Hola Habr, queremos hablar sobre uno de los proyectos del HeadHunter 2018 de la Escuela de Programadores. A continuación hay un artículo de nuestro graduado en el que hablará sobre la experiencia adquirida durante la capacitación.

Hola a todos Este año me gradué de la hh School of Programmers y en esta publicación hablaré sobre el proyecto de capacitación en el que participé. Durante el entrenamiento en la escuela, y especialmente en el proyecto, me perdí un ejemplo de una aplicación de combate (y aún mejor una guía), en la que pude ver cómo separar correctamente la lógica y construir una arquitectura escalable. Todos los artículos que encontré fueron difíciles de entender para un principiante, ya que o IoC se utilizó activamente en ellos sin explicaciones exhaustivas sobre cómo agregar nuevos componentes o modificar los antiguos, o eran arcaicos y contenían una tonelada de configuraciones xml y una interfaz en jsp. Traté de concentrarme en mi nivel antes de entrenar, es decir casi cero con algunas advertencias, por lo que este artículo debería ser útil para futuros estudiantes de la escuela, así como para entusiastas autodidactas que decidieron comenzar a escribir en Java.
Dado (enunciado del problema)
Equipo - 5 personas. El plazo es de 3 meses, al final de cada uno hay una demostración. El objetivo es crear una aplicación que ayude a RRHH a acompañar a los empleados en un período de prueba, automatizando todos los procesos que resultan. En la entrada nos dijeron cómo se organiza ahora el período de prueba (IS): tan pronto como se sabe que un nuevo empleado está saliendo, RR.HH. comienza a patear al futuro líder para establecer tareas para el IP, y esto debe hacerse antes del primer día hábil. El día que el empleado se va a trabajar, RR. HH. Celebra una reunión de bienvenida, habla sobre la infraestructura de la empresa y entrega tareas para IP. Después de 1,5 y 3 meses, se lleva a cabo una reunión intermedia y final de recursos humanos, el líder y el empleado, en la que se discute el éxito del pasaje y se elabora un formulario de resultados. En caso de éxito, después de la reunión final, al empleado se le entrega un cuestionario impreso de novato (preguntas en el estilo de "disfrutar el placer de la propiedad intelectual") y obtener tareas de recursos humanos en jira para completar un empleado de VHI.
Diseño
Decidimos hacer para cada empleado una página personal en la que se mostrará información general (nombre, departamento, líder, etc.), un campo para comentarios e historial de cambios, archivos adjuntos (tareas en la IP, cuestionario) y flujo de trabajo del empleado que refleje nivel de paso de IP. Se decidió dividir el flujo de trabajo en 8 etapas, a saber:
- Etapa 1: agregar un empleado: se completa inmediatamente después de registrar un nuevo empleado en el sistema de recursos humanos. Al mismo tiempo, se envían tres calendarios a Recursos Humanos para un pozo, una reunión intermedia y final.
- Segunda etapa: coordinación de tareas en IP: se envía un formulario a la cabeza para configurar las tareas en IP, que HR recibirá después de completarlo. A continuación, HR los imprime, los firma y marca la finalización de la etapa en la interfaz.
- Tercera etapa - reunión de bienvenida: RRHH celebra una reunión y presiona el botón "Etapa completada".
- 4ta etapa - reunión provisional: similar a la tercera etapa
- La quinta etapa: los resultados de una reunión provisional: Recursos Humanos completa los resultados en la página del empleado y hace clic en "Siguiente".
- 6ta etapa - reunión final: similar a la tercera etapa
- Séptima etapa: resultados de la reunión final: similar a la quinta etapa
- Octava etapa: finalización de la IP: en caso de completar con éxito la IP, se enviará al empleado un enlace con el formulario del cuestionario por correo electrónico, y en jira se crea automáticamente una tarea para el registro del seguro médico voluntario (la tarea se inició antes que nosotros).
Todas las etapas tienen tiempo, después de lo cual la etapa se considera expirada y se resalta en rojo, y llega una notificación por correo. La hora de finalización debe ser editable, por ejemplo, en caso de que la reunión provisional sea un día festivo o por alguna razón la reunión deba reprogramarse.
