“El equipo de @Cloudflare acaba de hacer cambios que han mejorado significativamente el rendimiento de nuestra red, especialmente para las solicitudes más lentas. Cuanto mas rapido Estimamos que estamos ahorrando a Internet aproximadamente 54 años de tiempo por día que de otro modo se habrían gastado esperando a que se carguen los sitios ” . -
Tweet de Matthew Prince, 28 de junio de 2018
10 millones de sitios, aplicaciones y API utilizan Cloudflare para acelerar las descargas de contenido para los usuarios. En el pico, procesamos más de 10 millones de solicitudes por segundo en 151 centros de datos. Con los años, hemos realizado muchos cambios en nuestra versión de Nginx para hacer frente al crecimiento. Este artículo trata sobre uno de estos cambios.
Cómo funciona Nginx
Nginx es uno de los programas que utiliza bucles de procesamiento de eventos para resolver
el problema C10K . Cada vez que llega un evento de red (una nueva conexión, solicitud o notificación para enviar una mayor cantidad de datos, etc.), Nginx se despierta, procesa el evento y luego regresa a otro trabajo (esto puede estar procesando otros eventos). Cuando llega un evento, los datos están listos, lo que le permite procesar eficientemente muchas solicitudes simultáneas sin tiempo de inactividad.
num_events = epoll_wait(epfd, events, events_len, -1); // events is list of active events // handle event[0]: incoming request GET http://example.com/ // handle event[1]: send out response to GET http://cloudflare.com/
Por ejemplo, así es como se vería un fragmento de código para leer datos de un descriptor de archivo:
// we got a read event on fd while (buf_len > 0) { ssize_t n = read(fd, buf, buf_len); if (n < 0) { if (errno == EWOULDBLOCK || errno == EAGAIN) { // try later when we get a read event again } if (errno == EINTR) { continue; } return total; } buf_len -= n; buf += n; total += n; }
Si fd es un socket de red, se devolverán los bytes ya recibidos. La última llamada devolverá
EWOULDBLOCK . Esto significa que el búfer de lectura local ha finalizado y ya no debería leer desde este socket hasta que aparezcan los datos.
Disk I / O es diferente de la red
Si fd es un archivo normal en Linux,
EWOULDBLOCK y
EAGAIN nunca aparecen, y la operación de lectura siempre espera para leer todo el búfer, incluso si el archivo se abre con
O_NONBLOCK . Como está escrito en el manual
abierto (2) :
Tenga en cuenta que este indicador no es válido para archivos normales y dispositivos de bloque.
En otras palabras, el código anterior se reduce esencialmente a esto:
if (read(fd, buf, buf_len) > 0) { return buf_len; }
Si el controlador necesita leer del disco, bloquea el bucle de eventos hasta que se complete la lectura, y los controladores de eventos posteriores esperan.
Esto es normal para la mayoría de las tareas, ya que leer desde un disco suele ser bastante rápido y mucho más predecible que esperar un paquete de la red. Especialmente ahora que todos tienen un SSD, y todos nuestros cachés están en SSD. En los SSD modernos, un retraso muy pequeño, generalmente en decenas de microsegundos. Además, puede ejecutar Nginx con múltiples flujos de trabajo para que un controlador de eventos lento no bloquee las solicitudes en otros procesos. La mayoría de las veces puede confiar en Nginx para procesar solicitudes de manera rápida y eficiente.
Rendimiento SSD: no siempre como se prometió
Como habrás adivinado, estas suposiciones optimistas no siempre son ciertas. Si cada lectura siempre toma 50 μs, entonces leer 0.19 MB en bloques de 4 KB (y leemos en bloques aún más grandes) tomará solo 2 ms. Pero las pruebas mostraron que el tiempo hasta el primer byte es a veces mucho peor, especialmente en los percentiles 99 y 999. En otras palabras, la lectura más lenta de cada 100 (o 1000) lecturas a menudo lleva mucho más tiempo.
Las unidades de estado sólido son muy rápidas, pero conocidas por su complejidad. Tienen computadoras dentro de esa cola y reordenan las E / S, y también realizan varias tareas en segundo plano, como la recolección de basura y la desfragmentación. De vez en cuando, las solicitudes disminuyen notablemente. Mi colega
Ivan Bobrov lanzó varios puntos de referencia de E / S y registró retrasos de lectura de hasta 1 segundo. Además, algunos de nuestros SSD tienen más picos de rendimiento que otros. En el futuro, tendremos en cuenta este indicador al comprar un SSD, pero ahora necesitamos desarrollar una solución para el equipo existente.
