Hola Habr!
Hace tres años, en el sitio de Leonid Zhukov, hice un enlace al curso de Análisis de Redes de Yure Leskovek cs224w y ahora lo tomaremos junto con todos en nuestro cómodo chat en el canal # class_cs224w. Inmediatamente después de un calentamiento con un curso de aprendizaje automático abierto que comienza en unos días.

Pregunta: ¿Qué leen allí?
Respuesta: Matemáticas modernas. Mostramos un ejemplo de mejora del proceso de reclutamiento de TI.
Debajo del gato del lector, hay una historia sobre cómo las matemáticas discretas llevaron al gerente del proyecto a las redes neuronales, por qué ERP y los gerentes de productos deberían leer la revista Bioinformatics, cómo apareció y se resolvió la tarea de recomendar conexiones, quién necesita incrustaciones de gráficos y de dónde provienen, así como la opinión de que cómo dejar de tener miedo a las preguntas sobre los árboles en las entrevistas y cuánto puede costar todo esto. Vamos!
Nuestro plan es el siguiente:
1) ¿Qué es cs224w
2) Cuadros o paseo
3) ¿Cómo llegué a todo esto?
4) ¿Por qué leer la revista de bioinformática?
5) ¿Qué es la incrustación de gráficos y de dónde vino?
6) Cochecito aleatorio en forma de matriz
7) El regreso de un cochecito aleatorio y la fuerza de los lazos
8) La ruta de un vagabundo aleatorio y la parte superior en el vector
9) Nuestros días son un vagabundo aleatorio para todos y para todos
10) Cómo y dónde almacenar dichos datos y dónde obtenerlos
11) ¿Qué temer?
12) Memo para el jugador
¿Qué es cs224w?
El curso de Análisis de Redes Yure Leskovek se destaca en la galaxia de productos educativos de la Facultad de Ciencias Computacionales de la Universidad de Stanford. La diferencia con los demás es que el programa cubre una amplia gama de temas. Es la naturaleza interdisciplinaria lo que hace que la aventura sea un desafío. El premio es el lenguaje universal para la descripción de sistemas complejos: teoría de grafos, que se puede abordar en diez semanas.

El curso no cuesta tanto, pero abre el programa de Certificado de Posgrado de Conjuntos de Datos Masivos de Minería , que todavía tiene muchas ventajas.
El segundo en la aventura es el CS229 Machine Learning de Andrew Eun, que se anuncia innecesariamente.
Esto es seguido por los conjuntos de datos masivos de minería CS246, Jure Leskoveka, en los que los que lo deseen están invitados a descansar en MapReduce y Spark.
Chris Manning finaliza el banquete CS276 Recuperación de información y búsqueda web.
Como beneficio adicional, los conjuntos de datos masivos de minería CS246H: Hadoop Labs está especialmente diseñado para aquellos que eran pocos. Nuevamente visitando Yure.
En general, prometen que aquellos que hayan aprobado el programa adquirirán habilidades y conocimientos suficientes para buscar información en Internet (sin Google y otros como ellos).
Paseo o damas
Érase una vez, mi líder y mentor, en ese momento, STO en el Nestlé ucraniano, me estaba explicando, joven y ambicioso, tratando de obtener un MBA para convertirse incluso en una estrella, la verdad de que la experiencia y el conocimiento están comprando y vendiendo en el mercado laboral, y no diplomas y resultados de exámenes.
La especialización descrita anteriormente se puede completar en línea por un simbólico de $ 18,900.
En promedio, una aventura toma 1-2 años, pero no más de 3. Para obtener un certificado, debe completar todos los cursos con una calificación de al menos B (3.0).
Hay otra manera
Todos los materiales de los cursos de Jure Leskovek se publican de manera abierta y muy rápida. Por lo tanto, aquellos que lo deseen pueden sufrir en cualquier momento conveniente, coordinando la carga con habilidades. Especialmente dotado, recomiendo probar el modo aventura "¡Esto es Stanford, cariño!" - aprobación paralela al curso - los videos de las conferencias se publican en un par de días, hay literatura adicional disponible de inmediato, la tarea y las soluciones se abren gradualmente.
Esta temporada, después del final del curso Open Machine Learning en Habré , que es útil para tomar como calentamiento, organizaremos una carrera en la clase de canal dedicada # cs_cs224w ods.ai.
Se recomienda tener el siguiente conjunto de habilidades:
- Fundamentos de Ciencias Computacionales a un nivel suficiente para escribir programas no triviales.
- Fundamentos de la teoría de la probabilidad.
- Fundamentos del álgebra lineal.
¿Cómo llegué a todo esto?
Vivía para sí mismo, no se molestaba. Proyectos de implementación de SAP gestionados. A veces, actuó como entrenador de juego en su especialización principal, y CRM se volvió loco. Se puede decir que casi no tocó a nadie. Estaba comprometido con la autoeducación. En algún momento, decidí especializarme en el campo de la transformación empresarial (o realizar cambios organizacionales). La tarea de analizar las organizaciones antes y después del cambio es una parte importante de este trabajo. Saber dónde y dónde cambiar ayuda mucho. Comprender las relaciones entre las personas es un factor de éxito significativo. Pasó varios años estudiando las metodologías "blandas" para investigar organizaciones, pero aún no podía estar satisfecho con la pregunta: "¿Quién recogerá a quién: el comisario jefe del contador principal, o es más fuerte que el resto del almacén?" Me he estado preguntando durante varios años seguidos. Estoy buscando una forma de medir con seguridad.
2014 fue un punto de inflexión, cuando abandoné los sueños de MBA y elegí la gestión de estadísticas e información en la nueva Universidad de Lisboa (el primer departamento de telecomunicaciones de la facultad de aviación y sistemas espaciales ya existente de la Universidad Politécnica de Kiev) como el segundo más alto (escucho el tambor) + Departamento de Comunicaciones en el ejército).
En el primer semestre de la segunda magistratura, probó el análisis de las redes sociales, una de las aplicaciones de la teoría de grafos. Fue entonces cuando aprendí que es algo que, resulta que hay algoritmos que resuelven problemas como quién será amigo de alguien en contra de la introducción de nuevas tecnologías, pero no lo sabía antes y me sequé la cabeza, analizando las conexiones de las personas en mi mente: realmente se hincha de esto. Resultó por casualidad que el análisis de redes, después de los primeros pasos, es una excavación continua de datos y aprendizaje automático, ya sea con un maestro o sin él.
Al principio, había suficientes clásicos.
Yo queria mas. Para hacer frente a las incrustaciones (y para reducir el trabajo de Marinka Zhitnik a sus tareas), tuve que profundizar en el aprendizaje profundo, que fue de gran ayuda con el curso Deep Learning en los dedos . Dada la velocidad con la que el grupo Leskovek crea nuevos conocimientos, para resolver las tareas de gestión automáticamente, es suficiente simplemente monitorear su trabajo.
El trabajo en equipo no es una tarea fácil. Quien no debe ser puesto en el mismo bote con uno es uno de los problemas apremiantes. Especialmente cuando las caras son nuevas. Y el área no es familiar. Y para llegar a costas distantes no necesita un solo barco, sino toda una flotilla. Y en el camino, es necesaria una estrecha interacción tanto en los barcos como entre ellos. Días laborables habituales de implementación de SAP , cuando el Cliente necesita entregar un sistema configurado para sus especificaciones a partir de un conjunto de módulos, y el plan del proyecto consta de miles de líneas. A pesar de todo su trabajo, nunca contrató a nadie, siempre emitieron un equipo. Eres un gerente de proyecto, tienes poderes y te das la vuelta. Algo asi. Torcido.
Ejemplo de vida:
Yo mismo no entrevisté, pero asigné Timlids para esto. Y para los recursos: demanda de mí. Y la integración de los nuevos miembros del equipo también es responsabilidad del gerente del proyecto. Creo que muchos estarán de acuerdo en que cuanto mejor se prepare la lista de candidatos, más agradable será el proceso para todos los participantes. Consideraremos esta tarea en detalle.
Pereza natural requerida: encuentre una manera de automatizar. Lo encontré Yo comparto
Un poco de teoría de la gestión. La metodología Adizes se basa en un principio básico: las organizaciones, como los organismos vivos, tienen su propio ciclo de vida y demuestran manifestaciones conductuales predecibles y repetitivas durante el crecimiento y el envejecimiento. En cada etapa del desarrollo organizacional, la compañía espera un conjunto específico de problemas. Qué tan bien los maneja la gerencia de la compañía, cuán exitosamente hace los cambios necesarios para una transición saludable de etapa en etapa, y determina el éxito o fracaso final de esta organización.
He estado familiarizado con las ideas de Itzjak Adizes durante unos diez años y, en muchos aspectos, estoy de acuerdo.
Las personalidades de los empleados, como las vitaminas, influyen en el éxito en ciertas condiciones. Existen ejemplos conocidos de cómo los líderes exitosos, al mudarse de una industria, fracasaron en otra. Sucede peor. Por ejemplo, Marissa Mayer, quien planteó una búsqueda en Google, dejó caer Yahoo. Warren Buffett dice que difícilmente habría logrado nacer en Bangladesh. El entorno y las formas de interactuar en él son un factor importante.
Sería bueno predecir complicaciones antes de experimentar con uno vivo, ¿verdad?
En este esquema se encuentra el próximo estudio de Marinka itnik publicado en la revista Bioinformatics. La tarea de predecir los efectos secundarios con el uso combinado de drogas está matemáticamente cerca de la gestión. Todo gracias a la versatilidad del lenguaje gráfico. Consideremos con más detalle.

