El tema de hoy, la confiabilidad del servidor de World of Tanks, es bastante resbaladizo. La confiabilidad del juego es una solución de compromiso, por lo tanto, todo debe hacerse de manera rápida y rápida en el desarrollo del juego. La carga en los servidores es grande, y los usuarios tienden a romper algo simplemente por interés. Levon Avakyan en RIT ++ dijo lo que Wargaming está haciendo para garantizar la confiabilidad.
Por lo general, cuando se habla de confiabilidad, el monitoreo, las pruebas de estrés, etc. se mencionan todo el tiempo. No hay nada sobrenatural en esto, y el informe se dedicó a momentos específicos de los tanques.

Sobre el orador: Levon Avakyan trabaja para Wargaming como Jefe de Servicios de Juego y Confiabilidad de WoT y se ocupa de los problemas de confiabilidad del servidor de tanque.
Hoy hablaré sobre cómo hacemos esto, incluido de qué se trata el servidor de World Of Tanks, en qué consiste, en qué se basa, para que entienda el tema de la conversación. Además, consideraremos qué puede salir mal dentro del servidor y a su alrededor, porque el juego ya es más que el servidor. Y también hablaremos un poco sobre los procesos, porque muchos olvidan que un proceso bien establecido en la producción es parte del éxito no solo en términos de ahorro de recursos (muchas prácticas provienen de la producción real), sino que afecta la calidad y la confiabilidad de la solución.

Por lo general, cuando se habla de confiabilidad, el monitoreo, las pruebas de estrés, etc., se mencionan todo el tiempo. No lo incluí aquí porque creo que es aburrido. No hemos descubierto nada sobrenatural en esto. Sí, también tenemos un sistema de monitoreo, hacemos pruebas de estrés con pruebas de estrés para aumentar la confiabilidad del sistema y saber dónde puede caerse. Pero hoy hablaré sobre lo que es más específico para los tanques.
BigWorld Technology
Este es un motor de back-end, así como un kit de herramientas para crear MMO.
Este motor bastante antiguo de BigWorld Server (creado a finales de los 90 y principios de los 2000) es un conjunto de procesos diferentes que admiten el juego. Los procesos se inician en un clúster, interconectados en una red de máquinas. Al interactuar entre sí, los procesos muestran al usuario algún tipo de mecánica de juego.
El motor se llama BigWorld, porque es muy bueno hacer juegos en él, en el que hay un gran campo (espacio), en el que tienen lugar operaciones militares (batallas). Para los tanques, esto encaja perfectamente.
En términos de confiabilidad, las siguientes características clave se invirtieron en BigWorld:
- Equilibrio de carga. El motor asigna recursos, tratando de lograr dos objetivos:
- use la menor cantidad de máquinas posible;
- al mismo tiempo, no cargue sus aplicaciones para que su carga exceda un cierto límite.
- Escalabilidad. Agregamos el auto al clúster, iniciamos procesos en él, lo que significa que puedes contar más batallas y aceptar jugadores.
- Alta disponibilidad Si, por ejemplo, un automóvil se cayó o algo salió mal con uno de los procesos del juego que sirve al juego en sí, no hay nada de qué preocuparse: el juego no se dará cuenta, se restaurará en otro lugar y funcionará.
- Mantener la integridad y la coherencia de los datos. Este es el segundo nivel de tolerancia a fallas. Si hay varios grupos, como en Tanques, y hubo algún tipo de desastre en el centro de datos o en el canal principal, esto no significa que perderemos por completo los datos del juego que la persona ha jugado. Nos recuperaremos, la consistencia será.
Los procesos que están en nuestro sistema y sus funciones.- CellApp es el proceso responsable de procesar el espacio del juego o parte de él.
Como dije, BigWorld trabaja con ciertos espacios que dividimos en celdas. Cada celda específica de nuestro espacio de juego se calcula mediante una aplicación específica.
- CellAppMgr : el proceso que coordina el trabajo de CellApp, el equilibrio de carga.
CellApp puede ser muchos, por lo tanto, debe haber un proceso que los controle.
- BaseApp gestiona entidades, aísla a los clientes de trabajar con CellApp.
Una de las cosas fundamentales en BigWorld es el concepto de entidad, por ejemplo, la cuenta de un jugador. Todo lo que hacemos en el campo de batalla, lo hacemos con esta entidad. CellApps calcula la física y la mecánica del juego, como disparar. BaseApp funciona con entidades. Sirve la cuenta, tanque, etc.
- ServiceApp es una BaseApp especializada que implementa algún tipo de servicio.
Esta es una versión simplificada de BaseApp, un proceso que realiza varias tareas de servicio. Por ejemplo, alguien debería poder leer desde RabbitMQ. No se trata de entidades de juego, sino que también es necesario.
- BaseAppMgr administra BaseApp y ServiceApp, porque también hay muchos de ellos.
- LoginApp crea nuevas conexiones de clientes, y también representa a los usuarios en BaseApp.
- DBApp implementa una interfaz de acceso al almacenamiento (bases de datos). Trabajamos con Percona, pero puede ser otra base de datos.
- DBAppMgr coordina el trabajo de DBApp.
- InterClusterMgr gestiona la comunicación entre clústeres .
- El revisor es un inspector de procesos que puede reiniciar los procesos.
- Bwmachined - un demonio que se ejecuta en cada máquina del clúster para coordinar su trabajo. Permite que todos los administradores de BaseApp se comuniquen entre sí.
