Contrariamente a la creencia popular, el aprendizaje automático no es una invención del siglo XXI. En los últimos veinte años, solo han aparecido plataformas de hardware lo suficientemente productivas como para que sea aconsejable utilizar redes neuronales y otros modelos de aprendizaje automático para resolver cualquier problema aplicado a diario. Las implementaciones de software de algoritmos y modelos también se han ajustado.
La tentación de hacer que las máquinas se encarguen de nuestra seguridad y protejan a las personas (bastante flojas, pero inteligentes) se ha vuelto demasiado grande. Según
CB Insights, casi 90 nuevas empresas (2 de ellas con una estimación de más de mil millones de dólares) están tratando de automatizar al menos parte de las tareas rutinarias y monótonas. Con mayor o menor éxito.

El principal problema de
la Inteligencia Artificial en materia de seguridad en este momento es demasiada exageración y una mierda de marketing franca. La frase "inteligencia artificial" atrae a los inversores. Las personas vienen a la industria que están dispuestas a llamar a la IA la correlación más simple de los eventos. Los compradores de soluciones por su propio dinero no obtienen lo que esperaban (incluso si estas expectativas eran inicialmente demasiado altas).

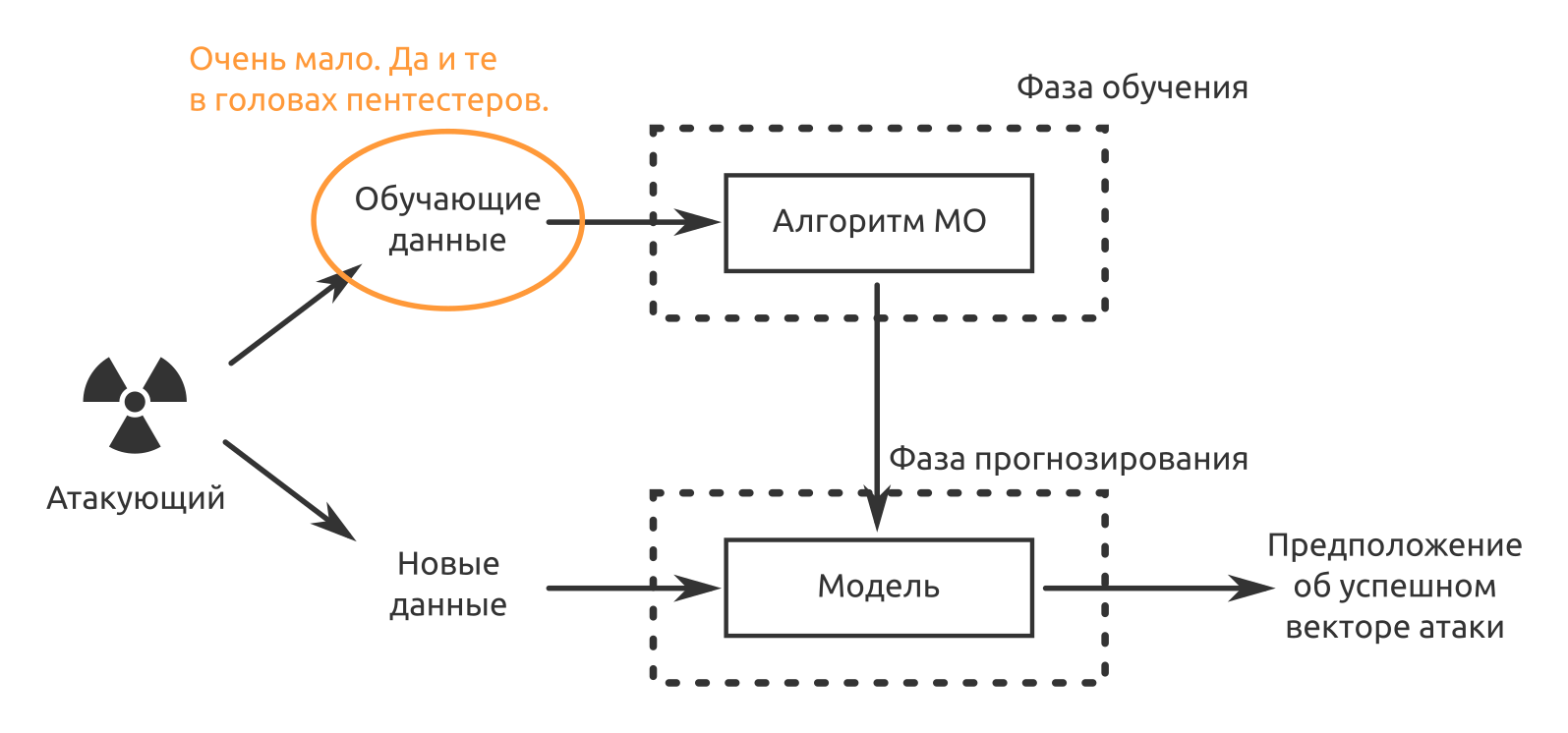
Como se puede ver en el mapa de CB Insights, hay docenas de áreas donde se usa MO. Pero el aprendizaje automático aún no se ha convertido en la "píldora mágica" de la ciberseguridad debido a varias limitaciones serias.
