
Las tareas de almacenamiento y acceso a datos son un punto de dolor para cualquier sistema de información. Incluso un sistema de almacenamiento bien diseñado (en lo sucesivo denominado SHD) durante la operación revela problemas asociados con un rendimiento reducido. Se debe prestar especial atención a un conjunto de problemas de escala cuando la cantidad de recursos involucrados se acerca a los límites establecidos establecidos por los desarrolladores de almacenamiento.
La razón fundamental de la aparición de estos problemas es la arquitectura tradicional basada en un enlace estricto con las características de hardware de los dispositivos de almacenamiento utilizados. La mayoría de los clientes aún eligen el método de almacenamiento y acceso a los datos, teniendo en cuenta las características de las interfaces físicas (SAS / SATA / SCSI) y no las necesidades reales de las aplicaciones utilizadas.
Hace una docena de años, esta fue una decisión lógica. Los administradores del sistema seleccionaron cuidadosamente los dispositivos de almacenamiento de información con las especificaciones requeridas, por ejemplo, SATA / SAS, y contaron con la obtención de un nivel de rendimiento basado en las capacidades de hardware de los controladores de disco. La lucha fue por el volumen de cachés del controlador RAID y por las opciones que evitan la pérdida de datos. Ahora este enfoque para resolver el problema no es óptimo.
En el entorno actual, al elegir sistemas de almacenamiento, tiene sentido comenzar no desde interfaces físicas, sino desde el rendimiento expresado en IOPS (el número de operaciones de E / S por segundo). El uso de la virtualización le permite utilizar de manera flexible los recursos de hardware existentes y garantizar el nivel de rendimiento requerido. Por nuestra parte, estamos listos para proporcionar recursos con esas características que son realmente necesarias para la aplicación.
Virtualización de almacenamiento
Con el desarrollo de los sistemas de virtualización, fue necesario encontrar una solución innovadora para almacenar y acceder a los datos, al tiempo que se garantizaba la tolerancia a fallas. Este fue el punto de partida para crear SDS (almacenamiento definido por software). Para satisfacer las necesidades comerciales, estos repositorios fueron diseñados con la separación de software y hardware.
La arquitectura SDS es fundamentalmente diferente de la tradicional. La lógica de almacenamiento se ha abstraído a nivel de software. La organización del almacenamiento se ha vuelto más fácil debido a la unificación y virtualización de cada uno de los componentes de dicho sistema.
¿Cuál es el factor principal que obstaculiza la implementación de SDS en todas partes? Este factor con mayor frecuencia es una evaluación incorrecta de las necesidades de las aplicaciones utilizadas y una evaluación de riesgos incorrecta. Para una empresa, la elección de la solución depende del costo de implementación, en función de los recursos actuales consumidos. Pocas personas piensan: qué sucederá cuando la cantidad de información y el rendimiento requerido excedan las capacidades de la arquitectura seleccionada. Pensar sobre la base del principio metodológico "uno no debería multiplicar lo existente sin necesidad", mejor conocido como "la espada de Occam", determina la elección a favor de las soluciones tradicionales.
Solo unos pocos entienden que la necesidad de escalabilidad y confiabilidad del almacenamiento de datos es más importante de lo que parece a primera vista. La información es un recurso y, por lo tanto, el riesgo de su pérdida debe estar asegurado. ¿Qué sucederá cuando un sistema de almacenamiento tradicional se caiga? Deberá usar la garantía o comprar equipos nuevos. ¿Y si el sistema de almacenamiento se interrumpe o ha finalizado el "período de vida" (el llamado EOL - End-of-Life)? Este puede ser un día negro para cualquier organización que no pueda continuar utilizando sus propios servicios familiares.
No hay sistemas que no tengan un solo punto de falla. Pero hay sistemas que pueden sobrevivir fácilmente a la falla de uno o más componentes. Tanto los sistemas de almacenamiento virtuales como los tradicionales se crearon teniendo en cuenta el hecho de que tarde o temprano se producirá una falla. Ese es solo el "límite de fuerza" de los sistemas de almacenamiento tradicionales establecidos en el hardware, pero en los sistemas de almacenamiento virtual se determina en la capa de software.
