RESTful también se usan en teléfonos inteligentes y dispositivos IoT. Las API Restful trabajan con recursos dirigidos a través de URI y proporcionan acceso a estos recursos para una amplia gama de clientes mediante comandos HTTP simples: GET, PUT, POST, etc. Trabajaremos principalmente con la API RESTful, pero se pueden utilizar los métodos básicos. y otras API.
Por ejemplo, tome el conocido Protocolo de datos abiertos (OData) para la API RESTful y dos API web del paquete API de Microsoft Graph (Figura 1), que, respectivamente, se utilizan para buscar correos electrónicos y eventos de calendario de usuario. Los recursos en OData son entidades, cada una de las cuales está asociada con una lista de propiedades. Por ejemplo, la entidad Mensaje (un correo electrónico) tiene propiedades como asunto (asunto), desde (desde), isRead (leer), recibidoDateTime (fecha y hora de recepción), etc.
Además, OData define un conjunto de parámetros de consulta, lo que le permite realizar manipulaciones avanzadas en los recursos. Por ejemplo, el parámetro FILTER le permite buscar correos electrónicos de un remitente específico o cartas recibidas en una fecha específica. Los parámetros de solicitud que utilizaremos se presentan en la Tabla 1. Llamamos a cada combinación del comando HTTP y la entidad (o conjunto de entidades) como una API, por ejemplo, GET-Messages, para buscar correos electrónicos. Cualquier solicitud parametrizada, por ejemplo, FILTER (isRead = False), se llama parámetro, y una llamada a la API es una API con una lista de parámetros.
NL2API
La tarea principal de NLI es comparar una declaración (un comando en un lenguaje natural) con una cierta representación formalizada, por ejemplo, formas lógicas o consultas SPARQL para bases de conocimiento o API web en nuestro caso. Cuando es necesario enfocarse en el mapeo semántico sin distraerse con detalles irrelevantes, generalmente se usa una representación semántica intermedia para no trabajar directamente con el objetivo. Por ejemplo, la gramática categórica combinatoria se usa ampliamente en la creación de NLI para bases de datos y bases de conocimiento. Un enfoque similar a la abstracción también es muy importante para NL2API. Muchos detalles, incluidas las convenciones de URL, los encabezados HTTP y los códigos de respuesta, pueden "distraer" al NL2API de resolver el problema principal: el mapeo semántico.
Por lo tanto, creamos una vista intermedia para las API RESTful (Figura 2) con el nombre de marco de API; esta vista refleja la semántica del marco. El marco API consta de cinco partes. HTTP Verb (HTTP Command) y Resource son los elementos básicos para una API RESTful. El tipo de retorno le permite crear API compuestas, es decir, combinar varias llamadas API para realizar una operación más compleja. Los parámetros obligatorios se utilizan con mayor frecuencia en las llamadas PUT o POST en la API, por ejemplo, la dirección, el encabezado y el cuerpo del mensaje son parámetros obligatorios para enviar correos electrónicos. Los parámetros opcionales a menudo están presentes en las llamadas GET en la API, ayudan a reducir la solicitud de información.
Si faltan los parámetros requeridos, serializamos el marco API, por ejemplo: GET-messages {FILTER (isRead = False), SEARCH ("PhD application"), COUNT ()}. Un marco API puede ser determinista y convertirse en una llamada API real. Durante el proceso de conversión, se agregarán los datos contextuales necesarios, incluida la identificación de usuario, la ubicación, la fecha y la hora. En el segundo ejemplo (Figura 1), el valor ahora en el parámetro FILTER será reemplazado por la fecha y hora de ejecución del comando correspondiente durante la conversión del marco API en una llamada API real. Además, los conceptos de un marco API y una llamada API se utilizarán indistintamente.
 Figura 2. El marco API. Arriba: equipo de lenguaje natural. En el medio: Frame API. Abajo: llamada API.