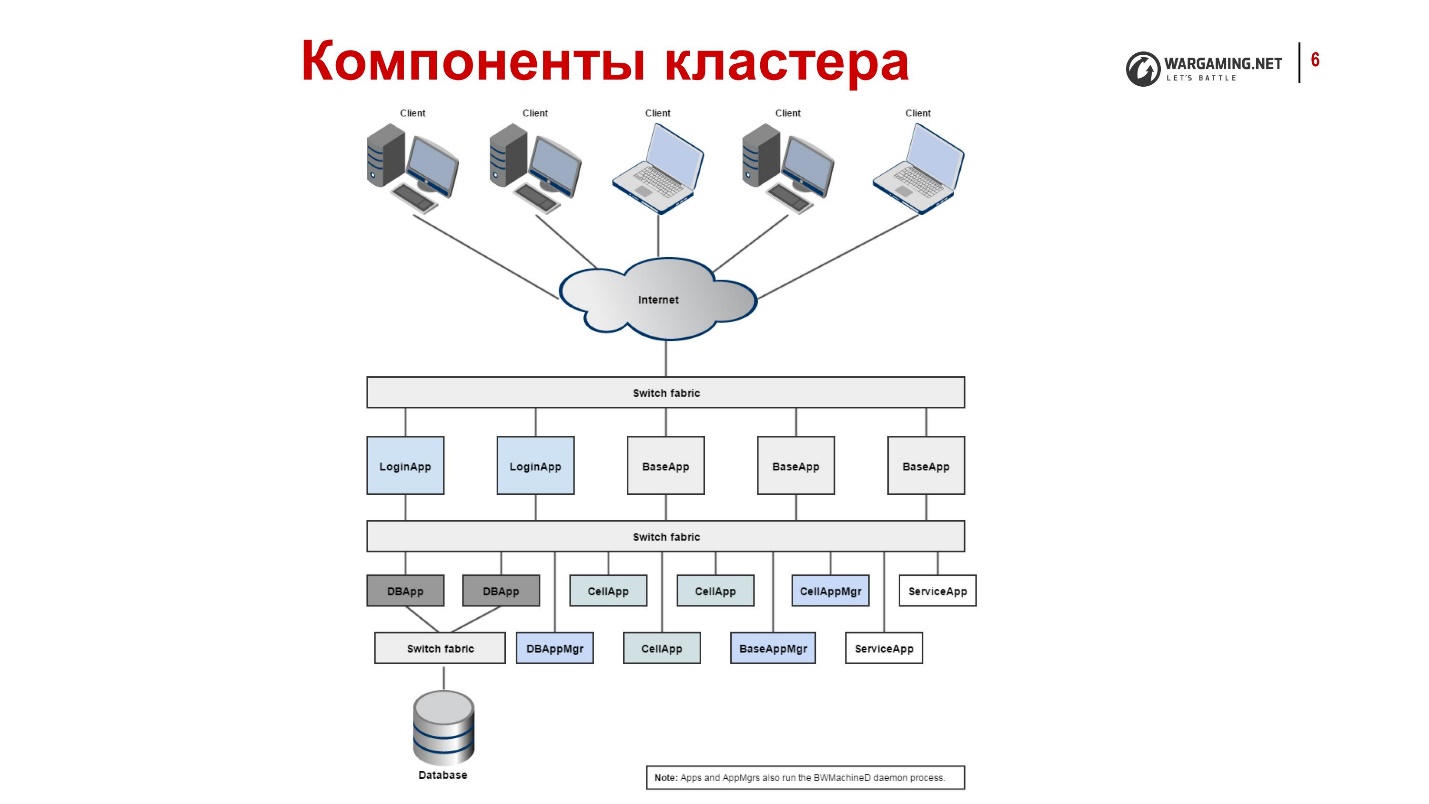
Así es como se ven los tanques desde adentro, aunque sea muy brevemente:
- Los clientes se conectan a través de Internet, acceden a LoginApp.
- LoginApp los autoriza utilizando DBApp y emite una dirección de BaseApp.
- Otros clientes juegan con ellos.
Todo esto está disperso en muchas máquinas, cada una de las cuales tiene un BWMachineD, que puede gestionar todo esto, orquestar, etc.
Ecosistema de World of Tanks
Que hay alrededor Parecería que hay un servidor de juego y jugadores: eligieron un tanque y fueron a jugar. Pero, desafortunadamente (o con alegría), el juego se está desarrollando y la mecánica del juego de "solo disparar" ya no es suficiente. En consecuencia, el servidor del juego comenzó a cubrirse con varios servicios, algunos de los cuales generalmente eran imposibles de hacer dentro del servidor, mientras que comenzamos a eliminar otros especialmente para aumentar la velocidad de entrega de contenido al jugador. Es decir, es más rápido escribir un pequeño servicio en Python que haga algún tipo de mecánica de juego que hacerlo dentro del servidor en todos los BaseAPP, grupos de soporte, etc.
Algunas cosas, por ejemplo, los sistemas de pago se emitieron originalmente. Soportamos a otros, porque Wargaming desarrolla más de un juego, después de todo. Esta es una trilogía: tanques, aviones, barcos, y hay Blitz y planes para nuevos juegos. Si estuvieran dentro de BigWorld, entonces no podrían usarse convenientemente en otros productos.
Todo fue bastante rápido y caótico, lo que resultó en algunas tecnologías de zoológico que se utilizan en nuestro ecosistema de tanques.
Tecnologías y protocolos clave:
1. Python 2.7, 3.5;
2. Erlang
3. Scala;
4. JavaScript;
Marcos
5. Django;
6. halcón;
7. asincio;
Almacenamiento:
8. Postgres;
9. Percona.
10. Memcached y Redis para el almacenamiento en caché.
Todo junto para el jugador, este es el servidor del tanque:
- Punto único de autorización;
- Chatear
- Clanes;
- Sistema de pago;
- Sistema de torneo;
- Meta juegos (mapa global, áreas fortificadas);
- Portal del tanque, portal del clan;
- Gestión de contenidos, etc.
Pero si nos fijamos, estas son cosas ligeramente diferentes escritas en diferentes tecnologías. Esto causa algunos problemas de confiabilidad.
