Hace unos meses, se lanzó la primera versión de Kepler.gl, una nueva herramienta de código abierto para visualizar y analizar grandes conjuntos de datos geográficos.
En este artículo, le sugiero que se familiarice con las características principales de la aplicación y cree usando dos visualizaciones cartográficas que nos permitirán conocer algunos datos interesantes sobre el estacionamiento pagado en Moscú.
Pero primero, algunas palabras sobre quién y por qué creó Kepler.gl
Inicialmente, Kepler.Gl fue creado por el equipo de Ingeniería de Uber para analistas de la compañía que querían comprender mejor "cómo se mueve la ciudad", utilizando para ello una gran cantidad de datos de tráfico de información geográfica recopilados diariamente por miles de "uber" en varias ciudades de todo el mundo.
Sin embargo, en mayo de este año, la compañía anunció el acceso abierto a esta aplicación y publicó todo el código fuente de Kepler.gl en GitHub
Características clave de Kepler.gl
Independientemente de las herramientas de análisis de datos seleccionadas, los servicios o marcos de mapas utilizados, así como las bibliotecas para crear diversas visualizaciones, el proceso de trabajar en ellas se reduce a 4 etapas principales:
- recopilación de información
- procesamiento de datos
- investigación y análisis de datos preparados (para identificar dependencias, buscar anomalías, etc.)
- creación de visualización
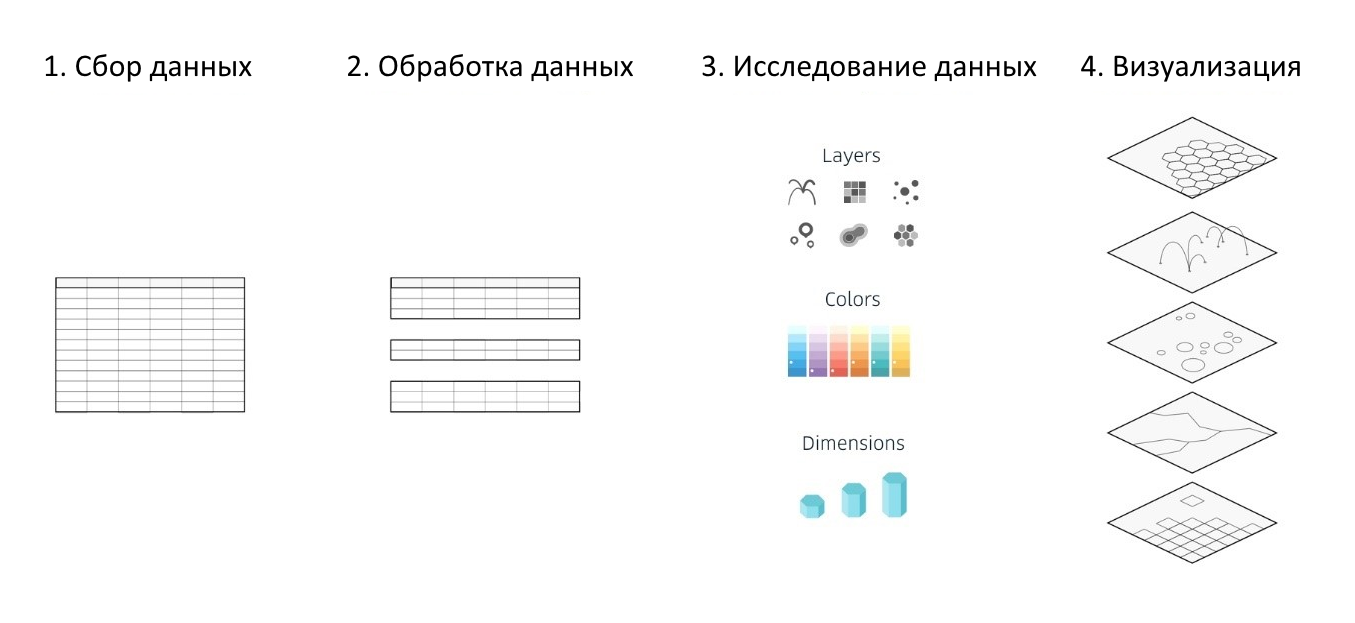 Figura 1. Las etapas básicas de la creación de una visualización.