Figura 2. El marco API. Arriba: equipo de lenguaje natural. En el medio: Frame API. Abajo: llamada API.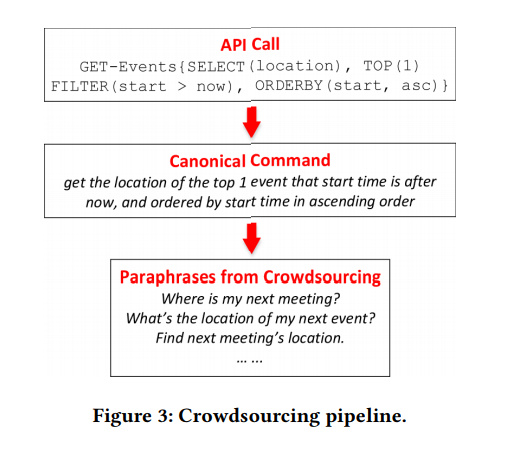 Figura 3. Transportador de crowdsourcing.
Figura 3. Transportador de crowdsourcing.NL2API . API , ( 3.1), ( 3). API, ( 3.2), ( 3.3).
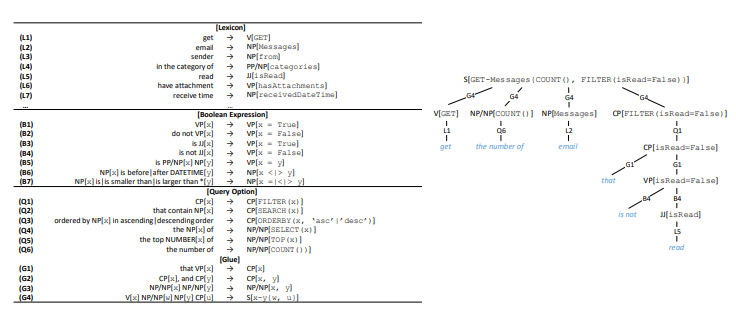 4. . : . : .
4. . : . : .API
API API. , , API, API . , Boolean, (True/False).
, Datetime, , today this_week receivedDateTime. , API (, ) API API.
, API . . , TOP, ORDERBY. , Boolean, isRead, ORDERBY . « » API API.
API. API . API API ( 4). ( HTTP, , ). , ⟨sender → NP[from]⟩ , from «sender», — (NP), .
(V), (VP), (JJ), - (CP), , (NP/NP), (PP/NP), (S) . .
, API , RESTful API OData — « » . 17 4 API, ( 5).
, API. ⟨t1, t2, ..., tn → c[z]⟩,
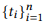
, z API, cz — . 4. API , S, G4, API . C , , - «that is not read».
, . , VP[x = False] B2, B4, x. x VP, B2 (, x is hasAttachments → «do not have attachment»); JJ, B4 (, x is isRead → «is not read»). («do not read» or «is not have attachment») .
Podemos generar una gran cantidad de llamadas API utilizando el enfoque anterior, pero anotar todas ellas mediante crowdsourcing no es económicamente factible. Por lo tanto, proponemos un modelo probabilístico jerárquico para crowdsourcing que lo ayude a decidir qué llamadas API se deben anotar. Hasta donde sabemos, este es el primer modelo probabilístico de usar crowdsourcing para crear interfaces NLI, lo que nos permite resolver la tarea única e intrigante de modelar la interacción entre representaciones de lenguaje natural y representaciones de estructura semántica formalizadas. Las representaciones formalizadas de la estructura semántica en general y las llamadas API en particular son de naturaleza compositiva. Por ejemplo, z12 = GET-Messages {COUNT (), FILTER (isRead = False)} consiste en z1 = GET-Messages {FILTER (isRead = False)} y z2 = GET-Messages {COUNT ()} (estos ejemplos son más detallados discutir más a fondo).
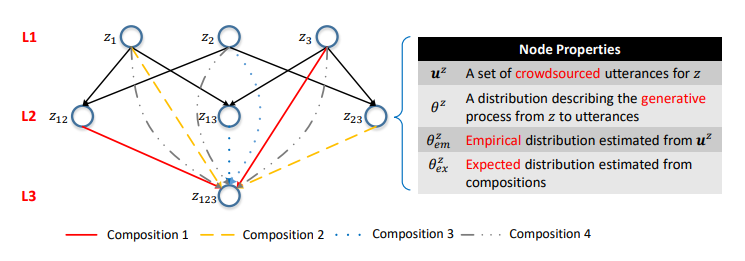 Figura 5. La red semántica. La capa i-ésima consiste en llamadas API con parámetros i. Las costillas son composiciones. Las distribuciones de probabilidad en los vértices caracterizan los modelos de lenguaje correspondientes.
Figura 5. La red semántica. La capa i-ésima consiste en llamadas API con parámetros i. Las costillas son composiciones. Las distribuciones de probabilidad en los vértices caracterizan los modelos de lenguaje correspondientes.Uno de los resultados clave de nuestro estudio fue la confirmación de que dicha composición se puede utilizar para modelar el proceso de crowdsourcing.
Primero, definimos la composición basada en un conjunto de parámetros de llamada API.
Definición 3.1 (composición). Tome una API y un conjunto de llamadas API
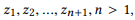
si definimos r (z) como un conjunto de parámetros para z, entonces
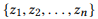
es una composición
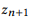
si y solo si
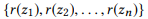
es parte
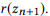
Según las relaciones de composición de las llamadas a la API, puede organizar todas las llamadas a la API en una sola estructura jerárquica. Las llamadas a la API con el mismo número de parámetros se representan como los vértices de una capa, y las composiciones se representan como
costillas dirigidas entre capas. Llamamos a esta estructura una red semántica (o SeMesh).
Por analogía con el enfoque basado en el modelado de lenguaje en la recuperación de información, asumimos que las declaraciones correspondientes a una llamada API z se generan utilizando un proceso estocástico caracterizado por un modelo de lenguaje
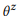
. Para simplificar, nos centramos en las probabilidades de las palabras, por lo tanto

