¿Se te ocurrió la idea de volver a escribir tu audaz aplicación empresarial desde cero? Si desde cero, entonces es wow. Al menos dos veces menos código, ¿verdad? Pero pasarán un par de años, y también crecerá, se convertirá en legado ... no hay mucho tiempo y dinero para reescribirlo a la perfección.
Cálmate, las autoridades aún no permitirán reescribir nada. Queda por refactorizar. ¿Cuál es la mejor manera de gastar sus pequeños recursos? ¿Cómo refactorizar dónde limpiar?
El título de este artículo incluye una referencia al libro
"Arquitectura limpia" del tío Bob, y fue realizado sobre la base de un maravilloso informe de Victor Rentea (
twitter ,
sitio web ) en JPoint (bajo el gato comenzará a hablar en primera persona, pero por ahora lea el introductorio). Leyendo libros inteligentes, este artículo no reemplaza, pero para una descripción tan breve se expone muy bien.
La idea es que cosas populares como "Arquitectura limpia" son realmente útiles. Sorpresa Si necesita resolver un problema muy específico, un código simple y elegante no requiere un esfuerzo adicional y una ingeniería excesiva. La arquitectura pura dice que necesita proteger su modelo de dominio de los efectos externos, y le dice exactamente cómo se puede hacer esto. Un enfoque evolutivo para aumentar el volumen de microservicios. Pruebas que hacen que la refactorización sea menos aterradora. ¿Ya sabes todo esto? O lo sabes, pero tienes miedo de pensarlo, porque es un horror ¿qué tendrás que hacer entonces?
¿Quién quiere obtener una píldora mágica contra la procrastinación que ayudará a dejar de temblar y comenzar a refactorizar? Bienvenido a la grabación de video del informe o en cat.
Mi nombre es Victor, soy de Rumania. Formalmente, soy consultor, experto técnico y arquitecto principal en la rumana IBM. Pero si me pidieron que diera una definición de mi actividad, entonces soy un evangelista de código puro. Me encanta crear un código hermoso, limpio y compatible; por regla general, hablo de esto en los informes. Aún más, me inspira la enseñanza: capacitar a los desarrolladores en los campos de Java EE, Spring, Dojo, Test Driven Development, Java Performance, así como en el campo del evangelismo mencionado: los principios de los patrones de código limpio y su desarrollo.
La experiencia en la que se basa mi teoría es principalmente el desarrollo de aplicaciones empresariales para el mayor cliente de IBM en Rumania: el sector bancario.
El plan para este artículo es el siguiente:
- Modelado de datos: las estructuras de datos no deberían convertirse en nuestros enemigos;
- Organización de la lógica: el principio de "descomposición del código, que es demasiado";
- "Onion" es la arquitectura de filosofía Transaction Script más pura;
- Pruebas como una forma de lidiar con los temores de los desarrolladores.
Pero primero, recordemos los principios principales que nosotros, como desarrolladores, debemos recordar siempre.
Principio de responsabilidad exclusiva

En otras palabras, cantidad vs calidad. Como regla general, cuanta más funcionalidad contenga su clase, peor resultará en un sentido cualitativo. Al desarrollar clases grandes, el programador comienza a confundirse, cometer errores en la creación de dependencias y el código grande, entre otras cosas, es más difícil de depurar. Es mejor dividir esa clase en varias más pequeñas, cada una de las cuales será responsable de alguna subtarea. Es mejor tener unos pocos módulos estrechamente acoplados que uno: grande y lento. La modularidad también permite la reutilización de la lógica.
Enlace débil del módulo

El grado de enlace es una medida de qué tan cerca interactúan sus módulos entre sí. Muestra cuán ampliamente puede propagarse el efecto de los cambios que realice en cualquier punto del sistema. Cuanto mayor sea el enlace, más difícil será hacer modificaciones: cambia algo en un módulo y el efecto se extiende mucho y no siempre de la manera esperada. Por lo tanto, el indicador de enlace debe ser lo más bajo posible; esto proporcionará más control sobre el sistema que está sufriendo modificaciones.
No repetir

Sus propias implementaciones pueden ser buenas hoy, pero no tan buenas mañana. No se permita copiar sus propias mejores prácticas y así distribuirlas en una base de código. Puede copiar desde StackOverflow, desde libros, desde cualquier fuente autorizada que (como sabe con certeza) ofrece una implementación ideal (o similar). Mejorar su propia implementación, que ocurre más de una vez, pero multiplicada por toda la base del código, puede ser muy agotador.
Sencillez y concisión

En mi opinión, este es el principio principal que debe observarse en la ingeniería y el desarrollo de software. "La encapsulación prematura es la raíz del mal", dijo Adam Bien. En otras palabras, la raíz del mal radica en la "reingeniería". El autor de la cita, Adam Bien, en un momento se ocupó de tomar aplicaciones heredadas y, reescribiendo completamente su código, recibió una base de código 2-3 veces más pequeña que la original. ¿De dónde viene tanto código extra? Después de todo, surge por una razón. Sus temores nos dan origen. Nos parece que al acumular una gran cantidad de patrones, generando indirectas y abstracciones, brindamos protección a nuestro código, protección contra las incógnitas del mañana y los requisitos del mañana. Después de todo, de hecho, hoy no necesitamos nada de esto, inventamos todo esto solo por el bien de algunas "necesidades futuras". Y es posible que estas estructuras de datos interfieran posteriormente. Para ser honesto, cuando algunos de mis desarrolladores se me acercan y me dicen que se le ocurrió algo interesante que se puede agregar al código de producción, siempre respondo de la misma manera: "Chico, esto no te será útil".
No debe haber mucho código, y el que debe ser simple debe ser la única forma de trabajar normalmente con él. Esto es una preocupación para sus desarrolladores. Debe recordar que son las figuras clave para su sistema. Intenta reducir su consumo de energía, reducir los riesgos con los que tendrán que trabajar. Esto no significa que tenga que crear su propio marco, además, no le aconsejaría que haga esto: siempre habrá errores en su marco, todos deberán estudiarlo, etc. Es mejor usar los activos existentes, de los cuales hay una masa hoy. Estas deberían ser soluciones simples. Escriba los manejadores de errores globales, aplique tecnología de aspecto, generadores de código, extensiones Spring o CDI, configure los ámbitos de Solicitud / Hilo, use la manipulación y generación de bytecode sobre la marcha, etc. Todo esto será su contribución a lo verdaderamente más importante: la comodidad de su desarrollador.
En particular, me gustaría demostrarle la aplicación de las áreas de Solicitud / Hilo. He visto repetidamente cómo esto simplificaba increíblemente las aplicaciones empresariales. La conclusión es que le da la oportunidad, como usuario registrado, de guardar los datos de RequestContext. Por lo tanto, RequestContext almacenará los datos del usuario en forma compacta.

Como puede ver, la implementación solo requiere un par de líneas de código. Después de escribir la solicitud en la anotación requerida (no es difícil hacerlo si usa Spring o CDI), se liberará de la necesidad de pasar el inicio de sesión del usuario a los métodos y lo que sea: los metadatos de la solicitud almacenados dentro del contexto navegarán de forma transparente por la aplicación. El proxy con alcance le permitirá acceder a los metadatos de la solicitud actual en cualquier momento.
Pruebas de regresión

Los desarrolladores tienen miedo de los requisitos actualizados porque tienen miedo de refactorizar los procedimientos (modificaciones de código). Y la forma más fácil de ayudarlos es crear un conjunto de pruebas confiable para las pruebas de regresión. Con él, el desarrollador tendrá la oportunidad en cualquier momento de probar su tiempo de funcionamiento, para asegurarse de que no rompa el sistema.
El desarrollador no debe tener miedo de romper nada. Debe hacer todo para que la refactorización se perciba como algo bueno.
La refactorización es un aspecto crítico del desarrollo. Recuerde, exactamente en el momento en que sus desarrolladores tienen miedo de refactorizar, se puede considerar que la aplicación se ha convertido en Legacy.
¿Dónde implementar la lógica de negocios?
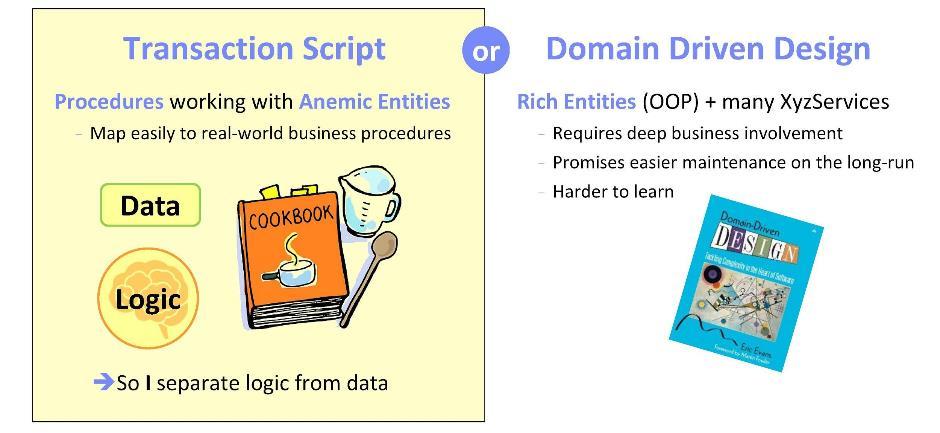
Al comenzar la implementación de cualquier sistema (o componentes del sistema), nos hacemos la pregunta: ¿dónde es mejor implementar la lógica de dominio, es decir, los aspectos funcionales de nuestra aplicación? Hay dos enfoques opuestos.
El primero se basa en la filosofía de
Transaction Script . Aquí, la lógica se implementa en procedimientos que funcionan con
entidades anémicas (es decir, con estructuras de datos). Tal enfoque es bueno porque en el curso de su implementación es posible confiar en las tareas comerciales formuladas. Mientras trabajaba en aplicaciones para el sector bancario, he observado repetidamente la transferencia de procedimientos comerciales a software. Puedo decir que es realmente muy natural correlacionar escenarios con software.
Un enfoque alternativo es utilizar los principios del
diseño impulsado por dominio . Aquí deberá correlacionar las especificaciones y los requisitos con una metodología orientada a objetos. Es importante considerar cuidadosamente los objetos y garantizar una buena participación empresarial. La ventaja de los sistemas diseñados de esta manera es que en el futuro se mantendrán fácilmente. Sin embargo, en mi experiencia, dominar esta metodología es bastante difícil: te sentirás más o menos valiente no antes de seis meses de estudiarlo.
Para mis desarrollos, siempre elegí el primer enfoque. Les puedo asegurar que en mi caso funcionó perfectamente.
Modelado de datos
Entidades
¿Cómo modelamos los datos? Tan pronto como la aplicación tome tamaños más o menos decentes, necesariamente aparecerán
datos persistentes . Este es el tipo de datos que necesita almacenar más tiempo que el resto: son las
entidades de dominio de su sistema. No importa dónde almacenarlos, ya sea en la base de datos, en un archivo o administrando directamente la memoria. Lo importante es
cómo los almacenará, en qué estructuras de datos.

