Del 19 al 21 de abril, se celebró la conferencia C ++ Rusia 2018 en San Petersburgo. De año en año, la organización y la conducta se elevan un nivel más, lo cual es una buena noticia. Gracias al organizador permanente de C ++ Rusia Sergey Platonov por su contribución al desarrollo de esta área.
El 19 de abril, se planificaron clases magistrales, que desafortunadamente no pudimos asistir, y del 20 al 21 se llevó a cabo el programa principal de la conferencia, en el que participamos con gran interés. Sergey
Sermp hizo un gran trabajo y atrajo a varios oradores extranjeros notables como oradores. El primer día de la conferencia fue inaugurado por Jon Kalb, el organizador de CppCon y autor de C ++ Today: The Beast is Back. El segundo día comenzó con una presentación de Daveed Vandevoorde, miembro del comité de estandarización, uno de los autores de C ++ Templates: The Complete Guide. Andrei Alexandrescu estaba en el centro de atención, quien, después de su informe sobre excepciones, en un momento reunió a toda una multitud de personas que querían obtener un autógrafo y tomar una foto conjunta. Por primera vez, se transmitió una charla de Herb Sutter en Skype sobre el operador de la nave espacial para C ++ 20.
Aunque la conferencia tuvo lugar hace más de 3 meses, el video (
lista de reproducción completa ) se publicó en este momento, por lo que es hora de refrescar sus recuerdos y sumergirse en las increíbles características de C ++.
Esta charla cubre por qué los ingenieros que buscan rendimiento eligen C ++. Jon presenta una perspectiva histórica de C ++ centrándose en lo que está sucediendo en la comunidad de C ++ en este momento y hacia dónde se dirige el lenguaje y su base de usuarios. Con un renovado interés en el rendimiento tanto para los centros de datos como para los dispositivos móviles, y el éxito de las bibliotecas de software de código abierto, C ++ ha vuelto y está de moda. Esta charla explica por qué C ++ es el lenguaje más utilizado por los ingenieros de software para el rendimiento. Recibirá un esbozo histórico aproximado que pone a C ++ en perspectiva y cubre sus altibajos de popularidad.

Los pares de iteradores son ubicuos en toda la biblioteca de C ++. En general, se acepta que la combinación de un par de este tipo en una sola entidad, generalmente denominada Rango, proporciona un código más conciso y legible. Sin embargo, definir la semántica precisa de dicho concepto de Range resulta sorprendentemente complicado. Las consideraciones teóricas entran en conflicto con las prácticas. Algunos objetivos de diseño son totalmente incompatibles entre sí.
Todos somos conscientes de que debemos conocer los algoritmos STL. Incluirlos en nuestros diseños nos permite hacer que nuestro código sea más expresivo y más robusto. Y a veces, de manera espectacular.
¿Pero conoces tus algoritmos STL?
En esta charla, el autor presenta 105 algoritmos que el STL tiene actualmente, incluidos los agregados en C ++ 11 y C ++ 17. Pero más que una simple lista, el objetivo de esta charla es presentar los diferentes grupos de algoritmos, los patrones que forman en el STL y cómo se relacionan los algoritmos.
Este tipo de panorama general es la mejor manera de recordarlos a todos, y constituye una caja de herramientas repleta de maneras de hacer que nuestro código sea más expresivo y más robusto.
¿Alguna vez quisiste modificar algún valor o ejecutar alguna declaración mientras tu programa C ++ se está ejecutando solo para probar algo, no es trivial o posible con un depurador? Los lenguajes de script tienen un REPL (read-eval-print-loop). Lo más parecido a C ++ es la adherencia (desarrollada por investigadores del CERN) pero está construida sobre LLVM y es muy engorrosa de configurar. RCRL (Read-Compile-Run-Loop) es un proyecto de demostración que muestra un enfoque innovador para hacer la compilación en tiempo de ejecución de C ++ en una plataforma y compilador de manera agnóstica que se puede incrustar fácilmente. En esta presentación, se muestra cómo usarlo, cómo funciona y cómo se puede modificar e integrar en cualquier aplicación y flujo de trabajo.