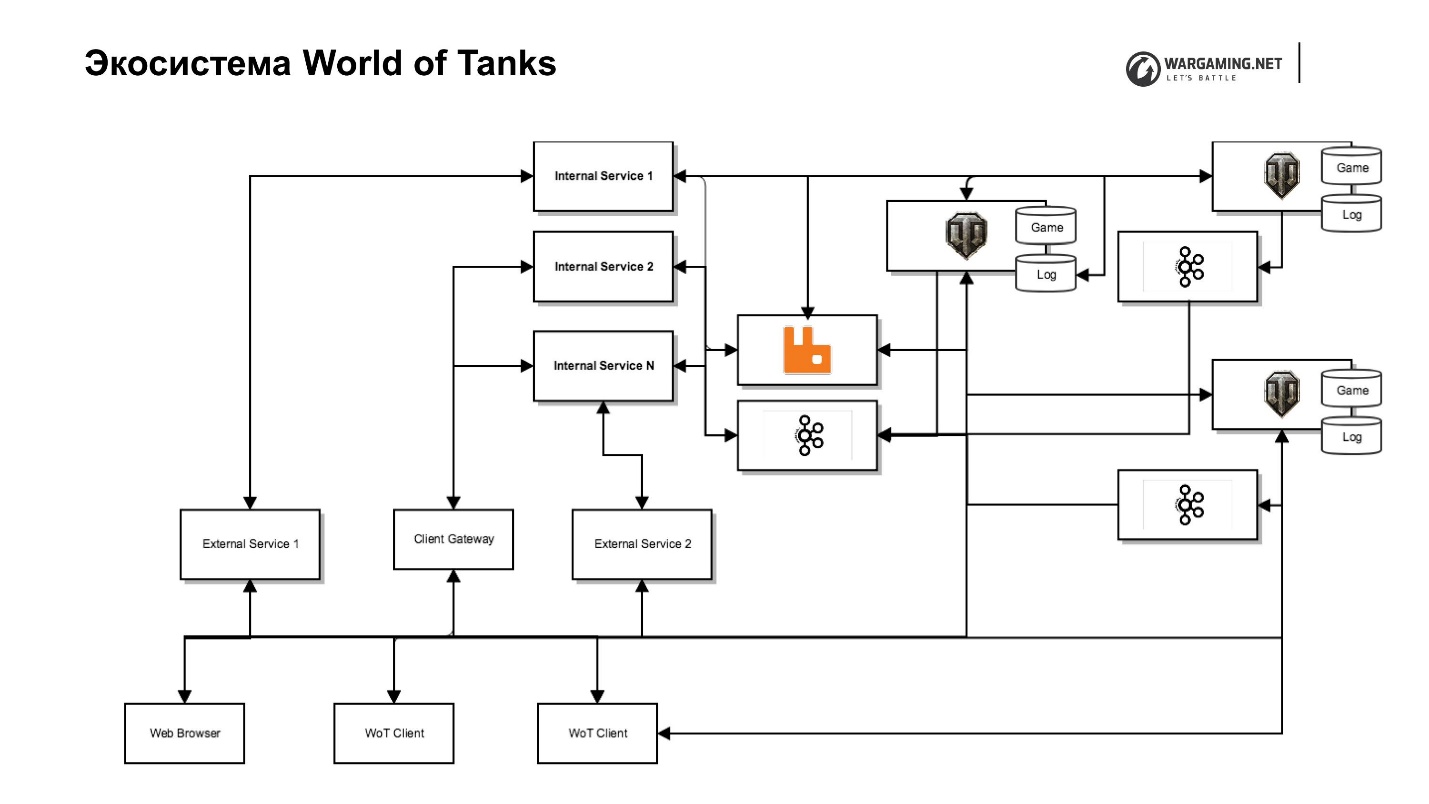
El diagrama muestra nuestro servidor de tanque junto con su ecosistema. Hay un servidor de juegos, servicios web (internos y externos), que incluyen servicios completamente especiales que se encuentran en la red de fondo y realizan funciones de servicio, y servicio a ellos, que realmente implementan las interfaces. Por ejemplo, hay un servicio de clan con su propio portal de clan, que le permite administrar este clan, hay un portal del juego en sí, etc.
Esta separación nos permite preocuparnos menos por la seguridad, porque nadie tiene acceso a la red interna, menos problemas. Pero esto lleva a esfuerzos adicionales, porque necesitamos representantes que nos den acceso si necesitamos empujarlo hacia afuera.
Ya dije que tomamos la decisión de eliminar parte del juego y la lógica del juego. Había una tarea de alguna manera incluir todo en el cliente. Tenemos un maravilloso Client Gateway que permite que un cliente tanque acceda directamente a un servidor desde algunas de las API de estos Servicios internos, los mismos clanes o API de nuestros metajuegos.
Además, introdujimos Chromium Embedded Framework (CEF) dentro del cliente de tanque. Ahora tenemos el mismo navegador. El jugador no lo distingue de la ventana del juego. Esto le permite trabajar con toda la infraestructura, evitando el trabajo con el servidor del juego.
Tenemos muchos grupos, sucedió, te diré por qué. Así es como se ve la región de la CEI.
