Antes de responder la pregunta “¿Cómo medir el éxito?”, Debe comprender qué significa “éxito” para usted. Para Dev y Ops, la definición de éxito es diferente. Para Dev, un proyecto exitoso está completamente probado. Para operación - monitoreo. Las pruebas y el monitoreo son necesarios, pero las pruebas nunca brindan una cobertura del 100% del problema, y una respuesta 200 de HTTP no es suficiente para asegurarse de que el sistema funcione bien. Leon Fayer en RIT ++ defendió el punto de vista de que DevOps no paga para garantizar que todas las métricas en el monitoreo estén en la zona verde. Pagan para hacer felices a los usuarios . Si no está satisfecho, el negocio está perdiendo dinero y a nadie le importa que todo sea verde.
Debajo de un gato hay muchos ejemplos de la práctica que prueban este punto de vista. Veamos por qué entender el negocio, cómo monitorear el éxito desde un punto de vista comercial y por qué los desarrolladores comunes lo necesitan.

Sobre el orador: Leon Fayer nació en una república que alguna vez fue amigable, pero creció en los Estados Unidos. Comencé a programar hace muchos años, y durante ese tiempo trabajé como programador, gerente, a quien simplemente no trabajaba. Participó en nuevas empresas: algunas tuvieron más éxito y otras no.
Durante muchos años, Leon ha estado trabajando en OmniTI. Esta compañía se especializa en el desarrollo de sistemas escalables, por lo que Leon tiene una oportunidad única de diseñar y construir sistemas para los sitios más visitados del mundo: Wikipedia, National Geographic, Casa Blanca, MTV, etc.

Antes de responder la pregunta “¿Cómo medir el éxito?”, Debe comprender qué significa “éxito” para usted. Para cada persona, la respuesta será diferente.
Si está leyendo este artículo, lo más probable es que esté involucrado con DevOps. ¿Eres más Dev que Ops? O, por el contrario, ¿más operaciones que Dev? Para Dev y Ops, la definición de éxito es un poco diferente: para Dev, por supuesto, está probando.
Prueba
Para mí, como programador, las pruebas exitosas significan que todo está en orden, todo está bien, todo funciona, puede ejecutarlo en producción. El problema es que también soy cínico y no soy fanático de las pruebas como tal. No porque sea difícil y no porque sea largo, sino porque las pruebas no me dan lo que quiero.

Entiéndeme correctamente, la prueba es un proceso obligatorio , debe incluirse en cualquier proyecto, pero claramente no es suficiente para garantizar el éxito .
Hay muchas opciones de prueba diferentes:
- pruebas de rendimiento;
- pruebas de usuario;
- prueba automática ...

¿Cuántos métodos de prueba usa: 1, 2, 3, 5? ¿Y qué, no estás despierto por la noche alerta? ¿Funciona todo en producción?
El problema es que las pruebas dan la ilusión de éxito . Está predeterminado: sabemos que el tren debe abandonar el punto A y llegar al punto B, para esto estamos probando. Hay opciones que estamos considerando. Si el tren se cae del volante o se queda sin madera, esto no será una sorpresa. Pero no probamos, por ejemplo, el robo de trenes. No podemos probar esto porque no sabemos que tal opción sea posible.
Hay un par de problemas debido a que las pruebas simplemente no son suficientes. El primero, por supuesto, es un problema de datos . El hecho de que la tarea funcione localmente, pero por alguna razón no funciona en producción, es un problema estándar.
No importa cuánto lo intentemos. No importa cuántas réplicas hagamos en vivo: el desarrollo y la producción nunca serán iguales. Habrá otra fila en la base de datos, habrá otra solicitud adicional; siempre habrá algo en producción que no esperábamos.
Wolfe + 585 - el apellido más largo del mundo:
Hubert blaine
Wolfeschlegelsteinhausenbergerdorffwelchevoralternwaren-gewissenhaftschaferswessenschafewarenwohlgepflegeundsorgfaltigkeitbeschutzen-vorangreifendurchihrraubgierigfeindewelchevoralternzwolfhunderttausendjahres-vorandieerscheinenvonderersteerdemenschderraumschiffgenachtmittungsteinund- siebeniridiumelektrischmotorsgebrauchlichtalsseinursprungvonkraftgestartsein-langefahrthinzwischensternartigraumaufdersuchennachbarschaftdersternwelchege-habtbewohnbarplanetenkreisedrehensichundwohinderneuerassevonverstandig-menschlichkeitkonntefortpflanzenundsicherfreuenanlebenslanglichfreudeundruhe-mitnichteinfurchtvorangreifenvorandererintelligentgeschopfsvonhinzwischensternartigraum,
Sr.
Pocos sistemas sobrevivirán si alguien ingresa ese apellido en el formulario. Sé al menos 5 puntos diferentes donde todo el sistema puede volar.
Por lo tanto, el segundo problema es el problema con los usuarios .

Estas son personas tan interesantes que romperán cualquier cosa. Si no hubiera usuarios, todo sería mucho más fácil, para ser honesto.
Incluso si hay un botón en su interfaz de usuario, todavía encontrarán un método para romper lo que estamos haciendo.
El mejor ejemplo es World of Warcraft .

Para aquellos que no saben, este es un juego en línea jugado por 10 millones de personas. Hubo un tiempo en que hubo errores bastante legendarios. El error de sangre corrupto es un ejemplo perfecto de cómo los usuarios estropean todo.
Como con cualquier juguete, en World of Warcraft nuevos contenidos, nuevas ideas, nuevos jefes aparecían constantemente. Uno de los nuevos jefes maldijo a uno de los 40 jugadores del grupo. El principio de la maldición era como una bomba de tiempo: lentamente le quitó la vida a todos los que estaban a su alrededor. Es decir, era necesario huir hacia un lado: había toda una mecánica. Y todo estuvo bien hasta que, en algún momento, uno de los jugadores decidió teletransportarse a la ciudad durante la batalla ...

En la ciudad había miles de personas de todos los niveles, los más pequeños también. No solo eso, todavía había personajes no jugadores que también se infectaron con una maldición. Durante el día, los servidores estaban vacíos. Era imposible ir a cualquier parte, donde había otros jugadores. Se convirtió en una plaga de juegos en el verdadero sentido de la palabra. Tuve que reiniciar todos los servidores para eliminar la maldición y cambiar la mecánica. Y todo por un probador: ni siquiera sé cómo llamarlo.
El tercer problema principal es el problema con la dependencia externa . Todos nos encontramos con esto: la API de la que depende de repente deja de funcionar; o dejas de controlar la API.
Pero hay un problema mayor con esto. La dependencia externa puede ser no solo directa, sino también indirecta. Todos usamos OpenSource ahora. Cada producto OpenSource depende de algunas bibliotecas, que también son OpenSource y que son compatibles con otra persona. Cuando algo se rompe, se rompe no solo en este pequeño módulo, sino en todo lo que depende de él.
Probablemente el ejemplo más ideal fue recientemente, hace aproximadamente un año, este es el panel izquierdo . Este es un módulo npm en node.js que expone espacios antes de la cadena (al comienzo de una línea). No discutiremos por qué se hizo este módulo. Pero resulta que se incluyó en muchos módulos populares. En algún momento, el autor decidió que tenía suficiente, eliminó este módulo de npm y voló el 70% del código escrito en node.js.
Si cree que este es un caso aislado, está equivocado.