¿No sería bueno si tuviéramos un tipo C ++ estándar para representar cadenas? Oh, espera ... hacemos: std :: string. ¿No sería bueno si pudiéramos usar ese tipo estándar en toda nuestra aplicación / proyecto? Bueno ... no podemos! A menos que estemos escribiendo una aplicación de consola o un servicio. Pero, si estamos escribiendo una aplicación con GUI o interactuando con API modernas del sistema operativo, es probable que debamos tratar con al menos otro tipo de cadena de C ++ no estándar. Dependiendo de la plataforma y el proyecto, puede ser CString desde MFC o ATL, Platform :: String desde WinRT, QString desde Qt, wxString desde wxWidgets, etc. Oh, no olvidemos a nuestro viejo amigo const char *, mejor aún const wchar_t * para la familia C de API ...
Así que terminamos con dos tipos de cadenas en nuestra base de código. OK, eso es manejable: nos quedamos con std :: string para todo el código independiente de la plataforma y convertimos de un lado a otro a XString cuando interactuamos con las API del sistema o el código GUI. Haremos algunas copias innecesarias al cruzar este puente y terminaremos con algunas funciones divertidas que hacen malabares con dos tipos de cadenas; pero ese es el código de pegamento, de todos modos ... ¿verdad?
Es un buen plan ... hasta que nuestro proyecto crezca y acumulemos muchas utilidades de cadena y algoritmos. ¿Restringimos esas ventajas algorítmicas a std :: string? ¿Recurrimos al denominador común const char * y perdemos la seguridad de tipo / memoria de nuestro tipo C ++? ¿Es C ++ 17 std :: string_view la respuesta a todos nuestros problemas de cadena?
El autor intenta explorar las opciones, junto con un estudio de caso en una aplicación de Windows de 15 años: Advanced Installer (www.advancedinstaller.com), un proyecto C ++ desarrollado activamente, modernizado a C ++ 17, gracias a clang-tidy y "Clang Power Tools" (
www.clangpowertools.com) ...
Escribir código que sea resistente a los errores siempre ha sido un punto crítico en todos los idiomas. Las excepciones son los medios políticamente correctos para señalar errores en C ++, pero muchas aplicaciones aún recurren a códigos de error por razones relacionadas con la facilidad de comprensión, la facilidad para manejar errores localmente y la eficiencia del código generado.
Esta charla muestra cómo una variedad de artefactos teóricos y prácticos se pueden combinar para abordar códigos de error y excepciones en un paquete simple y saludable. El tipo genérico Expected se puede usar para modales locales (estilo de código de error) y centralizados (estilo de excepción), basándose en las fortalezas de cada uno.

El software con una lógica empresarial muy compleja, como juegos, sistemas CAD y sistemas empresariales, a menudo necesita componer y modificar objetos en tiempo de ejecución, por ejemplo, para agregar o anular un método en un objeto existente. El estándar C ++ tiene tipos rígidos que se definen en tiempo de compilación y lo hacen difícil. Por otro lado, los lenguajes con tipos dinámicos como lua, Python y JavaScript lo hacen muy fácil. Por lo tanto, para mantener el código legible y mantenible, y cumplir con los complejos requisitos de lógica de negocios, muchos proyectos usan dichos lenguajes junto con C ++. Algunos inconvenientes de este enfoque incluyen la complejidad adicional en una capa de enlace de lenguaje, la pérdida de rendimiento por usar un lenguaje interpretado y la duplicación de código inevitable para muchas funcionalidades de utilidad pequeñas.
DynaMix es una biblioteca que intenta eliminar, o al menos reducir en gran medida, la necesidad de un lenguaje de script separado al permitir a los usuarios componer y modificar objetos polimórficos en tiempo de ejecución en C ++. Esta charla desarrolla este problema e introduce la biblioteca y sus características clave a usuarios o personas potenciales que podrían beneficiarse del enfoque con un ejemplo anotado y una pequeña demostración.