Figura 1. Las etapas básicas de la creación de una visualización.Kepler.gl automatiza y simplifica parcialmente 3 de los 4 pasos enumerados, lo que simplifica significativamente todo el proceso de análisis y visualización de grandes conjuntos de datos y ayuda a crear un mapa informativo, y lo más importante, colorido e interactivo basado en sus propios conjuntos de datos geográficos en solo media hora.
Al mismo tiempo, no se requiere experiencia en programación o diseño, ya que el filtrado y la agregación de datos, la elección de una forma de mostrar los datos en función de diversos parámetros de los objetos que se estudian, la superposición de información de varias fuentes, el cambio entre los modos 2D y 3D, y mucho más se configura utilizando el panel de la interfaz de usuario.
Cómo usar Kepler.gl para el análisis de datos
La forma más fácil es comenzar a familiarizarse con Kepler.gl utilizando su versión en línea, disponible en
kepler.gl o, si no confía en servidores de terceros, puede implementar una versión local para usted, siguiendo las instrucciones en
GitHub .
En lo sucesivo, utilizaré los datos sobre "Estacionamiento pagado en Moscú" proporcionados por el "Portal de datos abiertos" del gobierno de Moscú. Este conjunto contiene información sobre más de 9 mil objetos ubicados en la red de calles, incluida información sobre el costo y la cantidad de espacios de estacionamiento.
Etapa 1. Carga de datos
Hasta la fecha, Kepler.gl admite 3 formatos de datos de origen: geojson, json y csv. Habiendo guardado los datos en uno de los formatos indicados (en este ejemplo uso .csv), simplemente los cargamos en la aplicación. Por cierto, aquí, en el cuadro de diálogo de descarga, para familiarizarse con la aplicación, también puede usar uno de los docenas de conjuntos de datos de prueba predefinidos.
Nota Para Chrome, el tamaño máximo del archivo de carga no debe exceder los 250Mb. Los creadores de Kepler.gl sugieren usar Safari si necesita descargar un archivo más grande. Sin embargo, en cualquier caso, debe recordar que el rendimiento de la aplicación depende del dispositivo en el que se ejecuta. Después de todo, todas las manipulaciones asociadas con la agregación, el filtrado y la visualización de datos se producen en el cliente.
Etapa 2. Mostrar datos en un mapa
La aplicación admite 9 tipos de capas de visualización (capa de visualización de datos), que difieren entre sí en un conjunto de parámetros personalizables:
- capa de puntos
- capa de arcos (arco)
- capa de líneas (línea)
- rejilla (rejilla)
- rejilla hexagonal (Hexbin)
- polígonos de capa (Poligon)
- capa de clúster (Claster)
- capa de icono (icono)
- mapa de calor (mapa de calor)
Además, incluso las capas del mismo tipo, que muestran el mismo conjunto de datos, pueden diferir dramáticamente dependiendo de la configuración seleccionada.

Figura 2. Mapas creados en kepler.gl usando varios tipos de capas
Kepler.gl no limita el número de capas utilizadas al mostrar el conjunto de datos de prueba. Las capas se dibujan en el mapa en el mismo orden en que se ubican en la lista de capas en el panel lateral. Esta secuencia se puede cambiar fácilmente arrastrando las capas correspondientes entre sí en la pestaña Capas.
Cuando utilice varias capas, preste atención al parámetro "Fusión de capas", que es responsable de cómo se superponen las capas. Es uniforme en toda la visualización, lo que hace que sea imposible usar diferentes tipos de mezcla para diferentes capas.
Actualmente, hay tres valores disponibles para este parámetro:
- Normal
En este caso, las capas inferiores no afectan el color de los puntos (u otros elementos) de las capas superiores.
- Aditivo
Con este tipo de superposición, los valores de color de los elementos coincidentes se suman. Es conveniente para identificar áreas de alta densidad, que en este caso serán más brillantes. - Sustractivo
A diferencia del aditivo, no suma, sino que resta el significado de los colores en las áreas que se cruzan. Es conveniente cuando se usa no una tarjeta oscura, sino una clara.
Por lo tanto, para ver nuestros datos en el mapa, es necesario crear al menos una capa con ellos. Vale la pena señalar que después de descargar el archivo, Kepler.gl intentará identificar los campos que contienen información de geolocalización y mostrarlos instantáneamente, creando automáticamente capas de los tipos correspondientes (generalmente punto o polígono).