También está el módulo is-impar, que ahora está en npm. Este módulo define un número par o no.
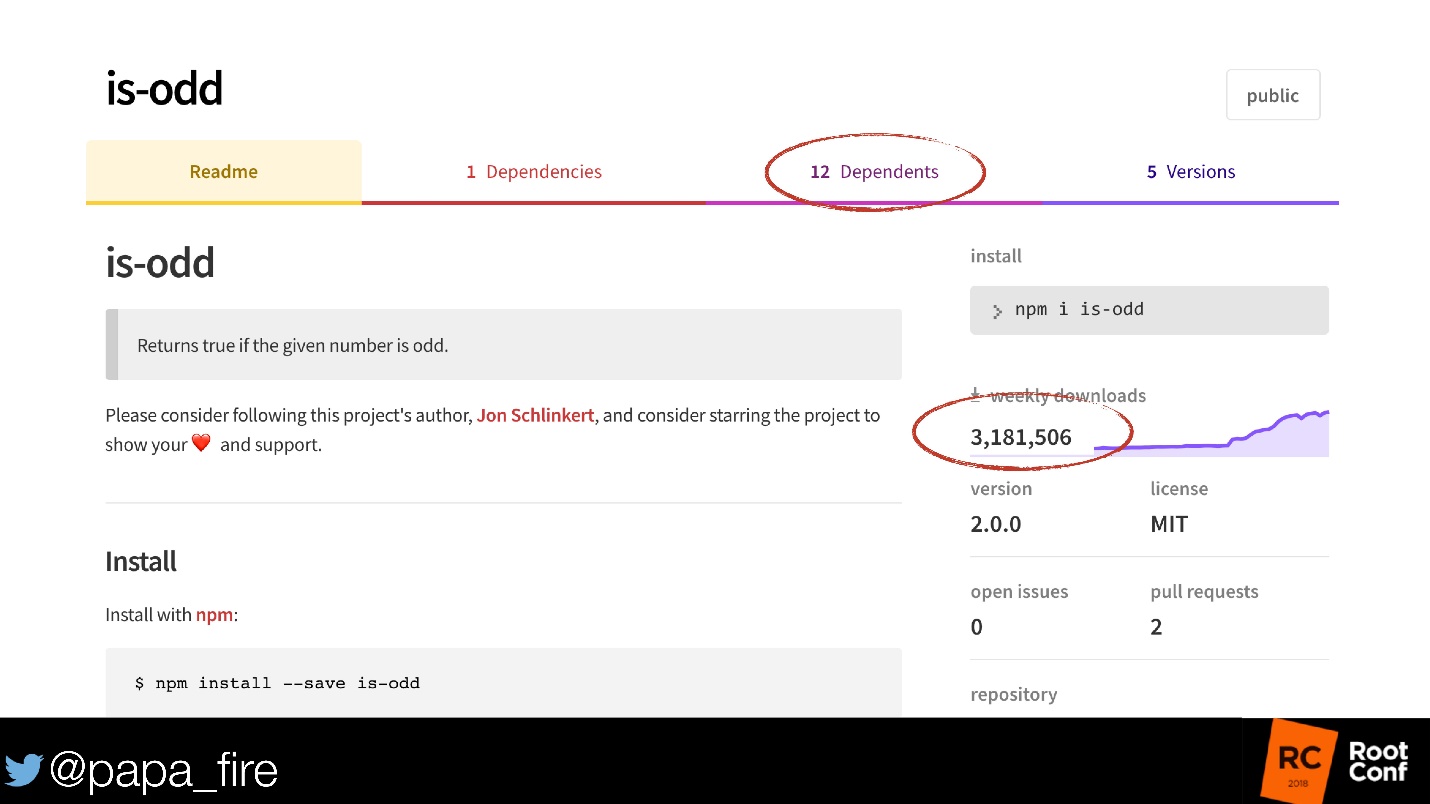
No discutiremos el hecho de que 3 millones de personas no saben cómo verificar la paridad / rareza. ¡Pero hay 12 módulos más que lo usan! Y no se sabe cuántos de estos módulos todavía están usando los módulos. Si te parece que no hay nada que romper, ¡hay 5 versiones!
Volviendo a nuestras ovejas, hay muchas más opciones:
- Miopía : no sabemos qué sucederá en el futuro. Y2K es un ejemplo perfecto. Nadie pensó que en 2000 todo lo escrito en Kobol volaría.
- Número de opciones de prueba .
Hay un buen ejemplo de nuevo con World of Warcraft: tienen muchos buenos ejemplos sobre este tema.
Seis meses después del lanzamiento del juego, comenzaron a llegar llamamientos en apoyo de que algunos jugadores no podían entrar en una cueva. Resultó que solo una versión de raza y género no podía entrar en esta cueva: estos eran tauren femeninos.
¿Por qué tardó 6 meses en encontrar este error, después de todo, millones de personas están jugando? Porque tauren es una raza ficticia, una mezcla de hombre y toro. La mujer Tauren es una vaca parlante. Nadie quería jugar una vaca, por lo que durante 6 meses ni una sola persona alcanzó el nivel máximo para entrar en la cueva y encontrar este error. En consecuencia, nadie lo probó.
- Cambio en la fuente de datos. Realmente no sabemos qué pasará mañana.
En cualquier caso, hay pocas pruebas. Pero las pruebas no dan una cobertura del 100%. Por lo tanto, las pruebas no garantizan el éxito. Esto nos lleva gradualmente a la segunda parte: operaciones. Para la explotación, el éxito es el monitoreo .
Monitoreo
Hay muchas razones por las cuales se necesita monitoreo:
- el código perfecto no existe;
- los sistemas se están volviendo más complejos;
- creciente dependencia externa;
- anticipación -> respuesta;
- ...
Se necesita monitoreo porque todo está cambiando. Esta es la razón principal. Además, está en producción, todo cambia constantemente allí, y necesitamos detectar esto.
¿Qué debería cubrir el monitoreo? - Eso es! Esta es una respuesta corta, pero debería cubrir todo.