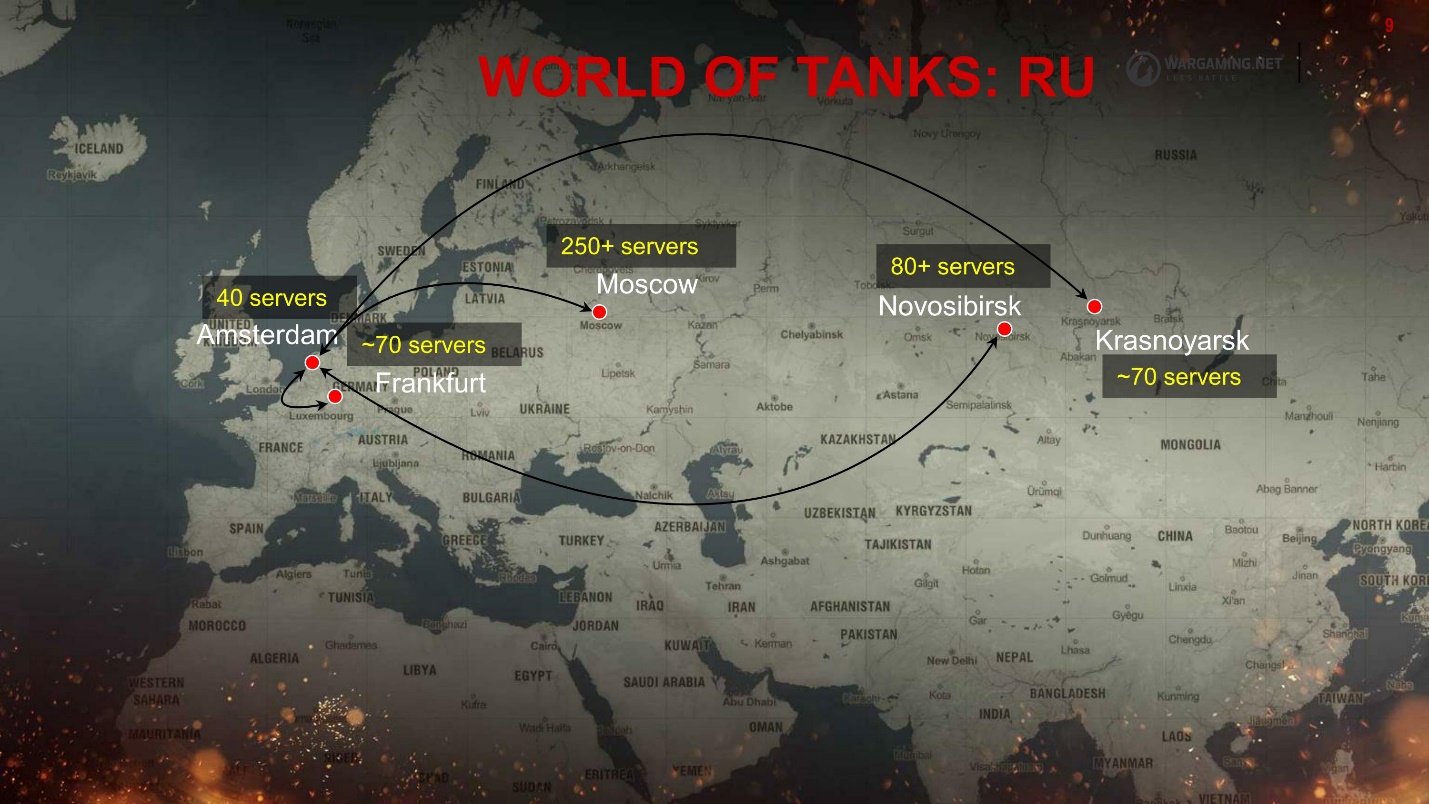
Todo está disperso por los centros de datos. Los jugadores, dependiendo de dónde sea mejor el ping, se conectan a la ubicación. Pero todo el ecosistema no se escala de esta manera, principalmente en Europa y Moscú, lo que también nos agrega algunos problemas de confiabilidad: latencia y reenvío adicionales.
Así es como se ve el ecosistema de World of Tanks.
¿Qué puede salir mal con toda esta economía? Lo que quieras! Y va J. Pero desarmemoslo.
Puntos clave de falla dentro de un clúster
Falla de una sola máquina o proceso
La opción más simple que podemos predecir es la falla de una máquina o proceso dentro de un clúster. Tenemos grupos de 10 a 100 autos, algo puede volar. Como dije, BigWorld proporciona mecanismos listos para usar que nos permiten ser más confiables.
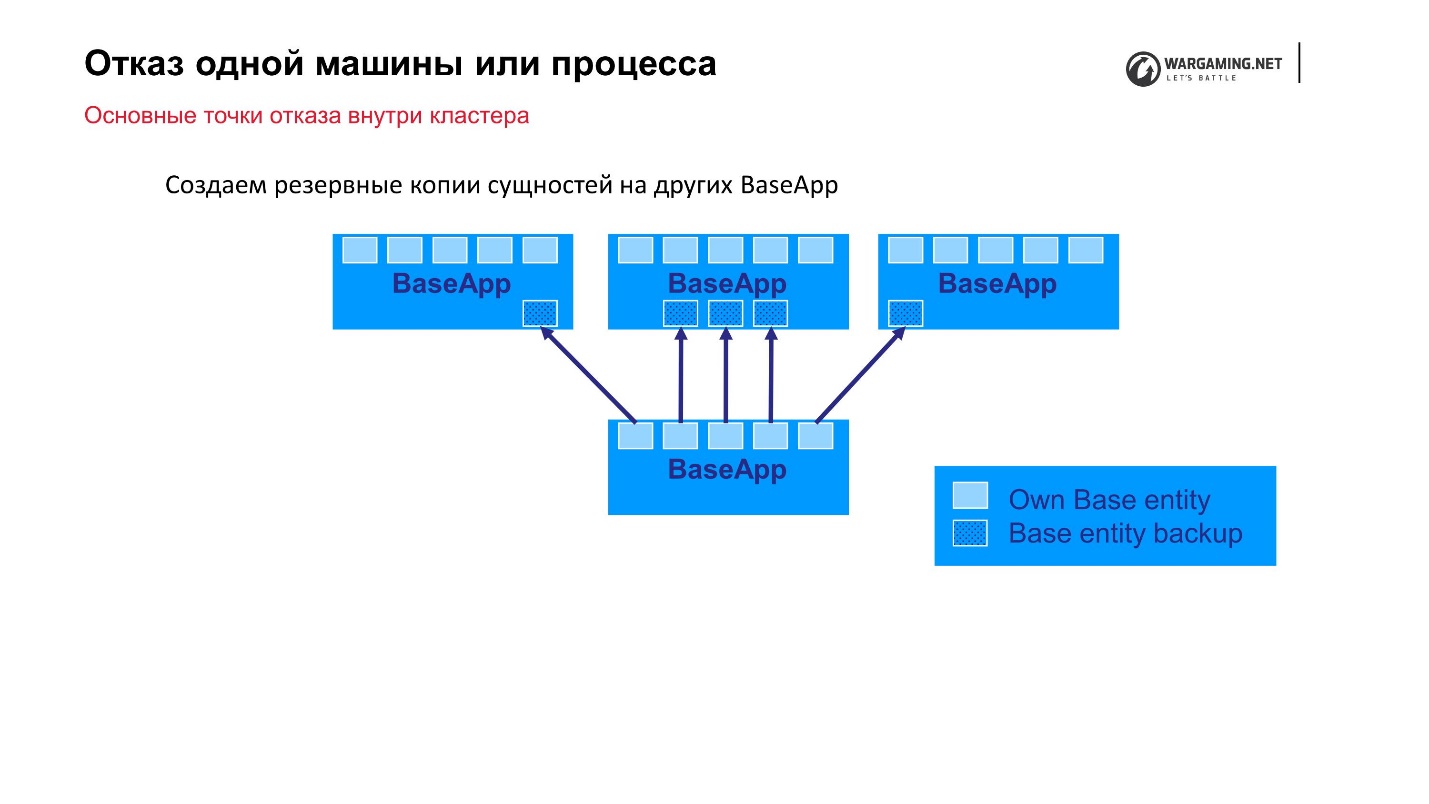
Esquema estándar: hay BaseApps que se distribuyen en diferentes máquinas. En estas BaseApp hay entidades que contienen entidades estatales. Cada BaseApp se respalda con Round Robin en otros.
