Esta es una historia sobre portar JavaScript a la plataforma nacional Elbrus, hecha por chicos de UniPro. El artículo proporciona un breve análisis comparativo de plataformas, detalles de procesos y dificultades.

El artículo se basa en un informe de Dmitry (
dbezheckov ) Bezhetskov y Vladimir (
volodyabo ) Anufrienko con HolyJS 2018 Piter. Debajo del corte, encontrará la transcripción de video y texto del informe.
Parte 1. Elbrus, originario de Rusia
Primero, entenderemos qué es Elbrus. Aquí hay algunas características clave de esta plataforma en comparación con x86.
Arquitectura VLIW
Una solución arquitectónica completamente diferente a la arquitectura superescalar, que ahora es más común en el mercado. VLIW le permite expresar con mayor precisión las intenciones en el código debido al control explícito de todos los dispositivos de lógica aritmética (ALU) independientes, que Elbrus tiene, por cierto, 4. Esto no excluye la posibilidad de tiempo de inactividad de algunas ALU, pero aún aumenta el rendimiento teórico en un ciclo de reloj El procesador.
Agrupación de equipos
Los comandos del procesador Ready se combinan en paquetes (Bundles). Un paquete es una gran instrucción que se ejecuta por reloj condicional. Tiene muchas instrucciones atómicas que se ejecutan de forma independiente e inmediata en la arquitectura Elbrus.

En la imagen de la derecha, los rectángulos grises indican los paquetes obtenidos al procesar el código JS de la izquierda. Si todo está aproximadamente claro con las instrucciones ldd, fmuld, faddd, fsqrts, entonces la declaración de devolución al comienzo del primer paquete es sorprendente para las personas que no están familiarizadas con el ensamblador de Elbrus. Esta instrucción carga la dirección de retorno de la función floatMath actual en el registro ctpr3 de antemano, de modo que el procesador pueda descargar las instrucciones necesarias. Luego, en el último paquete, ya hacemos la transición a la dirección precargada en ctpr3.
También vale la pena señalar que Elbrus tiene muchos más registros 192 + 32 + 32 frente a 16 + 16 +8 para x86.
Explícito especulativo versus implícito
Elbrus admite especulación explícita en el nivel de comando. Por lo tanto, podemos llamar y cargar a.bar desde la memoria incluso antes de verificar que no sea nulo, como se ve en el código de la derecha. Si la lectura lógica al final no es válida, entonces el valor en b simplemente se marcará como hardware incorrecto y no será posible acceder a él.

Soporte de ejecución condicional
Elbrus también admite ejecución condicional. Considere esto en el siguiente ejemplo.

Como podemos ver, el código del ejemplo anterior sobre especulación también se reduce debido al uso de la convolución de la expresión condicional en dependencia, no por control, sino por datos. El hardware de Elbrus admite registros de predicados, en los que solo puede almacenar dos valores verdaderos o falsos. Su característica principal es que puede marcar instrucciones con dicho predicado y, dependiendo de su valor en el momento de la ejecución, la instrucción se ejecutará o no. En este ejemplo, la instrucción cmpeq realiza la comparación y coloca su resultado lógico en el predicado P1, que luego se utiliza como marcador para cargar el valor de b en el resultado. En consecuencia, si el predicado era igual a verdadero, entonces el valor 0 permanecía en el resultado.
Este enfoque le permite transformar un gráfico de control de programa bastante complejo en ejecución de predicados y, en consecuencia, aumenta la plenitud del paquete. Ahora podemos generar equipos más independientes bajo diferentes predicados y llenarlos con paquetes. Elbrus admite 32 registros de predicados, lo que le permite codificar 65 flujos de control (más uno por la ausencia de un predicado en el comando).
Tres pilas de hardware en comparación con una en Intel
Dos de ellos están protegidos de modificaciones por el programador. Uno, la pila de cadena, es responsable de almacenar las direcciones para los retornos de las funciones, el otro, la pila de registros, contiene los parámetros a través de los cuales se pasan. El tercero, la pila de usuarios, almacena las variables y los datos del usuario. En Intel, todo se almacena en una pila, lo que da lugar a vulnerabilidades, ya que todas las direcciones de las transiciones, los parámetros están en un lugar que no está protegido por modificaciones por parte del usuario.
Sin predictor de rama dinámico
En su lugar, se utiliza un esquema con preparaciones de conversión y transición if para que la canalización de ejecución no se detenga.
Entonces, ¿por qué necesitamos JS en Elbrus?
- Sustitución de importaciones.
- Introducción de Elbrus al mercado de computadoras domésticas, donde ya se requiere Javascript para el mismo navegador.
- Elbrus ya es necesario en la industria, por ejemplo con Node.js. Por lo tanto, debe portar el nodo a esta arquitectura.
- El desarrollo de la arquitectura de Elbrus, así como especialistas en este campo.
Si no hay intérprete, vienen dos compiladores
La implementación anterior de v8 de Google se tomó como base. Funciona así: se crea un árbol de sintaxis abstracta a partir del código fuente, luego, dependiendo de si el código se ejecutó o no, utilizando uno de los dos compiladores (Crankshaft o FullCodegen), respectivamente, se crea un código binario optimizado o no optimizado. No hay intérprete

