Durante muchos años, Mail.ru ha organizado campeonatos de aprendizaje automático, cada vez que la tarea es interesante a su manera y compleja a su manera. Esta es la cuarta vez que participo en competiciones, me gusta mucho la plataforma y la organización, y fue con bootcamps que comenzó mi camino hacia el aprendizaje automático competitivo, pero logré tomar el primer lugar por primera vez. En el artículo, le diré cómo mostrar un resultado estable sin volver a entrenar en la tabla de clasificación pública o en muestras retrasadas, si la parte de prueba es significativamente diferente de la parte de capacitación de los datos.
Desafío
El texto completo de la tarea está disponible en →
enlace . En resumen: hay 10 GB de datos, donde cada línea contiene tres tipos json de "clave: contador", una determinada categoría, una determinada marca de tiempo e ID de usuario. Múltiples entradas pueden corresponder a un usuario. Se requiere determinar a qué clase pertenece el usuario, la primera o la segunda. La métrica de calidad para el modelo es ROC-AUC, está bien escrita al respecto en el blog de Alexander Dyakonov
[1] .
Entrada de archivo de ejemplo
00000d2994b6df9239901389031acaac 5 {"809001":2,"848545":2,"565828":1,"490363":1} {"85789":1,"238490":1,"32285":1,"103987":1,"16507":2,"6477":1,"92797":2} {} 39
Solución
La primera idea que surge de un científico de datos que ha descargado con éxito un conjunto de datos es convertir las columnas json en una matriz dispersa. En este punto, muchos participantes experimentaron problemas con la falta de RAM. Al implementar incluso una columna en python, el consumo de memoria fue mayor que el disponible en una computadora portátil promedio.
Algunas estadísticas secas. El número de claves únicas en cada columna es 2053602, 20275, 1057788. Además, en la parte del tren y en la parte de prueba solo hay 493866, 20268, 141931. 427994 usuarios únicos en el tren y 181024 en la parte de prueba. Aproximadamente el 4% de la clase 1 en la parte de capacitación.
Como puede ver, tenemos muchos signos, usarlos todos es una forma obvia de sobreajustar en el tren, porque, por ejemplo, los árboles de decisión usan combinaciones de signos, e incluso hay combinaciones más únicas de un número tan grande de signos y casi todos existen solo en la parte de entrenamiento datos o en prueba. Sin embargo, uno de los modelos básicos que tenía era lightgbm con colsample ~ 0.1 y una regularización muy estricta. Sin embargo, incluso a pesar de los enormes parámetros de regularización, mostró un resultado inestable en las partes públicas y privadas, ya que resultó después del final de la competencia.
El segundo pensamiento de la persona que decidió participar en esta competencia probablemente sería recoger el tren y probarlo, agregando información por identificadores. Por ejemplo, la cantidad. O un máximo. Y aquí resulta que dos cosas muy interesantes que Mail.ru ideó para nosotros. En primer lugar, la prueba se puede clasificar con una precisión muy alta. Incluso según las estadísticas sobre el número de entradas para cuid y el número de claves únicas en json, la prueba excede significativamente el tren. El clasificador base dio 0.9+ roc-auc en reconocimiento de prueba. En segundo lugar, los contadores no tienen ningún sentido, casi todos los modelos mejoraron al cambiar de contadores a signos binarios de la forma: no hay / no hay clave. Incluso los árboles, que en teoría no deberían ser peores por el hecho de que en lugar de una unidad hay un cierto número, parece ser reentrenado para los contadores.
Los resultados en la tabla de clasificación pública excedieron en gran medida los de la validación cruzada. Aparentemente, esto se debió al hecho de que era más fácil para el modelo construir la clasificación de dos registros en la prueba que en el tren, porque un mayor número de signos dio más términos para la clasificación.
En esta etapa, quedó completamente claro que la validación en esta competencia no es algo simple y ni la información pública ni los CV de otros participantes, que podrían ser engañados para atraerlos en el chat oficial
[2] . ¿Por qué sucedió? Parece que el tren y la prueba están separados por el tiempo, lo que luego fue confirmado por los organizadores.
Cualquier miembro experimentado de kaggle informará de inmediato la validación Adversarial
[3] , pero no es tan simple. A pesar de que la precisión del clasificador para el tren y la prueba es cercana a 1 por el métrico roc-auc, no hay muchas entradas similares en el tren. Traté de resumir las muestras agregadas de Cuid con el mismo objetivo para aumentar el número de registros con una gran cantidad de claves únicas en json, pero esto causó inconvenientes tanto en la validación cruzada como en público, y tenía miedo de usar tales modelos.
Hay dos formas: buscar valores eternos con aprendizaje no supervisado o tratar de tomar características que son más importantes para la prueba. Fui en ambos sentidos, usando TruncatedSVD para funciones sin supervisión y seleccionando características por frecuencia en la prueba.
El primer paso, sin embargo, hice un autoencoder profundo, pero me equivoqué, al tomar la misma matriz dos veces, no pude corregir el error y usar el conjunto completo de signos: el tensor de entrada no cabía en la memoria de la GPU en ningún tamaño de capa densa. Encontré un error y luego no intenté codificar las funciones.
Generé SVD de todas las formas imaginativas: en el conjunto de datos original con cat_feature y la suma posterior por cuid. Para cada columna por separado. Por tf-idf en json como bolsa de palabras
[4] (no ayudó).
Para una mayor variedad, intenté seleccionar una pequeña cantidad de características en el tren, usando A-NOVA para la parte del tren de cada pliegue en la validación cruzada.
