Hola% username%!
Probablemente sepa qué son las API y cuánto depende de ellas en su proyecto. Además, también creo que ya estás familiarizado con cuál es el
primer enfoque de la
API y sabes que
Swagger y su
API abierta son algunas de las herramientas más populares para ayudarlo a seguir.
Pero en este artículo quiero hablar sobre el enfoque para la implementación de la API primero, conceptualmente diferente de lo que ofrecen Swagger y Apiary. A la cabeza de la idea está el concepto de
contrato único y la posibilidad de su implementación basada en RAML 1.0.
Debajo del corte:
- Una breve descripción de los principios de la API primero;
- Contrato único : introducción de un concepto, requisitos previos para la aparición, consideración de la posibilidad de su implementación sobre la base de la OEA (Swagger);
- RAML + anotaciones + superposiciones como base para un contrato único , ejemplos;
- Problemas RAML, desacuerdos conceptuales de los desarrolladores;
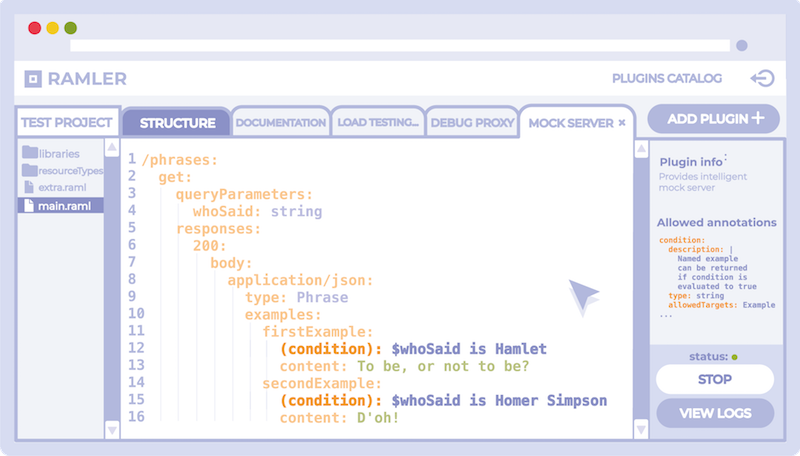
- La idea de un servicio SaaS basado en la idea anterior (imagen prototipo arriba).
Desde API primero en Swagger hasta contrato individual en RAML
Al diseñar sistemas de software modernos, a menudo surge la tarea de coordinar y desarrollar interfaces para la interacción de sus componentes entre sí. En la última década, el SPA y las aplicaciones móviles gruesas que interactúan con el servidor a través de API han ganado una inmensa popularidad y desarrollo. Anteriormente, el desarrollo de un sitio web interactivo se llevaba a cabo mediante la edición paso a paso del código del lado del servidor para generar el marcado HTML con su posterior transferencia al navegador del cliente, ahora el desarrollo de aplicaciones web dinámicas se ha desplazado hacia la creación de una API de servicio único y el desarrollo paralelo de muchas aplicaciones (incluido SPA) que funcionan con esta API como fuente principal de datos. Este enfoque le permite compartir tareas de manera más conveniente, organizar equipos especializados solo en tecnologías específicas (atraer especialistas más especializados), organizar el desarrollo paralelo en las primeras etapas y también le permite crear un único punto de comunicación: una interfaz API.
Tal punto único de comunicación requiere una definición formal e inequívoca, este documento es una especificación API. Para desarrollar y documentar las especificaciones API hoy en día, se utilizan diversas tecnologías y lenguajes, por ejemplo: OAS (Swagger), Apiary y RAML.
Los siguientes tres puntos determinan la naturaleza del primer enfoque de API:
- API debería ser la primera interfaz de cliente de la aplicación desarrollada;
- En primer lugar, se desarrolla una especificación API y luego la parte de software de sus clientes;
- Las etapas de vida de una API deben coincidir con las etapas de vida de su documentación.
