La conocida transformación rápida de Fourier se ha utilizado durante mucho tiempo no solo para resolver problemas de procesamiento de señales digitales, reconocimiento de objetos en la imagen, sino también en gráficos por computadora. Jerry Tessendorf describió un
modelo matemático que le permite sintetizar las olas del océano y animarlas en tiempo real. Este modelo se basa en una FFT bidimensional.
Cuando me encargaron desarrollar una aplicación para un procesador DSP que visualizara el funcionamiento de una FFT, me di cuenta de que el modelado de ondas es perfecto para este propósito.

Modelo matemático de la ola
La idea básica de un modelo matemático de una onda se puede describir mediante la expresión:
mathbfH = FFT2D (
mathbf widetildeH ), FFT2D se denota como el operador de una FFT bidimensional.
mathbfH Es el campo de alturas de la superficie del agua (tamaño de matriz
n1xn2 donde
n1 y
n2 puede tomar valores de potencias de dos). Los elementos de esta matriz son las alturas de las olas.
mathbf widetildeH - señal (tamaño de matriz
n1xn2 ), generados según una determinada ley y en función del tiempo.
mathbf widetildeH= mathbf widetildeH0.∗ mathbfA+ overline mathbf widetildeH0.∗ overline mathbfA donde los elementos de la matriz
mathbfA es
$ en línea $ e ^ {iω_ {ij} t} = cos (ω_ {ij} t) + isin (ω_ {ij} t) $ en línea $ y la matriz
overline mathbfA - conjugado complejo a
mathbfA matriz
i=0,1,...n1,j=0,1,...n2ωij Son elementos matriciales
Large mathbfω .
.∗ - multiplicación matricial por elementos.
mathbf widetildeH0 - campo de alturas en el momento inicial del tiempo
t = 0.
overline mathbf widetildeH0 - conjugado complejo a
mathbf widetildeH0 matriz (tamaño
n1xn2 )
Para crear una animación del movimiento de las ondas en tiempo real, es necesario volver a calcular la matriz.
mathbf widetildeH y
mathbfH cambiando
t . Matrices
mathbf widetildeH0 ,
overline mathbf widetildeH0 y
Large mathbfω se calculan una vez y se reutilizan.
Ahora pasemos a la descripción del procesador DSP, que, según las fórmulas anteriores, debe ser capaz de:
- Calcule FFT.
