¿Cómo puedo imprimir un flujo continuo de mensajes de Twitter con unas pocas líneas de código agregando datos meteorológicos a los lugares donde viven sus autores? ¿Y cómo puede limitar la velocidad de las solicitudes al proveedor del clima para que no nos incluyan en la lista negra?
Hoy le diremos cómo hacerlo, pero primero conoceremos la tecnología de Akka Streams, que hace que trabajar con flujos de datos en tiempo real sea tan fácil como los programadores que trabajan con expresiones LINQ sin requerir la implementación de actores individuales o interfaces de Reactive Streams. .
El artículo se basa en una transcripción del
informe de Vagif Abilov de nuestra conferencia de diciembre DotNext 2017 Moscú.
Mi nombre es Vagif, trabajo para la compañía noruega Miles. Hoy hablaremos sobre la biblioteca Akka Streams.
Akka y Reactive Streams son la intersección de conjuntos bastante estrechos, y uno podría tener la impresión de que este es un nicho que necesita tener un gran conocimiento para ingresar, pero todo lo contrario. Y este artículo pretende mostrar que al usar Akka Streams, puede evitar la programación de bajo nivel que se requiere al usar Reactive Streams y Akka.NET. Mirando hacia el futuro, puedo decir de inmediato: si al comienzo de nuestro proyecto, en el que usamos Akka, supiéramos sobre la existencia de Akka Streams, escribiríamos de manera muy diferente, ahorraríamos tiempo y código.
"Quizás lo peor que puede hacer es hacer que las personas que no tienen dolor tomen su aspirina".
Max Kreminski
"Puertas cerradas, dolores de cabeza y necesidades intelectuales"
Antes de entrar en los detalles técnicos, un poco sobre cuál puede ser su camino a Akka Streams y qué puede llevarlo allí. Un día me encontré con el blog de Max Kreminski, donde hizo una pregunta tan filosófica para los programadores: cómo o por qué es imposible para un programador explicar qué son las mónadas. Él lo explicó de esta manera: muy a menudo las personas recurren de inmediato a los detalles técnicos, explicando cuán bellamente funcional es la programación y cuánto sentido tiene en la mónada, sin molestarse en preguntarse por qué el programador podría necesitarla. Dibujando una analogía, es como tratar de vender aspirina sin molestarse en averiguar si su paciente tiene dolor.
Usando esta analogía, me gustaría hacer la siguiente pregunta: si Akka Streams es aspirina, ¿cuál debería ser el dolor que te llevará a ello?
Flujos de datos
Primero, hablemos de los flujos de datos. El flujo puede ser bastante simple, lineal.
Aquí tenemos un cierto consumidor de datos (un conejo en el video). Consume datos a la velocidad que más le convenga. Esta es la interacción ideal del consumidor con el flujo: establece el ancho de banda y los datos fluyen silenciosamente hacia él. Este flujo de datos simple puede ser infinito o puede terminar.
Pero el flujo puede ser más complejo. Si planta varios conejos uno al lado del otro, ya tendremos paralelización de flujos. Lo que Reactive Streams está tratando de resolver es precisamente cómo podemos comunicarnos con los flujos a un nivel más conceptual, es decir, independientemente de si estamos hablando de algún tipo de medición del sensor de temperatura, donde entran las mediciones lineales. , o tenemos mediciones continuas de miles de sensores de temperatura que ingresan al sistema a través de las colas RabbitMQ y se almacenan en los registros del sistema. Todo lo anterior puede considerarse como una secuencia compuesta. Si va más allá, la gestión automatizada de la producción (por ejemplo, por parte de una tienda en línea) también se puede reducir a un flujo de datos, y sería excelente si pudiéramos hablar sobre la planificación de dicho flujo, sin importar lo complicado que sea.

Para proyectos modernos, el soporte de hilos no es muy bueno. Si no recuerdo mal, Aaron Stannard, cuyo tweet que ves en la imagen, quería obtener una secuencia de un archivo de varios gigabytes que contenga CSV, es decir. texto, y resultó que no hay nada que puedas tomar y usar de inmediato, sin un montón de acciones adicionales. Pero simplemente no pudo obtener una corriente de valores CSV, lo que lo entristeció. Hay pocas soluciones (con la excepción de algunas áreas especiales), los métodos antiguos se dan cuenta de mucho, cuando abrimos todo esto, comenzamos a leer, al almacenamiento en búfer, en el peor de los casos, obtenemos algo como un bloc de notas, que dice que el archivo es demasiado grande.
A un alto nivel conceptual, todos estamos involucrados en el procesamiento de flujos de datos, y Akka Streams lo ayudará si:
- Estás familiarizado con Akka, pero quieres ahorrarte los detalles asociados con la escritura del código del actor y su coordinación;
- Usted está familiarizado con las secuencias reactivas y desea utilizar una implementación lista para usar de sus especificaciones;
- Los elementos de bloque de Akka Streams para etapas son adecuados para modelar su proceso;
- Desea aprovechar la contrapresión de Akka Streams (contrapresión) para administrar y refinar dinámicamente las etapas de rendimiento de su flujo de trabajo.
De actores a Akka Streams

La primera forma es desde actores hasta Akka Streams, a mi manera.
La imagen muestra por qué comenzamos a usar el modelo de actor. Estábamos agotados por el control manual de flujos, estado compartido, eso es todo. Todos los que han trabajado con sistemas grandes, con subprocesos múltiples, entienden cuánto lleva tiempo y lo fácil que es cometer un error, lo que puede ser fatal para todo el proceso. Esto nos llevó al modelo de actores. No lamentamos la elección realizada, pero, por supuesto, cuando comienzas a trabajar y programar más, no es que el entusiasmo inicial ceda el paso a otra cosa, sino que comienzas a darte cuenta de que algo se puede hacer aún más eficazmente.
“Por defecto, los destinatarios de sus mensajes se ingresan en el código de actores. Si creo un actor A que envía un mensaje al actor B, y desea reemplazar al destinatario con el actor C, en el caso general esto no funcionará para usted "
Noel Welch (underscore.io)
Actores criticados por no componer. Uno de los primeros en escribir sobre esto en su blog fue Noel Welch, uno de los desarrolladores de Underscore. Se dio cuenta de que el sistema de actores se parece a esto:

Si no utiliza nada adicional, como la inyección de dependencia, la dirección de su destinatario se cose al actor.

Cuando comienzan a enviarse mensajes entre sí, todo esto lo establece de antemano, programando actores. Y sin trucos adicionales, se obtiene un sistema tan rígido.
