Hola Mi nombre es Denis Kiryanov, trabajo en Sberbank y me ocupo de los problemas del procesamiento del lenguaje natural (PNL). Una vez que necesitábamos elegir un analizador sintáctico para trabajar con el idioma ruso. Para hacer esto, profundizamos en la naturaleza de la morfología y la tokenización, probamos diferentes opciones y evaluamos su aplicación. Compartimos nuestra experiencia en esta publicación.

Preparación para la selección
Comencemos con lo básico: ¿cómo funciona? Tomamos el texto, realizamos tokenización y obtenemos una serie de pseudo-tokens. Las etapas de análisis posteriores se ajustan a una pirámide:
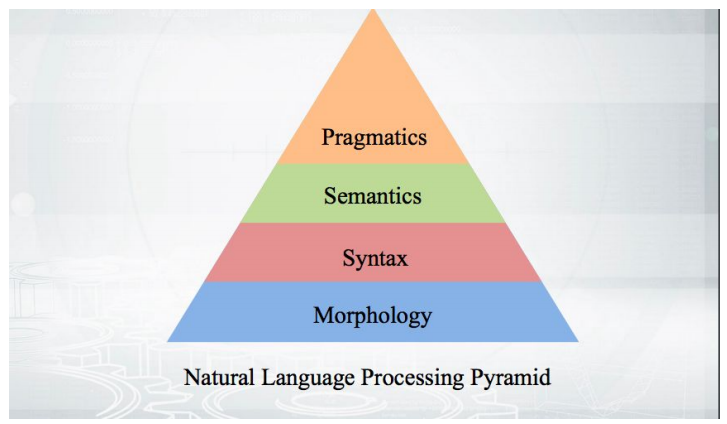
Todo comienza con la morfología, con un análisis de la forma de una palabra y sus categorías gramaticales (género, caso, etc.). La morfología se basa en la sintaxis: relaciones más allá de los límites de una palabra, entre palabras. Los analizadores sintácticos que se discutirán, analizarán el texto y darán a conocer la estructura de las dependencias de las palabras entre sí.
Gramática de dependencias y gramática de los componentes inmediatos.
Hay dos enfoques principales para analizar, que en teoría lingüística existen en igualdad de condiciones.

En la primera línea, la oración se analiza como parte de la gramática de dependencia. Este enfoque se enseña en la escuela. Cada palabra en una oración está de alguna manera conectada con otras. “Jabones”: un predicado del que depende la materia “madre” (aquí la gramática de las dependencias diverge de la escuela, donde el predicado depende de la materia). El sujeto tiene una definición dependiente de "mío". El predicado tiene un "marco" complementario directo dependiente. Y la adición directa al "marco" - la definición de "sucio".
En la segunda línea, el análisis está de acuerdo con la gramática de los componentes mismos.
Según ella, la oración se divide en grupos de palabras (frases). Las palabras dentro de un grupo están más estrechamente relacionadas. Las palabras "mi" y "madre" están más estrechamente relacionadas, "marco" y "sucio" - también. Y todavía hay un "jabón" separado.
El segundo enfoque para el análisis automático del idioma ruso es poco aplicable, porque en él las palabras estrechamente relacionadas (miembros del mismo grupo) a menudo no se colocan en una fila. Tendríamos que combinarlos con paréntesis extraños, en una o dos palabras. Por lo tanto, en el análisis automático del idioma ruso, se acostumbra trabajar en función de la gramática de las dependencias. Esto también es conveniente porque todos están familiarizados con ese "marco" en la escuela.
Árbol de dependencia
Podemos traducir un conjunto de dependencias en una estructura de árbol. La parte superior es la palabra "jabón", algunas palabras dependen directamente de ella, otras dependen de sus adictos. Aquí está la
definición del árbol de dependencia del libro de texto de Martin y Zhurafsky:
El árbol de dependencia es un gráfico dirigido que satisface las siguientes restricciones:- Hay un único nodo raíz designado que no tiene arcos entrantes.
- Con la excepción del nodo raíz, cada vértice tiene exactamente un arco entrante.
- Hay una ruta única desde el nodo raíz a cada vértice en V.
Hay un nodo de nivel superior: un predicado. Desde allí puedes llegar a cualquier palabra. Cada palabra depende de otra, pero solo de una. El árbol de dependencias se parece a esto:

En este árbol, los bordes se firman con algún tipo especial de relación sintáctica. En la gramática de las dependencias, no solo se analiza el hecho de la conexión entre palabras, sino también la naturaleza de esta conexión. Por ejemplo, "se toma" es casi una forma verbal, "inventario" es el tema de "se toma". En consecuencia, tenemos un borde "es" en una dirección y la otra. Estas no son las mismas conexiones; son de una naturaleza diferente, por lo que deben distinguirse.
De aquí en adelante, consideramos casos simples donde los miembros de una oración están presentes, no implícitos. Hay estructuras y marcas para lidiar con los pases. Algo aparece en el árbol que no tiene una expresión superficial: una palabra. Pero este es el tema de otro estudio, pero aún necesitamos enfocarnos en el nuestro.
Proyecto de dependencias universales
Para facilitar la elección de un analizador sintáctico, dirigimos nuestra atención al proyecto de
Dependencias Universales y la competencia
CoNLL Shared Task , que recientemente tuvo lugar dentro de su marco.
