El modelo de máquina de estado finito (FSM) se usa para escribir código para una amplia variedad de plataformas, incluido Android. Le permite hacer que el código sea menos engorroso, encaja bien en el paradigma Model-View-Presenter (MVP) y se presta a pruebas simples. El desarrollador Vladislav Kuznetsov le dijo a Droid Party cómo este modelo ayuda en el desarrollo de la aplicación Yandex.Disk.
- Primero, hablemos de teoría. Creo que cada uno de ustedes ha escuchado sobre MVP y la máquina de estado, pero lo repetiremos.

Hablemos sobre la motivación, sobre por qué se necesita todo esto y cómo puede ayudarnos. Pasemos a lo que hicimos, con un ejemplo real mostraré piezas de código. Y al final hablaremos sobre las pruebas, sobre cómo este enfoque ayudó a probar convenientemente todo.
Todos usaron la máquina de estado y el MVP, o algo similar, probablemente MVI.
Hay muchas máquinas de estado. Aquí está la definición más simple que se les puede dar: este es un tipo de abstracción matemática, presentada en forma de un conjunto finito de estados, eventos y transiciones del estado actual a uno nuevo dependiendo del evento.
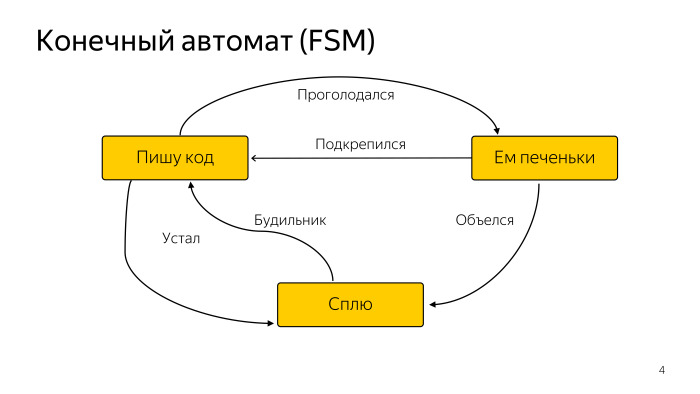
Aquí hay un diagrama simple de algún programador abstracto que a veces duerme, a veces come, pero principalmente escribe código. Esto es suficiente para nosotros. Hay una gran cantidad de variedades de una máquina de estados finitos, pero esto es suficiente para nosotros.

El alcance de la máquina de estado es bastante grande. Para cada artículo se usan y se aplican con éxito.
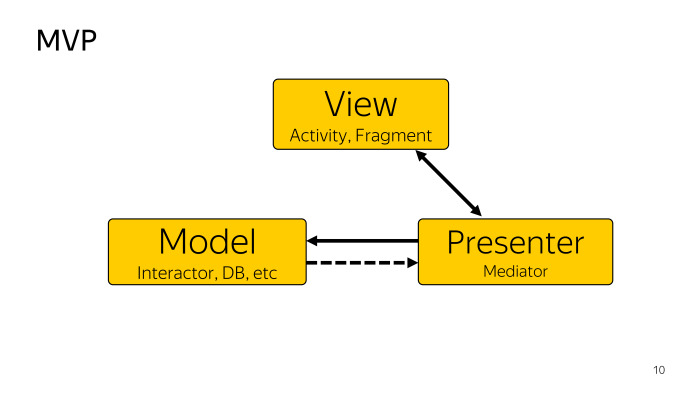
Como cualquier enfoque, MVP divide nuestra aplicación en varias capas. Ver: con mayor frecuencia, una Actividad o Fragmento, cuya tarea es reenviar alguna acción al usuario, para identificar al Presentador que el usuario ha hecho algo. Consideramos a Model como un proveedor de datos. Puede ser como una base de datos, si estamos hablando de arquitectura limpia o Interactor, cualquier cosa puede ser. Y Presenter es un intermediario que conecta la Vista y el modelo, mientras que al mismo tiempo puede recoger y actualizar la Vista desde el modelo. Esto es suficiente para nosotros.
¿Quién puede decir en una oración qué es un programa? Código ejecutable? Demasiado general, más detallado. Un algoritmo? Un algoritmo es una secuencia de acciones.
Este es un conjunto de datos y algún tipo de flujo de control. No importa quién manipule estos datos: el usuario o no. Sigue el pensamiento de que en cualquier momento el estado de una aplicación está determinado por la totalidad de todos sus datos. Y cuantos más datos haya en la aplicación, cuanto más difícil sea administrarlos, más impredecible puede surgir una situación cuando algo sale mal.

