Reescribir el código heredado como un viaje al dentista parece ser que todos entienden que deben ir, pero sin embargo postergan e intentan retrasar lo inevitable, porque saben que dolerá. En nuestro caso, las cosas fueron aún peores: tuvimos que reescribir la parte clave del sistema y, debido a circunstancias externas, no pudimos reemplazar los viejos fragmentos de código con partes nuevas en partes, solo de una vez y en su totalidad. Y todo esto en condiciones de falta de tiempo, recursos y documentación, pero con el requisito de gestión que como resultado de la "operación" ningún cliente debería sufrir.
Debajo del corte, la historia de cómo reescribimos el componente principal del producto con una historia de 17 años (!) De Scheme a Clojure, y todo funcionó de inmediato (bueno, casi :)).

17 años en el "reloj"
Solar Dozor es un sistema DLP con una historia muy larga. La primera versión apareció en 2001 como un servicio relativamente pequeño para filtrar el tráfico de correo. Durante 17 años, el producto se ha convertido en un gran paquete de software que recopila, filtra y analiza información heterogénea que se ejecuta dentro de la organización y protege el negocio de los clientes de las amenazas internas.
Al desarrollar la sexta versión de Solar Dozor, sacudimos el producto de manera decisiva, desechamos muletas viejas del código
y las reemplazamos por otras nuevas , actualizamos la interfaz, revisamos la funcionalidad en la dirección de las realidades modernas, en general, hicimos que el producto fuera arquitectónico y conceptualmente más holístico.
En ese momento, bajo el capó del Solar Dozor actualizado, había una enorme capa de código heredado monolítico: el servicio de filtrado, que durante todos estos 17 años se ha convertido gradualmente en una nueva funcionalidad, que incorpora soluciones a largo plazo y tareas comerciales a corto plazo, pero logró mantenerse dentro de la arquitectura original paradigmas
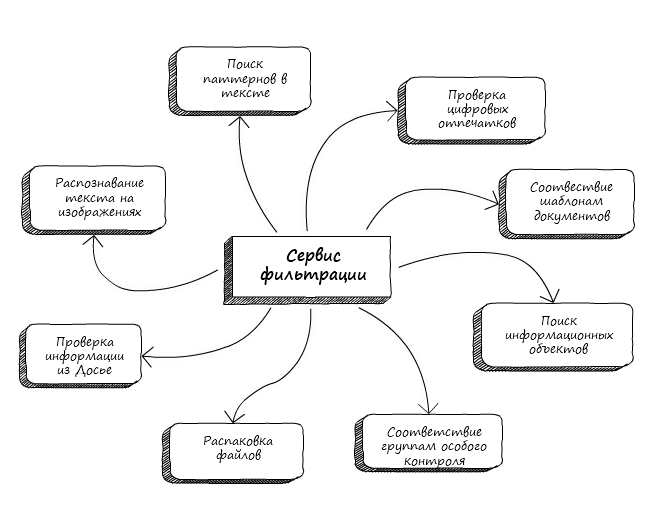 Servicio de filtrado
Servicio de filtradoNo es necesario decir que la introducción de cualquier cambio en un código tan antiguo requería especial delicadeza. Los desarrolladores tuvieron que tener mucho cuidado de no arruinar accidentalmente la funcionalidad creada hace una década. Además, se forzaron a introducir soluciones interesantes bastante nuevas en el lecho de arquitectura Procrustean, inventado en los albores de la era.
Entender que surgió la necesidad de actualizar el sistema apareció hace bastante tiempo. Pero faltaba claramente el espíritu de tocar un servicio de sistema enorme y antiguo.
No tratando de retrasar lo inevitable
Los productos con una larga historia de desarrollo tienen una característica interesante. No importa cuán extraño pueda parecer cualquier funcionalidad, si ha sobrevivido con éxito hasta nuestros días, esto significa que fue creado no a partir de las ideas teóricas de los desarrolladores, sino en respuesta a las necesidades específicas de los clientes.
En esta situación, no se puede hablar de ningún reemplazo por etapas. Era imposible cortar y rehacer la funcionalidad en partes, porque todas estas partes eran demandadas por los clientes, y no podíamos "cerrarlas para la reconstrucción". Era necesario eliminar cuidadosamente el servicio anterior y proporcionarle un reemplazo completo. Solo en su totalidad, solo a la vez.
Mejorar el proceso de desarrollo del producto, la velocidad de hacer cambios y mejorar la calidad en su conjunto era una condición necesaria pero no suficiente. La gerencia se preguntó qué beneficios aportaría el cambio a nuestros clientes. La respuesta fue expandir el conjunto de interfaces para interactuar con los nuevos sistemas de intercepción, lo que proporcionaría una retroalimentación rápida y permitiría a los interceptores responder más rápidamente a los incidentes.
También tuvimos que luchar para reducir el consumo de recursos, manteniendo (e idealmente aumentando) la tasa de procesamiento actual.
Un poco sobre relleno
A lo largo de la ruta de desarrollo del producto, el equipo de Solar Dozor tendió hacia un enfoque funcional. Esto lleva a una elección más bien no estándar de lenguajes de programación para una industria madura. En diferentes etapas de la vida del sistema, estos fueron Scheme, OCaml, Scala, Clojure, además de C (++) tradicional y Java.
El principal servicio de filtrado y otros servicios que ayudan a recibir y transmitir mensajes fueron escritos y desarrollados en el lenguaje Scheme en sus diversas implementaciones (Racket utilizó este último). No importa cuánto quiera cantar las alabanzas de la simplicidad y elegancia de este lenguaje, uno no puede dejar de admitir que su desarrollo cumple con más intereses académicos que los industriales. El retraso es especialmente notable en comparación con otros servicios más modernos de Solar Dozor, que se desarrollan principalmente en Scala y Clojure. El nuevo servicio también se decidió implementar en Clojure.
Clojure?!
Aquí, por supuesto, debo decir algunas palabras sobre por qué elegimos Clojure como el principal lenguaje de implementación.
En primer lugar, no quería perder la experiencia única del equipo que se desarrolla en Scheme. Clojure también es un miembro moderno de la familia de idiomas Lisp, y cambiar de un Lisp a otro suele ser bastante simple.
En segundo lugar, gracias a un compromiso con los principios funcionales y una serie de soluciones arquitectónicas únicas, Clojure proporciona una facilidad sin precedentes para manipular flujos de datos. También es importante que Clojure opere en la plataforma JVM, lo que significa que puede usar una base de datos conjunta con otros servicios en Java y Scala, así como también usar numerosas herramientas para la creación de perfiles y la depuración.
En tercer lugar, Clojure es un lenguaje conciso y expresivo. Esto facilita la lectura del código de otra persona y hace que sea fácil pasar el código a un compañero de equipo.
Finalmente, valoramos Clojure por su facilidad de creación de prototipos y el llamado desarrollo centrado en REPL. En casi cualquier situación donde haya dudas, simplemente puede crear un prototipo y continuar la discusión de una manera más sustantiva, con nuevos datos. El desarrollo orientado a REPL ofrece un retorno rápido, porque para verificar la funcionalidad de una función no es necesario volver a compilar el programa, sino incluso reiniciarlo (incluso si el programa es un servicio ubicado en un servidor remoto).
Mirando hacia el futuro, puedo decir: creo que no hemos perdido la elección.
Poniendo la funcionalidad poco a poco
Cuando hablamos de un reemplazo con todas las funciones, la primera pregunta que surge es la recopilación de información sobre la funcionalidad existente.
Esto se ha convertido en una tarea bastante interesante. Parece que aquí hay un sistema que funciona, aquí está la documentación para ello, aquí hay personas, expertos que trabajan estrechamente con el sistema y enseñan a otros sobre él. Pero para obtener una imagen completa de toda la variedad, y aún más, los requisitos para el desarrollo resultaron no ser tan simples.
El conjunto de requisitos no se considera en vano una disciplina de ingeniería separada. La implementación existente paradójicamente resulta ser el papel de algún "estándar corrupto". Muestra cómo y cómo debería funcionar, pero al mismo tiempo, los desarrolladores esperan que la nueva versión resulte mejor que la original. Es necesario separar los momentos necesarios para la implementación (generalmente relacionados con interfaces externas) de aquellos que pueden mejorarse de acuerdo con las expectativas de los usuarios.
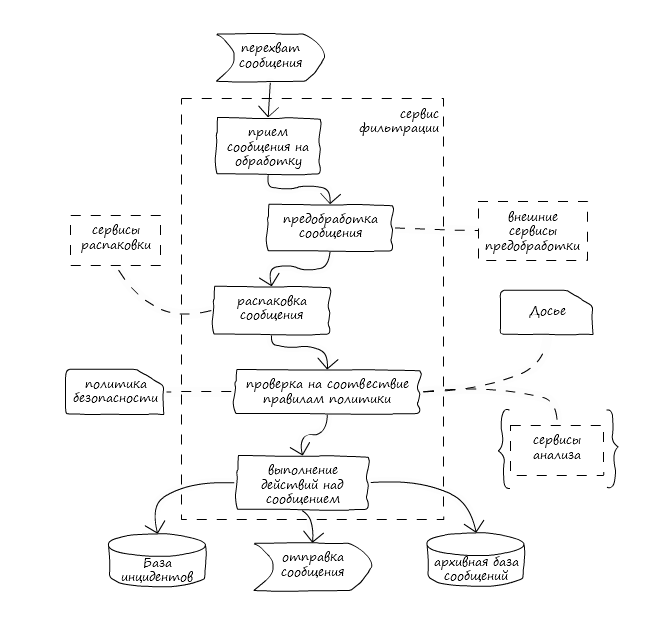 Proceso de filtrado de mensajes
Proceso de filtrado de mensajesLa documentación no es suficiente.
¿Cuál es la funcionalidad real del sistema? La respuesta a esta pregunta viene dada por varias descripciones, como documentación del usuario, manuales y documentos arquitectónicos, que reflejan la estructura del servicio en varios aspectos. Pero cuando se trata de eso, entiendes muy bien cuánto divergen las ideas y la realidad, cuántos matices y posibilidades no explicadas contiene el antiguo código.
Quiero contactar a todos los desarrolladores. ¡Cuida tu código! Este es tu activo más importante. No confíe en la documentación. Confíe solo en el código fuente.
Afortunadamente para nosotros, el código Scheme, debido a la naturaleza misma del lenguaje creado para la programación de la enseñanza, es bastante fácil de leer incluso para una persona no capacitada. Lo principal es acostumbrarse a algunas formas individuales que llevan un ligero toque de Lisp-arcaico.
Construye un proceso
El volumen de trabajo fue enorme y el equipo es muy pequeño. Por lo tanto, no fue sin dificultades organizativas. El flujo de trabajo de errores y solicitudes de arreglos (y mejoras menores) al antiguo servicio de filtrado ni siquiera se detuvo. Los desarrolladores regularmente tenían que distraerse con estas tareas.
Afortunadamente, fue posible evitar las solicitudes de incrustar nuevas piezas de gran funcionalidad en el filtro antiguo. Es cierto, bajo la promesa de integrar esta funcionalidad en un nuevo servicio. Sin embargo, el conjunto de tareas de lanzamiento crecía lenta pero seguramente.
Otro factor que agregó muchos problemas fueron las dependencias externas del servicio. Al ser un componente central, el servicio de filtrado utiliza numerosos servicios para desempacar y analizar contenido (textos, imágenes, huellas digitales, etc.). El trabajo con ellos fue parcialmente guiado por antiguas decisiones arquitectónicas. Durante el proceso de desarrollo, también fue necesario reescribir algunos componentes de una manera moderna (y algunos en un lenguaje moderno).
En tales condiciones, se construyó un sistema de pruebas funcionales paso a paso. Crecimos el servicio a un cierto estado, que fue reforzado por pruebas activas, y luego pasamos a implementar uno nuevo.
Iniciar desarrollo
En primer lugar, se implementó el marco principal del servicio, los mecanismos básicos para recibir mensajes y desempaquetar archivos. Este fue el mínimo absoluto necesario para comenzar a probar la velocidad y la corrección del servicio futuro.
Aquí debe aclararse que desempaquetar se refiere al proceso recursivo de obtener partes de un archivo y extraer información útil de ellas. Entonces, por ejemplo, un documento de Word puede contener no solo texto, sino también imágenes, un documento de Excel incrustado, objetos OLE y mucho más.
El mecanismo de desempaque no distingue entre el uso de bibliotecas internas, programas externos o servicios de terceros, proporcionando una interfaz única para organizar las canalizaciones de desempaque.
Otro cumplido hacia Clojure: obtuvimos un prototipo funcional, en el que delineamos los contornos de la funcionalidad futura, en el menor tiempo posible.
DSL para la política
El segundo paso fue agregar validación de mensajes utilizando políticas de filtrado.
Para describir las políticas, se creó un DSL especial, un lenguaje simple sin adornos, que nos permitió presentar las reglas y condiciones de la política en una forma más o menos legible para los humanos. Se llama MFLang.
El script en MFLang "sobre la marcha" se interpreta en el código Clojure, almacena en caché los resultados de las verificaciones en el mensaje, mantiene un registro detallado del trabajo (y, francamente, merece un artículo separado).
El uso de DSL apeló a los evaluadores. ¡Abajo excavando en la base de datos o en el formato de exportación! Ahora era posible enviar simplemente la regla generada para verificación, e inmediatamente quedó claro qué condiciones se verificaron. También fue posible obtener un registro detallado de verificación de mensajes, a partir del cual queda claro qué datos se tomaron para la verificación y qué resultados fueron devueltos por la función de comparación.
Podemos decir con confianza que MFLang resultó ser una herramienta absolutamente invaluable para la funcionalidad de depuración.
En plena fuerza
En la tercera etapa, se agregó un mecanismo para aplicar las acciones definidas por la política de seguridad al mensaje, así como enlaces de servicio que permiten la inclusión de nuevos componentes en el complejo Solar Dozor. Finalmente, pudimos lanzar el servicio y observar el resultado del trabajo en toda su diversidad.
La pregunta principal, por supuesto, era cómo la funcionalidad implementada corresponde a lo que se esperaba y cuán plenamente la implementa.
Observo que si la necesidad de pruebas unitarias no se ha cuestionado durante mucho tiempo (aunque las prácticas TDD en sí mismas todavía causan un debate vivo), la introducción de pruebas automatizadas de la funcionalidad del sistema a menudo se encuentra con una resistencia abierta.
El desarrollo de pruebas automáticas ayuda a todos los miembros del equipo a comprender mejor el proceso del producto, ahorra energía en la regresión e infunde cierta confianza en el rendimiento del producto. Pero el proceso de su creación está plagado de una serie de dificultades: recopilar los datos necesarios, determinar los indicadores de interés y las opciones de prueba. Los programadores inevitablemente perciben la creación de pruebas automáticas como un trabajo adicional opcional, que es mejor evitar si es posible.
Pero si logra superar la resistencia, se crea una base bastante sólida que le permite construir una idea de la salud del sistema.
Reemplazamos
Y entonces llegó un momento importante: incluimos el servicio en el paquete de entrega. Hasta ahora, junto con el anterior. Por lo tanto, un equipo podría realizar un cambio de versión y comparar el comportamiento de los servicios.
En este modo paralelo, el nuevo servicio de filtrado duró una versión. Durante este tiempo, logramos recopilar estadísticas adicionales sobre el trabajo, delinear e implementar las mejoras necesarias.
Finalmente, después de reunir nuestra fuerza, eliminamos el antiguo servicio de filtrado del producto. La etapa final de aceptación interna fue, los errores fueron corregidos, los desarrolladores comenzaron a cambiar gradualmente a otras tareas. De alguna manera imperceptible, sin alardes ni aplausos, se lanzó un producto con un nuevo servicio.
Y solo cuando comenzaron a surgir preguntas del equipo de implementación, se llegó al entendimiento: el servicio en el que habíamos estado trabajando durante tanto tiempo, ya estaba en los sitios y ... ¡funcionando!
Por supuesto, hubo errores y mejoras menores, sin embargo, después de un mes de uso activo, los clientes emitieron un veredicto: la introducción de un producto con una nueva versión del servicio de filtrado causó menos problemas que la implementación de versiones anteriores. Hey Parece que lo hicimos!
Al final
El desarrollo de un nuevo servicio de filtración tomó aproximadamente un año y medio. Más largo de lo que se pensaba originalmente, pero no crítico, especialmente porque la intensidad laboral real del trabajo coincidió con la evaluación inicial. Más importante aún, pudimos cumplir con las expectativas de la gerencia y los clientes y sentar las bases para futuras mejoras del producto. Ya en el estado actual, puede ver una reducción significativa en el consumo de recursos, a pesar de que el producto todavía tiene amplias oportunidades para la optimización.
Puedo agregar algunas impresiones personales.
Reemplazar un componente central con una larga historia es un soplo de aire fresco para el desarrollo. Por primera vez en mucho tiempo, existe la confianza de que el control del producto está volviendo a nuestras manos.
Es difícil sobreestimar los beneficios de un proceso de comunicación y desarrollo debidamente organizado. En este caso, era importante establecer un trabajo no tanto dentro del equipo como con numerosos consumidores del producto, que tenían preferencias y expectativas claras del sistema, y deseos vagos.
Para nosotros, esta fue la primera experiencia en el desarrollo de un proyecto a gran escala en Clojure. Inicialmente, había preocupaciones relacionadas con la naturaleza dinámica del lenguaje, la velocidad y la tolerancia a errores. Afortunadamente, no se materializaron.
Solo queda desear que el nuevo componente funcione durante tanto tiempo y con éxito como su predecesor.