Todo esto es un poco abstracto. De hecho, todos tenemos una lista de verificación que monitoreamos:
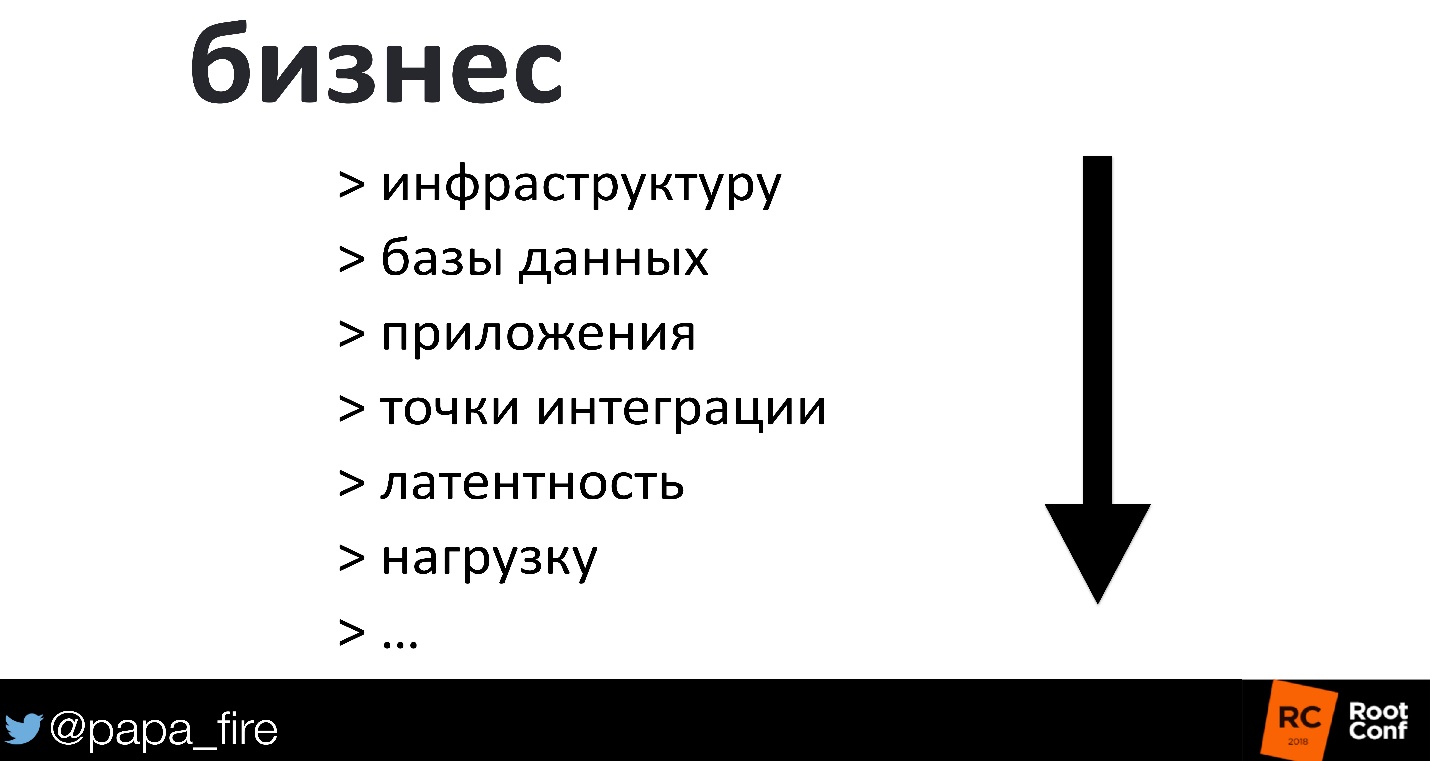
- infraestructura
- Bases de datos
- Aplicaciones
- puntos de integración;
- solicitar tiempo de procesamiento;
- carga
- ...
Puede haber un millón de cosas. Muchos recopilan cientos, miles y decenas de miles de métricas en sus sistemas.
Recopilaremos muchas métricas para esto:
Por supuesto, estoy exagerando, pero todo lo que necesitamos desde el punto de vista de Ops es que HTTP devuelva 200 . Esto significa que todo está bien con el sitio. Una vez que un sitio funciona, significa que las bases de datos funcionan, las aplicaciones funcionan, todo está en orden. Desde el punto de vista de Ops, el éxito es exactamente eso: todos los gráficos están en la zona verde, todo funciona correctamente, ¡todo está bien!

Todos saben lo que es Twitter. Procesan 500 millones de tweets por día, un número loco.

Pero también son conocidos por sus errores. Los errores son legendarios en su complejidad o facilidad: a qué lado mirar.
Se equivocaron: el sitio funcionaba, el cliente podía escribir un tweet, hacer clic en un botón, dijeron gracias, el tweet fue enviado, ¡y eso es todo! No apareció en ningún lado y simplemente desapareció, y el monitoreo mostró que todo estaba en orden. El sitio devuelve una solicitud 200: la API funciona. ¡Pero no hay tweets!
Tengo una cita favorita de un cliente. Reparé problemas en tres pantallas durante una hora, y él gritó por qué nada funciona. Cuando traté de explicar qué problemas estaba solucionando, una persona que escribió con dos dedos y no entendía cómo usar una computadora me dijo:
"Mientras siga ganando dinero, es una mierda para mí que los servidores estén encendidos".
De alguna manera, esto es muy correcto, y el ejemplo de Twitter lo confirma: todas las métricas mostraron que todo estaba en orden desde el punto de vista de los desarrolladores, pero desde el punto de vista del trabajo del negocio, no estaba en absoluto en orden.
Para ser sincero, todos tenemos la culpa. Por supuesto, las compañías que producen productos de monitoreo son las principales culpables. Pero nosotros también, porque tradicionalmente recopilamos métricas del sistema. Estamos acostumbrados a trabajar con sistemas pequeños, uno, quizás dos servidores. Si funcionan, entonces todo está en orden.
Ahora tenemos un poco más de servidores que dos, o incluso 10, y solo medir la salud del sistema o la salud del programa no es suficiente. Debemos rastrear el trabajo de otra cosa.
Volviendo a la cotización, no me pagan por que todo sea verde. Me pagan para que mis usuarios o mis gerentes estén satisfechos; alguien debería estar contento con el resultado . Si todos los usuarios están descontentos, a nadie le importa que todo sea verde.
Monitoreo de negocios
Dijimos que se necesita monitoreo porque todo está cambiando. Pero cuando todo cambia, los cambios afectan al negocio: algo se ha roto, el dinero ha dejado de llegar, algo ha sido reparado, el dinero ha comenzado a fluir nuevamente, una correlación directa. O no influyen en ello, pero si no controlamos el negocio, no lo sabemos.
Como ejemplo vivo, el gráfico de lectura de caché es familiar para todos.