Red convolucional del gráfico de decágono: una herramienta para predecir conexiones en redes multimodales.
El método consiste en construir un gráfico multimodal de las interacciones proteína-proteína, fármaco-proteína y los efectos secundarios de una combinación de medicamentos, que son relaciones fármaco-fármaco, donde cada uno de los efectos secundarios es un borde de cierto tipo. El decágono predice un tipo específico de efecto secundario, si lo hay, que aparece en el cuadro clínico.
La figura muestra un ejemplo de un gráfico de efectos secundarios obtenidos de los datos del genoma y la población. En total, 964 diferentes tipos de efectos secundarios (indicados por costillas del tipo ri, i = 1, ..., 964). Se presenta información adicional en el modelo en forma de vectores de las propiedades de proteínas y fármacos.
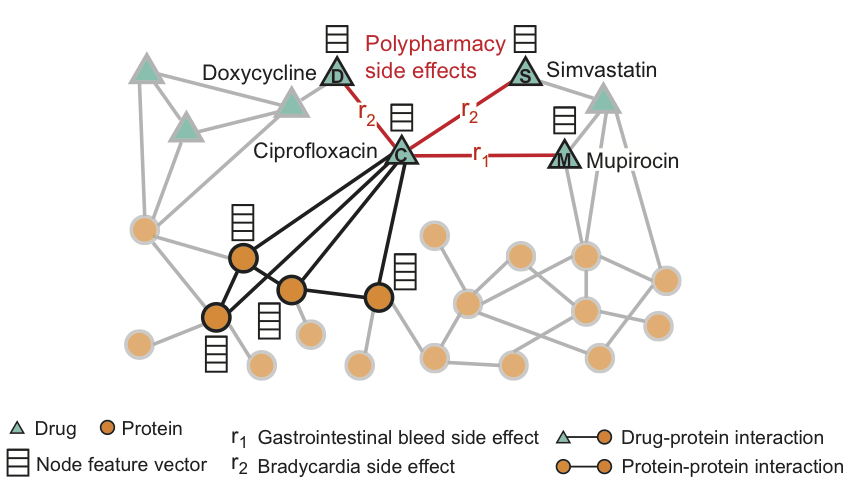
Para el medicamento Ciprofloxacino (nodo C), los vecinos resaltados en el gráfico reflejan los efectos sobre cuatro proteínas y otros tres medicamentos. Vemos que la ciprofloxacina (nodo C), tomada simultáneamente con doxiciclina (nodo D) o simvastatina (nodo S), aumenta el riesgo de un efecto secundario de disminución de la frecuencia cardíaca (un efecto secundario como r2) y una combinación con mupirocina (M) - aumenta el riesgo de sangrado del tracto gastrointestinal (efecto secundario tipo r1).
El decágono predice asociaciones entre pares de drogas y efectos secundarios (que se muestran en rojo) para identificar los efectos secundarios del uso concurrente, es decir. esos efectos secundarios que no pueden asociarse con ninguno de los medicamentos del par por separado.
Arquitectura del gráfico de red neuronal convolucional del decágono:
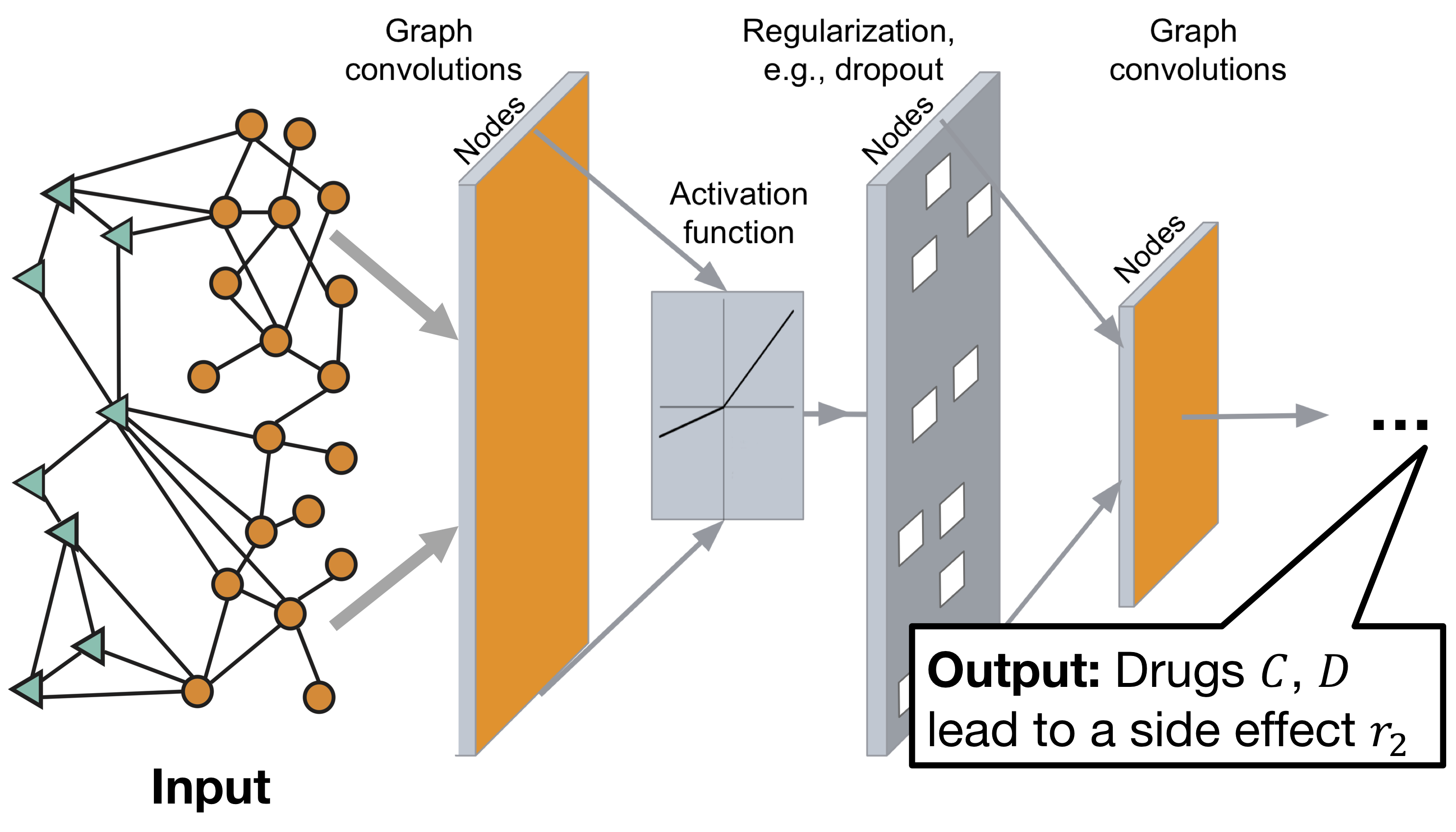
El modelo consta de dos partes:
Codificador: red convolucional de gráficos (GCN) que recibe un gráfico e incrustación de nodos,
Decodificador: un modelo de factorización tensorial que utiliza estas incorporaciones para detectar efectos secundarios.
Se puede encontrar más información en el sitio web del proyecto o debajo.
Genial, pero ¿cómo vincular esto con el trabajo en equipo?
Algo asi .
Aquí, para sentirse cómodo en el campo de investigación similar al descrito, vale la pena desenterrar el granito de la ciencia. Es cierto que la excavación ocurrirá intensamente: la teoría de gráficos se está desarrollando activamente. Por eso es la punta de lanza del progreso: pocas personas se sienten cómodas allí.
Para comprender los detalles del funcionamiento de Decagon, haremos una excursión a la historia.
¿Qué es la incrustación de gráficos y de dónde vino?
Observé un cambio en el conjunto de métodos avanzados para resolver problemas de predicción de conexiones en gráficos durante los últimos cuatro años. Eso fue divertido Casi como en un cuento de hadas: cuanto más, peor. La evolución siguió el camino desde la heurística que determinó el entorno para la parte superior del gráfico hasta las carriolas aleatorias, luego aparecieron los métodos espectrales (análisis matricial) y ahora las redes neuronales.
Formulamos el problema de predecir las relaciones:
Considere un gráfico no dirigido $ en línea $ \ begin {align *} G (V, E) \ end {align *} $ en línea $ donde
$ inline $ \ begin {align *} V \ end {align *} $ inline $ - muchos picos $ inline $ \ begin {align *} v \ end {align *} $ inline $ ,
$ inline $ \ begin {align *} E \ end {align *} $ inline $ - muchas costillas $ en línea $ \ begin {align *} e (u, v) \ end {align *} $ en línea $ conectando los picos $ en línea $ \ begin {align *} u \ end {align *} $ en línea $ y $ inline $ \ begin {align *} v \ end {align *} $ inline $ .
Definimos el conjunto de todos los bordes posibles. $ en línea $ E ^ {\ diamond} $ en línea $ su poder
$ en línea $ \ begin {align *} | E ^ {\ diamond} | & = \ frac {| V | * (| V | - 1)} {2} \\ \ end {align *} $ en línea $ donde
$ en línea $ \ begin {align *} | V | = n \ end {align *} $ en línea $ , Es el número de vértices.
Obviamente, muchos bordes inexistentes se pueden expresar como $ en línea $ \ begin {align *} \ overline {E} = E ^ {\ diamond} - E \ end {align *} $ inline $ .
Suponemos que en el set $ inline $ \ begin {align *} \ overline {E} \ end {align *} $ inline $ hay enlaces perdidos, o enlaces que aparecerán en el futuro, y queremos encontrarlos.
La solución se reduce a definir una función $ en línea $ \ begin {align *} D (u, v) \ end {align *} $ en línea $ la distancia entre los vértices del gráfico, lo que permite la estructura del gráfico $ en línea $ \ begin {align *} G (t_0, t_0 ^ \ star) \ end {align *} $ en línea $ establecido durante un período de tiempo $ inline $ \ begin {align *} (t_0, t_0 ^ \ star) \ end {align *} $ inline $ predecir la apariencia de los bordes $ inline $ \ begin {align *} G (t_1, t_1 ^ \ star) \ end {align *} $ inline $ en el rango $ inline $ \ begin {align *} (t_1, t_1 ^ \ star) \ end {align *} $ inline $ .
Una de las primeras publicaciones que propuso pasar de la agrupación a la tarea de predecir las relaciones en el contexto del estudio de la expresión génica conjunta apareció en la revista (como se podría adivinar) Bioinformática en 2000. Ya en 2003, se publicó un artículo de John Kleinberg con una descripción general de los métodos relevantes para resolver el problema de pronosticar conexiones en una red social. Su libro " Redes, multitudes y mercados: razonamiento sobre un mundo altamente conectado " es un libro de texto que se recomienda leer durante el curso cs224w, la mayoría de los capítulos se enumeran en la sección de lectura requerida.
