¡Es hora de reponer la alcancía de buenos informes en ruso sobre Machine Learning! ¡La alcancía en sí no se repondrá!
Esta vez nos familiarizaremos con
la fascinante historia de
Andrei Boyarov sobre el reconocimiento de escenas. Andrey es un investigador de visión por computadora que se dedica a la visión artificial en Mail.Ru Group.
El reconocimiento de escenas es una de las áreas ampliamente utilizadas de la visión artificial. Esta tarea es más complicada que el reconocimiento estudiado de objetos: la escena es un concepto más complejo y menos formalizado, es más difícil distinguir las características. La tarea de reconocer vistas se deriva del reconocimiento de escenas: debe resaltar los lugares conocidos en la foto, asegurando un bajo nivel de falsos positivos.
Estos son
30 minutos de video de la conferencia Smart Data 2017. El video es conveniente para ver en casa y mientras viaja. Para aquellos que no están listos para sentarse tanto en la pantalla, o que prefieren percibir la información en forma de texto, aplicamos un descifrado de texto completo, diseñado en forma de habrosta.
Hago visión artificial en Mail.ru. Hoy hablaré sobre cómo usamos el aprendizaje profundo para reconocer imágenes de escenas y atracciones.
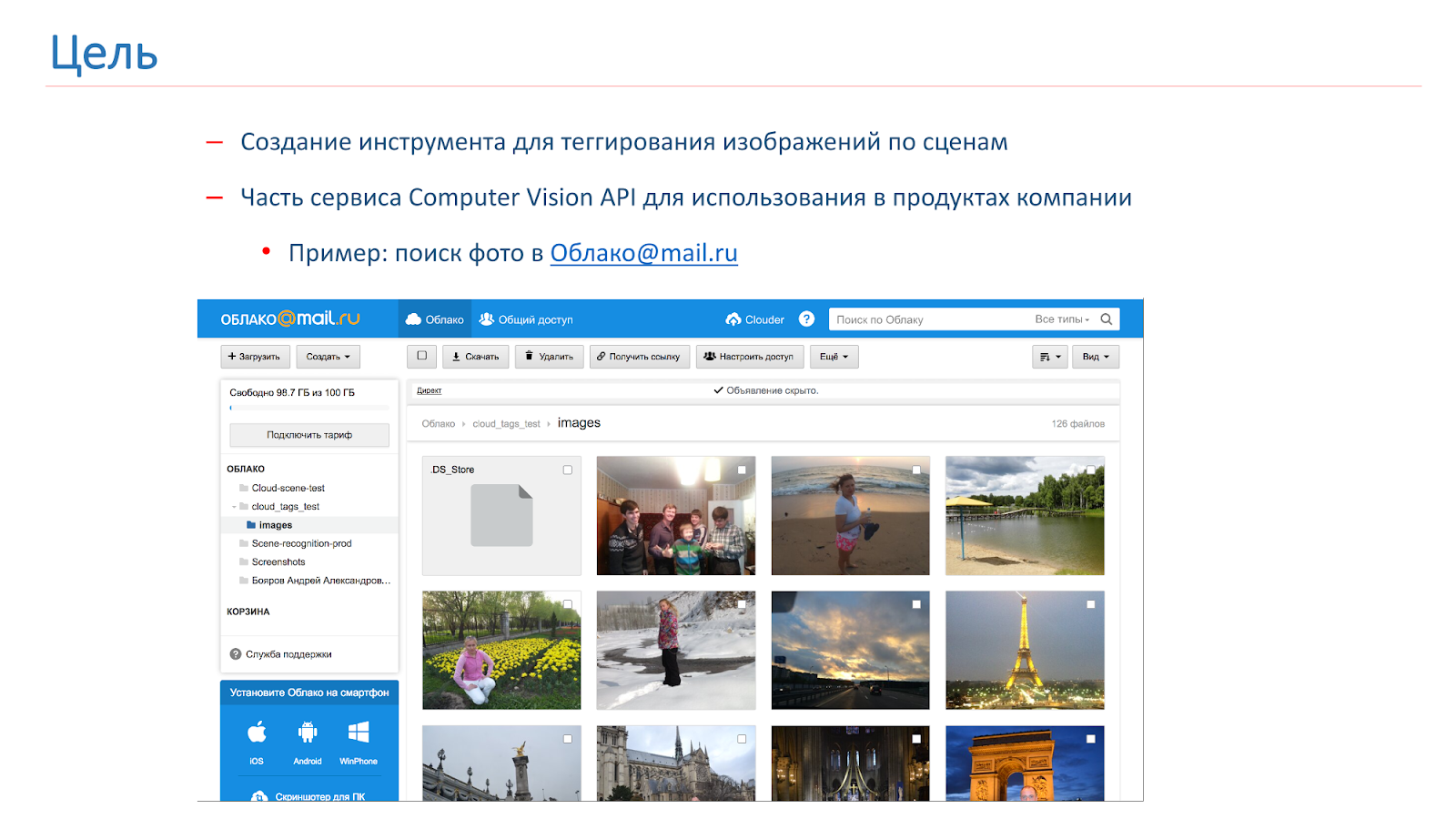
La compañía surgió la necesidad de etiquetar y buscar por imágenes de los usuarios, y para esto decidimos hacer nuestra propia API de Computer Vision, parte de la cual será una herramienta de etiquetado de escenas. Como resultado de esta herramienta, queremos obtener algo como lo que se muestra en la imagen a continuación: el usuario realiza una solicitud, por ejemplo, "catedral", y recibe todas sus fotos con catedrales.
En Computer Vision-community, el tema del reconocimiento de objetos en imágenes se ha estudiado bastante bien. Existe un conocido
concurso de ImageNet que se lleva a cabo durante varios años y cuya parte principal es el reconocimiento de objetos.
Básicamente necesitamos localizar algún objeto y clasificarlo. Con las escenas, la tarea es algo más complicada, porque la escena es un objeto más complejo, consiste en una gran cantidad de otros objetos y el contexto que los une, por lo que las tareas son diferentes.

