Hace algún tiempo, apareció un enlace en mi feed de Facebook al libro Anhelo de Aprendizaje Automático de Andrew Ng, que se puede traducir como Pasión de Aprendizaje Automático o Sed de Aprendizaje Automático.

Las personas interesadas en el aprendizaje automático o trabajar en esta área no necesitan presentar a Andrew. Para los no iniciados, es suficiente decir que es una estrella de clase mundial en el campo de la inteligencia artificial. Científico, ingeniero, emprendedor, uno de los fundadores de Coursera . Es autor de una excelente introducción al aprendizaje automático y los cursos que conforman la especialización de aprendizaje profundo .
Tengo un profundo respeto por Andrew, tomé sus cursos, así que inmediatamente decidí leer el libro publicado. Resultó que el libro aún no se ha escrito y se publica en partes, como está escrito por el autor. En general, esto ni siquiera es un libro, sino un borrador de un libro futuro (se desconoce si se publicará en papel). Entonces surgió la idea de traducir los capítulos que se publicaban. Actualmente traducido 14 capítulos (este es el primer extracto publicado del libro). Planeo continuar este trabajo y traducir todo el libro. Publicaré capítulos traducidos en mi blog sobre Habré.
Al momento de escribir estas líneas, el autor ha publicado 52 capítulos de 56 concebidos (una notificación de disponibilidad de 52 capítulos llegó a mi correo el 4 de julio). Todos los capítulos disponibles actualmente se pueden descargar aquí o encontrar en Internet usted mismo.
Antes de publicar mi traducción, busqué otras traducciones, encontré esta, también publicada en Habré. Es cierto que solo se han traducido los primeros 7 capítulos. No puedo juzgar qué traducción es mejor. Ni yo ni IliaSafonov (como siento por leer) somos traductores profesionales. Me gustan más algunas partes, Ilya algunas. En el prefacio de Ilya, puedes leer detalles interesantes sobre el libro, que omito.
Publico mi traducción sin revisión, "desde el horno", planeo volver a algunos lugares y corregirla (esto se aplica especialmente a la confusión con los conjuntos de datos train / dev / test). Le agradecería que me enviaran comentarios sobre el estilo, errores, etc., así como informativos sobre el texto del autor.
Todas las imágenes son originales (de Andrew Eun), sin ellas el libro sería más aburrido.
Entonces, al libro:
Capítulo 1. ¿Por qué necesitamos una estrategia de aprendizaje automático?
El aprendizaje automático es el núcleo de innumerables aplicaciones importantes, incluidas la búsqueda web, el correo electrónico antispam, el reconocimiento de voz, las recomendaciones de productos y otros. Supongo que usted o su equipo están trabajando en aplicaciones de aprendizaje automático. Y que desea acelerar su progreso en este trabajo. Este libro te ayudará a hacer esto.
Ejemplo: crear un inicio de reconocimiento de imagen felina
Supongamos que está trabajando en una startup que procesa un flujo interminable de fotos de gatos para los amantes de los gatos.

Utiliza una red neuronal para construir un sistema de visión por computadora para reconocer a los gatos en las fotografías.
Pero desafortunadamente, la calidad de su algoritmo de aprendizaje aún no es lo suficientemente buena y la tremenda presión sobre usted es mejorar su detector de gatos.
Que hacer
Su equipo tiene muchas ideas, como:
- Obtenga más datos: recopile más fotos de gatos.
- Recopile un conjunto de datos más heterogéneo. Por ejemplo, fotografías de gatos en posiciones inusuales; fotos de gatos con colores inusuales; imágenes con varias configuraciones de cámara; ...
- Entrene el algoritmo por más tiempo aumentando el número de iteraciones del descenso del gradiente
- Intente aumentar la red neuronal, con muchas capas / neuronas / parámetros ocultos.
- Intenta reducir la red neuronal.
- Intente agregar regularización (como la regularización L2)
- Cambiar la arquitectura de la red neuronal (función de activación, número de neuronas ocultas, etc.)
- ...
Si elige con éxito entre estas posibles direcciones, creará una plataforma líder de procesamiento de imágenes de gatos y llevará a su empresa al éxito. Si su elección no tiene éxito, puede perder meses de trabajo en vano.
Que hacer
Este libro te dirá cómo.
La mayoría de las tareas de aprendizaje automático tienen pistas que pueden decirle qué sería útil intentar y qué es inútil intentar. Si aprende a leer estos consejos, puede ahorrar meses y años de desarrollo.
2. Cómo usar este libro para ayudar a su equipo a trabajar
Una vez que termine de leer este libro, tendrá una comprensión profunda de cómo elegir la dirección técnica para el proyecto de aprendizaje automático.
Pero puede no estar claro para sus compañeros de equipo por qué recomienda una determinada dirección. Quizás desee que su equipo utilice una métrica de un parámetro para evaluar la calidad del algoritmo, pero sus colegas no están seguros de que sea una buena idea. ¿Cómo los convences?