Un artículo puede considerarse una porción de conocimiento en un campo estrecho, como vemos, al principio la variedad de métodos era pequeña e incluía:
- Métodos basados en vecinos gráficos , y el más obvio de estos es el número de vecinos comunes.
Damos la definición:
Arriba $ en línea $ u $ en línea $ es un gráfico vecino para la parte superior $ en línea $ v $ en línea $ si costilla $ en línea $ e (u, v) \ en E $ en línea $ .
Denotamos $ en línea $ \ Gamma (u) $ en línea $ muchos vecinos picos $ en línea $ u $ en línea $ ,
entonces la distancia entre los picos $ en línea $ u $ en línea $ y $ en línea $ v $ en línea $ se puede escribir como
$ en línea $ D_ {CN} (u, v) = \ Gamma (u) \ cap \ Gamma (v) $ en línea $ .
Intuitivamente, cuanto mayor es la intersección de los conjuntos de vecinos de dos picos, más probable es la conexión entre ellos, por ejemplo, la mayoría de los nuevos conocidos ocurren con amigos de amigos.
Heurística más avanzada: coeficiente Jacquard $ en línea $ D_J (u, v) = \ frac {\ Gamma (u) \ cap \ Gamma (v)} {\ Gamma (u) \ cup \ Gamma (v)} $ en línea $ (que ya tenía cien años) y recientemente (en ese momento) la distancia propuesta Adamik / Adar $ en línea $ D_ {AA} (u, v) = \ sum_ {x \ in \ Gamma (u) \ cap \ Gamma (v)} \ frac {1} {\ log | \ Gamma (x) |} $ en línea $ $ Desarrollar la idea a través de transformaciones simples.
- Métodos basados en rutas a lo largo de un gráfico : la idea es que la ruta más corta entre dos vértices en un gráfico corresponde a la posibilidad de una conexión entre ellos; cuanto más corta es la ruta, mayor es la posibilidad. Puede ir más allá y tener en cuenta no solo el camino más corto, sino también todos los otros caminos posibles entre pares de picos, por ejemplo, pesar los caminos, como lo hace la distancia de Katz . Ya entonces, se menciona la longitud de ruta esperada de un vagabundo aleatorio, el precursor del método de recomendación de amigos de Facebook.
Estime la calidad del pronóstico:
- Para cada par de vértices $ en línea $ (u, v) $ en línea $ cada costilla inexistente $ inline $ e (u, v) \ in \ overline {E} $ inline $ calcular la distancia $ en línea $ D (u, v) $ en línea $ en el gráfico $ en línea $ G (t_0, t_0 ^ \ star) $ en línea $ .
- Ordenar los pares $ en línea $ (u, v) $ en línea $ distancia descendente $ en línea $ D (u, v) $ en línea $ .
- Llevar $ en línea $ m $ en línea $ pares con los valores más altos es nuestro pronóstico.
- Veamos cuántos de los bordes predichos aparecieron en $ en línea $ G (t_1, t_1 ^ \ star) $ en línea $ .
Es importante recordar que el número de vecinos comunes y la distancia Adamik / Adar son métodos poderosos que especifican un nivel básico de calidad de pronóstico solo para la estructura del enlace, y si su sistema de recomendación muestra un resultado más débil, entonces algo está mal.
En general, las incrustaciones de gráficos son una forma de representar gráficos de forma compacta para tareas de aprendizaje automático utilizando la función de transformación $ inline $ \ begin {align *} \ phi: G (V, E) \ longmapsto \ mathbb {R} ^ d \ end {align *} $ inline $ .
Examinamos varias de estas funciones, la más efectiva de las primeras. Una lista más amplia se describe en un artículo de Kleinberg. Como podemos ver en la revisión, incluso entonces comenzaron a aplicar métodos de alto nivel, como la descomposición de la matriz, la agrupación preliminar y las herramientas del arsenal de la lingüística computacional. Hace quince años, todo recién comenzaba. Las incrustaciones fueron unidimensionales.
Cochecito aleatorio en forma de matriz
El siguiente hito en el camino hacia las mismas incrustaciones de gráficos fue el desarrollo de métodos de caminata aleatoria. Inventar y justificar nuevas fórmulas para calcular la distancia, aparentemente, se convirtió en un descanso. En algunas aplicaciones, parece que solo tienes que confiar en el azar y confiar en los vagabundos.
Damos la definición:
Matriz de adyacencia del gráfico $ en línea $ g $ en línea $ con un número finito de vértices $ en línea $ n $ en línea $ (numerado del 1 al $ en línea $ n $ en línea $ ) Es una matriz cuadrada $ en línea $ a $ en línea $ el tamaño $ en línea $ n \ veces n $ en línea $ en el que el valor del elemento $ en línea $ a_ {ij} $ en línea $ igual al peso $ en línea $ w_ {ij} $ en línea $ costillas $ en línea $ e (i, j) $ en línea $ .
Nota: aquí nos alejamos intencionalmente de los indicadores de vértice utilizados anteriormente $ en línea $ u, v $ en línea $ y usaremos la notación familiar para álgebra lineal y, en general, para trabajar con matrices $ en línea $ i, j $ en línea $ .
Ilustramos los conceptos considerados:
Dejar $ en línea $ g $ en línea $ - gráfico de cuatro vértices $ en línea $ \ {A, B, C, D \} $ en línea $ conectados por costillas.
Para simplificar las construcciones, asumimos que los bordes de nuestro gráfico son bidireccionales, es decir, $ inline $ \ forall e (i, j) \ in E, \ exist e (j, i) \ in E \ land w_ {ij} = w_ {ji} $ inline $ .
$ en línea $ e (A, B), w_ {AB} = 1; \\ e (B, C), w_ {BC} = 2; \\ e (A, C), w_ {AC} = 3; \ \ e (B, C), w_ {BC} = 1. $ en línea $
Representamos los conjuntos de aristas: $ en línea $ E $ en línea $ - en azul, y $ en línea $ \ overline {E} $ en línea $ - en verde.