Uno de los desarrolladores de Akka, Roland Kuhn,
explicó lo que generalmente se entiende por diseño deficiente. El método del actor se basa en el método tell, es decir, mensajes unidireccionales: es del tipo nulo, es decir, no devuelve nada (o unidad, dependiendo del idioma). Por lo tanto, es imposible construir una descripción del proceso a partir de una cadena de actores. Entonces enviaste decir, ¿entonces qué? Para Nos anulamos. Puede compararlo, por ejemplo, con expresiones LINQ, donde cada elemento de la expresión devuelve IQueryable, IEnumerable, y todo esto se puede compilar fácilmente. Los actores no dan esa oportunidad. Al mismo tiempo, Roland Kuhn se opuso al hecho de que, según dicen, no componen en principio, diciendo que, de hecho, se compilan de otras maneras, en el mismo sentido en que la sociedad humana se presta al diseño. Parece un argumento filosófico, pero si lo piensas bien, la analogía tiene sentido: sí, los actores se envían mensajes unidireccionales entre sí, pero también nos comunicamos entre ellos pronunciando mensajes unidireccionales, pero al mismo tiempo interactuamos de manera bastante efectiva, es decir, creamos sistemas complejos. Sin embargo, existe tal crítica a los actores.
public class SampleActor : ReceiveActor { public SampleActor() { Idle(); } protected override void PreStart() { } private void Idle() { Receive<Job>(job => ); } private void Working() { Receive<Cancel>(job => ); } }
Además, la implementación del actor requiere al menos escribir una clase si trabaja en C #, o funciones si trabaja en F #. En el ejemplo anterior, código repetitivo, que debe escribir en cualquier caso. Aunque no es muy grande, es un cierto número de líneas que siempre tendrá que escribir en este nivel bajo. Casi todo el código que está presente aquí es una especie de ceremonia. Lo que sucede cuando un actor recibe un mensaje directamente no se muestra aquí en absoluto. Y todo esto necesita ser escrito. Esto, por supuesto, no es mucho, pero es evidencia de que trabajamos con actores de bajo nivel, creando métodos tan nulos.
¿Qué pasaría si pudiéramos pasar a un nivel diferente y superior, hacernos preguntas para modelar nuestro proceso, que incluye el procesamiento de datos de varias fuentes que se mezclan, convierten y transfieren?
var results = db.Companies .Join(db.People, c => c.CompanyID, p => p.PersonID, (c, p) => new { c, p }) .Where(z => zcCreated >= fromDate) .OrderByDescending(z => zcCreated) .Select(z => zp) .ToList();
Un análogo de este enfoque puede ser lo que todos hemos estado acostumbrados a trabajar con LINQ durante diez años. No nos preguntamos cómo funciona la unión. Sabemos que existe un proveedor LINQ que hará todo esto por nosotros, y estamos interesados en un nivel superior en cumplir con la solicitud. Y generalmente podemos mezclar bases de datos aquí, podemos enviar solicitudes distributivas. ¿Qué pasaría si pudieras describir el proceso de esta manera?
HttpGet pageUrl |> fun s -> Regex.Replace(s, "[^A-Za-z']", " ") |> fun s -> Regex.Split(s, " +") |> Set.ofArray |> Set.filter (fun word -> not (Spellcheck word)) |> Set.iter (fun word -> printfn " %s" word)
(Fuente)O, por ejemplo, transformaciones funcionales. Lo que a muchas personas les gusta de la programación funcional es que puedes pasar datos a través de una serie de transformaciones, y obtienes un código compacto bastante claro, independientemente del idioma en el que lo escribas. Es lo suficientemente fácil de leer. El código en la imagen está escrito especialmente en F #, pero en general, probablemente, todos entienden lo que está sucediendo aquí.
val in = Source(1 to 10) val out = Sink.ignore val bcast = builder.add(Broadcast[Int](2)) val merge = builder.add(Merge[Int](2)) val f1,f2,f3,f4 = Flow[Int].map(_ + 10) source ~> f1 ~> bcast ~> f2 ~> merge ~> f3 ~> sink bcast ~> f4 ~> merge ~>
(Fuente)¿Qué tal esto entonces? En el ejemplo anterior, tenemos una fuente de datos fuente, que consiste en enteros del 1 al 10. Este es el llamado DSL gráfico (lenguaje específico del dominio). Los elementos del lenguaje de dominio en el ejemplo anterior son símbolos de flecha unidireccionales; estos son operadores adicionales definidos por herramientas de lenguaje que muestran gráficamente la dirección de la secuencia. Pasamos Source a través de una serie de transformaciones: para facilitar la demostración, todos simplemente agregan un diez al número. Luego viene Broadcast: multiplicamos los canales, es decir, cada número ingresa a dos canales. Luego agregamos 10 nuevamente, mezclamos nuestras secuencias de datos, obtenemos una nueva secuencia, agregamos 10 también, y todo esto va a nuestra secuencia de datos, en la que no sucede nada. Este es el código real que está escrito en Scala, parte de Akka Streams, implementado en este idioma. Es decir, usted especifica las fases de la transformación de sus datos, indica qué hacer con ellos, especifica la fuente, el stock, algunos puntos de control y luego forma un gráfico usando el DSL gráfico. Todo esto es código para un solo programa. Algunas líneas de código muestran lo que está sucediendo en el proceso.
Olvidemos cómo escribir el código de definición para actores individuales y, en cambio, aprendamos las primitivas de diseño de alto nivel que crearán y conectarán a los actores requeridos dentro de sí mismos. Cuando ejecutamos un gráfico de este tipo, el sistema que proporciona Akka Streams creará el actor requerido por sí mismo, enviará todos estos datos allí, los procesará como debería y finalmente se los entregará al destinatario final.
var runnable = Source .From(Enumerable.Range(1, 1000)) .Via(Flow.Create<int>().Select(x => x * 2) .To(Sink.ForEach<int>(x => Console.Write(x.ToString));
El ejemplo anterior muestra cómo se vería esto en C #. La forma más simple: tenemos una fuente de datos: estos son números del 1 al 1000 (como puede ver, en Akka Streams cualquier IEnumerable puede convertirse en una fuente de flujo de datos, lo cual es muy conveniente). Hacemos un cálculo simple, digamos, multiplicamos por dos, y luego en el flujo de datos, todo esto se muestra en la pantalla.
var graph = GraphDsl.Create(builder => { var bcast = builder.Add(new Broadcast<int>(2)); var merge = builder.Add(new Merge<int, int>(2)); var count = Flow.FromFunction(new Func<int, int>(x => 1)); var sum = Flow.Create<int>().Sum((x, y) => x + y); builder.From(bcast.Out(0)).To(merge.In(0)); builder.From(bcast.Out(1)).Via(count).Via(sum).To(merge.In(1)); return new FlowShape<int, int>(bcast.In, merge.Out); });
Lo que se muestra en el ejemplo anterior se llama "DSL gráfico en C #". De hecho, no hay gráficos aquí, es un puerto con Scala, pero en C # no hay forma de definir operadores de esta manera, por lo que parece un poco más engorroso, pero lo suficientemente compacto como para comprender lo que está sucediendo aquí. Entonces, estamos creando un determinado gráfico (hay diferentes tipos de gráficos, aquí se llama FlowShape) a partir de diferentes componentes, donde hay una fuente de datos y hay algunas transformaciones. Enviamos datos a un canal en el que generamos conteo, es decir, el número de elementos de datos a transmitir, y en el otro generamos la suma y luego lo mezclamos todo. A continuación veremos ejemplos más interesantes que solo el procesamiento de enteros.