Si consideramos el proceso basado en lo anterior, entonces la especificación API está en el centro del proceso de desarrollo, y todos los nodos que componen el sistema y usan esta API como puerta de enlace de interacción son clientes de la especificación API. Por lo tanto, la parte del servidor del sistema puede considerarse la misma API de especificación de cliente, como cualquier otro nodo que use la API para comunicarse con él. Los modelos de dominio de aplicación no tienen que coincidir con los modelos descritos en la especificación API. Sus posibles coincidencias intencionales con estructuras de clase en el código de aplicación del cliente o con estructuras de esquema de base de datos se introducen en lugar de simplificar el proceso de desarrollo, por ejemplo, cuando se utiliza un generador de código de acuerdo con la especificación OAS. Lógicamente, lo anterior se puede resumir bajo la definición de
contrato único .
Contrato único : muchos clientes.
Contrato único. Herramientas de contrato y bibliotecas
El término contrato único no reclama ninguna participación en las críticas por su uso en el texto del artículo. Su aplicación, en este contexto, es personalmente mi idea.
Extender el concepto de
API primero a un
contrato único más general nos permite considerar la especificación API no solo como una descripción formal de la interfaz entre los componentes del sistema, sino también como un
contrato único utilizado por cualquier cantidad de bibliotecas y herramientas externas como fuente de configuración. En este caso, estas herramientas y bibliotecas se pueden percibir como clientes contratados junto con SPA o aplicaciones móviles. Ejemplos de tales clientes incluyen:
- Generador de documentación
- API de servidor simulado
- Servicio de pruebas de estrés
- Biblioteca de validación de solicitud / respuesta
- Generador de código
- UI Generator
- etc.
El contrato único para dichos clientes es un archivo de configuración único y una fuente de datos. Los instrumentos contractuales solo funcionan sobre la base de la información obtenida de un contrato particular. Obviamente, para la funcionalidad completa de clientes tan heterogéneos como el servidor simulado de API, una descripción de API no es suficiente, se necesita metainformación adicional, por ejemplo, una descripción de la relación entre los parámetros de solicitud GET (identificador de recurso) y los datos que el servidor debe devolver, sugerencias apuntando a los campos de respuesta y parámetros de consulta utilizados para organizar la paginación. Además, este ejemplo se considerará con más detalle. La información específica para instrumentos específicos, al mismo tiempo, debe existir y mantenerse inextricablemente del documento principal, de lo contrario, esto violará el concepto de un contrato único.
Swagger (OEA) como herramienta de descripción de contrato único
Los Swagger (OAS) y Apiary (Blueprint) más populares en el mercado le permiten describir las API HTTP utilizando lenguajes especiales: API abierta basada en YAML o JSON, Blueprint basada en Markdown, que hace que las especificaciones sean fáciles de leer. También hay muchas herramientas y bibliotecas creadas por la gran comunidad de código abierto. Swagger actualmente está ampliamente distribuido y, uno podría decir, se ha convertido en el estándar de facto de API primero. Muchos sistemas externos admiten la importación de especificaciones Swagger, como
SoapUI ,
Readme.io ,
Apigee , etc. Además, el SaaS
Swagger Hub y
Apiary existentes permiten a los usuarios crear proyectos, cargar o crear sus propias especificaciones, usar los generadores de documentación incorporados y servidores simulados, así como publicar enlaces para acceder a ellos desde el exterior.
Swagger junto con su OAS 3.0 se ven bastante seguros y su funcionalidad para describir la API (especialmente simple) es suficiente en la mayoría de los casos. La siguiente es una lista de los pros y los contras de Swagger:
Pros:
- Lenguaje descriptivo claro y fácil de leer;
- Gran comunidad de código abierto;
- Una gran cantidad de editores, generadores, bibliotecas oficiales y de código abierto;
- La presencia de un equipo central de desarrollo que trabaja constantemente en el desarrollo y la mejora del formato;
- Hub de shareware para especificaciones;
- Documentación oficial detallada;
- Umbral de entrada bajo.