$ en línea $ \ begin {align *} A = \ left [\ begin {matrix} 0 y 1 y 3 y 0 \\ 1 y 0 y 2 y 1 \\ 3 y 2 y 0 y 0 \\ 0 y 1 y 0 & 0 \ end {matriz} \ right] \ end {align *} $ inline $
Escribir un gráfico en forma de matriz abre posibilidades interesantes. Para demostrarlos, eche un vistazo al trabajo de Sergey Brin y Larry Page, y vea cómo PageRank, un algoritmo para clasificar vértices de gráficos, sigue siendo una parte importante de la búsqueda de Google.
PageRank: acuñado para buscar las mejores páginas de Internet. Una página se considera buena si otras páginas buenas la aprecian (vinculan). , , PageRank .
.
:
(degree) — :
,
in-degree out-degree. .
, :
, 1 (.. — " "). .
PageRank , . PageRank
, PageRank, (.. PageRank), .
PageRank — :
-, ( ). , , — .
, . — , 1.
, — , — , . ,
. . + M_{in}p_n(t)$$display$$
,
- , , — . , PageRank . — PageRank — !
PageRank . , , , .. , — . ( , — , ). Page Rank . , 20-30 .
.

"" :
- .. " " — , — , PageRank . . .
- — — PageRank . - . .
20 ,
- , — . , .. - 5-7 . — . PageRank :
( , )
,
. . , , 37-38 14- cs224w 2017 , , Pinterest ( ).
. ?
:
PageRank. , , - , - .
— .
.
, . - ? 2006 .
:
, - , - .
.

, , , .
, , . - . , — (, ). , IT- , ( ) — .
, , — , , — .
, — .
- , Kaggle Hackerrank, , , (, ).
:
, :
:
, . PageRank — . , — .
80% Pinterest.
, , llamado Random Walks with Restarts: los cochecitos vuelven y vuelven a un pico de interés para nosotros. Como resultado, obtenemos una medida de proximidad para cada vértice del gráfico con respecto a ese único. Y esto resuelve el problema de predecir las conexiones mejor de lo que permite la distancia Adamik / Adar.
Agrega más mejoras:
Recordemos que las costillas $ inline $ \ begin {align *} e (i, j) \ in E \ in G \ end {align *} $ inline $ nuestro gráfico tiene pesos $ en línea $ \ begin {align *} w_ {ji} \ end {align *} $ en línea $ .
Esto le permitirá especificar una matriz ponderada $ inline $ \ begin {align *} M ^ w \ end {align *} $ inline $ probabilidades de transición:
$ en línea $ \ begin {align *} M ^ {w} _ {ij} = \ left \ {\ begin {matrix} \ frac {w_ {ij}} {\ sum_ {j} w_ {ij}} & \ forall i, j \ iff e (i, j) \ en E, \\ 0 & \ forall i, j \ iff e (i, j) \ notin E. \ end {matrix} \ right. \ end {align *} $ en línea $
El vagabundo hará transiciones, como antes, por accidente, ¡pero ya no es igualmente probable!
Un lector atento ya se ha preguntado cómo medir estos pesos.
Facebook quedó perplejo por lo mismo en 2011. Era necesario construir un sistema de recomendación para amigos de amigos de amigos, a fin de maximizar la creación de nuevas conexiones. Y el primer paso fue crear un gráfico ponderado de conexiones entre usuarios a partir de información en sus perfiles e historial de interacción (me gusta, mensajes, fotos conjuntas, etc.). De alguna manera mida el poder de la amistad en Internet.
$$ display $$ w_ {ij} = f ^ w (i, j) = e ^ {- \ sum_ {z} {\ xi_z x_ {ij} [z]}}, $$ display $$
donde $ en línea $ \ begin {align *} x_ {ij} \ end {align *} $ en línea $ Es el vector de propiedades de los vértices y los bordes que los conectan, es decir $ en línea $ \ begin {align *} x_ {ij} = f ^ {(i)} \ cup f ^ {(j)} \ cup f ^ {e (ij)} \ end {align *} $ inline $ y $ en línea $ \ begin {align *} \ xi \ end {align *} $ en línea $ Es el vector de pesos que se debe aprender de los datos.
Aquí, un lector capacitado aprende un modelo lineal , y un lector no preparado piensa que vale la pena tomar un curso de aprendizaje automático abierto para tratar el descenso de gradiente, con el cual aprenderemos los valores de los pesos en un vector $ en línea $ x_ {ij} $ en línea $ - mostrarán cómo los me gusta y los mensajes afectan las amistades en Internet.
¿Por qué necesitamos todo esto?
Además del hecho de que el enfoque en consideración nos permite predecir las conexiones aún mejor, podemos aprender las reglas para la formación exitosa del equipo. Y descubra qué buscar en el futuro.
Recordemos las condiciones de nuestro ejercicio. Observamos el desarrollo de la cooperación (participación conjunta en competiciones) en un grupo de analistas de datos condicionales en el intervalo $ inline $ \ begin {align *} (t_0, t_0 ^ \ star) \ end {align *} $ inline $ (por ejemplo, un mes calendario) y queremos predecir la formación de equipos en el intervalo $ inline $ \ begin {align *} (t_1, t_1 ^ \ star) \ end {align *} $ inline $ (otro mes) Además de participar en concursos, hacemos un seguimiento de la comunicación en foros, me gusta de los núcleos y qué más le gusta. Toda la información recopilada se almacena en una matriz. $ en línea $ X ^ {\ star} \ in \ mathbb {R} ^ {(2k + l) \ times | E |} $ en línea $ (sus columnas son vectores $ en línea $ x_ {ij} $ en línea $ , $ en línea $ k, l $ en línea $ - dimensiones de los vectores de propiedades de vértices y aristas $ en línea $ f ^ {(i)}, f ^ {e (ij)} $ en línea $ , respectivamente) y el gráfico $ inline $ \ begin {align *} G \ end {align *} $ inline $ por dos intervalos de tiempo
Vamos a preparar los datos para el aprendizaje automático.
Para cada vértice $ inline $ \ begin {align *} i \ end {align *} $ inline $ :
1) define muchos amigos de amigos:
$$ display $$ \ Gamma ^ {fof} (i) = \ bigcup_ {j \ in \ Gamma (i)} \ Gamma (j) - \ Gamma (i) $$ display $$
2) y construir sub-gráficos $ en línea $ \ begin {align *} G ^ {fof} (i) \ end {align *} $ en línea $ conexiones con amigos y amigos de amigos, $ en línea $ \ begin {align *} \ forall e (x, y) \ in E, e (x, y) \ in G ^ {fof} (i) \ iff x, y \ in \ Gamma ^ {fof} (i) \ cup \ Gamma (i) \ end {align *} $ inline $
3) selecciona el conjunto de vértices, $ inline $ \ begin {align *} D_i: \ {d_1, ..., d_k \} \ end {align *} $ inline $ con quienes hemos formado conexiones son nuestros ejemplos positivos para aprender,
4) todas las conexiones no aleatorias del conjunto $ inline $ \ begin {align *} \ overline {D_i} = \ Gamma ^ {fof} (i) - D_i \ end {align *} $ inline $ - Estos son nuestros ejemplos negativos para el entrenamiento.