Este es el primer camino que puede llevarlo a Akka Streams, si tiene experiencia trabajando con un modelo de actor y ha pensado si debe escribir manualmente cada uno, incluso el actor más simple. La segunda forma en que Akka Streams llega es a través de Reactive Streams.
De las corrientes reactivas a las corrientes de Akka
¿Qué son las
corrientes reactivas ? Esta es una iniciativa conjunta para desarrollar un estándar para el procesamiento asincrónico de flujos de datos. Define el conjunto mínimo de interfaces, métodos y protocolos que describen las operaciones y entidades necesarias para lograr el objetivo: procesamiento asincrónico de datos en tiempo real con contrapresión (contrapresión) sin bloqueo. Permite diversas implementaciones utilizando diferentes lenguajes de programación.
Reactive Streams le permite procesar un número potencialmente ilimitado de elementos en una secuencia y transferir elementos de forma asincrónica entre componentes con contrapresión sin bloqueo.
La lista de iniciadores de la creación de Reactive Streams es bastante impresionante: aquí están Netflix, Oracle y Twitter.
La especificación es muy simple para hacer que la implementación en diferentes idiomas y plataformas sea lo más accesible posible. Los componentes principales de la API Reactive Streams:
- Editor
- Suscriptor
- Suscripción
- Procesador
Esencialmente, esta especificación no implica que comenzará a implementar manualmente estas interfaces. Se entiende que hay algunos desarrolladores de bibliotecas que harán esto por usted. Y Akka Streams es una de las implementaciones de esta especificación.
public interface IPublisher<out T> { void Subscribe(ISubscriber<T> subscriber); } public interface ISubscriber<in T> { void OnSubscribe(ISubscription subscription); void OnNext(T element); void OnError(Exception cause); void OnComplete(); }
Las interfaces, como puede ver en el ejemplo, son realmente muy simples: por ejemplo, Publisher contiene solo un método: "suscribirse". El suscriptor, Suscriptor, contiene solo algunas reacciones al evento.
public interface ISubscription { void Request(long n); void Cancel(); } public interface IProcessor<in T1, out T2> : ISubscriber<T1>, IPublisher<T2> { }
Finalmente, la suscripción contiene dos métodos: "inicio" y "rechazar". El procesador no define ningún método nuevo; combina un editor y un suscriptor.
¿Qué distingue a Reactive Streams de otras implementaciones de stream? Reactive Streams combina modelos push y pull. Para soporte, este es el escenario de rendimiento más eficiente. Supongamos que tiene un suscriptor de datos lento. En este caso, presionar por él puede ser fatal: si le envía una gran cantidad de datos, no podrá procesarlos. Es mejor usar pull para que el suscriptor mismo extraiga los datos del editor. Pero si el editor es lento, resulta que el suscriptor está bloqueado todo el tiempo, esperando todo el tiempo. Una solución intermedia puede ser la configuración: tenemos un archivo de configuración en el que determinamos cuál de ellos es más rápido. ¿Y si cambian sus velocidades?
Entonces, la implementación más elegante es aquella en la que podemos cambiar dinámicamente los modelos push y pull.
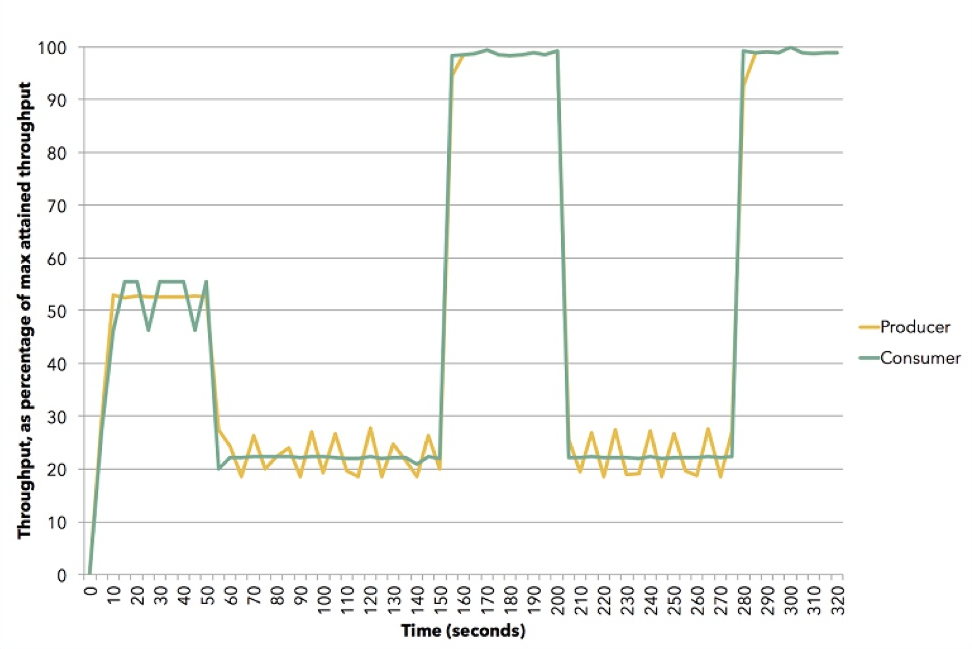 (Fuente (Apache Flink))
(Fuente (Apache Flink))El diagrama muestra cómo puede suceder esto. Esta demostración utiliza Apache Flink. Yellow es un editor, productor de datos, se estableció en aproximadamente el 50% de su capacidad. El suscriptor trata de elegir la mejor estrategia: resulta ser push. Luego reiniciamos el suscriptor a una velocidad de aproximadamente 20%, y él cambia para tirar. Luego pasamos al 100%, nuevamente regresamos el 20%, al modelo de extracción, etc. Todo esto sucede en la dinámica, no necesita detener el servicio, ingrese algo en la configuración. Esta es una ilustración de cómo funciona la contrapresión en Akka Streams.
Principios de las corrientes de Akka
Por supuesto, Akka Streams no ganaría popularidad si no hubiera bloques incorporados que sean muy fáciles de usar. Hay muchos de ellos. Se dividen en tres grupos principales:
- Fuente de datos (Fuente): etapa de procesamiento con una salida.