Contras:
- Soporte de modularidad débil;
- Falta de ejemplos autogenerados de respuestas a consultas basadas en una descripción de sus estructuras;
- A menudo hay problemas con la poca estabilidad de los productos SmartBear (autores fanáticos) y la reacción tardía del desarrollador a esto (la opinión se basa únicamente en la experiencia personal de uso y la experiencia de nuestro equipo).
Pero la principal limitación que no permite el uso de la OEA como un medio para describir
un contrato único es la falta de la capacidad de adjuntar metainformación personalizada para describir parámetros adicionales de herramientas / bibliotecas de destino.
Por lo tanto, todas las herramientas que funcionan según las especificaciones de Swagger deben estar contentas con el conjunto de información que puede acomodar el formato básico.
Por ejemplo, la implementación de un servidor de API simulado inteligente requiere más información de la que puede proporcionar un documento de especificación, razón por la cual la API de simulación Swagger Hub integrada solo es capaz de generar datos falsos basados en tipos / estructuras de datos obtenidos de un documento de especificación. Sin lugar a dudas, esto no es suficiente y una funcionalidad de servidor simulado solo puede ser satisfecha por un simple cliente API.
En nuestra empresa, durante el desarrollo de uno de los proyectos (servidor React SPA + API), se requería la siguiente funcionalidad de servidor simulado:
- imitación de paginación. El servidor no debe devolver valores completamente aleatorios de los campos currentPage, nextPage, pagesTotal en respuesta a las solicitudes de lista, sino que debe ser capaz de simular el comportamiento real del mecanismo de paginación con la generación de los valores de estos metapole dependiendo del valor de la página recibida del cliente;
- generar cuerpos de respuesta que contienen varios conjuntos de datos dependiendo del parámetro específico de la solicitud entrante;
- la capacidad de construir relaciones reales entre objetos falsos: el campo foo_id de la entidad Bar debería referirse a la entidad Foo generada previamente. Esto se puede lograr agregando soporte de idempotencia al servidor simulado;
- imitación del trabajo de varios métodos de autorización: OAuth2, JWT, etc.
Sin todo esto, es muy difícil desarrollar SPA en paralelo con el desarrollo de la parte del servidor del sistema. Y, al mismo tiempo, dicho servidor simulado, por la razón descrita anteriormente, es casi imposible de implementar sin una metainformación específica adicional que podría almacenarse directamente en la especificación API e informarle del comportamiento requerido al simular el siguiente punto final. Este problema se puede resolver agregando los parámetros requeridos en forma de un archivo separado con configuraciones paralelas a la especificación básica de OAS, pero, en este caso, debe admitir estas dos fuentes diferentes por separado.
Si habrá más de un servidor simulado con herramientas que trabajen en el entorno del proceso de desarrollo de acuerdo con este principio, obtendremos un "zoológico" de herramientas, cada una de las cuales, con su propia funcionalidad única, se ve obligada a tener su propio archivo de configuración único, vinculado lógicamente a la API base -especificaciones, pero en realidad ubicadas por separado y viviendo "su propia vida".
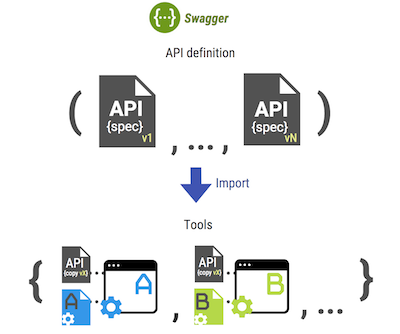
Problema: el desarrollador se verá obligado a mantener la relevancia de todas las configuraciones después de cambiar las versiones de la especificación base, a menudo en lugares y formatos completamente diferentes.
Algunos ejemplos de servicios que funcionan con un principio similar:
- SoapUI es un sistema para probar interfaces REST y SOAP. Admite la importación de un proyecto desde la especificación Swagger. Al cambiar la especificación básica de Swagger, la configuración de un proyecto basada en una lista de llamadas API continúa existiendo en paralelo y requiere sincronización manual;
- Otros productos SmartBear ;
- Apigee es un servicio de gestión del ciclo de vida API. Utiliza las especificaciones de Swagger como plantillas, en base a las cuales permite inicializar sus configuraciones de servicios internos. Tampoco hay sincronización automática;
- Readme.io es un servicio que le permite crear documentación hermosa basada en la especificación Swagger, y también tiene un mecanismo para rastrear cambios a la especificación básica y resolver conflictos mediante la actualización de la configuración del proyecto en el lado del servicio. Seguramente, esto requería una complejidad innecesaria para desarrollar este servicio.