Nuestra tarea es seleccionar dicho vector de pesos $ en línea $ \ begin {align *} \ xi \ end {align *} $ en línea $ en el que ejemplos positivos del conjunto $ inline $ \ begin {align *} D_i \ end {align *} $ inline $ obtendrá un valor de PageRank personalizado más alto en relación con $ inline $ \ begin {align *} i \ end {align *} $ inline $ que ejemplos negativos
Para hacer esto, definimos la función de pérdida, que minimizaremos:
$$ display $$ L = \ sum_ {i} \ sum_ {d \ en D_i, \ overline {d} \ in \ overline {D_i}} h (r _ {\ overline {d}} - r_ {d}) + \ lambda || \ xi || ^ 2, $$ display $$
donde $ en línea $ h (x) = 0 \ iff x <0; h (x) = x ^ 2 \ iff x \ geqslant 0; $ en línea $ - penalización por violación de los términos, $ en línea $ \ lambda $ en línea $ - poder $ en línea $ L_2 $ en línea $ regularización de pesas $ en línea $ \ xi $ en línea $ , $ en línea $ r $ en línea $ Es un vector con soluciones de la ecuación. $ en línea $ r = M ^ wr $ en línea $ con respecto $ en línea $ r $ en línea $ para un sub-gráfico de amigos de amigos de un solo top $ en línea $ i $ en línea $ .
Un detalle divertido: el gradiente de esta función se calcula de la misma manera que el PageRank, por el método de potencia. Los detalles se encuentran en la decimoséptima conferencia de la edición de 2014, diapositivas 9-27.
Así era la punta de lanza del progreso cuando conocí por primera vez el curso cs224w.
Carrito aleatorio y top en vector
¡Y luego vino el triunfo de la pereza!
Se sabe que la teoría de los gráficos fue inventada por Leonard Euler cuando estaba aburrido de resolver el problema sin solución sobre los puentes que ahora están en Kaliningrado. En lugar de secarse la cabeza para nada, inventó un aparato matemático que le permite demostrar la imposibilidad fundamental de resolver el rompecabezas.
En las mejores tradiciones de las ciencias computacionales, también seremos perezosos y nos preguntaremos la tarea de encontrar una función que nos permita alejarnos de las representaciones unidimensionales de los nodos e ir a vectores de propiedades multidimensionales.

Aquí nos familiarizamos con las incrustaciones de gráficos en el sentido moderno del término.
Formalmente, queremos:
1) Definir un codificador (una función de conformidad ENC que define una transformación de nodo $ en línea $ u $ en línea $ en vector $ en línea $ z_u $ en línea $ );
2) Determinar la función de similitud de nodos (una medida de proximidad en el gráfico, que aplicaremos a la entrada del codificador);
3) Optimice los parámetros del codificador para que:
$$ visualización $$ similitud (u, v) \ aprox z_ {v} ^ {T} z_v $$ visualización $$

Nos esforzamos por asegurarnos de que los vértices estrechamente espaciados en el gráfico reciban una representación cercana en el mapeo vectorial. En otras palabras, para que el ángulo entre los dos vectores obtenidos sea mínimo.
Genial, pero ¿cómo determinarlo, esta proximidad en el gráfico?
Por ejemplo, suponemos que el peso de la costilla es una buena medida de proximidad y puede considerarse aproximadamente igual al producto escalar para las incrustaciones de dos nodos. La función de pérdida para este caso tomará la forma:
$$ display $$ L = \ sum _ {(u, v) \ in V \ times V} || z_ {u} ^ {T} z_v - A_ {u, v} || ^ 2, $$ display $$
queda por encontrar (por ejemplo, pendiente de gradiente) la matriz $ en línea $ Z \ in \ mathbb {R} ^ {d \ times | V |} $ en línea $ que minimiza $ en línea $ L $ en línea $ .
Un enfoque alternativo es determinar el entorno. $ en línea $ N (v) $ en línea $ porque la cumbre es más ancha que muchos vecinos.

Esto nos ayudará a recorrer el gráfico. El primer proyecto en utilizar este enfoque es DeepWalk . La esencia del método es que comenzaremos un vagabundo para caminar alrededor del gráfico al azar desde cada vértice $ en línea $ v $ en línea $ y alimentar secuencias cortas de longitud fija de picos visitados durante su caminata en word2vec.
La intuición aquí es que la distribución de probabilidad de visitar los vértices del gráfico, una ley de poder, es muy similar a la distribución de probabilidad de la aparición de palabras en idiomas humanos. Y dado que word2vec funciona para palabras, puede hacerlo para gráficos. Lo probamos, ¡funcionó!
En DeepWalk, un vagabundo implementa un proceso de Markov de primer orden: de cada vértice vamos al vecino, de acuerdo con las probabilidades de una matriz de adyacencia ponderada $ en línea $ M $ en línea $ (o sus derivados, como $ en línea $ M ^ w $ en línea $ ) Donde llegamos a la cima no afecta la elección del siguiente paso.
Para implementar la caminata, necesitará un generador de números pseudoaleatorio y un poco de álgebra . Es hora de usar el bloque de cotizaciones para su propósito previsto.
“Cualquiera que esté de acuerdo con los métodos aritméticos de generación, por supuesto, es pecaminoso. Como se ha demostrado repetidamente, no existe un número aleatorio: solo hay métodos para crear tales números, y un procedimiento aritmético estricto, por supuesto, no es tal método ... Solo tratamos con recetas para crear números ...
- John von Neumann
Queda por aconsejar a aquellos que luchan por una vida justa encontrar el álbum "Black and White Noise" para la venta: en 1995, George Marsaglia escribió en el CD una serie de bytes recibidos al digitalizar el ruido del amplificador durante la reproducción del artista de rap y lo nombró en consecuencia.
El desarrollo del método es node2vec , en el que se implementa el proceso de Markov de segundo orden: observamos de dónde vino y esto afecta la probabilidad de elegir la dirección del siguiente paso. Veamos como funciona.
Digamos que comenzamos un vagabundo caminando por el gráfico desde arriba $ en línea $ u $ en línea $ adyacente a la cima $ en línea $ s_1 $ en línea $ tapas $ en línea $ s_2 $ en línea $ y $ en línea $ w $ en línea $ - en dos pasos, y $ en línea $ s_3 $ en línea $ - en tres. Después de cada paso, podemos realizar una de tres acciones posibles: 1) volver más cerca de $ en línea $ u $ en línea $ ; 2) explorar los picos a la misma distancia de $ en línea $ u $ en línea $ , como aquel en el que estamos ahora; 3) alejarse de $ en línea $ u $ en línea $ .

