Nuestra empresa SberTech (Sberbank Technologies) actualmente usa HDFS 2.8.4 porque tiene una serie de ventajas, como el ecosistema Hadoop, el trabajo rápido con grandes cantidades de datos, es bueno en análisis y mucho más. Pero en diciembre de 2017, Apache Software Foundation lanzó una nueva versión del marco de código abierto para desarrollar y ejecutar programas distribuidos: Hadoop 3.0.0, que incluye una serie de mejoras significativas sobre la línea de lanzamiento principal anterior (hadoop-2.x). Una de las actualizaciones más importantes e interesantes para nosotros es el soporte de códigos de redundancia (Erasure Coding). Por lo tanto, la tarea se estableció para comparar estas versiones entre sí.
SberTech Company asignó 10 máquinas virtuales de 40 GB cada una para este trabajo de investigación. Dado que la política de codificación RS (10.4) requiere un mínimo de 14 máquinas, no funcionará probarla.
En una de las máquinas, NameNode se ubicará además del DataNode. Las pruebas se realizarán con las siguientes políticas de codificación:
- XOR (2.1)
- RS (3.2)
- RS (6.3)
Y también, usando la replicación con un factor de replicación de 3.
El tamaño del bloque de datos se eligió igual a 32 MB.
Investigación
Prueba de velocidad de datos