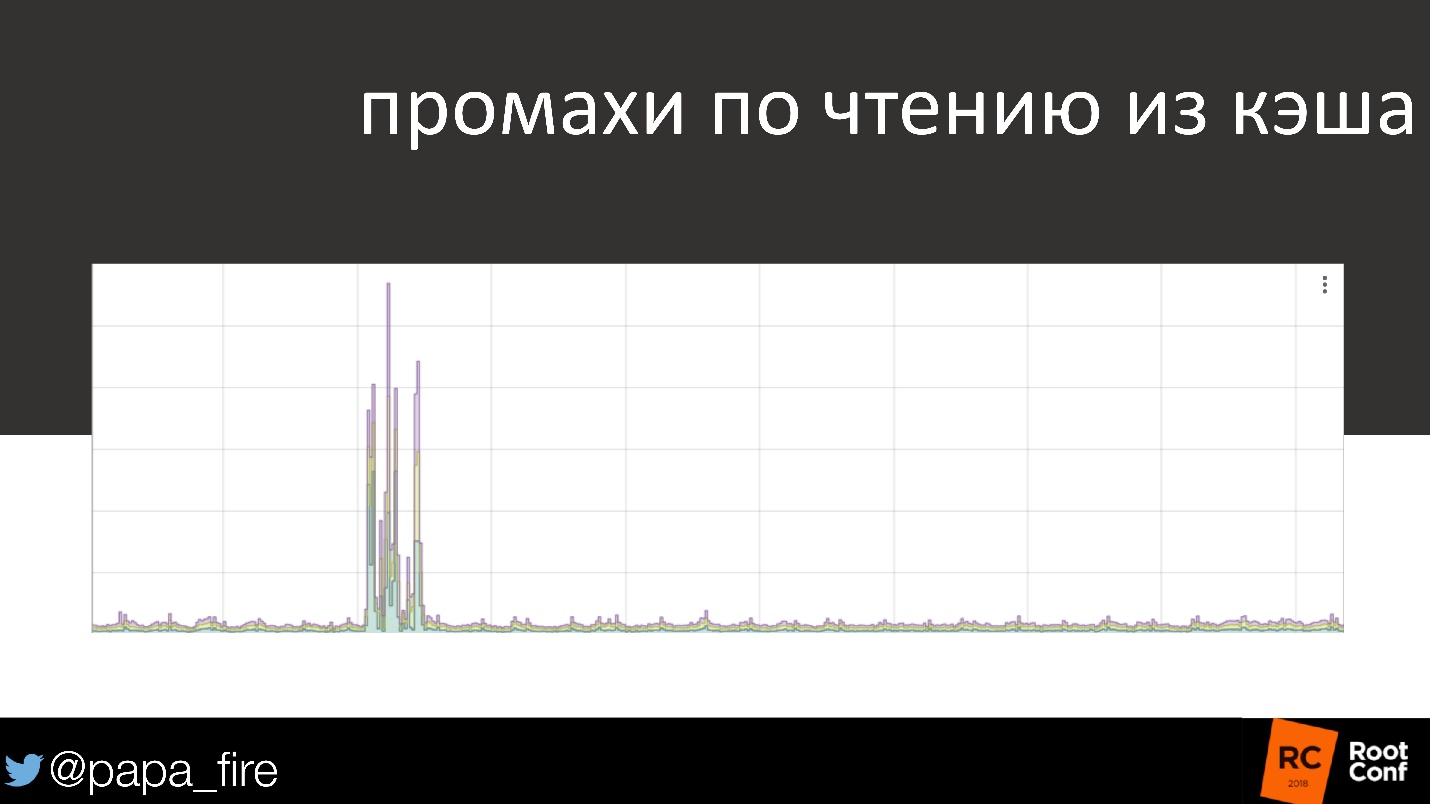
El 90% del tiempo, todo está en orden, casi todas las solicitudes van al caché. Y de repente algo sucedió, y muy serio. Este es un problema que debería despertarse a las 3 de la mañana, alguien que lo resolverá. Pero, si la velocidad de descarga para los usuarios no cambia, ¿es realmente un problema?
En inglés existe el término Observabilidad - observabilidad. Estos son: monitoreo, registro, alertas. Por lo tanto, el término monitoreo es un poco. Queremos observar todo: recopilar métricas del sistema en cada nodo, si es necesario. Pero queremos monitorear el negocio, porque emociona a todos. Este es un indicador de éxito.
Para hacer esto, debemos:
1. Comprenda el problema: qué es exactamente lo que necesitamos monitorear.
2. Determine la línea de base, es decir, ¿es suficiente que la velocidad de descarga del usuario no haya cambiado para que nadie se despierte en medio de la noche cuando la lectura del caché ha dejado de funcionar?
3. La correlación de datos es uno de los factores más importantes. Si el marketing recopila datos sobre ingresos, y usted recopila datos en servidores y no puede comparar estas dos observaciones, entonces tienen muy poco significado.
Usualmente doy muchos ejemplos. No importa cuán absurdos se vean, todos son de mi vida, y les dediqué muchos nervios.
Ejemplo: tuve un cliente con 100 millones de usuarios. Fue una empresa de marketing en Internet que envió muchos correos electrónicos y utilizó pruebas A / B. Para ellos, recolectamos 6 mil métricas.
Todo, como siempre, comenzó con una llamada. Suena el teléfono, significa que sucedió algo.
" Tenemos un problema". Algo no funciona.
- Bien, ¿qué no funciona exactamente? ¿En qué se expresa esto?
- Comenzamos a recibir menos ingresos.
- y?
- Algo no funciona en el sistema.
- No lo entiendo. Si tiene menos ingresos, hable con su equipo de ventas. ¿Por qué me llamas?
- No, estoy seguro de que algo en el sistema no funciona.
- Muy bien, veamos.
Gracias a Dios teníamos una métrica de ingresos, por lo que pudimos ver. El gráfico realmente muestra que en algún momento sus ingresos cayeron un 15%. Dado el número de usuarios, esto es bastante significativo.
Vale, tengo que mirar. En primer lugar, compruebo la velocidad de descarga: normal.
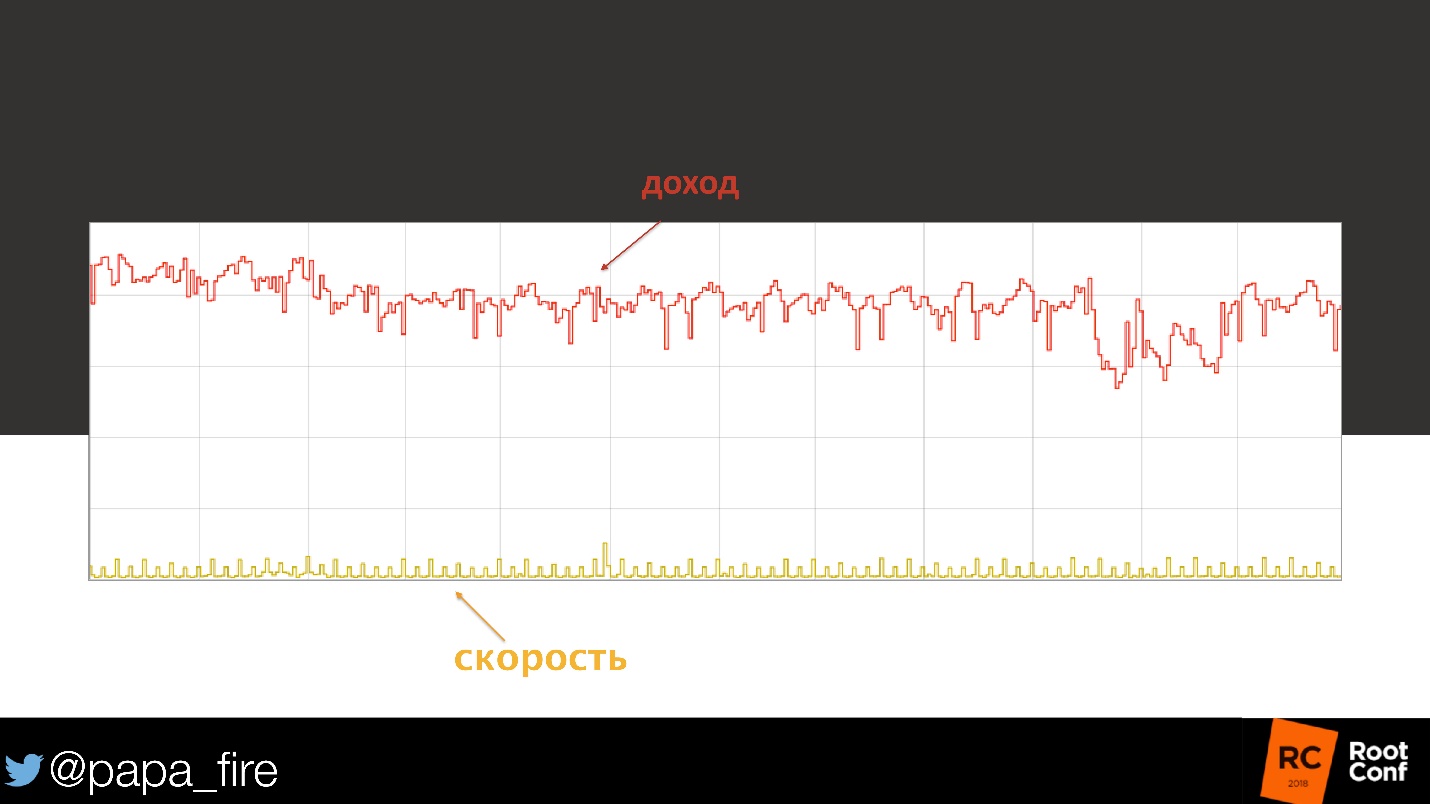
Observamos la carga en la base de datos: todo está dentro de límites razonables, parece que nada ha cambiado. Luego comenzamos a mirar la carga de la CPU, los nodos individuales, los cachés.