Universal Dependencies es un proyecto para unificar el marcado de corpus sintácticos (tribanks) en el marco de la gramática de dependencia. En ruso, el número de tipos de enlaces sintácticos es limitado: sujeto, predicado, etc. En inglés lo mismo, pero el conjunto ya es diferente. Por ejemplo, allí aparece un artículo que también debe etiquetarse de alguna manera. Si quisiéramos escribir un analizador mágico que pudiera manejar todos los idiomas, rápidamente tendríamos problemas para comparar diferentes gramáticas. Los heroicos creadores de Dependencias Universales lograron ponerse de acuerdo entre ellos y marcar todos los edificios que estaban a su disposición en un solo formato. No es muy importante cómo acordaron, lo principal es que en la salida obtuvimos un cierto formato uniforme para presentar esta historia completa:
más de 100 tribanks para 60 idiomas .
CoNLL Shared Task es una competencia entre desarrolladores de algoritmos de análisis, realizada como parte del proyecto Universal Dependencies. Los organizadores toman un cierto número de tribanks y los dividen en tres partes: capacitación, validación y prueba. La primera parte se proporciona a los participantes de la competencia para que entrenen a sus modelos en ella. La segunda parte también es utilizada por los participantes para evaluar el funcionamiento del algoritmo después del entrenamiento. Los participantes pueden repetir la capacitación y la evaluación de forma iterativa. Luego dan su mejor algoritmo a los organizadores, quienes lo ejecutan en la parte de prueba, cerrado a los participantes. Los resultados de los modelos en las partes de prueba de los tribanks son los resultados de la competencia.
Métricas de calidad
Tenemos conexiones entre las palabras y sus tipos. Podemos evaluar si la palabra superior se encuentra correctamente: la métrica UAS (puntaje de archivo adjunto sin etiqueta). O para evaluar si tanto el vértice como el tipo de dependencia se encuentran correctamente: la métrica LAS (puntaje de apego etiquetado).

Parece que una evaluación de precisión se inicia aquí: consideramos cuántas veces obtuvimos del número total de casos. Si tenemos 5 palabras y para 4 determinamos correctamente la parte superior, obtenemos el 80%.
Pero en realidad evaluar el analizador en su forma pura es problemático. Los desarrolladores que resuelven los problemas del análisis automático a menudo toman el texto sin formato como entrada, que, de acuerdo con la pirámide de análisis, pasa por las etapas de tokenización y análisis morfológico. Los errores de estos pasos anteriores pueden afectar la calidad del analizador. En particular, esto se aplica al procedimiento de tokenización: asignación de palabras. Si hemos identificado las palabras de unidad incorrectas, ya no podremos evaluar correctamente las relaciones sintácticas entre ellas; después de todo, en nuestro cuerpo original etiquetado las unidades eran diferentes.
Por lo tanto, la fórmula de evaluación en este caso es la medida f, donde la precisión es la proporción de resultados exactos en relación con el número total de predicciones, y la integridad es la proporción de resultados precisos en relación con el número de enlaces en los datos marcados.
Cuando damos estimaciones en el futuro, debemos recordar que las métricas utilizadas afectan no solo la sintaxis, sino también la calidad de la tokenización.
Idioma ruso en las dependencias universales
Para que el analizador pueda marcar sintácticamente las oraciones que aún no ha visto, necesita alimentar el corpus marcado para el entrenamiento. Para el idioma ruso, hay varios casos de este tipo:

La segunda columna indica el número de tokens: palabras. Cuantos más tokens, más cuerpos de entrenamiento y mejor será el algoritmo final (si se trata de buenos datos). Obviamente, todos los experimentos se llevan a cabo en SynTagRus (desarrollado por IPPI RAS), en el que hay más de un millón de tokens. Todos los algoritmos se entrenarán en él, lo que se discutirá más adelante.
Analizadores del ruso en la tarea compartida CoNLL
Según los resultados de la
competencia del año pasado, los modelos que fueron entrenados en el mismo SynTagRus lograron los siguientes indicadores LAS:

Los resultados de los analizadores de ruso son impresionantes: son mejores que los de analizadores de inglés, francés y otros idiomas más raros. Tuvimos mucha suerte por dos razones a la vez. En primer lugar, los algoritmos hacen un buen trabajo con el idioma ruso. En segundo lugar, tenemos SynTagRus, una carcasa grande y marcada.
Por cierto, la competencia de 2018 ya pasó, pero llevamos a cabo nuestra investigación en la primavera de este año, por lo que confiamos en los resultados de la pista del año pasado. Mirando hacia el futuro, notamos que la
nueva versión de UDPipe (Future) resultó ser aún más alta este año.
Syntaxnet, un analizador de Google, no está en la lista. ¿Qué le pasa a él? La respuesta es simple: Syntaxnet comenzó solo con la etapa de análisis morfológico. Tomó la tokenización ideal ya preparada, y ya construyó el procesamiento sobre ella. Por lo tanto, es injusto evaluarlo a la par del resto: el resto se dividió en tokens con sus propios algoritmos, y esto podría empeorar los resultados en la siguiente etapa de la sintaxis. La muestra de Syntaxnet 2017 tiene un mejor resultado que la lista completa anterior, pero las comparaciones directas no son justas.
La tabla tiene dos versiones de UDPipe, en 12 y 15 lugares. Las mismas personas que participaron activamente en el proyecto de Dependencias Universales están desarrollando este analizador.