Desafortunadamente, los prototipos dibujados en un pedazo de papel / tableros no se han conservado, pero al final habrá capturas de pantalla de la aplicación terminada.
Operación
Una de las metas de la escuela es preparar a los estudiantes para el trabajo en proyectos grandes, por lo que el proceso de liberación de tareas fue apropiado para nosotros.
Al final del trabajo en la tarea, se lo damos a review_1 a otro estudiante del equipo para corregir errores obvios / intercambiar experiencias. Luego viene review_2: la tarea es verificada por dos mentores que se aseguran de que no liberemos el govnokod en pareja con el revisor_1. Se suponían pruebas adicionales, pero esta etapa no es muy apropiada, dada la escala del proyecto escolar. Entonces, después de pasar por la revisión, pensamos que la tarea estaba lista para su lanzamiento.
Ahora algunas palabras sobre el despliegue. La aplicación debe estar disponible todo el tiempo en la red desde cualquier computadora. Para hacer esto, compramos una máquina virtual barata (por 100 rublos / mes), pero, como descubrí más tarde, todo se podía organizar de forma gratuita y de moda en el docker de AWS . Para una integración continua, elegimos Travis. Si alguien no lo sabe (personalmente no he oído hablar de la integración continua antes de la escuela), esto es algo tan bueno que su github monitoreará y cuando aparezca un nuevo commit (cómo configurarlo), recopile el código en jar, envíelo al servidor y reinicie la aplicación automáticamente. La forma de construirlo se describe en el Travis Jam en la raíz del proyecto, es bastante similar a bash, por lo que creo que no se requieren comentarios. También compramos el dominio www.adaptation.host para no registrar una dirección IP fea en la barra de direcciones de la demostración. También configuramos postfix (para enviar correo), apache (no nginx, porque apache estaba listo para usar) y el servidor jira (prueba). El frontend y el backend fueron creados por dos servicios separados que se comunicarán a través de http (# 2k18, # microservices). Esta parte del artículo "en la Escuela de Programadores HeadHunter" finaliza sin problemas y pasamos al servicio de descanso de Java.
Backend
0. Introducción
Utilizamos las siguientes tecnologías:
- JDK 1.8;
- Maven 3.5.2;
- Postgres 9.6;
- Hibernate 5.2.10;
- Jetty 9.4.8;
- Jersey 2.27.
Como marco, tomamos NaB 3.5.0 de hh. En primer lugar, se usa en HeadHunter, y en segundo lugar, contiene el embarcadero, jersey, hibernate, postgres incrustados fuera de la caja, que está escrito en el github. Voy a aclarar brevemente para principiantes: jetty es un servidor web que identifica a los clientes y organiza sesiones para cada uno de ellos; jersey - un marco que ayuda a crear convenientemente un servicio RESTful; hibernate - ORM para simplificar el trabajo con la base de datos; maven es un coleccionista de proyectos java.
Mostraré un ejemplo simple de cómo trabajar con esto. Creé un pequeño repositorio de prueba , en el que agregué dos entidades: un usuario y un currículum, así como recursos para crearlos y recibirlos con el enlace OneToMany / ManyToOne. Para comenzar, simplemente clone el repositorio y ejecute mvn clean install exec: java en la raíz del proyecto. Antes de comentar sobre el código, le contaré sobre la estructura de nuestro servicio. Se parece a esto:
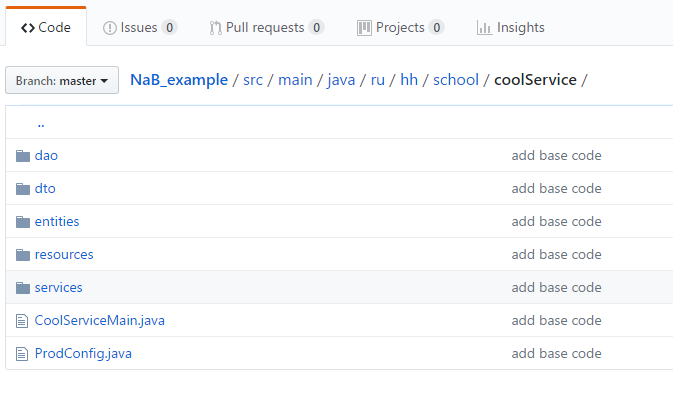
Directorios principales:
- Servicios: el directorio principal de la aplicación, aquí se almacena toda la lógica de negocios. En otros lugares, trabajar con datos sin una buena razón no debería serlo.