En C ++, puede resolver una sola tarea de varias maneras. El autor elige una tarea real de la producción e investiga cómo se puede resolver con una serie de herramientas que proporciona C ++: contenedores STL, boost.range, rangos C ++ 20, rutinas. También compara las restricciones API y el rendimiento de diferentes soluciones, y cómo se pueden convertir fácilmente de una a otra si el código está bien estructurado. Durante el proceso, el autor también explora aplicaciones de algunas características útiles de C ++ 17 como constexpr if, sentencias de selección con inicializador, std :: not_fn, etc. Se presta especial atención al tema: algoritmos estándar.

La programación paralela es un tema muy polifacético y profundo. A lo largo de las décadas de investigación, se han desarrollado una gran cantidad de enfoques, prácticas y herramientas, pero difícilmente podemos suponer que el lenguaje C ++ se mantuvo al día con estas tendencias. Comenzando con el estándar C ++ 11, se introdujeron conceptos como std :: thread, std :: atomic, std :: future, std :: mutex, y en el futuro se espera que se agreguen rutinas, un modelo de cálculos asincrónicos. Bueno, todas estas son cosas interesantes para estudiar, pero el informe se centrará en una idea completamente diferente.
La memoria transaccional de software (STM), el concepto de un modelo de datos transaccionalmente mutable, existe desde hace mucho tiempo y tiene varias implementaciones para todos los idiomas. Con STM, expresa su modelo de datos y comienza a cambiarlo a través de múltiples subprocesos, de manera competitiva, sin tener que preocuparse por la sincronización de subprocesos, el estado válido de los datos o los bloqueos. STM hará todo por ti. Esto suena muy bien, pero no todas las bibliotecas STM son igualmente útiles. Los STM imperativos tradicionales son muy complejos, propensos a errores multiproceso no triviales y difíciles de usar. Por otro lado, en el mundo de la programación funcional, el concepto de STM combinatorio ha existido durante mucho tiempo, transacciones en las que son ladrillos componibles, a partir de los cuales se construyen transacciones de un nivel superior. El enfoque combinatorio de STM le permite expresar un modelo de datos competitivo de manera más flexible, clara y confiable. ¡La programación paralela también puede ser agradable!
En el informe, el autor hablará sobre las características del STM combinatorio, cómo usarlo y cómo se puede implementar en C ++ 17.

A lo largo de toda la historia de la programación, el procesamiento secuencial por elementos de varios tipos de colecciones ha sido y sigue siendo una de las tareas prácticas más comunes. La representación interna de las colecciones, así como el algoritmo utilizado para recuperar elementos posteriores, pueden variar en un rango muy amplio: matriz, lista vinculada, árbol, tabla hash, archivo y otros. Sin embargo, detrás de la variedad de expresiones idiomáticas, funciones de biblioteca estándar, soluciones ad-hoc, uno puede revelar la esencia que permanece invariable para toda esa clase de tareas. Esta charla tiene como objetivo mostrar una transición paso a paso de algoritmos basados en la descripción explícita de acciones sobre elementos individuales hacia herramientas de procesamiento declarativo de alto nivel que tratan a una colección como una entidad y revelan adecuadamente la lógica del dominio.
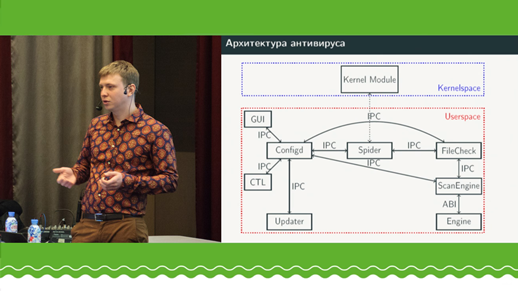
El autor contará sobre su experiencia en el desarrollo de un motor antivirus en C ++ en forma de una biblioteca compartida. Una característica única es la ausencia de dependencias externas (tiempo de ejecución C ++ o C). Todo este grupo se basa en el uso de una cadena de herramientas personalizada en GCC para un objetivo especial, que libc newlib va a usar para el mismo objetivo, además del cual se construye libstdc ++. En consecuencia, la biblioteca compartida se ensambla a través de una cadena de herramientas personalizada con libgcc_s, libc, libcstdc ++ (cambios solo en el ensamblaje). Toda interacción con el tiempo de ejecución es a través de la biblioteca compartida ABI. Por lo tanto, la biblioteca conserva la capacidad de usar C ++ moderno sin restricciones (RTTI, excepciones, iostream, etc.), que va a libstdc ++ libc (newlib) | l ibgcc-ABI. Se probó un enfoque similar en las cadenas de herramientas GCC / newlib / libstdc ++ para Linux y clang / newlib / libc ++ para MacOS. El informe puede ser de interés para aquellos que desean usar C ++ en bibliotecas compartidas, pero no pueden permitírselo debido a dependencias externas.