Se realizaron pruebas para las tasas de transferencia de datos. Los datos se transfirieron del sistema de archivos local al sistema de archivos distribuido. El tamaño del archivo utilizado en esta prueba es 292,2 MB.
Se obtuvieron los siguientes resultados:
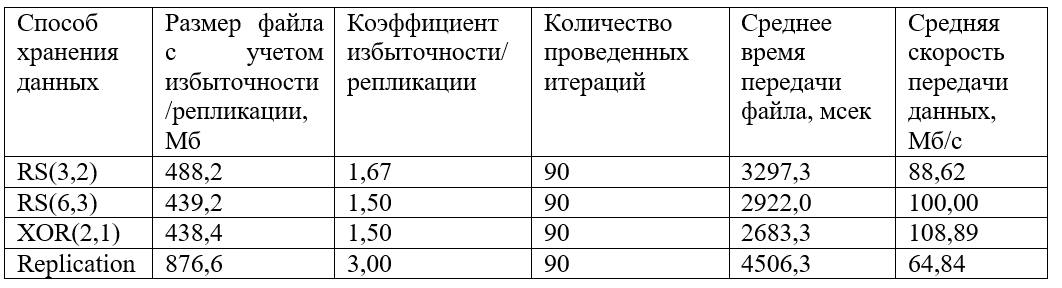
También se construye un gráfico de los valores recibidos agrupados del tiempo de transferencia de archivos:

Y también, un gráfico de velocidades de datos agrupados recibidos:
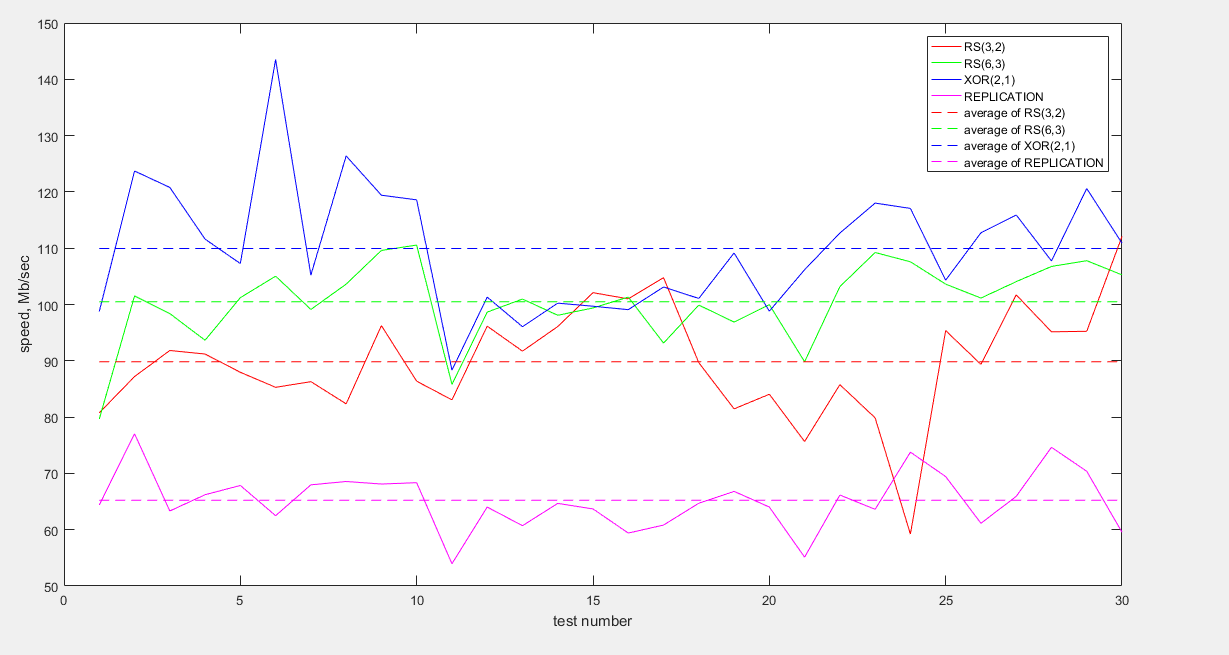
Como se puede ver en el gráfico, los datos más rápidos se transmiten codificados con XOR (2,1). Las codificaciones RS (6.3) y RS (3.2) muestran un comportamiento similar, aunque el valor de velocidad promedio para RS (6.3) es ligeramente mayor. La replicación pierde mucha velocidad (aproximadamente 1.5 veces menos que XOR y 1.5 veces menos que RS).
En cuanto a la eficiencia del almacenamiento, XOR (2.1) y RS (6.3) son los métodos de almacenamiento más rentables, los datos redundantes son solo del 50%. La replicación, con una relación de replicación de 3, pierde nuevamente, almacenando el 200% de los datos redundantes.
Prueba de rendimiento
En la prueba anterior, el estado de los servidores se monitoreó utilizando la herramienta de monitoreo Grafana.
A continuación se muestra un gráfico que muestra la carga de la CPU durante las pruebas de transferencia de datos:
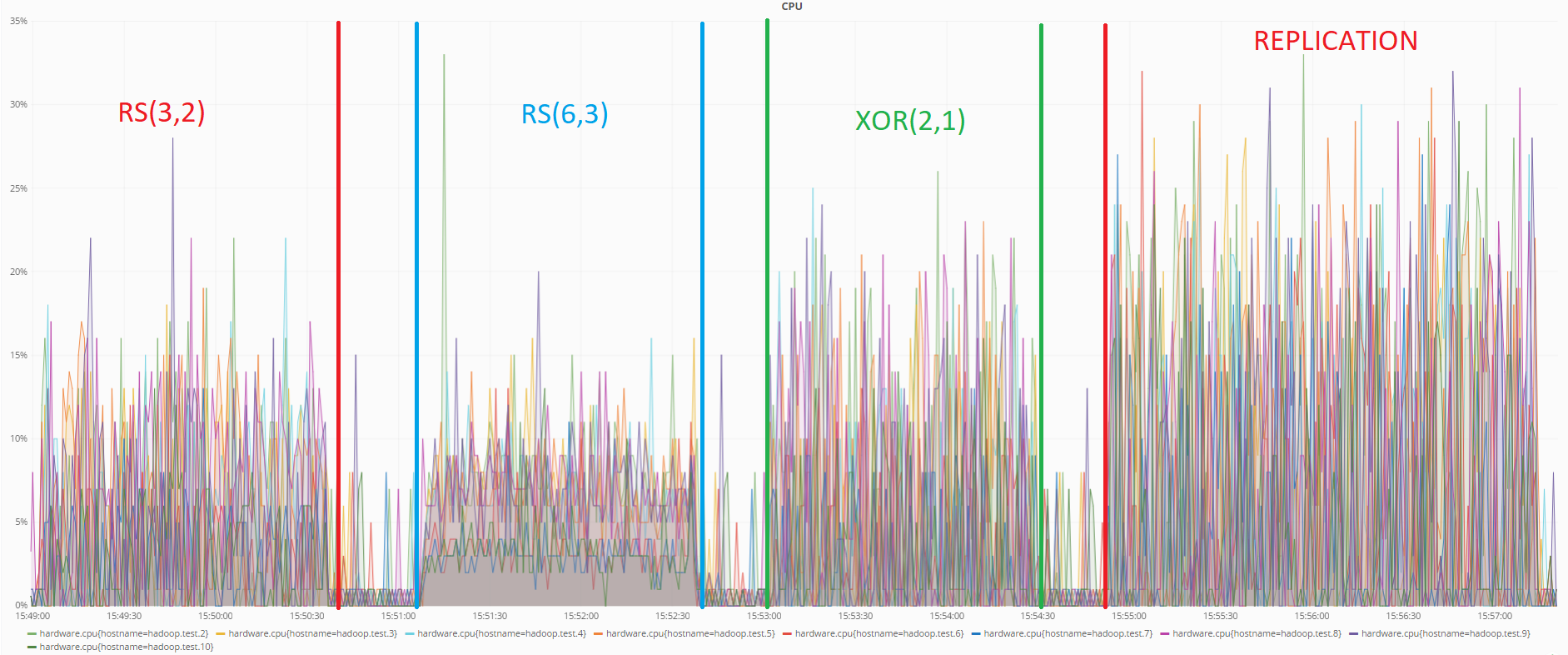
Como se puede ver en el gráfico, en esta prueba también la codificación RS (6.3) consume la menor cantidad de recursos. La replicación muestra nuevamente el peor resultado.
Consumo de recursos en recuperación de datos
Para realizar esta prueba, se cargó una cierta cantidad de datos en el sistema de archivos distribuido de Hadoop. Luego se omitieron dos máquinas con un DataNode.
A continuación se muestran gráficos del estado de las máquinas en el momento de la recuperación de datos con codificación RS (6.3) y cuando se usa la replicación:
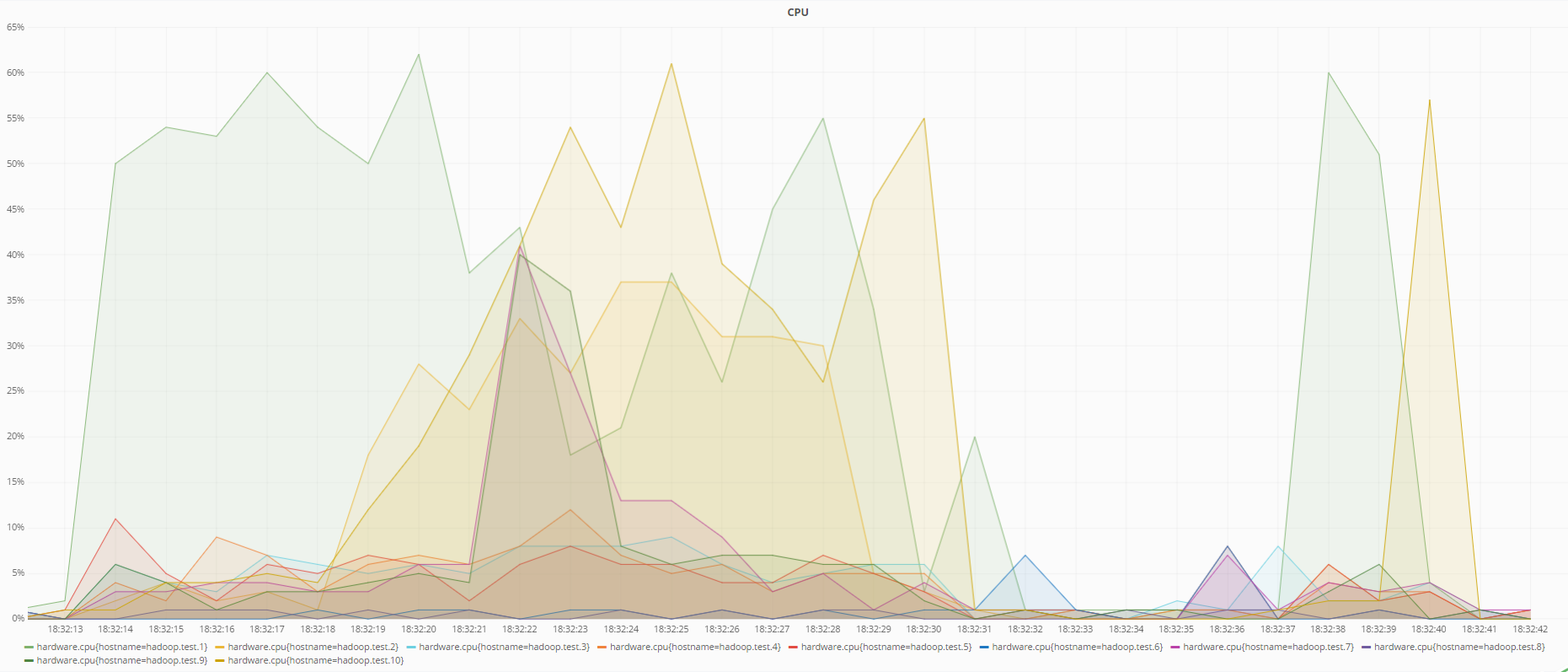
Estado del procesador durante la recuperación de datos mediante codificación RS (6.3)

Estado de la CPU durante la recuperación de datos mediante la replicación
Como se puede ver en los gráficos, la codificación RS (6.3) carga el procesador más que la replicación durante la recuperación de datos, lo cual es lógico, porque para recuperar datos perdidos utilizando códigos redundantes, es necesario calcular la matriz de redundancia inversa, que consume más recursos que simplemente sobrescribir datos de otro DataNode en caso de replicación.
Resultados de la prueba:
- Para velocidades de transferencia de datos, es mejor usar codificación XOR (2.1) o RS (6.3)