Integración
Los cambios dramáticos en la infraestructura de TI son siempre un fenómeno indeseable, cargado de tiempo de inactividad y pérdida de fondos. Solo la implementación fluida de nuevas soluciones hace posible evitar consecuencias negativas y mejorar el trabajo de los servicios. Es por eso que Selectel diseñó y
lanzó la nube basada en VMware , un líder reconocido en el mercado de virtualización. El servicio creado por nosotros permitirá que cada empresa resuelva toda la gama de tareas de infraestructura, incluido el almacenamiento de datos.
Le diremos exactamente cómo decidimos la elección de un sistema de almacenamiento, así como qué ventajas nos dio esta opción. Por supuesto, se consideraron tanto los sistemas de almacenamiento tradicionales como las SDS. Para comprender claramente todos los aspectos de la operación y los riesgos, ofrecemos una visión más profunda del tema.
En la etapa de diseño, se impusieron los siguientes requisitos a los sistemas de almacenamiento:
- tolerancia a fallas;
- rendimiento
- escalado
- la capacidad de garantizar velocidad;
- funcionamiento correcto en el ecosistema VMware.
El uso de soluciones de hardware tradicionales no podría proporcionar el nivel requerido de escalabilidad, ya que es imposible aumentar constantemente el volumen de almacenamiento debido a limitaciones arquitectónicas. La reserva a nivel de un centro de datos completo también fue de gran dificultad. Por eso dirigimos nuestra atención a SDS.
Hay varias soluciones de software en el mercado de SDS que nos convienen para construir una nube basada en VMware vSphere. Entre estas soluciones se pueden observar:
- Dell EMC ScaleIO;
- SAN virtual hiperconvergente de Datacore;
- HPE StoreVirtual.
Estas soluciones son adecuadas para usar con VMware vSphere, sin embargo, no se integran en el hipervisor y se ejecutan por separado. Por lo tanto, la elección se hizo a favor de VMware vSAN. Consideremos en detalle cómo se ve la arquitectura virtual de tal solución.
Arquitectura
Imagen tomada de la documentación oficial.A diferencia de los sistemas de almacenamiento tradicionales, toda la información no se almacena en ningún punto. Los datos de la máquina virtual se distribuyen uniformemente entre todos los hosts, y el escalado se realiza agregando hosts o instalando unidades de disco adicionales en ellos. Se admiten dos opciones de configuración:
- Configuración AllFlash (solo unidades de estado sólido, tanto para almacenamiento de datos como para caché);
- Configuración híbrida (almacenamiento magnético y caché de estado sólido).
El procedimiento para agregar espacio en el disco no requiere configuraciones adicionales, por ejemplo, crear un LUN (Número de unidad lógica, números de disco lógico) y configurar el acceso a ellos. Tan pronto como se agregue el host al clúster, su espacio en disco estará disponible para todas las máquinas virtuales. Este enfoque tiene varias ventajas significativas:
- falta de vinculación con el fabricante del equipo;
- mayor tolerancia a fallas;
- asegurar la integridad de los datos en caso de falla;
- centro de control único desde la consola vSphere;
- conveniente escala horizontal y vertical.
Sin embargo, esta arquitectura impone altas demandas en la infraestructura de red. Para garantizar el máximo rendimiento, en nuestra nube la red se basa en el modelo Spine-Leaf.
Red
El modelo de red tradicional de tres niveles (núcleo / agregación / acceso) tiene una serie de inconvenientes importantes. Un ejemplo sorprendente son las limitaciones de los protocolos Spanning-Tree.
El modelo Spine-Leaf utiliza solo dos niveles, lo que ofrece las siguientes ventajas:
- distancia predecible entre dispositivos;
- el tráfico va por la mejor ruta;
- facilidad de escalamiento;
- Exclusión de restricciones de protocolo L2.
Una característica clave de dicha arquitectura es que está optimizada para el paso del tráfico "horizontal". Los paquetes de datos pasan por un solo salto, lo que permite una estimación clara de los retrasos.