Imagine una clase simple con tres banderas booleanas. Para asegurarse de que cubre todos los escenarios para combinar estas banderas, necesita 2³ escenarios. Es necesario cubrir ocho escenarios con la garantía de decir que estoy procesando todas las combinaciones de banderas con seguridad. Si agrega otra bandera, aumenta proporcionalmente.
Nos enfrentamos a un problema similar. Parecía ser una tarea simple, pero a medida que la desarrollamos y trabajamos, comenzamos a darnos cuenta de que algo iba mal. Hablaré sobre las características que lanzamos. Se llama eliminar fotos locales. El punto es que el usuario carga algunos datos a la nube en modo automático. Lo más probable es que estas sean fotos y videos que tomó en su teléfono. Resulta que los archivos parecen estar en la nube. ¿Por qué ocupar un espacio precioso en su teléfono cuando puede eliminar estas fotos?

Los diseñadores dibujaron tal concepto. Parece solo un diálogo, tiene un encabezado donde se dibuja la cantidad de espacio que podemos liberar, el texto del mensaje y una marca de verificación de que hay dos modos de limpieza: eliminar todas las fotos que el usuario ha subido, o solo aquellas que tienen más de un mes.

Buscamos, parece que no hay nada complicado. Diálogo, dos vistas de texto, casilla de verificación, botones. Pero cuando comenzamos a trabajar en este problema en detalle, nos dimos cuenta de que obtener datos sobre cuántos archivos podemos eliminar es una tarea a largo plazo. Por lo tanto, debemos mostrarle al usuario algún tipo de código auxiliar. Este es un pseudocódigo, en la vida real se ve diferente, pero el significado es el mismo.
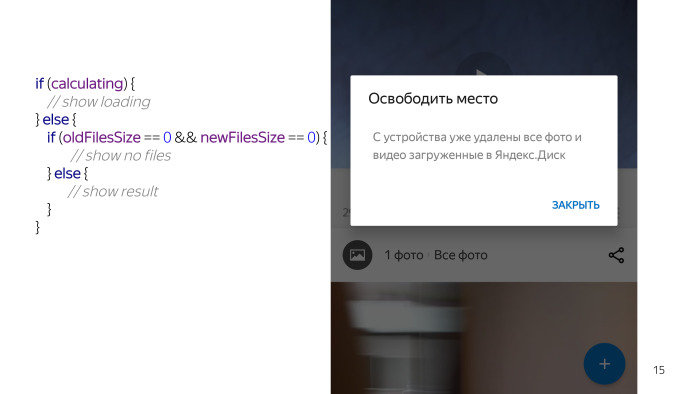
Verificamos algún estado, verificamos que estamos calculando y dibujamos un tapón "Esperar".

