Introduccion
Todos los que usan el sistema de monitoreo Zabbix y monitorean su desarrollo saben que con el lanzamiento de Zabbix 3.4 tenemos una gran característica: Elementos dependientes (elementos de datos dependientes), sobre los cuales ya había una publicación de blog
correspondiente en Zabbix. Sin embargo, en la forma en que se introdujo en 3.4, usarlo "al máximo" era problemático debido al hecho de que las macros LLD no eran compatibles para su uso en las reglas de preprocesamiento (
ZBXNEXT-4109 ), así como como un "padre" Solo se pudo seleccionar uno del elemento de datos creado por la propia regla LLD (
ZBXNEXT-4200 ). En resumen, tuve que hacer todo exactamente como se describe en el enlace anterior: trabajar con sus manos, lo que, con una gran cantidad de métricas, causó muchos inconvenientes. Sin embargo, con el lanzamiento de Zabbix 4.0alpha9, todo ha cambiado.
Un poco de historia
Para mí, la funcionalidad descrita fue importante debido al hecho de que nuestra empresa utiliza varios sistemas de almacenamiento de HP, a saber, HP MSA 2040/2050, cuyas métricas se eliminan mediante solicitudes a su API XML utilizando un
script Python .
Al principio, cuando la tarea era monitorear el equipo designado y se encontró una opción usando la API, resultó que en el caso más simple, para averiguar, por ejemplo, el estado de salud de un componente del sistema de almacenamiento, era necesario hacer dos consultas:
- Solicitar token de autenticación (clave de sesión);
- La solicitud en sí, devolviendo información sobre el componente.
Ahora imagine que el almacenamiento consta de 24 discos (o tal vez más), dos fuentes de alimentación, un par de controladores, ventiladores, varias agrupaciones de discos, etc. - multiplicamos todo esto por 2 y obtenemos más de 50 elementos de datos, lo que equivale a la misma cantidad de solicitudes para API en las comprobaciones de cada minuto. Si intenta ir por este camino, la API "se establece" rápidamente y, después de todo, solo estamos hablando de solicitar el "estado" de los componentes, sin tener en cuenta las otras métricas posibles e interesantes: temperatura, horas de funcionamiento de los discos duros, velocidad del ventilador, etc.
La primera decisión que tomé para descargar la API, incluso antes del lanzamiento de la versión 3.4 de Zabbix, fue crear un caché para el token recibido, cuyo valor se escribió en el archivo y se almacenó durante N minutos. Esto permitió reducir el número de llamadas a la API exactamente dos veces, sin embargo, la situación no cambió mucho: fue difícil obtener algo más que el estado de salud. Alrededor de este tiempo, visité Zabbix Moscow Meetup 2017, organizado por Badoo, donde aprendí sobre la funcionalidad de los elementos de datos dependientes mencionados anteriormente.
La secuencia de comandos se modificó para poder proporcionar objetos JSON detallados que contienen información de interés para nosotros sobre varios componentes del repositorio y su salida comenzó a parecerse a esto en lugar de una sola cadena o valores numéricos:
{"1.1":{"health":"OK","health-num":"0","error":"0","temperature":"24","power-on-hours":"27267"},"1.2":{"health":"OK","health-num":"0","error":"0","temperature":"23","power-on-hours":"27266"},"1.3":{"health":"OK","health-num":"0","error":"0","temperature":"24","power-on-hours":"27336"}, ... }
Este es un ejemplo con los datos dados en todos los discos de almacenamiento. Para otros componentes, la imagen es similar: la clave es la ID del componente y el valor es un objeto JSON que contiene las métricas necesarias.
Todo estaba bien, pero los matices descritos al principio del artículo surgieron rápidamente: todas las métricas dependientes tuvieron que crearse y actualizarse manualmente, lo que fue bastante doloroso (alrededor de 300 métricas por sistema de almacenamiento más desencadenantes y gráficos). LLD podría salvarnos, pero aquí, al crear el prototipo, no nos permitió especificar el que no fue creado por la regla como elemento principal, y eliminó el truco sucio al crear un elemento ficticio a través de LLD y reemplazar su itemid en la base de datos con el deseado Servidor Zabbix. Las solicitudes de funciones mencionadas aparecieron rápidamente en el rastreador de errores Zabbix, lo que indicaba que esta funcionalidad era importante no solo para mí.