Esta estrategia se implementa utilizando dos parámetros:
$ en línea $ p $ en línea $ - establece la probabilidad de volver al vértice anterior;
$ en línea $ q $ en línea $ - establece el equilibrio entre la búsqueda en amplitud y la búsqueda en profundidad.
Estos parámetros determinan las probabilidades de transición no normalizadas de la siguiente manera:
Digamos que estamos en la cima $ en línea $ w $ en línea $ y entró desde arriba $ en línea $ s_1 $ en línea $ . Para costilla $ en línea $ e (w, s_1) $ en línea $ asignaremos peso (probabilidad no normalizada) $ en línea $ 1 / p $ en línea $ . Para costilla $ en línea $ e (w, s_2) $ en línea $ - $ en línea $ 1 $ en línea $ (como para todos los otros bordes que conducen a vértices equidistantes de $ en línea $ u $ en línea $ ) Por alejarse de $ en línea $ u $ en línea $ costillas $ en línea $ e (w, s_3) $ en línea $ - $ en línea $ 1 / q $ en línea $ .
Luego normalizamos las probabilidades (para que la suma sea igual a 1), y damos el siguiente paso.
Estamos interesados en la secuencia de los picos visitados: lo enviaremos a word2vec ( este artículo lo ayudará a lidiar con él o a la lección 8 del curso de Aprendizaje profundo con los dedos ). La selección de estrategias para el vagabundo, óptima para resolver problemas específicos es un área de investigación activa. Por ejemplo, node2vec, que revisamos, es un campeón en la clasificación de los picos (por ejemplo, determinar la toxicidad de las drogas o el sexo / edad / raza de un miembro de una red social).
Optimizaremos la probabilidad de aparición de picos en el camino del vagabundo, la función de pérdida:
$$ display $$ L = \ sum_ {u \ in V} \ sum_ {v \ in N_ {R} (u)} -log (P (v | z_u)) $$ display $$
en su forma explícita, una carga computacional bastante costosa
$$ display $$ L = \ sum_ {u \ in V} \ sum_ {v \ in N_ {R} (u)} -log (\ frac {e ^ {z_ {u} ^ {T} z_v}} { \ sum_ {n \ in V} e ^ {z_ {u} ^ {T} z_n}}), $$ display $$
que, por casualidad, se resuelve mediante muestreo negativo , porque
$$ display $$ log (\ frac {e ^ {z_ {u} ^ {T} z_v}} {\ sum_ {n \ in V} e ^ {z_ {u} ^ {T} z_n}}) \ aprox. log (\ sigma (z_ {u} ^ {T} z_v)) - \ sum_ {i = 1} ^ {k} log (\ sigma (z_ {u} ^ {T} z_ {n_i})), \\ donde \, \, \, n_i \ sim P_V, \ sigma (x) = \ frac {1} {1 + e ^ {- x}}. $$ display $$
Entonces, descubrimos cómo obtener una representación vectorial de los vértices. ¡La cosa es el sombrero!

Cómo preparar incrustaciones para costillas:
Necesitamos definir un operador que permita cualquier par de vértices $ en línea $ u $ en línea $ y $ en línea $ v $ en línea $ construir representación vectorial $ en línea $ z _ {(u, v)} = g (z_u, z_v) $ en línea $ , independientemente de si están conectados en el gráfico. Tal operador puede ser:
a) media aritmética: $ en línea $ [z_u \ oplus z_v] _i = \ frac {z_u (i) + z_v (i)} {2} $ en línea $ ;
b) el trabajo de Hadamard: $ en línea $ [z_u \ odot z_v] _i = z_u (i) * z_v (i) $ en línea $ ;
c) norma ponderada de L1: $ en línea $ || z_u - z_v || _ {\ overline {1} i} = | z_u (i) - z_v (i) | $ en línea $ ;
d) tasa ponderada de L2: $ en línea $ || z_u - z_v || _ {\ overline {2} i} = | z_u (i) - z_v (i) | ^ 2 $ en línea $ .
En experimentos, el trabajo de Hadamard se comporta de manera más constante.
Por si acaso, recuerde el teorema del almuerzo gratis:
Ningún algoritmo es universal: vale la pena consultar varios métodos.
El desarrollo de node2vec es el proyecto OhmNet , que le permite combinar varios gráficos en una jerarquía y construir incrustaciones de vértices para diferentes niveles de la jerarquía. Originalmente se desarrolló para modelar los enlaces entre proteínas en diferentes órganos (y se comportan de manera diferente dependiendo de la ubicación).

Un lector astuto verá similitudes con la estructura organizativa y los procesos comerciales.
Y nosotros, volveremos a un ejemplo del campo de reclutamiento de TI, la selección de las personas más adecuadas para el equipo ya existente. Anteriormente, consideramos gráficos unimodales de relaciones de analistas de datos condicionales obtenidos de la historia de interacción (en el gráfico unimodal del vértice y la conexión, del mismo tipo). En realidad, el número de círculos sociales en los que se puede incluir a un individuo es más de uno.
Supongamos que, además del historial de participación conjunta en competencias, también hemos recopilado información sobre cómo se comunican los datos en nuestro acogedor chat . Ahora ya tenemos dos gráficos de conexiones, y OhmNet es perfecto para resolver el problema de crear incrustaciones a partir de varias estructuras.
Ahora, sobre las deficiencias de los métodos basados en codificadores poco profundos, dentro de word2vec solo hay una capa oculta, cuyos pesos codifican la codificación. En la salida, obtenemos una tabla de correspondencia vértice-vector. Todos estos enfoques tienen las siguientes limitaciones:
- Cada vértice está codificado por un vector único y el modelo no implica compartir parámetros;
- Solo podemos codificar los vértices que vio el modelo durante el entrenamiento; no podemos hacer nada por los nuevos vértices (excepto cómo volver a entrenar el codificador);
- Los vectores de propiedad de vértice no se tienen en cuenta de ninguna manera.
Las redes convolucionales gráficas están libres de las deficiencias indicadas. ¡Llegamos al decágono!
Nuestros días son un vagabundo aleatorio para todos y para todos
Sobre los vagabundos, tuve la suerte de escribir mi primer título de maestría y defenderlo en 2003, pero con un entrenamiento profundo tuve que seguir el camino clásico para descubrir qué había debajo del capó. Y es gracioso allí.
Primero, veamos por qué los métodos estándar de aprendizaje profundo no se ajustan a los gráficos.
¡Los recuentos no son gatos para ti!
El conjunto moderno de herramientas de aprendizaje profundo (redes multicapa, convolucionales y recurrentes) está optimizado para resolver problemas en datos bastante simples: secuencias y redes. Un gráfico es una estructura más complicada. Uno de los problemas que nos impedirá tomar la matriz de adyacencia y enviarla a la red neuronal es el isomorfismo .
En nuestra columna de juguete $ en línea $ g $ en línea $ que consiste en vértices $ en línea $ \ {A, B, C, D \} $ en línea $ , para construir una matriz de adyacencia $ en línea $ a $ en línea $ , sugerimos numeración de extremo a extremo $ en línea $ \ {1,2,3,4 \} $ en línea $ . Es fácil ver que podemos numerar los vértices de manera diferente, por ejemplo $ en línea $ \ {1,3,2,4 \} $ en línea $ o $ en línea $ \ {4,1,3,2 \} $ en línea $ - cada vez que recibe una nueva matriz de adyacencia del mismo gráfico.
$ en línea $ \ begin {align *} A = \ left [\ begin {matrix} 0 y 1 y 3 y 0 \\ 1 y 0 y 2 y 1 \\ 3 y 2 y 0 y 0 \\ 0 y 1 y 0 & 0 \ end {matrix} \ right], \, A ^ {\ {1,3,2,4 \}} = \ left [\ begin {matrix} 0 & 3 & 1 & 0 \\ 3 & 0 & 2 & 0 \\ 1 & 2 & 0 & 1 \\ 0 & 0 & 1 & 0 \ end {matrix} \ right], \, A ^ {\ {4,1,3,2 \}} = \ left [\ begin {matrix} 0 y 1 y 2 y 1 \\ 1 y 0 y 0 y 0 \\ 2 y 0 y 0 y 3 \\ 1 y 0 y 3 y 0 \ end {matriz} \ right]. \ end {align *} $ inline $
En el caso de los sellos, nuestra red tendría que aprender a reconocerlos para todas las permutaciones posibles de filas y columnas; ese es otro problema. Como ejercicio, intente cambiar la numeración de los puntos en la imagen a continuación para que cuando los conecte en serie, obtenga un gato.