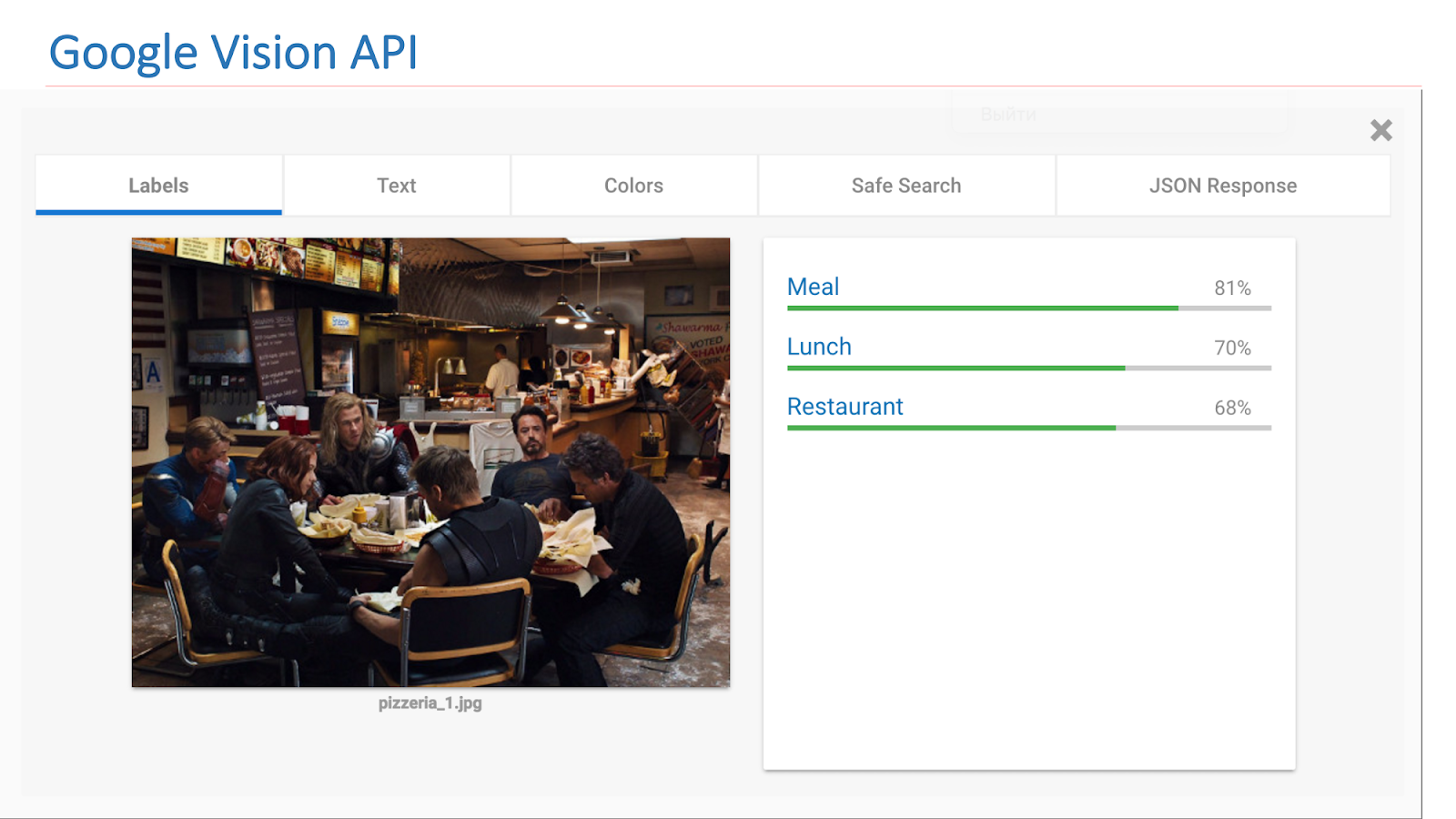
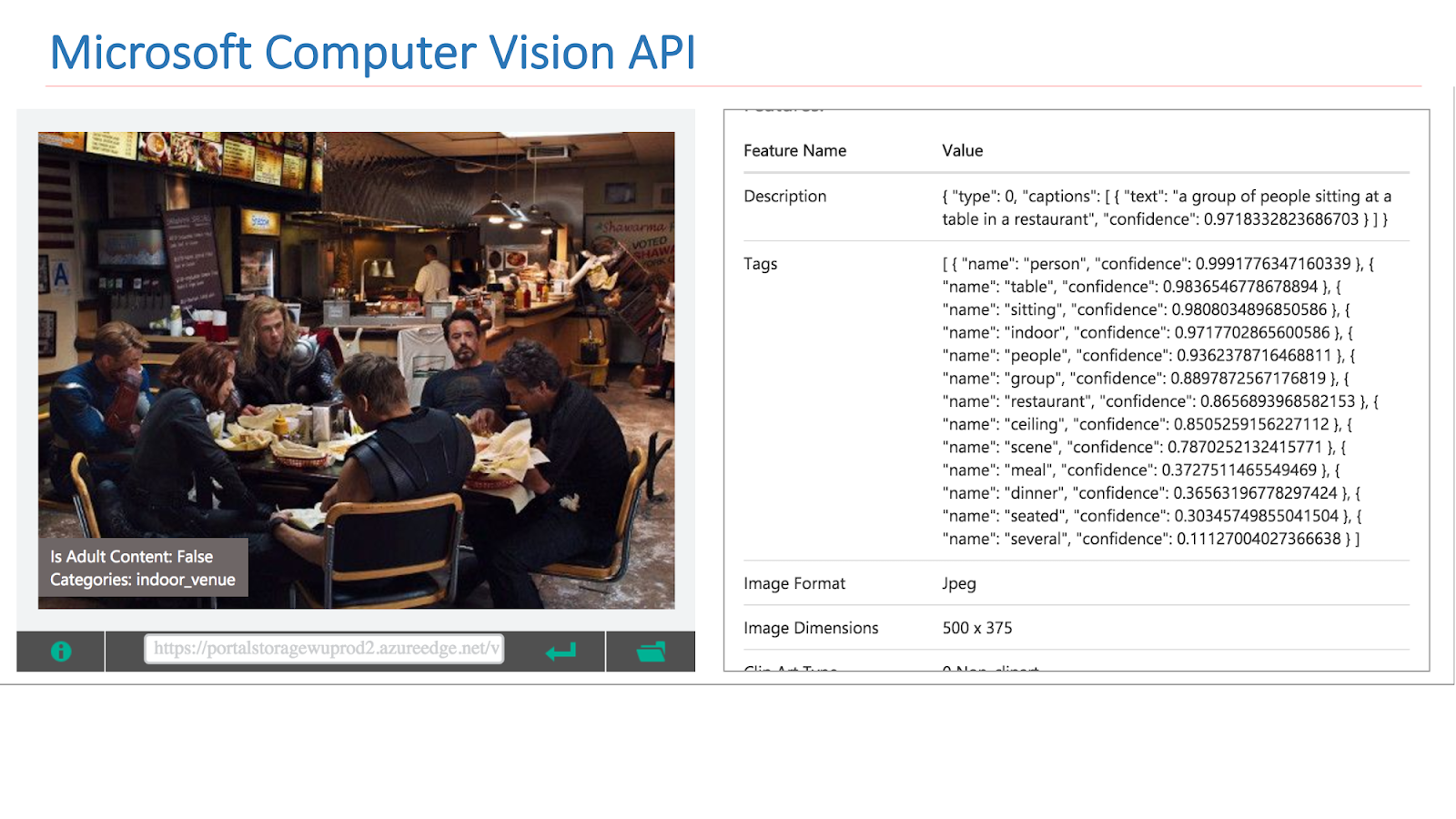
En Internet hay servicios disponibles de otras compañías que implementan dicha funcionalidad. En particular, esta es la API de Google Vision o la API de Microsoft Computer Vision, que puede encontrar escenas en imágenes.
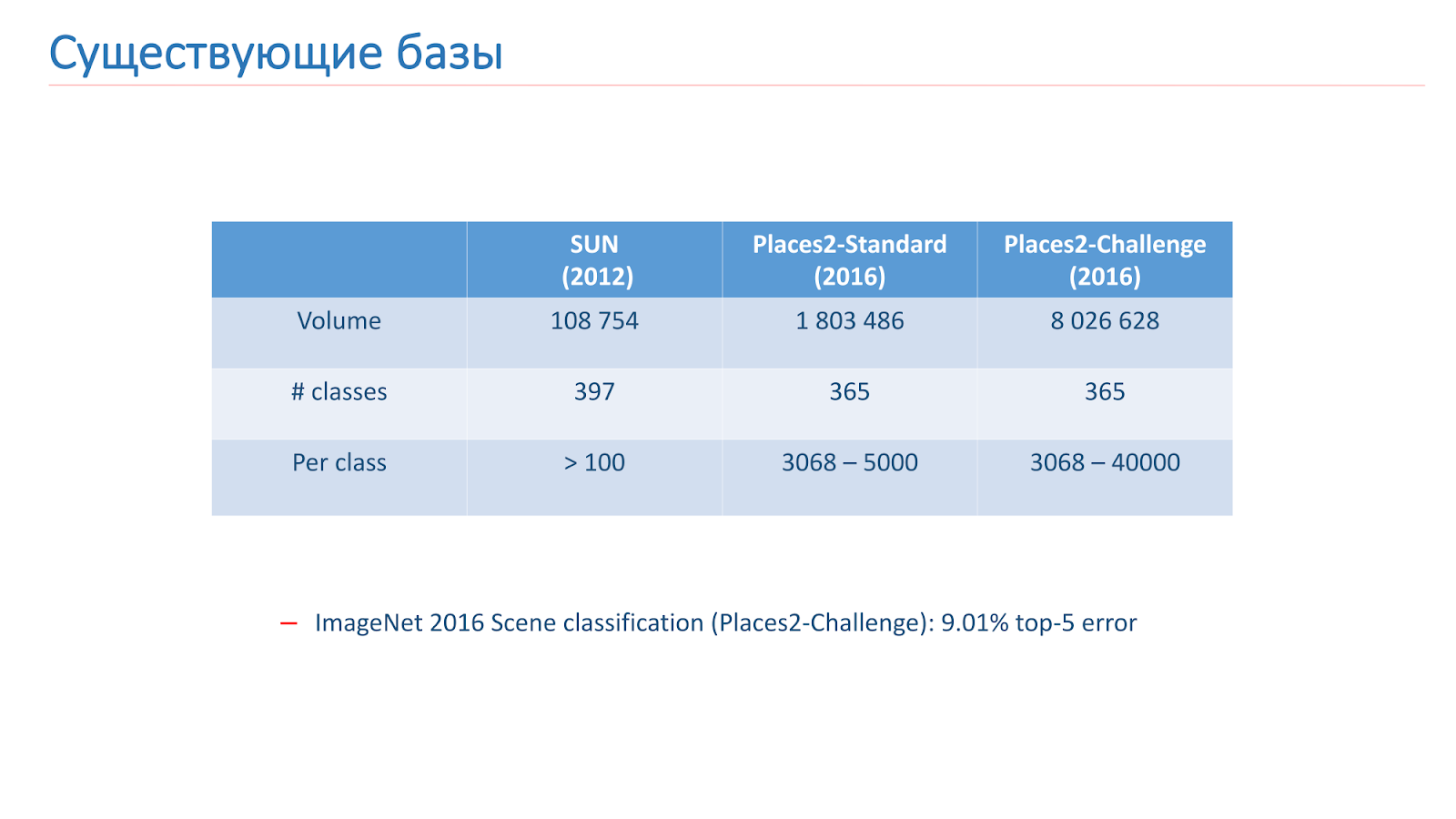
Resolvimos este problema con la ayuda del aprendizaje automático, por lo que para esto necesitamos datos. Hay dos bases principales para el reconocimiento de escenas en acceso abierto ahora. El primero de ellos apareció en 2013: esta es
la base de SUN de la Universidad de Princeton. Esta base consta de cientos de miles de imágenes y 397 clases.
La segunda base en la que entrenamos es
la base Places2 del MIT. Ella apareció en 2013 en dos versiones. El primero es Places2-Standart, una base más equilibrada con 1,8 millones de imágenes y 365 clases. La segunda opción, Places2-Challenge, contiene ocho millones de imágenes y 365 clases, pero el número de imágenes entre clases no está equilibrado. En el concurso ImageNet 2016, la sección de Reconocimiento de escena incluyó el Places2-Challenge, y el ganador mostró el mejor resultado de
error de clasificación Top-5 de aproximadamente el 9%.
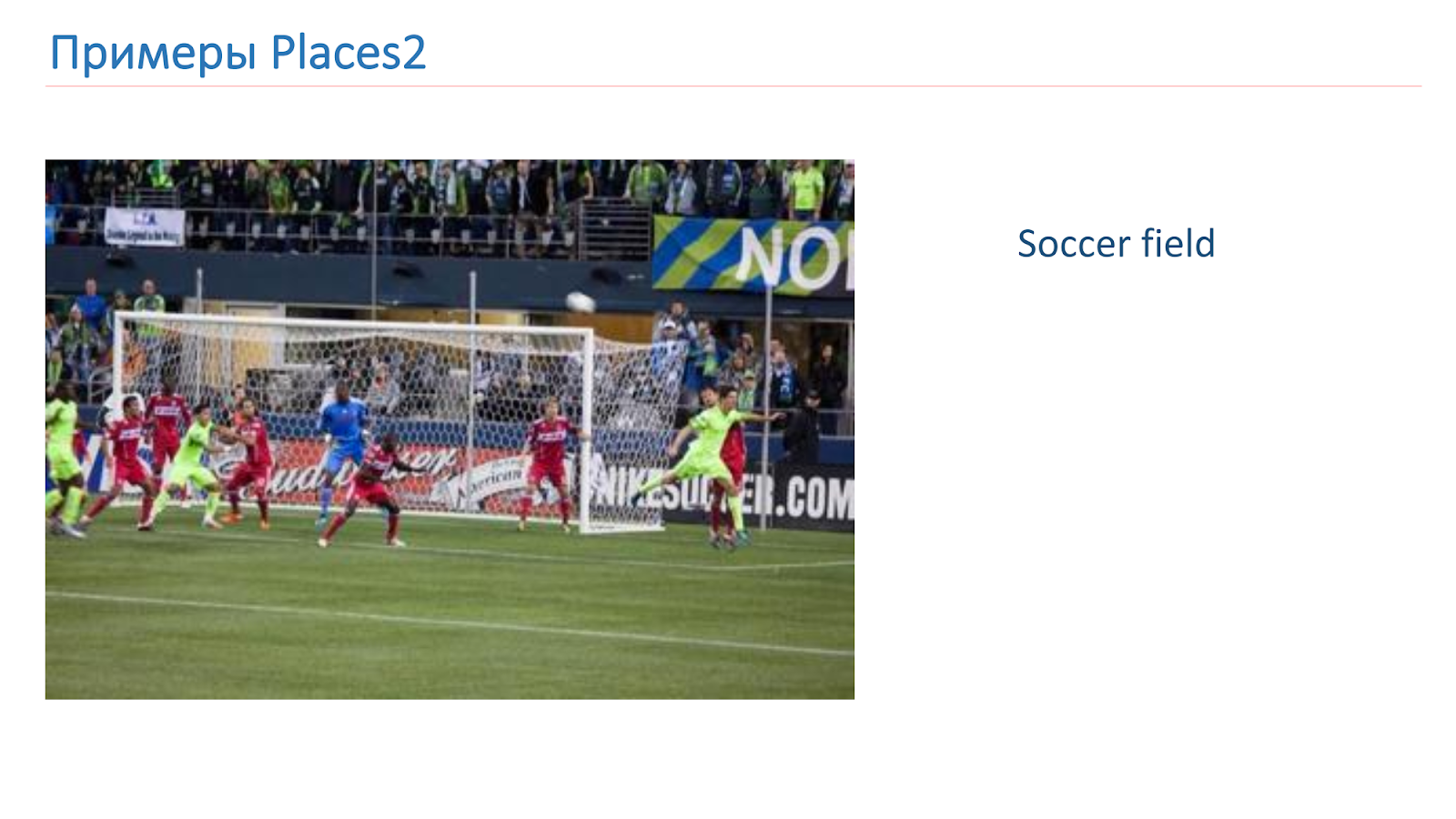
Entrenamos sobre la base de Places2. Aquí hay una imagen de ejemplo desde allí: es un cañón, pista, cocina, campo de fútbol. Estos son objetos complejos completamente diferentes en los que debemos aprender a reconocer.