Modelos
Los principales modelos base: lightgbm, votepal wabbit, xgboost, SGD. Además, utilicé varias arquitecturas de redes neuronales. Dmitry Nikitko, que estaba en el primer lugar de la tabla de clasificación pública, recomendó usar
HashEmbeddings , este modelo después de una selección de parámetros mostró un buen resultado y mejoró el conjunto.
Otro modelo de red neuronal con búsqueda de interacciones (estilo de máquina de factorización) entre 3-4-5 columnas de datos (tres entradas a la izquierda), estadísticas numéricas (4 entradas), matriz SVD (5 entradas).
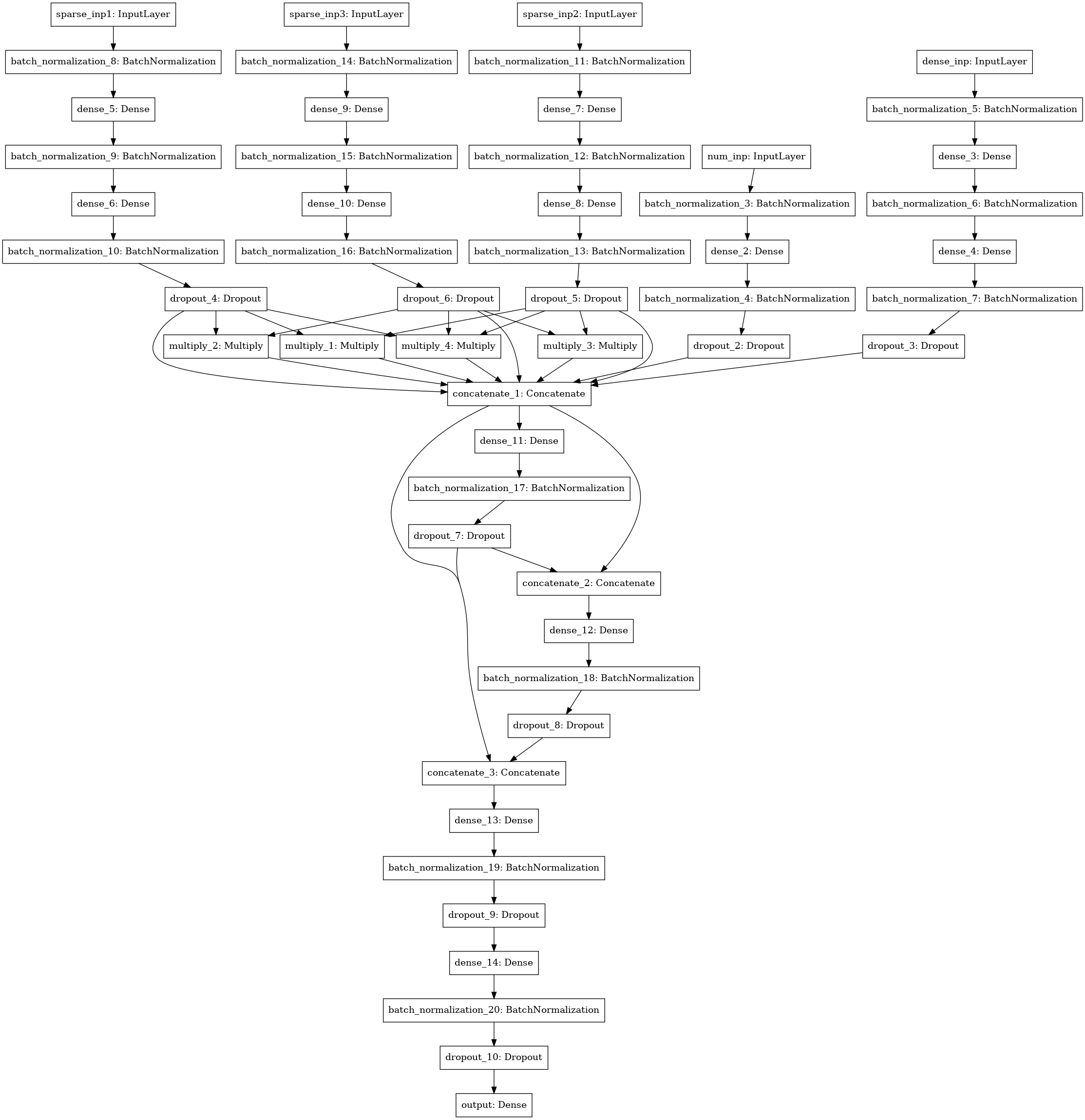
Conjunto
Conté todos los modelos por pliegues, promediando las predicciones de prueba de modelos entrenados en varios pliegues. Se usaron predicciones de trenes para apilar. El mejor resultado lo mostró la pila de nivel 1 usando xgboost en las predicciones de los modelos base y 250 atributos de cada columna json, seleccionados de acuerdo con la frecuencia con la que se reunió el atributo en la prueba.
Pasé ~ 30 horas de mi tiempo en la solución, contando con un servidor con 4 núcleos core-i7, 64 gigabytes de RAM y un GTX 1080. Como resultado, mi solución resultó ser bastante estable y pasé del tercer lugar en la clasificación pública al primero privado.
Una parte sustancial del código está disponible en un bitbucket en forma de computadoras portátiles
[5] .
¡Quiero agradecer a Mail.ru por concursos interesantes y otros participantes por la comunicación interesante en el grupo!
[1]
ROC-AUC en el blog de Aleksandrov Dyakonov[2]
Oficial de chat oficial de ML BootCamp[3]
Validación adversaria[4]
bolsa de palabras[5]
código fuente para la mayoría de los modelos