Esta opción se le otorga como desarrollador, y depende solo de usted si estas estructuras de datos funcionarán para usted o en su contra al implementar requisitos funcionales en el futuro. Para que todo sea bueno, debe implementar entidades colocando en ellas granos de
lógica de dominio reutilizada . ¿Cómo específicamente? Demostraré varios métodos usando un ejemplo.

Veamos qué le proporcioné a la entidad Cliente. En primer lugar, implementé un
getFullName() sintético getFullName() que me devolverá la concatenación de firstName y lastName. También implementé el método
activate() para monitorear el estado de mi entidad, encapsulando así. En este método, coloqué, en primer lugar, una
operación de validación y, en segundo lugar,
asigné valores al estado y a los
campos activados, por lo que no es necesario configurarlos. También agregué a la entidad Cliente los
isActive() y
canPlaceOrders() , que implementan la validación lambda dentro de mí. Esto se llama encapsulación de predicados. Dichos predicados son útiles si usa filtros Java 8: puede pasarlos como argumentos a los filtros. Te aconsejo que uses estos ayudantes.
Quizás esté utilizando algún tipo de ORM como Hibernate. Supongamos que tiene dos entidades con comunicación bidireccional. La inicialización debe realizarse en ambos lados, de lo contrario, como comprenderá, tendrá problemas al acceder a estos datos en el futuro. Pero los desarrolladores a menudo olvidan inicializar un objeto de una de las partes. Al desarrollar estas entidades, puede proporcionar métodos especiales que garanticen la inicialización bidireccional. Echa un vistazo a
addAddress() .

Como puede ver, esta es una entidad muy común. Pero en su interior yace la lógica del dominio. Tales entidades no deben ser escasas y superficiales, pero no deben ser abrumadas por la lógica. El desbordamiento con la lógica ocurre con mayor frecuencia: si decide implementar toda la lógica en el dominio, entonces, para cada caso de uso, será tentador implementar algún método específico. Como regla, hay muchos casos de uso. No recibirá una entidad, sino una gran pila de todo tipo de lógica. Intente observar la medida aquí: solo la
lógica reutilizada se coloca en el dominio y solo
en una pequeña cantidad.
Objetos de valor
Además de las entidades, lo más probable es que también necesite valores de objeto. Esto no es más que una forma de agrupar datos de dominio para que luego pueda moverlos juntos por el sistema.
El objeto de valor debe ser:
- Pequeño . ¡Sin
float para variables monetarias! Tenga cuidado al elegir los tipos de datos. Cuanto más compacto sea su objeto, más fácil será para un nuevo desarrollador descubrirlo. Esta es la base para una vida cómoda.
- Inmutable Si el objeto es realmente inmutable, entonces el desarrollador puede estar tranquilo de que su objeto no cambiará su valor y no se romperá después de la creación. Esto sienta las bases para un trabajo tranquilo y seguro.

Y si agrega una llamada al método
validate() al constructor, el desarrollador podrá calmarse por la validez de la entidad creada (al pasar, por ejemplo, una moneda inexistente o una cantidad negativa de dinero, el constructor no funcionará).
La diferencia entre una entidad y un objeto de valor
Los objetos de valor difieren de las entidades en que no tienen una ID fija. Las entidades siempre tendrán campos asociados con la clave externa de alguna tabla (u otro almacenamiento). Los objetos de valor no tienen tales campos. Surge la pregunta: ¿son diferentes los procedimientos para verificar la igualdad de dos objetos de valor y dos entidades? Como los objetos de valor no tienen un campo ID, para concluir que dos de estos objetos son iguales, debe comparar los valores de todos sus campos en pares (es decir, examinar todos los contenidos). Al comparar entidades, es suficiente hacer una sola comparación, por ID de campo. Es en el procedimiento de comparación donde radica la principal diferencia entre entidades y objetos de valor.
Objetos de transferencia de datos (DTO)

¿Cuál es la interacción con la interfaz de usuario (IU)? Debe pasarle los
datos para que se le muestren . ¿Realmente necesitarás otra estructura? Así es Y todo porque la interfaz de usuario no es para nada tu amiga. Tiene sus propias solicitudes: necesita que los datos se almacenen de acuerdo con la forma en que se deben mostrar. Esto es tan maravilloso, que a veces son las interfaces de usuario y sus desarrolladores las que nos requieren. Luego necesitan obtener datos para cinco filas; entonces se les ocurre crear un campo booleano
isDeletable para el objeto (¿puede el objeto tener ese campo en principio?) para saber si el botón Eliminar está activo o no. Pero no hay nada que indignarse. Las interfaces de usuario simplemente tienen diferentes requisitos.
La pregunta es, ¿se les puede confiar a nuestras entidades para su uso? Lo más probable es que los cambien, y de la manera más indeseable para nosotros. Por lo tanto, les proporcionaremos algo más:
objetos de transferencia de datos (DTO). Se adaptarán especialmente a los requisitos externos y a una lógica diferente a la nuestra. Algunos ejemplos de estructuras DTO son: Formulario / Solicitud (proveniente de la interfaz de usuario), Vista / Respuesta (enviada a la interfaz de usuario), Criterios de búsqueda / Resultado de búsqueda, etc. En cierto sentido, puede llamar a esto un modelo API.
Primer principio importante: el DTO debe contener un mínimo de lógica.
Aquí hay un ejemplo de implementación de
CustomerDto .
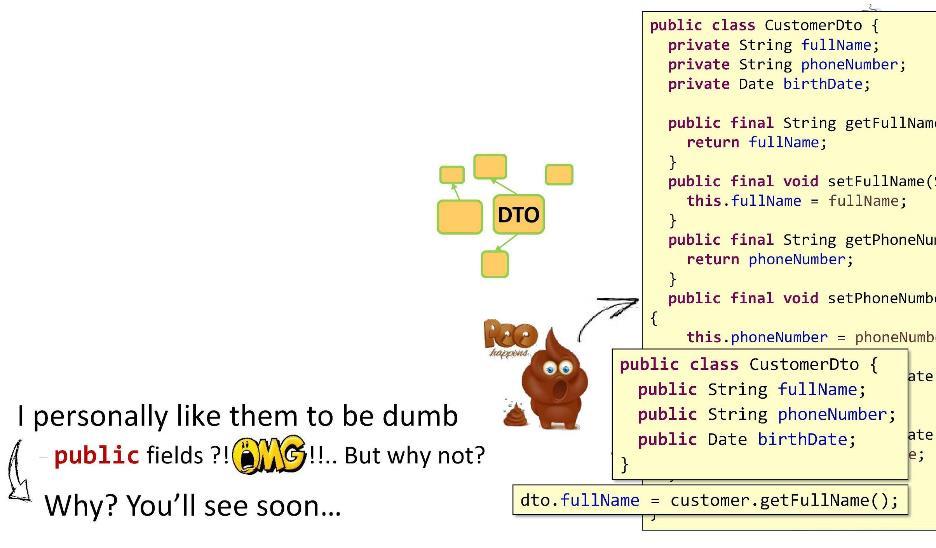
Contenido: campos
privados , captadores
públicos y setters para ellos. Todo parece estar super. OOP en todo su esplendor. Pero una cosa es mala: en forma de captadores y establecedores, he implementado demasiados métodos. En DTO, debe haber la menor lógica posible. ¿Y entonces cuál es mi salida? ¡Hago públicos los campos! Dirás que esto funciona mal con las referencias de métodos de Java 8, que habrá limitaciones, etc. Pero, créanlo o no, hice todos mis proyectos (10-11 piezas) con tales DTO. Hermano esta vivo. Ahora, dado que mis campos son públicos, puedo establecer fácilmente el valor en
dto.fullName simplemente poniendo un signo igual. ¿Qué podría ser más hermoso y más simple?
Organización lógica
Mapeo
Entonces, tenemos una tarea: necesitamos transformar nuestras entidades en DTO. Implementamos la transformación de la siguiente manera:
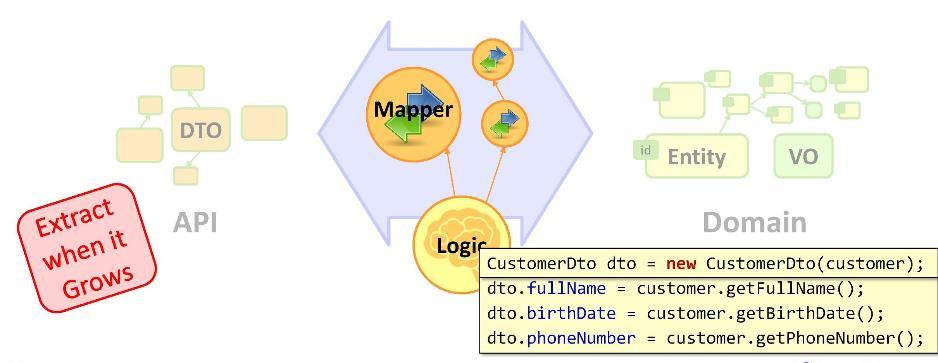
Como puede ver, al declarar un DTO, pasamos a las operaciones de mapeo (asignación de valor). ¿Necesito ser un desarrollador senior para escribir tareas regulares en esos números? Para algunos, esto es tan inusual que comienzan a cambiar sus zapatos sobre la marcha: por ejemplo, copiar datos utilizando algún tipo de marco de mapeo utilizando la reflexión. Pero se pierden lo principal: que tarde o temprano, la interfaz de usuario interactuará con el DTO, como resultado de lo cual la entidad y el DTO divergen en sus significados.
Uno podría, por ejemplo, poner operaciones de mapeo en el constructor. Pero esto no es posible para ningún mapeo; en particular, el diseñador no puede acceder a la base de datos.
Por lo tanto, nos vemos obligados a dejar las operaciones de mapeo en la lógica empresarial. Y si tienen una apariencia compacta, entonces no hay nada de qué preocuparse. Si el mapeo no toma un par de líneas, sino más, entonces es mejor colocarlo en el llamado
mapeador . Un mapeador es una clase diseñada específicamente para copiar datos. Esto, en general, es cosa antediluviana y repetitiva. Pero luego, detrás de ellos, puede ocultar nuestras muchas tareas, para que el código sea más limpio y delgado.
Recuerde: un
código que ha crecido demasiado debe moverse a una estructura separada . En nuestro caso, las operaciones de mapeo fueron realmente un poco demasiado, por lo que las trasladamos a una clase separada: el mapeador.
¿Deberían los mapeadores permitir el acceso a la base de datos? Puede habilitarlo de forma predeterminada; esto a menudo se hace por razones de simplicidad y pragmatismo. Pero te expone a ciertos riesgos.
Ilustraré con un ejemplo. Basado en el DTO existente, creamos la entidad del
Customer .
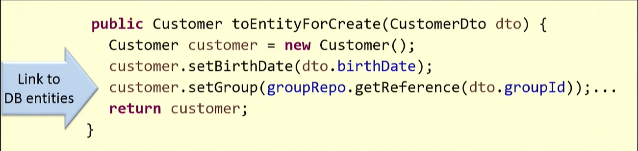
Para el mapeo, necesitamos obtener un enlace al grupo de clientes desde la base de datos. Entonces ejecuto el método
getReference() , y me devuelve alguna entidad. Lo más probable es que la solicitud vaya a la base de datos (en algunos casos esto no sucede y la función de código auxiliar funciona).
Pero el problema no nos espera aquí, sino en el método que realiza la operación inversa: transformar la entidad en DTO.

Usando un bucle, revisamos todas las direcciones asociadas con el Cliente existente y las traducimos a direcciones DTO. Si usa ORM, entonces, probablemente, cuando llame al método
getAddresses() , se realizará una carga diferida. Si no utiliza ORM, esta será una solicitud abierta para todos los hijos de este padre. Y aquí corres el riesgo de sumergirte en el "problema N + 1". Por qué
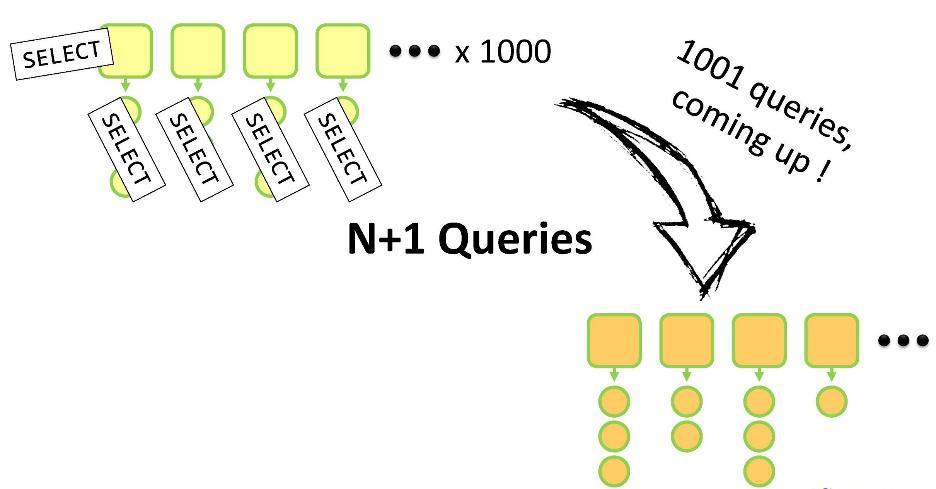
Tienes un conjunto de padres, cada uno de los cuales tiene hijos. Para todo esto, debe crear sus propios análogos dentro del DTO. Deberá realizar una consulta
SELECT para atravesar N entidades principales y luego N consultas
SELECT para recorrer los elementos secundarios de cada una de ellas. Solicitud total de N + 1. Para 1000 entidades de
Customer principales, dicha operación tomará entre 5 y 10 segundos, lo que, por supuesto, lleva mucho tiempo.
Supongamos que, sin embargo, nuestro método
CustomerDto() se llama dentro del bucle, convirtiendo la lista de objetos Customer en la lista CustomerDto.
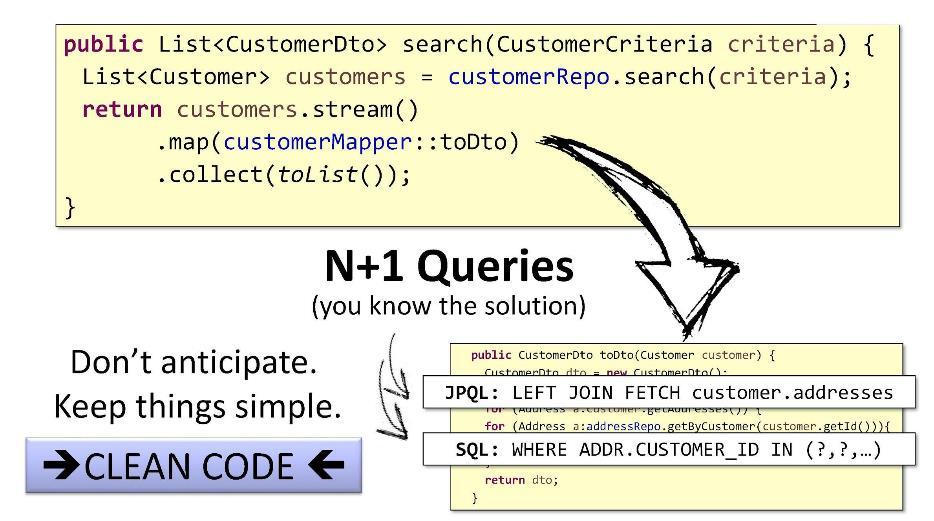
El problema con las consultas N + 1 tiene soluciones estándar simples: en
JPQL puede usar
FETCH by customer.addresses para recuperar hijos y luego conectarlos usando
JOIN , y en SQL puede usar el bypass
IN y la
WHERE .
Pero lo haría de manera diferente. Puede averiguar cuál es la longitud máxima de la lista de hijos (esto se puede hacer, por ejemplo, en base a una búsqueda con paginación). Si la lista contiene solo 15 entidades, entonces solo necesitamos 16 consultas. En lugar de 5 ms, gastaremos en todo, digamos, 15 ms; el usuario no notará la diferencia.
Acerca de la optimización
No le recomendaría que revise el rendimiento del sistema en la etapa inicial de desarrollo. Como dijo Donald Knud: "La optimización prematura es la raíz del mal". No puede optimizar desde el principio. Esto es exactamente lo que debe dejarse para más adelante. Y lo que es especialmente importante:
sin supuestos, ¡solo mediciones y evaluación de mediciones!¿Estás seguro de que eres competente y de que eres un verdadero experto? Sé humilde al evaluarte a ti mismo. No piense que comprende la JVM hasta que lea al menos un par de libros sobre la compilación JIT. Sucede que los mejores programadores de nuestro equipo se me acercan y me dicen que
piensan que han encontrado una implementación más eficiente. Resulta que nuevamente inventaron algo que solo complica el código. Entonces respondo una y otra vez: YAGNI. No lo necesitamos
A menudo, para aplicaciones empresariales, no se requiere optimización de algoritmos. El cuello de botella para ellos, por regla general, no es la compilación y no en lo que respecta al procesador, sino todo tipo de operaciones de entrada-salida. Por ejemplo, al leer un millón de filas de una base de datos, escrituras voluminosas en un archivo, interacción con sockets.
Con el tiempo, comenzará a comprender qué cuellos de botella contiene el sistema y, reforzando todo con mediciones, comenzará a optimizar gradualmente. Por ahora, mantenga el código lo más limpio posible. Encontrará que dicho código es mucho más fácil de optimizar aún más.
Prefiere la composición sobre la herencia
De vuelta a nuestro DTO. Supongamos que definimos un DTO como este:

Es posible que lo necesitemos en muchos flujos de trabajo. Pero estos flujos son diferentes y, muy probablemente, cada caso de uso asumirá un grado diferente de relleno de campo. Por ejemplo, obviamente necesitaremos crear un DTO antes que cuando tengamos información completa del usuario. Puede dejar temporalmente los campos en blanco. Pero cuantos más campos ignore, más querrá crear un nuevo DTO más estricto para este caso de uso.
Alternativamente, puede crear copias de un DTO excesivamente grande (en la cantidad de casos de uso disponibles) y luego eliminar campos adicionales para cada copia. Pero para muchos programadores, en virtud de su inteligencia y alfabetización, realmente duele presionar Ctrl + V. El axioma dice que copiar y pegar es malo.
Puede recurrir al principio de
herencia conocido en la teoría OOP: simplemente defina un DTO básico y cree un heredero para cada caso de uso.
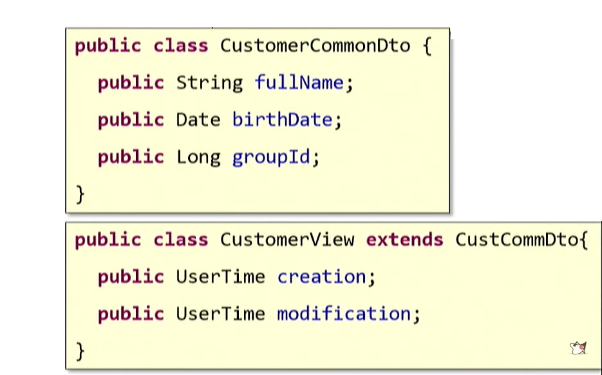
Un principio bien conocido es: "Prefiero la composición sobre la herencia". Lea lo que dice:
"se extiende" . Parece que deberíamos haber "expandido" la clase fuente. Pero si lo piensa, lo que hemos hecho no es "expansión" en absoluto. Esta es la verdadera "repetición": la misma vista lateral de copiar y pegar. Por lo tanto, no usaremos la herencia.
Pero entonces, ¿qué deberíamos ser? ¿Cómo ir a la composición? Hagámoslo de esta manera: escriba un campo en CustomerView que apunte al objeto del DTO subyacente.
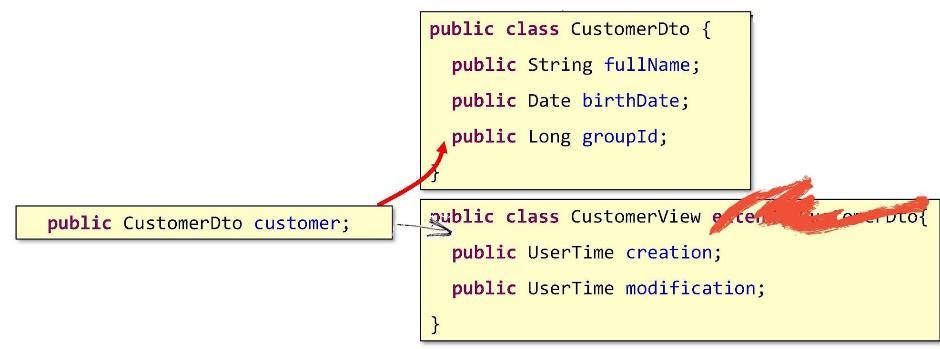
Por lo tanto, nuestra estructura base estará anidada en su interior. Así es como sale la composición real.
Ya sea que usemos la herencia o resolvamos el problema por composición, todos estos son detalles, sutilezas que surgieron profundamente en el curso de nuestra implementación. Son muy
frágiles . ¿Qué significa frágil? Eche un vistazo de cerca a este código:

La mayoría de los desarrolladores a quienes les mostré esto inmediatamente dijeron que el número "2" se repite, por lo que debe eliminarse como una constante. No notaron que la deuce en los tres casos tiene un significado completamente diferente (o "valor comercial") y que su repetición no es más que una coincidencia. Poner un dos en una constante es una decisión legítima, pero muy frágil. Intenta no permitir la lógica frágil en el dominio. Nunca trabaje desde allí con estructuras de datos externas, en particular, con DTO.
Entonces, ¿por qué el trabajo de eliminar la herencia e introducir la composición es inútil? Precisamente porque creamos DTO no para nosotros, sino para un cliente externo. Y cómo la aplicación cliente analizará el DTO recibido de usted, solo puede adivinar. Pero obviamente, esto tendrá poco que ver con su implementación. Los desarrolladores, por otro lado, pueden no hacer una distinción para los DTO básicos y no básicos que usted ha pensado cuidadosamente; probablemente usan la herencia, y quizás copiar y pegar estúpidamente eso es todo.
Fachadas

Volvamos a la imagen general de la aplicación. Le recomendaría que implemente la lógica de dominio a través del
patrón Fachada , expandiendo las fachadas con
los servicios de dominio según sea necesario. Se crea un servicio de dominio cuando se acumula demasiada lógica en la fachada, y es más conveniente colocarlo en una clase separada.
Sus servicios de dominio necesariamente deben hablar el idioma de su modelo de dominio (sus entidades y objetos de valor). En ningún caso deberían funcionar con DTO, porque DTO, como recordará, son estructuras que cambian constantemente en el lado del cliente, demasiado frágiles para un dominio.
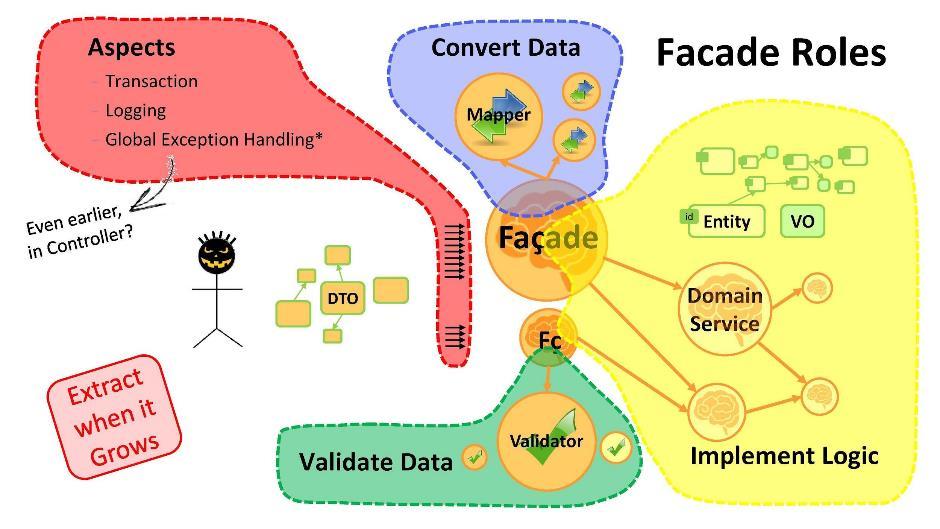
¿Cuál es el propósito de la fachada?
- Conversión de datos. Si tenemos entidades de un extremo y DTO del otro, es necesario llevar a cabo transformaciones de uno a otro. Y esto es lo primero para lo que son las fachadas. Si el procedimiento de conversión ha crecido en volumen, use las clases de mapeador.
- La implementación de la lógica. En la fachada, comenzará a escribir la lógica principal de la aplicación. Tan pronto como se convierta en mucho, tome parte en el servicio de dominio.
- Validación de datos. Recuerde que cualquier dato recibido del usuario es, por definición, incorrecto (que contiene errores). La fachada tiene la capacidad de validar datos. Estos procedimientos, cuando se excede el volumen, generalmente se llevan a los validadores .
- Aspectos Puede ir más allá y hacer que cada caso de uso atraviese su fachada. Luego resultará agregar cosas como transacciones, registros, manejadores de excepciones globales a los métodos de fachada. Observo que es muy importante tener manejadores de excepciones globales en cualquier aplicación que detecte todos los errores que otros manejadores no detectan. Ayudarán enormemente a sus programadores, les darán tranquilidad y libertad de acción.
Descomposición de mucho código
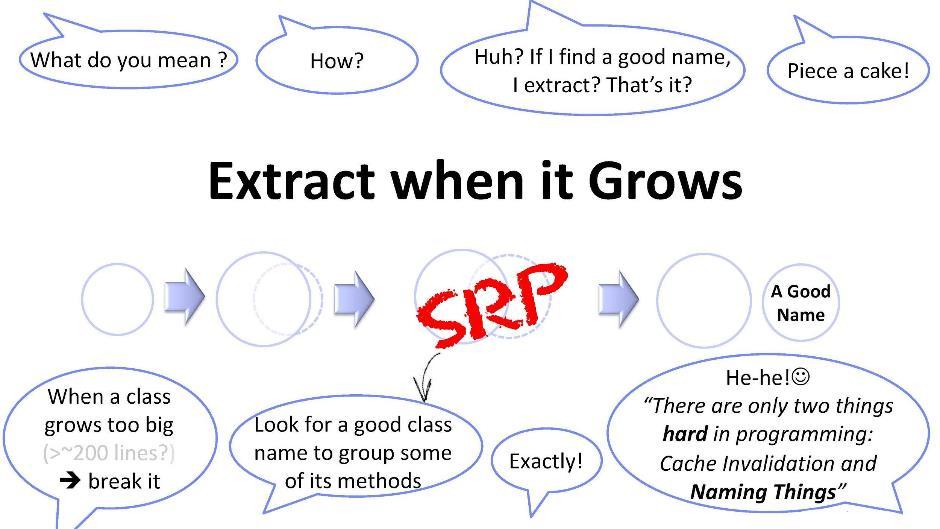
Algunas palabras más sobre este principio. Si la clase ha alcanzado algún tamaño inconveniente para mí (por ejemplo, 200 líneas), entonces debería tratar de romperlo en pedazos. Pero aislar una nueva clase de una existente no siempre es fácil. Necesitamos encontrar algunas formas universales. Uno de estos métodos es buscar nombres: está tratando de encontrar un nombre para un subconjunto de los métodos de su clase. Tan pronto como logre encontrar un nombre, no dude en crear una nueva clase. Pero esto no es tan simple. En programación, como saben, solo hay dos cosas complejas: esto es invalidar el caché e inventar nombres. En este caso, inventar un nombre implica identificar una subtarea: ocultar y, por lo tanto, no haber sido identificado previamente por nadie.
Un ejemplo:
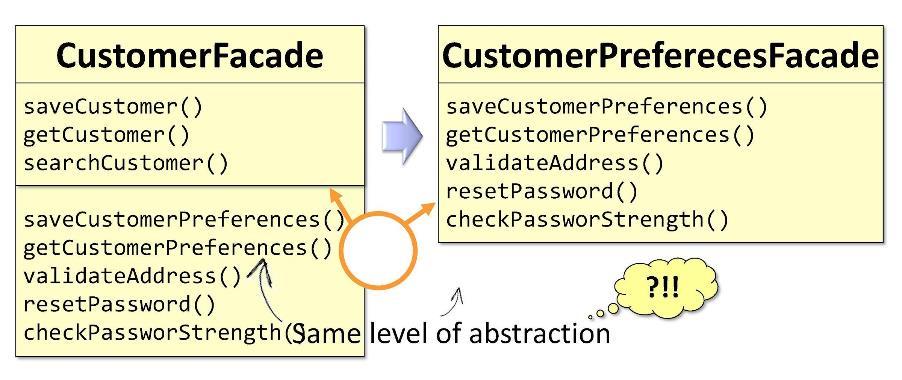
En la fachada original de
CustomerFacade algunos de los métodos están directamente relacionados con el cliente y otros con las preferencias del cliente. En base a esto, podré dividir la clase en dos cuando alcance tamaños críticos. Tengo dos fachadas:
CustomerFacade y
CustomerPreferencesFacade . Lo único malo es que ambas fachadas pertenecen al mismo nivel de abstracción. La separación por niveles de abstracción implica algo diferente.
Otro ejemplo:

Supongamos que hay una clase
OrderService en nuestro sistema en la que implementamos un mecanismo de notificación por correo electrónico. Ahora estamos creando un
DeliveryService y nos gustaría utilizar el mismo mecanismo de notificación aquí. Copiar y pegar está excluido. Hagámoslo de esta manera: extraiga la funcionalidad de notificación en la nueva clase
AlertService y escríbala como una dependencia para las
OrderService DeliveryService y
OrderService . Aquí, en contraste con el ejemplo anterior, la separación ocurrió precisamente en los niveles de abstracción.
DeliveryServicemás abstracto que AlertService, porque lo usa como parte de su flujo de trabajo.La separación por niveles de abstracción siempre supone que la clase extraída se convierte en una dependencia , y la extracción se lleva a cabo para su reutilización .La tarea de extracción no siempre es fácil. También puede implicar algunas dificultades y requerir una refactorización de las pruebas unitarias. Sin embargo, según mis observaciones, es aún más difícil para los desarrolladores buscar cualquier funcionalidad en la enorme base de código monolítico de la aplicación.Programación en pareja
 Muchos consultores hablarán sobre programación de pares, sobre el hecho de que esta es una solución universal a cualquier problema de desarrollo de TI hoy en día. Durante el mismo, los programadores desarrollan sus habilidades técnicas y conocimientos funcionales. Además, el proceso en sí mismo es interesante, une al equipo.Hablando no como consultores, sino humanamente, lo más importante es esto: la programación de pares mejora el "factor bus". La esencia del "factor bus" es que debe haber tantas personas con conocimiento sobre la estructura del sistema como sea posible . Perder a estas personas significa perder las últimas pistas de este conocimiento.La refactorización de programación en pareja es un arte que requiere experiencia y capacitación. Es útil, por ejemplo, la práctica de refactorización agresiva, realización de hackatones, cortes, codificación de dojos, etc.La programación de pares funciona bien en casos en los que necesita resolver problemas de alta complejidad. El proceso de trabajar juntos no siempre es simple. Pero le garantiza que evitará la "reingeniería"; por el contrario, obtendrá una implementación que aborde los requisitos establecidos con una complejidad mínima.
Muchos consultores hablarán sobre programación de pares, sobre el hecho de que esta es una solución universal a cualquier problema de desarrollo de TI hoy en día. Durante el mismo, los programadores desarrollan sus habilidades técnicas y conocimientos funcionales. Además, el proceso en sí mismo es interesante, une al equipo.Hablando no como consultores, sino humanamente, lo más importante es esto: la programación de pares mejora el "factor bus". La esencia del "factor bus" es que debe haber tantas personas con conocimiento sobre la estructura del sistema como sea posible . Perder a estas personas significa perder las últimas pistas de este conocimiento.La refactorización de programación en pareja es un arte que requiere experiencia y capacitación. Es útil, por ejemplo, la práctica de refactorización agresiva, realización de hackatones, cortes, codificación de dojos, etc.La programación de pares funciona bien en casos en los que necesita resolver problemas de alta complejidad. El proceso de trabajar juntos no siempre es simple. Pero le garantiza que evitará la "reingeniería"; por el contrario, obtendrá una implementación que aborde los requisitos establecidos con una complejidad mínima. Organizar un formato de trabajo conveniente es una de sus principales responsabilidades para el equipo. Debe cuidar constantemente las condiciones de trabajo del desarrollador: proporcionarles total comodidad y libertad de creatividad, especialmente si se requiere que aumenten la arquitectura de diseño y su complejidad.
Organizar un formato de trabajo conveniente es una de sus principales responsabilidades para el equipo. Debe cuidar constantemente las condiciones de trabajo del desarrollador: proporcionarles total comodidad y libertad de creatividad, especialmente si se requiere que aumenten la arquitectura de diseño y su complejidad.“Soy arquitecto. Por definición, siempre tengo razón ".
Esta estupidez se expresa periódicamente públicamente o detrás de escena. En la práctica actual, los arquitectos como tales se encuentran cada vez menos. Con el advenimiento de Agile, este rol pasó gradualmente a los desarrolladores senior, porque generalmente todo el trabajo, de una forma u otra, se desarrolla en torno a ellos. El tamaño de la implementación está creciendo gradualmente, y con esto hay una necesidad de refactorización y se está desarrollando una nueva funcionalidad.Arquitectura de cebolla
La cebolla es la filosofía más pura de Transaction Script. Al construirlo, nos guiamos por el objetivo de proteger el código que consideramos crítico, y para esto lo trasladamos al módulo de dominio. En nuestra aplicación, los más importantes son los servicios de dominio: implementan los flujos más críticos. Moverlos al módulo de dominio. Por supuesto, también vale la pena mover todos sus objetos de dominio aquí: entidades y objetos de valor. Todo lo demás que hemos compilado hoy (DTO, mapeadores, validadores, etc.) se convierte, por así decirlo, en la primera línea de defensa del usuario. Porque el usuario, por desgracia, no es nuestro amigo, y es necesario proteger el sistema de él.Atención a esta dependencia:
En nuestra aplicación, los más importantes son los servicios de dominio: implementan los flujos más críticos. Moverlos al módulo de dominio. Por supuesto, también vale la pena mover todos sus objetos de dominio aquí: entidades y objetos de valor. Todo lo demás que hemos compilado hoy (DTO, mapeadores, validadores, etc.) se convierte, por así decirlo, en la primera línea de defensa del usuario. Porque el usuario, por desgracia, no es nuestro amigo, y es necesario proteger el sistema de él.Atención a esta dependencia: El módulo de aplicación dependerá del módulo de dominio, es decir, no al revés. Al registrar dicha conexión, garantizamos que el DTO nunca entrará en el territorio sagrado del módulo de dominio: simplemente no son visibles e inaccesibles desde el módulo de dominio. Resulta que, en cierto sentido, cercamos el territorio del dominio, restringimos el acceso a él por parte de extraños.Sin embargo, el dominio puede necesitar interactuar con algún servicio externo. Con medios externos antipáticos, porque está equipado con su DTO. Cuales son nuestras opciones?Primero: omita al enemigo dentro del módulo.
El módulo de aplicación dependerá del módulo de dominio, es decir, no al revés. Al registrar dicha conexión, garantizamos que el DTO nunca entrará en el territorio sagrado del módulo de dominio: simplemente no son visibles e inaccesibles desde el módulo de dominio. Resulta que, en cierto sentido, cercamos el territorio del dominio, restringimos el acceso a él por parte de extraños.Sin embargo, el dominio puede necesitar interactuar con algún servicio externo. Con medios externos antipáticos, porque está equipado con su DTO. Cuales son nuestras opciones?Primero: omita al enemigo dentro del módulo.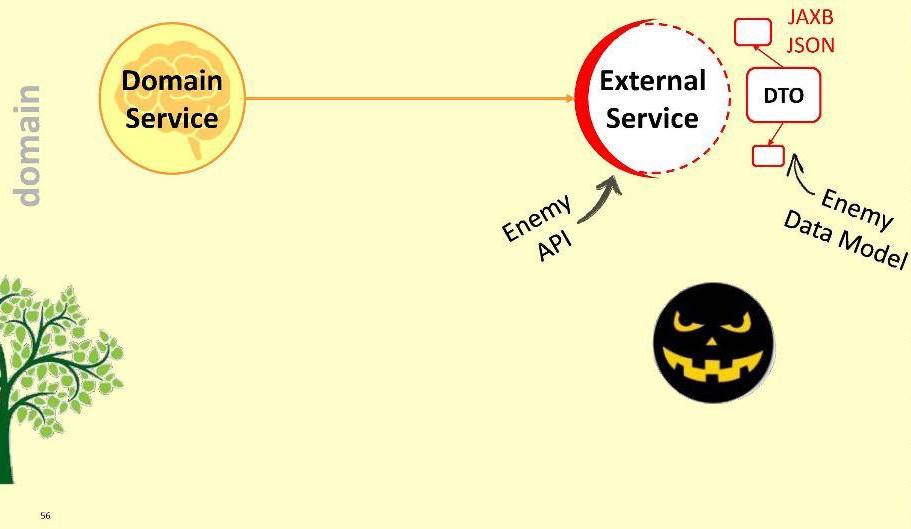 Obviamente, esta es una mala opción: es posible que mañana el servicio externo no se actualice a la versión 2.0, y tendremos que volver a dibujar nuestro dominio. ¡No dejes al enemigo dentro del dominio!Propongo un enfoque diferente: crearemos un adaptador especial para la interacción .
Obviamente, esta es una mala opción: es posible que mañana el servicio externo no se actualice a la versión 2.0, y tendremos que volver a dibujar nuestro dominio. ¡No dejes al enemigo dentro del dominio!Propongo un enfoque diferente: crearemos un adaptador especial para la interacción .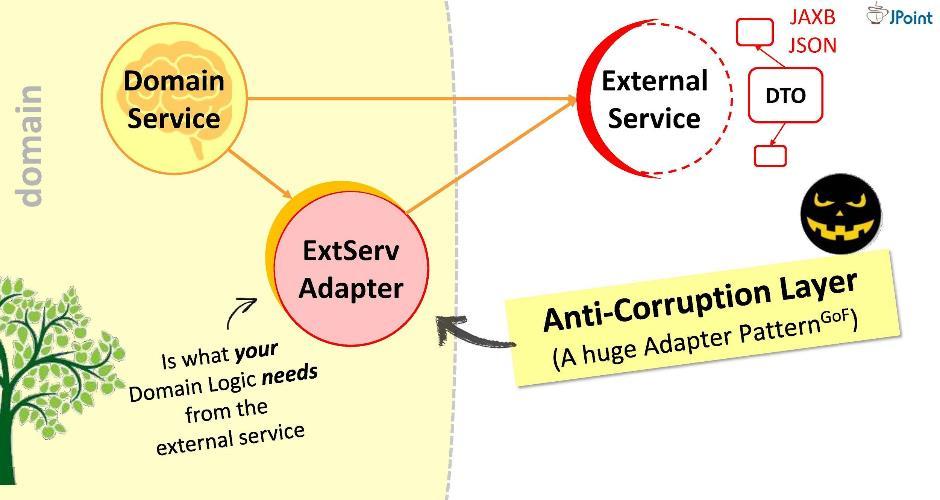 El adaptador recibirá datos de un servicio externo, extraerá los datos que nuestro dominio necesita y los convertirá en los tipos de estructuras requeridos. En este caso, todo lo que se requiere de nosotros durante el desarrollo es correlacionar las llamadas al sistema externo con los requisitos del dominio. Piense en ello como un gran adaptador como este . Yo llamo a esta capa "anticorrupción".Por ejemplo, es posible que necesitemos ejecutar consultas LDAP desde un dominio. Para hacer esto, estamos implementando el "módulo anticorrupción"
El adaptador recibirá datos de un servicio externo, extraerá los datos que nuestro dominio necesita y los convertirá en los tipos de estructuras requeridos. En este caso, todo lo que se requiere de nosotros durante el desarrollo es correlacionar las llamadas al sistema externo con los requisitos del dominio. Piense en ello como un gran adaptador como este . Yo llamo a esta capa "anticorrupción".Por ejemplo, es posible que necesitemos ejecutar consultas LDAP desde un dominio. Para hacer esto, estamos implementando el "módulo anticorrupción" LDAPUserServiceAdapter. En el adaptador podemos:
En el adaptador podemos:- Ocultar llamadas API feas (en nuestro caso, ocultar el método que toma la matriz Object);
- Paquete de excepciones en nuestras propias implementaciones;
- Convierta las estructuras de datos de otras personas en las suyas (en nuestros objetos de dominio);
- Verifique la validez de los datos entrantes.
Este es el propósito del adaptador. Bien, en la interfaz con cada sistema externo con el que necesita interactuar, su adaptador debe estar instalado. Por lo tanto, el dominio no dirigirá la llamada a un servicio externo, sino al adaptador. Para hacer esto, la dependencia correspondiente debe estar registrada en el dominio (desde el adaptador o desde el módulo de infraestructura en el que se encuentra). ¿Pero es segura esta adicción? Si lo instala así, un DTO de servicio externo puede ingresar a nuestro dominio. No debemos permitir esto. Por lo tanto, le sugiero otra forma de modelar dependencias.
Por lo tanto, el dominio no dirigirá la llamada a un servicio externo, sino al adaptador. Para hacer esto, la dependencia correspondiente debe estar registrada en el dominio (desde el adaptador o desde el módulo de infraestructura en el que se encuentra). ¿Pero es segura esta adicción? Si lo instala así, un DTO de servicio externo puede ingresar a nuestro dominio. No debemos permitir esto. Por lo tanto, le sugiero otra forma de modelar dependencias.Principio de inversión de dependencia
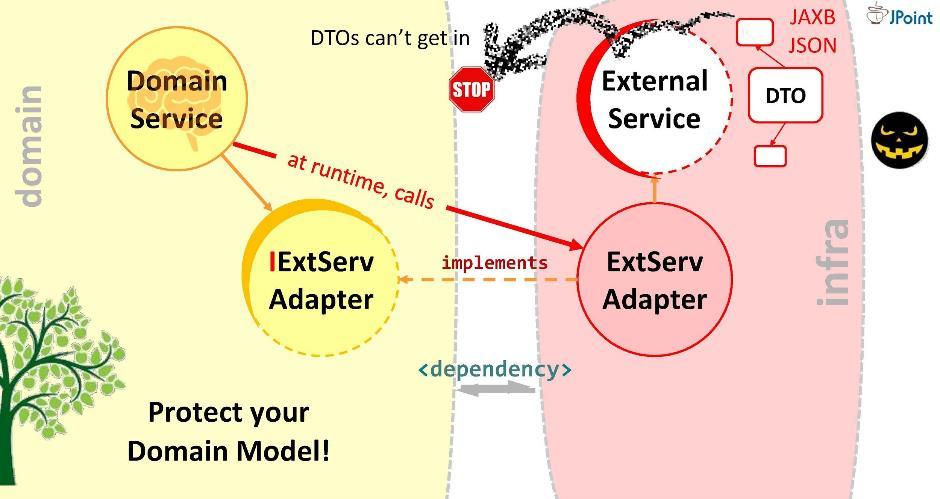 Creemos una interfaz, escriba en ella la firma de los métodos necesarios y colóquela dentro de nuestro dominio. La tarea del adaptador es implementar esta interfaz. Resulta que la interfaz está dentro del dominio y el adaptador está afuera, en el módulo de infraestructura que importa la interfaz. Por lo tanto, giramos la dirección de dependencia en la dirección opuesta. En tiempo de ejecución, el sistema de dominio llamará a cualquier clase a través de interfaces.Como puede ver, con solo introducir interfaces en la arquitectura, pudimos implementar dependencias y así proteger nuestro dominio de estructuras externas y API que caen en él. Este enfoque se llama inversión de dependencia .
Creemos una interfaz, escriba en ella la firma de los métodos necesarios y colóquela dentro de nuestro dominio. La tarea del adaptador es implementar esta interfaz. Resulta que la interfaz está dentro del dominio y el adaptador está afuera, en el módulo de infraestructura que importa la interfaz. Por lo tanto, giramos la dirección de dependencia en la dirección opuesta. En tiempo de ejecución, el sistema de dominio llamará a cualquier clase a través de interfaces.Como puede ver, con solo introducir interfaces en la arquitectura, pudimos implementar dependencias y así proteger nuestro dominio de estructuras externas y API que caen en él. Este enfoque se llama inversión de dependencia .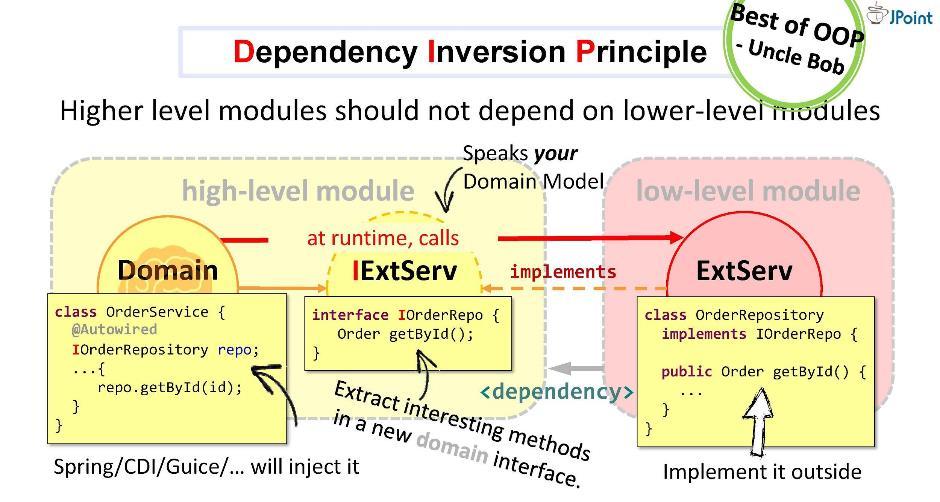 En general, la inversión de dependencia supone que coloca los métodos que le interesan en la interfaz dentro de su módulo de alto nivel (en el dominio) e implementa esta interfaz desde el exterior, en uno u otro módulo feo de bajo nivel (infraestructura).La interfaz implementada dentro del módulo de dominio debe hablar el idioma del dominio, es decir, funcionará en sus entidades, sus parámetros y tipos de retorno. En tiempo de ejecución, el dominio llamará a cualquier clase a través de una llamada polimórfica a la interfaz. Los marcos de inyección de dependencias (como Spring y CDI) nos proporcionan una instancia concreta de la clase en tiempo de ejecución.Pero lo principal es que durante la compilación, el módulo de dominio no verá el contenido del módulo externo. Eso es lo que necesitamos. Ninguna entidad externa debe caer en el dominio.Según el tío Bob , el principio de inversión de control (o, como él lo llama, "arquitectura de plug-in") es quizás el mejor que ofrece el paradigma OOP en general.
En general, la inversión de dependencia supone que coloca los métodos que le interesan en la interfaz dentro de su módulo de alto nivel (en el dominio) e implementa esta interfaz desde el exterior, en uno u otro módulo feo de bajo nivel (infraestructura).La interfaz implementada dentro del módulo de dominio debe hablar el idioma del dominio, es decir, funcionará en sus entidades, sus parámetros y tipos de retorno. En tiempo de ejecución, el dominio llamará a cualquier clase a través de una llamada polimórfica a la interfaz. Los marcos de inyección de dependencias (como Spring y CDI) nos proporcionan una instancia concreta de la clase en tiempo de ejecución.Pero lo principal es que durante la compilación, el módulo de dominio no verá el contenido del módulo externo. Eso es lo que necesitamos. Ninguna entidad externa debe caer en el dominio.Según el tío Bob , el principio de inversión de control (o, como él lo llama, "arquitectura de plug-in") es quizás el mejor que ofrece el paradigma OOP en general.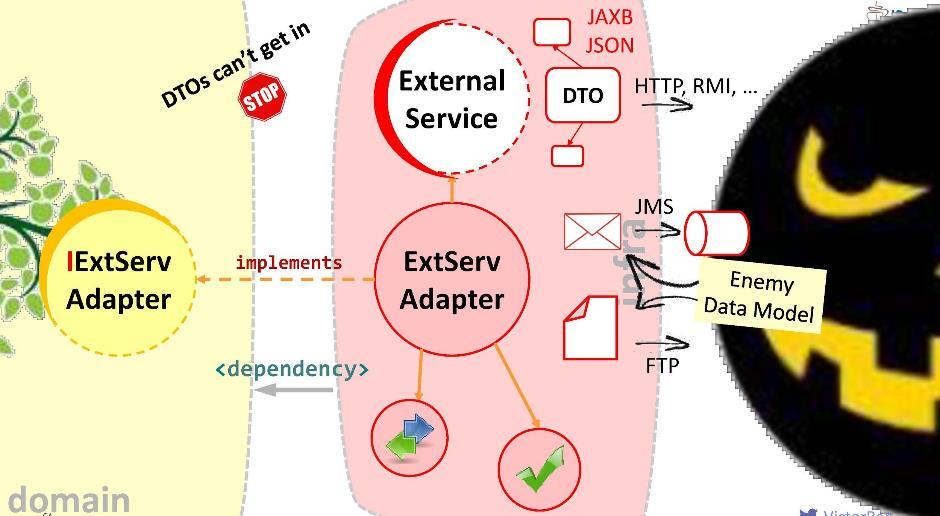 Esta estrategia se puede utilizar para la integración con cualquier sistema, para llamadas y mensajes sincrónicos y asincrónicos, para enviar archivos, etc.
Esta estrategia se puede utilizar para la integración con cualquier sistema, para llamadas y mensajes sincrónicos y asincrónicos, para enviar archivos, etc.Descripción general de la bombilla
 Entonces, decidimos proteger el módulo de dominio. Dentro hay un servicio de dominio, entidades, objetos de valor y ahora interfaces para servicios externos, además de interfaces para el repositorio (para interactuar con la base de datos).La estructura se ve así:
Entonces, decidimos proteger el módulo de dominio. Dentro hay un servicio de dominio, entidades, objetos de valor y ahora interfaces para servicios externos, además de interfaces para el repositorio (para interactuar con la base de datos).La estructura se ve así: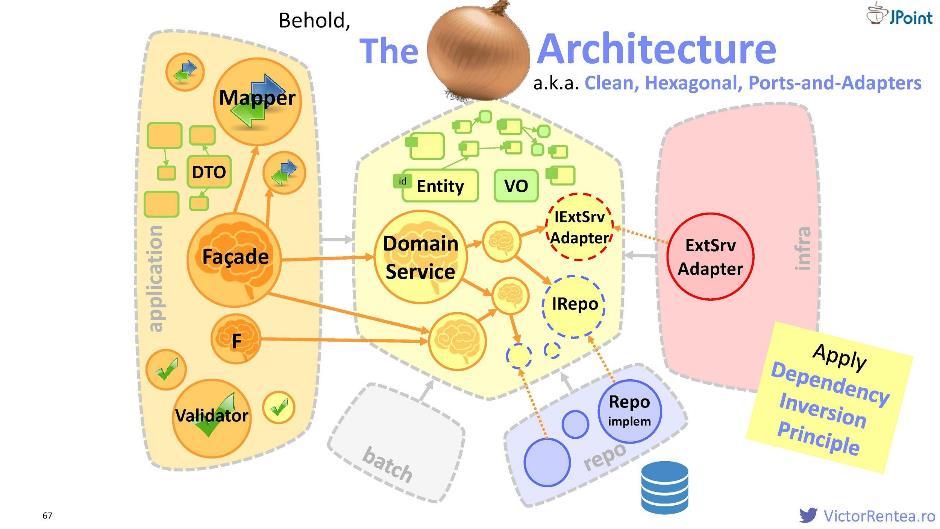 el módulo de aplicación, el módulo de infraestructura (a través de la inversión de dependencia), el módulo de repositorio (también consideramos la base de datos como un sistema externo), el módulo por lotes y posiblemente otros módulos son dependencias declaradas para el dominio. Esta arquitectura se llama "cebolla" ; también se llama "limpio", "hexagonal" y "puertos y adaptadores".
el módulo de aplicación, el módulo de infraestructura (a través de la inversión de dependencia), el módulo de repositorio (también consideramos la base de datos como un sistema externo), el módulo por lotes y posiblemente otros módulos son dependencias declaradas para el dominio. Esta arquitectura se llama "cebolla" ; también se llama "limpio", "hexagonal" y "puertos y adaptadores".Módulo de repositorio
Hablaré brevemente sobre el módulo de repositorio. Si sacarlo del dominio es una pregunta. La tarea del repositorio es hacer que la lógica sea más limpia, ocultándonos el horror de trabajar con datos persistentes. La opción para los muchachos de la vieja escuela es usar JDBC para interactuar con la base de datos: también puedes usar Spring y su JdbcTemplate:
también puedes usar Spring y su JdbcTemplate: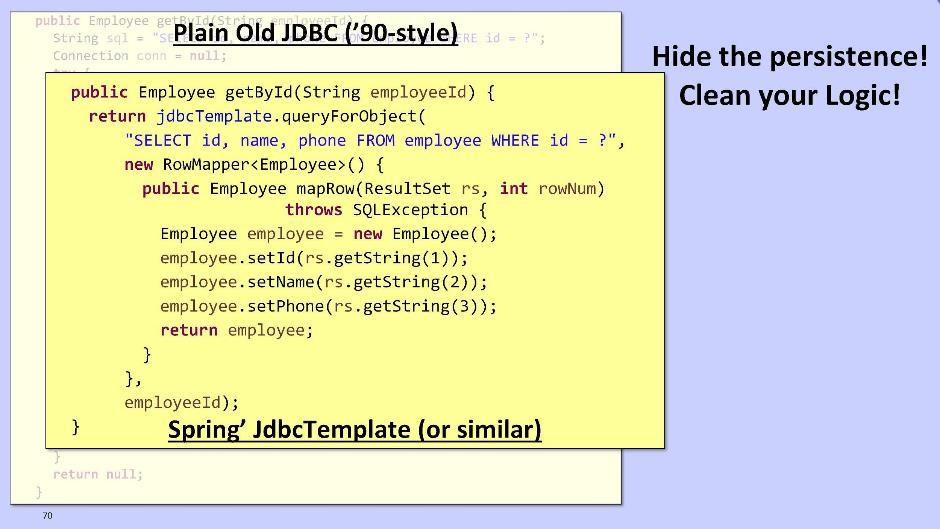 o MyBatis DataMapper:
o MyBatis DataMapper: Pero es tan complicado y feo que desalienta cualquier deseo de hacer algo más. Por lo tanto, sugiero usar JPA / Hibernate o Spring Data JPA. Nos darán la oportunidad de enviar consultas creadas no en el esquema de la base de datos, sino directamente sobre la base del modelo de nuestras entidades.Implementación para JPA / Hibernate:
Pero es tan complicado y feo que desalienta cualquier deseo de hacer algo más. Por lo tanto, sugiero usar JPA / Hibernate o Spring Data JPA. Nos darán la oportunidad de enviar consultas creadas no en el esquema de la base de datos, sino directamente sobre la base del modelo de nuestras entidades.Implementación para JPA / Hibernate: en el caso de Spring Data JPA:
en el caso de Spring Data JPA: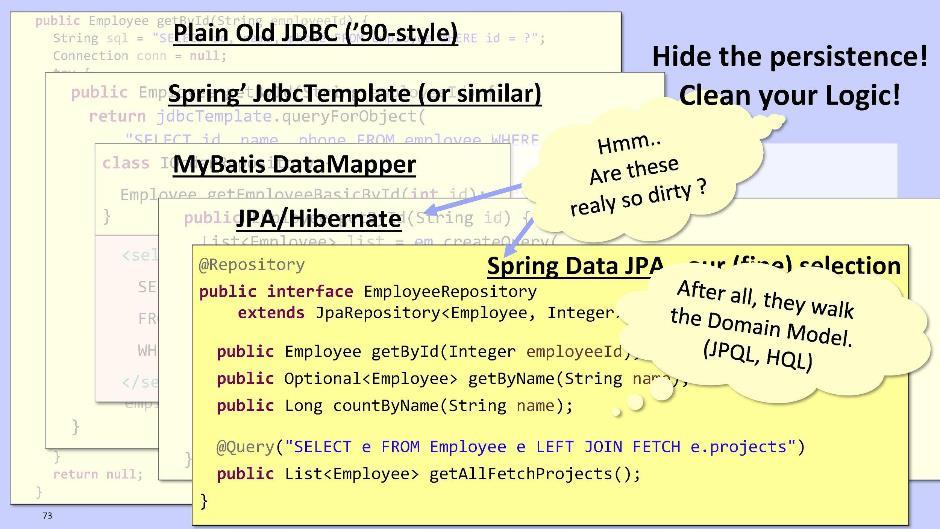 Spring Data JPA puede generar automáticamente métodos en tiempo de ejecución, como, por ejemplo, getById (), getByName (). También le permite ejecutar consultas JPQL si es necesario, y no a la base de datos, sino a su propio modelo de entidad.El código JPA de Hibernate y Spring Data JPA realmente se ve bastante bien. ¿Necesitamos extraerlo del dominio? En mi opinión, esto no es tan necesario. Lo más probable es que el código sea aún más limpio si deja este fragmento dentro del dominio. Así que actúa sobre la situación.
Spring Data JPA puede generar automáticamente métodos en tiempo de ejecución, como, por ejemplo, getById (), getByName (). También le permite ejecutar consultas JPQL si es necesario, y no a la base de datos, sino a su propio modelo de entidad.El código JPA de Hibernate y Spring Data JPA realmente se ve bastante bien. ¿Necesitamos extraerlo del dominio? En mi opinión, esto no es tan necesario. Lo más probable es que el código sea aún más limpio si deja este fragmento dentro del dominio. Así que actúa sobre la situación. Sin embargo, si crea un módulo de repositorio, para la organización de dependencias es mejor utilizar el principio de inversión de control de la misma manera. Para hacer esto, coloque la interfaz en el dominio e impleméntela en el módulo de repositorio. En cuanto a la lógica del repositorio, es mejor transferirlo al dominio. Esto hace que las pruebas sean convenientes, ya que puede usar objetos Mock en el dominio. Le permitirán probar la lógica rápida y repetidamente.Tradicionalmente, solo se crea una entidad para un repositorio en un dominio. Lo rompen en pedazos solo cuando se vuelve demasiado voluminoso. Recuerda que las clases deben ser compactas.
Sin embargo, si crea un módulo de repositorio, para la organización de dependencias es mejor utilizar el principio de inversión de control de la misma manera. Para hacer esto, coloque la interfaz en el dominio e impleméntela en el módulo de repositorio. En cuanto a la lógica del repositorio, es mejor transferirlo al dominio. Esto hace que las pruebas sean convenientes, ya que puede usar objetos Mock en el dominio. Le permitirán probar la lógica rápida y repetidamente.Tradicionalmente, solo se crea una entidad para un repositorio en un dominio. Lo rompen en pedazos solo cuando se vuelve demasiado voluminoso. Recuerda que las clases deben ser compactas.API
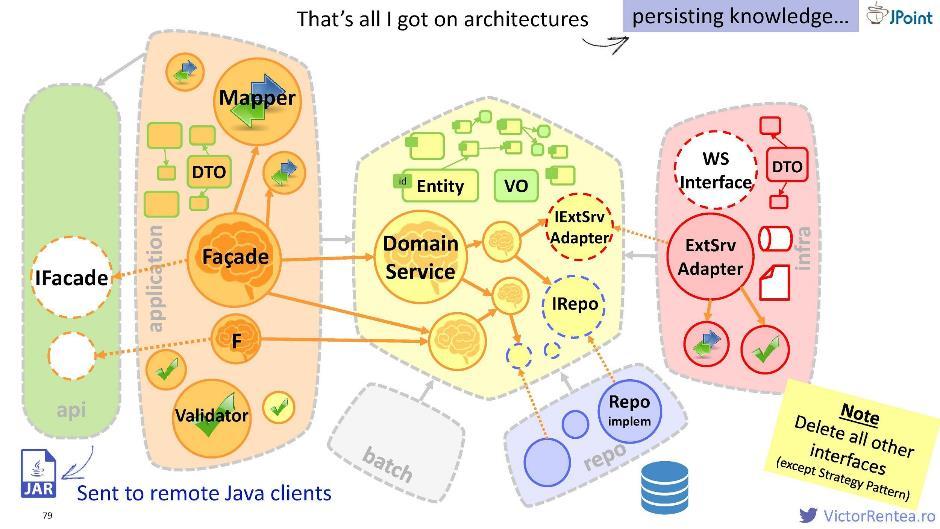 Puede crear un módulo separado, colocar la interfaz extraída de la fachada y los DTO que dependen de él, luego empaquetarlo en un JAR y transferirlo a sus clientes Java de esta forma. Con este archivo, podrán enviar solicitudes a las fachadas.
Puede crear un módulo separado, colocar la interfaz extraída de la fachada y los DTO que dependen de él, luego empaquetarlo en un JAR y transferirlo a sus clientes Java de esta forma. Con este archivo, podrán enviar solicitudes a las fachadas.Bulbo pragmático
Además de aquellos de nuestros "enemigos" a quienes les brindamos funcionalidad, es decir, clientes, también tenemos enemigos y, por otro lado, aquellos módulos de los que nosotros mismos dependemos. También debemos protegernos de estos módulos. Y para esto le ofrezco una "cebolla" ligeramente modificada: en ella, toda la infraestructura se combina en un solo módulo.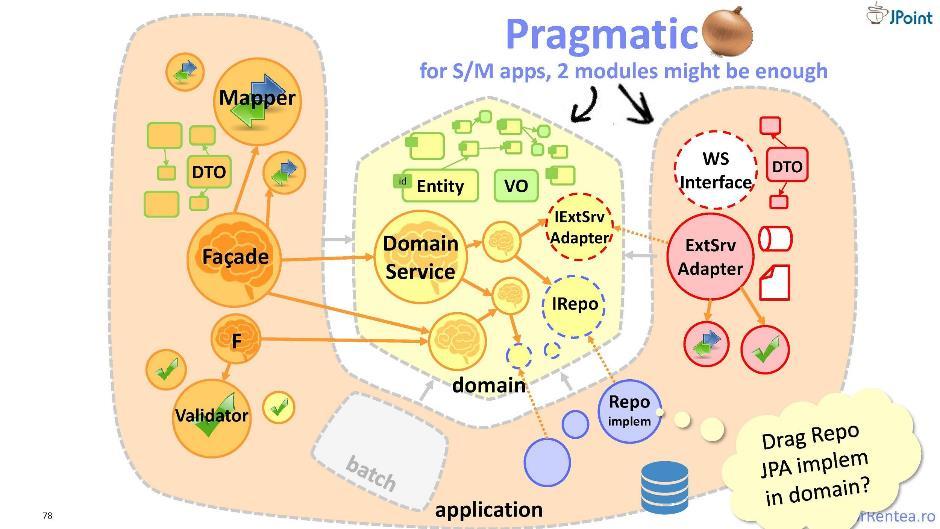 Yo llamo a esta arquitectura una "bombilla pragmática". Aquí, la separación de componentes se lleva a cabo de acuerdo con el principio de "mío" e "integrable": por separado, que se relaciona con mi dominio, y por separado, que se refiere a la integración con colaboradores externos. Por lo tanto, solo se obtienen dos módulos: el dominio y la aplicación. Tal arquitectura es muy buena, pero solo cuando el módulo de aplicación es pequeño. De lo contrario, es mejor volver a la cebolla tradicional.
Yo llamo a esta arquitectura una "bombilla pragmática". Aquí, la separación de componentes se lleva a cabo de acuerdo con el principio de "mío" e "integrable": por separado, que se relaciona con mi dominio, y por separado, que se refiere a la integración con colaboradores externos. Por lo tanto, solo se obtienen dos módulos: el dominio y la aplicación. Tal arquitectura es muy buena, pero solo cuando el módulo de aplicación es pequeño. De lo contrario, es mejor volver a la cebolla tradicional.Pruebas
