En el caso de la organización de microservicios de la aplicación, el trabajo sustancial se basa en los mecanismos de la conexión de integración de microservicios. Además, esta integración debe ser tolerante a fallas, con un alto grado de disponibilidad.
En nuestras soluciones, utilizamos la integración con Kafka, gRPC y RabbitMQ.
En este artículo, compartiremos nuestra experiencia de agrupar RabbitMQ, cuyos nodos están alojados en Kubernetes.

Antes de RabbitMQ versión 3.7, agruparlo en K8S no era una tarea muy trivial, con muchos hacks y soluciones no muy hermosas. En la versión 3.6, se usó un plugin de autocluster de la comunidad RabbitMQ. Y en 3.7 apareció Kubernetes Peer Discovery Backend. Está integrado por el complemento en la entrega básica de RabbitMQ y no requiere montaje e instalación por separado.
Describiremos la configuración final como un todo, mientras comentamos lo que está sucediendo.
En teoría
El complemento tiene un
repositorio en el github , en el que hay
un ejemplo de uso básico .
Este ejemplo no está destinado a Producción, lo cual está claramente indicado en su descripción, y además, algunos de los ajustes en él están configurados en contra de la lógica de uso en el producto. Además, en el ejemplo, la persistencia del almacenamiento no se menciona en absoluto, por lo que en cualquier situación de emergencia nuestro clúster se convertirá en un zilch.
En la practica
Ahora le diremos a qué se enfrentó y cómo instalar y configurar RabbitMQ.
Describamos las configuraciones de todas las partes de RabbitMQ como un servicio en K8s. Aclararemos de inmediato que instalamos RabbitMQ en K8s como StatefulSet. En cada nodo del clúster K8s, una instancia de RabbitMQ siempre funcionará (un nodo en la configuración clásica del clúster). También instalaremos el panel de control RabbitMQ en K8 y daremos acceso a este panel fuera del clúster.
Derechos y roles:
rabbitmq_rbac.yaml--- apiVersion: v1 kind: ServiceAccount metadata: name: rabbitmq --- kind: Role apiVersion: rbac.authorization.k8s.io/v1beta1 metadata: name: endpoint-reader rules: - apiGroups: [""] resources: ["endpoints"] verbs: ["get"] --- kind: RoleBinding apiVersion: rbac.authorization.k8s.io/v1beta1 metadata: name: endpoint-reader subjects: - kind: ServiceAccount name: rabbitmq roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: endpoint-reader
Los derechos de acceso para RabbitMQ se toman completamente del ejemplo, no se requieren cambios en ellos. Creamos una cuenta de servicio para nuestro clúster y le damos permisos de lectura a los puntos finales K8.
Almacenamiento persistente:
rabbitmq_pv.yaml kind: PersistentVolume apiVersion: v1 metadata: name: rabbitmq-data-sigma labels: type: local annotations: volume.alpha.kubernetes.io/storage-class: rabbitmq-data-sigma spec: storageClassName: rabbitmq-data-sigma capacity: storage: 10Gi accessModes: - ReadWriteMany persistentVolumeReclaimPolicy: Recycle hostPath: path: "/opt/rabbitmq-data-sigma"
Aquí tomamos el caso más simple como el almacenamiento persistente: hostPath (una carpeta regular en cada nodo K8s), pero puede usar cualquiera de los muchos tipos de volúmenes persistentes admitidos por K8s.
rabbitmq_pvc.yaml kind: PersistentVolumeClaim apiVersion: v1 metadata: name: rabbitmq-data spec: storageClassName: rabbitmq-data-sigma accessModes: - ReadWriteMany resources: requests: storage: 10Gi
Crear reclamo de volumen en el volumen creado en el paso anterior. Este reclamo se utilizará en StatefulSet como un almacén de datos persistente.
Servicios:
rabbitmq_service.yaml kind: Service apiVersion: v1 metadata: name: rabbitmq-internal labels: app: rabbitmq spec: clusterIP: None ports: - name: http protocol: TCP port: 15672 - name: amqp protocol: TCP port: 5672 selector: app: rabbitmq
Creamos un servicio interno sin cabeza a través del cual funcionará el complemento Peer Discovery.
rabbitmq_service_ext.yaml kind: Service apiVersion: v1 metadata: name: rabbitmq labels: app: rabbitmq type: LoadBalancer spec: type: NodePort ports: - name: http protocol: TCP port: 15672 targetPort: 15672 nodePort: 31673 - name: amqp protocol: TCP port: 5672 targetPort: 5672 nodePort: 30673 selector: app: rabbitmq
Para que las aplicaciones en K8 funcionen con nuestro clúster, creamos un servicio equilibrador.