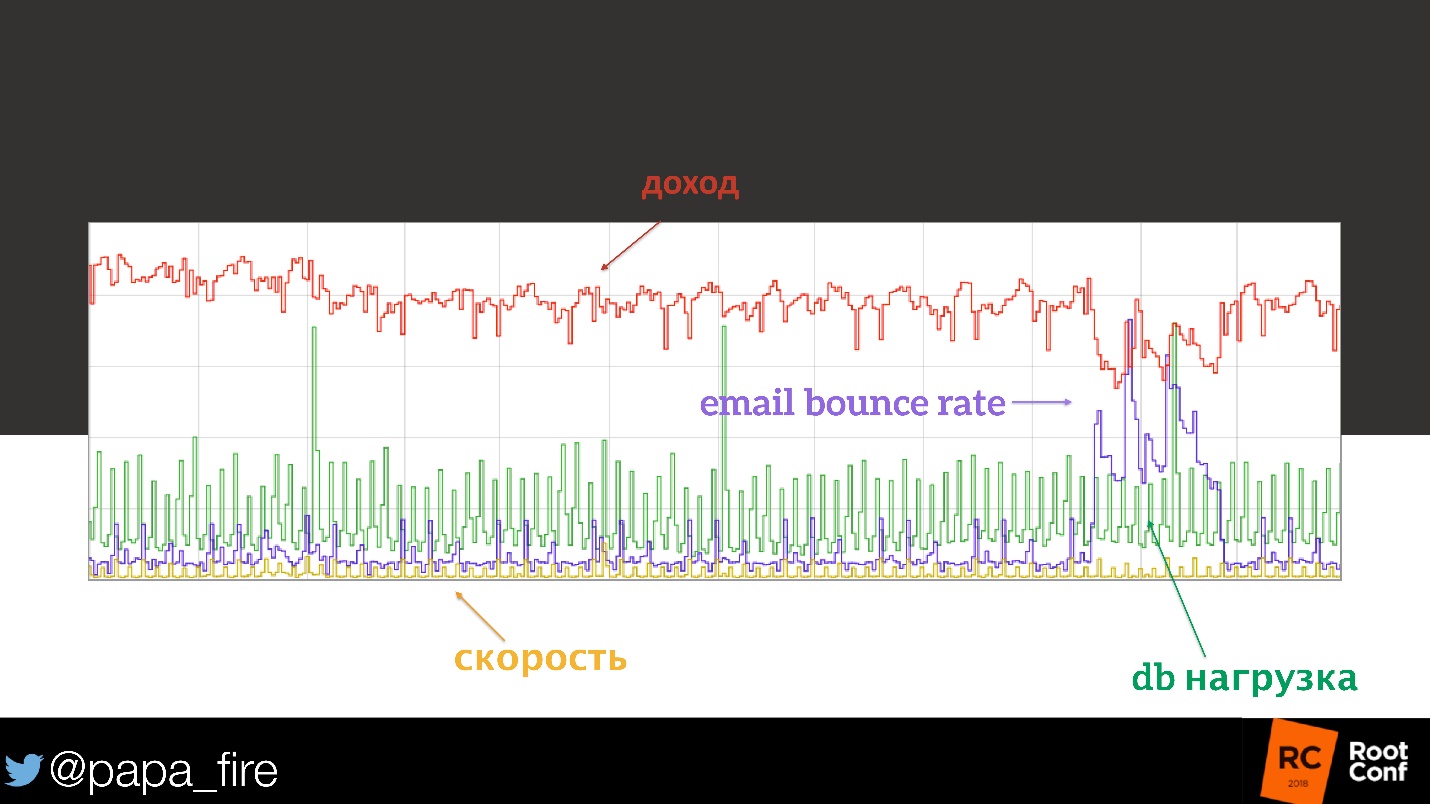
Todo estaba en orden. Hasta que llegamos a las métricas del boletín electrónico. Uno de los grandes proveedores puso accidentalmente su dominio en la lista negra. El porcentaje de su marketing por correo electrónico ha dejado de llegar a los usuarios, lo que significa que menos personas: recibieron cartas, hicieron clic en el botón, fueron al sitio y compraron algo.
¡Aquí hay tal correlación!
Somos afortunados de tener estas métricas. Si no los tuviéramos, los agregaríamos; esta es una respuesta muy simple.
El error más grande que comete la gente es creer que el monitoreo se puede poner al final del proyecto. Es como una característica: hacer su propio proyecto, poner en marcha el monitoreo, y eso es todo, ¡estamos listos!
La instrumentación nunca puede ser terminada. Siempre hay problemas que se desconocen desde el principio. Al igual que con las pruebas, no puede escribir pruebas y cubrir todo, porque no sabe qué es "todo". No sabemos cómo predecir el futuro y no sabemos cómo predecir un negocio, por lo que no sabemos qué es "todo".
Un ejemplo absolutamente idéntico a lo que estoy hablando. Fue el CEO, que se despertó en una conferencia en París por la mañana, bebió café, miró su correo y su estado de resultados, y me llamó con el mismo problema: los ingresos cayeron.
Lo recuerdo bien, porque tenía 9 de la mañana y yo tenía 6 horas antes, también el sábado. Acabo de ser transportado a casa desde una fiesta de cumpleaños, pero eso no importa. Entonces, a las 3 de la mañana, me siento en la computadora y comenzamos a seguir los mismos pasos. Es decir, observamos la carga en el sistema, el número de registro, en absoluto.
La única desviación de la norma que encontramos es un porcentaje menor de autorizaciones exitosas. Es decir, la cantidad es la misma, pero el porcentaje es ligeramente menor. Sé que esto podría ser spam, etc. Pero todas las demás métricas técnicas son absolutamente normales. Y llegamos al punto en el que casi estábamos caminando a lo largo de las líneas en la base de datos y tratando de verificar si había algo que pudiera ser atrapado por el ojo. Absolutamente nada!
Nos sentamos medio domingo, continuamos el lunes también, pero ya estábamos seguros de que el problema no era técnico. Déjelos decidirlo ellos mismos. Y aquí el lunes me siento en el trabajo y un empleado de su departamento de contabilidad me llama:
- Escucha, ¿puedes ayudarme rápido?
- ¿Qué necesitas?
- ¿Puedes quitar la insignia de American Express del sitio?
- Por supuesto que puedo! ¿Por qué de repente?
- Sabes, discutimos con ellos aquí, y hasta que aceptemos a los estadounidenses.
Expresar en general.
"Pido disculpas por preguntar, ¿cuándo dejaste de tomarlos?"
- Antes del fin de semana, en mi opinión, el viernes o el sábado .
¡Nadie en su sano juicio jamás pondría una colección métrica en el porcentaje de autorizaciones de un determinado tipo de tarjeta de crédito! Después de este incidente, por supuesto, nos pusimos en marcha.
¿Por qué te estoy diciendo esto? Primero debe mirar el negocio, porque todos estos problemas sistémicos eran simplemente invisibles. No despertaron a nadie en medio de la noche, no vimos que estos fueran problemas. Es fácil notar una caída en los ingresos, y todo lo demás debe ser rastreado para que pueda correlacionar estos datos con los datos comerciales.
Éxito para los negocios
Para una empresa, el éxito puede ser diferente; depende de los objetivos. Lo más importante, ¿cómo se puede medir esto? Tradicionalmente, medimos el rendimiento del sistema, a veces como ingenieros, olvidando que puede medir cualquier cosa.
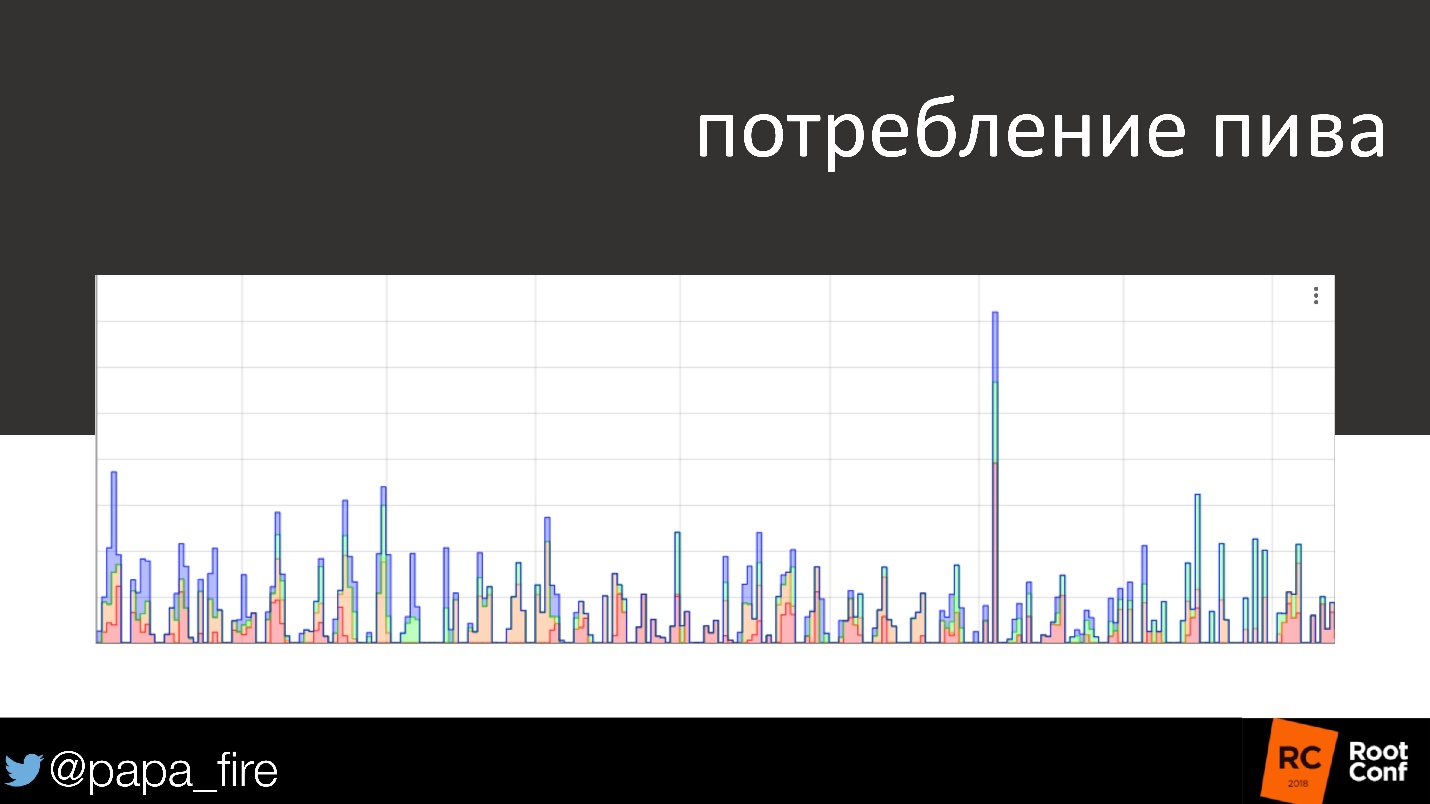
Por ejemplo, puedes medir tu propio alcoholismo. Por cierto, no estoy bromeando. En nuestra oficina hay una cerveza de barril con cuatro grifos. Como todos somos ingenieros, mi colega decidió ponerse los sensores Raspberry Pi para ver cuánta cerveza bebemos y cuál.

Parece una broma simple, pero en realidad es conveniente, porque vemos cuando la cerveza llega a su fin y necesitamos reemplazar el barril. En general, podemos ver cuándo las personas beben, qué cerveza les gusta más: oscura, clara, etc. Por cierto, el pico es mi cumpleaños.
Absolutamente por casualidad, encontramos otra aplicación para esto.
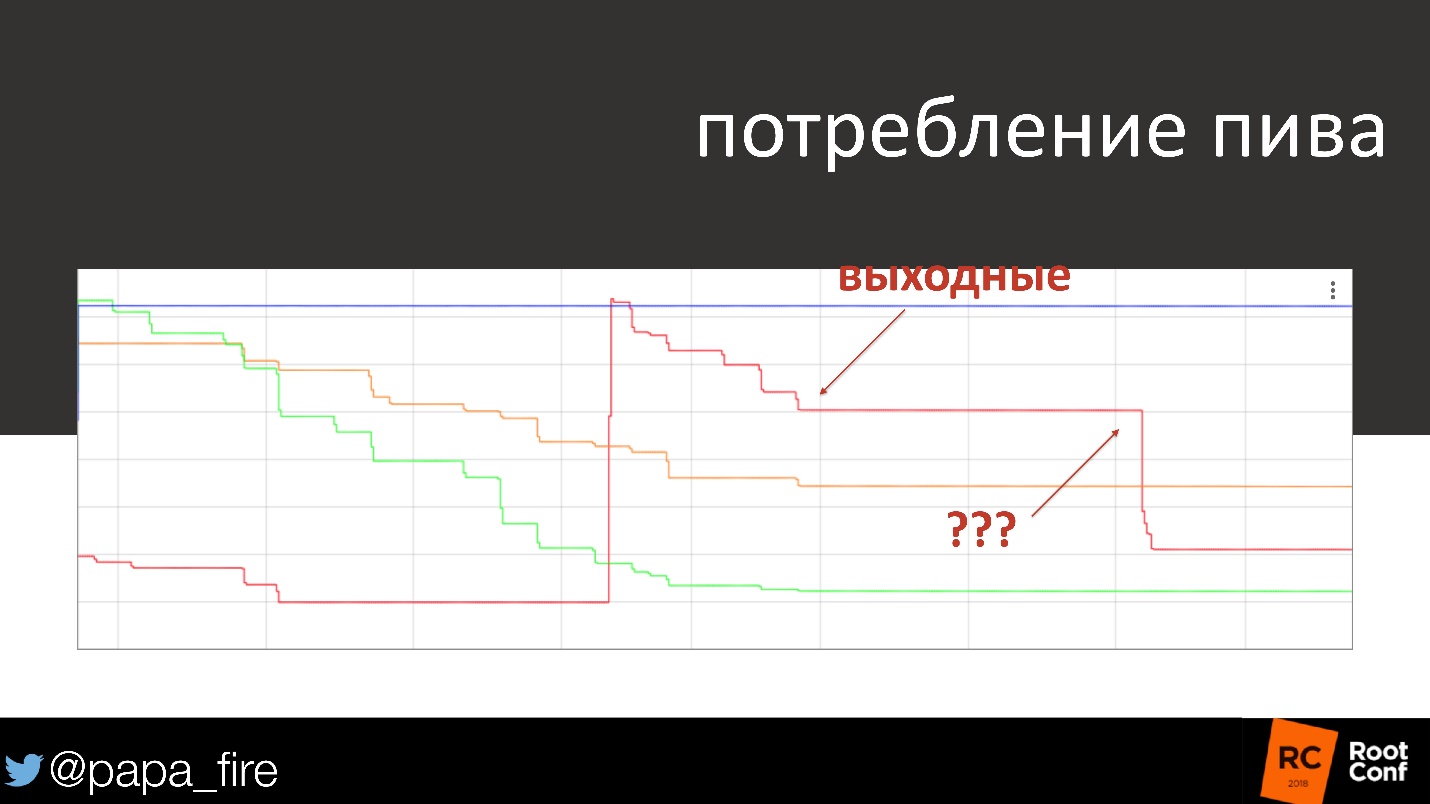
El gráfico muestra el consumo de cerveza durante varios días y fines de semana. Para el fin de semana, el consumo de alcohol generalmente disminuye, casi desaparece. Un día llegamos el lunes, miramos el horario y vemos que alguien el sábado bebió un cuarto de barril de cerveza. El gráfico muestra el tiempo exacto dentro de media hora. Resultó que los limpiadores que vinieron el sábado tenían resaca, por lo que tenían resaca.
Una broma, pero al final tuvieron serios problemas, porque generalmente es malo beber en el trabajo, ¡e incluso la cerveza de otra persona!
Al final, cualquier métrica puede ser útil. Incluso esta métrica, que recopilamos exclusivamente para nuestro propio fanático, resultó ser importante en otra cosa. Pero básicamente, las métricas realmente necesarias se reducen al dinero. El dinero es lo más importante para los negocios.
Por lo general, el criterio para el éxito de un negocio es algo que finalmente involucra dinero:
- ganancia
- ingreso
- costos
- efectividad.
Métricas comerciales:
- Registro
- compras;
- vistas de anuncios
- conversiones
- porcentaje de retorno;
- cantidad de cerveza borracha
Todo esto tiene un equivalente monetario. , , — , . , .
. . , , .
, — . , — , — , . , — 99- , SLA .
, , -.
, . , , , . , .
. , . . . , 3 , .
— . , , , , .
.
: , , , - .
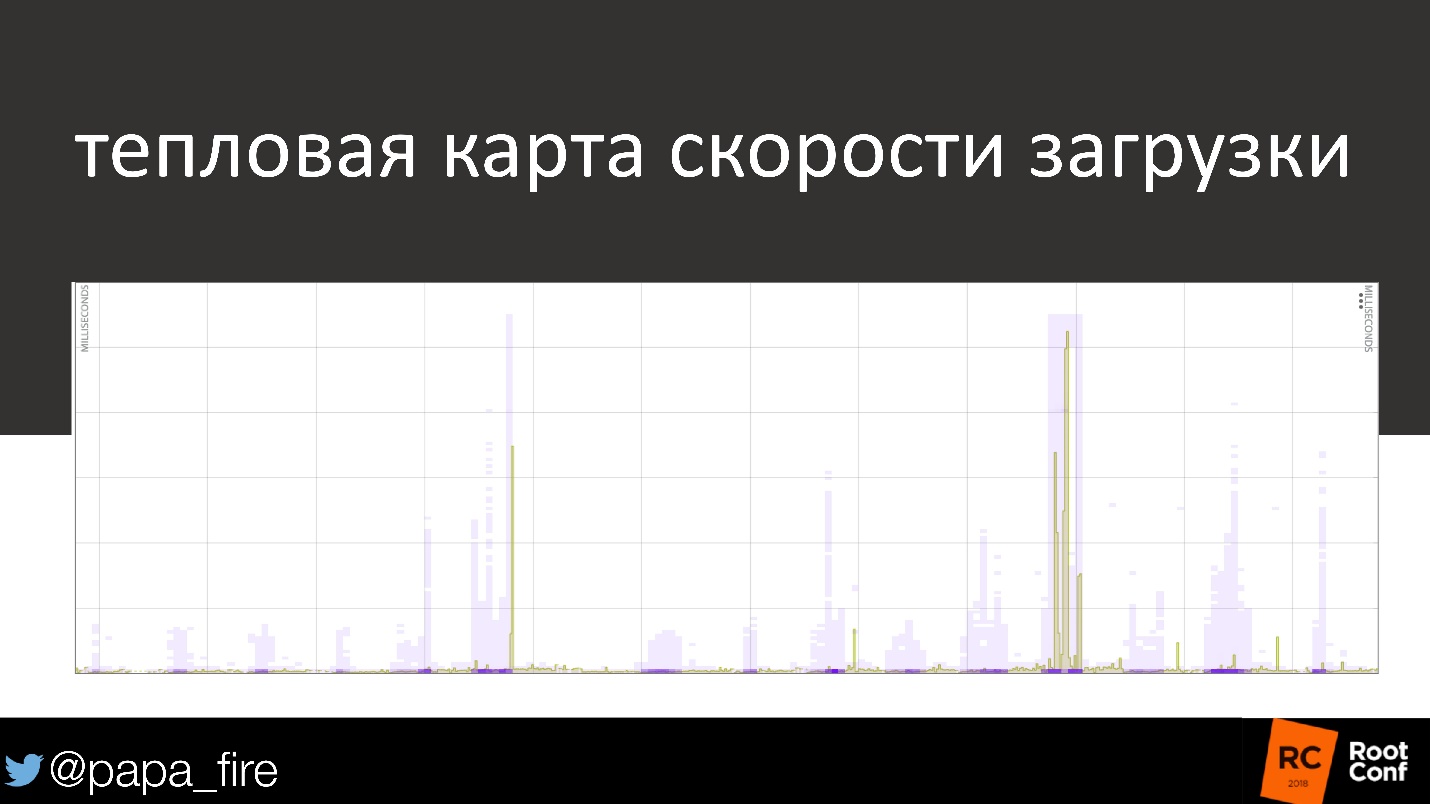
, . , , , 50 % « », , .
1 ?
1-2 . . 10 000 , . , 10 000 , - .