- Al transmitir datos, el procesador carga menos la codificación RS (6.3) y RS (3.2)
- Al restaurar los datos, el procesador está menos estresado por el uso de la replicación.
- La forma más compacta de almacenar datos son las codificaciones RS (6.3) y XOR (2.1)
El método de almacenamiento más confiable es la codificación RS (6.3), ya que le permite perder hasta tres máquinas sin pérdida de datos, y la replicación con un coeficiente de replicación de 3 admite fallas de hasta 2 máquinas. XOR (2, 1) es la forma más poco confiable de almacenar datos, ya que le permite perder un máximo de una máquina.
Conclusión
Los objetivos principales del uso del sistema de archivos distribuido en SberTech son:
- Alta fiabilidad
- Minimizar el costo de mantenimiento de servidores para el almacenamiento de datos.
- Proporcionar herramientas de análisis de datos.
En base a los resultados del análisis, se hacen las siguientes conclusiones:
- HDFS 3 supera la confiabilidad sobre HDFS 2.
- HDFS 3 gana al minimizar los costos de mantenimiento del servidor porque almacena los datos de manera más compacta.
- HDFS 3 tiene el mismo conjunto de herramientas de análisis de datos que HDFS 2.
En este sentido, se concluyó que HDFS 3 es un reemplazo racional para HDFS 2.
Fuentes utilizadas: