Hola Habr Mi nombre es Vitaliy Kotov, trabajo en el departamento de pruebas de Badoo. Escribo muchas pruebas automáticas de UI, pero trabajo aún más con aquellos que han estado haciendo esto no hace mucho tiempo y aún no han logrado pisar todos los rastrillos.
Entonces, después de agregar mi propia experiencia y observaciones de otros tipos, decidí preparar una colección de "cómo escribir pruebas no vale la pena". Apoyé cada ejemplo con una descripción detallada, ejemplos de código y capturas de pantalla.
El artículo será interesante para los autores principiantes de pruebas de IU, pero los veteranos en este tema probablemente aprenderán algo nuevo, o simplemente sonreirán, recordándose a sí mismos "en su juventud". :)
Vamos!

Contenido
Localizadores sin atributos
Comencemos con un ejemplo simple. Como estamos hablando de pruebas de IU, los localizadores juegan un papel importante en ellas. Un localizador es una línea compuesta de acuerdo con una determinada regla y que describe uno o más elementos XML (en particular HTML).
Existen varios tipos de localizadores. Por ejemplo, los
localizadores CSS se utilizan para las hojas de estilo en cascada.
Los localizadores XPath se utilizan para trabajar con documentos XML. Y así sucesivamente.
Puede encontrar una lista completa de los tipos de localizadores utilizados por
Selenium en
seleniumhq.imtqy.com .
En las pruebas de IU, los localizadores se usan para describir los elementos con los que el controlador debe interactuar.
En casi cualquier inspector de navegador, es posible seleccionar el elemento que nos interesa y copiar su XPath. Se parece a esto:
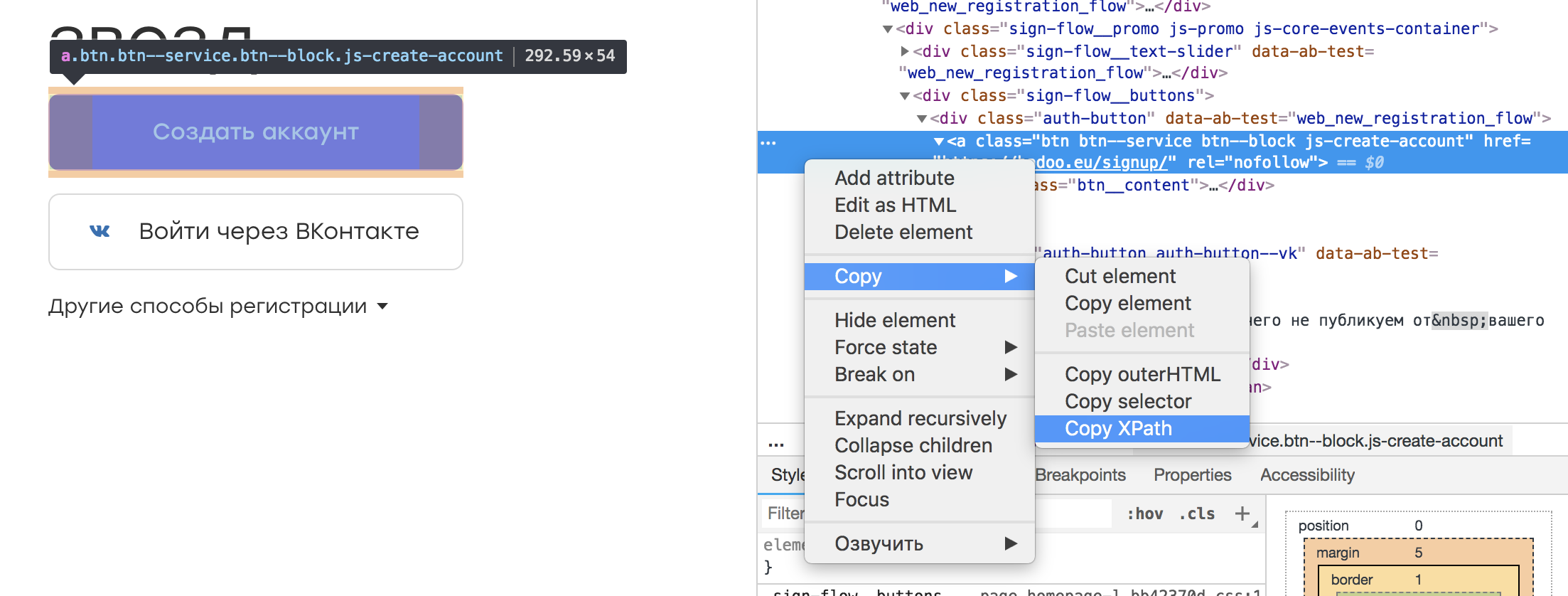
Resulta tal localizador:
/html/body/div[3]/div[1]/div[2]/div/div/div[2]/div[1]/a
Parece que no hay nada de malo con tal localizador. Después de todo, podemos guardarlo en alguna constante o campo de la clase, que por su nombre transmitirá la esencia del elemento:
@FindBy(xpath = "/html/body/div[3]/div[1]/div[2]/div/div/div[2]/div[1]/a") public WebElement createAccountButton;
Y ajuste el texto de error correspondiente en caso de que no se encuentre el elemento:
public void waitForCreateAccountButton() { By by = By.xpath(this.createAccountButton); WebDriverWait wait = new WebDriverWait(driver, timeoutInSeconds); wait .withMessage(“Cannot find Create Account button.”) .until( ExpectedConditions.presenceOfElementLocated(by) ); }
Este enfoque tiene una ventaja: no hay necesidad de aprender XPath.