Las actualizaciones de UDPipe aparecen periódicamente (algo menos frecuente, por cierto, el diseño de los casos también se actualiza). Entonces, después de la competencia el año pasado, UDPipe se actualizó (estos eran compromisos para la versión 2.0 aún no lanzados; en el futuro, por simplicidad, nos referiremos aproximadamente al compromiso de UDPipe 2.0 que tomamos, aunque estrictamente hablando esto no es así); Por supuesto, no hay tales actualizaciones en la tabla de la competencia. El resultado de "nuestro" compromiso está aproximadamente en el séptimo lugar.
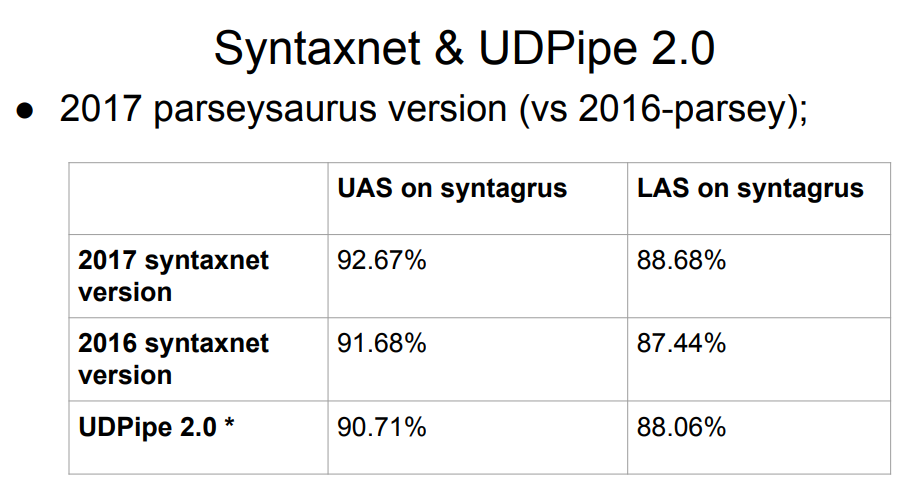
Por lo tanto, debemos elegir un analizador sintáctico para el idioma ruso. Como datos iniciales, tenemos la placa de arriba con el Syntaxnet líder y con UDPipe 2.0 en algún lugar del séptimo lugar.
Elige un modelo
Lo hacemos simple: comenzamos con el analizador con las tasas más altas. Si algo está mal con él, ve abajo. Algo puede no estar bien de acuerdo con los siguientes criterios: tal vez no sean perfectos, pero se nos ocurrieron:
- Velocidad de trabajo . Nuestro analizador debería funcionar lo suficientemente rápido. La sintaxis, por supuesto, está lejos de ser el único módulo "bajo el capó" de un sistema en tiempo real, por lo que no debe gastar más de una docena de milisegundos en él.
- La calidad del trabajo . Como mínimo, el analizador se basa en datos del idioma ruso. El requisito es obvio. Para el idioma ruso, tenemos analizadores morfológicos bastante buenos que se pueden integrar en nuestra pirámide. Si podemos asegurarnos de que el analizador en sí mismo funciona bien sin morfología, entonces esto nos vendrá bien; más adelante deslizaremos la morfología.
- Disponibilidad de un código de capacitación y preferiblemente un modelo en el dominio público . Si tenemos un código de entrenamiento, podremos repetir los resultados del autor del modelo. Para hacer esto, deben estar abiertos. Y, además, necesitamos monitorear cuidadosamente las condiciones para la distribución de casos y modelos. ¿Tendremos que comprar una licencia para usarlos, si los usamos como parte de nuestros algoritmos?
- Lanzamiento sin esfuerzo extra . Este artículo es muy subjetivo, pero importante. ¿Qué significa esto? Esto significa que si nos sentamos durante tres días y comenzamos algo, pero no comienza, entonces no podremos seleccionar este analizador, incluso si será de una calidad perfecta.
Todo lo que era superior a UDPipe 2.0 en el gráfico del analizador no nos convenía. Tenemos un proyecto de Python, y algunos analizadores de la lista no están escritos en Python. Para implementarlos en el proyecto Python, sería necesario aplicar los súper esfuerzos. En otros casos, nos enfrentamos con código fuente cerrado, desarrollos académicos e industriales; en general, no llegarás al fondo.
Star Syntaxnet merece una historia aparte sobre la calidad del trabajo. Aquí no nos convenía por la velocidad del trabajo. El tiempo de su respuesta a algunas frases simples comunes en los chats es de 100 milisegundos. Si gastamos tanto en sintaxis, no tenemos tiempo suficiente para nada más. Al mismo tiempo, UDPipe 2.0 analiza por ~ 3 ms. Como resultado, la elección recayó en UDPipe 2.0.
UDPipe 2.0
UDPipe es una tubería que aprende la tokenización, la lematización, el etiquetado morfológico y el análisis de gramática de dependencia. Podemos enseñarle todo esto o algo por separado. Por ejemplo, haga otro analizador morfológico para el idioma ruso con él. O entrenar y usar UDPipe como un tokenizador.
UDPipe 2.0 está documentado en detalle. Hay una
descripción de la arquitectura , un
repositorio con un código de capacitación , un
manual . Lo más interesante son los
modelos confeccionados , incluso para el idioma ruso. Descargar y ejecutar También en este recurso se han publicado los parámetros de capacitación seleccionados para cada corpus de idiomas. Para cada modelo de este tipo, se necesitan unos 60 parámetros de capacitación y, con su ayuda, puede lograr de forma independiente los mismos indicadores de calidad que en la tabla. Puede que no sean óptimos, pero al menos podemos estar seguros de que la tubería funcionará correctamente. Además, la presencia de dicha referencia nos permite experimentar tranquilamente con el modelo por nuestra cuenta.