donde
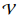
denota un diccionario.
Por razones que se harán aparentes un poco más tarde, en lugar del modelo estándar de unigrama de lenguaje, sugerimos usar un conjunto de distribuciones de Bernoulli (Bag of Bernoulli, BoB). Cada distribución de Bernoulli corresponde a una variable aleatoria W, que determina si la palabra w aparece en la oración generada en base a z, y la distribución BoB es un conjunto de distribuciones de Bernoulli para todas las palabras

. Usaremos
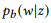
como una notación corta para
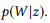
.
Supongamos que hemos formado un conjunto (múltiple) de declaraciones

para z
La estimación de máxima verosimilitud (MLE) para la distribución BoB le permite seleccionar sentencias que contienen w:
 Ejemplo 2.
Ejemplo 2. Con respecto a la llamada API z1 anterior, supongamos que tenemos dos declaraciones u1 = "buscar correos electrónicos no leídos" y u2 = "correos electrónicos que no se leen", luego u = {u1, u2}. pb ("correos electrónicos" | z) = 1.0, ya que "correos electrónicos" está presente en ambas declaraciones. Del mismo modo, pb ("no leído" | z) = 0.5 y pb ("reunión" | z) = 0.0.
En la red semántica, hay tres operaciones básicas a nivel de vértice:
Anotación, diseño e interpolación.
ANOTAR (anotar) significa recopilar declaraciones
parafrasear el comando canónico del vértice z usando crowdsourcing y evaluar la distribución empírica
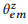
método de máxima verosimilitud.
COMPOSE (componer) intenta derivar un modelo de lenguaje basado en composiciones para calcular la distribución esperada
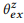
. Como mostramos experimentalmente,
Es una composición para z. Si procedemos del supuesto de que las declaraciones correspondientes se caracterizan por la misma conexión compositiva, entonces
debe presentarse en

:

donde f es una función compositiva. Para la distribución BoB, la función de composición se verá así:
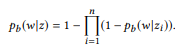
En otras palabras, si ui es una declaración zi, u es una declaración
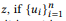
composicionalmente forma u, entonces la palabra w no te pertenece. Si y solo si no pertenece a ninguna interfaz de usuario. Cuando z tiene muchas composiciones, θe x se calcula por separado y luego se promedia. El modelo estándar de unigrama de lenguaje no conduce a una función compositiva natural. En el proceso de normalización de las probabilidades de palabras, la longitud de las oraciones está involucrada, lo que, a su vez, tiene en cuenta la complejidad de las llamadas API, violando la descomposición en la ecuación (2). Es por eso que ofrecemos distribución BoB.
Ejemplo 3. Supongamos que preparamos una anotación para las llamadas API mencionadas anteriormente z1 y z2, cada una de las cuales tiene dos declaraciones:
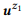
= {"Buscar correos electrónicos no leídos", "correos electrónicos que no se leen"} y
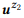
= {"¿Cuántos correos electrónicos tengo?", "Encuentra el número de correos electrónicos"}. Calificamos modelos de lenguaje
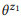
y
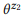
. La operación de composición está tratando de evaluar
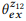
sin preguntar
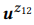
. Por ejemplo, para la palabra "correos electrónicos", pb ("correos electrónicos" | z1) = 1.0 y pb ("correos electrónicos" | z2) = 1.0, por lo que se deduce de la ecuación (3) que pb ("correos electrónicos" | z12) = 1.0, es decir, creemos que esta palabra se incluirá en cualquier declaración de z12. Del mismo modo, pb ("find" | z1) = 0.5 y pb ("find" | z2) = 0.5, entonces pb ("find" | z12) = 0.75. Una palabra tiene una buena probabilidad de ser generada a partir de cualquier z1 o z2, por lo que su probabilidad para z12 debería ser mayor.
Por supuesto, las declaraciones no siempre se combinan compositivamente. Por ejemplo, varios elementos en una representación formalizada de una estructura semántica se pueden transmitir en una sola palabra o frase en un lenguaje natural, este fenómeno se llama composicionalidad subléxica. Un ejemplo de este tipo se muestra en la Figura 3, donde los tres parámetros: TOP (1), FILTER (inicio> ahora) y ORDERBY (inicio, asc), están representados por la sola palabra "siguiente". Sin embargo, es imposible obtener dicha información sin anotar la llamada API, por lo que el problema en sí se parece al problema de los huevos y la gallina. En ausencia de dicha información, es razonable adherirse al supuesto predeterminado de que las declaraciones se caracterizan por la misma relación de composición que las llamadas API.
Esta es una suposición plausible. Vale la pena señalar que esta suposición se usa solo para modelar el proceso de crowdsourcing con el objetivo de recopilar datos. En la etapa de prueba, las declaraciones de usuarios reales pueden no corresponder a esta suposición. La interfaz de lenguaje natural podrá hacer frente a tales situaciones no compositivas si están cubiertas por los datos de capacitación recopilados.
INTERPOLATE (interpolación) combina toda la información disponible sobre z, es decir, declaraciones anotadas z e información obtenida de las composiciones, y obtiene una estimación más precisa
por interpolación
y
.
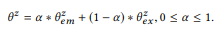
El parámetro de equilibrio α controla las compensaciones entre anotaciones
picos actuales que son precisos pero suficientes, y la información obtenida de las composiciones basadas en el supuesto de composición puede no ser tan precisa, pero proporciona una cobertura más amplia. En cierto sentido
tiene el mismo propósito que el suavizado en el modelado de lenguaje, lo que permite una mejor estimación de la distribución de probabilidad con datos insuficientes (anotaciones). Mas que
cuanto más peso en
. Para un vértice raíz que no tiene composición,
=
. Para un top sin anotar
=
.
A continuación, describimos el algoritmo de actualización de red semántica, es decir, cálculos
para todos los z (algoritmo 1), incluso si solo se anotara una pequeña parte de los vértices. Suponemos que el valor
Ya actualizado para todos los sitios anotados. Bajando de arriba a abajo, calculamos secuencialmente
y
para cada vértice z. Primero, debe actualizar las capas superiores para poder calcular la distribución esperada de los vértices del nivel inferior. Anotamos todos los vértices raíz, por lo que podemos calcular
para todos los vértices
Algoritmo 1. Actualizar distribuciones de nodos de malla semántica
3.3 Optimización del crowdsourcing
La red semántica forma una visión holística de todo el espacio de llamadas API, así como la interacción de declaraciones y llamadas. Según esta vista, podemos anotar selectivamente solo un subconjunto de llamadas API de alto valor. En esta sección, describimos nuestra estrategia de distribución diferencial para optimizar el crowdsourcing.
Considere una red semántica con muchos vértices Z. Nuestra tarea es determinar un subconjunto de vértices dentro del proceso iterativo
para ser anotado por los trabajadores de crowdsourcing. Los vértices anotados anteriormente se denominarán estado estado,
entonces necesitamos encontrar la política política