La primera limitación es la aplicabilidad estrecha de la funcionalidad de cada modelo en particular. Una red neuronal puede hacer bien una cosa. Si reconoce bien las imágenes, la misma red no podrá reconocer el audio. Lo mismo con la seguridad de la información, si el modelo fue entrenado para clasificar eventos de sensores de red y detectar ataques informáticos en equipos de red, entonces no podrá trabajar con dispositivos móviles, por ejemplo. Si el cliente es un fanático de la IA, comprará, comprará y comprará.
La segunda limitación es la falta de datos de entrenamiento. Las soluciones están preformadas, pero no en sus datos. Si la situación "Quién considera falso positivo en las primeras dos semanas de operación" aún puede aceptarse, en el futuro habrá un ligero desconcierto del "personal de seguridad", porque compraron una decisión para que la máquina asumiera la rutina, y no al revés.

Lo tercero y probablemente lo más importante hasta ahora es que los productos MO no pueden hacerse responsables de sus decisiones. Incluso el desarrollador de un "medio único de protección con inteligencia artificial" puede responder a tales afirmaciones: "Bueno, ¿qué querías? ¡Una red neuronal es una caja negra! ¿Por qué decidió ella de esa manera? Nadie excepto ella lo sabe. Por lo tanto, las personas ahora confirman los incidentes de seguridad de la información. Las máquinas ayudan, pero las personas siguen siendo responsables.
Hay problemas con la protección de la información. Se resolverán tarde o temprano. ¿Pero qué hay del ataque? ¿Pueden MO e IA convertirse en la "bala de plata" de los ciberataques?
Opciones para usar el aprendizaje automático para aumentar la probabilidad de éxito de pentest o análisis de seguridad
Probablemente, ahora es más rentable usar MO donde:
- necesita crear algo similar a lo que la red neuronal ya ha encontrado;
- Es necesario identificar patrones que no sean obvios para el hombre.
El MO ya lo está haciendo muy bien con estas tareas. Pero además de esto, algunas tareas pueden acelerarse. Por ejemplo, mis colegas ya han escrito sobre la
automatización de ataques usando python y metasploit .
Tratando de engañar
O verifique el conocimiento de los empleados sobre los problemas de seguridad de la información. Como lo demuestra nuestra práctica de pruebas de penetración, la ingeniería social funciona: en casi todos los proyectos donde se llevó a cabo tal ataque, tuvimos éxito.
Supongamos que ya hemos restaurado utilizando métodos tradicionales (sitio web de la empresa, redes sociales, sitios de trabajo, publicaciones, etc.):
- estructura organizacional;
- lista de empleados clave;
- Patrones de direcciones de correo electrónico o direcciones reales
- telefoneó, fingió ser un cliente potencial, descubrió el nombre del vendedor, gerente, secretario.
Luego, necesitamos obtener datos para entrenar una red neuronal que imite la voz de una persona en particular. En nuestro caso, alguien de la gerencia de la empresa probada. Este
artículo establece que un minuto de voz es suficiente para fingir auténticamente.
Estamos buscando grabaciones de discursos en conferencias, vamos a ellos mismos y los grabamos, tratamos de hablar con la persona que necesitamos. Si logramos imitar una voz, podemos crear una situación estresante para una víctima específica del ataque nosotros mismos.
- hola
- Vendedor Preseylovich, hola. Este es el director Nachalnikovich. Tu teléfono móvil no responde. Allí recibirá una carta de Vector-Fake LLC, consulte. ¡Esto es urgente!
"Sí, pero ..."
- Eso es todo, ya no puedo hablar. Estoy en una reunion. Antes de la comunicación. ¡Contéstales!
¿Quién no contestará? ¿Quién no verá el archivo adjunto? Todos lo verán. Y puede cargar cualquier cosa en esta carta. Al mismo tiempo, no es necesario saber ni el número de teléfono del director ni el número de teléfono personal del vendedor; no es necesario falsificar una dirección de correo electrónico en una dirección corporativa interna de la que saldrá un correo electrónico malicioso.
Por cierto, la preparación de ataques (recopilación y análisis de datos) también se puede automatizar parcialmente. Ahora estamos buscando un
desarrollador en un equipo que resuelva ese problema y cree un paquete de software que facilite la vida de un analista en el campo de la inteligencia competitiva y la seguridad económica de una empresa.
Atacamos la implementación de criptosistemas
Supongamos que podemos escuchar el tráfico encriptado de la organización atacada. Pero nos gustaría saber qué hay exactamente en este tráfico. Esta investigación de los empleados de Cisco "
Detectando código malicioso en el tráfico TLS cifrado (sin descifrado) " se le ocurrió la idea. De hecho, si podemos determinar la presencia de objetos maliciosos a partir de los datos de los servicios de NetFlow, TLS y DNS, ¿qué nos impide utilizar los mismos datos para identificar las comunicaciones entre los empleados de la organización atacada y entre los empleados y los servicios de TI corporativos?
Atacar una cripta en la frente es más costoso. Por lo tanto, usando datos en las direcciones y puertos de origen y destino, la cantidad de paquetes transmitidos y su tamaño, parámetros de tiempo, tratamos de determinar el tráfico encriptado.
Además, habiendo determinado las puertas de enlace criptográficas o los nodos finales en el caso de las comunicaciones p2p, comenzamos a finalizarlos, lo que obliga a los usuarios a cambiar a métodos de comunicación menos seguros que son más fáciles de atacar.
El encanto del método consiste en dos ventajas:
- La máquina se puede entrenar en casa, en virtualochki. Hay muchos productos gratuitos e incluso de código abierto para crear comunicaciones seguras. “Máquina, este es tal y tal protocolo, tiene tal y tal tamaño de paquete, tal y tal entropía. Lo entiendes? ¿Recuerdas? Repita tantas veces como sea posible en diferentes tipos de datos abiertos.
- No es necesario "conducir" y pasar por el modelo todo el tráfico, solo los metadatos son suficientes.
Desventaja: aún es necesario recibir MitM.
Buscando errores de software y vulnerabilidades
Probablemente el intento más famoso de automatizar la búsqueda, explotación y corrección de vulnerabilidades es el DARPA Cyber Grand Challenge. En 2016, siete sistemas totalmente automáticos diseñados por diferentes equipos se unieron en la batalla final similar al CTF. Por supuesto, el objetivo del desarrollo se declaró exclusivamente bueno: proteger las infraestructuras, las aplicaciones, en tiempo real y con una participación mínima de las personas. Pero puede ver los resultados desde un ángulo diferente.
La primera dirección en la que se está desarrollando el MO en este asunto es la automatización difusa. Los mismos miembros de CGC hicieron un uso extensivo de American Fuzzy Lop. Dependiendo de la configuración, los fuzzers generan más o menos salida durante la operación. Donde hay muchos datos estructurados y débilmente estructurados, los modelos MO buscan patrones perfectamente. Si el intento de "descartar" la aplicación funcionó con alguna entrada, existe la posibilidad de que este enfoque funcione en otro lugar.