Supongamos que tenemos un archivo y algo de BaseApp murió, o la máquina entera murió, ¡está bien! Las BaseApps restantes dejaron estas entidades, se restaurarán y el juego para el jugador no sufrirá.
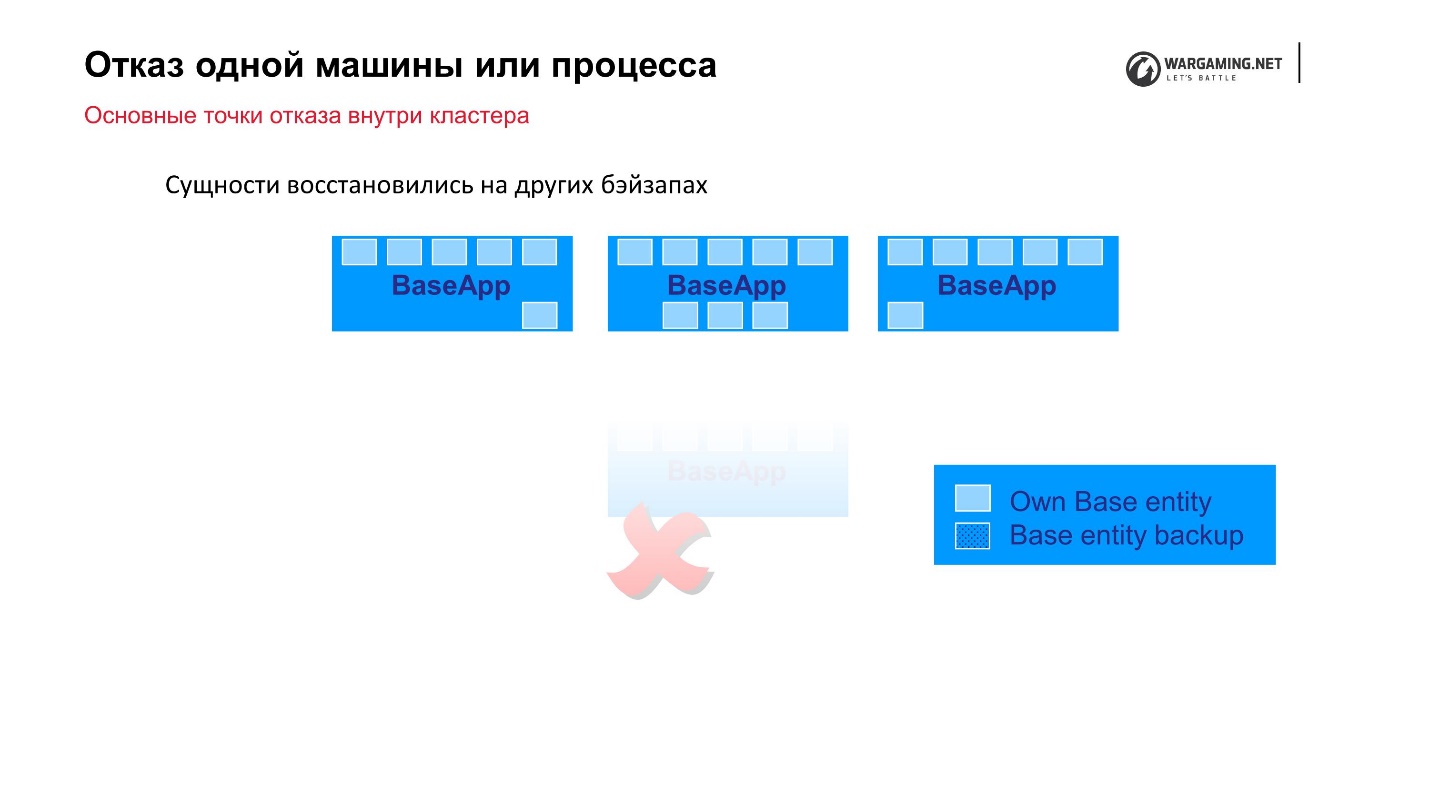
Los CellAPP hacen exactamente lo mismo, lo único es que también almacenan sus estados en BaseApps, y no en otros CellAPP.
Parece ser un mecanismo confiable, pero ...
Tienes que pagar por todo
Con el tiempo, comenzamos a observar lo siguiente.
• La creación de copias de seguridad de entidades comienza a ocupar más y más recursos del sistema y tráfico de red.
De hecho, el proceso de copia de seguridad comienza a afectar la estabilidad del sistema cuando, dentro del clúster, la mayor parte de la red está ocupada transmitiendo copias a Round Robins.
• El tamaño de las entidades crece con el tiempo, a medida que se agregan nuevos atributos y mecánicas de juego.
Pero lo más desagradable es que los tamaños de estas entidades crecen como una avalancha. Por ejemplo, un jugador realiza alguna acción (compra la propiedad del juego), y esta operación comenzó a ralentizarse. Todavía no lo hemos completado, pero hemos guardado los cambios en estos atributos. Es decir, el sistema es tan malo y todavía estamos empezando a aumentar el tamaño de la copia de seguridad que debe hacerse. Hay un efecto de bola de nieve.
• La estabilidad general del sistema disminuye
Debido al hecho de que estamos tratando de escapar de la caída de una máquina o proceso, dejamos caer la estabilidad de todo el sistema.