Se proporciona una conexión física utilizando varios enlaces de 10 GbE por servidor, cuyo ancho de banda se combina mediante el protocolo de agregación. Por lo tanto, cada host físico recibe acceso de alta velocidad a todos los objetos de almacenamiento.
El intercambio de datos se implementa utilizando un protocolo patentado creado por VMware, que permite un funcionamiento rápido y confiable de la red de almacenamiento en el transporte Ethernet (desde 10 GbE y superior).
La transición al modelo de objetos del almacenamiento de datos permitió un ajuste flexible del uso del almacenamiento de acuerdo con los requisitos de los clientes. Todos los datos se almacenan en forma de objetos que se distribuyen de cierta manera entre los hosts del clúster. Aclaramos los valores de algunos parámetros que se pueden controlar.
Tolerancia a fallos
- FTT (Fallos de tolerancia). Indica el número de fallas de host que el clúster puede manejar sin interrumpir la operación regular.
- FTM (Método de tolerancia a fallas). El método para garantizar la tolerancia a fallos a nivel de disco.
a. Reflejo
Imagen tomada del blog de VMware.
Representa una duplicación completa de un objeto, y las réplicas siempre se encuentran en diferentes hosts físicos. El análogo más cercano a este método es RAID-1. Su uso permite que el clúster procese rutinariamente hasta tres fallas de cualquier componente (discos, hosts, pérdida de red, etc.). Este parámetro se configura configurando la opción FTT.
De forma predeterminada, esta opción tiene un valor de 1 y se crea 1 réplica para el objeto (solo 2 instancias en diferentes hosts). A medida que aumenta el valor, el número de copias será N + 1. Por lo tanto, con un valor máximo de FTT = 3, 4 instancias del objeto estarán en diferentes hosts.
Este método le permite alcanzar el máximo rendimiento a expensas de la eficiencia del espacio en disco. Se puede utilizar en configuraciones híbridas y AllFlash.
b. Codificación de borrado (análogo de RAID 5/6).
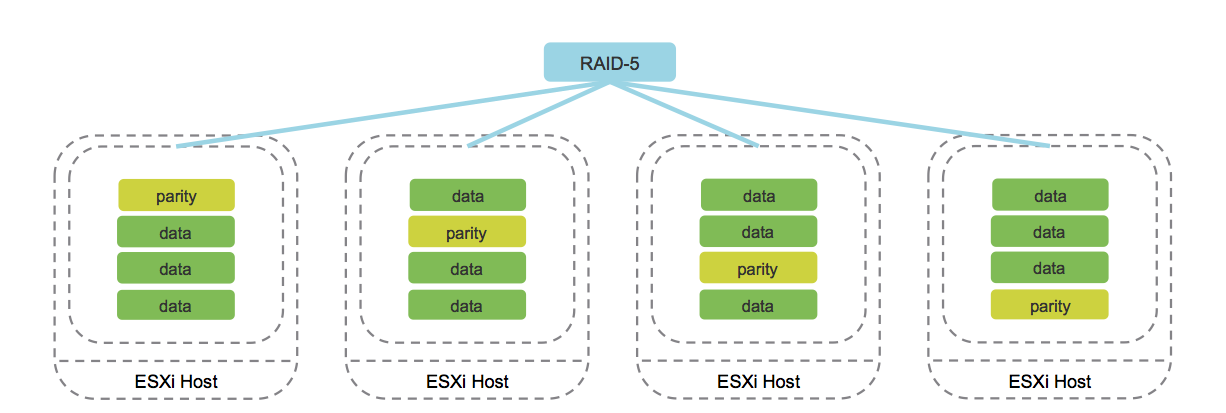
Imagen tomada del blog cormachogan.com.
El trabajo de este método se admite exclusivamente en configuraciones AllFlash. En el proceso de grabación de cada objeto, se calculan los bloques de paridad correspondientes, que permiten recuperar datos de manera única en caso de falla. Este enfoque ahorra significativamente espacio en disco en comparación con Mirroring.