¿Cómo funciona FullCodegen?
Los nodos del árbol de sintaxis se traducen en código binario, después de lo cual todo se "pega". Un nodo tiene aproximadamente 300 líneas de código en un ensamblador de macros. Esto, en primer lugar, ofrece un amplio horizonte de optimizaciones y, en segundo lugar, no hay transiciones de código de bytes, como en el intérprete. Es simple, pero al mismo tiempo hay un problema: durante la transferencia tendrá que volver a escribir una gran cantidad de código en el ensamblador de macros.
Sin embargo, todo esto se hizo y el resultado fue una versión del compilador FullCodegen 1.0 para Elbrus. Todo se hizo a través de C ++ runtime v8, no optimizaron nada, el código del ensamblador simplemente se reescribió de x86 a la arquitectura Elbrus.
Codegen 1.1
Como resultado, el resultado no fue exactamente el esperado, y se decidió lanzar FullCodegen 1.1:
- Menos tiempo de ejecución, escribió en un ensamblador de macros;
- Se agregaron conversiones if manuales (en la figura, como ejemplo, se verifica que la variable js sea verdadera o falsa);

Tenga en cuenta que la comprobación de NaN, indefinido, nulo se realiza a la vez, sin usar if, que sería necesario en la arquitectura Intel.
- El código no solo se reescribió con Intel, sino que también implementó la especulación en stubs e implementó la ruta rápida también a través de MAsm (ensamblador macro).
Las pruebas se realizaron en Google Octane. Máquinas de prueba:
- Elbrus: E2S 750 MHz, 24 GB
- Intel: Core i7 3.4 GHz, 16 GB
Resultados adicionales:

En el histograma está la relación de los resultados, es decir. ¿Cuántas veces es Elbrus peor que Intel? En dos pruebas, Crypto y zlib, los resultados son notablemente peores debido al hecho de que Elbrus aún no tiene instrucciones de hardware para trabajar con cifrado. En general, dada la diferencia de frecuencias, resultó bastante bien.
La siguiente es una prueba en comparación con el intérprete js de firefox, que es parte de la distribución estándar de Elbrus. Más es mejor.
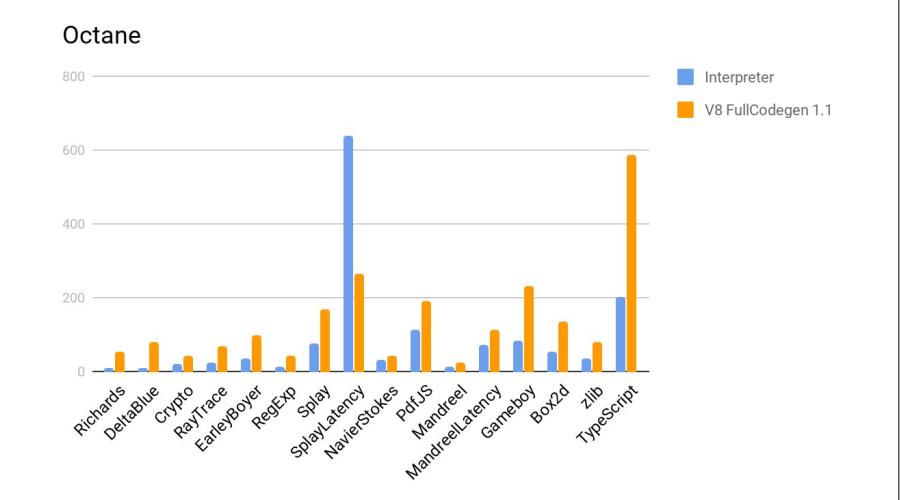
Veredicto: el compilador volvió a hacer un buen trabajo.
Resultados de desarrollo
- El nuevo motor JS pasó las pruebas test262. Esto le da derecho a ser llamado un entorno de tiempo de ejecución completo ECMAScript 262.
- La productividad aumentó en promedio cinco veces en comparación con el motor anterior: el intérprete.
- Node.js 6.10 también fue portado como un ejemplo de uso de V8, ya que no fue difícil.
- Sin embargo, todavía es peor que Core i7 en FullCodegen siete veces.
Nada parecía presagiar
Todo estaría bien, pero aquí Google anunció que ya no es compatible con FullCodegen y Crankshaft y se eliminarán. Después de lo cual el equipo recibió una orden de desarrollo para el navegador Firefox, y más sobre eso más adelante.

Parte 2. Firefox y su mono araña
Se trata del motor del navegador Firefox: SpiderMonkey. En la figura, las diferencias entre este motor y el nuevo V8.
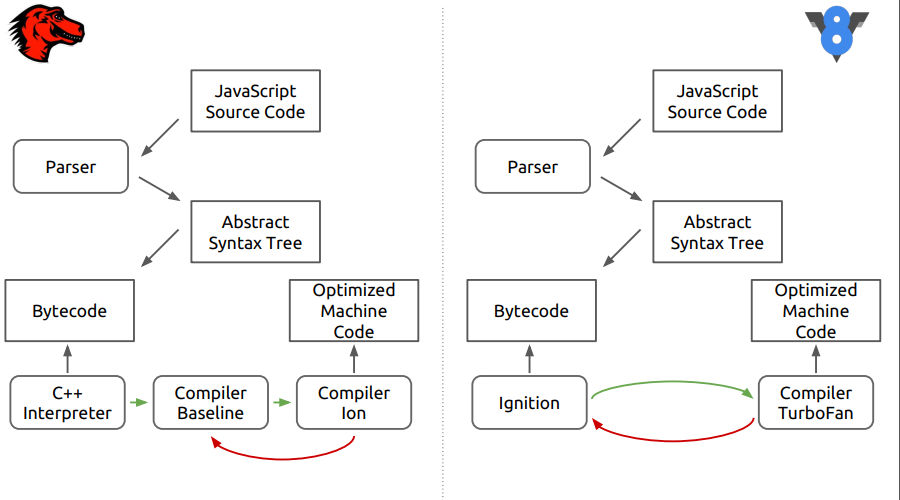
Se puede ver que en la primera etapa todo parece que el código fuente se analiza en un árbol de sintaxis abstracta, luego en código de bytes y luego comienzan las diferencias.
En SpiderMonkey, el bytecode es interpretado por el intérprete de C ++, que en esencia se asemeja a un interruptor grande, dentro del cual se realizan los saltos de bytecode. Además, el código interpretado ingresa al compilador de neotimización de la línea base. Luego, en la etapa final, se incluye el compilador de optimización Ion en el caso. En el motor V8, el bytecode es procesado por el intérprete Ingnition y luego por el compilador TurboFan.
Línea de base, ¡te elijo a ti!
La portabilidad comenzó con el compilador Baseline. Es esencialmente una máquina apilada. Es decir, hay una cierta pila de la que las células toma variables, las recuerda, realiza algunas acciones con ellas, después de lo cual devuelve las variables y los resultados de las acciones a las celdas de la pila. A continuación, en algunas imágenes, este mecanismo se muestra paso a paso con respecto a la función simple foo:
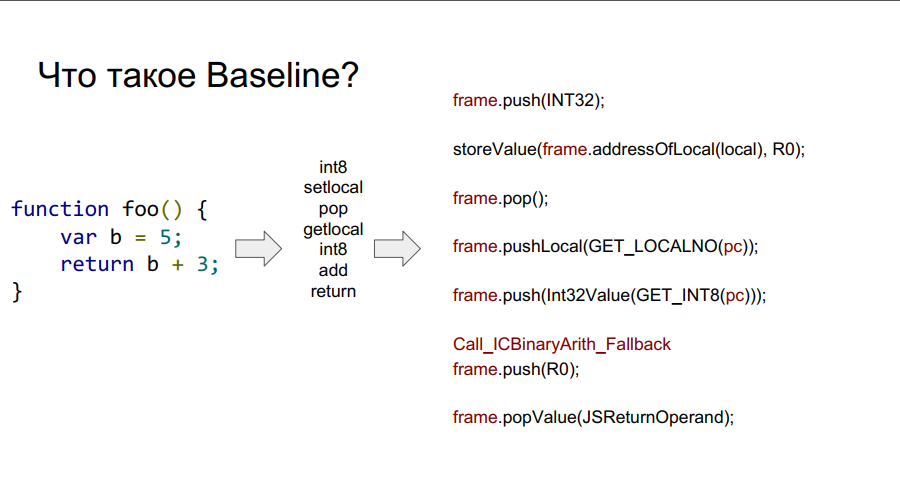


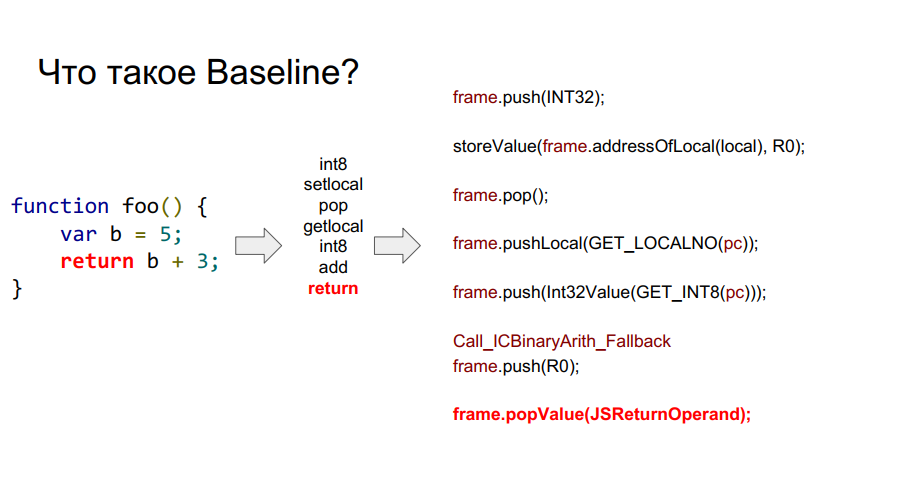
¿Qué es un marco?
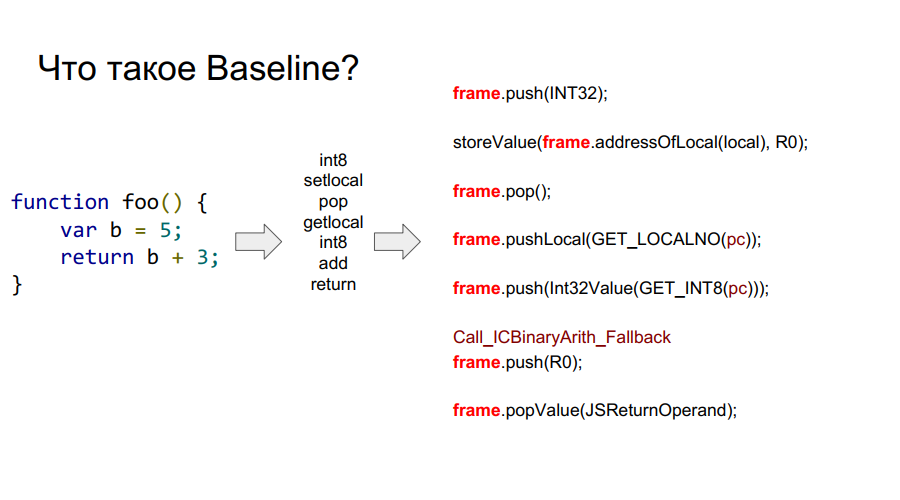
En las imágenes de arriba puedes ver la palabra marco. En términos generales, este es un contexto de Javascript en el hardware, es decir, un conjunto de datos en la pila que describe cualquiera de sus funciones. En la imagen a continuación, la función es foo, y a la derecha de ella se ve cómo se ve en la pila: argumentos, descripción de la función, dirección de retorno, indicación del marco anterior, porque la función se llamó desde algún lugar y para regresar correctamente al lugar de la llamada, esta información debe almacenarse en stack, y luego las variables locales mismas funciones y operandos para los cálculos.