Es por eso que hice los capítulos cortos: para que pueda imprimirlos y dar a sus colegas una o dos páginas que contengan material con el que necesita familiarizar al equipo.
Pequeños cambios en la priorización pueden tener un gran efecto en la productividad de su equipo. ¡Ayudando con estos pequeños cambios, espero que puedas convertirte en el superhéroe de tu equipo!

3. Antecedentes y observaciones
Si ha completado un curso de aprendizaje automático, como mi curso de aprendizaje automático MOOC en Coursera, o si tiene experiencia en la enseñanza de algoritmos con un maestro, no será difícil que comprenda este texto.
Supongo que está familiarizado con la “capacitación de maestros”: aprender una función que vincula xay utilizando ejemplos de capacitación etiquetados (x, y). Los algoritmos de aprendizaje con un maestro incluyen regresión lineal, regresión logística, redes neuronales y otros. Hoy en día, existen muchas formas y enfoques para el aprendizaje automático, pero la mayoría de los enfoques de importancia práctica se derivan de los algoritmos de la clase "aprender con un maestro".
A menudo me referiré a las redes neuronales (al "aprendizaje profundo"). Solo necesita ideas básicas sobre cuáles son para comprender este texto.
Si no está familiarizado con los conceptos mencionados aquí, mire el video de las primeras tres semanas del curso de Machine Learning en Coursera http://ml-class.org/
4. La barra de progreso en el aprendizaje automático
Muchas ideas para el aprendizaje profundo (redes neuronales) han existido durante décadas. ¿Por qué estas ideas se disparan hoy?