Puede agregar muchos otros servicios a esta lista que proporcionan la función de integración con la especificación Swagger. La integración para la mayoría de ellos significa la copia habitual de la estructura básica de la especificación Swagger y la posterior autocompletación de los campos de configuración locales sin admitir la sincronización con cambios en la especificación básica.
RAML, anotaciones, superposiciones
El deseo de encontrar una herramienta que excluya la restricción de la OEA mencionada anteriormente, lo que nos permite considerar la especificación como un contrato único para todas las herramientas del cliente, nos ha llevado a familiarizarnos con el lenguaje RAML. Hay bastante escrito sobre RAML, puede leerlo, por ejemplo, aquí
https://www.infoq.com/articles/power-of-raml . Los desarrolladores de RAML han intentado establecer el soporte del lenguaje para la modularidad a nivel de su concepto. Ahora, cada empresa o desarrollador individual puede crear sus propios diccionarios públicos o utilizarlos al diseñar la API, redefinir y heredar modelos de datos preparados. A partir de la versión 1.0, RAML admite 5 tipos diferentes de módulos externos:
incluir, biblioteca, extensión, rasgo, superposición , lo que permite que cada uno de ellos se use de la manera más flexible posible según la tarea.
Es hora de discutir la característica principal de RAML, que, por razones que no se entienden completamente, no tiene análogos en OEA y Blueprint - Annotations.
Las anotaciones en RAML son la capacidad de adjuntar metadatos personalizados a las estructuras de lenguaje subyacentes.
Fue esta función RAML la que se convirtió en la razón para escribir este artículo.
Un ejemplo:
#%RAML 1.0 title: Example API mediaType: application/json # Annotation types block may be placed into external file annotationTypes: validation-rules: description: | Describes strict validation rules for the model properties. Can be used by validation library allowedTargets: [ TypeDeclaration ] type: string[] info-tip: description: | Can be used by Documentation generator for showing tips allowedTargets: [ Method, DocumentationItem, TypeDeclaration ] type: string condition: description: | Named example can be returned if condition is evaluated to true. Can be used by Intelligent mock server allowedTargets: [ Example ] type: string types: Article: type: object properties: id: type: integer title: string paragraphs: Paragraph[] createdAt: type: string (validation-rules): ["regex:/\d{4}-[01]\d-[0-3]\dT[0-2]\d:[0-5]\d:[0-5]\d(?:\.\d+)?Z?/"] Paragraph: type: object properties: order: type: integer (validation-rules): ["min:0"] content: string (validation-rules): ["max-length:1024"] /articles/{articleId}: get: (info-tip): This endpoint is deprecated description: Returns Article object by ID responses: 200: body: application/json: type: Article
Las estructuras de anotación del usuario deben tener descripciones claras en RAML. Para esto, se utiliza una sección especial de
annotationTypes , cuyas definiciones también pueden extraerse al módulo externo. Por lo tanto, se hace posible definir parámetros especiales de una herramienta externa en forma de anotaciones adjuntas a la definición base de la API RAML. Para evitar saturar la especificación básica con una gran cantidad de anotaciones para diversas herramientas externas, existe la posibilidad de transferirlas a archivos separados:
superposiciones (y también
extensiones ), con clasificación por alcance. Esto es lo que se dice sobre las superposiciones en la documentación RAML (
https://github.com/raml-org/raml-spec/blob/master/versions/raml-10/raml-10.md#overlays ):
Una superposición agrega o anula los nodos de una definición de API RAML mientras conserva sus aspectos funcionales y de comportamiento. Ciertos nodos de una definición de API RAML especifican el comportamiento de una API: sus recursos, métodos, parámetros, cuerpos, respuestas, etc. Estos nodos no se pueden cambiar aplicando una superposición. Por el contrario, otros nodos, como descripciones o anotaciones, abordan inquietudes más allá de la interfaz funcional, como la documentación descriptiva orientada al ser humano en algún idioma, o la información de implementación o verificación para su uso en herramientas automatizadas. Estos nodos se pueden cambiar aplicando una superposición.
Las superposiciones son particularmente importantes para separar la interfaz de la implementación. Las superposiciones permiten ciclos de vida separados para los aspectos de comportamiento de la API que deben controlarse estrictamente, como un contrato entre el proveedor de API y sus consumidores, en comparación con aquellos que necesitan poco control, como los aspectos orientados a la implementación o humanos que pueden evolucionar en diferentes ritmos Por ejemplo, agregar ganchos para probar y monitorear herramientas, agregar metadatos relevantes a un registro de API o proporcionar documentación humana actualizada o traducida se puede lograr sin cambiar ningún aspecto de los aspectos de comportamiento de la API. Estas cosas pueden controlarse mediante una versión rigurosa y un proceso de gestión de cambios.
En otras palabras, esta funcionalidad le permite "separar el grano de la paja", por ejemplo, la descripción principal de la especificación API, de la metainformación adicional específica de una herramienta particular que la utiliza para el trabajo. La metainformación en cada superposición separada se "cuelga" en varios bloques de la especificación en forma de anotaciones.
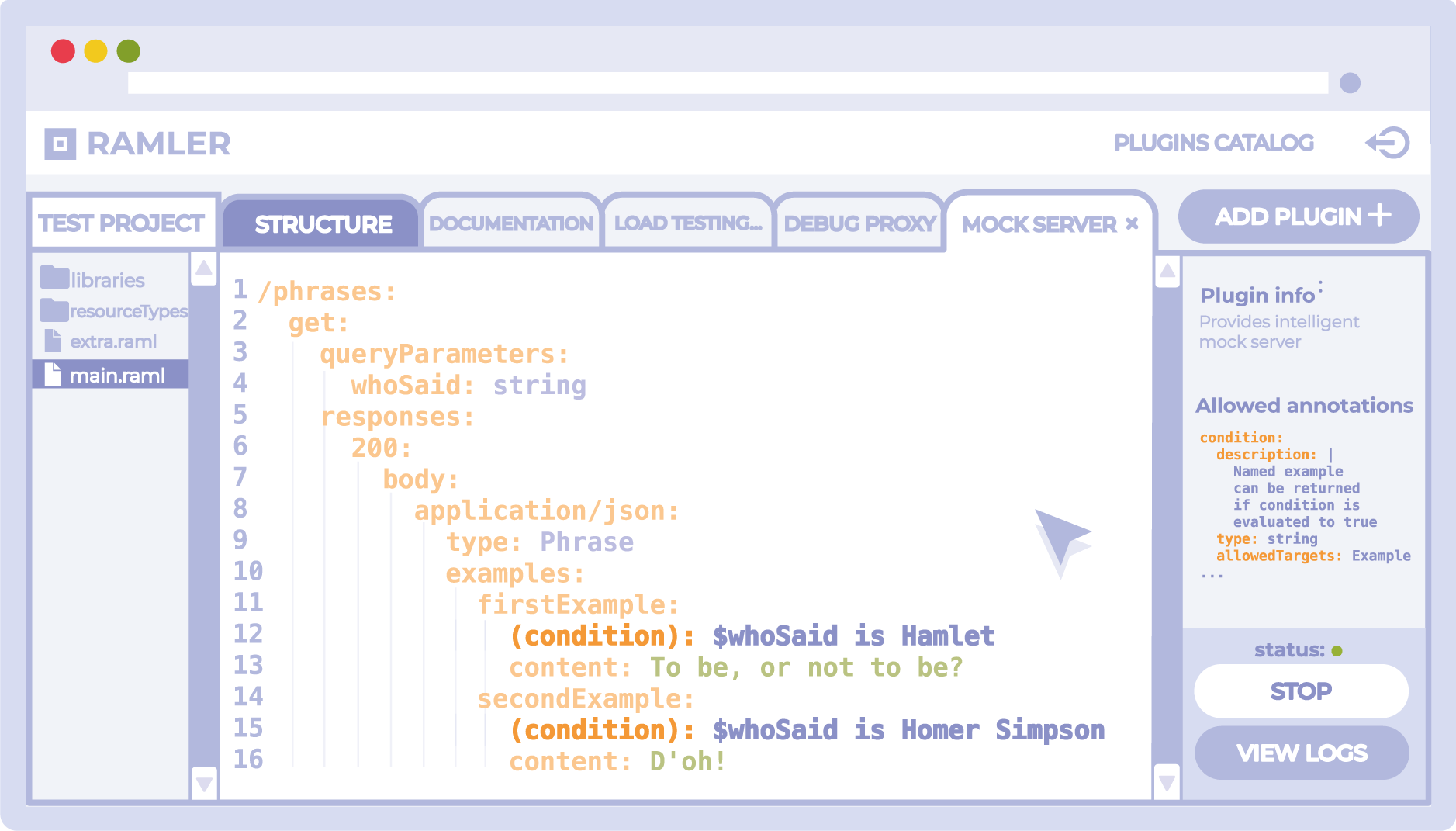
Un ejemplo de una estructura básica:
#%RAML 1.0 title: Phrases API mediaType: application/json types: Phrase: type: object properties: content: string /phrases: get: queryParameters: whoSaid: string responses: 200: body: application/json: type: Phrase
Superposición:
#%RAML 1.0 Overlay usage: Applies annotations for Intelligent mock server extends: example_for_article_2_1.raml annotationTypes: condition: description: | Named example can be returned if condition is evaluated to true type: string allowedTargets: Example /phrases: get: responses: 200: body: application/json: examples: firstExample: (condition): $whoSaid is Hamlet content: "To be, or not to be?" secondExample: (condition): $whoSaid is Homer Simpson content: "D'oh!"