Durante el último año y medio, el autor ha liderado la creación de la especialización Coursera en C ++ moderno. La especialización consistirá en cinco cursos, dos de los cuales ya están en ejecución, y otro está casi listo.
El informe dirá:
- qué problemas se pueden encontrar al trabajar en cursos (por ejemplo, después de 3 meses de trabajo, los desarrolladores tiraron todos los materiales y comenzaron de nuevo)
- cómo se forma el plan de estudios y por qué exactamente (por ejemplo, por qué la palabra "puntero" no sonó en los primeros dos cursos ni siquiera una vez)
Además, durante el trabajo de especialización, se ha desarrollado un conjunto de principios que son aplicables en el trabajo diario:
- en el proceso de integrar a un nuevo empleado en el proyecto
- durante la revisión de código
- al contratar
Por lo tanto, el autor no solo quiere decir cómo hacen la especialización, sino que también intentará transferir la experiencia adquirida a las tareas cotidianas.
No es ningún secreto que el desarrollo en C / C ++ tiene requisitos mucho más altos para la calidad del código que el desarrollo en Java. La probabilidad de cometer un error fatal es mucho mayor. Al mismo tiempo, recopilar información sobre tales errores es una tarea no trivial incluso para programadores experimentados.
En la primera parte del informe, revisaremos brevemente los desarrollos existentes: cómo funciona el depurador de Android incorporado, qué soluciones ya existen. La segunda parte está dedicada a la historia de cómo funciona "bajo el capó": cómo obtener el estado del procesador en el momento del error, cómo desenrollar la pila de llamadas, cómo encontrar los números de línea en el código fuente. Se proporcionará una descripción general de las bibliotecas de promoción de pila, como libcorkscrew, libunwind, libunwindstack.
El informe será de interés tanto para los desarrolladores de Android, cuyas aplicaciones usan NDK, como para todos los demás para ampliar sus horizontes.
int * ptr = nuevo int;
* ptr = 42;
eliminar ptr;
¿Qué sucede realmente cuando se ejecutan estas 3 líneas de código? Examinaremos el asignador de memoria, el sistema operativo y el hardware moderno para dar una respuesta exhaustiva a esta pregunta.
En 2017, la cuestión de elegir un asignador en C ++ no pierde relevancia. Agregaron una nueva forma al estándar para elegir un asignador local para contenedores (std :: pmr), tcmalloc global y jemalloc continúan evolucionando, así como las interfaces del núcleo en las que confían. Este informe está dedicado al "piso inferior" de este diseño: las características de mmap y madvise en el kernel de Linux y el impacto de estas características en el rendimiento de los asignadores.

La nueva nave espacial fue adoptada recientemente como una función de lenguaje para C ++ 20. En esta charla, el diseñador y autor de la propuesta de la nave espacial ofrece una visión general de la característica, discute su motivación y diseño, y muestra ejemplos de cómo usarla. Él pone un énfasis particular en cómo la función hace que el código C ++ sea más limpio para escribir y leer, más rápido al evitar el trabajo redundante y más robusto al evitar varias dificultades importantes pero sutiles en el código más frágil que anteriormente teníamos que escribir a mano sin esta función.