Por supuesto, la operación de este método aumenta la sobrecarga, que se expresa en una disminución de la productividad. Sin embargo, dado el rendimiento de la configuración de AllFlash, este inconveniente se nivela, lo que hace que el uso de Codificación de borrado sea una opción aceptable para la mayoría de las tareas.
Además, VMware vSAN presenta el concepto de "dominios de falla", que son una agrupación lógica de bastidores de servidores o cestas de discos. Tan pronto como se agrupan los elementos necesarios, esto conduce a la distribución de datos entre diferentes nodos teniendo en cuenta los dominios de falla. Esto permite que el clúster sobreviva a la pérdida de un dominio completo, ya que todas las réplicas correspondientes de los objetos se ubicarán en otros hosts en un dominio de falla diferente.
El dominio más pequeño de falla es un grupo de discos, que es una unidad de disco conectada lógicamente. Cada grupo de discos contiene dos tipos de medios: caché y capacidad. Como un medio de caché, el sistema permite usar solo discos de estado sólido, y tanto los discos magnéticos como los de estado sólido pueden actuar como portadores de capacidad. El almacenamiento en caché de medios ayuda a acelerar los discos magnéticos y reduce la latencia al acceder a los datos.
Implementación
Hablemos sobre las limitaciones que existen en la arquitectura VMware vSAN y por qué son necesarias. Independientemente de las plataformas de hardware utilizadas, la arquitectura proporciona las siguientes restricciones:
- no más de 5 grupos de discos por host;
- no más de 7 portadores de capacidad en un grupo de discos;
- no más de 1 portadora de caché en un grupo de discos;
- no más de 35 portadores de capacidad por host;
- no más de 9000 componentes por host (incluidos los componentes de testigo);
- no más de 64 hosts en un clúster;
- no más de 1 vSAN-datastore por cluster.
¿Por qué se necesita esto? Hasta que se excedan los límites especificados, el sistema funcionará con la capacidad declarada, manteniendo un equilibrio entre el rendimiento y la capacidad de almacenamiento. Esto le permite garantizar el funcionamiento correcto de todo el sistema de almacenamiento virtual en su conjunto.
Además de estas limitaciones, se debe recordar una característica importante. No se recomienda llenar más del 70% del volumen total de almacenamiento. El hecho es que cuando se alcanza el 80%, el mecanismo de reequilibrio se inicia automáticamente y el sistema de almacenamiento comienza a redistribuir los datos en todos los hosts del clúster. El procedimiento requiere muchos recursos y puede afectar seriamente el rendimiento del subsistema de disco.
Para satisfacer las necesidades de una amplia variedad de clientes, hemos implementado tres grupos de almacenamiento para facilitar su uso en varios escenarios. Miremos cada uno de ellos en orden.
Agrupación rápida de discos
La prioridad para crear este grupo era obtener un almacenamiento que proporcionara el máximo rendimiento para alojar sistemas altamente cargados. Los servidores de este grupo usan un par de Intel P4600 como caché y 10 Intel P3520 para el almacenamiento de datos. El caché en este grupo se utiliza para que los datos se lean directamente desde los medios y las operaciones de escritura se realicen a través del caché.
Para aumentar la capacidad útil y garantizar la tolerancia a fallas, se utiliza un modelo de almacenamiento de datos llamado Erasure Coding. Este modelo es similar a una matriz RAID 5/6 normal, pero a nivel de almacenamiento de objetos. Para eliminar la probabilidad de corrupción de datos, vSAN usa un mecanismo de cálculo de suma de verificación para cada bloque de datos 4K.
La validación se realiza en segundo plano durante las operaciones de lectura / escritura, así como para los datos "en frío", cuyo acceso no se solicitó durante el año. Cuando se detecta una falta de coincidencia de suma de comprobación y, por lo tanto, se detecta corrupción de datos, vSAN recuperará automáticamente los archivos sobrescribiéndolos.
Conjunto de unidades híbridas
En el caso de este grupo, su tarea principal es proporcionar una gran cantidad de datos, mientras se garantiza un buen nivel de tolerancia a fallas. Para muchas tareas, la velocidad de acceso a los datos no es una prioridad, el volumen y el costo de almacenamiento son mucho más importantes. El uso de unidades de estado sólido como tal almacenamiento tendrá un costo irrazonablemente alto.