- El sumidero es un paso de procesamiento de entrada única.
- Punto de control (flujo): etapa de procesamiento con una entrada y una salida. Las transformaciones funcionales tienen lugar aquí, y no necesariamente en la memoria: puede ser, por ejemplo, una llamada a un servicio web, a algunos elementos de paralelismo, multiproceso.
De estos tres tipos, se pueden formar gráficos. Estas ya son etapas de procesamiento más complejas, que se crean a partir de fuentes, drenajes y puntos de control. Pero no todos los gráficos se pueden ejecutar: si hay agujeros en él, es decir, entradas y salidas abiertas, entonces este gráfico no se ejecuta.
Un gráfico es un gráfico ejecutable, si está cerrado, es decir, hay una salida para cada entrada: si los datos han ingresado, deben haber ido a alguna parte.

Akka Streams tiene fuentes incorporadas: en la imagen puedes ver cuántas de ellas. Sus nombres son uno a uno y reflejan lo que Scala o la JVM tienen, con la excepción de algunas fuentes útiles específicas de .NET. Los dos primeros (FromEnumerator y From) son algunos de los más importantes: cualquier numeración, cualquier número numerable se puede convertir en una fuente de flujo.

Hay drenajes integrados: algunos de ellos se parecen a los métodos LINQ, por ejemplo, Primero, Último, Primero o Por defecto. Por supuesto, todo lo que obtienes, puedes volcarlo en archivos, en secuencias, no en secuencias de Akka, sino en secuencias .NET. Y de nuevo, si tiene actores en su sistema, puede usarlos tanto en la entrada como en la salida del sistema, es decir, si lo desea, incrustar esto en su sistema terminado.

Y hay una gran cantidad de puntos de control integrados, que, quizás, recuerdan aún más a LINQ, porque aquí hay Select, y SelectMany, y GroupBy, es decir, todo con lo que estamos acostumbrados a trabajar en LINQ.
Por ejemplo, Select in Scala se llama SelectAsync: es lo suficientemente potente porque toma el nivel de paralelismo como uno de los argumentos. Es decir, puede indicar que, por ejemplo, Select envía datos a algún servicio web en paralelo en diez subprocesos, luego todos se recopilan y pasan. De hecho, usted determina el grado de escala del punto de control con una línea de código.
Una declaración de flujo es su plan de ejecución, es decir, un gráfico, incluso uno de ejecución, no se puede ejecutar de esa manera: debe materializarse. Debe haber un sistema instanciado, un sistema de actores, debe darle una secuencia, este plan de ejecución y luego se ejecutará. Además, en tiempo de ejecución está altamente optimizado, al igual que cuando envía una expresión LINQ a una base de datos: un proveedor puede optimizar su SQL para una salida de datos más eficiente, esencialmente reemplazando el comando de consulta por otro. Lo mismo con Akka Streams: a partir de la versión 2.0, puede establecer un cierto número de puntos de control, y el sistema comprenderá que algunos de ellos se pueden combinar para que sean ejecutados por un actor (fusión de operadores). Los puntos de control, como regla, mantienen el orden de los elementos de procesamiento.
var results = db.Companies .Join(db.People, c => c.CompanyID, p => p.PersonID, (c, p) => new { c, p }) .Where(z => zcCreated >= fromDate) .OrderByDescending(z => zcCreated) .Select(z => zp) .ToList();
La materialización de la secuencia se puede comparar con el último elemento ToList en la expresión LINQ en el ejemplo anterior. Si no escribimos ToList, obtenemos una expresión LINQ no materializada que no hará que los datos se transfieran al servidor SQL u Oracle, ya que la mayoría de los proveedores de LINQ admiten la llamada ejecución de consulta diferida (ejecución de consulta diferida), t es decir, la solicitud se ejecuta solo cuando se da un comando para dar algún resultado. Dependiendo de lo que se solicite, una lista o el primer resultado, se formará el equipo más efectivo. Cuando decimos ToList, le pedimos al proveedor LINQ que nos dé el resultado final.
var runnable = Source .From(Enumerable.Range(1, 1000)) .Via(Flow.Create<int>().Select(x => x * 2) .To(Sink.ForEach<int>(x => Console.Write(x.ToString));
Akka Streams funciona de la misma manera. En la imagen está nuestro gráfico lanzado, que consiste en una fuente de puntos de control y escorrentía, y ahora queremos ejecutarlo.
var runnable = Source .From(Enumerable.Range(1, 1000)) .Via(Flow.Create<int>().Select(x => x * 2) .To(Sink.ForEach<int>(x => Console.Write(x.ToString)); var system = ActorSystem.Create("MyActorSystem"); using (var materializer = ActorMaterializer.Create(system)) { await runnable.Run(materializer); }
Para que esto suceda, necesitamos crear un sistema de actores, en él hay un materializador, pasarle nuestro gráfico y él lo ejecutará. Si lo recreamos, lo ejecutará nuevamente y se pueden obtener otros resultados.
Además de la materialización del flujo, hablando de la parte material de Akka Streams, vale la pena mencionar los valores materializados.
var output = new List<int>(); var source1 = Source.From(Enumerable.Range(1, 1000)); var sink1 = Sink.ForEach<int>(output.Add); IRunnableGraph<NotUsed> runnable1 = source1.To(sink1); var source2 = Source.From(Enumerable.Range(1, 1000)); var sink2 = Sink.Sum<int>((x,y) => x + y); IRunnableGraph<Task<int>> runnable2 = source2.ToMaterialized(sink2, Keep.Right);
Cuando tenemos una secuencia que va desde la fuente a través de los puntos de control hasta el drenaje, si no solicitamos ningún valor intermedio, no están disponibles para nosotros, ya que se ejecutará de la manera más eficiente. Es como una caja negra. Pero puede ser interesante para nosotros extraer algunos valores intermedios, porque en cada punto a la izquierda entran algunos valores, salen otros valores a la derecha y puede especificar un gráfico para indicar lo que le interesa. En el ejemplo anterior, un gráfico de ejecución en el que se indica NotUsed, es decir, no nos interesan valores materializados. A continuación, lo creamos con la indicación de que en el lado derecho de la escorrentía, es decir, después de que se hayan completado todas las transformaciones, necesitamos dar valores materializados. Obtenemos la Tarea del gráfico: una tarea, una vez completada, obtenemos un int, es decir, lo que sucede al final de este gráfico. Puede indicar en cada párrafo que necesita algún tipo de valores materializados, todo esto se recopilará gradualmente.