Por lo tanto, las
ventajas de la línea de base :
- Parece FullCodegen, por lo que su experiencia de portabilidad fue útil;
- Portar el ensamblador, obtener un compilador que funcione;
- Es conveniente depurar;
- Cualquier trozo puede ser reescrito.
Pero también hay
desventajas :
- Código lineal, hasta que ejecute un código de byte, no podrá ejecutar lo siguiente, lo que no es muy bueno para la arquitectura con computación paralela;
- Como funciona con bytecode, realmente no optimizas.
Solo quedaba implementar el ensamblador de macros y obtener un compilador listo para usar. La depuración no fue un buen augurio, fue suficiente mirar la pila en la arquitectura x86, y luego en la que se obtuvo al portar para encontrar el problema.
Como resultado, en las pruebas con el nuevo compilador, la productividad se ha triplicado:

Sin embargo, Octane no admite excepciones. Y su implementación es muy importante.
Trabajo excepcional
Primero, veamos cómo funcionan las excepciones en x86. Mientras se ejecuta el programa, las direcciones de retorno de las funciones se escriben en la pila. En algún momento, ocurre una excepción. Pasamos al controlador de excepciones de tiempo de ejecución, que utiliza los marcos de los que hablamos anteriormente. Encontramos dónde ocurrió exactamente la excepción, después de lo cual debemos rebobinar la pila al estado deseado, y luego la dirección de retorno cambia a aquella donde se procesará la excepción.
El problema es que debido a otro dispositivo de pila en la arquitectura de Elbrus, esto no funcionará. Será necesario calcular por llamadas al sistema cuánto necesita rebobinar en la pila de Cadena. A continuación, realizamos una llamada al sistema para obtener la pila de llamadas. A continuación, en la dirección en la pila de Cadena, hacemos un reemplazo para la dirección que realiza la devolución.
A continuación se muestra una ilustración de la secuencia de estos pasos.

No es la forma más rápida, sin embargo, se maneja la excepción. Pero aún así, en Intel parece un poco más simple:

Con Elbrus, habrá más saltos al controlador:

Es por eso que no debe basar la lógica del programa en excepciones, especialmente en Elbrus.
¡Optimízalo!
Entonces, se implementa el manejo de excepciones. Ahora le diremos cómo lo hicimos todo un poco más rápido:
- Reescribió cachés en línea;
- Hizo un arreglo manual (y luego automático) de demoras;
- Hicieron preparativos para las transiciones (mayor en el código): cuanto antes se prepare la transición, mejor;
- Recolector de basura incremental soportado
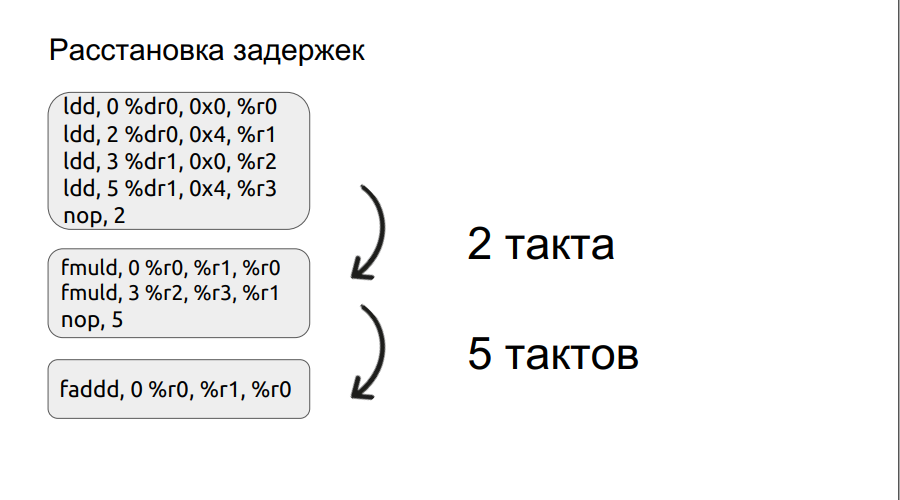
El segundo párrafo se detendrá en un poco más de detalle. Ya hemos examinado un pequeño ejemplo de trabajo con paquetes, y continuaremos con él.

Cualquier operación, por ejemplo, la carga, no se realiza en un ciclo, en este caso se realiza en tres ciclos. Por lo tanto, si queremos multiplicar dos números, ingresamos a la operación de multiplicación, pero los operandos mismos aún no se han cargado, el procesador solo puede esperar a que se carguen. Y esperará un cierto número de medidas, un múltiplo de cuatro. Pero si configura manualmente el retraso, el tiempo de espera puede reducirse, mejorando así el rendimiento. Además, el proceso de organización de los retrasos fue automatizado.
Resultados de la optimización BaseLine v1.0 vs Baseline v1.1. Claro, el motor se ha vuelto más rápido.

¿Cómo pueden los programadores no hacer una pistola de iones?
En la ola de éxito de la implementación de Baseline v1.1, se decidió portar el compilador de optimización Ion.