El siguiente problema para los gráficos con redes neuronales ordinarias es la dimensión de entrada estándar. Cuando trabajamos con imágenes, siempre normalizamos el tamaño de la imagen para enviarla a la entrada de red; es un tamaño fijo. Tales gráficos no funcionarán con los gráficos (el número de vértices puede ser arbitrario), exprimir la matriz de conectividad a una dimensión dada sin perder información es otro desafío.
Solución: construiremos nuevas arquitecturas, inspiradas en la estructura de los gráficos.

Para hacer esto, usamos una estrategia simple de dos pasos:
- Para cada vértice, construimos un gráfico computacional usando un vagabundo;
- Recopilamos y transformamos información sobre vecinos.
Recordemos que almacenamos las propiedades de los vértices en vectores $ en línea $ f ^ {(u)} $ en línea $ - columnas matriciales $ en línea $ X \ in \ mathbb {R} ^ {k \ times | V |} $ en línea $ y nuestra tarea es para cada vértice $ en línea $ u $ en línea $ recoger propiedades de vértices vecinos $ en línea $ f ^ {(v \ en N (u))} $ en línea $ obtener vectores de incrustación $ en línea $ z_ {u} $ en línea $ . Un gráfico computacional puede ser de profundidad arbitraria. Considere una opción de dos capas.

La capa cero son las propiedades de los vértices, la primera es una agregación intermedia que utiliza alguna función (indicada por un signo de interrogación), la segunda es la agregación final, que produce los vectores de incrustación que nos interesan.
¿Y qué hay en las cajas?
En el caso simple , una capa de neuronas y no linealidad:
$$ display $$ h ^ 0_v = x_v (= f ^ {(v)}); \\ h ^ k_v = \ sigma (W_k \ sum_ {u \ in N (v)} \ frac {h ^ {k-1} _v} {| N (v) |} + B_k h ^ {k-1} _v), \ forall k \ in \ {1, ..., K \}; \\ z_v = h ^ K_v, $$ display $$
donde $ en línea $ W_k $ en línea $ y $ en línea $ B_k $ en línea $ - los pesos del modelo que aprenderemos por gradiente de descenso, aplicando una de las funciones de pérdida consideradas, y $ en línea $ \ sigma $ en línea $ - no linealidad, por ejemplo RELU: $ en línea $ \ sigma (x) = max (0, x) $ en línea $ .
Y aquí nos encontramos en una encrucijada, dependiendo de la tarea en cuestión, podemos:
- estudiar sin un maestro y aprovechar cualquiera de las funciones de pérdida consideradas anteriormente: vagabundos o el peso de los bordes. Los pesos resultantes se optimizarán para que los vectores de vértices similares se coloquen de forma compacta;
- Comience a entrenar con un maestro, por ejemplo, para resolver el problema de clasificación, preguntándose si el medicamento será tóxico.
Para el problema de clasificación binaria, la función de pérdida toma la forma:
$$ display $$ L = \ sum_ {v \ in V} y_v log (\ sigma (z_v ^ T \ theta)) + (1-y_v) log (1- \ sigma (z_v ^ T \ theta)), $ $ display $$
donde $ en línea $ y_v $ en línea $ - clase de vértice $ en línea $ v $ en línea $ , $ en línea $ \ theta $ en línea $ Es el vector de los pesos, y $ en línea $ \ sigma $ en línea $ - no linealidad, por ejemplo, un sigmoide: $ en línea $ \ sigma (x) = \ frac {1} {1 + e ^ {- x}} $ en línea $ .
Aquí, un lector capacitado reconocerá la entropía cruzada y la regresión logística, mientras que un lector no preparado pensará en tomar un curso de aprendizaje automático abierto para sentirse cómodo con la tarea de clasificación , algoritmos simples y más avanzados para resolverlo (incluido el aumento de gradiente ).
Y seguiremos adelante y consideraremos cómo funciona GraphSAGE , el heraldo de Decagon.

Para cada vértice $ en línea $ v $ en línea $ agregaremos información de los vecinos $ en línea $ u \ en N (v) $ en línea $ y ella misma.
$$ display $$ h ^ k_v = \ sigma ([W_k \ cdot AGG (\ {h ^ {k-1} _u, \ forall u \ en N (v) \}), B_k h ^ {k-1} _v]), $$ display $$
donde $ en línea $ AGG $ en línea $ - una designación generalizada de la función de agregación - lo más importante - diferenciable.
Promedio: tomar un promedio ponderado de los vecinos
$$ display $$ AGG = \ sum_ {u \ in N (v)} \ frac {h ^ {k-1} _u} {| N (v) |}. $$ display $$
Agrupación: valor medio / máximo por elemento
$$ display $$ AGG = \ gamma (\ {Qh ^ {k-1} _u, \ forall u \ in N (v) \}). $$ display $$
LSTM: sacude el entorno (¡no lo mezcles!) Y corre en LSTM
$$ display $$ AGG = LSTM ([h ^ {k-1} _u, \ forall u \ in \ pi (N (v))]). $$ display $$
Pinterest, , PinSAGE .
LSTM ( ). IT-.
:
, — . , . , , , . (/) , , , — — , 30 .
.
— (multi-label node
classification task) — . — . () ( — — 42% ). GraphSAGE, , — .
!
, — , , . , .
- , Decagon. , -, -, , -, — ri . . - 964 ( ) .

— , -, -.

,
— , RELU. , Decagon — . , , GraphSAGE. , .

, .
— , . -. , :
, :
, (end-to-end) -, : (i) — , (ii) — - -, (iii) — , (iv) — .
— - .
— .
— , , : 1) — — ; 2) " , , , " — - . , , , .
— — .
, ( ) , . , , GenBank 1 , , - — , . — , - ( ) , SNAP .
.
Neo4j , (property graph).

, . , , — (i) -, (ii) , (iii) , — — . .
— :