Los dos principales impulsores del progreso reciente son:
- Disponibilidad de datos Hoy en día, las personas pasan mucho tiempo con dispositivos informáticos (computadoras portátiles, dispositivos móviles). Su actividad digital genera enormes cantidades de datos que podemos alimentar a nuestros algoritmos de aprendizaje.
- Poder informático Hace solo unos años se hizo posible entrenar redes neuronales de un tamaño suficientemente grande, lo que le permite obtener los beneficios de utilizar los enormes conjuntos de datos que teníamos.
Aclararé, incluso si acumula muchos datos, generalmente la curva de crecimiento de la precisión de los algoritmos de aprendizaje antiguos, como la regresión logística, es "plana". Esto implica que la curva de aprendizaje se "aplana" y que la calidad de la predicción del algoritmo deja de crecer a pesar de que le proporciona más datos para el entrenamiento.
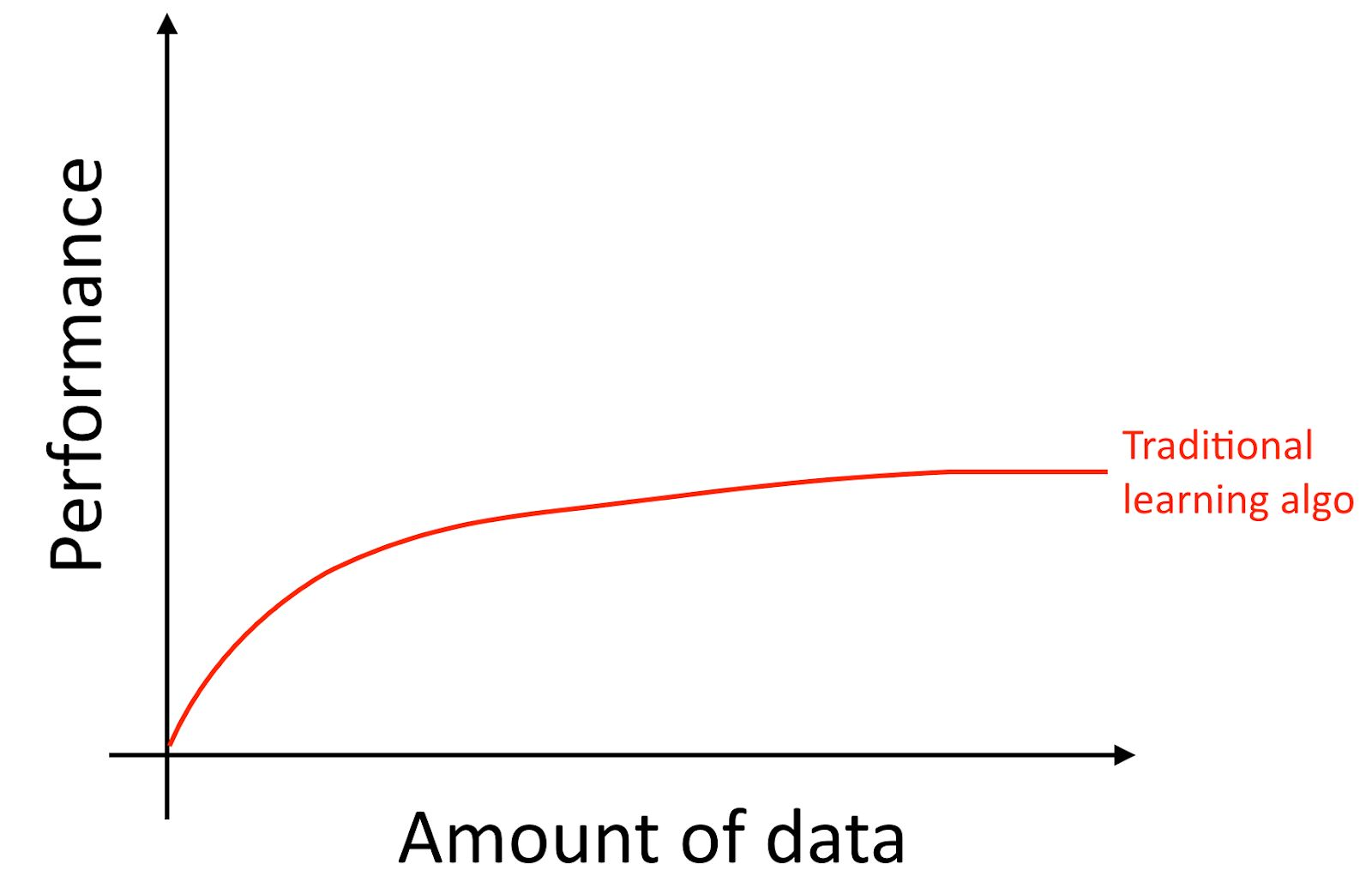
Parece que los viejos algoritmos no saben qué hacer con todos estos datos que ahora están a nuestra disposición.
Si entrena una pequeña red neuronal (NN) para la misma tarea de "aprender con un maestro", puede obtener un resultado ligeramente mejor que los "algoritmos antiguos".
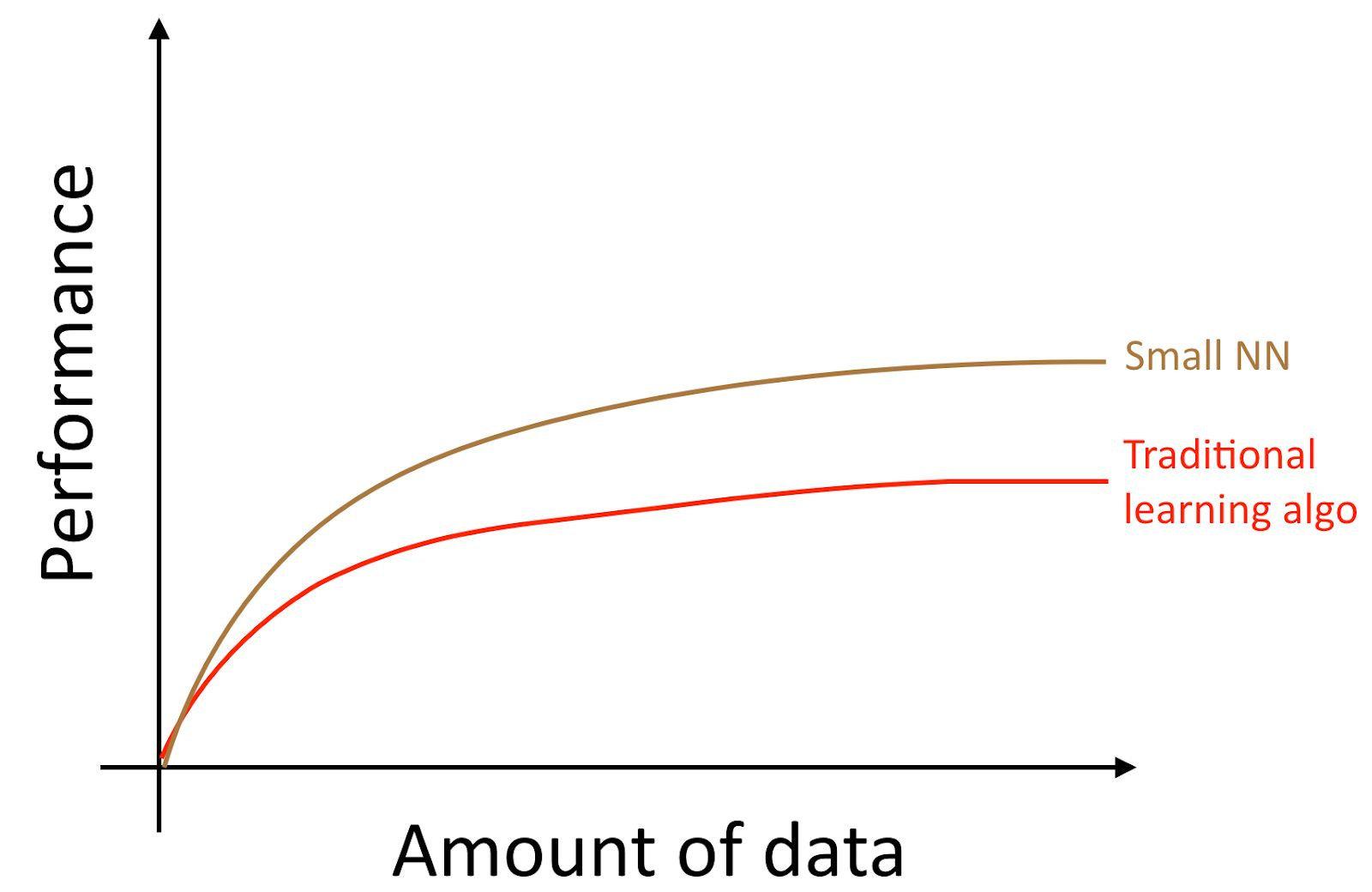
Aquí, por "NN pequeño" nos referimos a una red neuronal con un pequeño número de neuronas / capas / parámetros ocultos. Finalmente, si comienzas a entrenar redes neuronales cada vez más grandes, puedes obtener una calidad cada vez mayor.