Como resultado, se hace posible implementar un contrato único: toda la información funcional, de comportamiento y meta se almacena y versiona en un solo lugar, y las herramientas del contrato, los clientes del contrato, deben tener soporte para las anotaciones utilizadas en esta especificación. Por otro lado, son las herramientas en sí mismas las que pueden presentar sus propios requisitos para las anotaciones, que deben "colgarse" en la especificación; esto proporcionará una gama más amplia de posibilidades al desarrollar herramientas de contrato.
El concepto anterior se representa en la figura a continuación:
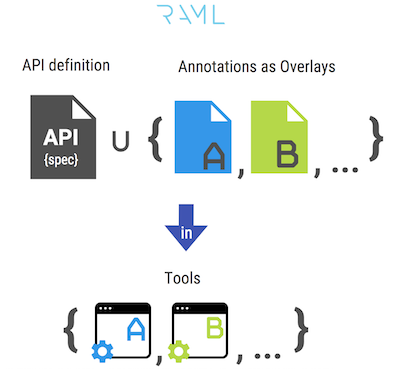
Entre los inconvenientes de este enfoque, se puede destacar la alta complejidad de la sincronización manual del archivo de especificación base y cada una de las superposiciones: al actualizar la estructura de la especificación básica, debe aplicar los cambios necesarios en las estructuras de las superposiciones. Este problema se vuelve más grave cuando aparece más de una superposición.
Una solución posible y más obvia sería desarrollar un editor especial o complemento para el editor RAML en línea existente
https://github.com/mulesoft/api-designer . El área de edición permanece sin cambios, pero es posible crear pestañas: cada nueva pestaña es una ventana para editar la superposición asignada a ella. Al editar la estructura básica de la especificación en la ventana principal, las estructuras en todas las pestañas creadas también cambian, y cuando se detecta una incompatibilidad de la nueva estructura con las anotaciones existentes ubicadas en las pestañas superpuestas, aparece una advertencia. Una consideración más detallada de dicho editor es un tema aparte y merece una seria consideración.
Desarrollos existentes
En la búsqueda de soluciones existentes que están cerca de darse cuenta de la idea de usar anotaciones como un medio para describir la metainformación, se encontraron las siguientes soluciones:
- https://github.com/raml-org/raml-annotations repositorio que contiene anotaciones oficiales aprobadas por la comunidad de desarrolladores RAML. En la versión actual, solo están disponibles las anotaciones de OAuth2. Pueden ser utilizados por herramientas externas para obtener metainformación que describa aspectos de la implementación de OAuth2 para la especificación API desarrollada;
- https://github.com/petrochenko-pavel-a/raml-annotations biblioteca de anotaciones de usuario @ petrochenko-pavel-a con una agrupación lógica por área de aplicación. El proyecto es más experimental, pero ilustra perfectamente la idea de usar anotaciones. Los grupos de anotaciones más interesantes:
- AdditionalValidation.raml : anotaciones para describir reglas adicionales para la validación de modelos de especificación. Pueden ser utilizados, por ejemplo, por la biblioteca del servidor para validar consultas de acuerdo con la especificación RAML;
- mock.raml : anotaciones para describir los detalles del servidor falso basado en la especificación RAML;
- semanticContexts.raml : anotaciones que apuntan al contexto semántico de los bloques estructurales individuales declarados de la especificación RAML;
- estructural.raml : anotaciones que aclaran el papel de una entidad RAML separada en la estructura general del modelo de dominio descrito;
- uiCore.raml : un ejemplo de anotaciones posibles para el uso de herramientas de generación de interfaz de usuario basadas en la especificación RAML;
El repositorio también contiene bibliotecas de tipos de utilidad adecuados para su uso como primitivas en la descripción de estructuras de datos de la especificación RAML.
Problemas RAML
A pesar de la funcionalidad, la progresividad de la idea básica y la atención de los grandes fabricantes de software (cisco, spotify, vmware, etc.), RAML hoy tiene serios problemas que pueden llegar a ser fatales con respecto a su destino exitoso:
- Comunidad de código abierto pequeña y fragmentada;
- Una estrategia incomprensible del desarrollador principal de RAML es mulesoft . La compañía desarrolla productos que son solo una copia de las soluciones existentes basadas en OAS (incluidas en Anypoint Platform ), en lugar de crear servicios que enfaticen las ventajas de RAML sobre Swagger;
- La consecuencia del primer párrafo: un pequeño número de bibliotecas / herramientas de código abierto;
- Umbral de entrada más alto que la OEA (esto es extraño, pero mucha gente piensa que sí);
- Debido a la gran cantidad de errores y problemas con UX / UI, el servicio principal que es completamente inadecuado y repele a los usuarios es el punto de entrada a RAML: https://anypoint.mulesoft.com/ .
Desacuerdo conceptual. Primera conclusión
Hay contradicciones dentro de la comunidad con respecto al concepto básico. Alguien piensa que RAML es un
lenguaje de definición de modelo , y alguien piensa que es un
lenguaje de definición de API como OAS o Blueprint (los tipos que se hacen llamar desarrolladores RAML a menudo mencionan esto en varios comentarios). El concepto de
lenguaje de definición de
modelo permitiría dentro de la especificación RAML describir el modelo de dominio del dominio sin vinculación estrecha con el contexto de la descripción del recurso API, expandiendo los horizontes de las opciones para usar la especificación con herramientas externas (de hecho, ¡creando la base para la existencia de este
contrato Único !) Aquí se puede ver una definición del concepto de un recurso en el sitio web readhat docs (
http://restful-api-design.readthedocs.io/en/latest/resources.html , por cierto, recomiendo a todos leer esta maravillosa guía sobre diseño de API):
Llamamos a la información que describe los tipos de recursos disponibles, su comportamiento y sus relaciones, el modelo de recursos de una API . El modelo de recursos se puede ver como la asignación RESTful del modelo de datos de la aplicación .