Distribución de carga uniforme con SO_REUSEPORT
Es difícil evitar una respuesta lenta por cada 1000 solicitudes, pero lo que realmente no queremos es bloquear las 1000 solicitudes restantes por un segundo entero. Conceptualmente, Nginx puede procesar muchas solicitudes en paralelo, pero solo inicia un controlador de eventos a la vez. Entonces agregué una métrica especial:
gettimeofday(&start, NULL); num_events = epoll_wait(epfd, events, events_len, -1); // events is list of active events // handle event[0]: incoming request GET http://example.com/ gettimeofday(&event_start_handle, NULL); // handle event[1]: send out response to GET http://cloudflare.com/ timersub(&event_start_handle, &start, &event_loop_blocked);
El percentil 99 (p99)
event_loop_blocked superó el 50% de nuestro TTFB. En otras palabras, la mitad del tiempo al atender una solicitud es el resultado de bloquear el ciclo de procesamiento de eventos por otras solicitudes.
event_loop_blocked solo mide la mitad del bloqueo (porque no se miden las llamadas pendientes a
epoll_wait() ), por lo que la proporción real del tiempo bloqueado es mucho mayor.
Cada una de nuestras máquinas ejecuta Nginx con 15 flujos de trabajo, es decir, una E / S lenta no bloqueará más del 6% de las solicitudes. Pero los eventos no se distribuyen de manera uniforme: el trabajador principal recibe el 11% de las solicitudes.
SO_REUSEPORT puede resolver el problema de la distribución desigual. Marek Maikovsky escribió anteriormente sobre el
inconveniente de este enfoque en el contexto de otras instancias de Nginx, pero aquí puede ignorarlo principalmente: las conexiones aguas arriba en el caché son duraderas, por lo que puede descuidar un ligero aumento en el retraso al abrir la conexión. Este cambio de configuración solo con la activación de
SO_REUSEPORT mejoró el pico p99 en un 33%.
Mover read () a un grupo de subprocesos: no una bala de plata
La solución es hacer que read () no bloquee. En realidad, esta función se
implementa en Nginx normal ! Usando la siguiente configuración, read () y write () se ejecutan en el grupo de subprocesos y no bloquean el bucle de eventos:
aio threads; aio_write on;
Pero probamos esta configuración y, en lugar de mejorar el tiempo de respuesta en 33 veces, notamos solo un pequeño cambio en p99, la diferencia está dentro del margen de error. El resultado fue muy desalentador, por lo que pospusimos temporalmente esta opción.
Hay varias razones por las que no tuvimos mejoras significativas, como los desarrolladores de Nginx. En la prueba, utilizaron 200 conexiones simultáneas para solicitar archivos de 4 MB al HDD. Los Winchesters tienen mucha más latencia de E / S, por lo que la optimización tiene un mayor efecto.
Además, nos preocupa principalmente el rendimiento de p99 (y p999). La optimización del retraso promedio no necesariamente resuelve el problema del pico de emisión.
Finalmente, en nuestro entorno, los tamaños de archivo típicos son mucho más pequeños. El 90% de nuestros hits de caché son menos de 60 KB. Cuanto más pequeños son los archivos, menos casos de bloqueo (generalmente leemos el archivo completo en dos lecturas).
Echemos un vistazo a la E / S del disco cuando se golpea en la memoria caché:
// https://example.com 0xCAFEBEEF fd = open("/cache/prefix/dir/EF/BE/CAFEBEEF", O_RDONLY); // 32 // , "aio threads" read(fd, buf, 32*1024);
32K no siempre se leen. Si los encabezados son pequeños, entonces necesita leer solo 4 KB (no usamos E / S directamente, por lo que el núcleo se redondea a 4 KB).
open() parece inofensivo, pero en realidad requiere recursos. Como mínimo, el núcleo debe verificar si el archivo existe y si el proceso de llamada tiene permiso para abrirlo. Necesita encontrar el inodo para
/cache/prefix/dir/EF/BE/CAFEBEEF , y para esto tendrá que buscar
CAFEBEEF en
/cache/prefix/dir/EF/BE/ . En resumen, en el peor de los casos, el núcleo realiza esta búsqueda:
/cache /cache/prefix /cache/prefix/dir /cache/prefix/dir/EF /cache/prefix/dir/EF/BE /cache/prefix/dir/EF/BE/CAFEBEEF
Estas son 6 lecturas separadas que
open() produce, en comparación con 1
read() . Afortunadamente, en la mayoría de los casos, la búsqueda cae en el
caché de dentry y no llega al SSD. Pero está claro que procesar
read() en un grupo de subprocesos es solo la mitad de la imagen.
Acorde final: open () sin bloqueo en grupos de subprocesos
Por lo tanto, realizamos un cambio en Nginx para que
open() se ejecute principalmente dentro del grupo de subprocesos y no bloquee el bucle de eventos. Y aquí está el resultado de open () y read () sin bloqueo al mismo tiempo:
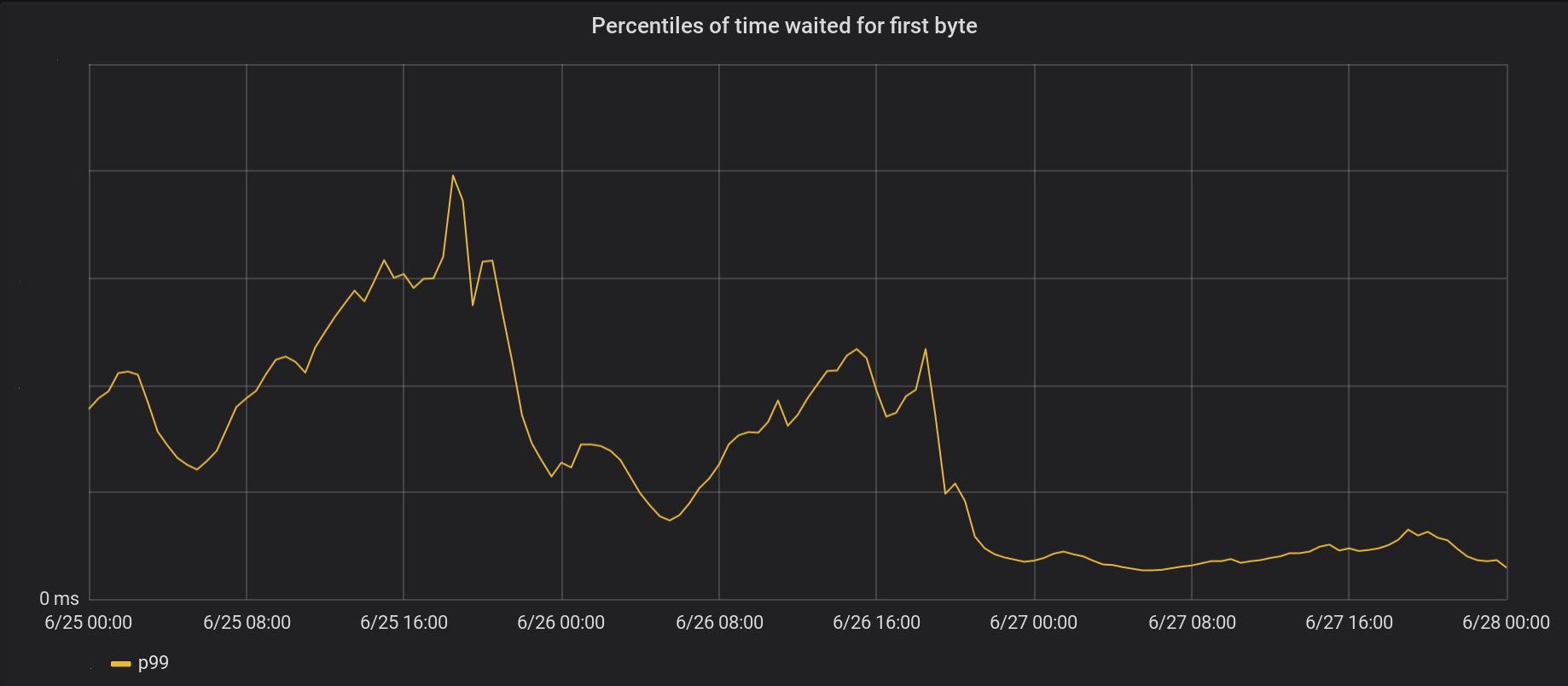
El 26 de junio, transferimos los cambios a los 5 centros de datos más activos y, al día siguiente, a los otros 146 centros de datos de todo el mundo. El pico total p99 TTFB disminuyó 6 veces. De hecho, si resumimos todo el tiempo desde el procesamiento de 8 millones de solicitudes por segundo, ahorramos a Internet 54 años de espera todos los días.
Nuestra serie de eventos aún no se ha deshecho por completo de las cerraduras. En particular, el bloqueo aún ocurre la primera vez que el archivo se almacena en caché (tanto
open(O_CREAT) como
rename() ) o al actualizar la revalidación. Pero tales casos son raros en comparación con los accesos a caché. En el futuro, consideraremos la posibilidad de mover estos elementos fuera del ciclo de procesamiento de eventos para mejorar aún más el factor de retraso p99.
Conclusión
Nginx es una plataforma poderosa, pero escalar cargas de E / S de Linux extremadamente altas puede ser una tarea desalentadora. Nginx estándar descarga la lectura en hilos separados, pero en nuestra escala a menudo necesitamos ir un paso más allá.