Cuando terminan los cálculos, tenemos varias opciones sobre qué mostrarle al usuario. Por ejemplo, el número de archivos que podemos eliminar es cero. En este caso, le enviamos un mensaje al usuario de que no hay nada que eliminar, así que venga la próxima vez. Luego, los diseñadores acuden a nosotros y nos dicen que debemos distinguir entre situaciones en las que el usuario ya ha borrado los archivos o no ha borrado nada, nada cargado. Por lo tanto, aparece otra condición de que estamos esperando el inicio y le dibujamos otro mensaje.
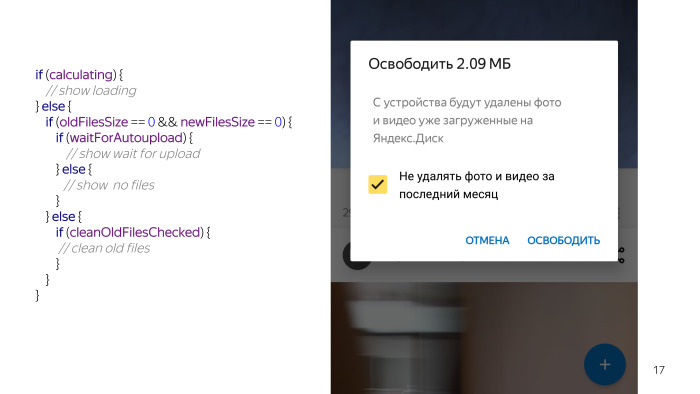
Luego, hay situaciones en las que algo funciona y, por ejemplo, el usuario tiene una marca de verificación para no eliminar archivos nuevos. En este caso, también hay dos opciones. O bien los archivos se pueden limpiar o los archivos no se pueden limpiar, es decir, ya borró todos los archivos, por lo que le advertimos que ya ha eliminado todos los archivos nuevos.
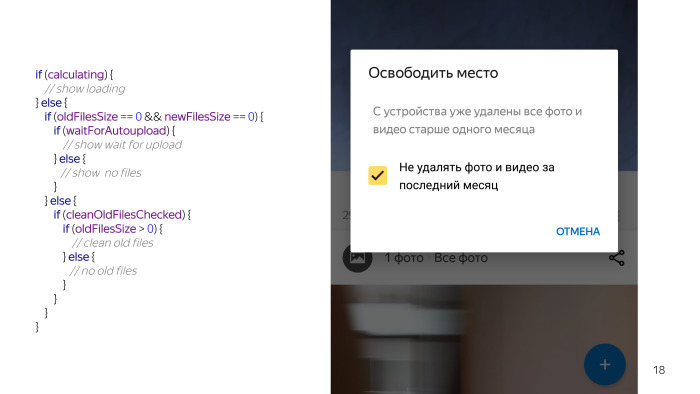
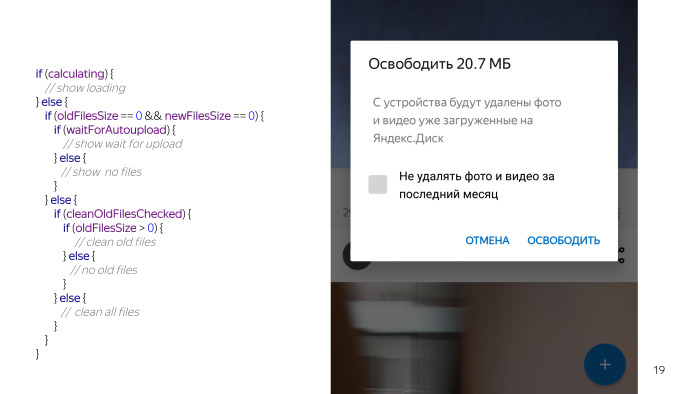
Hay una condición más cuando realmente podemos eliminar algo. Sin marcar, y hay una opción que puede eliminar algo. Miras este código y parece que algo está mal. Todavía no he enumerado todo, tenemos un chequeo permanente, porque nada funciona sin ellos, no podemos tocar los archivos en la tarjeta, además tenemos que verificar que el usuario tenga la carga automática habilitada, porque las funciones son inútiles sin carga automática, lo que haremos para limpiar Y algunas condiciones más. Y maldita sea, parece una cosa tan simple, y muchos problemas han surgido debido a eso.
Y obviamente, surgen varios problemas de inmediato. En primer lugar, este código es ilegible. Aquí se representa un cierto pseudocódigo, pero en un proyecto real se extiende sobre diferentes funciones, fragmentos de código, no es tan fácil de percibir a simple vista. El soporte para dicho código también es bastante complicado. Especialmente cuando vienes a un nuevo proyecto, te dicen que necesitas hacer una función, agregas alguna condición, compruebas un escenario positivo, todo funciona, pero luego los probadores vienen y dicen que bajo ciertas condiciones todo se rompió. Esto sucede porque simplemente no tomaste en cuenta ningún escenario.
Además, es redundante en el sentido de que, dado que tenemos una gran rama de condiciones, debemos verificar todas las condiciones que no nos convengan de antemano. Son negativos de antemano, pero como están escritos con tales ramas, debemos verificarlos. El hecho es que en el ejemplo tengo algún tipo de indicadores booleanos, pero en la práctica, es posible que tenga llamadas a funciones que van más allá de la base de datos. Cualquier cosa puede ser, debido a la redundancia habrá frenos adicionales.
Y lo más triste es un comportamiento inesperado que se perdió durante la fase de prueba, no pasó nada allí, y en algún lugar de la producción el usuario no sucedió en el mejor de los casos, algún tipo de curva de IU, y en el peor de los casos, se cayó o se perdieron los datos . Simplemente la aplicación no se comportó de manera consistente.
¿Cómo resolver este problema? Por el poder de la máquina de estado.