Cómo funciona UDPipe 2.0
Primero, el texto se divide en oraciones y las oraciones en palabras. UDPipe hace todo esto a la vez con la ayuda de un módulo conjunto: una red neuronal (GRU de dos lados de una sola capa), que para cada carácter predice si es el último en una oración o en una palabra.
Luego, el etiquetador comienza a funcionar, algo que predice las propiedades morfológicas del token: en cuyo caso la palabra es, en qué número. Basado en los últimos cuatro caracteres de cada palabra, un etiquetador genera hipótesis con respecto a una parte del discurso y las etiquetas morfológicas de esa palabra, y luego, con la ayuda de un perceptrón, selecciona la mejor opción.
UDPipe también tiene un lematizador que selecciona la forma inicial de las palabras. Aprende sobre el mismo principio por el cual un hablante no nativo podría tratar de determinar el lema de una palabra desconocida. Cortamos el prefijo y el final de la palabra, agregamos algo de "t", que está presente en la forma inicial del verbo, etc. Entonces se generan los candidatos, de los cuales elige el mejor perceptrón.
El esquema de marcado morfológico (que determina el número, el caso y todo lo demás) y las predicciones de los lemas son muy similares. Se pueden predecir juntos, pero mejor por separado: la morfología del idioma ruso es demasiado rica. También puede conectar su lista de lemas.
Pasemos a la parte más interesante: el analizador. Existen varias arquitecturas de analizador de dependencias. UDPipe es una arquitectura basada en la transición: funciona rápidamente, pasando a través de todos los tokens una vez en un tiempo lineal.
El análisis sintáctico en dicha arquitectura comienza con una pila (donde al principio solo hay raíz) y una configuración vacía. Hay tres formas predeterminadas de cambiarlo:
- LeftArc: aplicable si el segundo elemento de la pila no es root. Mantiene la relación entre el token en la parte superior de la pila y el segundo token, y también expulsa el segundo de la pila.
- RightArc es igual, pero la dependencia se construye de la otra manera y se descarta la sugerencia.
- Shift: transfiere la siguiente palabra del búfer a la pila.
A continuación se muestra un ejemplo del analizador (
fuente ). Tenemos la frase "resérvame el vuelo de la mañana" y nos estamos volviendo a conectar:

Aquí está el resultado:

El analizador clásico basado en la transición tiene las tres operaciones enumeradas anteriormente: flecha unidireccional, flecha unidireccional y shift. También hay una operación de intercambio, en las arquitecturas básicas de analizador basado en transición no se usa, pero se incluye en UDPipe. Swap devuelve el segundo elemento de la pila al búfer para tomar el siguiente del búfer (si están espaciados). Esto ayuda a omitir algunas palabras y restablecer la conexión correcta.
Hay un buen artículo del
enlace de la persona a la que se le ocurrió la operación de intercambio. Seleccionaremos un punto: a pesar del hecho de que repetidamente pasamos por el búfer de token inicial (es decir, nuestro tiempo ya no es lineal), estas operaciones se pueden optimizar para que el tiempo regrese muy cerca de lineal. Es decir, ante nosotros no es solo una operación significativa desde el punto de vista del lenguaje, sino también una herramienta que no ralentiza mucho el trabajo del analizador.
Usando el ejemplo anterior, mostramos las operaciones, como resultado de lo cual obtenemos alguna configuración: el búfer de token y las conexiones entre ellos. Le damos esta configuración en el paso actual al analizador basado en la transición, y con él, debe predecir la configuración en el siguiente paso. Al comparar los vectores de entrada y las configuraciones en cada paso, se entrena el modelo.
Entonces, seleccionamos un analizador que se ajusta a todos nuestros criterios, e incluso entendimos cómo funciona. Procedemos a los experimentos.
Problemas UDPipe
Hagamos una pequeña oración: "Transfiera cien rublos a mamá". El resultado te hace agarrarte la cabeza.
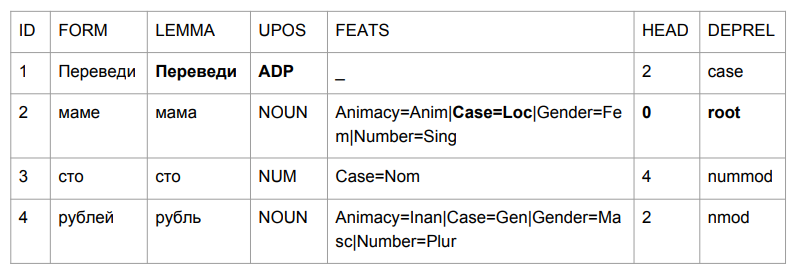
"Traducir" resultó ser una excusa, pero esto es bastante lógico. Determinamos la gramática de la forma de la palabra por los últimos cuatro caracteres. "Plomo" es algo así como "en el medio", por lo que la elección es relativamente lógica. Es más interesante con "mamá": "mamá" estaba en el caso preposicional y se convirtió en el pináculo de esta oración.
Si tratamos de interpretar todo en función de los resultados del análisis, obtendríamos algo así como "en medio de una madre (¿de quién es mamá? ¿Quién es esta madre?) Cientos de rublos". No era exactamente lo que era al principio. Necesitamos lidiar de alguna manera con esto. Y se nos ocurrió cómo.