Porque se completaron todas las operaciones preparatorias de mi parte, decidí tolerar y no producir soluciones temporales, como la generación dinámica de plantillas, y solo esperé el cierre de los ZBXNEXT indicados al comienzo del artículo y recientemente se hizo.
Como se ve ahora
Para demostrar las nuevas características de Zabbix tomamos:
- Almacenamiento HPE MSA 2040 disponible a través de HTTP / HTTPS;
- Servidor Zabbix 4.0alpha9 instalado desde el repositorio oficial en CentOS 7.5.1804;
- Un script escrito en Python de la tercera versión y que nos brinda la capacidad de detectar componentes de almacenamiento (LLD) y devolver datos en formato JSON para analizar en el lado del servidor Zabbix usando la ruta JSON.
El elemento de datos principal será una "verificación externa" que llama al script con los argumentos necesarios y almacena los datos recibidos como texto.
Preparación
El script Python se instala de acuerdo con la
documentación y tiene una biblioteca de "solicitudes" en las dependencias de Python. Si tiene una distribución basada en RHEL, puede instalarla usando el administrador de paquetes yum:
[root@zabbix]
O usando pip:
[root@zabbix]
Puede probar el script desde el shell solicitando, por ejemplo, datos LLD sobre discos:
[root@zabbix]
Configuración del host
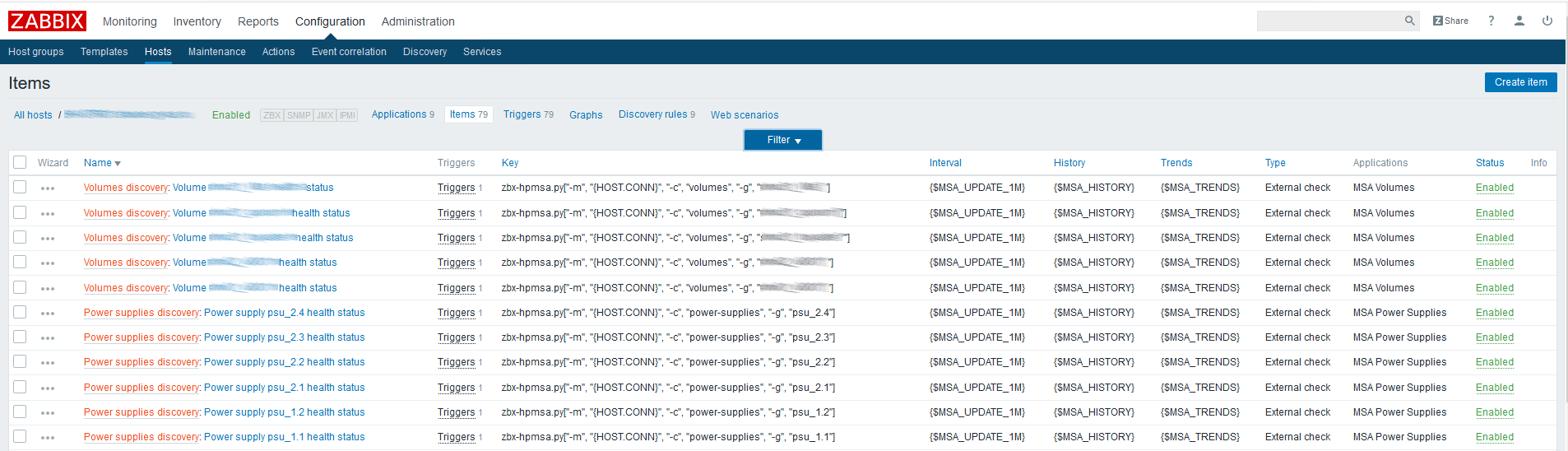
Primero debe crear elementos de datos primarios que contendrán todas las métricas que necesitamos. Como ejemplo, cree un elemento para discos físicos:
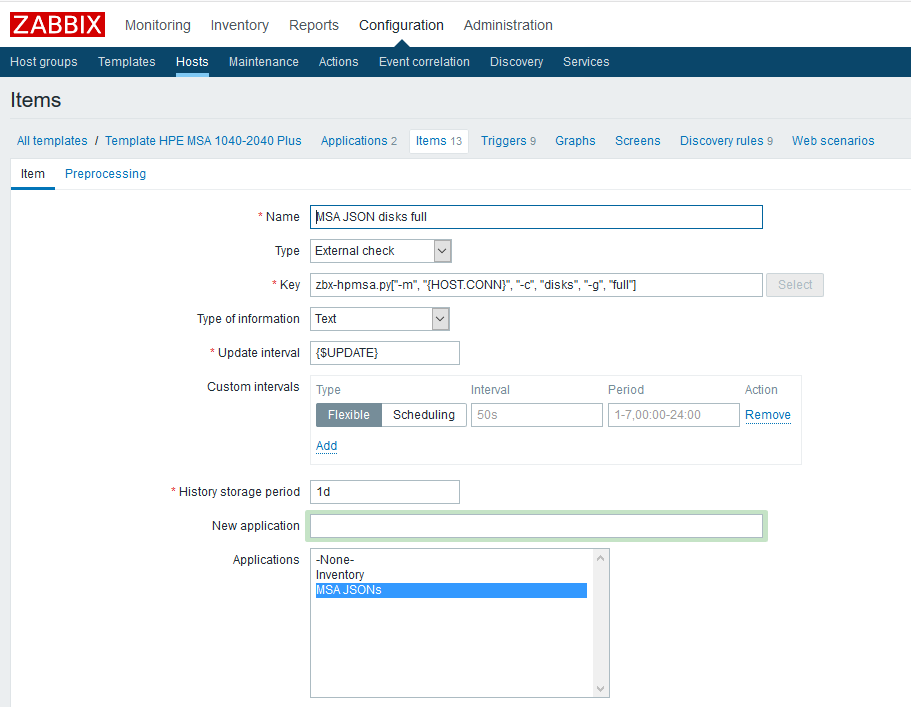 Nombre
Nombre : especifique arbitrariamente;
Tipo : verificación externa;
La clave es llamar al script con los parámetros necesarios (consulte la
documentación del
script en GitHub);
Tipo de información - texto;
Intervalo de actualización : el ejemplo utiliza una macro personalizada {$ UPDATE} que se expande al valor "1m";
El período de almacenamiento del historial es de un día. Creo que almacenar el elemento de datos padre ya no tiene sentido.
Verifique los últimos datos para el elemento creado:
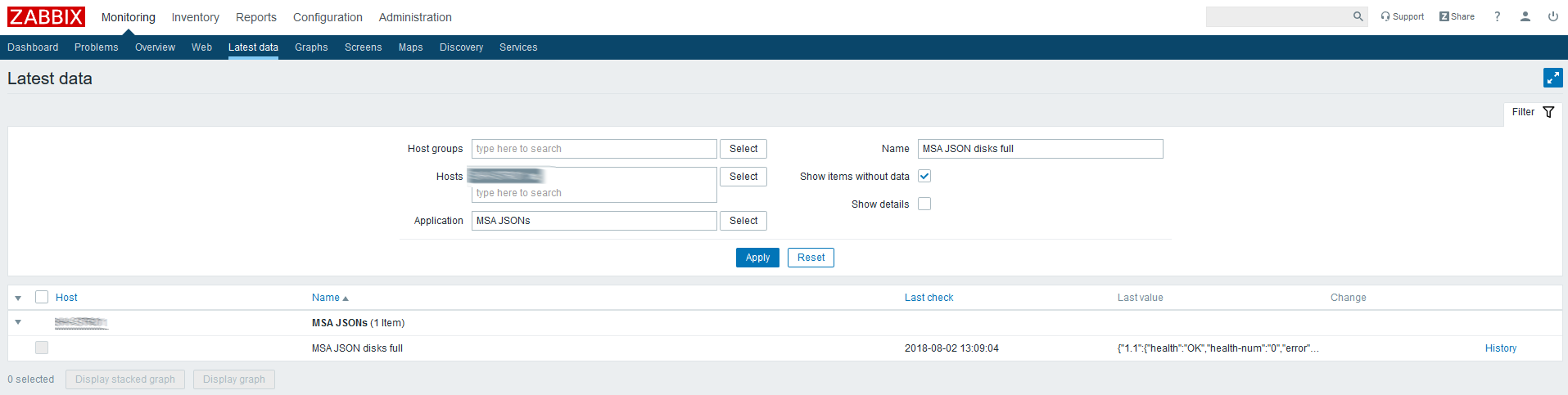
JSON viene, entonces todo se hace correctamente.
Lo siguiente será establecer reglas de descubrimiento que encontrarán todos los componentes disponibles para monitorear y crear elementos dependientes y disparadores. Continuando con el ejemplo con discos físicos, se verá así:
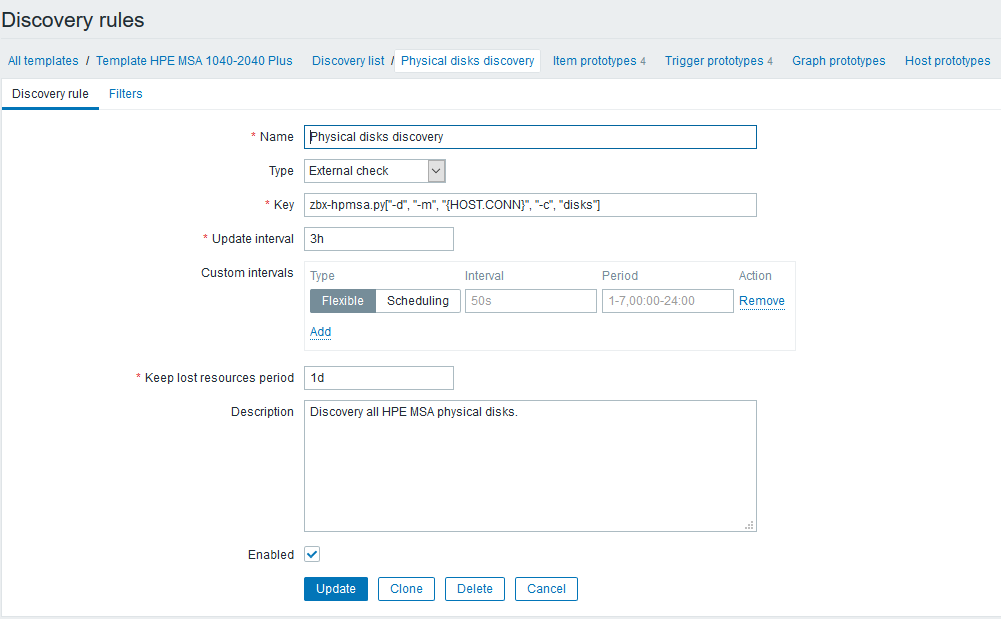
Después de crear la regla LLD, deberá crear prototipos de elementos de datos. Creemos un prototipo de este tipo, utilizando datos de temperatura como ejemplo:
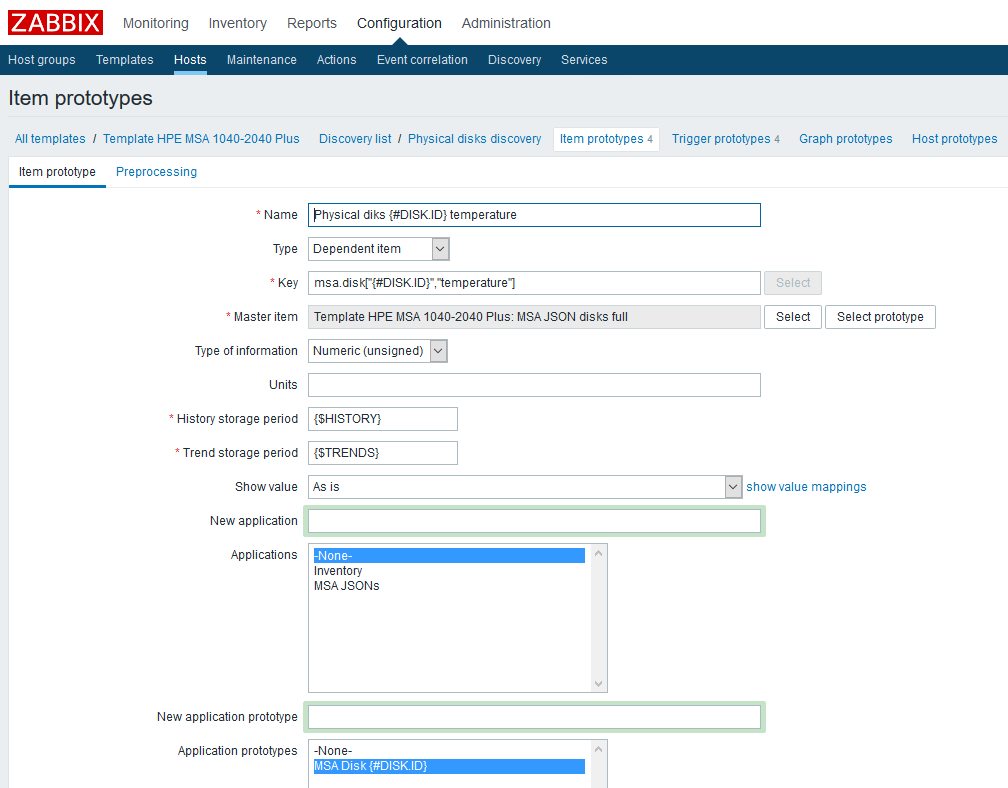 Nombre
Nombre : especifique arbitrariamente;
El tipo es dependiente. Como elemento de datos principal, seleccione el elemento correspondiente creado previamente;
Clave : mostraremos imaginación, pero debemos tener en cuenta que cada clave debe ser única, por lo tanto, incluiremos la macro LLD en ella;
Tipo de información , en este caso numérica;
Período de almacenamiento del historial : en el ejemplo, esta es una macro personalizada, indicada a su discreción;
El período de almacenamiento de tendencias es, nuevamente, una macro personalizada;
También agregué un prototipo de la "Aplicación": puede vincular convenientemente las métricas relacionadas con un componente.
En la pestaña "Preprocesamiento", cree un paso del tipo "Ruta JSON" con una regla que recupere las lecturas de temperatura:
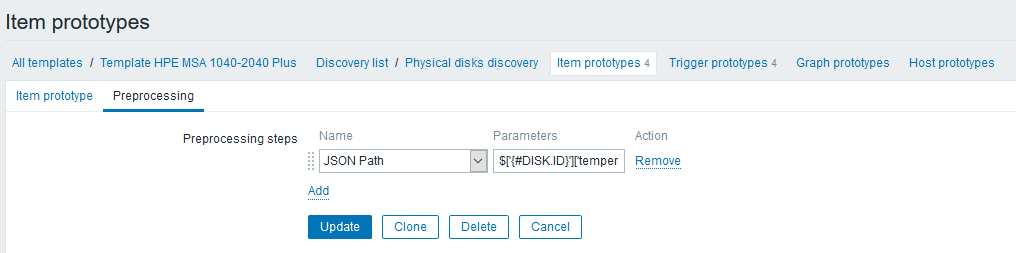
La expresión de paso se ve así:
$['{#DISK.ID}']['temperature']Tenga en cuenta que ahora puede usar macros LLD en la expresión, lo que no solo simplifica enormemente nuestro trabajo, sino que también hace que sea bastante fácil hacer esas cosas (ya habría sido enviado a la API de Zabbix antes).
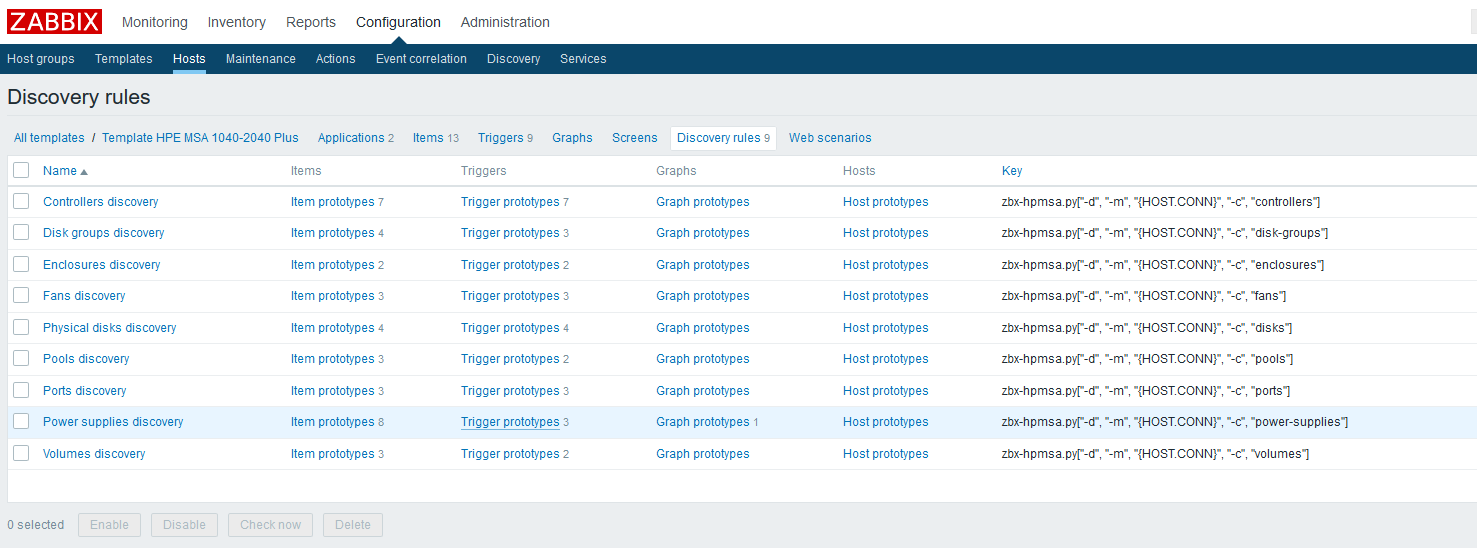
A continuación, por analogía con la temperatura, cree los prototipos restantes de elementos de datos:

En esta etapa, puede verificar el resultado yendo a "Datos recientes" en el host. Si todo le conviene allí, seguimos trabajando más. Terminé con la siguiente imagen:
Estamos esperando que se actualice la caché de configuración o la estamos empujando manualmente para actualizar:
[root@zabbix]
Después de eso, puede usar otro "truco" genial de la versión 4.0: el botón "Comprobar ahora" para ejecutar las reglas LLD creadas:
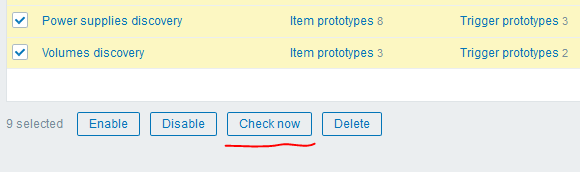
Obtuve el siguiente resultado:
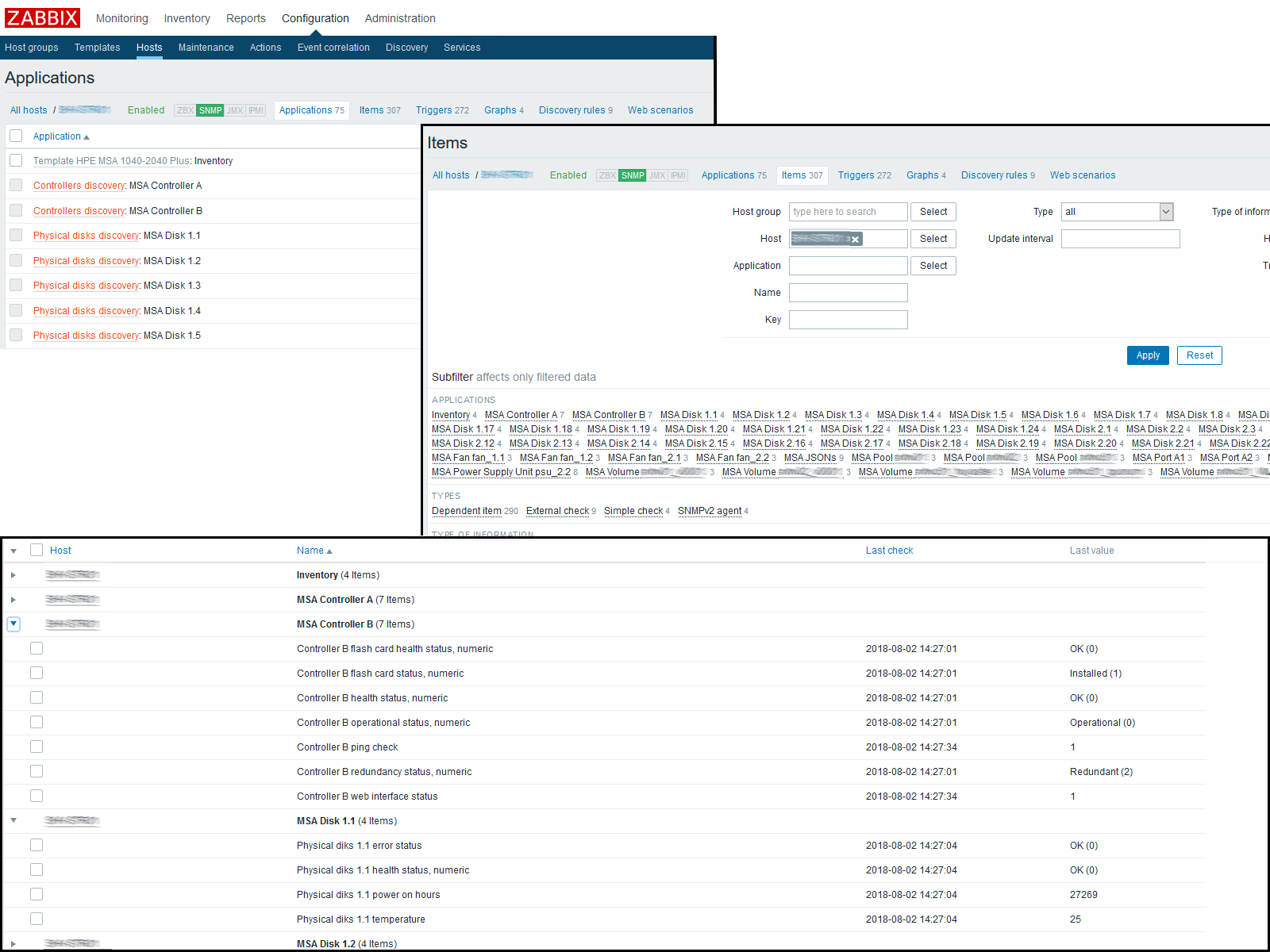
Conclusión
Como resultado, con solo nueve solicitudes a la API XML, pudimos obtener más de trescientas métricas de un nodo de red, dedicando un mínimo de tiempo y obteniendo la máxima flexibilidad. LLD nos dará la capacidad de detectar automáticamente nuevos componentes o actualizar los antiguos.
Gracias por leer, los enlaces a los materiales utilizados y también a la plantilla actual para el HPE MSA P2000G3 / 2040/2050 se pueden encontrar a continuación.
PD: Por cierto, en la versión 4.0 también se introduce un nuevo tipo de comprobaciones: un agente HTTP, que, junto con el preprocesamiento y la ruta XML, puede potencialmente evitar que usemos scripts externos: solo necesita resolver el problema de obtener un token de autenticación, que aún debe actualizarse periódicamente. Una de las opciones que veo es el uso de una macro global con este token, que se puede actualizar a través de la API de Zabbix por corona, incl. Las personas interesadas pueden desarrollar esta idea. =)
GuiónZabbix Share TemplateElementos de datos dependientesCamino JsonZabbix 4.0alpha9