¿Qué hemos hecho para lidiar con esto ? Decidimos que cada entidad resalte lo que realmente necesita ser respaldado. Dividimos los atributos en mutables e inmutables, y no copiamos toda la entidad, pero solo respaldamos sus atributos mutables. De esta manera, simplemente redujimos la cantidad de información que realmente necesita mantenerse en hierro. Ahora, al agregar un nuevo atributo, quien lo haga debería ver más claramente dónde atribuirlo. Pero en general, esto nos salvó la situación.
Para ser completamente franco, este mecanismo se estableció en BigWorld, pero en Tanks en algún momento ya no fue compatible hasta el final, y no todas las entidades pueden recuperarse de su respaldo. En Ships, por ejemplo, los chicos apoyan esto. Allí puede apagar las máquinas de forma segura: la información simplemente se restaurará en otras máquinas y el cliente no notará nada. Desafortunadamente, este no es siempre el caso en Tanks, pero lograremos el retorno de toda esta funcionalidad para que funcione como debería.
Falla del centro de datos. Multi-cluster
Si de repente no caen 1-2 autos, y comenzamos a perder todo el centro de datos, es decir, el clúster por completo, ¿qué propiedades debe tener el sistema para que el juego no caiga en tal situación?
- Cada grupo debe ser independiente, es decir:
- debe tener su propia base de datos;
- el grupo procesa solo sus espacios (arenas de batalla).
Por lo tanto, si algunas arenas golpean, otras aún funcionan. - Los grupos deben comunicarse entre sí para que uno pueda decir al segundo: "¡Me caí!" Cuando aumenta, los datos se restaurarán a partir de las copias guardadas.
- También es deseable que pueda transferir al usuario de un clúster a otro.
Por el momento, el esquema de nuestro multi-cluster se ve así.
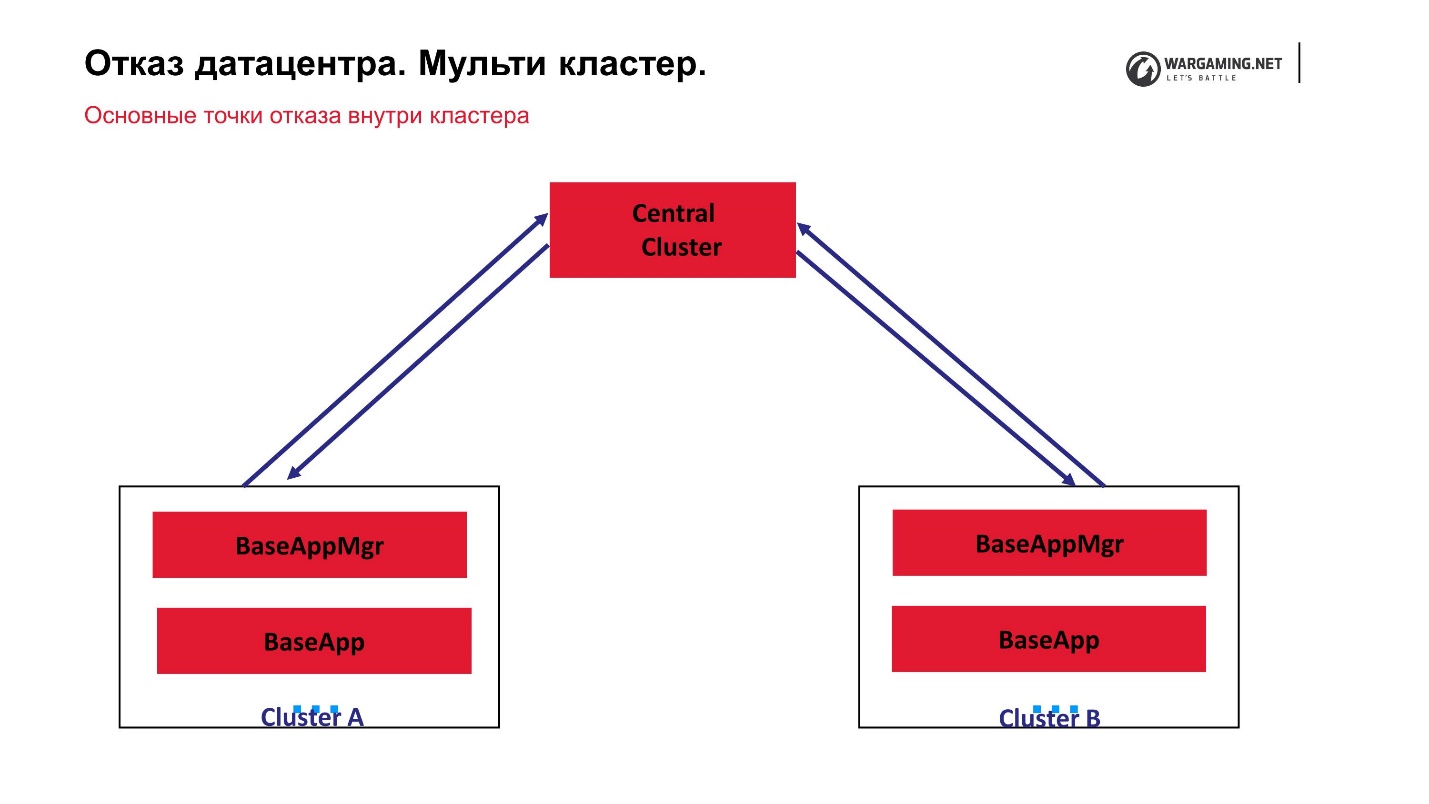
Tenemos un grupo central y lo que llamamos periféricos en los que se libran las batallas reales. CellApp no se ejecuta en el clúster central; de lo contrario, es exactamente igual que todos los demás. Es el punto central del procesamiento de cuentas: se elevan allí, se envían a la periferia y en la periferia ya está jugando una persona. Es decir, el fracaso de cualquiera de los grupos no conduce a una pérdida de operatividad de todo el juego. Incluso la falla del grupo central simplemente no permite que los nuevos jugadores inicien sesión, pero aquellos que ya están jugando en la periferia pueden continuar el juego.