Como dije antes, si todos le temen a su aplicación, considere que ha reabastecido los rangos de Legacy.  Pero las pruebas son buenas. Nos dan una sensación de confianza que nos permite continuar refactorizando. Pero desafortunadamente, esta confianza puede resultar fácilmente injustificada. Explicaré por qué. TDD (desarrollo a través de pruebas) supone que usted es el autor del código y el autor de los casos de prueba: lee las especificaciones, implementa la funcionalidad e inmediatamente escribe un conjunto de pruebas para ello. Las pruebas, por ejemplo, tendrán éxito. Pero, ¿qué pasa si no entendiste los requisitos de las especificaciones? Luego, las pruebas verificarán no lo que se necesita. Entonces tu confianza no vale nada. Y todo porque escribiste código y pruebas solo.Pero trata de cerrar los ojos a esto. Las pruebas siguen siendo necesarias y, en cualquier caso, nos dan confianza. Por encima de todo, por supuesto, nos encantan las pruebas funcionales: no implican ningún efecto secundario, ni dependencias, solo datos de entrada y salida. Para probar un dominio, debe usar objetos simulados: le permitirán probar las clases de forma aislada.En cuanto a las consultas de la base de datos, probarlas es desagradable. Estas pruebas son frágiles, requieren que primero agregue datos de prueba a la base de datos, y solo después de eso puede proceder a probar la funcionalidad. Pero como comprende, estas pruebas también son necesarias, incluso si usa JPA.
Pero las pruebas son buenas. Nos dan una sensación de confianza que nos permite continuar refactorizando. Pero desafortunadamente, esta confianza puede resultar fácilmente injustificada. Explicaré por qué. TDD (desarrollo a través de pruebas) supone que usted es el autor del código y el autor de los casos de prueba: lee las especificaciones, implementa la funcionalidad e inmediatamente escribe un conjunto de pruebas para ello. Las pruebas, por ejemplo, tendrán éxito. Pero, ¿qué pasa si no entendiste los requisitos de las especificaciones? Luego, las pruebas verificarán no lo que se necesita. Entonces tu confianza no vale nada. Y todo porque escribiste código y pruebas solo.Pero trata de cerrar los ojos a esto. Las pruebas siguen siendo necesarias y, en cualquier caso, nos dan confianza. Por encima de todo, por supuesto, nos encantan las pruebas funcionales: no implican ningún efecto secundario, ni dependencias, solo datos de entrada y salida. Para probar un dominio, debe usar objetos simulados: le permitirán probar las clases de forma aislada.En cuanto a las consultas de la base de datos, probarlas es desagradable. Estas pruebas son frágiles, requieren que primero agregue datos de prueba a la base de datos, y solo después de eso puede proceder a probar la funcionalidad. Pero como comprende, estas pruebas también son necesarias, incluso si usa JPA.Pruebas unitarias
 Diría que el poder de las pruebas unitarias no está en la posibilidad de ejecutarlas, sino en lo que abarca el proceso de escribirlas. Mientras escribe una prueba, reconsidera y trabaja el código (reduce la conectividad, lo divide en clases), en una palabra, realiza la siguiente refactorización. El código bajo prueba es código puro; es más simple, la conectividad se reduce en ella; en general, también está documentado (una prueba unitaria bien escrita describe perfectamente cómo funciona la clase). No es sorprendente que escribir pruebas unitarias sea difícil, especialmente las primeras piezas.
Diría que el poder de las pruebas unitarias no está en la posibilidad de ejecutarlas, sino en lo que abarca el proceso de escribirlas. Mientras escribe una prueba, reconsidera y trabaja el código (reduce la conectividad, lo divide en clases), en una palabra, realiza la siguiente refactorización. El código bajo prueba es código puro; es más simple, la conectividad se reduce en ella; en general, también está documentado (una prueba unitaria bien escrita describe perfectamente cómo funciona la clase). No es sorprendente que escribir pruebas unitarias sea difícil, especialmente las primeras piezas.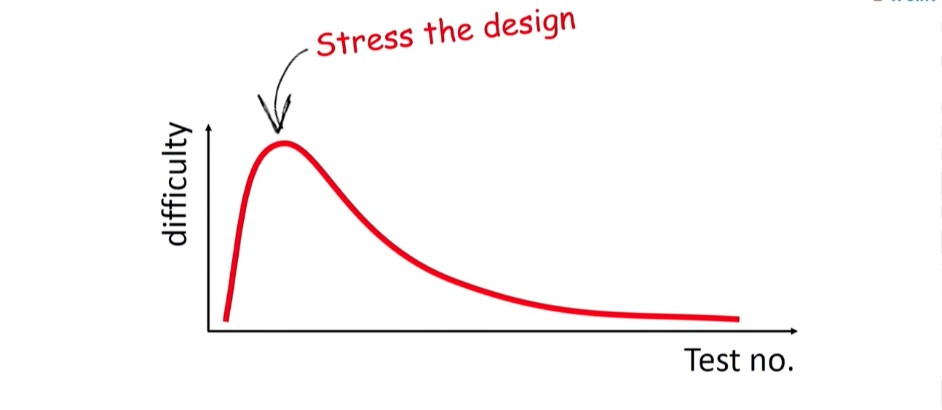 En la etapa de las primeras pruebas unitarias, muchas personas realmente temen las perspectivas de que realmente tengan que probar algo. ¿Por qué se les da tanto?Porque estas pruebas son la primera carga para tu clase. Este es el primer golpe al sistema, que, tal vez, mostrará que es frágil y endeble. Pero debe comprender que estas pocas pruebas son las más importantes para su desarrollo. Son, en esencia, sus mejores amigos, porque lo dirán todo sobre la calidad de su código. Si tienes miedo de esta etapa, entonces no llegarás lejos. Debe ejecutar pruebas para su sistema. Después de eso, la complejidad disminuirá, las pruebas se escribirán más rápido. Agregándolos uno por uno, creará una base de prueba de regresión confiable para su sistema. Y esto es increíblemente importante para el trabajo futuro de sus desarrolladores. Será más fácil para ellos refactorizar; Entenderán que el sistema puede probarse mediante regresión en cualquier momento, por lo que trabajar con la base de código es seguro. Y, te aseguro, se dedicarán a refactorizar mucho más de buena gana.
En la etapa de las primeras pruebas unitarias, muchas personas realmente temen las perspectivas de que realmente tengan que probar algo. ¿Por qué se les da tanto?Porque estas pruebas son la primera carga para tu clase. Este es el primer golpe al sistema, que, tal vez, mostrará que es frágil y endeble. Pero debe comprender que estas pocas pruebas son las más importantes para su desarrollo. Son, en esencia, sus mejores amigos, porque lo dirán todo sobre la calidad de su código. Si tienes miedo de esta etapa, entonces no llegarás lejos. Debe ejecutar pruebas para su sistema. Después de eso, la complejidad disminuirá, las pruebas se escribirán más rápido. Agregándolos uno por uno, creará una base de prueba de regresión confiable para su sistema. Y esto es increíblemente importante para el trabajo futuro de sus desarrolladores. Será más fácil para ellos refactorizar; Entenderán que el sistema puede probarse mediante regresión en cualquier momento, por lo que trabajar con la base de código es seguro. Y, te aseguro, se dedicarán a refactorizar mucho más de buena gana. Mi consejo para ti: si sientes que tienes mucha fuerza y energía hoy, dedícate a escribir pruebas unitarias. Y asegúrese de que cada uno esté limpio, rápido, tenga su propio peso y no repita los demás.
Mi consejo para ti: si sientes que tienes mucha fuerza y energía hoy, dedícate a escribir pruebas unitarias. Y asegúrese de que cada uno esté limpio, rápido, tenga su propio peso y no repita los demás.Consejos
Resumiendo todo lo que se ha dicho hoy, me gustaría amonestarlo con los siguientes consejos:- Manténgalo simple durante el mayor tiempo posible (y no importa lo que cueste) : evite la "reingeniería" y la optimización tardía, no sobrecargue la aplicación;
- , , ;
- «» — ;
- , — : ;
- «», , — ;
- No tenga miedo de las pruebas : deles la oportunidad de derrumbar su sistema, sienta todos sus beneficios; al final, son sus amigos porque pueden señalar problemas con honestidad.
Al hacer estas cosas, ayudará tanto a su equipo como a usted mismo. Y luego, cuando llegue el día de la entrega del producto, estará listo para ello.Que leer

. JPoint — , 19-20 - Joker 2018 — Java-. . .