para evaluar cada vértice no anotado en función del estado actual.
Antes de profundizar en la discusión de los enfoques para calcular políticas efectivas, supongamos que ya tenemos una y damos una descripción de alto nivel de nuestro algoritmo de crowdsourcing (Algoritmo 2) para describir los métodos que lo acompañan. Más específicamente, primero anotamos todos los vértices raíz para evaluar la distribución de todos los vértices en Z (línea 3). En cada iteración, actualizamos la distribución de vértices (línea 5), calculamos
una política basada en el estado actual de la red semántica (línea 6), seleccione el vértice no anotado con la calificación máxima (línea 7) y anote el vértice y el resultado en el nuevo estado (línea 8). En términos prácticos, puede anotar múltiples vértices como parte de una iteración para aumentar la eficiencia.
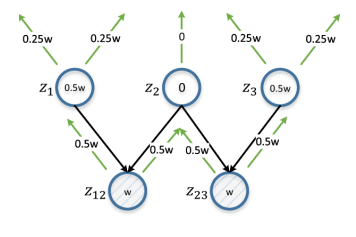 Figura 6. Distribución diferencial. z12 y z23 representan el par de vértices en estudio. w es una estimación calculada sobre la base de d (z12, z23), y se propaga iterativamente de abajo hacia arriba, duplicada en cada iteración. La estimación para el vértice será la diferencia absoluta de sus estimaciones de z12 y z23 (por lo tanto, diferencial). z2 obtiene una puntuación de 0 porque es la entidad principal común para z12 y z23; La anotación en este caso será de poca utilidad para garantizar la distinción de z12 y z23.
Figura 6. Distribución diferencial. z12 y z23 representan el par de vértices en estudio. w es una estimación calculada sobre la base de d (z12, z23), y se propaga iterativamente de abajo hacia arriba, duplicada en cada iteración. La estimación para el vértice será la diferencia absoluta de sus estimaciones de z12 y z23 (por lo tanto, diferencial). z2 obtiene una puntuación de 0 porque es la entidad principal común para z12 y z23; La anotación en este caso será de poca utilidad para garantizar la distinción de z12 y z23.En un sentido amplio, las tareas que resolvemos pueden atribuirse al problema del aprendizaje activo, nos fijamos el objetivo de identificar un subconjunto de ejemplos para anotaciones con el fin de obtener un conjunto de capacitación que pueda mejorar los resultados del aprendizaje. Sin embargo, varias diferencias clave no permiten la aplicación directa de los métodos clásicos de enseñanza activa, como la "incertidumbre del muestreo". Por lo general, en el proceso de aprendizaje activo, el estudiante, que en nuestro caso sería la interfaz NLI, intenta estudiar el mapeo f: X → Y, donde X es el patrón de espacio de entrada, que consiste en un pequeño conjunto de muestras marcadas y una gran cantidad de marcas sin marcar, y Y generalmente es un conjunto de marcadores clase
El alumno evalúa el valor informativo de los ejemplos no etiquetados y selecciona el más informativo para obtener una marca Y de los trabajadores de crowdsourcing. Pero dentro del marco del problema que estamos resolviendo, el problema de la anotación se plantea de manera diferente. Necesitamos seleccionar una instancia de Y, un gran espacio de llamada API, y pedir a los trabajadores de crowdsourcing que lo etiqueten especificando patrones en X, el espacio de oración. Además, no estamos vinculados a un alumno en particular. Por lo tanto, proponemos una nueva solución al problema en cuestión. Nos inspiramos en numerosas fuentes sobre aprendizaje activo.
Primero, determinamos el objetivo, en base al cual se evaluará el contenido de información de los nodos. Obviamente, queremos que se puedan distinguir diferentes llamadas a la API. En la red semántica, esto significa que la distribución
diferentes picos tienen diferencias obvias. Para comenzar, presentamos cada distribución
como un vector n-dimensional

donde n = |
El | - El tamaño del diccionario. Por una cierta métrica de la distancia del vector d (en nuestros experimentos usamos la distancia entre los vectores pL1) queremos decir