En la pirámide de análisis, la sintaxis se construye sobre la morfología, basada en etiquetas morfológicas. Aquí hay un ejemplo de libro de texto de un lingüista L.V. Shcherby a este respecto:
"Gloky cuzdra shteko budlanula bokra y niño de cabello rizado".El análisis de esta propuesta no causa problemas. Por qué Porque nosotros, como etiquetadores UDPipe, miramos el final de una palabra y entendemos a qué parte del discurso se refiere y de qué forma es. La historia con "traducir" como una excusa contradice completamente nuestra intuición, pero resulta lógico en el momento en que intentamos hacer lo mismo con palabras desconocidas. Una persona puede pensar de la misma manera.
Evaluaremos el etiquetador UDPipe por separado. Si no nos conviene, tomaremos otro etiquetador y luego construiremos el análisis sobre otro marcado morfológico.
Etiquetado desde texto sin formato (puntuación CoNLL17 F1)- formas doradas: 301639 ,
- upostag: 98.15% ,
- xpostag: 99.89% ,
- hazañas: 93.97% ,
- alltags: 93.44% ,
- lemas: 96.68%
La calidad de la morfología de UDPipe 2.0 no es mala. Pero para el idioma ruso se puede lograr mejor. El analizador Mystem (el
desarrollo de Yandex ) logra mejores resultados en la determinación de las partes del habla que UDPipe. Además, otros analizadores son más difíciles de implementar en un proyecto de Python, y trabajan más lentamente con una calidad comparable a la de Mystem. ,
.
UDPipe. . , Mystem . , « » «» — «», «». . , «», (), , . :
- « » —
- « » — ..
- « - » — (- )
En tales casos, Mystem honestamente le da a toda la cadena:
m.analyze(" ")
[{'analysis': [{'lex': '', 'gr': 'PART='}], 'text': ''},
{'text': ' '},
{'analysis': [{'lex': '', 'gr': 'S,,=(,|,|,)'}],
'text': ''},
{'text': '\n'}]
Pero no podemos enviar toda la cadena de tuberías a UDPipe, pero debemos especificar una etiqueta mejor. ¿Cómo elegirlo? Si no tocas nada, quiero tomar el primero, tal vez funcione. Pero las etiquetas se ordenan alfabéticamente de acuerdo con los nombres en inglés, por lo que nuestra elección será casi aleatoria, y algunos análisis casi pierden la oportunidad de ser los primeros.
Hay un analizador que puede ofrecer la mejor opción: Pymorphy2. Pero con un análisis de la morfología, él es peor. Además, da la mejor palabra fuera de contexto. Pymorphy2 solo dará un análisis para "sin director", "ver director" y "director". No será aleatorio, pero realmente la mejor probabilidad, que en pymorphy2 se consideraba en un cuerpo de textos separado. Pero se garantizará un cierto porcentaje de análisis incorrecto de los textos de combate, simplemente porque pueden contener frases con diferentes formas reales: tanto "veo al director" como "los directores vinieron a la reunión" y "no hay director". Una probabilidad de análisis sin contexto no nos conviene.
¿Cómo obtener contextualmente el mejor conjunto de etiquetas? Usando el analizador
RNNMorph . Pocas personas se enteraron de él, pero el año pasado ganó la competencia entre analizadores morfológicos, realizada como parte de la conferencia de Diálogo.
RNNMorph tiene su propio problema: no tiene tokenización. Si Mystem puede tokenizar texto sin formato, RNNMorph requiere una lista de tokens en la entrada. Para llegar a la sintaxis, primero deberá usar un tokenizador externo, luego dar el resultado a RNNMorph y solo luego alimentar la morfología resultante al analizador de sintaxis.
Aquí están las opciones que tenemos. No rechazaremos el análisis sin contexto pymorphy2 por ahora sobre los casos discutibles en el Mystem; de repente, no se quedará muy atrás de RNNMorph. Aunque si los comparamos puramente al nivel de calidad del marcado morfológico (datos de
MorphoRuEval-2017 ), entonces la pérdida es significativa, alrededor del 15%, si tomamos la precisión de acuerdo con las palabras.
A continuación, debemos convertir la salida de Mystem al formato que UDPipe entiende: conllu. Y nuevamente, esto es un problema, incluso hasta dos. Puramente técnico: las líneas no coinciden. Y conceptual: no siempre está completamente claro cómo compararlos. Frente a dos marcas diferentes de datos de idioma, es casi seguro que se encontrará con el problema de la coincidencia de etiquetas, consulte los ejemplos a continuación. Las respuestas a la pregunta "qué etiqueta está aquí" pueden ser diferentes, y probablemente la respuesta correcta dependa de la tarea. Debido a esta inconsistencia, hacer coincidir los sistemas de marcado no es una tarea fácil en sí misma.
¿Cómo convertir? Hay
russian_tagsets _
package , un paquete para Python que puede convertir diferentes formatos. No hay traducción del formato de emisión de Mystem a Conllu, que se acepta en Dependencias Universales, pero sí hay una traducción a conllu, por ejemplo, del formato de marcado del corpus nacional del idioma ruso (y viceversa). El autor del paquete (por cierto, es el autor de pymorphy2) escribió algo maravilloso directamente en la documentación: "Si no puede usar este paquete, no lo use". Lo hizo no porque el programador krivorukov (¡es un excelente programador!), Sino porque si necesita convertirse uno a otro, entonces corre el riesgo de tener problemas debido a la inconsistencia lingüística de las convenciones de marcado.