La tarea principal que maneja la máquina de estados es tomar una gran tarea compleja y dividirla en pequeños estados discretos con los que es más fácil interactuar y administrar. Después de sentarnos, pensar, ya que estamos tratando de hacer algo MVP, ¿cómo vincular nuestro estado a todo esto? Hemos llegado a tal esquema aproximadamente. Quien lee el libro GOF es un patrón de estado clásico, justo lo que se llama contexto, lo llamé un estado, y de hecho es un presentador. El presentador tiene este estado, sabe cómo cambiarlos y aún puede proporcionar algunos datos a nuestros estados si desea saber algo, por ejemplo, el tamaño del archivo o si desea solicitar una solicitud asincrónica, seleccione.

Aquí no hay nada súper tonto, la próxima diapositiva es más importante.
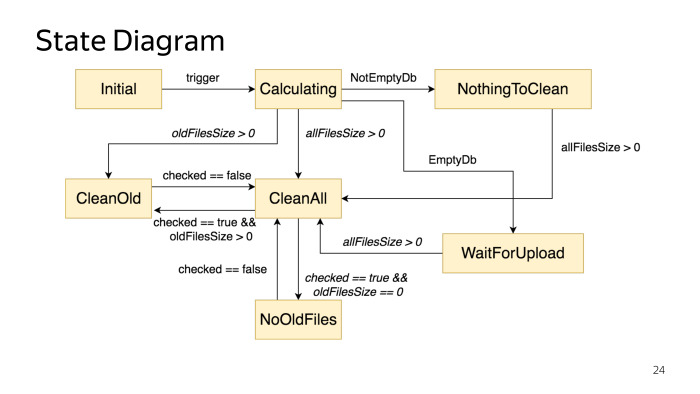
Con esto, debe comenzar el desarrollo cuando comience a hacer una máquina de estados. Te sientas en tu computadora o en algún lugar alrededor de la mesa, y en un pedazo de papel o en herramientas especiales dibujas un diagrama de estado. Tampoco hay nada complicado, pero esta etapa tiene muchas ventajas. En primer lugar, en una etapa temprana, puede detectar de inmediato algunas inconsistencias en la lógica empresarial. Sus productos pueden venir, expresar su deseo, todo está bien, pero cuando comienza a escribir código, comprende que algo no encaja. Creo que todos tenían esa situación. Pero cuando haces un diagrama, puedes ver en una etapa temprana que algo no está atracando. Se dibuja de manera bastante simple, hay herramientas especiales como PlantUML, en las que ni siquiera necesita poder dibujar, debe poder escribir pseudocódigo, y en sí mismo genera gráficos.
Nuestro gráfico se ve así, que describe el estado de este diálogo. Hay varios estados y la lógica de la transición entre ellos.