Para transferir datos a los flujos de Akka Streams o sacarlos de allí, por supuesto, se necesita algún tipo de interacción con el mundo exterior. Las etapas fuente integradas contienen una amplia gama de flujos de datos reactivos:
- Source.FromEnumerator y Source.From le permiten transferir datos desde cualquier fuente que implemente IEnumerable;
- Unfold y UnfoldAsync generan los resultados de los cálculos de la función siempre que devuelva valores distintos de cero;
- FromInputStream transforma un flujo;
- FromFile analiza el contenido del archivo en la secuencia reactiva;
- ActorPublisher convierte mensajes de actor.
Como ya dije, para los desarrolladores de .NET es muy productivo usar Enumerator o IEnumerable, pero a veces es una forma demasiado primitiva y demasiado ineficiente de acceder a los datos. Las fuentes más complejas que contienen una gran cantidad de datos requieren conectores especiales. Tales conectores están escritos. Hay un proyecto de código abierto Alpakka, que apareció originalmente en Scala y ahora está en .NET. Además, Akka tiene los llamados actores persistentes, y tienen sus propias transmisiones que se pueden usar (por ejemplo, Akka Persistence Query forma el flujo de contenido del Akka Event Journal).

Si trabaja con Scala, entonces la forma más fácil es para usted: hay una gran cantidad de conectores y seguramente encontrará algo a su gusto. Para información, Kafka es el llamado Kafka Reactivo, no Kafka Streams. Kafka Streams, hasta donde yo sé, no admite contrapresión. Reactive Kafka es una implementación de flujo de Kafka que admite flujos reactivos.
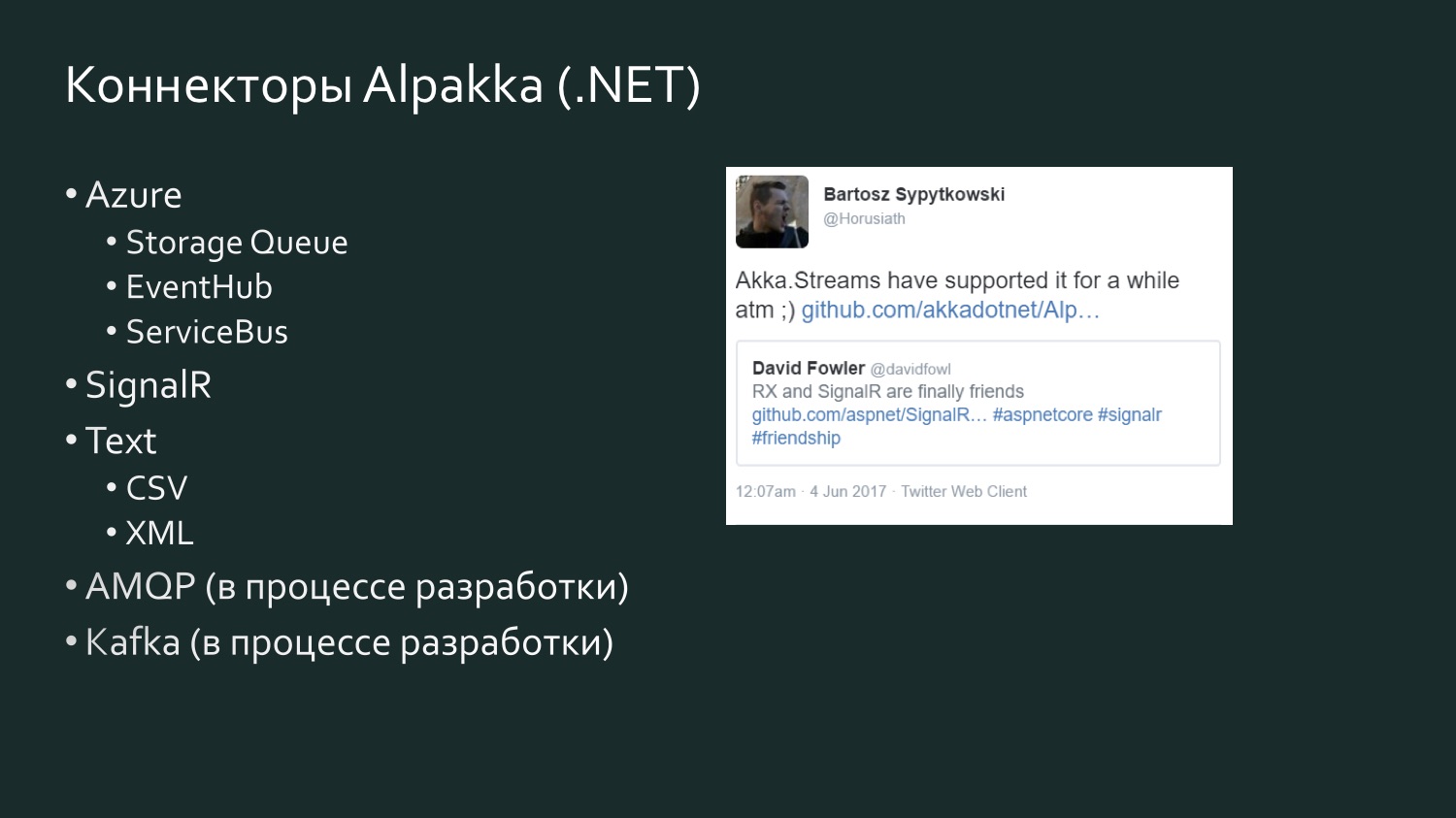
La lista de conectores Alpakka .NET es más modesta, pero se repone y hay un elemento de competencia. Hay un tweet de seis meses de David Fowler de Microsoft, quien dijo que SignalR ahora puede intercambiar datos con Reactive Extensions, y uno de los desarrolladores de Akka respondió que realmente había estado en Akka Streams durante algún tiempo. Akka admite varios servicios de Microsoft Azure. CSV es el resultado de la frustración de Aaron Stannard cuando descubrió que no hay una buena transmisión para CSV: ahora Akka tiene su propia transmisión para CSV XML. Hay AMQP (en realidad, RabbitMQ), está en desarrollo, pero está disponible para su uso, funciona. Kafka también está en desarrollo. Esta lista continuará expandiéndose.
Algunas palabras sobre las alternativas, ya que si trabaja con flujos de datos, Akka Streams no es, por supuesto, la única forma de manejar estos flujos. Lo más probable es que, en su proyecto, la elección de cómo implementar hilos dependerá de muchos otros factores que pueden convertirse en clave. Por ejemplo, si trabaja mucho con Microsoft Azure y Orleans está integrado orgánicamente en las necesidades de su proyecto con su soporte para actores virtuales o, como los llaman, granos, entonces tienen su propia implementación que no cumple con la especificación de Reactive Streams: Orleans Streams, que será más cercano para ti y tiene sentido que le prestes atención. Si trabaja mucho con TPL, existe TPL DataFlow; esta puede ser la analogía más cercana a Akka Streams: también tiene primitivas para componer flujos de datos, así como herramientas de limitación de ancho de banda y almacenamiento en memoria intermedia (BoundedCapacity, MaxMessagePerTask). Si las ideas del modelo de actor son cercanas a usted, entonces Akka Streams es una forma de abordar esto y ahorrar una cantidad significativa de tiempo sin tener que escribir cada actor manualmente.