- Recursos: controladores de URL, una capa entre los servicios y la interfaz. Aquí se permite la validación de datos entrantes y la conversión de datos salientes, pero no la lógica de negocios.
- Dao (objeto de acceso a datos): una capa entre la base de datos y los servicios. Tao debe contener solo operaciones básicas fundamentales: agregar, contar, actualizar, eliminar uno / todos.
- Entidad: objetos que ORM intercambia con la base de datos. Como regla, corresponden directamente a las tablas y deben contener todos los campos como la entidad en la base de datos con los tipos correspondientes.
- Dto (objeto de transferencia de datos): un análogo de la entidad, solo para recursos (frente), ayuda a formar json a partir de los datos que queremos enviar / recibir.
1. Base
En el buen sentido, debe usar los postgres instalados cerca, como en la aplicación principal, pero quería que el caso de prueba sea simple y se ejecute con un solo comando, así que tomé el HSQLDB incorporado. La conexión de la base de datos a nuestra infraestructura se realiza agregando un DataSource a ProdConfig (también recuerde decirle a Hibernate qué base de datos está usando):
@Bean(destroyMethod = "shutdown") DataSource dataSource() { return new EmbeddedDatabaseBuilder() .setType(EmbeddedDatabaseType.HSQL) .addScript("db/sql/create-db.sql") .build(); }
Creé el script de creación de tabla en el archivo create-db.sql. Puede agregar otros scripts que inicializan la base de datos. En nuestro ejemplo ligero in_memory, podríamos prescindir de los scripts. Si especifica hibernate.hbm2ddl.auto=create en la configuración de hibernate.properties, hibernate creará tablas por entidad cuando se inicie la aplicación. Pero si necesita tener algo en la base de datos que la entidad no tiene, entonces no puede prescindir de un archivo. Personalmente, estoy acostumbrado a compartir la base de datos y la aplicación, por lo que generalmente no confío en hibernate para hacer tales cosas.
db/sql/create-db.sql :
CREATE TABLE employee ( id INTEGER IDENTITY PRIMARY KEY, first_name VARCHAR(256) NOT NULL, last_name VARCHAR(256) NOT NULL, email VARCHAR(128) NOT NULL ); CREATE TABLE resume ( id INTEGER IDENTITY PRIMARY KEY, employee_id INTEGER NOT NULL, position VARCHAR(128) NOT NULL, about VARCHAR(256) NOT NULL, FOREIGN KEY (employee_id) REFERENCES employee(id) );
2. Entidad
entities/employee :
@Entity @Table(name = "employee") public class Employee { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) @Column(name = "id", nullable = false) private Integer id; @Column(name = "first_name", nullable = false) private String firstName; @Column(name = "last_name", nullable = false) private String lastName; @Column(name = "email", nullable = false) private String email; @OneToMany(mappedBy = "employee") @OrderBy("id") private List<Resume> resumes;
entities/resume :
@Entity @Table(name = "resume") public class Resume { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Integer id; @ManyToOne(fetch = FetchType.LAZY) @JoinColumn(name = "employee_id") private Employee employee; @Column(name = "position", nullable = false) private String position; @Column(name = "about") private String about;
Las entidades no se refieren entre sí con el campo de clase, sino con todo el objeto padre / hijo. Por lo tanto, podemos obtener recursividad cuando intentamos tomar de la base de datos de Empleados, para lo cual se dibujan currículums, para lo cual ... Para evitar que esto suceda, indicamos las anotaciones @OneToMany(mappedBy = "employee") y @ManyToOne(fetch = FetchType.LAZY) . Se tendrán en cuenta en el servicio al ejecutar una transacción de escritura / lectura desde la base de datos. Configurar FetchType.LAZY es opcional, pero el uso de una comunicación diferida facilita la transacción. Entonces, si en una transacción obtenemos un currículum vitae de la base de datos y no contactamos a su propietario, entonces la entidad del empleado no se cargará. Puede verificar esto usted mismo: elimine FetchType.LAZY y vea en la depuración que regresa del servicio junto con el currículum. Pero debe tener cuidado: si no cargamos a los empleados en la transacción, acceder a los campos de empleados fuera de la transacción puede causar una LazyInitializationException .