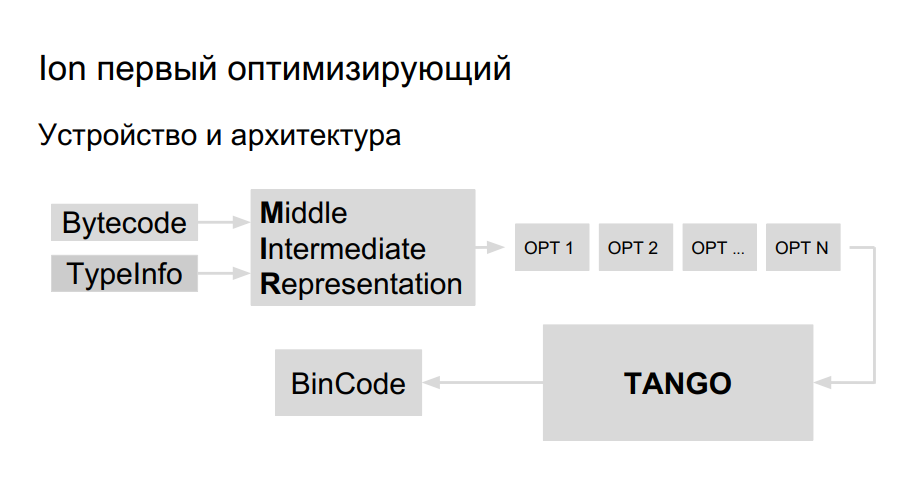
¿Cómo funciona el compilador de optimización? El código fuente se interpreta, se inicia la compilación. En el proceso de ejecución del código de bytes, Ion recopila datos sobre los tipos utilizados en el programa y el análisis de las "funciones activas", aquellas que se realizan con más frecuencia que otras. Después de eso, se decide compilarlos mejor, optimizarlos. A continuación, se construye una representación de alto nivel del compilador, un gráfico de operación. El gráfico está optimizado (opt 1, opt 2, opt ...), se crea una representación de bajo nivel, que consta de instrucciones de la máquina, se reservan registros, se genera un código binario directamente optimizado.
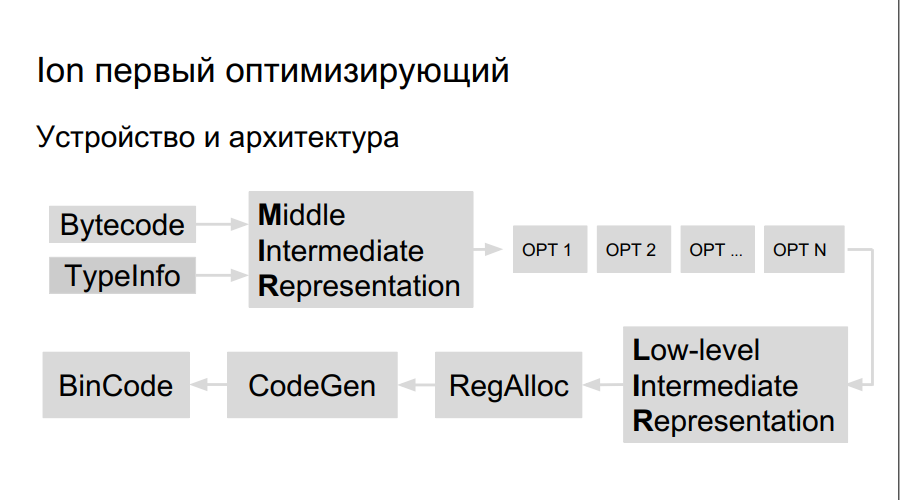
Hay más registros en Elbrus y los equipos en sí son grandes, por lo tanto, necesitamos:
- Team Planner
- Distribuidor de registro propio;
- LIR propio (Representación intermedia de bajo nivel);
- Código propio generador.
El equipo ya tenía experiencia en portar Java a Elbrus, decidieron usar la misma biblioteca para la generación de código para portar Ion. Ella se llama TANGO. Tiene:
- Team Planner
- Distribuidor de registro propio;
- Optimizaciones de bajo nivel.
Queda por introducir una representación de alto nivel en TANGO, para hacer un selector. El problema es que la vista de bajo nivel en TANGO es como ensamblador, que es difícil de mantener y depurar. ¿Cómo debería verse el compilador por dentro? Para una mejor comprensión, Mozilla creó su propio compilador HolyJit; también hay una opción para escribir su propio mini idioma para traducir entre una representación de alto nivel y de bajo nivel.
El desarrollo aún está en marcha. Bueno y más sobre cómo no exagerar con la optimización.
Parte 3. Lo mejor es enemigo de lo bueno
Compilación como es
El proceso de optimización en Ion, cuando el código se calienta y luego se compila y optimiza, es codicioso, esto se puede ver en el siguiente ejemplo.
function foo(a, b) {
return a + b;
}
function doSomeStuff(obj) {
for (let i = 0; i < 1100; ++i) {
print(foo(obj,obj));
}
}
doSomeStuff("HollyJS");
doSomeStuff({n:10});
JS Shell ( ), Mozilla, :

. , , - bailout (). , . foo object, , , . , :
function doSomeStuff(obj) {
for (let i=0; i < 1100; ++i) {
if (!(obj instanceof String))
print(foo_only_str(obj, obj));
}
}
, .
. , , DCE.
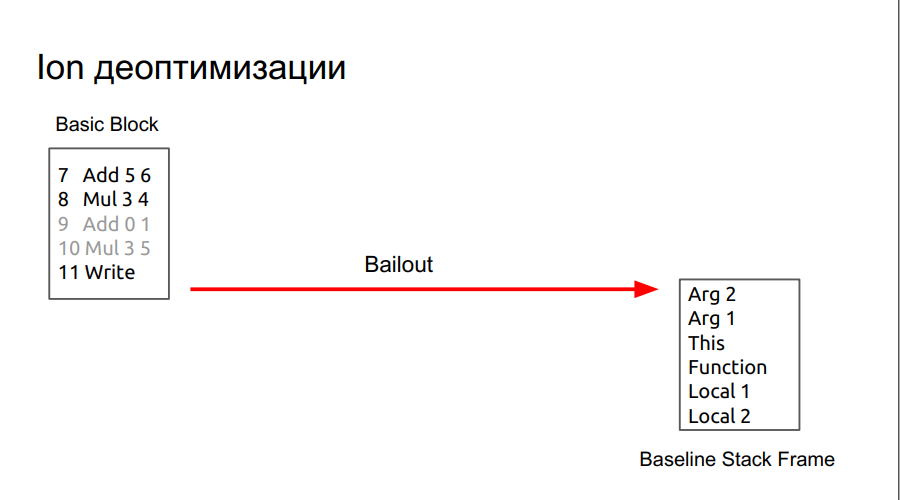
, , , .
, , , SpiderMonkey Resume Point. - , . , baseline . , runtime , . lowering, regAlloc, (snapshot), , . baseline .
:

runtime x86 : , . . , , , , , . , , Type . :
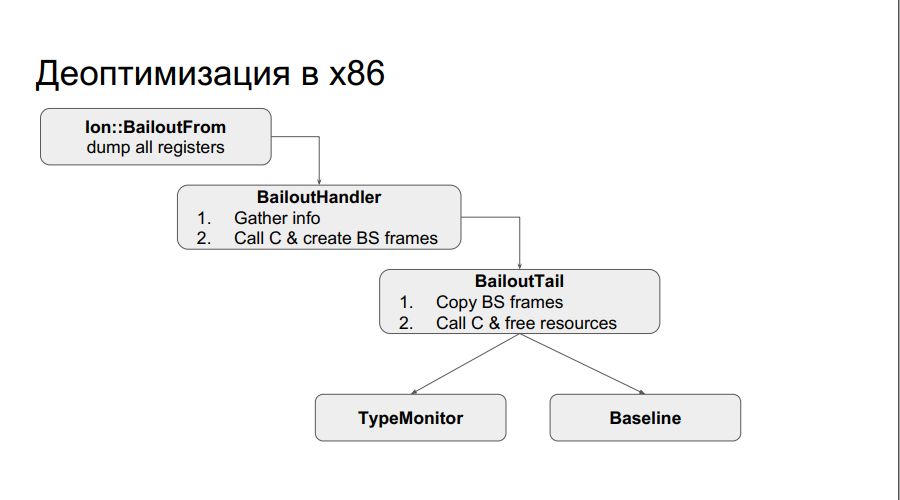
, , chain . , , .
: , chain-, N , , baseline, .
, .
:

Ion 4- baseline. :
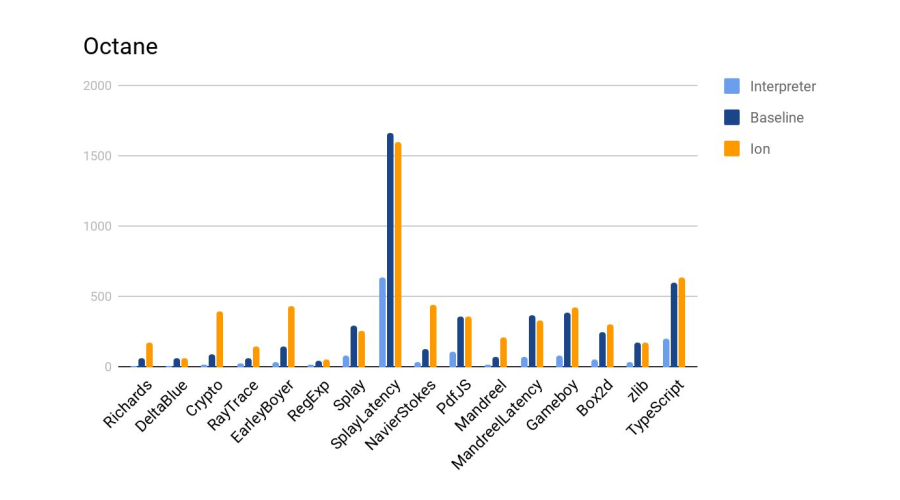
, , SpiderMonkey, V8 Node. — . .
. , , chain-.
, : 24-25 HolyJS, . — , .