Pasemos al código. En sí mismo, no hay nada importante, lo principal es que tiene tres métodos: onEnter, que, al ingresar, llama primero invalidateView. ¿Por qué se hace esto? Para que tan pronto como entremos en el estado, la interfaz de usuario se actualiza. Además, está el método invalidateView, que sobrecargamos si necesitamos hacer algo con la interfaz de usuario, y el método onExit, en el que podemos hacer algo si salimos del estado.

Dueño del Estado. Una interfaz que proporciona la capacidad de hacer clic en estado. Como descubrimos, será un futuro presentador. Y estos son métodos que proporcionan acceso adicional a los datos. Si alguna información se revuelve entre estados, podemos guardarla en el presentador y proporcionarla a través de esta interfaz. En este caso, podemos dar el tamaño de los archivos que podemos limpiar y brindar la oportunidad de realizar algún tipo de solicitud. Estamos en un estado, queremos solicitar algo y a través de StateOwner podemos llamar a un método.
Otra de esas utilidades es que él también puede devolver un enlace a la vista. Esto se hace para que si tiene un estado y llegan algunos datos, no desea cambiar a un nuevo estado, es simplemente redundante, puede actualizar directamente la vista, el texto. Usamos esto para actualizar la cantidad de dígitos que el usuario ve cuando mira el diálogo. Estamos en tiempo de ejecución descargando archivos, él mira el diálogo y los números se actualizan. No nos estamos moviendo a un nuevo estado, solo estamos actualizando la Vista actual.

Aquí está el MVP estándar, todo debe ser extremadamente simple, sin lógica, métodos simples que dibujen algo. Me adhiero a este concepto. No debe haber lógica, al menos algún tipo de acción. Tomamos limpiamente una vista de texto, la cambiamos, no más.

Presentador Hay cosas más interesantes En primer lugar, podemos buscar datos en algunos estados, tenemos dos variables marcadas con la anotación de estado. Quien usó Icepick está familiarizado con él. No escribimos serialización con nuestras manos en Partible, utilizamos una biblioteca preparada.
El siguiente es el estado inicial. Siempre es útil establecer el estado inicial, incluso si no hace nada. La utilidad es que no necesita hacer comprobaciones nulas, pero si decimos que puede hacer algo. Por ejemplo, debe hacer algo una vez durante el ciclo de vida de su aplicación, cuando comencemos, debe ejecutar el procedimiento una vez y nunca volver a hacerlo. Cuando salimos del estado inicial, siempre podemos hacer algo como esto, y nunca volvemos a este estado. Escriba para que se dibuje el diagrama de estado. Aunque quién sabe quién dibujará, quizás puedas volver.
Estoy a favor de minimizar las verificaciones para Null, etc., así que aquí guardo un enlace a una implementación de vista simple. No necesitamos sincronizar nada, solo en algún momento cuando ocurre la desconexión, reemplazamos la vista por una vacía, y el presentador puede cambiar en algún lugar de los estados, pensar que hay una vista, la actualiza, pero en realidad funciona Con implementación vacía.
Hay varios métodos más para salvar el estado, pero queremos sobrevivir a la agitación de la actividad, en este caso todo se hace a través del constructor. Todo es un poco más complicado, aquí hay un ejemplo exagerado.

Es necesario reenviar saveState, si alguien trabajó con bibliotecas similares, todo es bastante trivial. Puedes escribir con tus manos. Y dos métodos son muy importantes: adjuntar, llamado onStart, y desconectar, llamado onStop.

¿Cuál es su importancia? Inicialmente, planeamos adjuntar y separar en onCreateView, onDestroyView, pero esto no fue suficiente. Si tiene una Vista, su texto puede actualizarse o puede aparecer un fragmento de diálogo. Y si no queda atrapado en onStop e intenta mostrar el fragmento, detectará la conocida excepción de que no puede realizar una transacción cuando todavía tenemos el estado. O usa commit state loss, o no lo haga. Por lo tanto, se detalla en onStop, mientras que el presentador continuará trabajando allí, cambiará de estado, capturará eventos. Y en ese momento cuando se produce el inicio, activaremos la vista del evento adjunto y el presentador actualizará la IU para que coincida con el estado actual.


Hay un método de lanzamiento, generalmente se llama en onDestroy, realiza una separación y, además, libera recursos.

Otro importante método setState. Como estamos planeando cambiar la interfaz de usuario en onEnter y onExit, hay una comprobación para el hilo principal. Esto crea una restricción para nosotros de que no estamos haciendo nada pesado aquí, todas las solicitudes deben ser a la UI o deben ser asíncronas. La ventaja de este lugar es que aquí podemos reservar la entrada y la salida del estado, es muy útil al depurar, por ejemplo, cuando algo sale mal, puede ver cómo hizo clic el sistema y entender qué estaba mal.
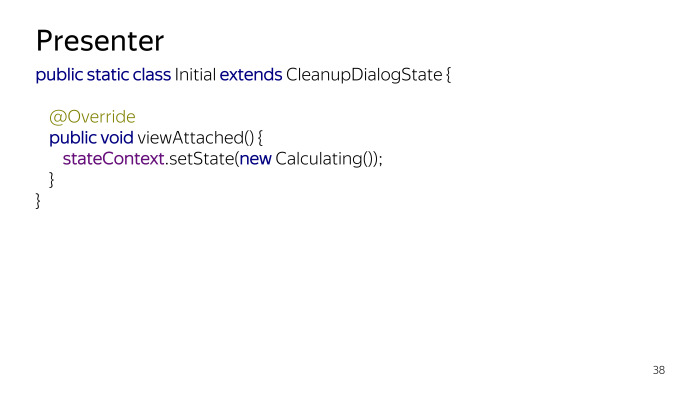
Un par de ejemplos de condiciones. Hay un estado Inicial, solo activa el cálculo de cuánto espacio necesita liberar en el momento en que la vista estuvo disponible. Esto sucederá después de onStart. Tan pronto como sucede onStart, entramos en un nuevo estado y el sistema comienza a solicitar datos.

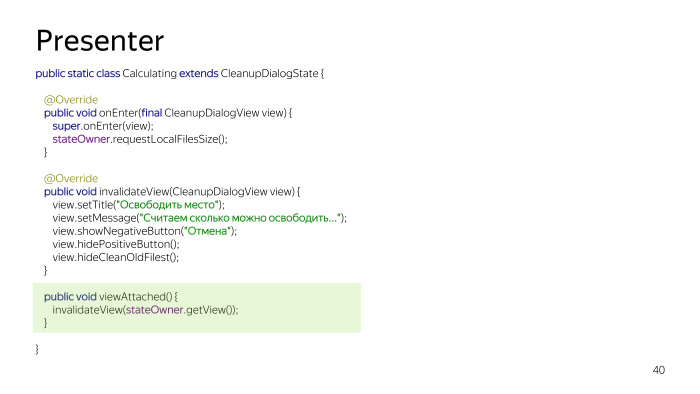
Un ejemplo del estado es Calculando, indicaremos el tamaño de los archivos con stateOwner, de alguna manera se arrastra a la base de datos, y luego todavía hay un InValidateView, actualizamos la IU del usuario actual. Y se llama a viewAttached si la vista se vuelve a unir. Si estábamos en segundo plano, el cálculo estaba en segundo plano, volvemos nuevamente a nuestra Actividad, se llama a este método y actualiza todos los datos.

Un ejemplo de un evento, le preguntamos a stateOwner cuántos archivos se pueden liberar, y llama al método filesSizeUpdated. Aquí era demasiado vago, era posible escribir tres métodos separados, como actualizado, hay tantos archivos antiguos como cómo separar diferentes eventos. Pero tienes que entender, una vez que será difícil para ti, una vez que sea mucho más simple. No es necesario caer en la sobreingeniería de que cada evento es un método separado. Puedes arreglártelas con un simple si, no veo nada malo en eso.

Veo varias mejoras potenciales. No me gusta que nos veamos obligados a echar mano de estos métodos, como onStart, on Stop, onCreate, onSave y más. Puedes conectarte a Lifecycle, pero no está claro qué hacer con saveState. Existe una idea, por ejemplo, para hacer un fragmento de presentador. Por que no Un fragmento sin una interfaz de usuario que capta el ciclo de vida y, en general, no necesitaremos nada, todo volará por nosotros mismos.
Otro punto interesante: este presentador se recrea cada vez, y si tiene grandes datos almacenados en el presentador, fue a la base de datos, sostuvo un cursor enorme, entonces es inaceptable solicitarlo cada vez que gira la pantalla. Por lo tanto, puede almacenar en caché el presentador, como lo hace, por ejemplo, ViewModule de Architecture Components, hacer algún fragmento que contenga el caché de presentadores y devolverlos para cada vista.
Puede usar la forma tabular para especificar máquinas de estado, porque el patrón de estado que usamos tiene un inconveniente significativo: tan pronto como necesite agregar un método a un nuevo evento, debe agregar la implementación a todos los descendientes. Al menos vacío. O hacerlo en condiciones básicas. Esto no es muy conveniente. Por lo tanto, la forma tabular de especificar máquinas de estado se usa en todas las bibliotecas: si busca en GitHub la palabra FSM, encontrará una gran cantidad de bibliotecas que le proporcionan un tipo de generador donde establece el estado inicial, el evento y el estado final. Expandir y mantener una máquina de estado de este tipo es mucho más fácil.
Otro punto interesante: si usa el patrón de estado, si su máquina de estado comienza a crecer, lo más probable es que tenga que manejar algunos eventos de la misma manera para que el código no se copie, cree un estado básico. Cuantos más eventos, las condiciones más básicas comienzan a aparecer, la jerarquía crece y algo sale mal.
Como sabemos, la herencia debe ser reemplazada por delegación, y las máquinas de estado jerárquicas ayudan a resolver este problema. Tiene estados que no dependen del nivel de herencia, solo cree un árbol de estados que pasen el controlador anterior. También puedes leer por separado, algo muy útil. En Android, por ejemplo, las máquinas de estado jerárquicas se usan en WatchDog Wi-Fi, que monitorea el estado de la red, están allí, directamente en la fuente de Android.

Por último pero no menos importante. ¿Cómo se puede probar esto? En primer lugar, los estados deterministas pueden ser probados. Hay un estado separado, creamos una instancia, extraemos el método onEnter y vemos que los valores correspondientes se invocan en la vista. Por lo tanto, validamos que nuestro estado actualice correctamente la Vista. Si su Vista no hace nada serio, lo más probable es que cubra una gran cantidad de escenarios.

Puede bloquear algunos métodos con una función que devuelve el tamaño, llamar a otro evento después de onEnter y ver cómo un estado en particular responde a eventos específicos. En este caso, cuando se produce el evento filesSizeUpdated y cuando AllFilesSize es mayor que cero, debemos pasar al nuevo estado CleanAllFiles. Con la ayuda del diseño, verificamos todo esto.

Y el último: podemos probar todo el sistema. Construimos el estado, le enviamos un evento y verificamos cómo se comporta el sistema. Tenemos tres etapas de prueba. , UI, , , , .
, 70%. 80% . , .

, ? — . - .
. . - , , - , — , .
- , , , . , , . , , . - , , . , , . lock . - , .
— . , , , , . , - , , -, , . , . , .