En el
modelo de datos de la aplicación RAML
, estos son tipos declarados en el bloque de
tipos , y el
modelo de recursos de una API es lo que se describe en el bloque RAML de
recursos . Por lo tanto, debe tener la capacidad de describir esta
asignación . Pero la implementación actual de RAML permite que dicha
asignación se realice solo de 1 a 1, es decir, para usar los tipos "tal cual" dentro de la declaración de API de recursos.
Creo que este es el principal problema del lenguaje, cuya solución permitirá que RAML vaya más allá del
lenguaje de definición API y se convierta en un
lenguaje de definición de modelo completo: un lenguaje más general (en lugar de OEA o Blueprint) utilizado para describir los contratos individuales de sistemas, que en esencia son el núcleo formal Muchos de sus componentes.
Lo anterior convierte a RAML en un jugador débil que actualmente no puede ganar la competencia contra Swagger. Quizás es por eso que, como resultado, el desarrollador principal de RAML tomó medidas drásticas
https://blogs.mulesoft.com/dev/api-dev/open-api-raml-better-together/La idea del contrato único RAML SaaS
Basado en el concepto de
contrato único , a partir de la idea de alojar una API de especificaciones Swagger basada en la OAS de especificaciones, además de confiar en la posibilidad de que RAML declare metainformación y comparta la especificación básica usando superposiciones, la idea de una solución SaaS alternativa para alojar y administrar especificaciones basadas en el lenguaje RAML sugiere Supere el Swagger Hub y Apiary en el volumen y la calidad de la posible funcionalidad.
El nuevo servicio, por analogía con el centro Swagger, será el alojamiento de contratos de usuarios con la provisión de un editor en línea y la capacidad de ver previsualizaciones de documentación con actualizaciones en tiempo real. La principal diferencia debería ser la presencia de un catálogo de complementos de contrato integrados en el servicio, cualquiera de los cuales el usuario podrá instalar especificaciones de API en su proyecto actual. Para la instalación, será necesario implementar las anotaciones RAML requeridas especificadas en la documentación del complemento. Después de agregar un nuevo complemento al proyecto, se agregará una nueva pestaña en la ventana del editor de código cuando lo cambie, las anotaciones de edición del complemento instalado estarán disponibles. La estructura de la especificación básica debe duplicarse automáticamente en todas las pestañas correspondientes a los complementos. Si surgen conflictos entre la estructura básica y las anotaciones ya existentes, un mecanismo especial debe ofrecer opciones para su solución, o resolverlo automáticamente.
Técnicamente, cada pestaña será una abstracción de la superposición RAML que contiene anotaciones de cada complemento específico. Esto asegura que la especificación sea compatible con cualquier herramienta que soporte RAML 1.0.
El directorio de complementos debe estar abierto para la expansión de la comunidad de código abierto. La implementación de complementos pagados también es posible, lo que puede servir como un incentivo para el desarrollo de nuevos.
Posibles complementos: documentación API con soporte para una gran cantidad de anotaciones para la parametrización flexible de su representación, servidor simulado "inteligente" (del ejemplo anterior), bibliotecas descargables para validar solicitudes o generación de código, herramientas de depuración para solicitudes API salientes para aplicaciones móviles (proxy de almacenamiento en caché), pruebas de carga con la configuración de pruebas de flujo a través de anotaciones, varios complementos para la integración con servicios externos.
Esta idea del servicio contiene claras ventajas sobre los servicios existentes para administrar las especificaciones de la API, y su implementación allana el camino para un posible cambio en el enfoque de la implementación de cualquier sistema externo que de alguna manera esté relacionado con la API.
Segunda conclusión
El propósito de este artículo no es criticar a Swagger, Apiary u otras herramientas estándar de facto para desarrollar API, sino más bien examinar la diferencia conceptual con el enfoque de las especificaciones de diseño promovidas por RAML, intentar
primero introducir el concepto de
Contrato y considerar la posibilidad de su implementación basada en RAML. Otro objetivo era el deseo de atraer la merecida atención de los desarrolladores a RAML para el posible desarrollo de su comunidad.
Sitio oficial RAMLCanal flojoEspecificaciónGracias por su atencion