Este factor fue la razón de la creación del grupo, que es un híbrido de almacenamiento en caché de unidades de estado sólido (como en otros grupos es Intel P4600) y discos duros de nivel empresarial desarrollados por HGST. Un flujo de trabajo híbrido acelera el acceso a los datos solicitados frecuentemente al almacenar en caché las operaciones de lectura y escritura.
A nivel lógico, los datos se reflejan para eliminar la pérdida en caso de una falla de hardware. Cada objeto se divide en componentes idénticos y el sistema los distribuye a diferentes hosts.
Piscina con recuperación ante desastres

La tarea principal del grupo es lograr el nivel máximo de tolerancia a fallas y rendimiento. El uso de la tecnología
vSAN estirada nos permitió
distribuir el almacenamiento entre los centros de datos Tsvetochnaya-2 en San Petersburgo y Dubrovka-3 en la región de Leningrado. Cada servidor en este grupo está equipado con un par de unidades Intel P4600 de alta velocidad y capacidad para operación de caché y 6 unidades Intel P3520 para almacenamiento de datos. A nivel lógico, estos son 2 grupos de discos por host.
La configuración de AllFlash no tiene un inconveniente grave: una fuerte caída en IOPS y un aumento en la cola de solicitudes de disco con un mayor volumen de acceso aleatorio a los datos. Al igual que en un grupo con discos rápidos, las operaciones de escritura pasan por el caché y la lectura se realiza directamente.
Ahora sobre la diferencia principal del resto de las piscinas. Los datos de cada máquina virtual se reflejan dentro de un centro de datos y al mismo tiempo se replican sincrónicamente en otro centro de datos que nos pertenece. Por lo tanto, incluso un accidente grave, como una interrupción completa de la conectividad entre los centros de datos, no será un problema. Incluso una pérdida completa del centro de datos no afectará los datos.
Un accidente con una falla completa del sitio: la situación es bastante rara, pero vSAN puede sobrevivir con honor sin perder datos. Los invitados a nuestro evento
SelectelTechDay 2018 pudieron ver por sí mismos cómo el clúster vSAN estirado experimentó una falla completa del sitio. Las máquinas virtuales estuvieron disponibles solo un minuto después de que todos los servidores de uno de los sitios se apagaran. Todos los mecanismos funcionaron exactamente según lo planeado, pero los datos permanecieron intactos.
El abandono de la arquitectura de almacenamiento familiar conlleva muchos cambios. Uno de estos cambios fue la aparición de nuevas "entidades" virtuales, que incluyen el dispositivo testigo. El significado de esta solución es rastrear el proceso de grabación de réplicas de datos y determinar cuál es relevante. Al mismo tiempo, los datos en sí no se almacenan en componentes de testigos, solo metadatos sobre el proceso de grabación.
Este mecanismo surte efecto en caso de un accidente cuando ocurre una falla durante el proceso de replicación, lo que resulta en que las réplicas no estén sincronizadas.
Para determinar cuál contiene información relevante, se utiliza un mecanismo de determinación de quórum. Cada componente tiene un "derecho de voto" y se le asigna un cierto número de votos (1 o más). El mismo "derecho de voto" tiene componentes de testigos que desempeñan el papel de árbitros en caso de una situación controvertida.
Se alcanza un quórum solo cuando una réplica completa está disponible para un objeto y el número de "votos" actuales es superior al 50%.
Conclusión
La elección de VMware vSAN como sistema de almacenamiento se ha convertido en una decisión importante para nosotros. Esta opción pasó las pruebas de estrés y las pruebas de tolerancia a fallas antes de que se incluyera en nuestro proyecto de nube basado en VMware.
Según los resultados de la prueba, quedó claro que la funcionalidad declarada funciona como se esperaba y cumple con todos los requisitos de nuestra infraestructura en la nube.
¿Tiene algo que contar basado en su propia experiencia con vSAN? Bienvenidos a los comentarios.