Lanzamiento de
planes de servicio de inicio de catálogo. La compañía está
desarrollando una instalación especial que le permitirá registrar un terabyte de datos en 500 billones de moléculas de ADN diariamente.
A continuación, hablamos sobre el enfoque utilizado por Catálogo y otros desarrollos recientes en el campo del ADN.
 / foto Universidad de Michigan CC
/ foto Universidad de Michigan CCDetalles del proyecto
El enfoque clásico para escribir datos en el ADN implica convertir una secuencia de bits, ceros y unos, en una secuencia de cuatro bases básicas de ADN. Por ejemplo, las bases nitrogenadas adenina (A), timina (T), guanina (G) y citosina (C) se pueden representar de la siguiente manera: A = 00, T = 01, G = 10, C = 11.
Con este enfoque, en 2016 Microsoft
pudo "perpetuar" 200 MB de texto y video en moléculas de ADN sintético (como ya escribimos en
una de las publicaciones ). Sin embargo, este método no es adecuado para el registro de datos en masa, aunque es costoso.
En lugar de usar millones de cadenas de ADN, los investigadores del Catálogo sugieren generar una gran cantidad de moléculas de ADN diferentes, que consisten en no más de 30 pares de bases. Luego, debido a
las reacciones enzimáticas, estas "piezas" preparadas previamente forman patrones especiales que codifican la información. Por lo tanto, en lugar de representar una sola base de nitrógeno, los bits se organizan en matrices multidimensionales. Y grupos de moléculas reflejan la posición de los bits en estas matrices.
Devin Leake, Director de Investigación de Catálogo,
cita la siguiente analogía: “Imagina que tienes un libro. Puede copiarlo manualmente: letra por letra. Del mismo modo, puede escribir datos en el ADN, molécula por molécula. Este enfoque fue utilizado por Microsoft. Proponemos crear una especie de "imprenta", donde las moléculas de ADN serán un
auricular . Por lo tanto, al reorganizar las moléculas pregeneradas, trabajamos de inmediato con palabras completas, organizándolas en el orden correcto ".
Usando este método, los investigadores del Catálogo registraron y recuperaron con
éxito los datos en el ADN. Para hacer esto, usaron el poema
The Road Not Taken (en una de las traducciones - "Otro camino") de Robert Frost. Ahora la empresa está resolviendo el problema de escalar la plataforma a las necesidades de las empresas de TI y las organizaciones gubernamentales.
Según Hyunjun Park, uno de los fundadores del Catálogo, este enfoque hará que los almacenamientos de ADN de terabytes sean comercialmente viables a principios de 2019. Sin embargo, aún se desconoce el costo exacto del servicio de almacenamiento de datos que ofrecerá la startup.
Desarrollos similares
Como ya se señaló, los problemas de creación de repositorios de ADN son manejados por Microsoft. Y desde 2016, los investigadores de la compañía han
avanzado en su desarrollo: en febrero de 2018, crearon una "biblioteca de
cebadores " para organizar el acceso aleatorio al ADN. Cada uno de los cebadores está "unido" a una cadena específica, por lo tanto, utilizando la
reacción en cadena de la
polimerasa, puede seleccionar cualquiera de ellos (y obtener acceso a los datos grabados).
 / foto Col Ford y Natasha de Vere CC
/ foto Col Ford y Natasha de Vere CCLa compañía espera que este enfoque, junto con un nuevo algoritmo para escribir y leer datos, que es menos susceptible a errores, ayude en el futuro a crear almacenamientos de ADN con un volumen de varios terabytes. El gigante de TI planea proporcionar almacenamiento de ADN como un servicio. La compañía
se propuso implementar la idea para 2020.
Ganar-ganar ADN e IA
No hay ninguna dificultad particular con el registro de información en un portador de ADN: las empresas han ideado métodos de automatización. Pero el proceso de lectura de información sigue siendo complicado y requiere mucho tiempo. Para resolver este problema, Lifebit
planea usar sistemas de inteligencia artificial. Lifebit está desarrollando la plataforma en la nube Deploit basada en algoritmos MO, que automatizará el proceso de lectura de información de portadores de ADN.
Por lo tanto, el aprendizaje automático contribuirá a la organización de los depósitos de ADN. Sin embargo, lo contrario también es cierto: las moléculas de ADN se utilizan para crear sistemas de inteligencia artificial. Por ejemplo, los investigadores de Caltech
están trabajando en esta área.
El principio de funcionamiento de su red neuronal se
basa en reacciones químicas, llamadas
desplazamiento de hilo (un mecanismo de replicación de ADN conocido en algunos virus), cuando un hilo llamado entrante desplaza una de las hebras del ADN original. El sistema inteligente ya ha sido
enseñado a reconocer números escritos
a mano.
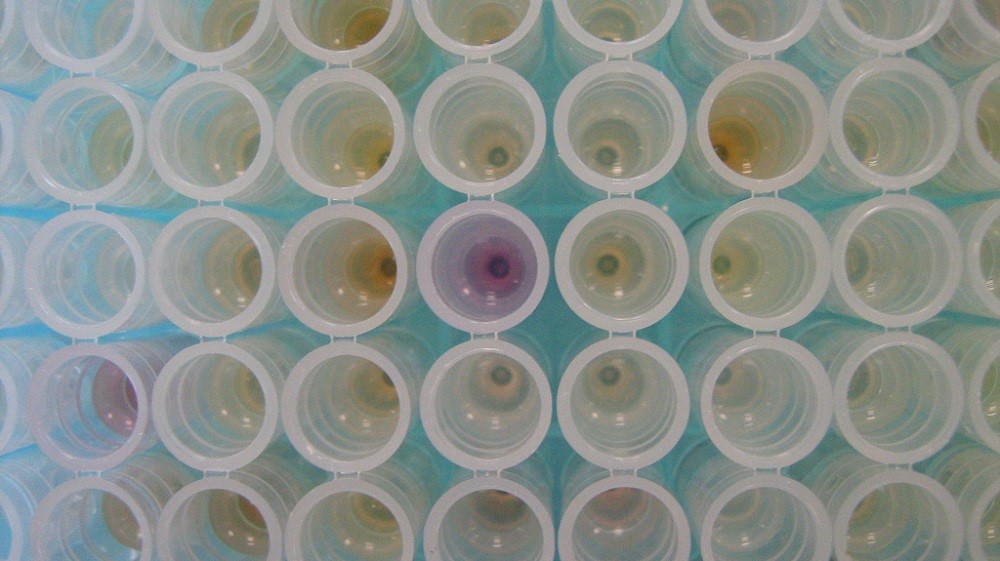
La figura se dibuja en un plano cuadrado, dividido en cien celdas idénticas (10x10) - píxeles originales. Cada una de estas células está representada por una molécula de ADN que "sabe" si hay un dígito en este píxel. Después de que todas las moléculas se mezclan en un tubo de ensayo, la red de ADN da su respuesta usando señales fluorescentes. El tubo comienza a emitir un brillo cuyo color depende del dígito reconocido. Por ejemplo, verde y amarillo significan cinco, y verde y rojo significan nueve.
Los investigadores planean formar un tipo de memoria en la red neuronal para que "recuerde" los vectores de entrenamiento y los use para resolver otros problemas.
O catálogo
Catalog es una startup estadounidense fundada en 2016, que está desarrollando tecnologías para almacenar datos en moléculas de ADN. Con sede en Boston, Massachusetts.
PD: un par de materiales adicionales del primer blog corporativo de IaaS:
La dirección principal de nuestra actividad es la provisión de servicios en la nube:
Infraestructura virtual (IaaS) | Alojamiento PCI DSS | Nube FZ-152 | Alquile 1C en la nube