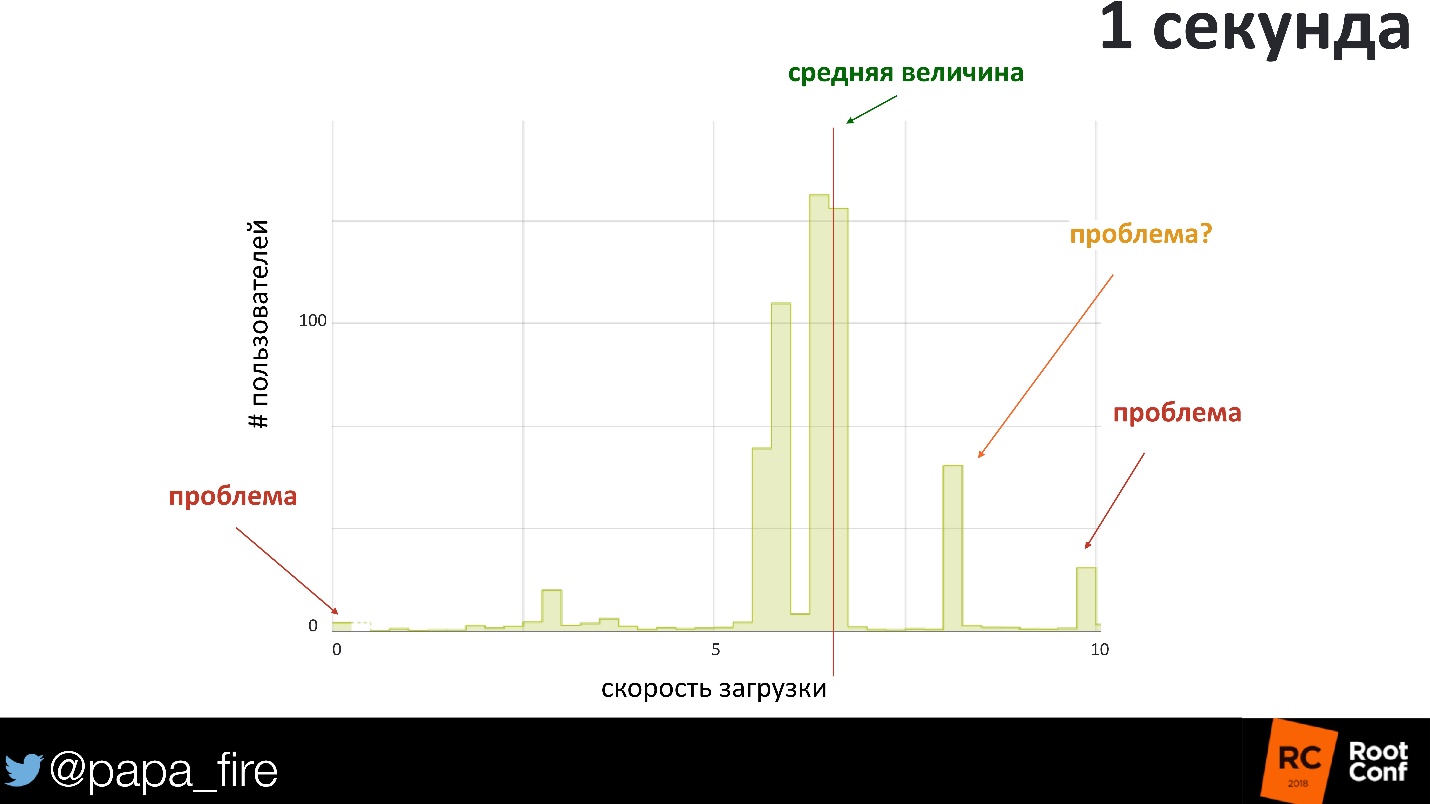
1 . 600-700 . , 600 — , . , , . 800 , , — .
, , . 0 , - , ! .
, - . — , .
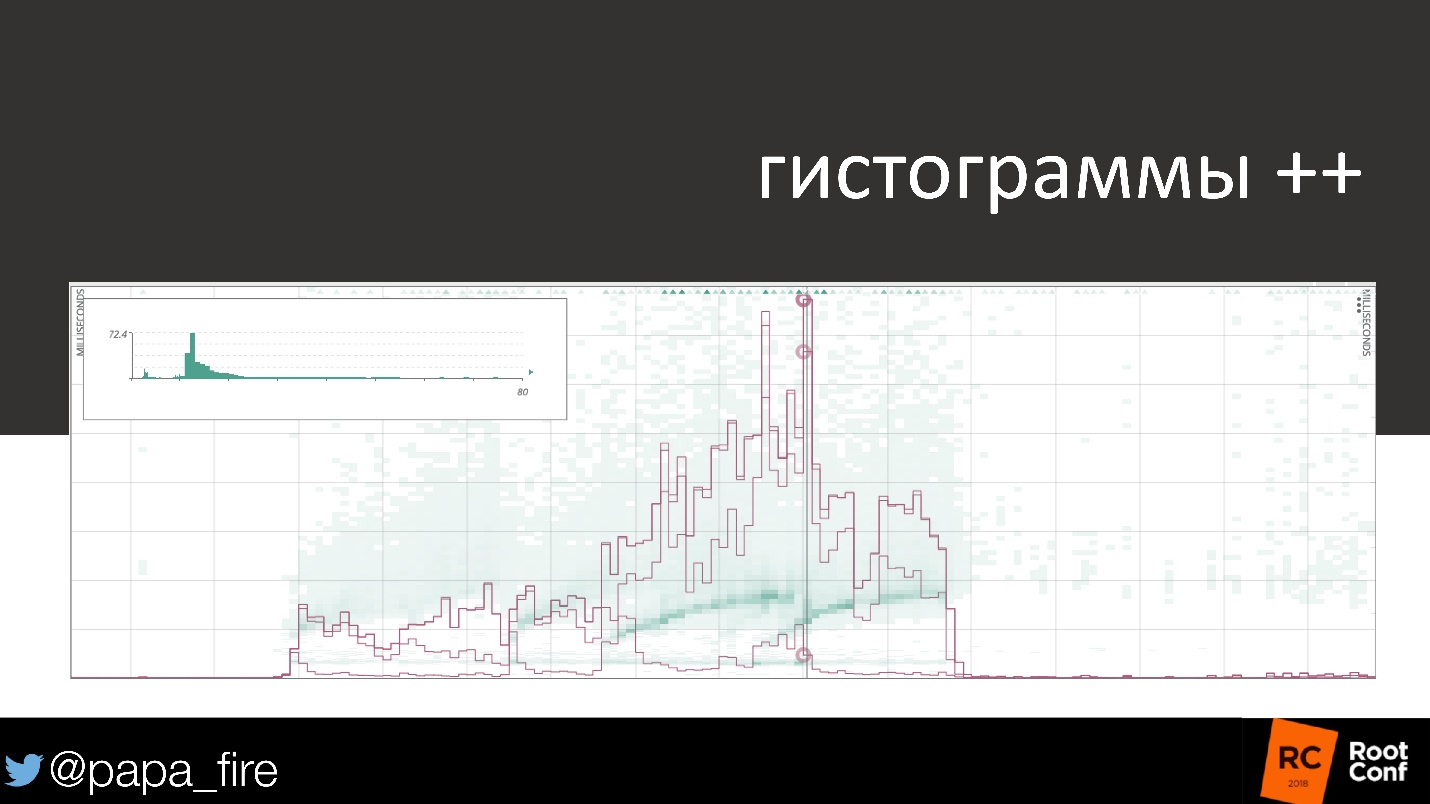
99- 50- , . , .
, — , DevOps — .
, , .
Value stream mapping — . , . , , , , , . , , .
:
- MTTD (mean time to discovery) — , .
- MTTR (mean time to recovery) — , .
- , .
- / .
, , , , . : « — . , , ».
, , . , .
. , — , , . , . .
— , , . , , , . — .
1 2 , DevOpsConf Russia .
DevOps, , , . , , .
, , .