Nota del autor : este diagrama muestra que las redes neuronales funcionan mejor en el modo de conjunto de datos pequeños. Este efecto es menos estable que el efecto de las redes neuronales que funcionan bien en el modo de gran conjunto de datos. En el modo de datos pequeños, dependiendo de cómo se procesaron las características (dependiendo de la calidad de la ingeniería de las características), los algoritmos tradicionales pueden funcionar mejor y peor que las redes neuronales. Por ejemplo, si tiene 20 ejemplos de entrenamiento, realmente no importa si usa regresión logística o una red neuronal; la preparación de características tiene un efecto mayor que la elección del algoritmo. Sin embargo, si tiene 1 millón de ejemplos de entrenamiento, preferiría una red neuronal.

Por lo tanto, obtienes la mejor calidad del algoritmo cuando (i) entrenas una red neuronal muy grande, en cuyo caso estás en la curva verde en la imagen de arriba; (ii) tiene una gran cantidad de datos a su disposición.
Muchos otros detalles, como la arquitectura de red neuronal también son importantes, y se han creado muchas soluciones innovadoras en esta área. Pero la forma más confiable de mejorar la calidad del algoritmo hoy en día es (i) aumentar el tamaño de la red neuronal entrenada (ii) obtener más datos para el entrenamiento.
El proceso de cumplimiento conjunto de las condiciones (i) y (ii) en la práctica es sorprendentemente complejo. Este libro discutirá en detalle sus detalles. Comenzamos con estrategias generales que son igualmente útiles para los algoritmos tradicionales y las redes neuronales, y luego estudiamos las estrategias más modernas utilizadas en el diseño y desarrollo de sistemas de aprendizaje profundo.
5. Crear muestras para algoritmos de entrenamiento y prueba
Volvamos a nuestro ejemplo de foto de gato anterior: lanzó una aplicación móvil y los usuarios cargan una gran cantidad de fotos diferentes a su aplicación. Desea buscar automáticamente fotos de gatos.
Su equipo recibe un amplio conjunto de capacitación descargando fotos de gatos (ejemplos positivos) y fotos en las que no hay gatos (ejemplos negativos) de varios sitios web. Cortaron el conjunto de datos dividido en entrenamiento y prueba en una proporción del 70% al 30%. Utilizando estos datos, crearon un algoritmo que encuentra gatos que funcionan bien tanto en datos de entrenamiento como de prueba.
Sin embargo, cuando introdujo este clasificador en una aplicación móvil, descubrió que su calidad es muy pobre.

Que paso
De repente, descubre que las fotos que los usuarios cargan en su aplicación móvil tienen un aspecto completamente diferente a las fotos de los sitios web que componen su conjunto de datos de entrenamiento: los usuarios cargan fotos tomadas con cámaras de teléfonos móviles, que generalmente tienen menor resolución, menos nítida y con poca luz. Después de entrenar en sus muestras de entrenamiento / prueba recolectadas de fotos de sitios web, su algoritmo no pudo generalizar cualitativamente los resultados a la distribución real de datos relevantes para su aplicación (fotos tomadas con cámaras de teléfonos móviles).
Antes de la llegada de la era moderna del big data, la regla general del aprendizaje automático era dividir los datos en datos educativos y de prueba en una proporción del 70% al 30%. A pesar del hecho de que este enfoque aún funciona, será una mala idea usarlo en más y más aplicaciones donde la distribución de la muestra de entrenamiento (fotos de sitios web en el ejemplo discutido anteriormente) es diferente de la distribución de datos que se usarán en combate modo de su aplicación (fotos de la cámara de teléfonos móviles).