Antes de estudiar, adaptamos las bases que tenemos para satisfacer nuestras necesidades. Hay un truco para el reconocimiento de objetos al experimentar con modelos en pequeñas bases CIFAR-10 y CIFAR-100 en lugar de ImageNet, y solo entonces los mejores entrenan en ImageNet.
Decidimos seguir el mismo camino, tomamos la base de datos SUN, la redujimos, obtuvimos 89 clases, 50 mil imágenes en el tren y 10 mil imágenes en la validación. Como resultado, antes de entrenar en Places2, configuramos experimentos y probamos nuestros modelos basados en SUN. El entrenamiento en él lleva solo 6-10 horas, a diferencia de varios días en Places2, lo que permitió realizar muchos más experimentos y hacerlo más efectivo.
También miramos la base de datos de Places2 y nos dimos cuenta de que no necesitábamos algunas clases. Ya sea por consideraciones de producción, o porque hay muy pocos datos sobre ellos, eliminamos clases como, por ejemplo, un acueducto, una casa en el árbol, una puerta de granero.

Como resultado, después de todas las manipulaciones, obtuvimos la base de datos Places2, que contiene 314 clases y medio millón de imágenes (en su versión estándar), en la versión Challenge, alrededor de 7,5 millones de imágenes. Construimos capacitación sobre estas bases.
Además, al ver las clases restantes, descubrimos que hay demasiadas para producción, son demasiado detalladas. Y para esto, aplicamos el mecanismo de mapeo de escenas cuando algunas clases se combinan en una común. Por ejemplo, conectamos todo lo relacionado con los bosques en un bosque, todo lo relacionado con los hospitales, en un hospital, con hoteles, en un hotel.
Utilizamos el mapeo de escenas solo para pruebas y para el usuario final, porque es más conveniente. En el entrenamiento, utilizamos todas las clases 314 estándar. Llamamos a la base resultante Lugares Sift.
Enfoques, soluciones
Ahora considere los enfoques que usamos para resolver este problema. En realidad, tales tareas están conectadas con el enfoque clásico: redes neuronales convolucionales profundas.
La imagen a continuación muestra una de las primeras redes clásicas, pero ya contiene los principales bloques de construcción que se utilizan en las redes modernas.

Estas son capas convolucionales, estas son capas de arrastre, capas completamente conectadas. Para determinar la arquitectura, verificamos los mejores resultados de los concursos ImageNet y Places2.

Podemos decir que las principales arquitecturas principales se pueden dividir en dos familias: Inception y la familia ResNet (red residual). En el curso de los experimentos, descubrimos que la familia ResNet es más adecuada para nuestra tarea, y realizamos el siguiente experimento en esta familia.

ResNet es una red profunda que consta de una gran cantidad de bloques residuales. Este es su bloque de construcción principal, que consta de varias capas con pesos y conexión de acceso directo. Como resultado de este diseño, esta unidad aprende cuánto difiere la señal de entrada x de la salida f (x). Como resultado, podemos construir redes de tales bloques, y durante el entrenamiento, la red en las últimas capas puede hacer pesos cercanos a cero.
Por lo tanto, podemos decir que la red misma decide qué tan profunda debe ser para resolver algunas de las tareas. Gracias a esta arquitectura, es posible construir redes de gran profundidad con una gran cantidad de capas. El ganador de ImageNet 2014 contenía solo 22 capas, ResNet superó este resultado y ya contenía 152 capas.
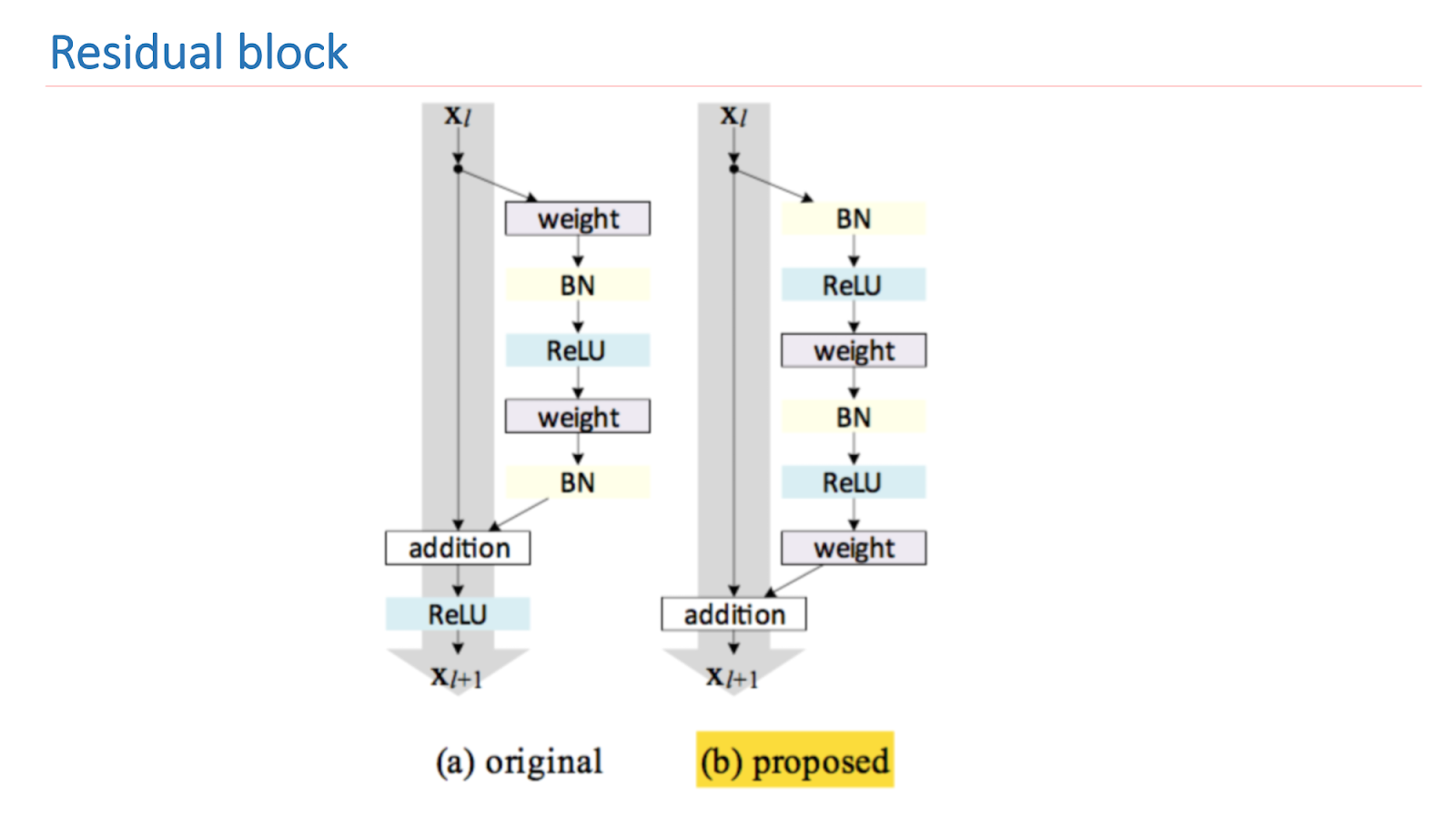
La investigación central de ResNet es mejorar y construir adecuadamente un bloque residual. La imagen a continuación muestra una versión empírica y matemáticamente sólida que brinda el mejor resultado. Tal construcción del bloque le permite lidiar con uno de los problemas fundamentales del aprendizaje profundo: un gradiente que se desvanece.
Para entrenar nuestras redes, utilizamos el marco Torch escrito en Lua debido a su flexibilidad y velocidad, y para ResNet bifurcamos la
implementación de ResNet desde Facebook . Para validar la calidad de la red, utilizamos tres pruebas.
La primera prueba val de Places es la validación de muchos conjuntos de Sift de Places. La segunda prueba es Tamizar lugares usando el mapeo de escenas, y la tercera es la prueba de Nube más cercana a la situación de combate. Imágenes de empleados tomadas de la nube y etiquetadas manualmente. En la imagen de abajo hay dos ejemplos de tales imágenes.

Comenzamos a medir y entrenar redes, compararlas entre sí. El primero es el punto de referencia ResNet-152, que viene con Places2, el segundo es ResNet-50, que capacitamos en ImageNet y lo capacitamos en nuestra base, el resultado ya fue mejor. Luego tomaron ResNet-200, también capacitado en ImageNet, y al final mostró el mejor resultado.

A continuación hay ejemplos de trabajo. Este es un punto de referencia ResNet-152. Se pronostican las etiquetas originales que entrega la red. Las etiquetas mapeadas son las etiquetas que vinieron después del mapeo de escenas. Se puede ver que el resultado no es muy bueno. Es decir, ella parece estar dando algo sobre el caso, pero no muy bien.

El siguiente ejemplo es la operación de ResNet-200. Ya muy adecuado.

Mejora de ResNet
Decidimos tratar de mejorar nuestra red, y al principio solo intentamos aumentar la profundidad de la red, pero después de eso se hizo mucho más difícil entrenar. Este es un problema conocido, el año pasado se publicaron varios artículos sobre este tema, que dicen que ResNet, de hecho, es un conjunto de una gran cantidad de redes ordinarias de varias profundidades.
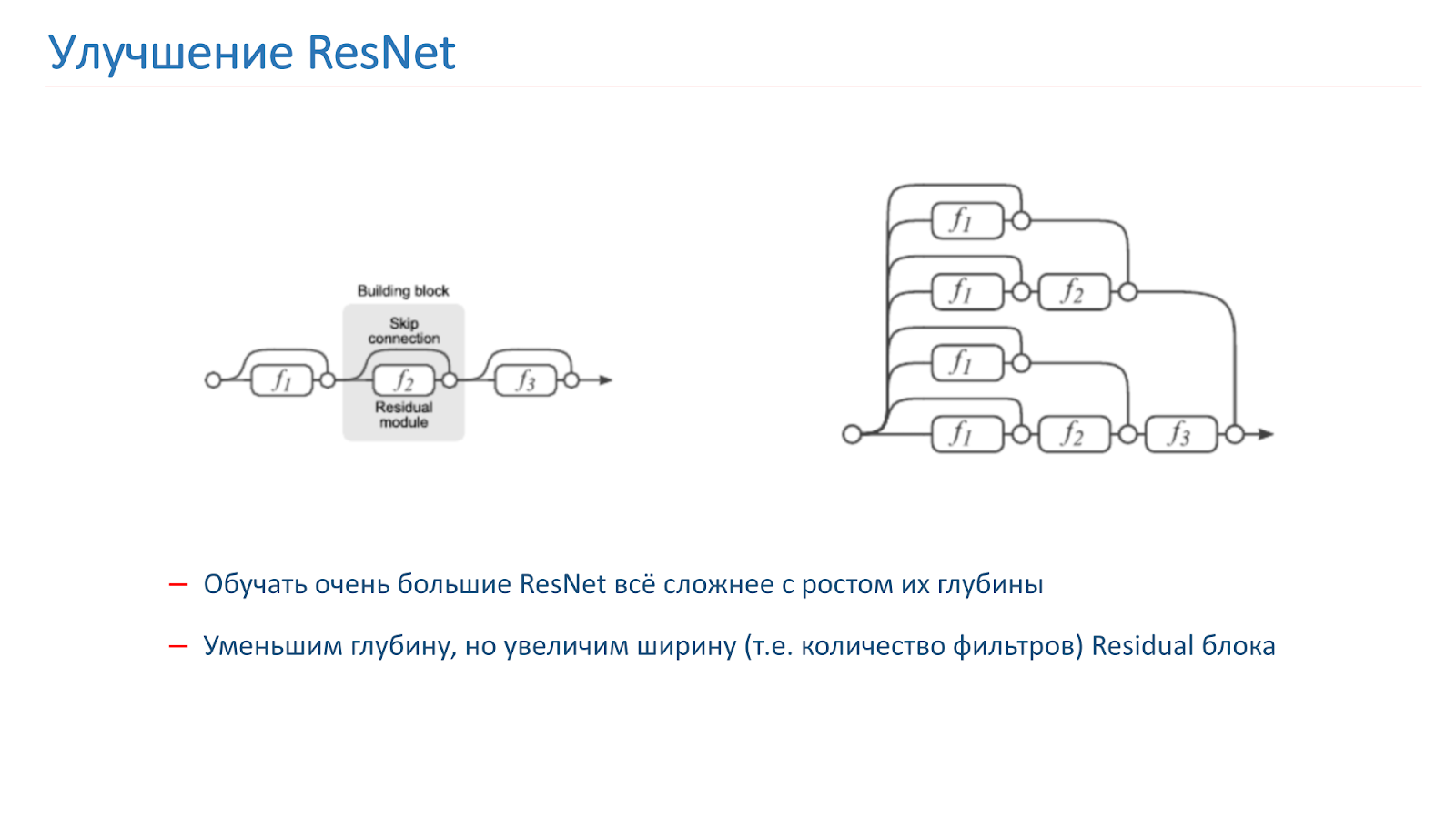
Los bloques res, que se encuentran al final de la cuadrícula, hacen una pequeña contribución a la formación del resultado final. Parece más prometedor aumentar no la profundidad de la red, sino su ancho, es decir, la cantidad de filtros dentro del bloque Res.
Esta idea es implementada por Wide Residual Network, que apareció en 2016. Terminamos usando WRN-50-2, que es el ResNet-50 habitual con el doble de filtros en la convolución 3x3 del cuello de botella interno.

La red muestra en ImageNet resultados similares con el ResNet-200, que ya hemos usado, pero, lo que es más importante, es casi el doble de rápido. Aquí hay dos implementaciones del bloque Residual en Torch; el parámetro que se duplica se resalta de manera brillante. Este es el número de filtros en la convolución interna.