Sin embargo, en nuestro caso, debido a la diferencia en los formatos de datos esperados y utilizados, deberá especificar la fuente de coordenadas usted mismo. Para hacer esto, primero elimine las capas de polígono creadas por Kepler.gl, y luego agregue manualmente una nueva capa de tipo Punto. Como fuente de coordenadas, utilizamos los campos Latitude_WGS84 y Longitude_WGS84 en lugar del campo Coordenadas seleccionado automáticamente por la aplicación para representar datos en el mapa.
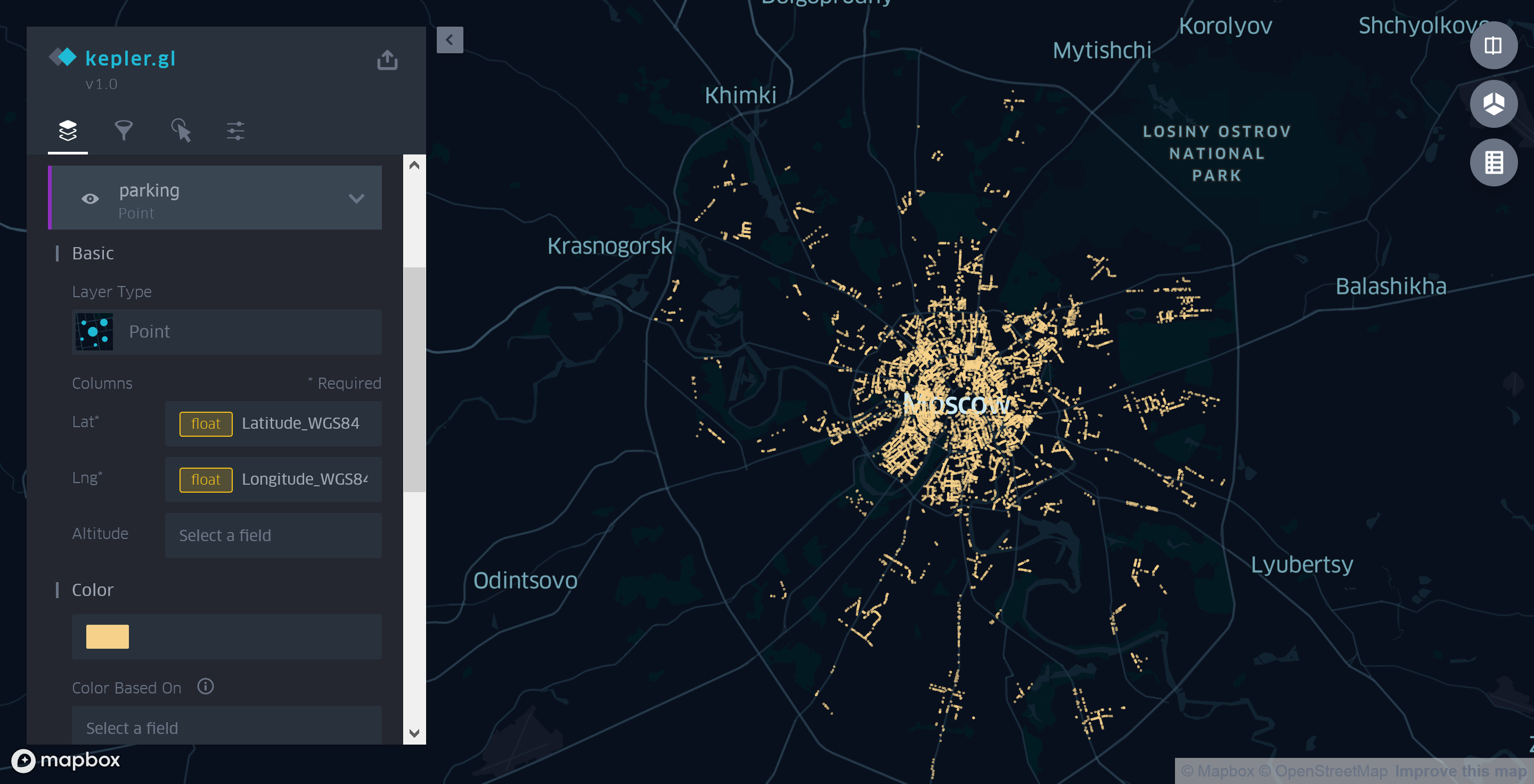
Figura 3. Uso de la capa de puntos Kepler.gl para mostrar los estacionamientos de Moscú
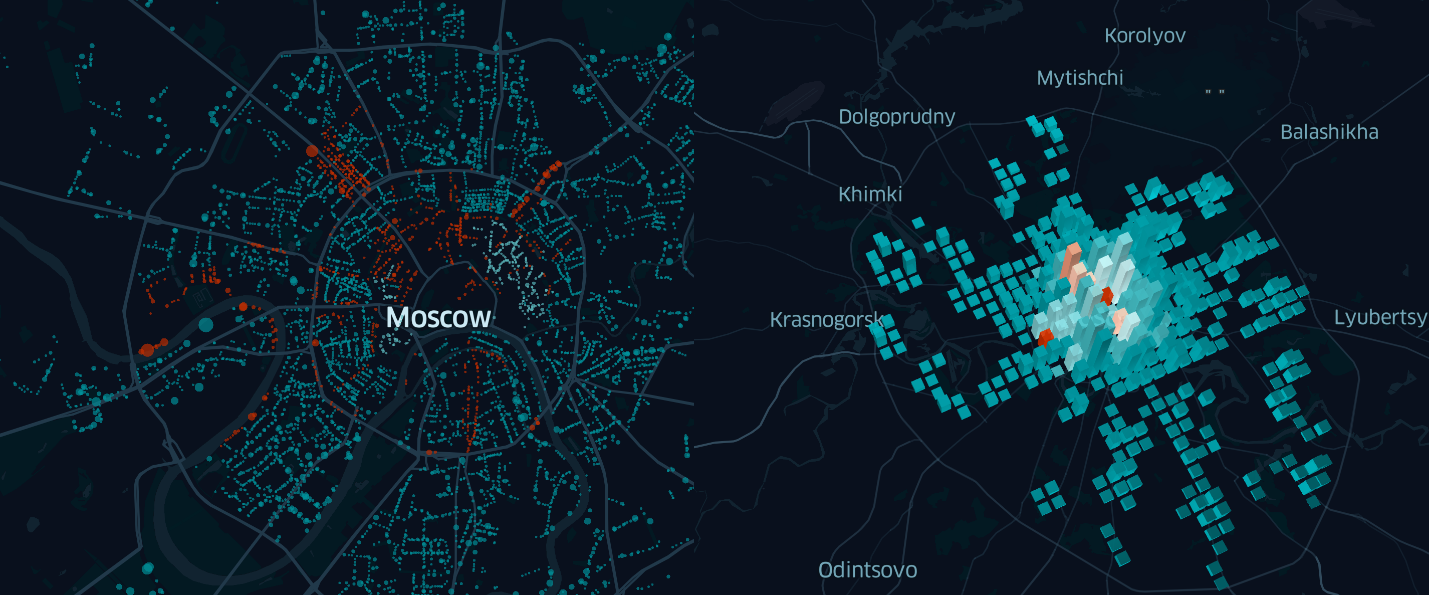
En esta realización, la tarjeta no es muy informativa. Lo único que se puede decir, mirándola, es que hay más estacionamientos en el centro que en las afueras.
Por lo tanto, es hora de utilizar otra información sobre los objetos estudiados para un análisis más detallado y buscar datos y / o patrones interesantes.
Etapa 3. Modificación de la apariencia del mapa sobre la base de datos relacionados en los objetos mostrados
El conjunto descargado del Open Data Portal contiene mucha información sobre cada uno de los estacionamientos, sin embargo, dos parámetros me parecieron los más interesantes: el costo de una hora de estacionamiento y la cantidad de espacios disponibles.
¿Dónde están los estacionamientos más caros en Moscú? ¿Existe una relación entre el tamaño del estacionamiento y su distancia del centavo? ¿Cuál es la diferencia en el costo de una hora de estacionamiento dentro y fuera del Garden Ring? Para responder a estas preguntas, es suficiente que cambiemos ligeramente la configuración de visualización de la capa de puntos creada anteriormente y que volvamos a mirar el mapa.