, es decir, la distancia entre dos vértices es igual a la distancia entre sus distribuciones.
El objetivo obvio es maximizar la distancia total entre todos los pares de vértices. Sin embargo, la optimización de todas las distancias por pares puede ser demasiado complicada para los cálculos, e incluso esto no es necesario. Un par de picos distantes ya tiene suficientes diferencias, por lo que un mayor aumento de la distancia no tiene sentido. En cambio, podemos centrarnos en los pares de vértices que causan la mayor confusión, es decir, la distancia entre ellos es la más pequeña.
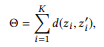
donde
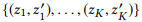
señala los primeros K pares de vértices si clasificamos todos los pares de nodos por distancia en orden ascendente.
Algoritmo 2. Anotar iterativamente una malla semántica con una política Algoritmo 3. Política de cálculo basada en propagación diferencial
Algoritmo 3. Política de cálculo basada en propagación diferencial Algoritmo 4. Propagar recursivamente un puntaje de un nodo fuente a todos sus nodos principales
Algoritmo 4. Propagar recursivamente un puntaje de un nodo fuente a todos sus nodos principales
Los vértices con mayor contenido de información después de la anotación aumentan potencialmente el valor de Θ. Para la cuantificación en este caso, proponemos utilizar una estrategia de distribución diferencial. Si la distancia entre un par de vértices es pequeña, examinamos todos sus vértices principales: si el vértice principal es común para un par de vértices, debería obtener una calificación baja, ya que la anotación conducirá a cambios similares para ambos vértices.
De lo contrario, el vértice debe tener una calificación alta, y cuanto más cerca esté el par de vértices, mayor será la calificación. Por ejemplo, si la distancia entre los vértices de "correos electrónicos no leídos sobre la aplicación de doctorado" y "cuántos correos electrónicos son sobre la aplicación de doctorado" es pequeña, entonces anotar sus vértices principales "correos electrónicos sobre la aplicación de doctorado" no tiene mucho sentido desde el punto de vista de distinguir estos vértices. Es más recomendable anotar los nodos principales que no serán comunes para ellos: "correos electrónicos no leídos" y "cuántos correos electrónicos".
Un ejemplo de tal situación se muestra en la Figura 6, y su algoritmo es el algoritmo 3. Como estimación, tomamos el recíproco de la distancia del nodo delimitada por una constante (línea 6), por lo que los pares de vértices más cercanos tienen el mayor impacto. Cuando trabajamos con un par de vértices, asignamos simultáneamente una evaluación de cada vértice a todos sus vértices principales (línea 9, 10 y algoritmo 4). Una estimación de un vértice no anotado es la diferencia absoluta en las estimaciones del par de vértices correspondiente con la suma de todos los pares de vértices (línea 12).
Interfaz de lenguaje natural
Para evaluar el marco propuesto, es necesario entrenar los modelos NL2API utilizando los datos recopilados. Por el momento, el modelo NL2API terminado no está disponible, pero estamos adaptando dos modelos NLI probados de otras áreas para aplicarlos a la API.
Modelo de lenguaje Modelo de extracción
Basado en desarrollos recientes en el campo de NLI para bases de conocimiento, podemos considerar la creación de NL2API en el contexto del problema de extracción de información para adaptar el modelo de extracción basado en el modelo de lenguaje (LM) a nuestras condiciones.
Para decir u, necesita encontrar una llamada API z en la red semántica con la mejor coincidencia para usted. Primero transformamos la distribución de BoB

cada llamada de la API z al modelo de unigrama de lenguaje:
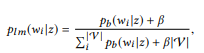
donde usamos suavizado aditivo, y 0 ≤ β ≤ 1 es el parámetro de suavizado. Mayor valor
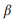
, mayor es el peso de las palabras que aún no se han analizado. Las llamadas a la API se pueden clasificar por su probabilidad logarítmica:
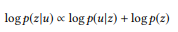
(sujeto a una distribución de probabilidad uniforme a priori)
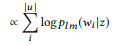
La llamada de API mejor calificada se utiliza como resultado de la simulación.
Módulo de reformulación Seq2Seq
Las redes neuronales se están generalizando como modelos para NLI, mientras que el modelo Seq2Seq es mejor que los demás para este propósito, ya que le permite procesar naturalmente secuencias de entrada y salida de longitudes variables. Adaptamos este modelo para NL2API.
Para la secuencia de entrada e

, el modelo estima la distribución de probabilidad condicional p (y | x) para todas las secuencias de salida posibles
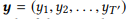
. Las longitudes T y T 'pueden variar y tomar cualquier valor. En NL2API, x es la declaración de salida. Puede ser una llamada API serializada o su comando canónico. Utilizaremos comandos canónicos como secuencias de salida de destino, lo que en realidad convierte nuestro problema en un problema de reformulación.
Un codificador implementado como una red neuronal recurrente (RNN) con unidades de recurrencia controlada (GRU) representa primero x como un vector de tamaño fijo,

donde RN N es una breve representación para aplicar GRU a toda la secuencia de entrada, marcador por marcador, seguido de la salida del último estado oculto.
El decodificador, que también es un RNN con GRU, toma h0 como estado inicial y procesa la secuencia de salida y, marcador por marcador, para generar una secuencia de estados,

La capa de salida toma cada estado del decodificador como un valor de entrada y genera una distribución de diccionario.
como el valor de salida. Simplemente utilizamos la transformación afín seguida de la función logística multivariable softmax:
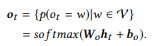
La probabilidad condicional final, que nos permite evaluar qué tan bien el comando canónico y reformula la declaración de entrada x, es