Estas son mediciones en las pruebas de ResNet-200 ImageNet. Al principio tomamos WRN-22-6, mostró un resultado peor. Luego tomaron WRN-50-2-ImageNet, lo entrenaron, tomaron WRN-50-2, entrenaron en ImageNet y lo entrenaron en Places2-challenge, y mostró el mejor resultado.
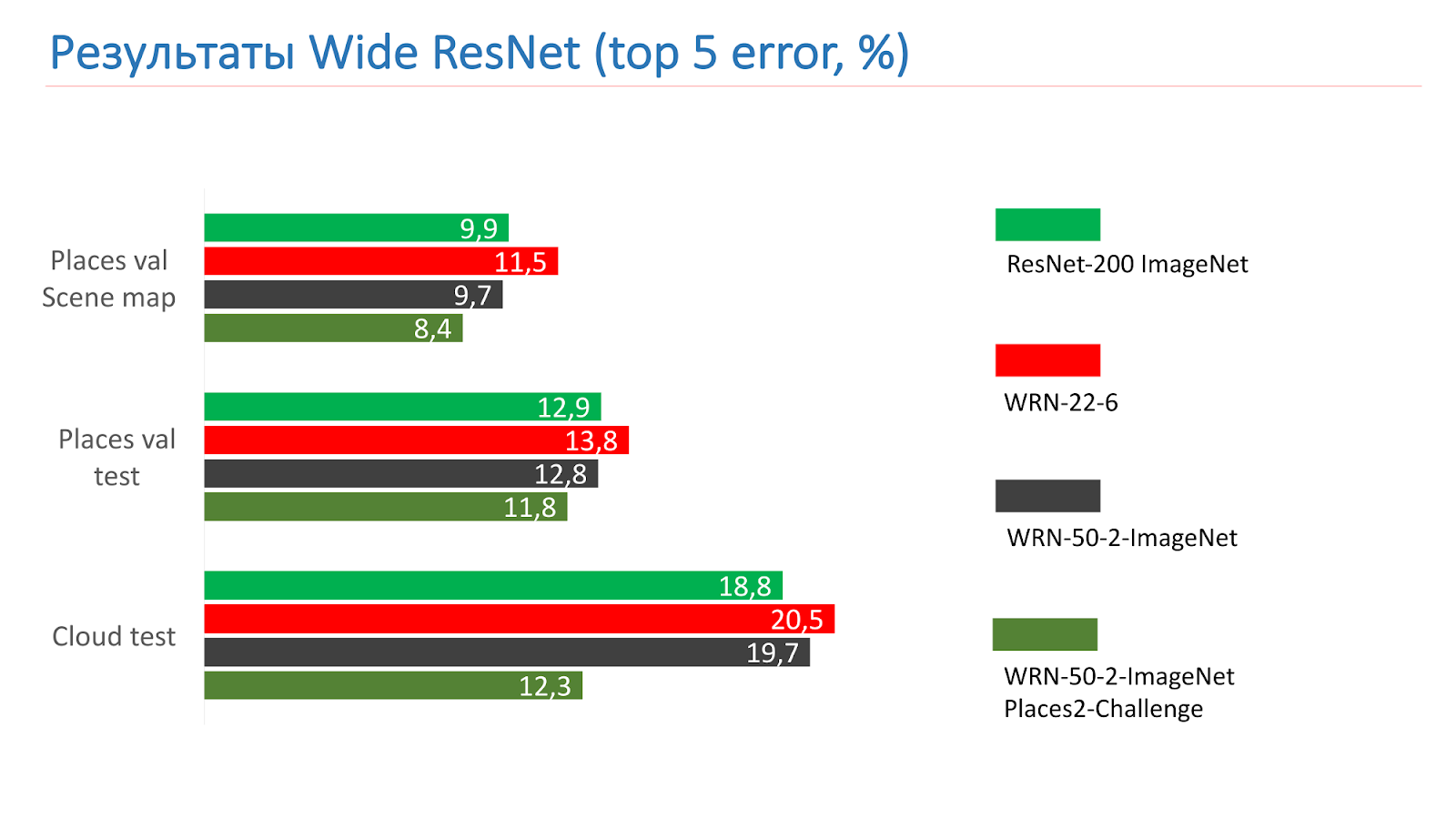
Aquí hay un ejemplo del WRN-50-2: un resultado bastante adecuado en nuestras imágenes que ya ha visto.

Y este es un ejemplo de trabajo en fotografías de combate, también con éxito.

Hay, por supuesto, trabajos no muy exitosos. El puente de Alejandro III en París no fue reconocido como un puente.

Mejora modelo
Pensamos en cómo mejorar este modelo. La familia ResNet continúa mejorando, con nuevos artículos que salen. En particular, en 2016 se publicó un artículo interesante PyramidNet, que mostró resultados prometedores en CIFAR-10/100 e ImageNet.
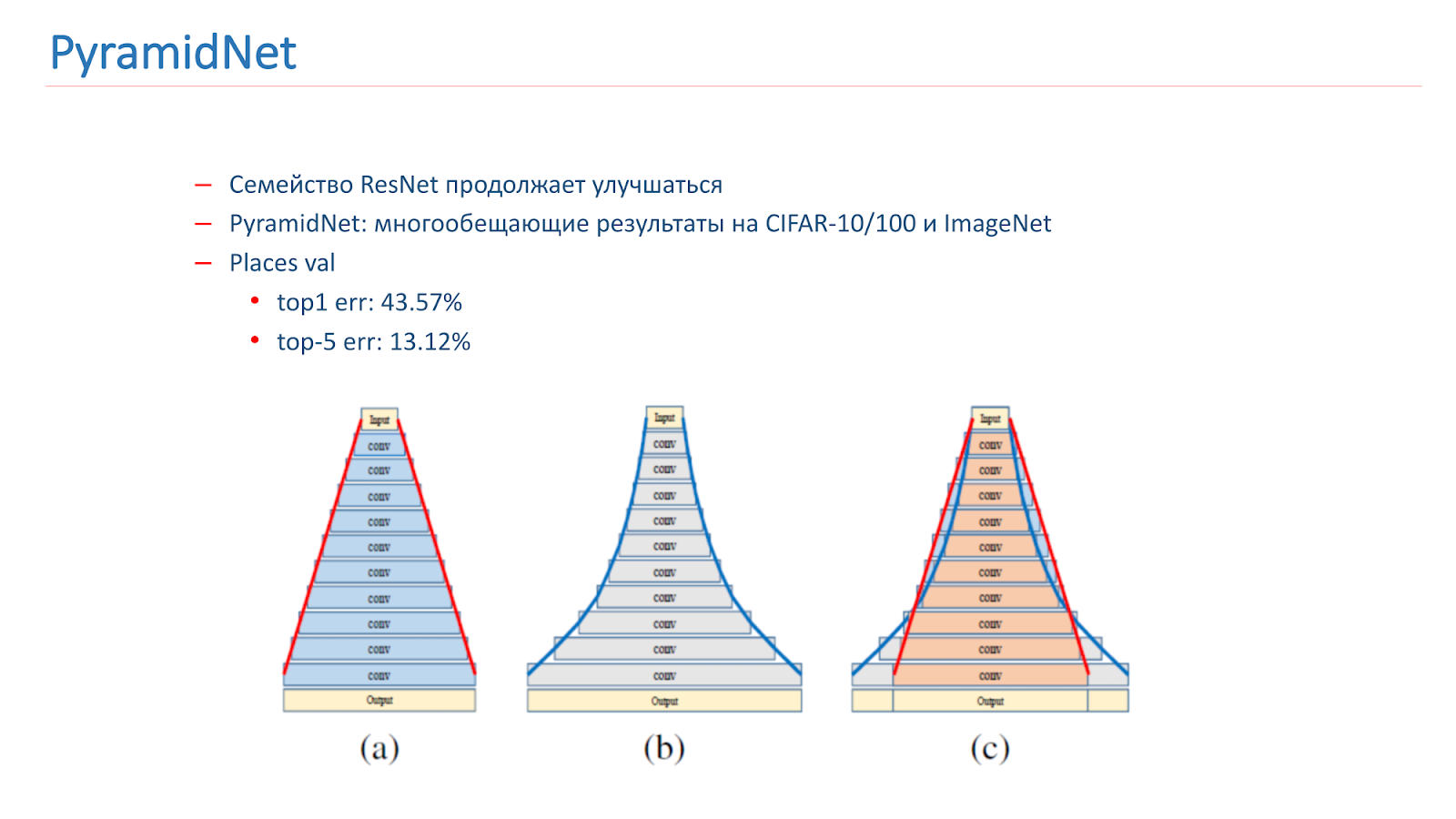
La idea no es aumentar bruscamente el ancho del bloque residual, sino hacerlo gradualmente. Entrenamos varias opciones para esta red, pero, desafortunadamente, mostró resultados ligeramente peores que nuestro modelo de combate.
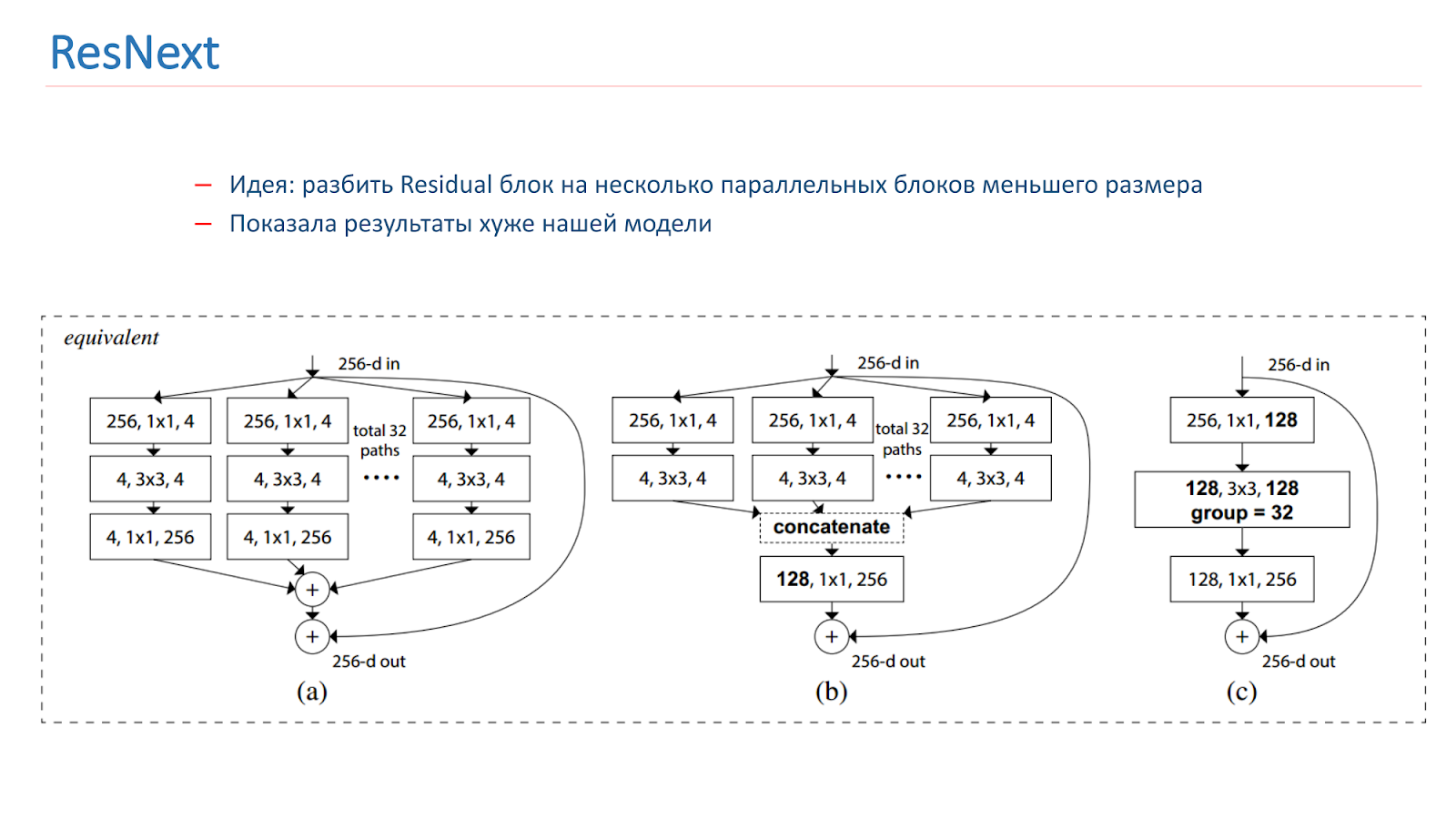
En la primavera de 2018, se lanzó el modelo ResNext, también una idea prometedora: dividir el bloque residual en varios bloques paralelos de menor tamaño y menor ancho. Esto es similar a la idea de Inception, también experimentamos con ella. Pero, desafortunadamente, ella mostró peores resultados que nuestro modelo.
También experimentamos con varios enfoques "creativos" para mejorar nuestros modelos. En particular, intentamos usar el mapeo de activación de clase (CAM), es decir, estos son los objetos que la red mira cuando clasifica la imagen.

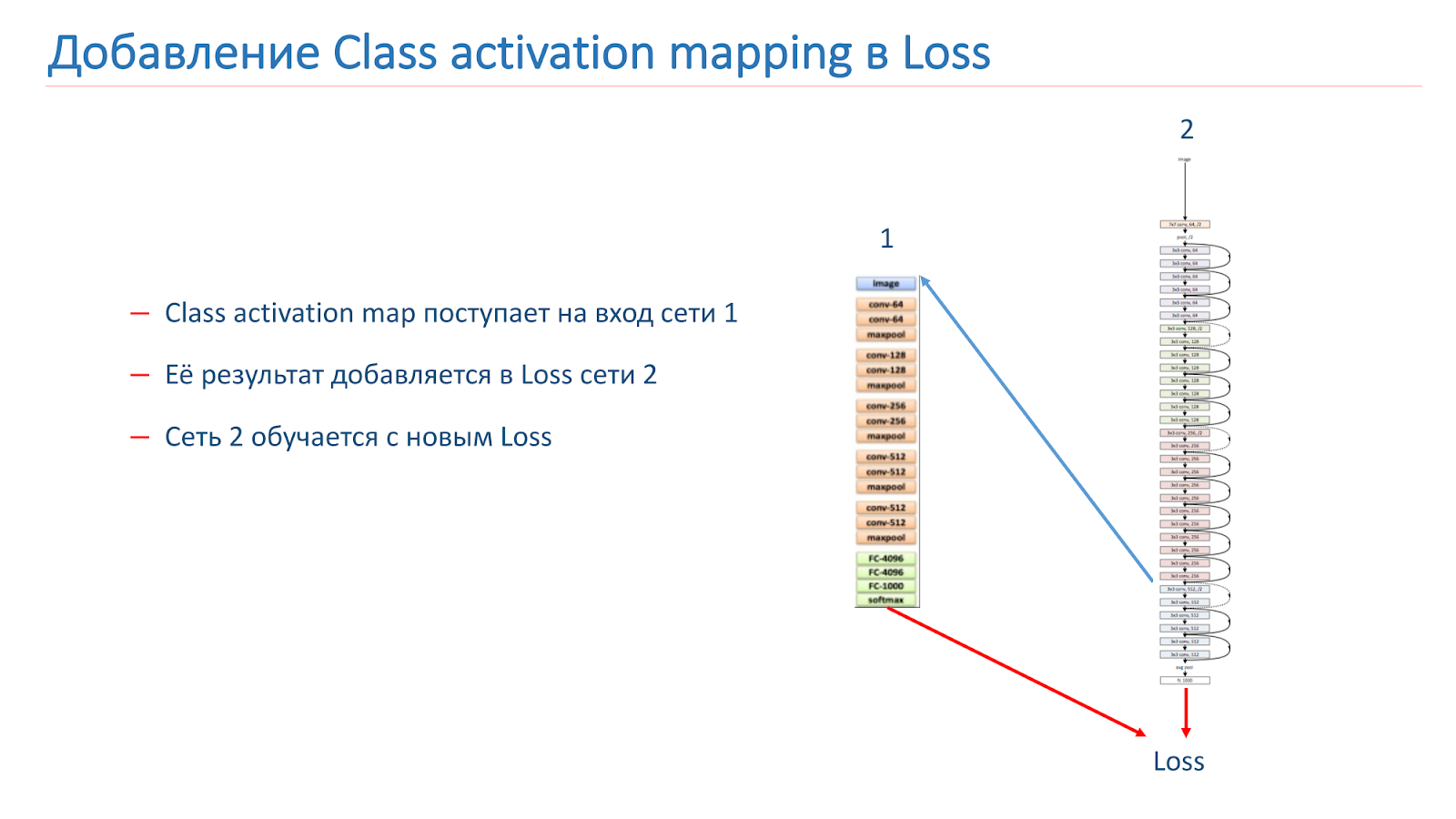
Nuestra idea era que las instancias de la misma escena deberían tener los mismos o similares objetos que una clase CAM. Intentamos usar este enfoque. Al principio tomaron dos redes. Uno está capacitado en ImageNet, el segundo es nuestro modelo, que queremos mejorar.

Tomamos la imagen, corremos a través de la red 2, agregamos el CAM para la capa, luego lo alimentamos a la entrada de la red 1. Corre a través de la red 1, agregamos los resultados a la función de pérdida de la red 2, continuamos con las nuevas funciones de pérdida.
La segunda opción es que ejecutamos la imagen a través de la red 2, tomamos el CAM, lo alimentamos a la entrada de la red 1, y luego con estos datos simplemente entrenamos la red 1 y usamos el conjunto de los resultados de la red 1 y la red 2.
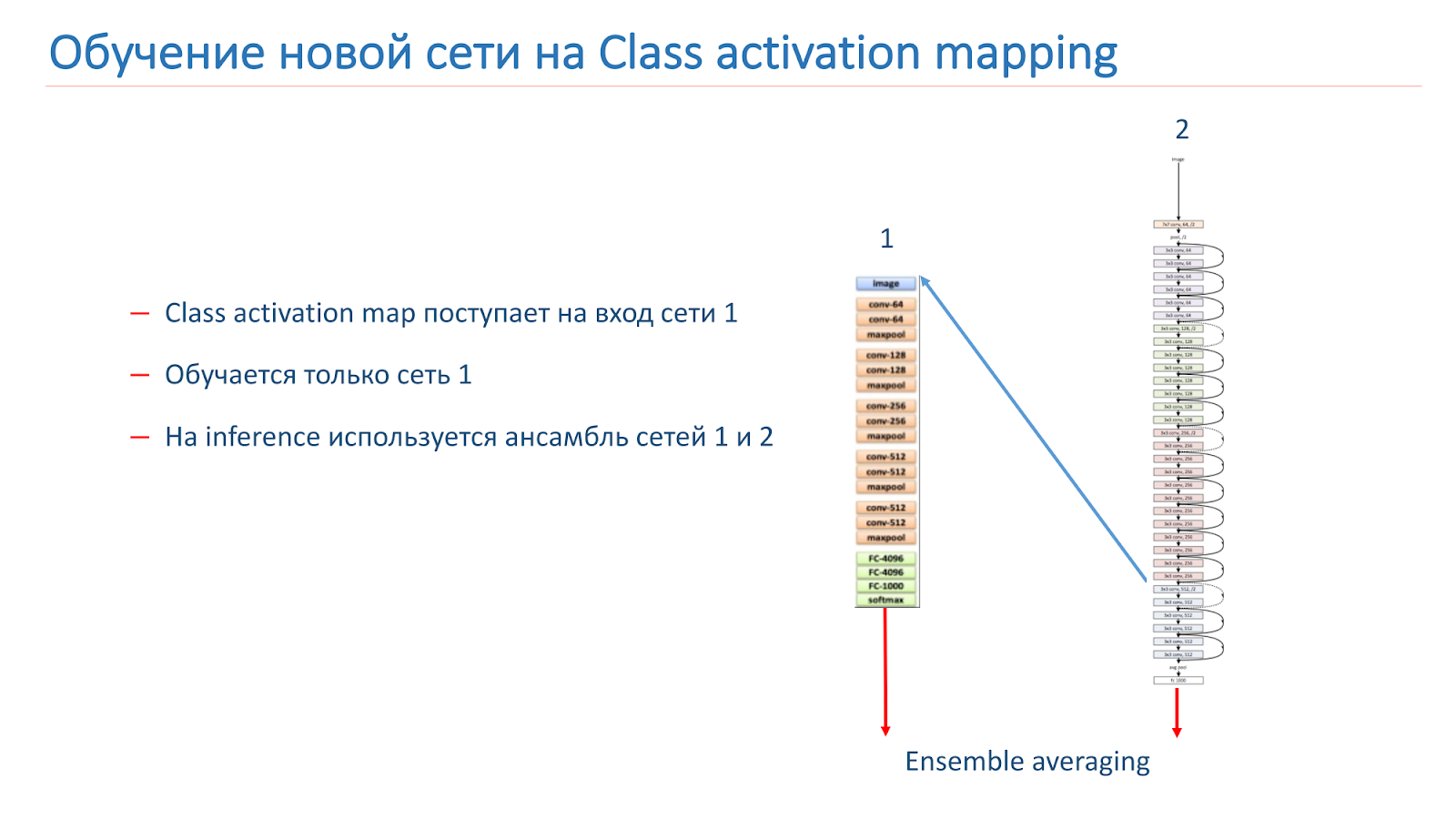
Volvimos a entrenar nuestro modelo en WRN-50-2, como la red 1 usamos ResNet-50 ImageNet, pero no fue posible aumentar significativamente la calidad de nuestro modelo.
Pero continuamos investigando sobre cómo mejorar nuestros resultados: estamos entrenando nuevas arquitecturas de CNN, en particular la familia ResNet. Intentamos experimentar con CAM y considerar varios enfoques con un procesamiento más inteligente de los parches de imagen; nos parece que este enfoque es bastante prometedor.
Reconocimiento de hito