- Multiplica matrices elemento por elemento.
- Agregar matrices.
- Calcular el vector de senos y cosenos.
Como procesador DSP, se utilizó 1879VM6Ya basado en la arquitectura NeuroMatrix, desarrollada por el "Módulo" del Centro Científico y Técnico CJSC. El circuito en la Figura 1.
El procesador contiene 2 núcleos operativos paralelos NMPU0 y NMPU1 (que funcionan a una frecuencia de 500 MHz), cada uno de los cuales tiene un procesador RISC y un coprocesador vectorial (NMCore FPU para coma flotante y NMCore INT para aritmética de enteros). El núcleo NMPU0 es para el procesamiento de datos de punto flotante, y NMPU1 es para datos enteros. NMPU0 tiene 8 bancos de SRAM interna (128 kB cada uno), y NMPU1 tiene 4 bancos (128 kB) de la misma memoria. En 1879VM6Ya, se instala un controlador DMA y una interfaz DDR2.
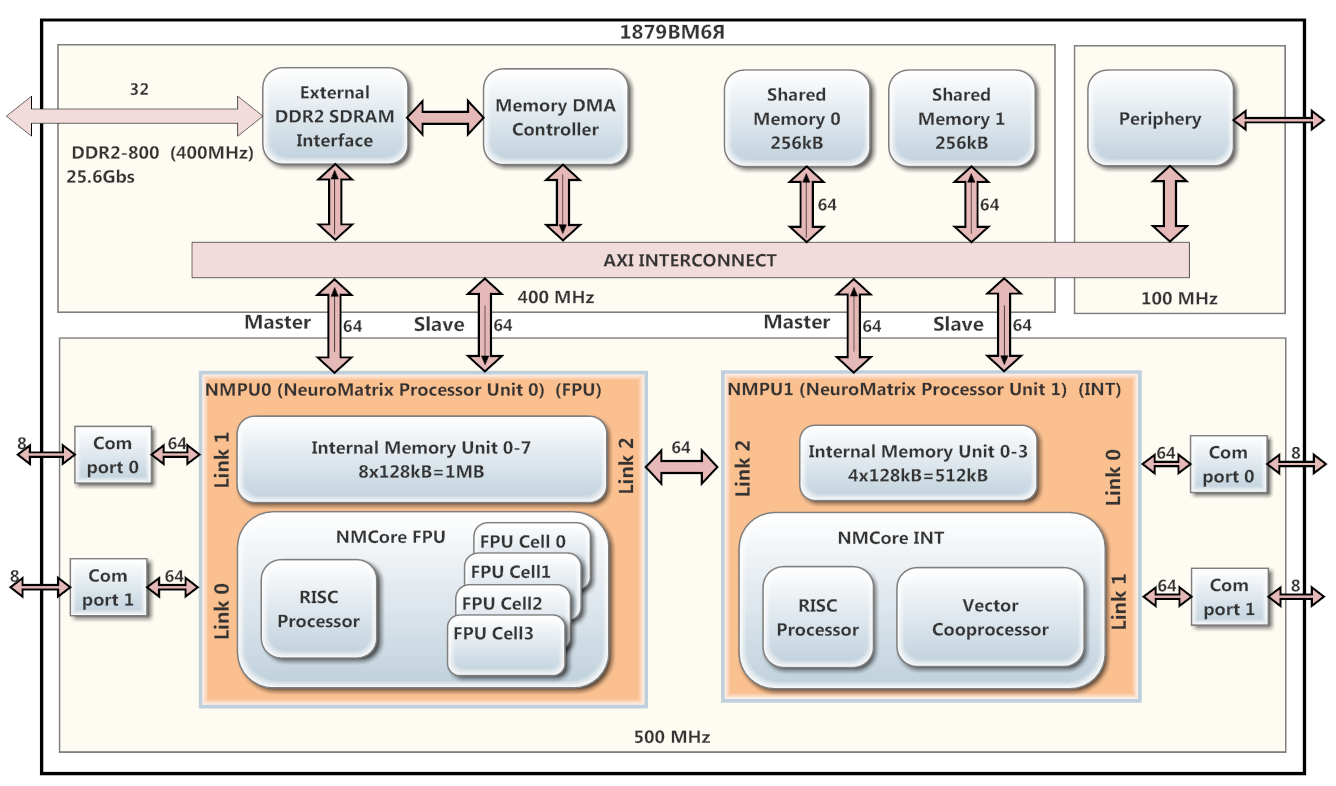 Fig. 1. Diagrama del procesador 1879VM6YA
Fig. 1. Diagrama del procesador 1879VM6YAEl procesador está ubicado en el módulo del instrumento MC121.01 (ver. Fig. 2). Este módulo también tiene 512 MB de memoria DDR2.
 Fig.2. MS121.01
Fig.2. MS121.01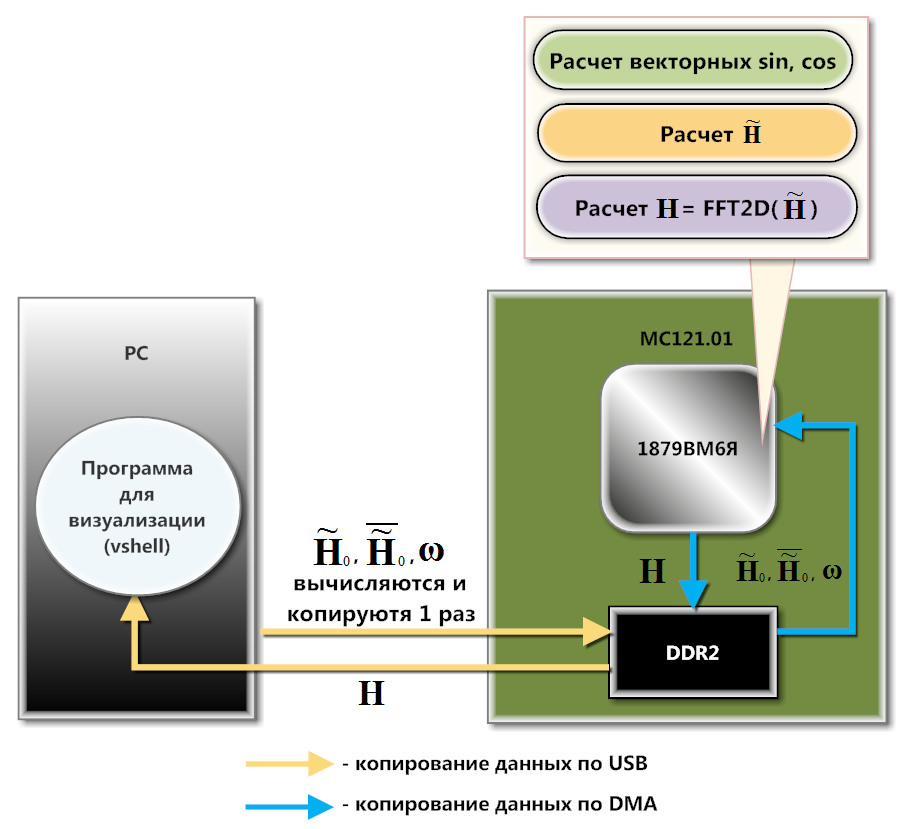 Fig. 3. Esquema de interacción de MC121.01 y PC
Fig. 3. Esquema de interacción de MC121.01 y PCMC121.01 interactúa con la PC a través de USB (diagrama en la Figura 3). A nivel de software, esta interacción se organiza utilizando la biblioteca de descarga e intercambio de datos, que forma parte del SDK de esta placa. Matrices precalculadas
mathbf widetildeH0 ,
overline mathbf widetildeH0 y
Large mathbfω se cargan en la memoria DDR2 a través de las funciones de la biblioteca de descarga e intercambio. Copias del controlador DMA
mathbf widetildeH0 ,
overline mathbf widetildeH0 y
Large mathbfω línea por línea en la memoria interna (SRAM) del procesador. La descarga a DDR2 se debe al hecho de que ninguna de estas matrices se ajusta completamente a SRAM. Aquí se realiza una copia línea por línea, porque 1879BM6Ya calcula a partir de SRAM más rápido que a partir de DDR2. Además, una parte importante de los cálculos se puede hacer en el contexto de la DMA.
Usando las funciones vectoriales de la biblioteca NMPP para calcular senos, cosenos, multiplicación y adición de vectores, el procesador calcula las filas de la matriz
mathbf widetildeH y toma la FFT unidimensional de ellos. El resultado es enviado por DMA a DDR2. Entonces, en DDR2 se forma una matriz intermedia, a partir de las columnas de las cuales el procesador calcula la FFT unidimensional (después de cargar las columnas de la matriz intermedia por DMA en SRAM). Por lo tanto, se forma una matriz en DDR2
mathbfH . Esta matriz se descarga a la PC para dibujar un solo cuadro con la imagen de la superficie de la onda. Para animar la imagen en tiempo real, debe calcular la matriz de acuerdo con el algoritmo descrito anteriormente
mathbfH aumentando el parámetro
t .
En la práctica, resulta que 1879M6 calcula la matriz
mathbfH más rápido que la PC lo desinfla. Debido a esto, el procesador puede estar inactivo, esperando que la PC recoja el próximo lote de datos. Fue posible resolver este problema usando un buffer de anillo (que contiene varias matrices
mathbfH ) organizado en la placa de memoria DDR2.
A nivel de software, trabaje con el controlador DMA y el buffer de anillo se realiza utilizando las funciones de biblioteca HAL (Nivel de abstracción de hardware) para procesadores NeuroMatrix.
Visualización de la superficie de las olas
Cuando el DEM
mathbfH cargado en la memoria de la PC, puede visualizar la superficie. Para mostrarlo más claramente, necesita coordinar x, y, z, describiendo puntos en la superficie, multiplicados por
la matriz de rotación . Entonces obtenemos las nuevas coordenadas de la superficie x ', y', z ', girándola en cierto ángulo.
Al escalar las nuevas coordenadas y conectar los puntos a lo largo de ellas con líneas rectas, puede ver la animación de las olas del océano (vea el video a continuación). Para la visualización de la superficie, la biblioteca solía mostrar la imagen en la pantalla de vshell.
Conclusión
En conclusión, quiero decir que el cálculo y la transmisión a través de USB de una matriz
mathbfH con un tamaño de 256x256 números flotantes, se gastan ~ 4.7 millones de ciclos de reloj (72 ciclos de reloj por flotante). La velocidad de fotogramas es ~ 107. Si no tiene en cuenta el tiempo necesario para transferir datos a través de USB, los cálculos costarán ~ 2.5 millones de ciclos (38 ciclos por flotación). Este es el tiempo total empleado por el procesador 1879M6 en la multiplicación por elementos y la adición de matrices, cálculo de FFT, senos, cosenos y copia usando DMA. Estos cálculos se realizan en el contexto de la transferencia de datos USB.
La diferencia de 2,2 millones de ciclos de reloj (4,7 millones - 2,5 millones = 2,2 millones) indica que en el sistema PC-MC121.01 USB es un "cuello de botella", y 1879VM6YA se puede cargar con los cálculos en un 46% más sin recibir Drawdown FPS.
También me gustaría señalar que en el contexto de la transferencia de datos USB y los cálculos en un coprocesador para un punto flotante, se puede usar un coprocesador para aritmética de enteros, que no se usó en esta tarea.
La tabla muestra el rendimiento de algunas funciones vectoriales de la biblioteca nmpp.
| Función | Bares |
|---|
| FFT unidimensional, 256 puntos | 1770 |
| Seno, 256 puntos | 1400 |
| Coseno, 256 puntos | 1400 |
Referencias
NMPP: una biblioteca de primitivas para la arquitectura NeuroMatrixHAL - Biblioteca de abstracción dependiente del hardware NeuroMatrixVSHELL - procesamiento de imágenes y biblioteca de visualización