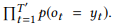
. Las llamadas a la API se clasifican según la probabilidad condicional de su comando canónico. Le recomendamos que se familiarice con la fuente, donde se describe el proceso de aprendizaje modelo con más detalle.
Los experimentos
Experimentalmente, estudiamos los siguientes temas de investigación: [PI1]: ¿Podemos usar el marco propuesto para recopilar datos de capacitación de alta calidad a un precio razonable? [PI2]: ¿La red semántica proporciona una evaluación más precisa de los modelos de lenguaje que la evaluación de máxima verosimilitud? [PI3]: ¿Una estrategia de distribución diferencial mejora la eficiencia del crowdsourcing?
Crowdsourcing
-API Microsoft — GET-Events GET-Messages — . API, API ( 3.1) . API 2. , Amazon Mechanical Turk. , API .
. API 10 , 10 . 201 , . 44 , 82 , 8,2 , , , . , 400 , 17,4 %.
(, ORDERBY a COUNT parameter) (, , ). . NLI. , , [1] . .
, , , , API (. 3). API . , . 61 API 157 GET-Messages, 77 API 190 GET-Events. , , API (, ) , , .
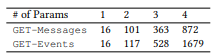 2. API.
2. API. 3. : ().
3. : ()., , . , α = 0,3, LM β = 0,001. K, , 100 000. , , Seq2Seq — 500. ( ).
NLI, . .
. , , . LM: , . , . ROOT — . TOP2 = ROOT + 2; TOP3 = TOP2 + 3. .
4. LM (MLE) ,
, . , , , MLE .
MLE,

,

- , . API . 16 API (ROOT) LM SeMesh Seq2Seq API (TOP2) , 500 API (TOP3).
, , , , ( 3.2) . , GET-Events , GET-Messages. , GET-Events
, , , .
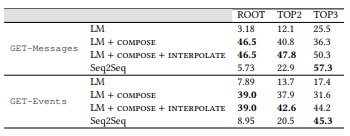 4. . LM, Seq2Seq, . , .
4. . LM, Seq2Seq, . , .LM + , ,
θem with
.
y
, , ROOT,
y
. , , . MLE. , , [2] .
0,45 0,6: , NLI . , API. API (. 7) , RNN , . .
. : |u | α. - LM ( 7). , |u | < 10, 10 . GET-Events, GET-Messages .
, , , . , , . , α, ([0.1, 0.7]). α , , .
(DP) . API . 50 API, , NL2API .
, . LM, . . , ( 5.1), API .
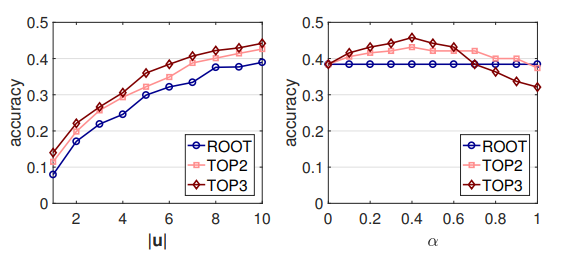
7. .
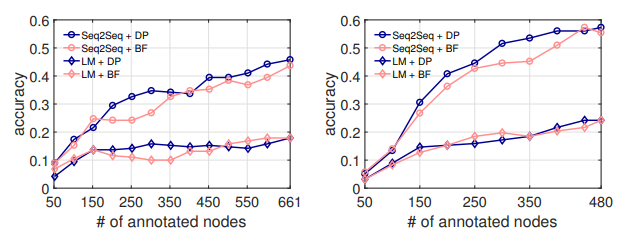
8. . : GET-Events. : GET-Messages
breadth first (BF), . . . API , API .
8. NL2API API DP . 300 API, Seq2Seq, DP 7 % API. , . , DP API, NL2API. , , [3] .
- . - (NLI) . NLI . , , . .
NLI , -, API . NL2API : API , - , . . API REST .
NLI. NLI « ». , Google Suggest API, API IFTTT. NLI, . , .
NLI, . NLI , . , , .
API . , -API. .
-API. , -API. , -API API, -API . NL2API , , API.
- -API (NL2API) NL2API . NL2API . : (1) . , , ? (2) .
? (3) NL2API. , API. (4) API. API? (5) : NL2API ?