El hecho de que todo funciona para nosotros a través del clúster central ha resultado porque, en general, la tecnología BigWorld en sí misma supone que existe un proceso de gestión especial entre los gestores entre clasificadores. De hecho, tales gerentes entre clasificadores pueden ser criados de alguna manera.
Históricamente, los tanques necesitaban un clúster múltiple, porque comenzó a crecer la avalancha en línea. Cuando llegamos al pico de 200 mil jugadores, el tráfico entrante de ellos simplemente dejó de ser colocado en el centro de datos a través de la red. Tuvimos que arrodillarnos literalmente algún tipo de solución para que los jugadores pudieran lanzarse a varios centros de datos.
De hecho, solo ganamos, porque ahora tenemos un multi-cluster. También se ha vuelto útil para los jugadores, porque el ping, es decir, la accesibilidad a través de la red, afecta en gran medida el juego. Si el retraso es más de 50-70 ms, esto ya comienza a afectar la calidad del juego en sí, porque en Tanks absolutamente todo se calcula en el servidor. No hay cálculos sobre el cliente. Por lo tanto, tenga en cuenta que prácticamente no hay nada que hacer. Por supuesto, algunas modificaciones se realizan allí, pero no afectan el proceso en sí. Puedes intentar adivinar lo que sucederá, pero afectar la mecánica del juego en sí, no.
Debido a este enfoque, nuestro
grupo central se ha convertido en un punto de falla . Todo estaba cerrado para él. Decidimos: dado que estas máquinas y una gran base de guarida de juego están parados allí, dejemos que nuestros periféricos se ocupen exclusivamente de la lucha. Entonces, realmente no hay necesidad de almacenar grandes cantidades de información: las batallas se juegan y se juegan, guardemos todo allí.
Para reescribir absolutamente todo para alejarse del concepto de un grupo central, ahora no hay tiempo, no hay un deseo especial. Pero decidimos, en primer lugar, enseñar a los grupos periféricos a comunicarse entre sí. Luego, abrimos un agujero en ellos para que fuera posible influir en ellos utilizando servicios de terceros.
Por ejemplo, para crear una batalla antes, era necesario decirle al grupo central que era necesario crear una batalla en alguna parte de la periferia. Además, por mecanismos internos, las entidades se movieron, se creó la esencia de la arena, etc.
Ahora es posible contactar directamente con la periferia, sin pasar por el grupo central. Entonces le quitamos el trabajo extra. Pero hasta ahora no existe el deseo de cambiar completamente a un esquema en el que todos los grupos sean casi iguales, y todo esto está controlado por algunos procesos, pero no por el grupo.
Les recuerdo que además del grupo de juegos con sus BaseApps, CellApps y otros, tenemos un ecosistema.
Intentamos asegurarnos de que el rendimiento del ecosistema no afecte la jugabilidad. En el peor de los casos, por ejemplo, el sistema de torneo no funciona, pero puedes jugar al azar; de todos modos, la mayoría de las personas juegan al azar. Sí, bajamos la calidad, pero en general, puedes sobrevivir varias horas sin torneos.
Esto no siempre sucede. En primer lugar, ya existen servicios web que están profundamente integrados en el juego. Por ejemplo, un único punto de autorización es un servicio que le permite iniciar sesión en la web o en algún lugar en un lugar, y en realidad iniciar sesión en todo el universo Wargaming.
El segundo ejemplo es un servicio que sirve compras y transacciones de juegos. También tuvo que incorporarse al juego solo porque necesitábamos un rastro de las compras del jugador. El hecho es que en algunas regiones estamos obligados a mostrar información al cliente sobre qué propiedad del juego se compró con dinero real y cuál para el dinero del juego. Inicialmente, el sistema no asumía esto, nadie lo presentó hace 5 años, pero la
ley es dura: debe hacerlo, hágalo .
Puntos de falla del ecosistema de World of Tanks
Problema número 1. Mayor carga
Tenemos un clúster múltiple en el que 10 clústeres con una gran cantidad de máquinas. Los jugadores los juegan, y la web es pequeña. Nadie compra cinco máquinas más en cada centro de datos. Pero al mismo tiempo, brindamos la misma funcionalidad y todo lo que se necesita dentro del cliente. Este es el principal problema.
La interactividad y la reactividad de la interfaz son la fuente principal del aumento de la carga del ecosistema.
Daré dos ejemplos del servicio del clan:
- Quieres invitar a otro jugador al clan. Por supuesto, quiero que el invitado reciba de inmediato una notificación y que pueda unirse a usted. Para implementar esto, es necesario hacer que el servicio del clan notifique de alguna manera al cliente, o dejar que el cliente pregunte al servicio web de vez en cuando: “¿Ha cambiado algo? ¿Tengo alguna nueva invitación? Esta es la primera opción de donde puede venir la carga extra.
- Los tanques tienen un régimen fortificado. Supongamos que lo juega no una persona, sino varias. Todos los jugadores tienen una ventana abierta con áreas fortificadas. El comandante construyó el edificio. Es aconsejable que para todos los que tengan esta ventana abierta, el edificio aparezca de inmediato.
La decisión en la frente con la encuesta no es muy buena. De hecho, está funcionando, es solo que necesita asignar tantas capacidades para esto que esta característica no generará ningún beneficio para la empresa. Y si la función no genera ganancias, entonces no es necesario que lo haga.
Mi consejo personal sobre cómo manejar esto: la mejor manera de hacer que el sistema sea más confiable bajo carga es generalmente reducir la carga de alguna manera lógica.
No deberías quedarte acostado con hierro, idear sistemas novedosos, optimizar algo; de todos modos, cuanto mayor sea la carga, más artefactos aparecerán de los que no puedes escapar. Además, los artefactos ocurrirán incluso en niveles de abstracción cada vez más bajos: primero con las aplicaciones, luego con diferentes servicios web, luego accederá a la red (Cisco, etc.). En algún nivel, simplemente no puede resolver los problemas.
Si piensa con cuidado, simplemente se pueden evitar.
Lo primero que hicimos fue
aprender a notificar a los clientes a través de un servidor de juegos utilizando su infraestructura. Por ejemplo, cuando llega una invitación al clan, le decimos al servidor: "Invitamos a tal o cual gente", y luego el clúster del clúster mismo encuentra a quién debe enviarse la notificación, especialmente porque tienen una conexión. Es decir, empujamos desde el servicio, y no alguien nos vierte constantemente. , , . , , .