Aquí hay un ejemplo. A la escuela se le enseñó la "categoría de condición" (frío, necesario). Algunos dicen que es un adverbio, otros dicen un adjetivo. Necesita convertir esto, y agrega algunas reglas, pero aún así no logra una correspondencia inequívoca entre un formato y otro.
Otro ejemplo: una promesa (o alguien hizo algo o hizo algo con alguien). "Petya mató a alguien" o "Petya fue asesinada". "Vasya toma fotos" - "Vasya toma fotos" (es decir, "Vasya es fotografiada"). También hay una garantía intermedia en SynTagRus: ni siquiera profundizaremos en qué es y por qué. Pero en Mystem no lo es. Si necesita de alguna manera llevar un formato a otro, este es un callejón sin salida.
Más o menos honestamente tomamos el consejo del autor del paquete russian_tagsets: no utilizamos su desarrollo, porque no encontramos el par requerido en la lista de formatos de correspondencia. Como resultado, escribimos nuestro convertidor personalizado de Mystem a Conllu y continuamos.
Conectamos el etiquetador de terceros y el analizador UDPipe
Después de todas las aventuras, tomamos tres algoritmos, que se describieron anteriormente:
- UDPipe basal
- Mym con desambiguación de etiqueta de pymorphy2
- RNNMorph
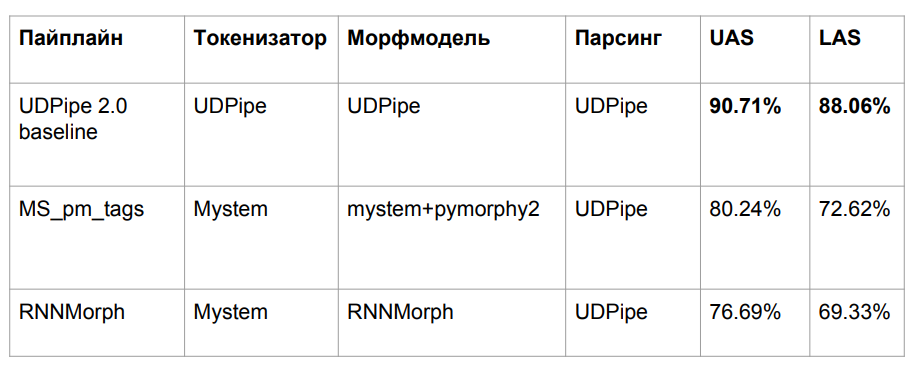
Perdimos calidad por una razón bastante obvia. Tomamos el modelo UDPipe entrenado en una morfología, pero deslizamos otra morfología en una entrada. El problema clásico de la falta de coincidencia de datos entre el tren y la prueba es el resultado de una caída en la calidad.
Intentamos alinear nuestras herramientas automáticas de marcado morfológico con el marcado SynTagRus, que se marcó manualmente. No tuvimos éxito, por lo tanto, en el caso de entrenamiento SynTagRus, reemplazaremos todas las marcas morfológicas manuales con las obtenidas de Mystem y pymorphy2 en un caso y de RNNMorph en otro. En un caso validado marcado a mano, nos vemos obligados a cambiar el marcado manual a automático, porque "en la batalla" nunca obtendremos el marcado manual.
Como resultado, capacitamos al analizador UDPipe (solo el analizador) con los mismos hiperparámetros que la línea de base. Lo que fue responsable de la sintaxis, la ID de vértice, de la que depende el tipo de conexión, nos fuimos, cambiamos todo lo demás.
Resultados
Además, nos compararé con Syntaxnet y otros algoritmos. Los organizadores de CoNLL Shared Task han presentado la partición SynTagRus (train / dev / test 80/10/10). Inicialmente tomamos otro (tren / prueba 70/30), por lo que los datos no siempre coinciden con nosotros, aunque fueron recibidos en el mismo caso. Además, tomamos la última versión (a partir de febrero-marzo) del repositorio SynTagRus: esta versión es ligeramente diferente de la de la competencia. Los datos de lo que no despegó se dan en artículos donde la división fue la misma que en la competencia: dichos algoritmos están marcados con un asterisco en la tabla.
Aquí están los resultados finales:
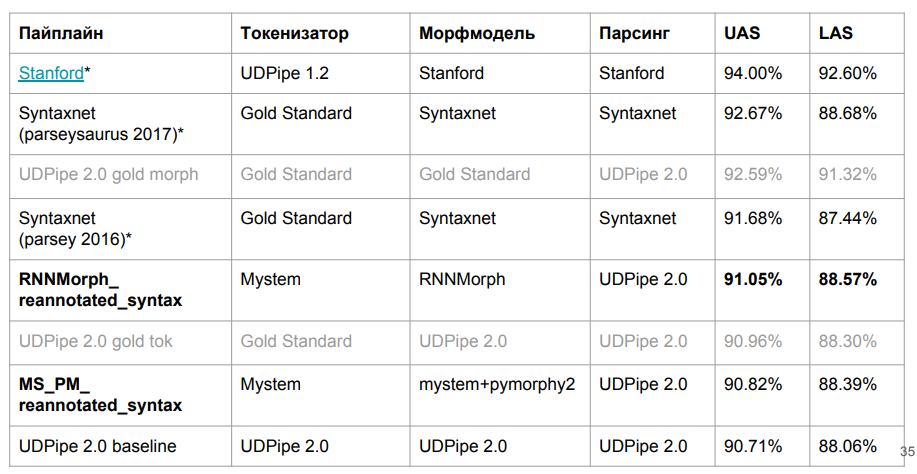
RNNMorph realmente resultó ser mejor, no en el sentido absoluto, sino en el papel de una herramienta auxiliar para obtener una métrica común de acuerdo con los resultados del análisis (en comparación con Mystem + pymorphy2). Es decir, cuanto mejor es la morfología, mejor es la sintaxis, pero la separación "sintáctica" es mucho menor que la morfológica. Tenga en cuenta también que no nos alejamos mucho del modelo de referencia, lo que significa que en la morfología realmente no había tanto como esperábamos.