Cuando observa las plantillas, la reflexión, la generación de código en la etapa de compilación, las metaclases, tiene la sensación de que C ++ se ha propuesto la tarea de "ocultar" el código final del desarrollador tanto como sea posible. Un uso no trivial del preprocesador (y numerosas ramas) puede hacer que la secuencia del programa sea muy obvia. Por supuesto, estos enfoques salvan a los desarrolladores de copiar y pegar sin fin y la repetición de partes similares de la base de código, pero requieren un soporte más avanzado en herramientas de desarrollo.
¿Es posible depurar código sin reiniciarlo continuamente, sin un depurador e incluso sin una simple compilación de toda la base de código? ¿Es posible encontrar errores en el código que no se pueden ensamblar o ejecutar en la máquina local? Hay! Los entornos de desarrollo integrado (IDE) tienen un amplio conocimiento y comprensión del código personalizado, y son ellos quienes pueden proporcionar las herramientas adecuadas.
Este informe mostrará cómo uno podría "depurar" las sustituciones de macros anidadas por typedef, comprender los tipos de variables (que en C ++ moderno a menudo están "ocultas"), depurar diferentes ramas de la sobrecarga del preprocesador u operador, y mucho más con la ayuda de un sistema verdaderamente inteligente IDE Algunas de las funciones ya están disponibles en CLion y ReSharper C ++, y algunas son solo ideas interesantes para el futuro, que sería interesante discutir con la audiencia.

El ensamblaje de un proyecto C ++ se puede mover dentro del contenedor acoplable, mientras que en lugar de instalar las bibliotecas y dependencias necesarias en el sistema host, se pueden instalar directamente en la imagen acoplable (por ejemplo, Cuda) o instalar usando el administrador C ++ de la biblioteca Conan (por ejemplo, Boost). Esto da como resultado un entorno controlado aislado (y cada vez el mismo) para el ensamblaje, en el que puede conectar el caché de Conan, por lo que diferentes proyectos que usan las mismas bibliotecas usarán los mismos ensamblajes. Además, la compilación ya no depende de la distribución de Linux donde se está construyendo el proyecto, lo principal es que puede ejecutar Docker en esta distribución.

En el curso del informe, escribiremos una pequeña biblioteca de trabajo con std :: tuple. Usando esta biblioteca, compilamos el tiempo de compilación en una tabla hash heterogénea. Además, sobre esta base, escribiremos un pequeño marco RPC, utilizando el hecho de que no tenemos borrado de tipo.
Habrá muchos cálculos de constexpr, plantillas y nuevas características en C ++ 17 (específicamente, si constexpr).
A menudo se necesita reflexión para generalizar los algoritmos de serialización. Implementación de varios protocolos, trabajo con bases de datos. Para resolver estos problemas, escribimos un compilador IDL casero para generar estructuras C ++ y una biblioteca para interactuar con el resultado. Protobuf con pedales y si valió la pena.
Hace algún tiempo, el comité de estandarización de C ++ creó un subgrupo "SG-7" para explorar cómo agregar capacidades de reflexión al lenguaje. Más recientemente, ese grupo ha agregado "metaprogramación" a su plato y ha tomado algunas decisiones importantes con respecto a la forma de la solución final. En esta charla, el autor analiza el pasado que nos trajo aquí y examina un posible camino para el soporte de primera clase de C ++ de la "metaprogramación reflexiva".
Con los conceptos que se agregan a la próxima revisión de C ++, se espera que se definan nuevos conceptos. Cada concepto define un conjunto de operaciones utilizadas por el código genérico. Uno de estos usos podría ser una prueba genérica que verifique que todas las partes de un concepto estén definidas y que verifique las interacciones genéricas entre las operaciones de un concepto. Idealmente, tal prueba incluso funciona con clases que solo modelan parcialmente un concepto para guiar la implementación de las clases.
Esta presentación no utiliza las extensiones de concepto reales, pero muestra cómo se pueden crear pruebas genéricas utilizando las características de C ++ 17. Para las pruebas genéricas, el idioma de detección y constexpr se usan para determinar la disponibilidad de las operaciones requeridas y tratar con gracia la ausencia de operaciones. Las pruebas genéricas deberían poder cubrir los conceptos básicos de las clases que modelan un concepto. Obviamente, el comportamiento específico para las clases aún requerirá las pruebas correspondientes.