—
Web-sockets (nginx-pushstream) . , Web-sockets. , Chromium Embedded Framework — , , Web-sockets Nginx. pushstream, Web-sockets .
№ 2.
, , ,
— . , , — .
, , .
? : - , - , , . - , , . .
.

,
120 Game Play . . , , . , . .
3 , :
- HTTP API;
- RabbitMQ — ;
- Apache Kafka .
, , , , , . , - — , . , .
1. HTTP— HTTP. , , -, . :
, , . , , , Django, 100 200 , API, . , , - 30-40 , , . , — .
, , HTTP, — . . — — . ,
, , , .
. . - , - API — API, .
— , . , , . , 10 , - 100 500. , HTTP . nginx' , — .
, HTTP , .
2. RabbitMQRabbitMQ BigWord .
— - , , , .
: . , API: « N — ». , , , , — . , .
«», «», — .
RabbitMQ , , , , , , , .
— RabbitMQ .
3. Kafka, , — Kafka. , RabbitMQ - .
, , , . , , . . Kafka. , — , .
, . , , - — .
Kafka , , , - , . .
— .

:
- . , - , ..
- — , , , .
- — , . , , .
. , , , entity. . , , .
DLC
, DLC (Development Lifecycle) — , , .
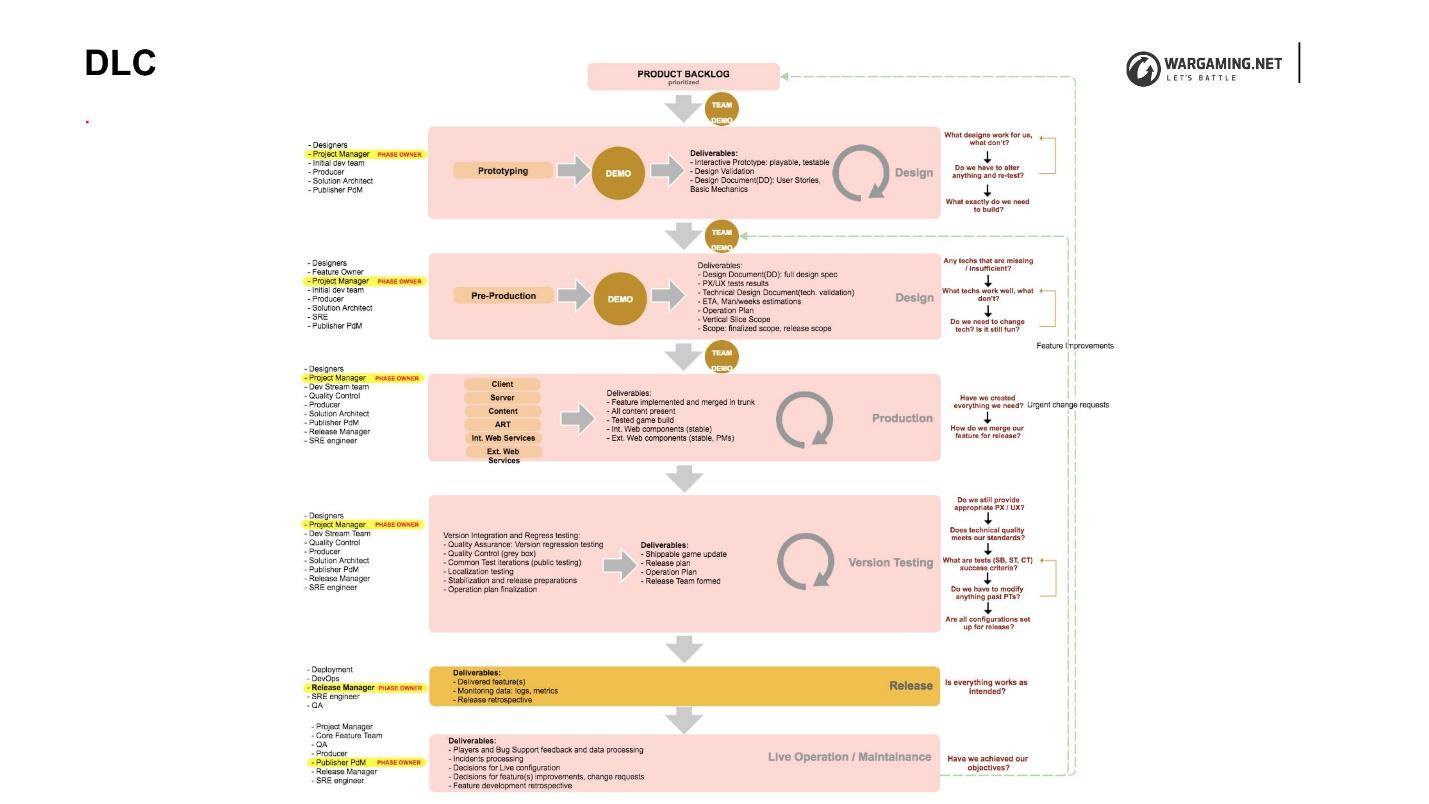
, , . DLC , , . , . , , , .
DLC, . , , , .
DLC, , :
•
( )., , «- , », . , , , , .
• : SRE.
, solution-, technical-owner, reability- — , - , game- . , , , . - , , , , . , .
•
SRE .— - . , . , SRE -. SRE , : « , , , — !» , .
QA , , - , , — .
BigWorld Technology «» . , . . « », .
« » , , . — «» (, ) — . , . , - .
: ++. , 40 , . al final del informe y escucha, quizás te interesaron algunos aspectos.La conferencia RootConf está cambiando de marca, ahora es DevOpsConf Rusia . Decidimos organizar una conferencia profesional por separado sobre DevOps el 1 y 2 de octubre en Moscú , en Infospace. Planeamos discutir todos los temas que son relevantes para los especialistas en sistemas de información. Vea qué tipo de solicitudes de informes recibió el Comité del Programa: ¡hay mucho para elegir!