Además, la contribución de Neo4j a la industria es crear el lenguaje Cypher declarativo , que implementa un modelo gráfico con propiedades y opera en una forma similar a SQL con los siguientes tipos de datos: vértices, relaciones, diccionarios, listas, enteros, coma flotante y números binarios, y cuerdas Una consulta de ejemplo que devuelve una lista de películas con Nicole Kidman:
MATCH (nicole:Actor {name: 'Nicole Kidman'})-[:ACTED_IN]->(movie:Movie) WHERE movie.year < $yearParameter RETURN movie
Usando muletas, se puede hacer que Neo4j trabaje en la memoria.
También vale la pena mencionar Gephi , una herramienta conveniente para visualizar y diseñar gráficos en un avión, la primera herramienta de análisis de red de prueba personal. Con un estiramiento, podemos suponer que en Gephi es posible implementar un gráfico con las propiedades de vértices y bordes, aunque trabajar con él no será muy conveniente, y el conjunto de algoritmos para el análisis es limitado. Esto no resta valor a los méritos del paquete; para mí, está en primer lugar entre las herramientas de visualización. Al dominar el formato de almacenamiento interno GEXF , puede crear imágenes impresionantes. Atrae la capacidad de exportar fácilmente a la web, así como la capacidad de establecer propiedades para vértices y bordes a tiempo y obtener animaciones complejas como resultado: construyó las rutas para vendedores ambulantes a partir de datos de ventas. Todo gracias a la disposición de los gráficos en el mapa por las coordenadas de los vértices, la parte estándar del paquete.
Ahora llevo a cabo la mayor parte de la investigación analíticamente, hago dibujos al final.
Mi búsqueda de herramientas y métodos para procesar datos en sistemas con conexiones complejas continúa. Hace tres años encontré una solución para trabajar con gráficos multimodales. La biblioteca SNAP de Jure Leskovek es una herramienta que desarrolló para sí mismo y ya ha medido muchas cosas. Uso Snap.py : la versión para Python (proxy a funciones SNAP implementadas en C ++) y un conjunto de aproximadamente trescientas operaciones disponibles es suficiente para mí en la mayoría de los casos.
Recientemente, Marinka Zhitnik lanzó MAMBO , un conjunto de herramientas (dentro - SNAP) para trabajar con redes multimodales y un tutorial en forma de una serie de cuadernos Jupyter con un análisis ejemplar de mutaciones genéticas.
Finalmente, está el Gráfico SAP HANA , allí dentro de ML, SQL, OpenCypher, todo lo que tu corazón desea.
A favor de SAP HANA, el hecho de que excavar probablemente genere datos de transacciones bien estructurados de ERP, mientras que los datos puros valen mucho. Otra ventaja - herramientas poderosas para encontrar sub-gráficos por patrones dados - una tarea útil y difícil, cuya implementación en otros paquetes no ha cumplido y ha utilizado programas especializados . Una licencia gratuita para el desarrollador proporciona una base de datos de 1 GB, lo suficiente para jugar con redes lo suficientemente grandes. Una llamada divertida, un conjunto de algoritmos analíticos listos para usar, es pequeña, PageRank deberá implementarse de forma independiente. Para hacer esto, necesitará dominar GraphScript , un nuevo lenguaje de programación, pero esto es muy sencillo. Como dijo mi entrenador de remo de slalom, para el maestro, ¡es polvo!
Ahora sobre dónde obtener los datos para construir gráficos a partir de ellos. Algunas ideas
- Repositorios Públicos Universitarios: Stanford - General y Biomédica , Colorado ;
- Combine el plan del proyecto con la estructura organizacional y el registro de riesgos;
- Identificar la relación entre la estructura del producto, la tecnología y los deseos del usuario;
- Realizar un estudio sociográfico en equipo;
- Cree algo propio, inspirado en los proyectos del curso cs224w del año pasado .
A que temer
Podemos decir que aquí estará la última advertencia sobre los riesgos asociados con esta parte.

Como saben, damas y caballeros, el objetivo del programa es reflejar el estado de las cosas a la vanguardia de un grupo de investigación muy productivo y financiado generosamente. Esto es como Leningrado , solo sobre las matemáticas modernas. Posibles efectos secundarios:
- Dunning-Kruger , modificado, sin la euforia de un novato y una meseta de excelencia. Leskovek intenta ponerse al día.
- Aburrimiento en una provincia junto al mar. De las 400 personas en el curso que recibieron el aparato, me hicieron escribir un proyecto y aprobar el examen en la primera sesión durante mi segundo programa de maestría, los recuentos fueron uno y medio. Los docentes en sus actividades de investigación se han mantenido en el nivel de modularidad y medidas de centralidad. En mitaps sobre python y datos también es triste. En general, si no sabes entretenerte, te lo advertí.
- Orgullo con acento eslavo en habla inglesa.
Memo de reproducción
Hola reproductor!
En la aventura que nos dio Jura Leskovek, necesitas tiempo libre. El curso consta de 20 conferencias, cuatro tareas, cada una de las cuales se recomienda asignar aproximadamente 20 horas, literatura recomendada, así como una extensa lista de materiales adicionales que permitirán dar una primera impresión del estado de las cosas al frente del progreso en cualquiera de los temas discutidos.
Para completar las tareas, se recomienda utilizar la biblioteca SNAP (en cierto sentido, todo el curso puede considerarse como una descripción general de sus capacidades).
Además, puede intentar implementar su propio proyecto o escribir un tutorial sobre un tema que le guste.
Resumen de conferencias 2017:1. Introducción y estructura gráfica.
El análisis de red es un lenguaje universal para describir sistemas complejos y ahora es el momento de tratarlo. El curso se enfoca en tres áreas: propiedades de red, modelos y algoritmos. Comencemos con las formas de representar objetos: nodos, aristas y cómo organizarlos.
2. World Wide Web y modelo de gráfico aleatorio
Aprenderemos por qué Internet es como una mariposa y nos familiarizaremos con el concepto de componentes fuertemente relacionados. Cómo medir redes: propiedades básicas: distribución de grados de nodos, longitud de ruta y coeficiente de agrupamiento. Y familiarícese con el modelo del conde Erdos-Rainey al azar.
3. El fenómeno del mundo pequeño.
Medimos las principales propiedades de un gráfico aleatorio. Compárelo con redes reales. Hablemos sobre el número de Erdosh y lo pequeño que es el mundo. Recordemos a Stanley Milgram y unos seis apretones de manos. Finalmente, describimos todo lo que sucede matemáticamente (el modelo Watts-Strogatz).
4. Búsqueda descentralizada en el mundo pequeño y redes de perforación
Cómo navegar en una red distribuida. Y cómo funcionan los torrentes. Poniendo todo junto: propiedades, modelos y algoritmos.
5. Aplicaciones de análisis de redes sociales.
Medidas de centralidad. Personas en Internet: cómo alguien evalúa a quién. El efecto de la similitud. Estado Teoría del equilibrio estructural.
6. Redes con bordes ambiguos.
Balance de red. Me gusta y estatus mutuos. Cómo alimentar a los trolls.
7. Cascadas: modelos basados en decisiones
Distribución en redes: difusión de innovaciones, efectos de red, epidemias. Modelo de acción colectiva. Decisiones y teoría de juegos en redes.
8. Cascadas: modelos probabilísticos de difusión de información.
Modelos aleatorios de propagación de epidemias basadas en árboles. La propagación de llagas. Cascadas independientes. La mecánica del marketing viral. Simulamos las interacciones entre infecciones.
9. Maximizando la influencia
Cómo crear grandes cascadas. En general, ¿qué tan difícil es la tarea? Los resultados de los experimentos.
10. Detección de infección.
¿Qué tienen en común el contagio y las noticias? Cómo mantenerse al tanto de lo más interesante. Y dónde colocar los sensores en el suministro de agua.
11. Licenciatura en derecho y afiliación preferida
Proceso de crecimiento de la red. Redes invariantes de escala. Matemáticas de la función de distribución de poder. Consecuencias: estabilidad de la red. El modelo de adhesión preferido: los ricos se hacen más ricos.
12. Modelos de red en crecimiento
Colas de medición: exponencial versus exponencial. La evolución de las redes sociales. Una vista panorámica de todo esto.
13. gráficos de Kronecker
Seguimos el vuelo. Modelo de incendio forestal. Generación gráfica recursiva. Gráficos estocásticos de Kronecker. Experimentos con redes reales.
14. Análisis de enlaces: HITS y PageRank
¿Cómo organizar Internet? Centros y Autoridades. El hallazgo de Sergey Brin y Larry Page. Vagabundo borracho con teletransporte. Cómo hacer recomendaciones: experiencia en Pinterest.
15. La fuerza de los lazos débiles y la estructura comunitaria en las redes.
Tríadas y corrientes de información. ¿Cómo destacar las comunidades? El método Hirvan-Newman. Modularidad
16. Descubrimiento de la comunidad: agrupación espectral
Bienvenido matriz! Busca la sección óptima. Motivos (graflets). Cadenas alimentarias. Expresión génica.
17. redes biológicas
Interacciones proteicas. Identificación de cadenas de reacciones dolorosas. Determinación de atributos moleculares, como las funciones de proteínas en las células. ¿Qué hacen los genes? Ponemos atajos.
18. Redes cruzadas
Diferentes círculos sociales. Desde agrupaciones hasta comunidades que se cruzan.
19. Estudiar representaciones gráficas
La formación automática de características es solo una celebración para los perezosos. Incrustaciones gráficas. Nodo2vec. Desde gráficos individuales hasta estructuras jerárquicas complejas: OhmNet.
20. Redes: un par de diversión
Ciclo de vida de un participante abstracto de la comunidad. Y cómo manejar el comportamiento de la comunidad con insignias.
Creo que después de la inmersión en la teoría de grafos, las preguntas sobre los árboles ya no darán miedo. Sin embargo, esta es solo la opinión de un aficionado que nunca en su vida ha tomado una entrevista con un desarrollador.