Primero, cambie el color de los puntos dependiendo del costo de una hora de estacionamiento en este lugar. Para hacer esto, en la lista desplegable "Color basado en", como base para elegir un color, indicamos el parámetro "Precio" del conjunto de datos original.

Figura 4. Uso del color para mostrar información sobre el costo de la hora de estacionamiento
Ya en esta etapa, se pueden hacer varias observaciones interesantes. Por ejemplo, que no todo el centro es igual de caro para los automovilistas, pero en Tverskaya es mejor ser peatón
Ahora veamos la capacidad de los estacionamientos. Para esto, utilizaremos el campo "CarCapacity" como parámetro básico para determinar el radio de un punto (el atributo "Radius Based On" de una capa de puntos). Establezca el rango de radio de 0 a 30px.

Figura 5. Personalización del tamaño de los puntos en función del número de plazas de aparcamiento.
Por lo tanto, en solo unos minutos, nuestro mapa de estacionamiento se ha vuelto notablemente más informativo. Ahora, incluso una mirada superficial permite no solo comparar la política de precios de diferentes áreas de la ciudad, sino también evaluar aproximadamente sus posibilidades de encontrar un espacio libre dada no solo la cantidad de estacionamientos en las cercanías, sino también su amplitud.
Etapa 4. Agregando datos con Kepler.gl
El uso de una capa de puntos para mostrar cada uno de más de 9000 estacionamientos ya nos ha permitido hacer algunas observaciones interesantes, pero el mapa no nos permite responder fácilmente preguntas como "¿Dónde están la mayoría de los espacios de estacionamiento por unidad de área?" Para responderlo, necesitamos usar una de las capas de agregación.
Actualmente, Kepler.Gl admite 4 tipos de tales capas: cuadrícula (Cuadrícula), cuadrícula hexagonal (Hexbin), mapa de calor (Mapa de calor) y clúster (Clúster). Los últimos dos tipos (Cluster y Heatmap) son convenientes cuando necesita agregar datos por un solo parámetro. La cuadrícula y la cuadrícula hexagonal permiten analizar valores agregados por varios parámetros simultáneamente.
Para responder a la pregunta planteada anteriormente, cambiaremos el tipo de capa de puntos que creamos previamente a “cuadrícula” (Cuadrícula), esto no solo evaluará el número total de espacios de estacionamiento por unidad de área, sino que también guardará información sobre el costo promedio de una hora de estacionamiento en este lugar.
Establezca el tamaño de la cuadrícula en 1 km2 (el mínimo disponible en Kepler.gl). El valor del parámetro Cobertura se reduce de 1 a 0.7 para que aparezca un pequeño espacio entre las celdas, lo que mejora la legibilidad del mapa final.
Nota La lista de opciones disponibles para la personalización varía según el tipo de capa seleccionado. Puede encontrar más detalles sobre los atributos admitidos por cada uno de ellos en la documentación oficial de Kepler.gl.
El color de cada celda en la nueva visualización, como antes, dependerá del costo de una hora de estacionamiento. Sin embargo, ahora, además del nombre del campo en el conjunto de datos utilizado, también debemos indicar cómo Kepler.gl agregará esta información. Los métodos de agregación dependen del tipo de campo seleccionado. En nuestro caso, "Precio" es un tipo numérico (int) y la aplicación ofrece una de 5 opciones:
- valor más alto (mínimo)
- valor más pequeño (máximo)
- cantidad (suma)
- valor promedio (promedio)
- mediana
La altura de cada una de las columnas de la cuadrícula reflejará el número total de espacios de estacionamiento en esta área. Para hacer esto, vaya al modo 3D de ver el mapa. Luego, en la pestaña "Capas" del panel lateral , seleccione "Habilitar altura" para nuestra capa de agregación y seleccione el campo "CarCapacity" como el parámetro base.