Me pregunto cuánto miente sobre la morfología. ¿Es posible lograr una mejora fundamental en el analizador sintáctico debido a la morfología ideal? Para responder a esta pregunta, manejamos UDPipe 2.0 en tokenización y morfología que estaban perfectamente calibrados (usando el estándar de marcado manual estándar). Hubo un cierto margen (vea la línea sobre Gold Morph en la tabla; resulta + 1.54% de RNNMorph_reannotated_syntax) de lo que teníamos, incluso desde el punto de vista de determinar correctamente el tipo de conexión. Si alguien escribe un analizador morfológico absolutamente perfecto del idioma ruso, es probable que los resultados que obtengamos con un analizador sintáctico abstracto también crezcan. Y aproximadamente entendemos el techo (al menos el techo para esa arquitectura y para la combinación de parámetros que usamos para UDPipe; se muestra en la tercera fila de la tabla anterior).
Curiosamente, casi llegamos a la versión Syntaxnet en la métrica LAS. Está claro que tenemos datos ligeramente diferentes, pero en principio todavía es comparable. La tokenización de Syntaxnet es "oro", y para nosotros, de Mystem. Escribimos el contenedor antes mencionado en Mystem, pero el análisis aún ocurre automáticamente; probablemente Mystem también se equivoca en alguna parte. De la línea de la tabla "UDPipe 2.0 gold tok", se puede ver que si toma la tokenización UDPipe y gold predeterminada, aún pierde un poco Syntaxnet-2017. Pero funciona mucho más rápido.
Lo que nadie ha alcanzado es el
analizador Stanford . Está diseñado de la misma manera que Syntaxnet, por lo que funciona durante mucho tiempo. En UDPipe, simplemente vamos a lo largo de la pila. La arquitectura del analizador sintáctico y Syntaxnet de Stanford tiene un concepto diferente: primero generan un gráfico orientado completo, y luego el algoritmo funciona para dejar el esqueleto (árbol de expansión mínima) que es más probable. Para hacer esto, pasa por combinaciones, y esta búsqueda ya no es lineal, porque recurrirá a una palabra más de una vez. A pesar de que durante mucho tiempo, desde el punto de vista de la ciencia pura, al menos para el idioma ruso, es una arquitectura más eficiente. Intentamos elevar este desarrollo académico durante dos días; por desgracia, no funcionó. Pero según su arquitectura, está claro que no funciona rápido.
En cuanto a nuestro enfoque, aunque formalmente casi no aumentamos por métricas, ahora todo está bien con la "madre".
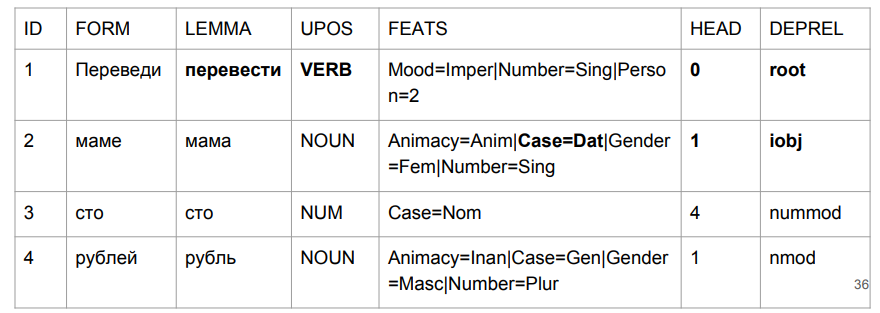
En la frase "traducir cien rublos a mamá", "traducir" es realmente un verbo en el estado de ánimo imperativo. "Mamá" tiene su caso dativo. Y lo más importante para nosotros es nuestra etiqueta (iobj), un objeto indirecto (destino). Aunque el crecimiento en números es insignificante, manejamos bien el problema con el que comenzó la tarea.
Bonus track: puntuación
Si volvemos a los datos reales, resulta que la sintaxis depende de la puntuación. Tome la frase "no puede ejecutar la misericordia". Lo que no se puede hacer exactamente, "ejecutar" o "tener piedad", depende de dónde se encuentre la coma. Incluso si ponemos al lingüista para marcar los datos, necesitará la puntuación como algún tipo de herramienta auxiliar. No podía prescindir de ella.
Tomemos las frases "Peter hola" y "Peter hola" y veamos su análisis por el modelo baseline-UDPipe. Dejamos de lado los problemas que, según este modelo, entonces:
1) "Petya" es un sustantivo femenino;
2) "Petya" es (a juzgar por el conjunto de etiquetas) la forma inicial, pero al mismo tiempo, su lema supuestamente no es "Petya".
Así es como el resultado cambia debido a la coma, con su ayuda obtenemos algo similar a la verdad.