Las siguientes definiciones se usan comúnmente:
- Conjunto de entrenamiento: una muestra de datos que se usa para entrenar el algoritmo
- Muestreo de validación (conjunto Dev (desarrollo)): un muestreo de datos que se utiliza para seleccionar parámetros, seleccionar características y tomar otras decisiones con respecto a la capacitación del algoritmo. A veces también se conoce como un conjunto de validación cruzada de retención.
- Muestra de prueba : una muestra que se usa para evaluar la calidad del algoritmo, mientras que no se usa para enseñar el algoritmo o los parámetros utilizados en esta capacitación.
Comentario del traductor: Andrew Eun utiliza el concepto de conjunto de desarrollo o conjunto de desarrollo, en ruso y en la terminología rusa del aprendizaje automático, dicho término no aparece. "Design Sample" o "Design Sample" (traducción directa de palabras en inglés) suena engorroso. Por lo tanto, continuaré usando la frase "selección de validación" como traducción del conjunto de desarrollo.
Observación del traductor 2: DArtN sugirió traducir el conjunto de desarrolladores como "muestreo de depuración"; creo que es una muy buena idea, pero ya he usado el término "muestreo de validación" en un gran volumen de texto y ahora es laborioso reemplazarlo. Para ser justos, observo que el término "muestra de validación" tiene una ventaja: esta muestra se usa para evaluar la calidad del algoritmo (para evaluar la calidad del algoritmo entrenado en la muestra de entrenamiento), por lo tanto, en cierto sentido, es "prueba", el término "validación" en Incluye este aspecto. El adjetivo "depuración" se centra en los parámetros de ajuste. Pero, en general, este es un término muy bueno (especialmente desde el punto de vista del idioma ruso) y si se me ocurriera antes, lo usaría en lugar del término "muestra de validación".
Elija la validación y las muestras de prueba para que (a excepción de la selección (ajuste) de los parámetros) refleje los datos que espera recibir en el futuro y desea que su algoritmo funcione bien en ellos.
En otras palabras, su muestra de prueba no debe ser solo el 30% de los datos disponibles, especialmente si espera que los datos que lleguen en el futuro (fotos de teléfonos móviles) difieran en naturaleza de su conjunto de entrenamiento (fotos tomadas de la web sitios).
Si aún no ha lanzado su aplicación móvil, es posible que no tenga usuarios y, como resultado, es posible que no haya datos disponibles que reflejen los datos de combate que su algoritmo debería manejar. Pero puedes intentar aproximarlos. Por ejemplo, pídale a sus amigos que tomen fotos de gatos usando teléfonos móviles y se las envíen. Después de iniciar su aplicación, podrá actualizar su validación y muestras de prueba utilizando los datos actuales del usuario.
Si no puede obtener datos que se aproximen a los datos que subirán los usuarios, probablemente pueda intentar comenzar a usar fotos de sitios web. Pero debe tener en cuenta que esto conlleva el riesgo de que el sistema no funcione bien con los datos de combate (su capacidad de generalización será insuficiente para ellos).
El desarrollo de muestras de validación y prueba requiere un enfoque serio y una reflexión exhaustiva. No postule inicialmente que la distribución de su conjunto de entrenamiento debe coincidir exactamente con la distribución del conjunto de prueba. Intente elegir los casos de prueba de tal manera que reflejen la distribución de datos en los que desea que su algoritmo funcione bien al final, y no los datos que estaban a su disposición al crear la muestra de capacitación.
6. Las muestras de validación y prueba deben tener la misma distribución

Suponga que los datos de su aplicación de fotografía de gato están segmentados en cuatro regiones correspondientes a sus mercados más grandes: (i) EE. UU., (Ii) China, (iii) India, (iv) Otros.
Supongamos que formamos una muestra de validación a partir de datos obtenidos de los mercados estadounidense e indio, y una prueba basada en datos chinos y de otro tipo. En otras palabras, podemos asignar aleatoriamente dos segmentos para obtener una muestra de validación y otros dos para obtener una muestra de prueba. Derecho?
Una vez que haya determinado las muestras de validación y prueba, su equipo se centrará en mejorar el funcionamiento del algoritmo en la muestra de validación. Por lo tanto, la muestra de validación debe reflejar las tareas que son más importantes para resolver: el algoritmo debe funcionar bien en los cuatro segmentos geográficos, y no solo en dos.
El segundo problema que surge de las diferentes distribuciones de las muestras de validación y prueba es que es probable que su equipo desarrolle algo que funcione bien en la muestra de validación solo para descubrir que produce una calidad deficiente en la muestra de prueba. He visto muchas decepciones y esfuerzos desperdiciados debido a esto. Evita que esto te suceda.