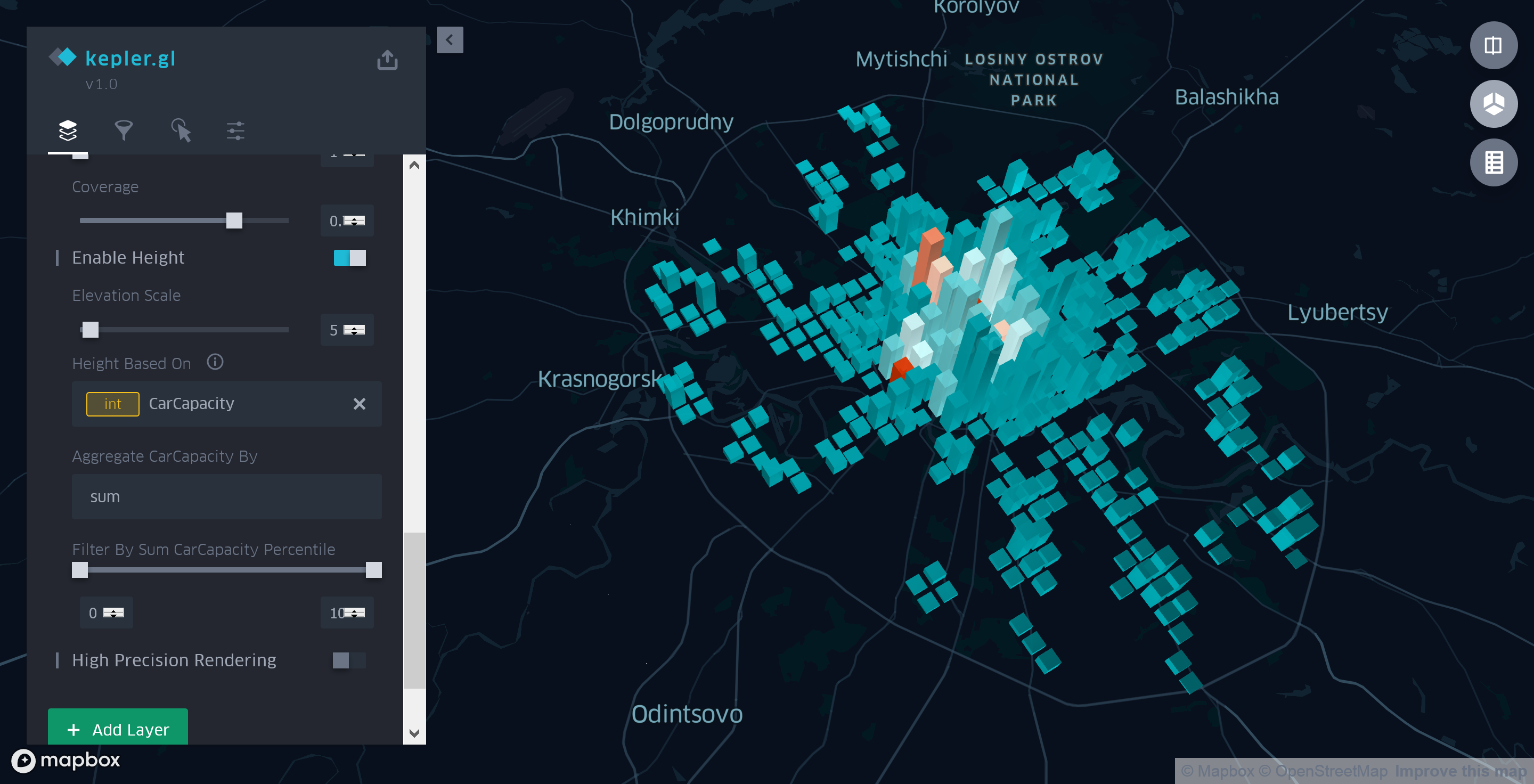
Figura 6. Información generalizada sobre el costo y la capacidad de estacionamiento.
Por lo tanto, después de pasar unos minutos más en la configuración de la capa de agregación, podemos decir con confianza que dentro del Anillo del Jardín no solo el número de estacionamientos, sino también el número real de espacios de estacionamiento es mucho mayor que el exterior.
Conclusión
En este artículo, utilizando un ejemplo específico, solo una parte de las capacidades de Kepler.gl se consideró como una herramienta moderna para la visualización y el análisis básico de diversos datos geográficos. Si está interesado en esta aplicación, le recomiendo que también se familiarice con los artículos y tutoriales a continuación, así como que experimente con el filtrado de datos usted mismo, configure información sobre herramientas y estilos de mapas, y otras características de esta aplicación.
Y en el próximo artículo, le contaré sobre las formas de compartir las visualizaciones y los mapas que creó, así como sobre el uso de Kepler.gl como un componente React para su aplicación web.
Enlaces utiles