Sin embargo, hay una serie de desventajas. En primer lugar, al cambiar el diseño no hay garantía de que el elemento en dicho localizador siga siendo el mismo. Es posible que otro tome su lugar, lo que conducirá a circunstancias imprevistas. En segundo lugar, la tarea de las pruebas automáticas es buscar errores y no monitorear los cambios de diseño. Por lo tanto, la adición de algún contenedor u otros elementos más altos en el árbol no debería afectar nuestras pruebas. De lo contrario, nos llevará bastante tiempo actualizar los localizadores.
Conclusión: debe crear localizadores que describan correctamente el elemento y sean resistentes a los cambios de diseño fuera de la parte probada de nuestra aplicación. Por ejemplo, puede enlazar a uno o más atributos de un elemento:
//a[@rel=”createAccount”]
Tal localizador es más fácil de percibir en el código, y se romperá solo si desaparece "rel".
Otra ventaja de dicho localizador es la capacidad de buscar en el repositorio de plantillas con el atributo especificado. ¿Pero qué buscar si el localizador se ve en el ejemplo original? :)
Si inicialmente en la aplicación los elementos no tienen ningún atributo o se configuran automáticamente (por ejemplo, debido a la
ofuscación de clases), vale la pena discutirlo con los desarrolladores. No deberían estar menos interesados en automatizar las pruebas de productos y seguramente lo conocerán y le ofrecerán una solución.
Verifique si hay elementos faltantes
Cada usuario de Badoo tiene su propio perfil. Contiene información sobre el usuario: (nombre, edad, fotos) e información sobre con quién quiere chatear el usuario. Además, es posible indicar sus intereses.
Supongamos que alguna vez tuvimos un error (aunque, por supuesto, esto no es así :)). El usuario en su perfil eligió intereses. Al no encontrar un interés adecuado en la lista, decidió hacer clic en "Más" para actualizar la lista.
Comportamiento esperado: los viejos intereses deberían desaparecer, deberían aparecer otros nuevos. Pero en su lugar apareció un "error inesperado":
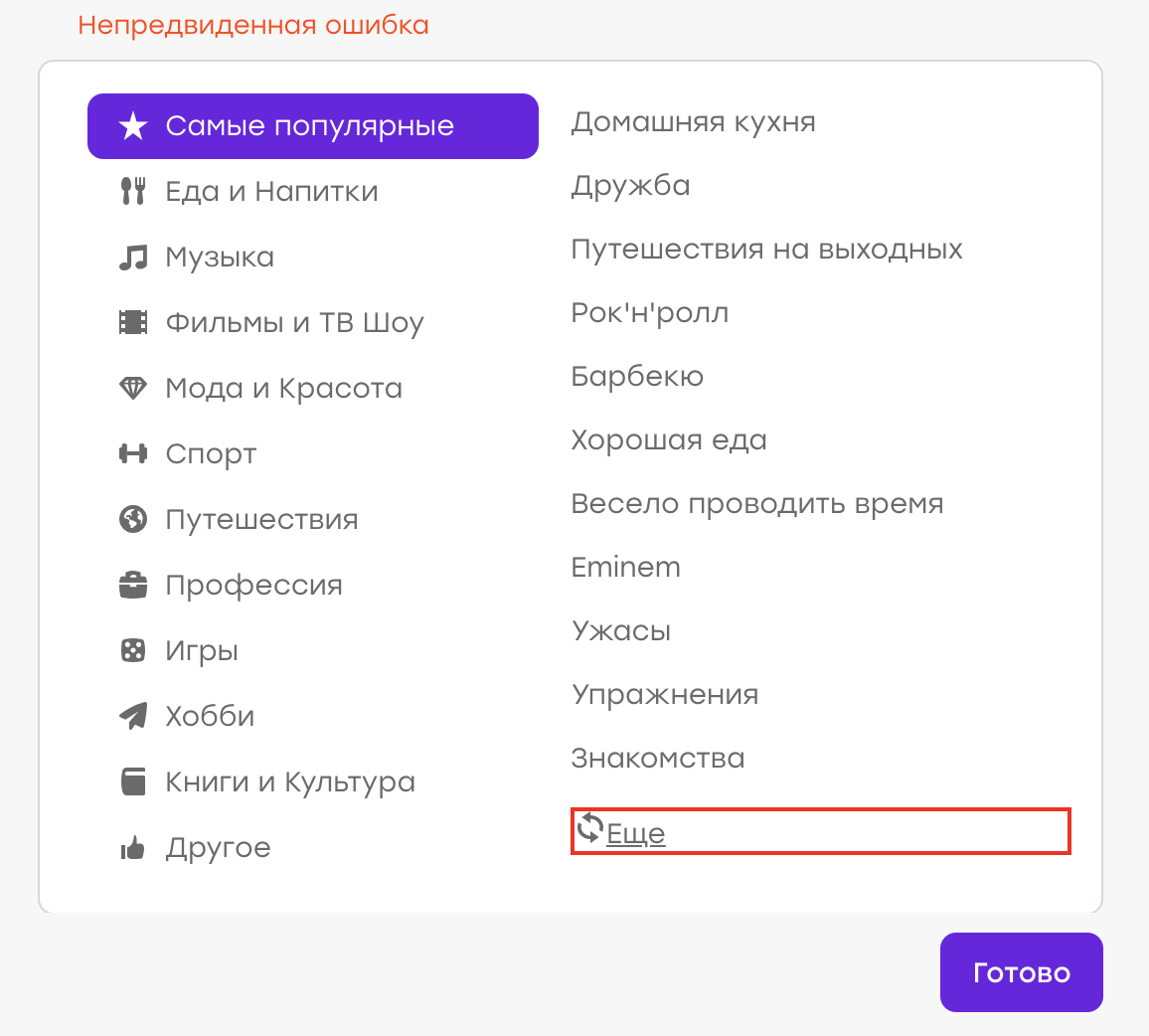
Resultó que había un problema en el lado del servidor, la respuesta no era la misma y el cliente procesó este asunto mostrando una notificación.
Nuestra tarea es escribir una prueba automática que verifique este caso.
Escribimos aproximadamente el siguiente script:
- Abrir perfil
- Abrir lista de intereses
- Haga clic en el botón "Más"
- Asegúrese de que el error no apareció (por ejemplo, no hay ningún elemento div.error)
Realizamos tal prueba. Sin embargo, sucede lo siguiente: después de unos días / meses / años, el error vuelve a aparecer, aunque la prueba no detecta nada. Por qué
Todo es bastante simple: durante la aprobación exitosa de la prueba, el localizador del elemento por el que buscamos el texto de error ha cambiado. Hubo una refactorización de las plantillas y en lugar de la clase "error" obtuvimos la clase "error_new".
Durante la refactorización, la prueba continuó funcionando como se esperaba. El elemento div.error no apareció; no había razón para la caída. Pero ahora el elemento "div.error" no existe en absoluto, por lo tanto, la prueba nunca fallará, pase lo que pase en la aplicación.
Conclusión: es mejor probar la operabilidad de la interfaz con verificaciones positivas. En nuestro ejemplo, debemos esperar que la lista de intereses haya cambiado.
Hay situaciones en las que una prueba negativa no se puede reemplazar por una positiva. Por ejemplo, cuando interactúa con algún elemento, no sucede nada en una situación "buena" y aparece un error en una situación "mala". En este caso, debe encontrar una manera de simular un escenario "malo" y escribir una prueba automática también. Por lo tanto, verificamos que el elemento de error aparece en el caso negativo y, por lo tanto, monitoreamos la relevancia del localizador.
Verificar un artículo
¿Cómo asegurarse de que la interacción de prueba con la interfaz fue exitosa y que todo funciona? Esto se ve con mayor frecuencia en los cambios que se han producido en esta interfaz.
Considera un ejemplo. Debes asegurarte de que al enviar un mensaje aparezca en el chat:
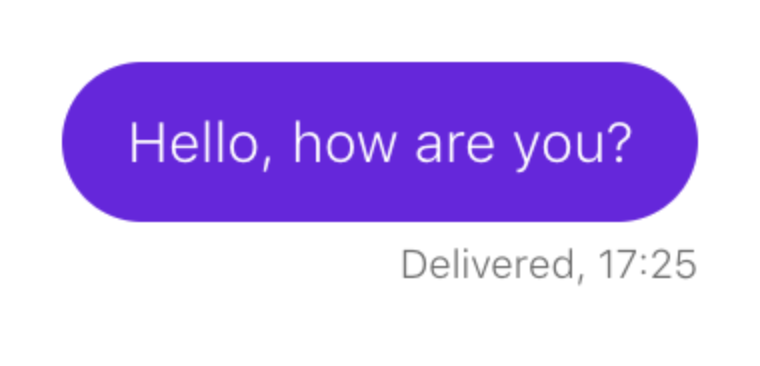
El guión se parece a esto:
- Abrir perfil de usuario
- Abrir chat con él
- Escribir un mensaje
- Enviar
- Espera a que aparezca el mensaje.
Describimos tal escenario en nuestra prueba. Supongamos que un mensaje de chat coincide con un localizador:
p.message_text
Así es como verificamos que aparece el elemento:
this.waitForPresence(By.css('p.message_text'), "Cannot find sent message.");
Si nuestra espera funciona, entonces todo está en orden: se dibujan mensajes de chat.
Como habrás adivinado, después de un tiempo, el envío de mensajes de chat se interrumpe, pero nuestra prueba continúa funcionando sin interrupciones. Vamos a hacerlo bien.
Resulta que el día antes de que apareciera un nuevo elemento en el chat: un texto que le pide al usuario que resalte el mensaje si de repente pasa desapercibido:
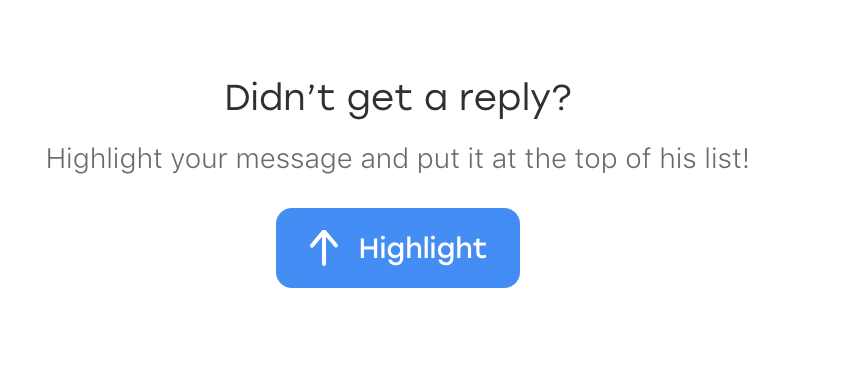
Y, lo más divertido, también cae bajo nuestro localizador. Solo tiene una clase adicional que lo distingue de los mensajes enviados:
p.message_text.highlight
Nuestra prueba no se rompió cuando apareció este bloque, pero la marca "esperar a que aparezca el mensaje" dejó de ser relevante. El elemento que fue un indicador de un evento exitoso ahora siempre está ahí.
Conclusión: si la lógica de la prueba se basa en verificar la apariencia de algún elemento, es necesario verificar que no exista dicho elemento antes de nuestra interacción con la interfaz de usuario.
- Abrir perfil de usuario
- Abrir chat con él
- Asegúrese de que no haya mensajes enviados
- Escribir un mensaje
- Enviar
- Espera a que aparezca el mensaje.
Datos aleatorios
Muy a menudo, las pruebas de IU funcionan con formularios en los que ingresan datos. Por ejemplo, tenemos un formulario de registro:
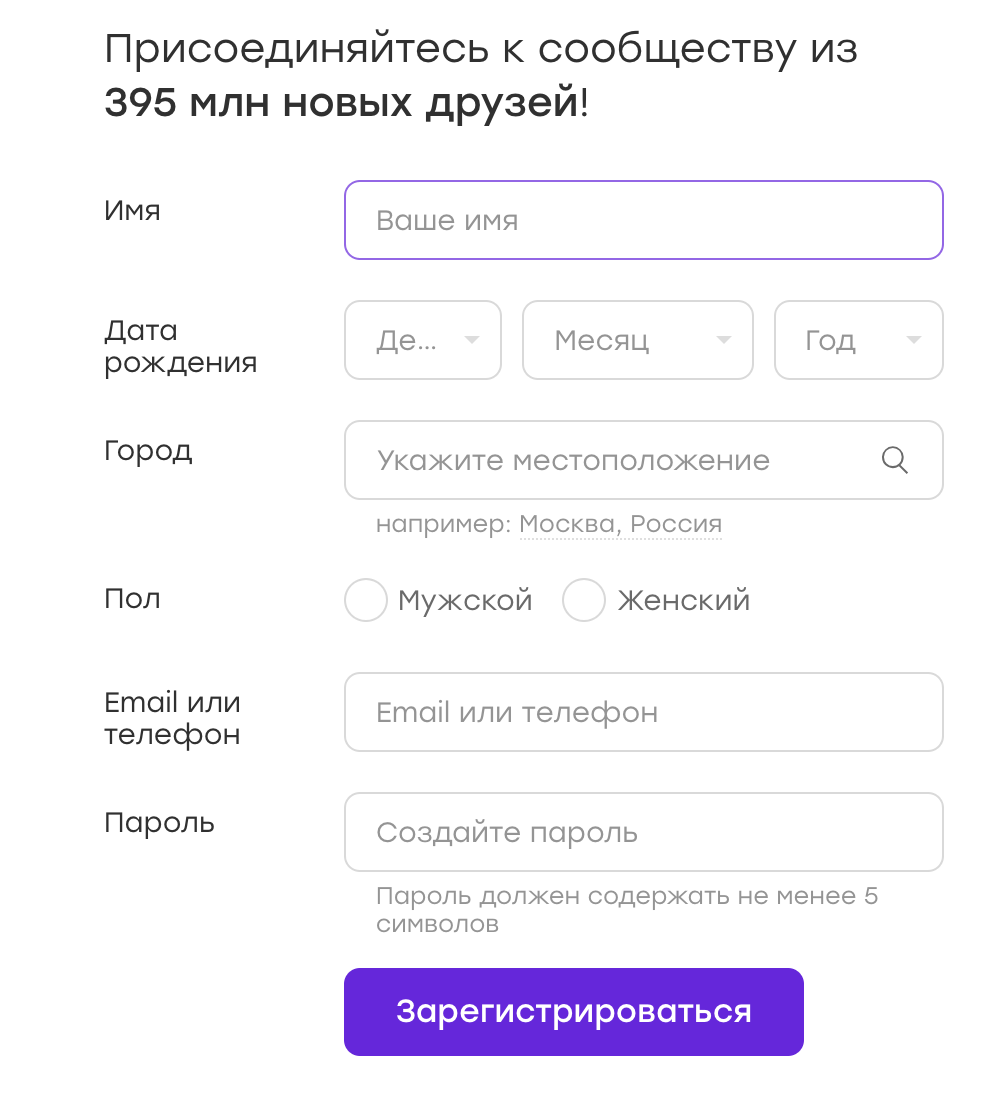
Los datos para tales pruebas se pueden almacenar en configuraciones o codificar en una prueba. Pero a veces se me ocurre la idea: ¿por qué no aleatorizar los datos? ¡Esto es bueno, cubriremos más casos!
Mi consejo: no lo hagas. Y ahora te diré por qué.
Supongamos que nuestra prueba está registrada en Badoo. Decidimos que elegiremos el género del usuario al azar. Al momento de escribir la prueba, el flujo de registro para la niña y el niño no es diferente, por lo que nuestra prueba se aprueba con éxito.
Ahora imagine que después de un tiempo el flujo de registro se vuelve diferente. Por ejemplo, le damos a la niña bonos gratis inmediatamente después del registro, sobre lo cual le notificamos con una superposición especial.
En la prueba, no hay lógica para cerrar la superposición, pero, a su vez, interfiere con cualquier otra acción prescrita en la prueba. Obtenemos una prueba que cae en el 50% de los casos. Cualquier herramienta de automatización confirmará que las pruebas de IU no son inherentemente estables por naturaleza. Y esto es normal, uno tiene que vivir con él, atacando constantemente entre la lógica redundante "para todas las ocasiones" (que estropea notablemente la legibilidad del código y complica su soporte) y esta inestabilidad en sí misma.
La próxima vez, cuando caiga la prueba, es posible que no tengamos tiempo para enfrentarla. Simplemente lo reiniciamos y vemos que ha pasado. Decidimos que en nuestra aplicación todo funciona como debería y es una prueba inestable. Y cálmate.
Ahora sigamos adelante. ¿Qué pasa si esta superposición se rompe? La prueba continuará pasando en el 50% de los casos, lo que retrasa significativamente la búsqueda del problema.
Y es bueno cuando, debido a la aleatorización de datos, creamos una situación de "50 por 50". Pero sucede de manera diferente. Por ejemplo, antes de registrarse, una contraseña se consideraba aceptable con al menos tres caracteres de longitud. Escribimos código que aparece con una contraseña aleatoria no menor a tres caracteres (a veces tres caracteres y otras veces más). Y luego la regla cambia, y la contraseña ya debe contener al menos cuatro caracteres. ¿Cuál es la probabilidad de una caída en este caso? Y, si nuestra prueba detecta un error real, ¿qué tan rápido lo resolveremos?
Es especialmente difícil trabajar con pruebas en las que se ingresan muchos datos aleatorios: nombre, género, contraseña, etc. En este caso, también hay muchas combinaciones diferentes, y si se produce un error en alguna de ellas, generalmente es difícil notarlo.
Conclusión Como escribí anteriormente, aleatorizar datos es malo. Es mejor cubrir más casos a expensas de los proveedores de datos, sin olvidar las
clases de equivalencia , por supuesto. Pasar las pruebas llevará más tiempo, pero puedes combatirlo. Pero nos aseguraremos de que si hay un problema, se detectará.
Atomicidad de las pruebas (parte 1)
Veamos el siguiente ejemplo. Estamos escribiendo una prueba que verifica el contador de usuarios en el pie de página.

El escenario es simple:
- Aplicación abierta
- Encontrar contador de pie de página
- Asegúrate de que sea visible
Llamamos a tal prueba testFooterCounter y la ejecutamos. Luego se hace necesario verificar que el contador no muestre cero. Agregamos esta prueba a una prueba existente, ¿por qué no?
Pero luego se hace necesario verificar que en el pie de página haya un enlace a la descripción del proyecto (el enlace "Acerca de nosotros"). ¿Escribir una nueva prueba o agregar a una existente? En el caso de una nueva prueba, tendremos que volver a subir la aplicación, preparar al usuario (si revisamos el pie de página en la página autorizada), iniciar sesión, en general, pasar un tiempo precioso. En tal situación, cambiar el nombre de la prueba a testFooterCounterAndLinks parece una buena idea.
Por un lado, este enfoque tiene ventajas: ahorrar tiempo, almacenar todos los controles de alguna parte de nuestra aplicación (en este caso, pie de página) en un solo lugar.
Pero hay un notable menos. Si la prueba falla en la primera prueba, no verificaremos el resto del componente. Suponga que una prueba falla en alguna rama, no por inestabilidad, sino por un error. Que hacer ¿Devuelve una tarea que describe solo este problema? Luego corremos el riesgo de obtener una tarea con una solución de solo este error, ejecutamos una prueba y descubrimos que el componente también se rompe aún más, en otro lugar. Y puede haber muchas iteraciones de este tipo. Patear un boleto de ida y vuelta en este caso tomará mucho tiempo y será ineficaz.
Conclusión: si es posible, atomice los cheques. En este caso, incluso teniendo un problema en un caso, verificaremos todos los demás. Y, si tiene que devolver el boleto, podemos describir inmediatamente todas las áreas problemáticas.
Atomicidad de las pruebas (parte 2)
Considere otro ejemplo. Estamos escribiendo una prueba de chat que verifica la siguiente lógica. Si los usuarios tienen simpatía mutua, el siguiente bloque de promoción aparece en el chat:

El escenario es el siguiente:
- Vote por el usuario A para el usuario B
- Vote por el usuario B para el usuario A
- El usuario A abre el chat con el usuario B
- Confirme que la unidad esté en su lugar
Durante algún tiempo, la prueba funciona con éxito, pero luego sucede lo siguiente ... No, esta vez la prueba no pierde ningún error. :)
Después de un tiempo, descubrimos que hay otro error no relacionado con nuestra prueba: si abre un chat, ciérrelo inmediatamente y vuelva a abrirlo, el bloqueo desaparece. No es el caso más obvio, y en la prueba, por supuesto, no lo previmos. Pero decidimos que necesitamos cubrirlo también.
Surge la misma pregunta: ¿escribir otra prueba o insertar una prueba en una existente? Escribir uno nuevo parece inapropiado, porque el 99% del tiempo hará lo mismo que el existente. Y decidimos agregar la prueba a la prueba que ya está allí:
- Vote por el usuario A para el usuario B
- Vote por el usuario B para el usuario A
- El usuario A abre el chat con el usuario B
- Confirme que la unidad esté en su lugar
- Cerrar chat
- Chat abierto
- Confirme que la unidad esté en su lugar
Puede surgir un problema cuando, por ejemplo, refactorizamos una prueba después de mucho tiempo. Por ejemplo, se realizará un rediseño en un proyecto, y tendrá que reescribir muchas pruebas.
Abriremos la prueba e intentaremos recordar lo que verifica. Por ejemplo, una prueba se llama testPromoAfterMutualAttraction. ¿Entendemos por qué la apertura y el cierre del chat se escriben al final? Lo más probable es que no. Especialmente si esta prueba no fue escrita por nosotros. ¿Dejaremos esta pieza? Quizás sí, pero si hay algún problema con él, es probable que simplemente lo borremos. Y la verificación se perderá simplemente porque su significado no será obvio.
Veo dos soluciones aquí. Primero: aún haga la segunda prueba y llámela testCheckBlockPresentAfterOpenAndCloseChat. Con tal nombre, quedará claro que no solo estamos haciendo un cierto conjunto de acciones, sino que estamos haciendo un control muy consciente, porque hubo una experiencia negativa. La segunda solución es escribir un comentario detallado en el código sobre por qué estamos haciendo esta prueba en esta prueba en particular. También es recomendable indicar el número de error en el comentario.
Error al hacer clic en un elemento existente
¡El siguiente ejemplo me arrojó
bbidox , por lo que es una gran ventaja en el karma!
Hay una situación muy interesante cuando el código de prueba ya se convierte en ... un marco. Supongamos que tenemos un método como este:
public void clickSomeButton() { WebElement button_element = this.waitForButtonToAppear(); button_element.click(); }
En algún momento, algo extraño comienza a suceder con este método: la prueba se bloquea cuando intentas hacer clic en un botón. Abrimos la captura de pantalla tomada en el momento en que se bloqueó la prueba, y vemos que hay un botón en la captura de pantalla y el método waitForButtonToAppear funcionó con éxito. Pregunta: ¿qué hay de malo con el clic?
La parte más difícil en esta situación es que la prueba a veces puede tener éxito. :)
Vamos a hacerlo bien. Supongamos que el botón considerado en el ejemplo se encuentra en una superposición de este tipo:
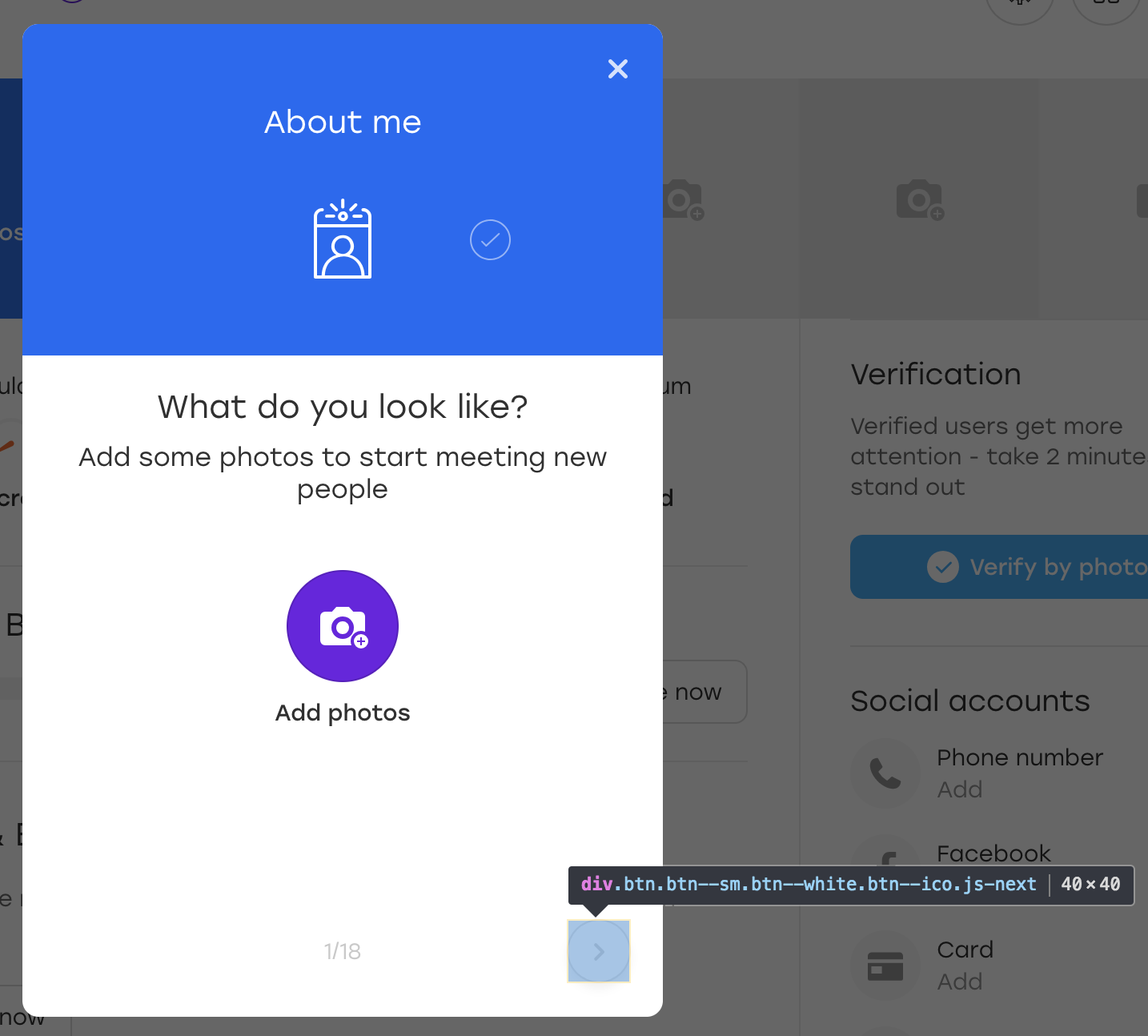
Esta es una superposición especial a través de la cual un usuario en nuestro sitio web puede completar información sobre sí mismo. Cuando hace clic en el botón de superposición resaltado, el siguiente bloque parece llenarse.
Por diversión, agreguemos una clase OLOLO adicional para este botón:
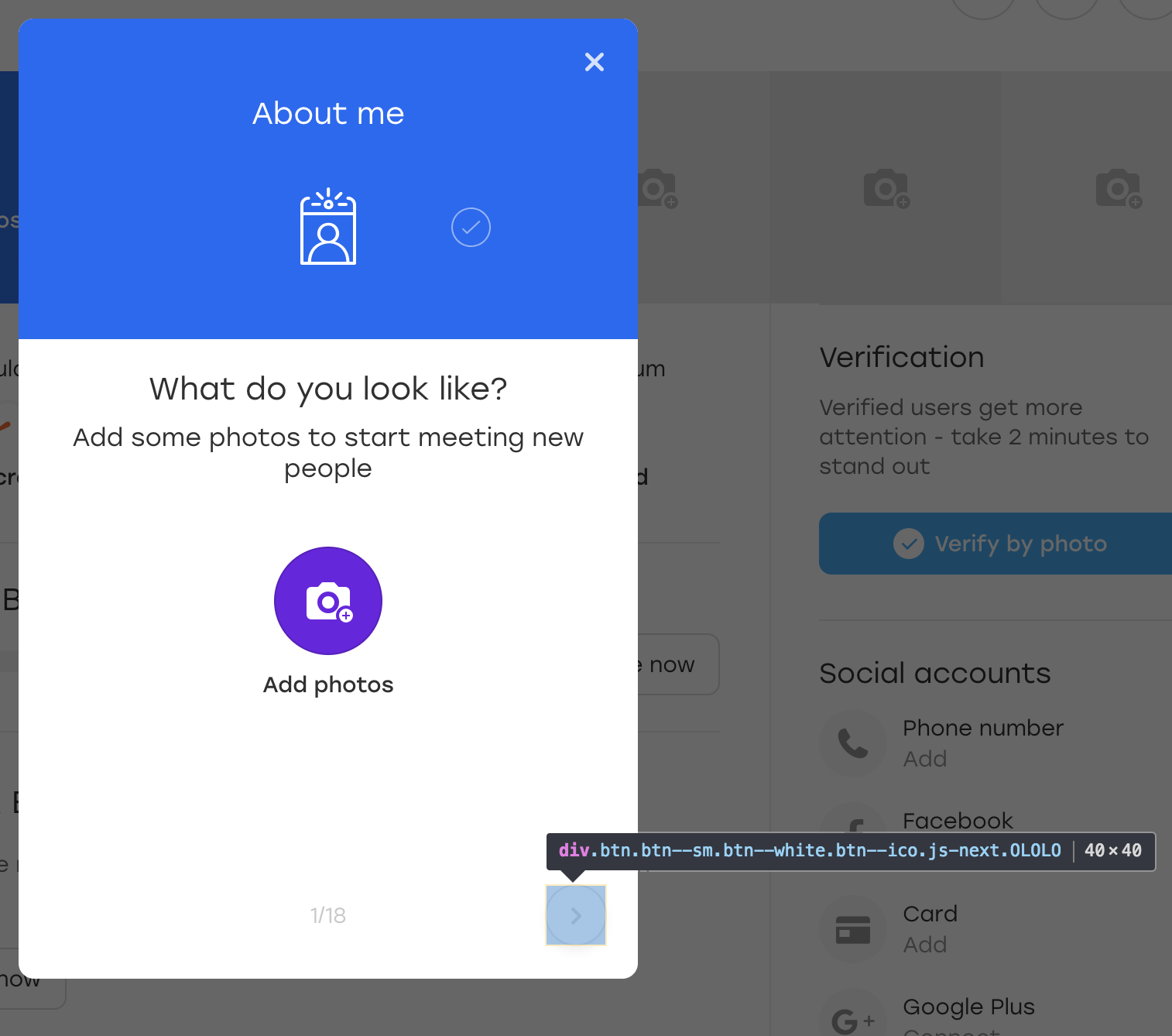
Después de lo cual hacemos clic en este botón. Visualmente, nada ha cambiado, pero el botón en sí se ha mantenido en su lugar:
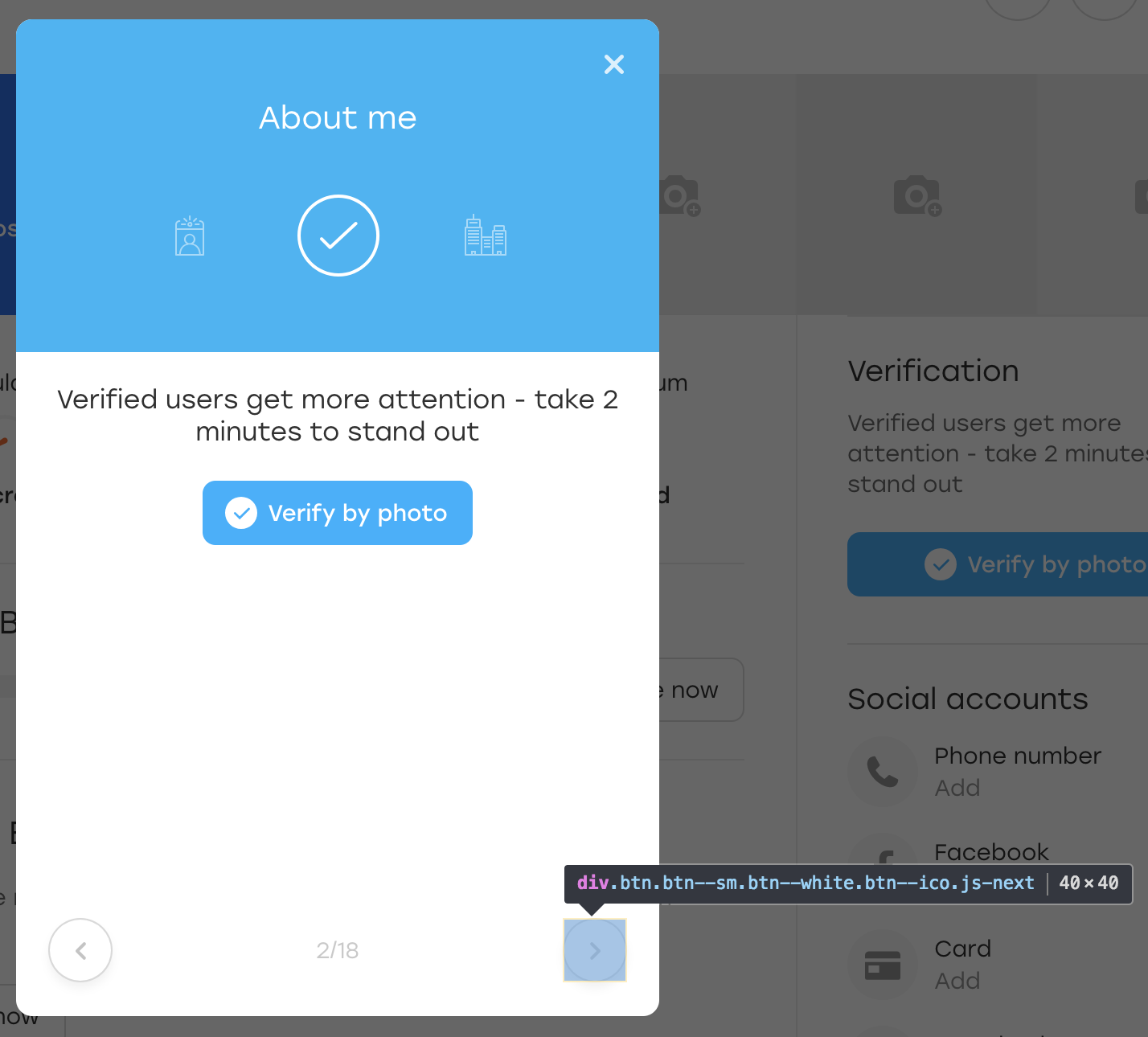
Que paso De hecho, cuando JS volvió a dibujar el bloque para nosotros, también volvió a dibujar el botón. Todavía está disponible en el mismo localizador, pero este es otro botón. Esto se evidencia por la falta de la clase OLOLO que agregamos.
En el código anterior, almacenamos el elemento en la variable $ element. Si un elemento se regenera durante este tiempo, puede que no sea visible visualmente, pero ya no puede hacer clic en él; el método click () fallará.
Hay varias soluciones:
- Haga clic de ajuste en el bloque de prueba y en el elemento de reconstrucción de captura
- Agregue un botón a un atributo para indicar que ha cambiado
Texto de error
Finalmente, un punto simple, pero no menos importante.
Este ejemplo se aplica no solo a las pruebas de IU, sino que también ocurre con mucha frecuencia en ellas. Por lo general, cuando escribe una prueba, se encuentra en el contexto de lo que está sucediendo: describe la verificación después de la verificación y comprende su significado. Y escribes textos de error en el mismo contexto:
WebElement element = this.waitForPresence(By.css("a.link"), "Cannot find button");
¿Qué podría ser incomprensible en este código? La prueba espera la aparición de un botón y, si no está allí, cae naturalmente.
Ahora imagine que el autor de la prueba está de baja por enfermedad, y su colega se ocupa de las pruebas. Y luego deja caer la prueba testQuestionsOnProfile y escribe este mensaje: "No se puede encontrar el botón". Un colega debe comprender lo que está sucediendo lo más rápido posible, porque el lanzamiento llegará pronto.
¿Qué tendrá que hacer él?
No tiene sentido abrir la página en la que se realizó la prueba y verificar el localizador "a.link": no hay ningún elemento. Por lo tanto, debe estudiar cuidadosamente la prueba y descubrir qué verifica.
Sería mucho más simple con un texto de error más detallado: "No se puede encontrar el botón de envío en la superposición de preguntas". Con tal error, puede abrir inmediatamente la superposición y ver dónde fue el botón.
Salida dos. En primer lugar, vale la pena pasar el texto de error a cualquier método de su marco de prueba, y es un parámetro obligatorio para que no haya tentación de olvidarlo. En segundo lugar, el texto del error debe hacerse detallado. Esto no siempre significa que debe ser largo, es suficiente para dejar en claro qué salió mal en la prueba.
¿Cómo entender que el texto del error está bien escrito? Muy simple Imagine que su aplicación se ha roto y necesita ir a los desarrolladores y explicar qué y dónde se rompió. Si solo les dice lo que está escrito en el texto del error, ¿lo entenderán?
Resumen
Escribir un guión de prueba es a menudo una actividad interesante. Al mismo tiempo, perseguimos muchos objetivos. Nuestras pruebas deberían:
- cubrir tantos casos como sea posible
- trabajar lo más rápido posible
- para ser entendido
- solo expande
- fácil de mantener
- pedir pizza
- y así sucesivamente ...
Es especialmente interesante trabajar con pruebas en un proyecto en constante evolución y cambio, en el que deben actualizarse constantemente: agregar algo y cortar algo. Es por eso que vale la pena pensar en algunos puntos de antemano y no siempre apresurarse con las decisiones. :)
Espero que mis consejos lo ayuden a evitar algunos problemas y lo hagan reflexivo en los estudios de casos. Si al público le gusta el artículo, intentaré recopilar algunos ejemplos más aburridos. Mientras tanto, ¡chao!