Por ejemplo, suponga que su equipo ha desarrollado un sistema que funciona bien en una muestra validada, pero no funciona en una prueba. Si sus muestras de validación y prueba se obtienen de la misma distribución, usted [obtiene un diagnóstico muy claro de eso] puede diagnosticar fácilmente lo que salió mal: su algoritmo se volvió a entrenar en la muestra de validación. .
, .
- , . , .
- , , . . .
. , — . , , , .
, , , ( ). , , , . — , . , , , , . .
7. ?
, . , 90.0% 90.1%, , , 100 , 0.1%.
: . ( ), .
— , , -, , , 0.01% , . , 10000, , .
? . 30% . , , 100 10000 . , , , , , . / , , .
8.
: ( ), , , . , 97% , 90%, .
(precision) (recall), . . . :
, .
: (precision) () , , . (recall) () , , . , .
, , , , . . , (accuracy) , .
, , . , . F1 , , .
: F1 , . https://en.wikipedia.org/wiki/F1_score , « » , 2/((1/Precision)+(1/Recall)).
, . .
, , : (i) , (ii) , (iii) (iv) . . , . .
9.
.
, . :
, , [] — 0.5*[] , .
: -, , «». , 100 . , . (satisficing) — , , 100 . .
N , ( - , ), , , N-1 . . . , . (N-) , . , , , .
, , « », ( , ). , Amazon Echo «Alexa»; Apple Siri «Hey Siri»; Android «Okay, Google»; Baidu «Hello Baidu». false-positive — , , false-negative — . false-negative ( ) false positive 24 ( ).
.
10
, . - . , :
- ,
- ( )
- , . ( !) , .
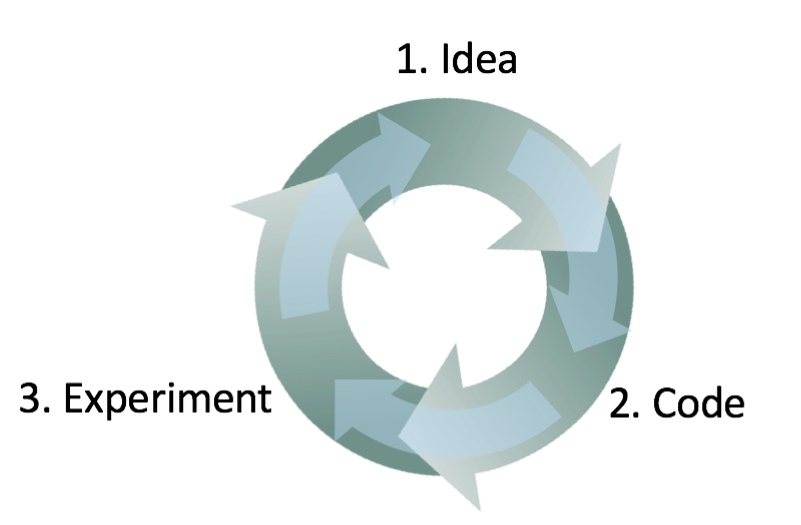
. , . : , , .
, , . , - , , . ! , 95.0% 95.1%, 0.1% () . 0.1%- . , , ( ) , , .
11 (dev/test sets)
, , .
, . - , . , . , . , .
Si luego decide que sus selecciones iniciales de desarrollo / prueba o la métrica original no se seleccionaron correctamente, haga todo el esfuerzo para cambiarlas rápidamente. Por ejemplo, si su muestra de desarrollo + métrica clasifica al clasificador A más alto que el clasificador B, y usted y su equipo piensan que el clasificador B es objetivamente mejor para su producto, entonces esto puede ser una señal de que necesita cambiar el desarrollo / prueba conjuntos de datos o en cambio de métricas para la evaluación de calidad.
Hay tres posibles razones principales por las cuales una muestra de validación o una métrica de evaluación de calidad clasifica incorrectamente al Clasificador A por encima del Clasificador B:
1. La distribución real a mejorar difiere de las muestras de desarrollo / prueba
Imagine que sus conjuntos de datos de desarrollo / prueba originales contienen principalmente imágenes de gatos adultos. Comienza a distribuir su aplicación de gato y descubre que los usuarios están cargando significativamente más imágenes de gatitos de lo que esperaba. Por lo tanto, la distribución de desarrollo / prueba no es representativa; no refleja la distribución real de los objetos cuya calidad de reconocimiento necesita mejorar. En este caso, actualice sus selecciones de desarrollo / prueba para que sean más representativas.

2. Se vuelve a entrenar en una selección de validación (conjunto de desarrollo)
El proceso de evolución múltiple de ideas, en un conjunto de validación (conjunto de desarrollo) hace que su algoritmo se vuelva a entrenar gradualmente. Cuando haya completado el desarrollo, evalúa la calidad de su sistema en una muestra de prueba. Si encuentra que la calidad de su algoritmo en el conjunto de validación (conjunto de desarrollo) es mucho mejor que en el conjunto de prueba (conjunto de prueba), esto indica que usted volvió a entrenar en la muestra de validación. En este caso, necesita obtener una nueva muestra de validación.