Lo mismo ocurre con el análisis de código estático y el análisis dinámico de archivos ejecutables cuando el código fuente de la aplicación no está disponible. Las redes neuronales pueden buscar no solo fragmentos de código con vulnerabilidades, sino también códigos que parecen vulnerables. Afortunadamente, hay mucho código con vulnerabilidades confirmadas (y reparadas). El investigador tendrá que verificar esta sospecha. Con cada nuevo error encontrado, dicho NS se volverá cada vez más "más inteligente". Gracias a este enfoque, puede evitar usar solo firmas preescritas.
En el análisis dinámico, si una red neuronal puede "comprender" la relación entre los datos de entrada (incluidos los datos del usuario), el orden de ejecución, las llamadas al sistema, la asignación de memoria y las vulnerabilidades confirmadas, eventualmente puede buscar nuevas.
Operación automatizada
Ahora con la operación puramente automática hay un problema:
Isao Takaesu y los otros colaboradores que desarrollan Deep Exploit, "Herramienta de prueba de penetración totalmente automática que usa Machine Learning", están tratando de resolverlo. Los detalles sobre él están escritos
aquí y
aquí .
Esta solución puede funcionar en dos modos: modo de recopilación de datos y modo de fuerza bruta.
En el primer modo, DE identifica todos los puertos abiertos en el host atacado y lanza exploits que anteriormente funcionaban para tal combinación.
En el segundo modo, el atacante indica el nombre del producto y el número de puerto, y DE "aciertos por área" utilizando todas las combinaciones disponibles del exploit, la carga útil y el objetivo.
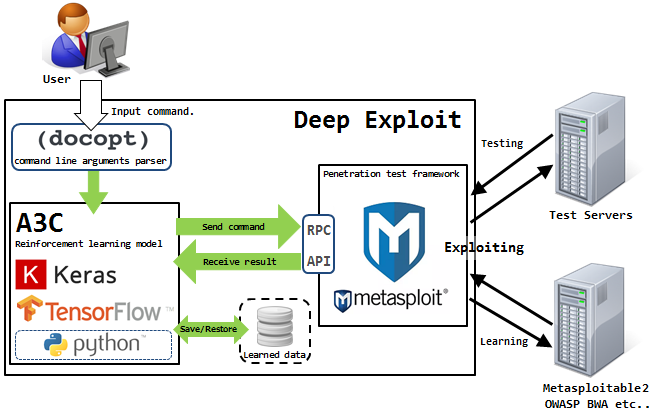
Deep Exploit puede aprender de manera independiente métodos operativos utilizando entrenamiento reforzado (gracias a los comentarios que DE recibe del sistema que está siendo atacado).
¿Puede la IA reemplazar al equipo de Pentester ahora?
Probablemente aún
no .
Las máquinas tienen problemas para construir cadenas lógicas de explotación de vulnerabilidades identificadas. Pero esto es precisamente lo que a menudo afecta directamente el logro del objetivo de las pruebas de penetración. Una máquina puede encontrar una vulnerabilidad, incluso puede crear una vulnerabilidad por sí misma, pero no puede evaluar el grado de impacto de esta vulnerabilidad en un sistema de información específico, recursos de información o procesos comerciales de la organización en su conjunto.
El funcionamiento de los sistemas automatizados genera MUCHO ruido en el sistema atacado, lo que se nota fácilmente en los equipos de protección. Los autos funcionan torpemente. Es posible reducir este ruido y tener una idea del sistema con la ayuda de la ingeniería social, y con esto las máquinas tampoco lo hacen.
Y los autos no tienen ingenio ni sentido. Recientemente tuvimos un proyecto donde la forma más rentable de realizar pruebas sería utilizar un modelo controlado por radio. No puedo imaginar cómo una persona que no sea persona podría pensar en tal cosa.
¿Qué ideas para la automatización podrías ofrecer?