Tenemos un buen modelo para reconocer escenas, pero ahora queremos descubrir algunos lugares emblemáticos, es decir, lugares de interés. Además, los usuarios a menudo les toman fotos o las toman en su contexto.
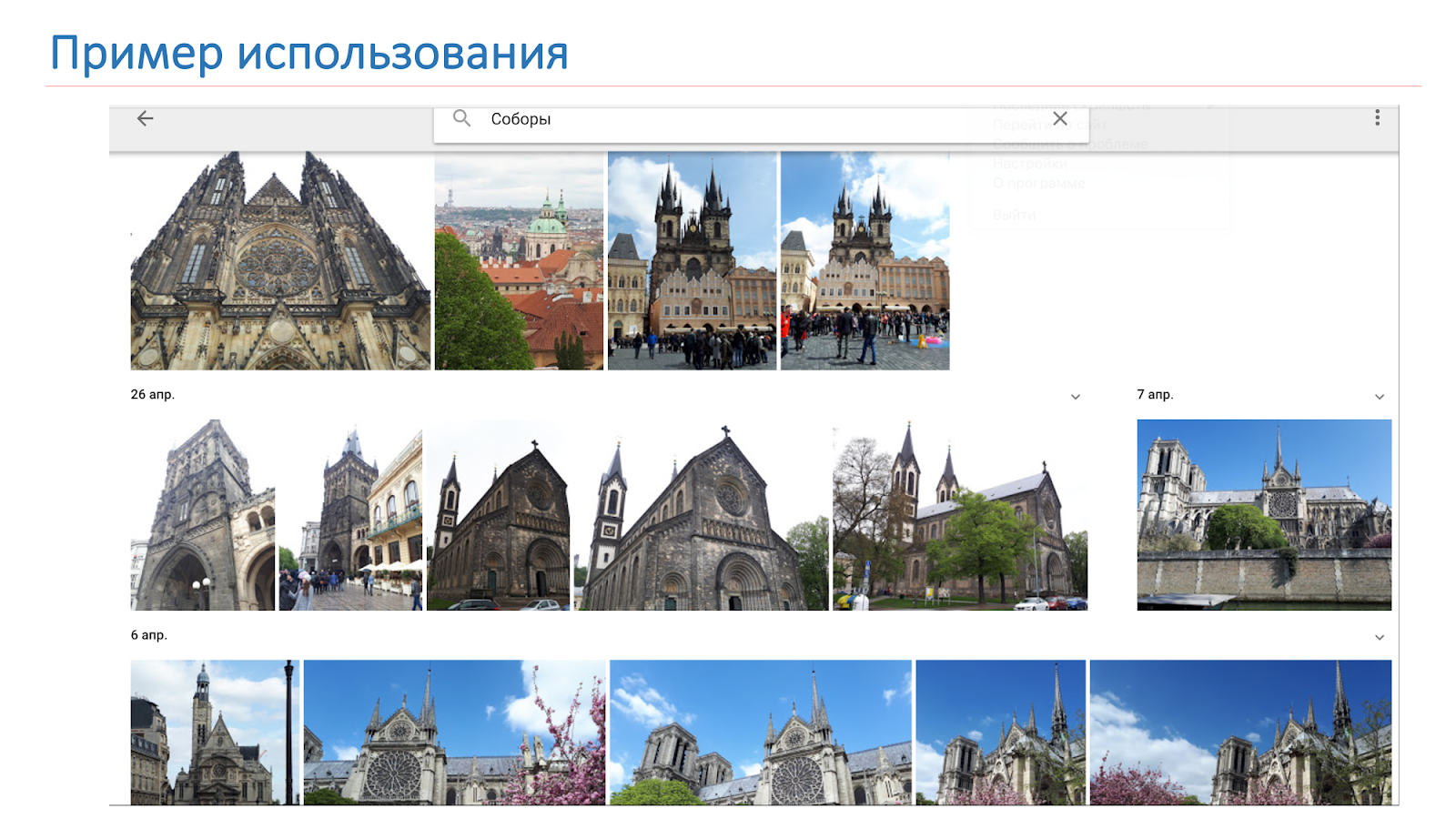
Queremos que el resultado no sea solo las catedrales, como en la imagen de la diapositiva, sino el sistema que diga: "Hay Notre Dame de Paris y las catedrales en Praga".
Cuando resolvimos este problema, encontramos algunas dificultades.
- Prácticamente no hay estudios sobre este tema y no hay datos preparados en el dominio público.
- Una pequeña cantidad de imágenes "limpias" en el dominio público para cada atracción.
- No está del todo claro qué es un hito de los edificios. Por ejemplo, una casa con torres en Sq. Leo Tolstoi en Petersburgo, TripAdvisor no considera atracciones, pero Google considera.
Comenzamos recopilando una base de datos, compilamos una lista de 100 ciudades y luego utilizamos la API de Google Places para descargar datos JSON para los puntos de interés de estas ciudades.
Los datos se filtraron y analizaron, y de acuerdo con la lista, descargamos 20 imágenes de la Búsqueda de Google para cada atracción. El número 20 está tomado de consideraciones empíricas. Como resultado, obtuvimos una base de 2827 atracciones y alrededor de 56 mil imágenes. Esta es la base sobre la que formamos nuestro modelo. Para validar nuestro modelo, utilizamos dos pruebas.
Prueba en la nube: estas son imágenes de nuestros empleados, etiquetadas manualmente. Contiene 200 imágenes en 15 ciudades y 10 mil imágenes sin atracciones. El segundo es la prueba de búsqueda. Fue construido usando la búsqueda Mail.ru, que contiene de 3 a 10 imágenes para cada atracción, pero, desafortunadamente, esta prueba está sucia.
Entrenamos a los primeros modelos, pero mostraron resultados pobres en la prueba de Cloud en fotos de combate.
Aquí hay un ejemplo de la imagen en la que fuimos entrenados, y un ejemplo de fotografía de combate. El problema en las personas es que a menudo son fotografiadas en el contexto de las vistas. En esas imágenes que obtuvimos de la búsqueda, no había personas.
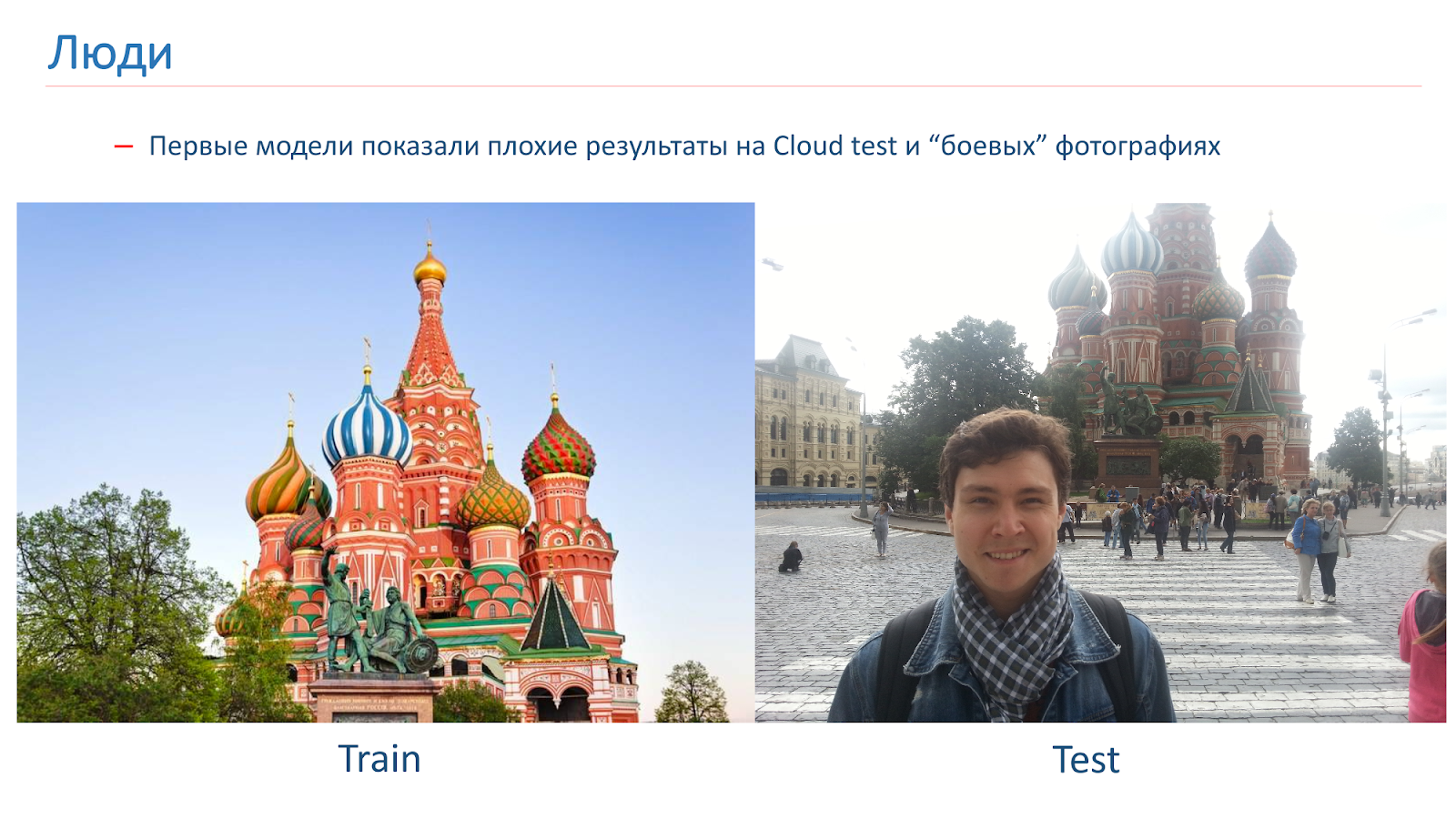
Para combatir esto, agregamos aumento "humano" durante el entrenamiento. Es decir, utilizamos enfoques estándar: rotaciones aleatorias, corte aleatorio de parte de la imagen, etc. Pero también en el proceso de aprendizaje, agregamos personas al azar a algunas imágenes.

Este enfoque nos ayudó a resolver el problema con las personas y a obtener un modelo de calidad aceptable.
Modelos de escena de ajuste fino
Cómo entrenamos el modelo: hay una base de entrenamiento, pero es bastante pequeña. Pero sabemos que una atracción turística es un caso especial de la escena. Y tenemos un modelo de escena bastante bueno. Decidimos entrenarla para las vistas. Para hacer esto, agregamos varias capas BN completamente conectadas en la parte superior de la red, los capacitamos a ellos y a los tres bloques residuales principales. El resto de la red estaba congelada.

Además, para el entrenamiento, utilizamos la función de pérdida central no estándar. Durante el entrenamiento, la pérdida del Centro intenta "separar" representantes de diferentes clases en diferentes grupos, como se muestra en la imagen.

En el entrenamiento, agregamos otra clase "no una atracción turística". Y la pérdida de centro no se aplicó a esta clase. En tal función de pérdida mixta, se realizó el entrenamiento.
Después de entrenar la red, cortamos la última capa de clasificación, y cuando la imagen pasa a través de la red, se convierte en un vector numérico llamado incrustación.
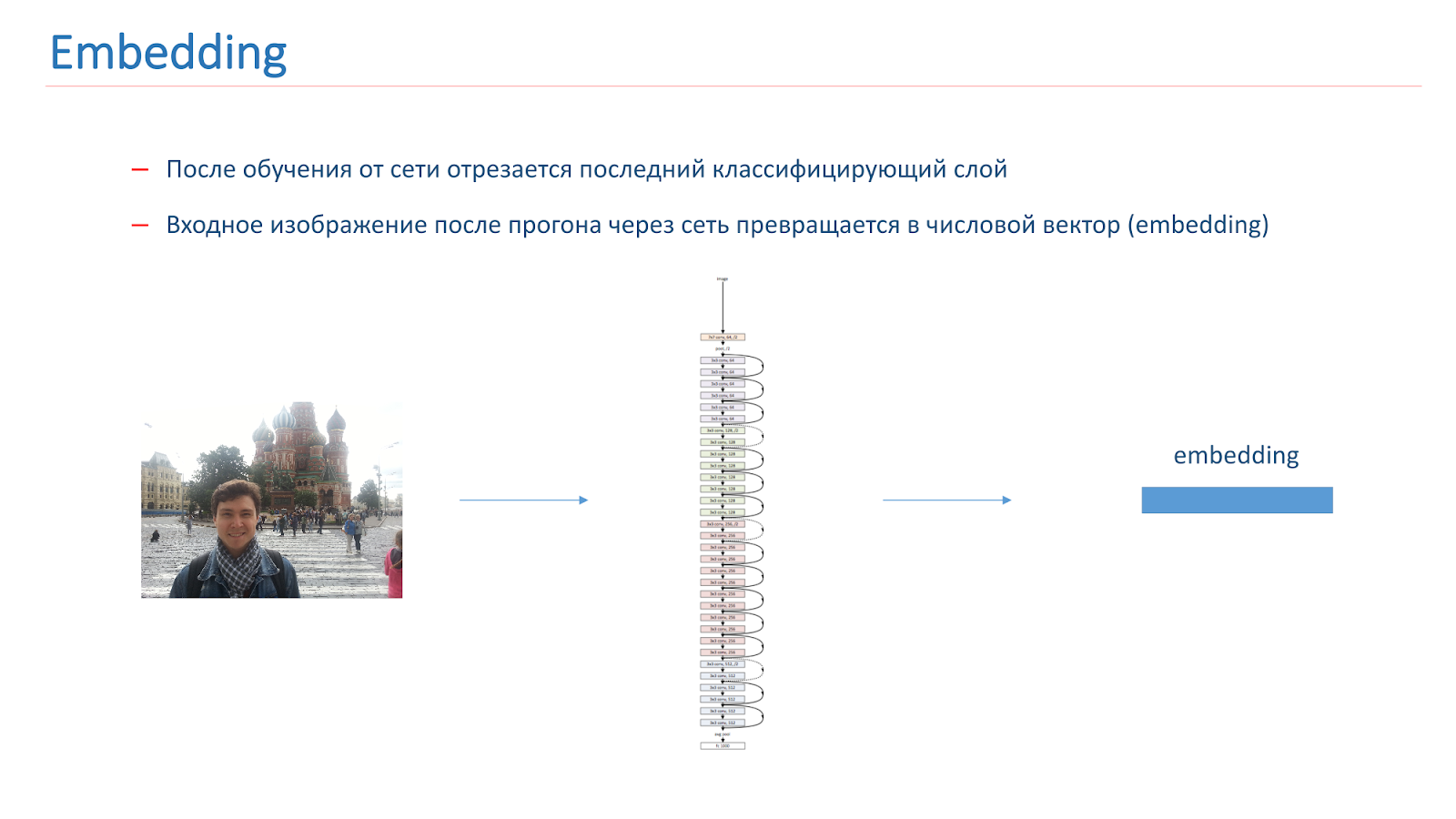
Para construir aún más un sistema de reconocimiento de puntos de referencia, creamos vectores de referencia para cada clase. Tomamos cada clase de atracciones de la multitud y pasamos las imágenes a través de la red. Consiguieron incrustaciones y tomaron su vector medio, que se llamaba vector de referencia de clase.

Para determinar las vistas en la foto, ejecutamos la imagen de entrada a través de la red, y su incrustación se compara con el vector de referencia de cada clase. Si el resultado de la comparación es menor que el umbral, entonces creemos que no hay ningún punto de interés en la imagen. De lo contrario, tomamos la clase con el valor de comparación más alto.
Resultados de la prueba
- En la prueba de la nube, la precisión de las vistas fue de 0.616, no de las vistas: 0.981
- La precisión promedio de 0.669 se obtuvo en la prueba de búsqueda, y la completitud promedio fue de 0.576.
En Búsqueda, no obtuvieron muy buenos resultados, pero esto se explica por el hecho de que el primero es bastante "sucio" y el segundo tiene características: entre las atracciones hay diferentes jardines botánicos que son similares en todas las ciudades.
Hubo una idea para el reconocimiento de escenas para entrenar primero la red, que determinará la máscara de escena, es decir, eliminará los objetos del primer plano y luego la introducirá en el modelo mismo, que reconoce escenas de imágenes sin estas áreas, donde el fondo está obstruido. Pero no está muy claro qué es exactamente lo que se debe eliminar de la capa frontal, qué máscara se necesita.
Será algo bastante complicado e inteligente, porque no todos entienden qué objetos pertenecen a la escena y cuáles son superfluos. Por ejemplo, se puede necesitar gente en un restaurante. Esta es una decisión no trivial, tratamos de hacer algo similar, pero no dio buenos resultados.
Aquí hay un ejemplo de trabajo en fotografías de combate.
Ejemplos de trabajo exitoso:


Pero el trabajo fallido: no se encontraron lugares de interés. El principal problema de nuestro modelo en este momento no es que la red confunda las vistas, sino que no las encuentra en la foto.

En el futuro, planeamos reunir una base para un número aún mayor de ciudades, encontrar nuevos métodos para capacitar a la red para esta tarea y determinar las posibilidades de aumentar el número de clases sin volver a capacitar a la red.
Conclusiones
Hoy nosotros:
- Observamos qué conjuntos de datos están disponibles para el reconocimiento de escena;
- Vimos que la Red Residual Amplia es el mejor modelo;
- Discutió otras posibilidades para aumentar la calidad de este modelo;
- Examinamos la tarea de reconocer vistas, qué dificultades surgen;
- Describimos el algoritmo para recopilar la base y los métodos de enseñanza del modelo para reconocer atracciones.
Puedo decir que las tareas son interesantes, pero poco estudiadas en la comunidad. Es interesante tratar con ellos, porque puede aplicar enfoques no estándar que no se aplican en el reconocimiento habitual de objetos.Minuto de publicidad. Si le gustó este informe de la conferencia SmartData, tenga en cuenta que SmartData 2018 se llevará a cabo en San Petersburgo el 15 de octubre, una conferencia para aquellos que están inmersos en el mundo del aprendizaje automático, el análisis y el procesamiento de datos. El programa tendrá muchas cosas interesantes, el sitio ya tiene sus primeros oradores e informes.