La programación paralela se puede utilizar para aprovechar las arquitecturas heterogéneas y de múltiples núcleos y puede aumentar significativamente el rendimiento del software. C ++ moderno ha recorrido un largo camino para hacer que la programación paralela sea más fácil y más accesible; proporcionando abstracciones de alto y bajo nivel. C ++ 17 lleva esto más lejos al proporcionar algoritmos paralelos de alto nivel, y se espera mucho más en C ++ 20. Esta charla ofrece una visión general de las utilidades de paralelismo actuales disponibles, y mira hacia el futuro de cómo las GPU y los sistemas heterogéneos pueden ser soportados a través de nuevas características de biblioteca estándar y otros estándares como SYCL.
El lenguaje C ++ y la infraestructura que lo rodea continúa evolucionando, lo que hace que este lenguaje sea una de las herramientas más efectivas en la actualidad. Me gustaría destacar tres factores que hacen que el lenguaje C ++ ahora sea tan atractivo.
- Primero: innovaciones en el lenguaje estándar, lo que le permite escribir código eficiente.
- Segundo: la madurez de las herramientas de desarrollo y un aumento en la velocidad de ensamblaje de proyectos.
- Tercero: herramientas de soporte maduras que le permiten controlar la calidad del código y otros aspectos del ciclo de vida del proyecto.
¡Este informe es una oda al lenguaje de programación C ++!
En el campo del desarrollo de aplicaciones multiproceso o distribuidas altamente cargadas, uno puede escuchar cada vez más conversaciones sobre el código asincrónico, incluida la especulación sobre la necesidad (falta de necesidad) de tener en cuenta la asincronía en el código, sobre la comprensibilidad (incomprensibilidad) del código asincrónico y su eficiencia (ineficiencia). En este informe, trataremos de profundizar en el área temática: analizaremos lo que es asincronía; cuando surge; cómo afecta el código que escribimos y el lenguaje de programación que usamos. Trataremos de averiguar qué futuros y promesas tienen que ver con eso, hablemos un poco sobre las corutinas y los actores. Afectaremos a JavaScript y a los sistemas operativos. El propósito del informe es hacer que los compromisos que surgen con uno u otro enfoque para el desarrollo de software multiproceso o distribuido sean más explícitos.