3. Dao
En nuestro caso, EmployeeDao y ResumeDao son casi idénticos, por lo que daré aquí solo uno de ellos.
EmployeeDao :
public class EmployeeDao { private final SessionFactory sessionFactory; @Inject public EmployeeDao(SessionFactory sessionFactory) { this.sessionFactory = sessionFactory; } public void save(Employee employee) { sessionFactory.getCurrentSession().save(employee); } public Employee getById(Integer id) { return sessionFactory.getCurrentSession().get(Employee.class, id); } }
La @Inject significa que en el constructor de nuestro dao, se utiliza la inyección de dependencia. En mi vida pasada, un físico que parcelaba archivos, construía gráficos basados en los resultados de los números y, como mínimo, descubría la POO, en las guías de Java, tales construcciones parecían un poco locas. Y en la escuela, quizás, este tema es el más obvio, en mi humilde opinión. Afortunadamente, hay mucho material sobre DI en Internet. Si eres demasiado vago para leer, entonces el primer mes puedes seguir la regla: registrar nuevos recursos / servicios / Tao en nuestra configuración de contexto , agregar entidades a la asignación . Si necesita usar algunos servicios / tao en otros, debe agregarlos en el constructor con la inyección de anotación, como se muestra arriba, y el resorte inicializa todo para usted. Pero entonces todavía tienes que lidiar con DI.
4. Dto
Dto, como dao, son casi idénticos para empleado y currículum. Consideramos solo employeeDto aquí. Necesitaremos dos clases: EmployeeCreateDto , necesario al crear un empleado; EmployeeDto utilizado en el recibo (contiene id campos adicionales y resumes ). El campo de id se agrega para que en el futuro, a pedido del exterior, podamos trabajar con los empleados sin realizar una búsqueda preliminar de la entidad por email . El campo de resumes para recibir a un empleado junto con todos sus currículums en una sola solicitud. Sería posible administrar con un dto para todas las operaciones, pero luego, para la lista de todos los currículums de un empleado en particular, tendríamos que crear un recurso adicional, como getResumesByEmployeeEmail, contaminar el código con consultas de bases de datos personalizadas y tachar todas las comodidades proporcionadas por ORM.
EmployeeCreateDto :
public class EmployeeCreateDto { public String firstName; public String lastName; public String email; }
EmployeeDto :
public class EmployeeDto { public Integer id; public String firstName; public String lastName; public String email; public List<ResumeDto> resumes; public EmployeeDto(){ } public EmployeeDto(Employee employee){ id = employee.getId(); firstName = employee.getFirstName(); lastName = employee.getLastName(); email = employee.getEmail(); if (employee.getResumes() != null) { resumes = employee.getResumes().stream().map(ResumeDto::new).collect(Collectors.toList()); } } }
Una vez más, llamo la atención sobre el hecho de que escribir lógica en dto es tan indecente que todos los campos se designan como public , para no usar getters y setters.
5. Servicio
EmployeeService :
public class EmployeeService { private EmployeeDao employeeDao; private ResumeDao resumeDao; @Inject public EmployeeService(EmployeeDao employeeDao, ResumeDao resumeDao) { this.employeeDao = employeeDao; this.resumeDao = resumeDao; } @Transactional public EmployeeDto createEmployee(EmployeeCreateDto employeeCreateDto) { Employee employee = new Employee(); employee.setFirstName(employeeCreateDto.firstName); employee.setLastName(employeeCreateDto.lastName); employee.setEmail(employeeCreateDto.email); employeeDao.save(employee); return new EmployeeDto(employee); } @Transactional public ResumeDto createResume(ResumeCreateDto resumeCreateDto) { Resume resume = new Resume(); resume.setEmployee(employeeDao.getById(resumeCreateDto.employeeId)); resume.setPosition(resumeCreateDto.position); resume.setAbout(resumeCreateDto.about); resumeDao.save(resume); return new ResumeDto(resume); } @Transactional(readOnly = true) public EmployeeDto getEmployeeById(Integer id) { return new EmployeeDto(employeeDao.getById(id)); } @Transactional(readOnly = true) public ResumeDto getResumeById(Integer id) { return new ResumeDto(resumeDao.getById(id)); } }
Aquellas transacciones que nos protegen de LazyInitializationException (y no solo). Para comprender las transacciones en hibernación, recomiendo un excelente trabajo en el hub ( leer más ... ), que me ayudó mucho a su debido tiempo.