Ejemplo de implementación: secuencia de registro de eventos
Veamos un par de ejemplos de implementación. — , . Akka Streams, , - , .
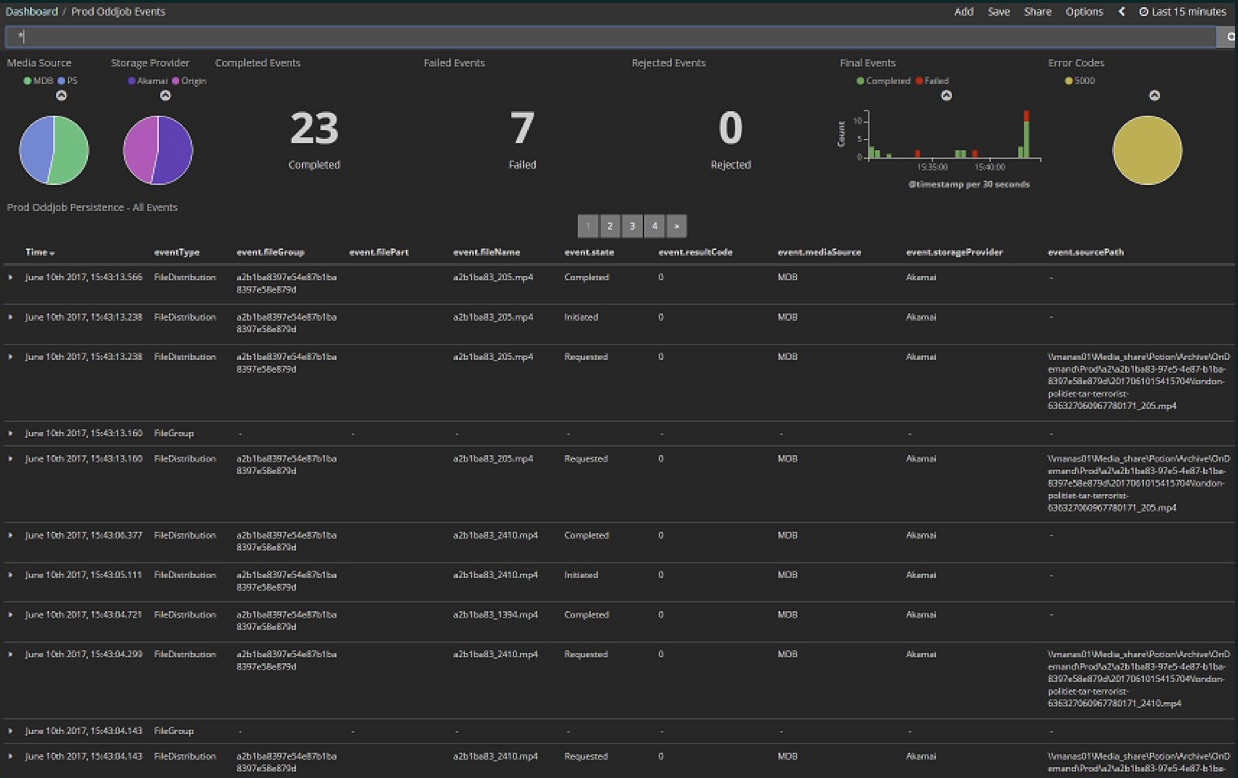
. : 15 23 , 7 . — . Kibana Dashboard.
Kibana Elasticsearch , Elasticsearch , , , , . , , , . . . (event journal) Akka, Microsoft SQL Server. , .
CREATE TABLE EventJournal ( Ordering BIGINT IDENTITY(1,1) PRIMARY KEY NOT NULL, PersistenceID NVARCHAR(255) NOT NULL, SequenceNr BIGINT NOT NULL, Timestamp BIGINT NOT NULL, IsDeleted BIT NOT NULL, Manifest NVARCHAR(500) NOT NULL, Payload VARBINARY(MAX) NOT NULL, Tags NVARCHAR(100) NULL CONSTRAINT QU_EventJournal UNIQUE (PersistenceID, SequenceNr) )
, , , , SQL Server, eventstore Akka, eventJournal. eventstore.
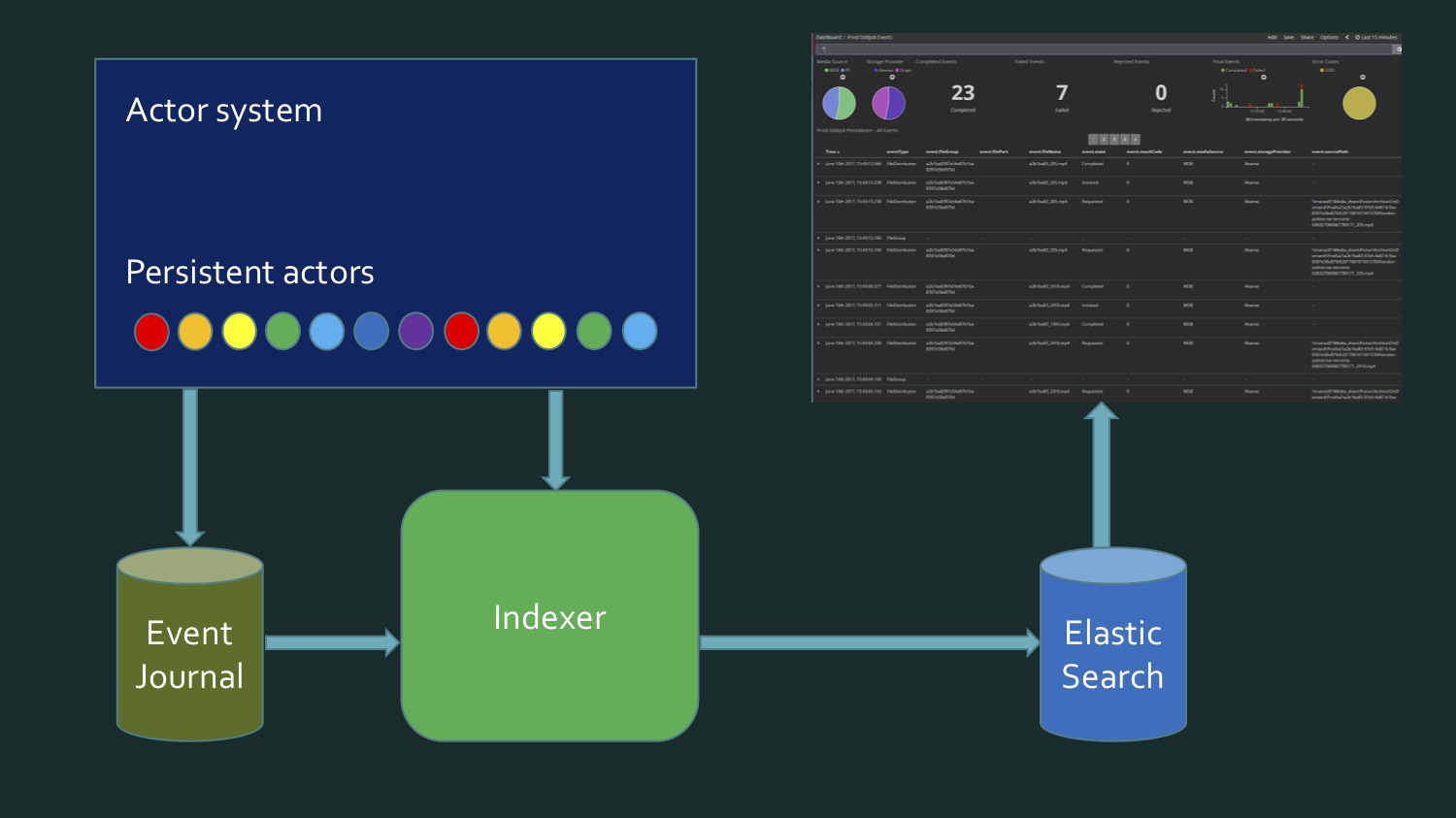
, . , , , , - : , . , . . . - . , . , . , Akka persistence query.