El informe discutirá el estado actual de WebAssembly en relación con productos reales. Hablaremos sobre nuestra experiencia de portar la aplicación, sobre qué problemas surgieron y cómo los resolvimos.
Los temas cubiertos incluyen:
- Soporte para el estándar en diferentes plataformas y navegadores.
- Rendimiento y tamaño de compilación versus asm.js.
- Interacciones con el navegador.
- Crea bloqueos del usuario.
- Características de VM.
El sistema de compilación CMake se está convirtiendo gradualmente en el estándar de facto para la programación C ++ multiplataforma. Sin embargo, a menudo se le critica de manera justa, incluso por el lenguaje de secuencias de comandos inconveniente, la documentación obsoleta y el hecho de que las mismas tareas se pueden realizar de diferentes maneras, y puede ser bastante difícil entender cuál es más correcto en una situación particular . El autor dirá:- antipatrones populares frecuentes y por qué son malos,
- a qué niveles de abstracción funciona CMake, y cuándo se “filtran”,
- ¿Qué es "CMake moderno" y cuáles son sus ventajas?
- cómo localizar y depurar problemas en scripts CMake (incluidos algunos bastante exóticos).
La arquitectura limpia del proyecto, las abstracciones simples en cada capa es el sueño de cualquier equipo. Para realizar este sueño, se han inventado muchas técnicas orientadas a objetos. Llevado por OOP, los desarrolladores olvidan monitorear la limpieza del código en la unión de C y C ++. Es aquí donde el estilo de procedimiento ayudará a restaurar el orden, crear abstracciones convenientes y seguras que se ajusten fácilmente al código orientado a objetos del proyecto. Descubriremos:- ¿Por qué necesita aislar la API de C (como winapi, POSIX, SQLite, OpenGL, OpenSSL)
- ¿Por qué OOP funciona mal en este negocio?
- cómo escribir una capa de abstracción en la parte superior de la API de estilo C
- cómo lidiar con las devoluciones de llamada, el manejo de errores y la administración de recursos para hacer que el código tradicionalmente complejo y confuso sea comprensible incluso para un junior
Sus intereses profesionales son la semántica de los lenguajes de programación, el diseño y la implementación de compiladores de PL y otras herramientas orientadas al lenguaje. Entre los logros más significativos se encuentran la participación en proyectos como la creación de un compilador del estándar completo del lenguaje C ++ (Interstron, Moscú, 2000), la implementación del compilador del lenguaje Zonnon para .NET (ETH Zurich, 2005) y la implementación del compilador prototipo Swift para la plataforma Tizen ( Samsung Research Institute, Moscú, 2015).C ++ siempre ha tenido un potente sub-lenguaje de metaprogramación que permitió a los desarrolladores de bibliotecas realizar hazañas mágicas como la introspección estática para lograr la ejecución polimórfica sin herencia. El problema era que la sintaxis era incómoda e innecesariamente detallada, lo que hacía que aprender metaprogramación fuera una tarea desalentadora.Con las recientes mejoras al estándar, y con las características planificadas para C ++ 20, la metaprogramación se ha vuelto mucho más fácil, y los metaprogramas se han vuelto más fáciles de entender y razonar.En esta charla, el autor presenta algunas técnicas modernas de metaprogramación, con un enfoque principal en la metafunción mágica void_t.El autor del informe ha sido responsable del desarrollo del marco SObjectizer de código abierto durante 16 años. Este es uno de los pocos marcos de actores multiplataforma en vivo y en desarrollo para C ++. El desarrollo de SObjectizer comenzó en el año 2002, cuando C ++ estaba entre los lenguajes de programación más populares y comunes. En el pasado, C ++ ha cambiado mucho, y la actitud hacia C ++ ha cambiado aún más. El informe discutirá cómo estos cambios afectaron el desarrollo de una herramienta con una historia de 16 años y cuán simple y conveniente fue hacer una herramienta para el lenguaje C ++. Y si era necesario hacer una herramienta para C ++ en general.
- Practique usando el patrón Modelo-Vista-Presentador
- Gestión del ciclo de vida del documento
- Almacenamiento de archivos de punteros inteligentes
Las noticias sobre la próxima vulnerabilidad encontrada aparecen regularmente aquí y allá. Las pérdidas colaterales de $, como regla, son enormes. Por lo tanto, en lugar de corregir vulnerabilidades, no se debe permitir que aparezcan.
Una forma de lidiar con los errores en el código es usar análisis estático. Pero, ¿qué tan adecuado es buscar vulnerabilidades? ¿Y hay realmente una gran diferencia entre errores simples y vulnerabilidades de código?
Discutiremos estos problemas durante el informe y, al mismo tiempo, hablaremos sobre cómo usar el análisis estático para aprovecharlo al máximo.
PSPor mi cuenta, quiero llamar su atención sobre la mini intriga en torno a
std :: string relacionada con los informes de mi colega Andrei Karpov. Entonces, en orden:
- Un fragmento del informe de Andrei (C ++ Rusia 2016) "Historias privadas de desarrolladores de analizadores de código" de 30:05 - enlace .
- Anton Polukhin (C ++ Rusia 2017), trolling fácil de personas como nosotros, en el informe "Cómo no hacerlo: construcción de bicicletas C ++ para profesionales" a partir de las 2:00 - enlace .
- La historia de Andrey en la conferencia C ++ Rusia 2018 de que no somos dinosaurios y estamos aprendiendo algo nuevo: "C ++ efectivo" de 12:21 - enlace .
Eso es todo! Disfruta tus informes.