6. Recursos
Finalmente, agregue los recursos para crear y obtener nuestras entidades:
EmployeeResource :
@Path("/") @Singleton public class EmployeeResource { private final EmployeeService employeeService; public EmployeeResource(EmployeeService employeeService) { this.employeeService = employeeService; } @GET @Produces("application/json") @Path("/employee/{id}") @ResponseBody public Response getEmployee(@PathParam("id") Integer id) { return Response.status(Response.Status.OK) .entity(employeeService.getEmployeeById(id)) .build(); } @POST @Produces("application/json") @Path("/employee/create") @ResponseBody public Response createEmployee(@RequestBody EmployeeCreateDto employeeCreateDto){ return Response.status(Response.Status.OK) .entity(employeeService.createEmployee(employeeCreateDto)) .build(); } @GET @Produces("application/json") @Path("/resume/{id}") @ResponseBody public Response getResume(@PathParam("id") Integer id) { return Response.status(Response.Status.OK) .entity(employeeService.getResumeById(id)) .build(); } @POST @Produces("application/json") @Path("/resume/create") @ResponseBody public Response createResume(@RequestBody ResumeCreateDto resumeCreateDto){ return Response.status(Response.Status.OK) .entity(employeeService.createResume(resumeCreateDto)) .build(); } }
Produces(“application/json”) necesita Produces Produces(“application/json”) para que json y dto se conviertan correctamente entre sí. Requiere una dependencia pom.xml:
<dependency> <groupId>org.glassfish.jersey.media</groupId> <artifactId>jersey-media-json-jackson</artifactId> <version>${jersey.version}</version> </dependency>
Otros convertidores json por alguna razón exponen MediaType no válido.
7. Resultado
Ejecute y verifique lo que tenemos ( mvn clean install exec:java en la raíz del proyecto). El puerto en el que se ejecuta la aplicación se especifica en service.properties . Crear un usuario y reanudar. Hago esto con curl, pero puedes usar cartero si desprecias la consola.
curl --header "Content-Type: application/json" \ --request POST \ --data '{"firstName": "Jason", "lastName": "Statham", "email": "jasonst@t.ham"}' \ http://localhost:9999/employee/create curl --header "Content-Type: application/json" \ --request POST \ --data '{"employeeId": 0, "position": "Voditel", "about": "Opyt raboty perevozchikom 15 let"}' \ http://localhost:9999/resume/create curl --header "Content-Type: application/json" --request GET http://localhost:9999/employee/0 curl --header "Content-Type: application/json" --request GET http://localhost:9999/employee/0
Todo funciona bien Entonces tenemos un backend que proporciona api. Ahora puede iniciar el servicio con la interfaz y dibujar los formularios correspondientes. Esta es una buena base para una aplicación que puede usar para iniciar la suya configurando varios componentes a medida que se desarrolla el proyecto.
Conclusión
El código de la aplicación principal se mantiene en funcionamiento en el github con instrucciones para comenzar en la pestaña wiki.