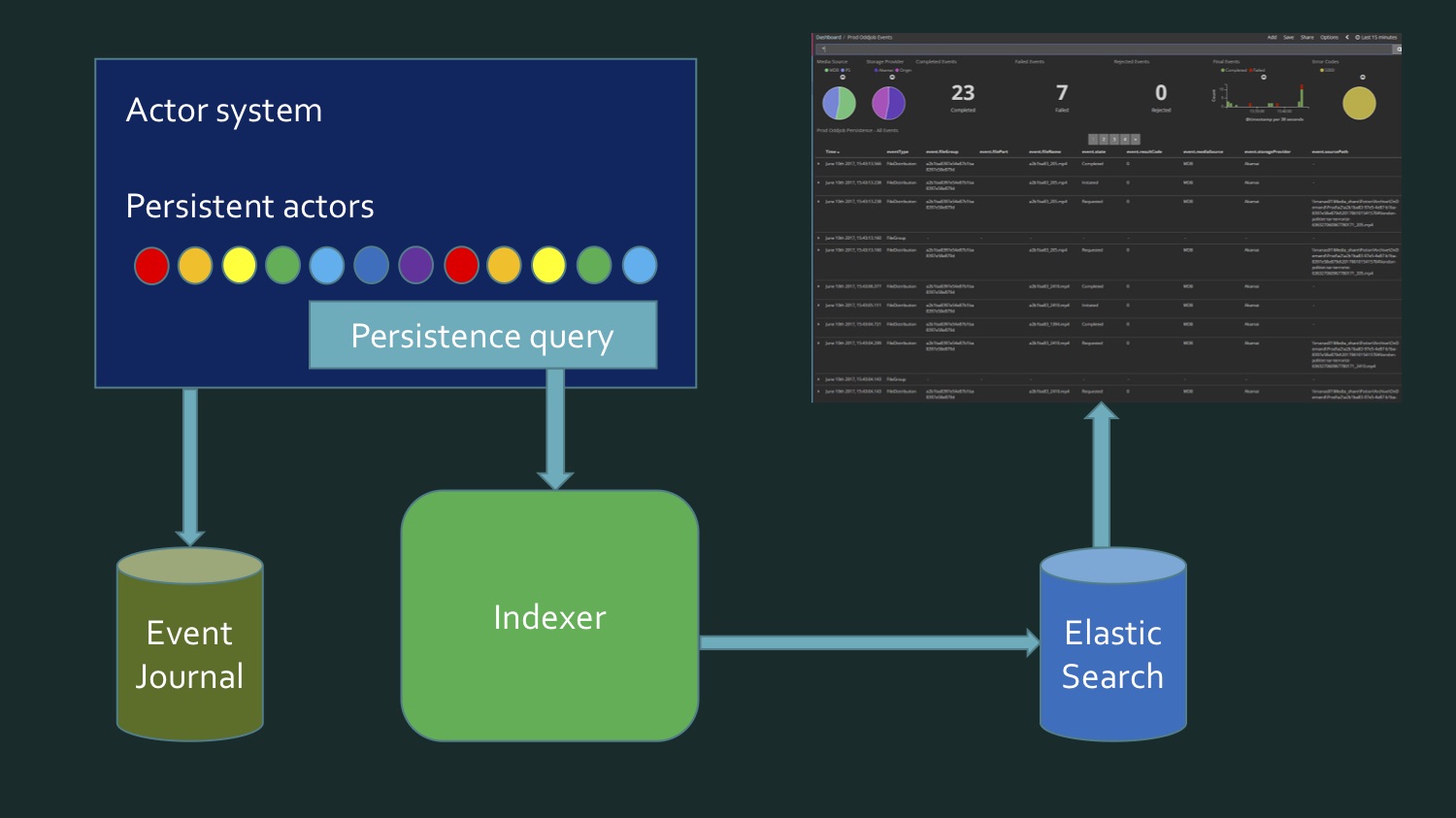
, , .
(persistence queries):
- AllPersistencelds
- CurrentPersistencelds
- EventsByPersistenceld
- CurrentEventsByPersistenceld
- EventsByTag
- CurrentEventsByTag
, , , Current — , . — . EventsByTag.
let system = mailbox.Context.System let queries = PersistenceQuery.Get(system) .ReadJournalFor<SqlReadJournal>(SqlReadJournal.Identifier) let mat = ActorMaterializer.Create(system) let offset = getCurrentOffset client config let ks = KillSwitches.Shared "persistence-elastic" let task = queries.EventsByTag(PersistenceUtils.anyEventTag, offset) .Select(fun e -> ElasticTypes.EventEnvelope.FromAkka e) .GroupedWithin(config.BatchSize, config.BatchTimeout) .Via(ks.Flow()) .RunForeach((fun batch -> processItems client batch), mat) .ContinueWith(handleStreamError mailbox, TaskContinuationOptions.OnlyOnFaulted) |> Async.AwaitTaskVoid
, . F#, C# . EventsByTag, Akka Streams, , Elasticsearch. . . - , , , — . .
. , , , , Twitter , — , , , . , Akka Streams.