Si necesita realizar un seguimiento del progreso de su equipo, también puede evaluar regularmente la calidad de su sistema, por ejemplo, semanal o mensualmente, utilizando la evaluación de la calidad del algoritmo en una muestra de prueba. Sin embargo, no use el conjunto de pruebas para tomar decisiones con respecto al algoritmo, incluida la posibilidad de volver a la versión anterior del sistema que se probó la semana pasada. Si comienza a usar la muestra de prueba para cambiar el algoritmo, comenzará a capacitarse nuevamente en la muestra de prueba y ya no podrá contar con ella para obtener una evaluación objetiva de la calidad de su algoritmo (que necesita si publica artículos de investigación, o tal vez use estas métricas). para tomar decisiones comerciales importantes).
3. La métrica evalúa algo diferente de lo que debe optimizarse para los propósitos del proyecto.
Suponga que para su aplicación felina, su métrica es la precisión de la clasificación. Esta métrica actualmente clasifica al clasificador A como un clasificador superior B. Pero suponga que probó ambos algoritmos y descubrió que las imágenes pornográficas aleatorias se deslizan a través del clasificador A. Aunque el clasificador A es más preciso, la mala impresión que dejan las imágenes pornográficas aleatorias hace que su calidad sea insatisfactoria. ¿Qué hiciste mal?
En este caso, la métrica que evalúa la calidad de los algoritmos no puede determinar que el algoritmo B sea realmente mejor que el algoritmo A para su producto. Por lo tanto, ya no puede confiar en la métrica para seleccionar el mejor algoritmo. Ha llegado el momento de cambiar la métrica de evaluación de calidad. Por ejemplo, puede cambiar la métrica introduciendo una penalización severa en el algoritmo por omitir una imagen pornográfica. Recomiendo elegir una nueva métrica y usar esta nueva métrica para establecer explícitamente un nuevo objetivo para el equipo, en lugar de seguir trabajando durante demasiado tiempo con una métrica no confiable, volviendo cada vez a la selección manual entre clasificadores.
Estos son enfoques bastante generales para cambiar muestras de desarrollo / prueba o cambiar la métrica de evaluación de calidad mientras se trabaja en un proyecto. Tener las muestras y métricas de desarrollo / prueba originales le permite comenzar rápidamente a iterar sobre su proyecto. Si incluso encuentra que las selecciones o métricas de desarrollo / prueba seleccionadas ya no orientan a su equipo en la dirección correcta, ¡eso realmente no importa! Simplemente cámbielos y asegúrese de que su equipo conozca una nueva dirección.
12 Recomendaciones: Preparamos muestras de validación (desarrollo) y prueba
- Seleccione dev y pruebe muestras de una distribución que refleje los datos que espera recibir en el futuro y en los que desea que su algoritmo funcione bien. Estas muestras pueden no coincidir con la distribución de su conjunto de datos de entrenamiento.
- Seleccione conjuntos de pruebas de desarrollo de la misma distribución, si es posible
- Elija una métrica de un parámetro para evaluar la calidad de los algoritmos para la optimización de su equipo. Si tiene varios objetivos que necesita lograr al mismo tiempo, considere combinarlos en una sola fórmula (como la métrica del error multiparámetro promediado) o defina métricas restrictivas y de optimización.
- El aprendizaje automático es un proceso altamente iterativo: puede probar muchas ideas antes de encontrar una que lo satisfaga.
- La existencia de muestras de desarrollo / prueba y una métrica de evaluación de calidad de un parámetro lo ayudará a evaluar rápidamente los algoritmos y, por lo tanto, iterar más rápido.
- Cuando comience el desarrollo de una nueva aplicación, intente instalar rápidamente las muestras de desarrollo / prueba y la métrica de evaluación de calidad, por ejemplo, no pase más de una semana en esto. Para aplicaciones maduras, es normal si este proceso lleva mucho más tiempo.
- La vieja heurística de dividir las muestras de entrenamiento y prueba como 70% a 30% no es aplicable a problemas en los que hay una gran cantidad de datos; Las muestras de desarrollo / prueba pueden ser significativamente menos del 30% de todos los datos disponibles.
- Si su métrica y muestra de desarrollo ya no le indica a su equipo la dirección correcta, cámbielos rápidamente: (i) si su algoritmo se vuelve a entrenar en el conjunto de validación (conjunto de desarrollo), agregue más datos (en su conjunto de desarrollo). (ii) Si la distribución de datos reales, la calidad del algoritmo en el que necesita mejorar, difiere de la distribución de datos en validación y (o) muestras de prueba (dev / test sets), cree nuevas muestras para pruebas y desarrollo (dev / test sets), utilizando otros datos. (iii) Si su métrica de evaluación de calidad ya no mide lo que es más importante para su proyecto, cambie esa métrica.
13 Cree su primer sistema rápidamente y luego actualícelo iterativamente
Desea compilar para construir un nuevo sistema antispam para correo electrónico. Tu equipo tiene varias ideas:
- Recopile una gran muestra de capacitación que consiste en correos electrónicos no deseados. Por ejemplo, configure un señuelo: envíe intencionalmente direcciones de correo electrónico falsas a spammers conocidos, para que pueda recopilar automáticamente correos electrónicos no deseados que enviarán a estas direcciones
- Desarrollar signos para comprender el contenido textual de la carta.
- Para desarrollar letreros para comprender el caparazón de la letra / título, letreros que muestran a través de qué servidores de Internet pasó la letra
- y así sucesivamente
Aunque trabajé duro en aplicaciones antispam, todavía me será difícil elegir una de estas áreas. Será aún más difícil si no eres un experto en el campo para el que se está desarrollando la aplicación.
Por lo tanto, no intente construir un sistema ideal desde el principio. En cambio, cree y entrene un sistema simple lo más rápido posible, posiblemente en unos pocos días.
Nota del autor: Este consejo está destinado a lectores que desean desarrollar aplicaciones de IA, en lugar de aquellos cuyo objetivo es publicar artículos académicos. Más tarde, volveré al tema de la investigación.
Incluso si un sistema simple está lejos de ser un sistema "ideal" que puede construir, será útil estudiar cómo funciona este sistema simple: encontrará rápidamente consejos que le muestran las áreas más prometedoras en las que debe invertir su tiempo. Los próximos capítulos le mostrarán cómo leer estos consejos.
14 Análisis de errores: mire ejemplos de conjunto de desarrollo para ideas.

Cuando jugaste con tu aplicación de gato, notaste varios ejemplos en los que la aplicación confundía perros con gatos. ¡Algunos perros parecen gatos!
Uno de los miembros del equipo sugirió introducir un software de terceros que mejoraría el rendimiento del sistema en fotografías de perros. La implementación de los cambios llevará un mes, el miembro del equipo que los propuso está entusiasmado. ¿Qué decisión debes tomar?
Antes de invertir un mes en resolver este problema, le recomiendo que primero evalúe cómo su solución mejorará la calidad del sistema. Luego puede decidir de manera más racional si vale la pena mejorar un mes de desarrollo o si será mejor usar este tiempo para resolver otros problemas.
Específicamente, qué se puede hacer en este caso:
- Reúna una muestra de 100 ejemplos del conjunto de desarrolladores que su sistema clasificó incorrectamente. Es decir, ejemplos en los que su sistema cometió un error.
- Estudie estos ejemplos y calcule qué parte de la imagen del perro es.
El proceso de estudiar ejemplos en los que el clasificador cometió un error se denomina "análisis de errores". En este ejemplo, supongamos que encuentra que solo el 5% de las imágenes mal clasificadas son perros, entonces no importa cuánto mejore el rendimiento de su algoritmo en las imágenes de perros, no podrá obtener una mejor calidad que el 5% de su tasa de error . En otras palabras, el 5% es el "techo" (implica el mayor número posible) en la medida en que la mejora esperada pueda ayudar. Por lo tanto, si su sistema general tiene actualmente una precisión del 90% (error del 10%), esta mejora es posible, en el mejor de los casos mejorará el resultado con una precisión del 90.5% (o la tasa de error será del 9.5%, que es 5% menos que el original 10% de errores)
Por el contrario, si encuentra que el 50% de los errores son perros, puede estar más seguro de que el proyecto propuesto para mejorar el sistema tendrá un gran efecto. Podría aumentar la precisión del 90% al 95% (reducción del error relativo del 50% del 10% al 5%)
Este sencillo procedimiento de evaluación para el análisis de errores le permite evaluar rápidamente los posibles beneficios de implementar un software de clasificación de imágenes de perros de terceros. Proporciona una evaluación cuantitativa para decidir la conveniencia de invertir tiempo en su implementación.
El análisis de errores a menudo puede ayudar a comprender cuán prometedoras son las diversas direcciones para el trabajo futuro. He observado que muchos ingenieros son reacios a analizar errores. A menudo parece más emocionante simplemente precipitarse en una idea que descubrir si la idea vale el tiempo que llevará. Este es un error común: esto puede llevar al hecho de que su equipo pasará un mes solo para entender después del hecho de que el resultado es una mejora insignificante.
Verificación manual de 100 ejemplos de la muestra, no es larga. Incluso si pasa un minuto en la imagen, todo el cheque tomará menos de 2 horas. Estas dos horas pueden ahorrarle un mes de esfuerzo perdido.
continuación