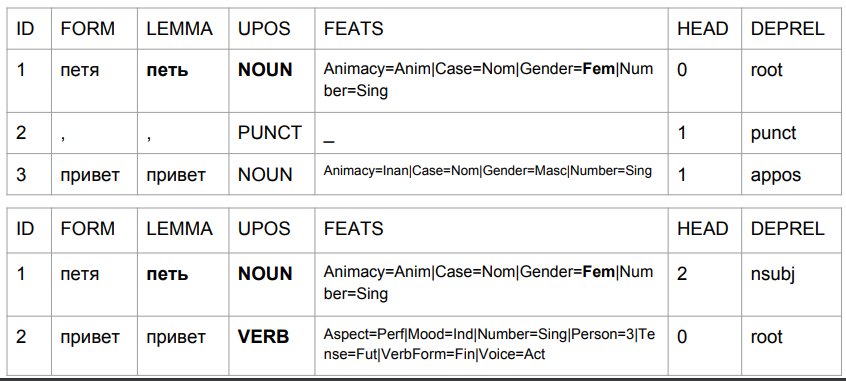
En el segundo caso, "Petia" es un sujeto y "hola" es un verbo. Volver a predecir la forma de una palabra basada en los últimos cuatro caracteres. En la interpretación del algoritmo, esto no es "saludos de Petia", sino "saludos de Petya". Escriba "Petya canta" o "Petya vendrá". El análisis es bastante comprensible: en ruso, no puede haber una coma entre el sujeto y el predicado. Por lo tanto, si la coma es, esta es la palabra "hola", y si no hay coma, bien podría ser algo así como "Petya Privet".
Encontraremos esto en la producción con bastante frecuencia, porque los correctores ortográficos corregirán la ortografía, pero no la puntuación. Para empeorar las cosas, el usuario puede establecer comas incorrectamente, y nuestro algoritmo las tendrá en cuenta para comprender el lenguaje natural. ¿Cuáles son las posibles soluciones aquí? Vemos dos opciones.
La primera opción es hacer lo que a veces hacen al traducir el discurso en texto. Inicialmente, no hay puntuación en dicho texto, por lo que se restaura a través del modelo. El resultado es un material relativamente competente en términos de las reglas del idioma ruso, que ayuda al analizador sintáctico a funcionar correctamente.
La segunda idea es algo más audaz y contradice las lecciones escolares del idioma ruso. Implica trabajar sin puntuación: si de repente la entrada es puntuación, la eliminaremos de allí. También eliminaremos absolutamente todos los signos de puntuación del cuerpo de entrenamiento. Suponemos que el idioma ruso existe sin puntuación. Solo puntos por dividir en oraciones.
Técnicamente, es bastante simple, porque no cambiamos los nodos finales en el árbol de sintaxis. No podemos tener tal que el signo de puntuación sea la parte superior. Este siempre es un nodo final, excepto el signo%, que por alguna razón en SynTagRus es el vértice del número anterior (50% en SynTagRus está marcado como% - vértice y 50 - dependiente).
Probemos usando el modelo Mystem (+ pymorphy 2).

Es de vital importancia para nosotros no dar el modelo de texto de puntuación sin puntuación. Pero si siempre damos el texto sin puntuación, estaremos en la línea superior y obtendremos al menos resultados aceptables. Si el texto sin puntuación y el modelo funciona sin puntuación, entonces, con respecto a la puntuación ideal y el modelo de puntuación, la caída será solo del 3%.
¿Qué hacer al respecto? Podemos detenernos en estos números, obtenidos utilizando el modelo sin puntuación y la purificación de la puntuación. O invente algún tipo de clasificador para restaurar la puntuación. No lograremos números ideales (aquellos con puntuación en el modelo de puntuación), porque el algoritmo de recuperación de puntuación funciona con algún error, y los números "ideales" se calcularon en SynTagRus absolutamente puro. Pero si vamos a escribir un modelo que restaure la puntuación, ¿el progreso pagará nuestros costos? La respuesta aún no es obvia.
Podemos pensar durante mucho tiempo en la arquitectura del analizador sintáctico, pero debemos recordar que, de hecho, todavía no hay un gran corpus de textos web marcado sintácticamente. Su existencia ayudaría a resolver mejor los problemas reales. Hasta ahora, estamos estudiando en el cuerpo de textos editados absolutamente literarios, y estamos perdiendo calidad al obtener textos personalizados en la batalla, que a menudo se escriben analfabetos.
Conclusión
Examinamos el uso de varios algoritmos sintácticos de análisis basados en la gramática de dependencia, tal como se aplica al idioma ruso. Resultó que, en términos de velocidad, conveniencia y calidad de trabajo, UDPipe resultó ser la mejor herramienta. Su modelo de referencia puede mejorarse si las etapas de tokenización y análisis morfológico se asignan a otros analizadores de terceros: este truco permite corregir el comportamiento incorrecto del etiquetador y, como resultado, el analizador en casos importantes para el análisis.
También analizamos el problema de la relación entre la puntuación y el análisis y llegamos a la conclusión de que, en nuestro caso, es mejor eliminar la puntuación antes del análisis sintáctico.
Esperamos que los puntos de aplicación discutidos en nuestro artículo lo ayuden a usar el análisis sintáctico para resolver sus problemas de la manera más eficiente posible.
El autor agradece a Nikita Kuznetsova y Natalya Filippova por su ayuda en la preparación del artículo; para asistencia en el estudio: Anton Alekseev, Nikita Kuznetsov, Andrei Kutuzov, Boris Orekhov y Mikhail Popov.