:
Akka Scala, Akka.NET, , , , , . . - .
Tweetinvi — , Twitter, . Reactive Streams, . . , , , , - Akka, , .

, , . . Broadcast-. , , . : , , , , .
GitHub-,
AkkaStreamsDemo . (
).
Comencemos con uno simple. Twitter: Program.cs
var useCachedTweets = false
, Twitter, , . RunnableGraph.
public static IRunnableGraph<IActorRef> CreateRunnableGraph() { var tweetSource = Source.ActorRef<ITweet>(100, OverflowStrategy.DropHead); var formatFlow = Flow.Create<ITweet>().Select(Utils.FormatTweet); var writeSink = Sink.ForEach<string>(Console.WriteLine); return tweetSource.Via(formatFlow).To(writeSink); }
(
)
, . , , ( ) .
StartTweetStream — Tweetinvi.
public static void StartTweetStream(IActorRef actor) { var stream = Stream.CreateSampleStream(); stream.TweetReceived += (_, arg) => { arg.Tweet.Text = arg.Tweet.Text.Replace("\r", " ").Replace("\n", " "); var json = JsonConvert.SerializeObject(arg.Tweet); File.AppendAllText("tweets.txt", $"{json}\r\n"); actor.Tell(arg.Tweet); }; stream.StartStream(); }
(
)
CreateSampleStream , . , , , : « ». IEnumerable, .
TweetEnumerator : , Current, MoveNext, Reset, Dispose, . , . , . .
useCachedTweets true, . CashedTweets — , 50000 , , , . , , . — . , .
TweetsWithBroadcast:
var graph = GraphDsl.Create(b => { var broadcast = b.Add(new Broadcast<ITweet>(2)); var merge = b.Add(new Merge<string>(2)); b.From(broadcast.Out(0)) .Via(Flow.Create<ITweet>().Select(tweet => tweet.CreatedBy)) .Via(formatUser) .To(merge.In(0)); b.From(broadcast.Out(1)) .Via(Flow.Create<ITweet>().Select(tweet => tweet.Coordinates)) .Via(formatCoordinates) .To(merge.In(1)); return new FlowShape<ITweet, string>(broadcast.In, merge.Out); });
(
)
Scala, , DSL. Broadcast — out(0), out(1) — CreatedBy, , . .
— . .
var graph = GraphDsl.Create(b => { var broadcast = b.Add(new Broadcast<ITweet>(2)); var merge = b.Add(new Merge<string>(2)); b.From(broadcast.Out(0)) .Via(Flow.Create<ITweet>().Select(tweet => tweet.CreatedBy) .Throttle(10, TimeSpan.FromSeconds(1), 1, ThrottleMode.Shaping)) .Via(formatUser) .To(merge.In(0)); b.From(broadcast.Out(1)) .Via(Flow.Create<ITweet>().Select(tweet => tweet.Coordinates) .Buffer(10, OverflowStrategy.DropNew) .Throttle(1, TimeSpan.FromSeconds(1), 10, ThrottleMode.Shaping)) .Via(formatCoordinates) .To(merge.In(1)); return new FlowShape<ITweet, string>(broadcast.In, merge.Out); });}
(
)
10 , 10. , , , . , , Akka Streams Reactive Streams: . , , , , - . , , , . , . , , . Buffer(10, OverFlowStrategy.DropHead). , . 10 , . , , - , — - , , , , . . . , .
var graph = GraphDsl.Create(b => { var broadcast = b.Add(new Broadcast<ITweet>(2)); var merge = b.Add(new Merge<string>(2)); b.From(broadcast.Out(0)) .Via(Flow.Create<ITweet>().Select(tweet => tweet.CreatedBy) .Throttle(10, TimeSpan.FromSeconds(1), 1, ThrottleMode.Shaping)) .Via(formatUser) .To(merge.In(0)); b.From(broadcast.Out(1)) .Via(Flow.Create<ITweet>().Select(tweet => tweet.Coordinates) .Buffer(10, OverflowStrategy.DropNew) .Throttle(1, TimeSpan.FromSeconds(1), 10, ThrottleMode.Shaping)) .Via(Flow.Create<ICoordinates>().SelectAsync(5, Utils.GetWeatherAsync)) .Via(formatTemperature) .To(merge.In(1)); return new FlowShape<ITweet, string>(broadcast.In, merge.Out); });
(
)
, SelectAsync, . , , 5: , 5 , , . , , .
public static async Task<decimal> GetWeatherAsync(ICoordinates coordinates) { var httpClient = new HttpClient(); var requestUrl = $"http://api.met.no/weatherapi/locationforecast/1.9/?lat={coordinates.Latitude};lon={coordinates.Latitude}"; var result = await httpClient.GetStringAsync(requestUrl); var doc = XDocument.Parse(result); var temp = doc.Root.Descendants("temperature").First().Attribute("value").Value; return decimal.Parse(temp); }
(
)
. -, , - , HttpClient , XML, , .
,
, , . 10 10 , , .
, — , . , Akka Streams, , . , , .
, , , Akka Streams, . , , Akka Streams, C# , , , , .
 ¿Qué ideas sobre Akka Streams me gustaría que hicieras después de leer este artículo? En DotNext 2017 Moscú estuve en una presentación de Alex Thyssen
¿Qué ideas sobre Akka Streams me gustaría que hicieras después de leer este artículo? En DotNext 2017 Moscú estuve en una presentación de Alex Thyssen Azure Functions. - , deployment, , ( - , , ), . , , , . , , Akka Streams, .. , . .
Akka Streams , , , , , . , , , , , . Akka Streams — , , .
, Akka Streams, «Akka Stream Rap».
, .
This is the Akka Stream.
This is the Source that feeds the Akka Stream.
This is the MapAsync that maps from the Source that feeds the Akka Stream.
This is the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
This is the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
This is the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Streams.
This is the Balance that splits the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
This is the Zip that combines from the Balance that splits the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
This is the Drop that removes from the Zip that combines from the Balance that splits the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
This is TakeWhile that pulls from the Drop that removes from the Zip that combines from the Balance that splits the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
This is the Throttle that speeds down the TakeWhile that pulls from the Drop that removes from the Zip that combines from the Balance that splits the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
This is the Bidiflow that turns back the Throttle that speeds down the TakeWhile that pulls from the Drop that removes from the Zip that combines from the Balance that splits the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the source that feeds the Akka Streams.
This is the Sink that is filled from the Bidiflow that turns back the Throttle that speeds down the TakeWhile that pulls from the Drop that removes from the Zip that combines from the Balance that splits the FilterNot that selects from the Merge that collects from the Broadcast that forks the MapAsync that maps from the Source that feeds the Akka Stream.
. — 22-23
DotNext 2018 Moscow , .
( ).