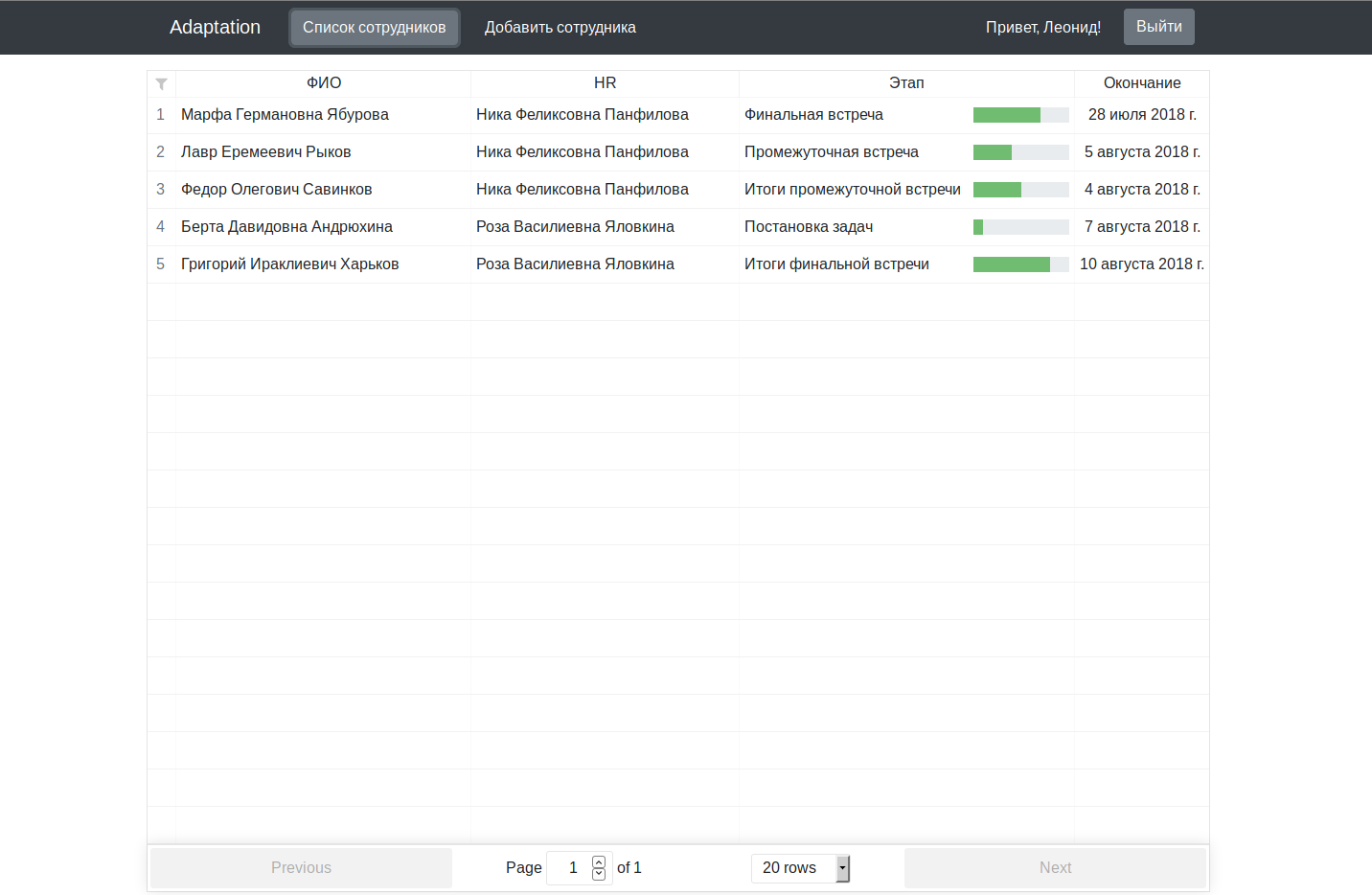
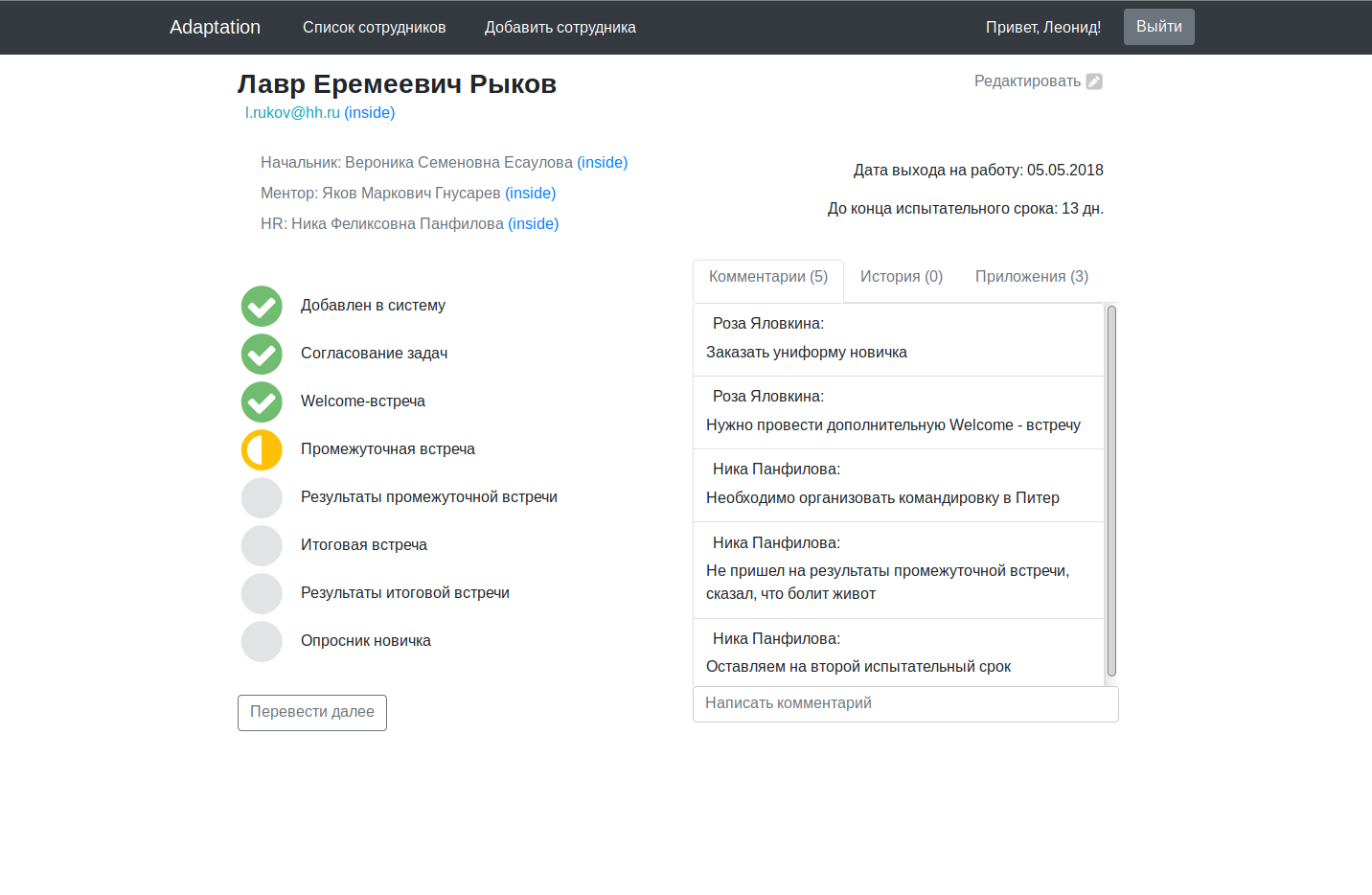
Para un proyecto multimillonario, parece un poco húmedo, por supuesto, pero como excusa, les recuerdo que trabajamos en él por la noche, después del trabajo / estudio.
Si el número de personas interesadas excede el número de zapatillas, en el futuro puedo convertir esto en una serie de artículos en los que hablaré sobre el frente, la dockerización y los matices que encontramos al trabajar con archivos de correo / grasa / dock.
PD: Después de un tiempo de haber sobrevivido a la conmoción de la escuela, el resto del equipo se reunió y, después de analizar los vuelos, decidió hacer la adaptación 2.0, teniendo en cuenta todos los errores. El objetivo principal del proyecto es el mismo: aprender a hacer aplicaciones serias, construir una arquitectura bien pensada y ser solicitado por especialistas en el mercado. Puedes seguir el trabajo en el mismo repositorio. Las solicitudes de piscina son bienvenidas. ¡Gracias por su atención y deséenos buena suerte!
bollos
video conferencia hoc ioc