Dado que necesitamos acceso al clúster RabbitMQ fuera de K8, pasamos por NodePort. RabbitMQ estará disponible al acceder a cualquier nodo del clúster K8s en los puertos 31673 y 30673. En el trabajo real, no hay una gran necesidad de esto. Cuestión de usabilidad del panel de administración de RabbitMQ.
Al crear un servicio con el tipo NodePort en K8, también se crea implícitamente un servicio con el tipo ClusterIP para servirlo. Por lo tanto, las aplicaciones en K8 que necesitan trabajar con nuestro RabbitMQ podrán acceder al clúster en
amqp: // rabbitmq: 5672Configuración:
rabbitmq_configmap.yaml apiVersion: v1 kind: ConfigMap metadata: name: rabbitmq-config data: enabled_plugins: | [rabbitmq_management,rabbitmq_peer_discovery_k8s]. rabbitmq.conf: | cluster_formation.peer_discovery_backend = rabbit_peer_discovery_k8s cluster_formation.k8s.host = kubernetes.default.svc.cluster.local cluster_formation.k8s.port = 443 ### cluster_formation.k8s.address_type = ip cluster_formation.k8s.address_type = hostname cluster_formation.node_cleanup.interval = 10 cluster_formation.node_cleanup.only_log_warning = true cluster_partition_handling = autoheal queue_master_locator=min-masters cluster_formation.randomized_startup_delay_range.min = 0 cluster_formation.randomized_startup_delay_range.max = 2 cluster_formation.k8s.service_name = rabbitmq-internal cluster_formation.k8s.hostname_suffix = .rabbitmq-internal.our-namespace.svc.cluster.local
Creamos archivos de configuración RabbitMQ. La magia principal.
enabled_plugins: | [rabbitmq_management,rabbitmq_peer_discovery_k8s].
Agregue los complementos necesarios a los permitidos para la descarga. Ahora podemos usar el Peer Discovery automático en el K8S.
cluster_formation.peer_discovery_backend = rabbit_peer_discovery_k8s
Exponemos el complemento necesario como back-end para el descubrimiento de pares.
cluster_formation.k8s.host = kubernetes.default.svc.cluster.local cluster_formation.k8s.port = 443
Especifique la dirección y el puerto a través del cual puede comunicarse con kubernetes apiserver. Aquí puede especificar la dirección IP directamente, pero será más hermoso hacerlo.
En el espacio de nombres predeterminado, generalmente se crea un servicio con el nombre kubernetes que conduce a k8-apiserver. En diferentes opciones de instalación de K8S, el espacio de nombres, el nombre del servicio y el puerto pueden ser diferentes. Si algo en una instalación particular es diferente, debe solucionarlo en consecuencia.
Por ejemplo, nos enfrentamos al hecho de que en algunos grupos el servicio está en el puerto 443 y en algunos en 6443. Será posible comprender que algo está mal en los registros de inicio de RabbitMQ, el tiempo de conexión a la dirección especificada aquí está claramente resaltado allí.
### cluster_formation.k8s.address_type = ip cluster_formation.k8s.address_type = hostname
De manera predeterminada, el ejemplo especifica el tipo de dirección del nodo del clúster RabbitMQ por dirección IP. Pero cuando reinicia el pod, obtiene una nueva IP cada vez. Sorpresa! El grupo está muriendo en agonía.
Cambie el direccionamiento a nombre de host. StatefulSet nos garantiza la invariabilidad del nombre de host dentro del ciclo de vida de todo el StatefulSet, lo que nos conviene por completo.
cluster_formation.node_cleanup.interval = 10 cluster_formation.node_cleanup.only_log_warning = true
Como cuando perdemos uno de los nodos, suponemos que se recuperará tarde o temprano, deshabilitamos la eliminación automática por un grupo de nodos inaccesibles. En este caso, tan pronto como el nodo regrese en línea, ingresará al clúster sin perder su estado anterior.
cluster_partition_handling = autoheal
Este parámetro determina las acciones del clúster en caso de pérdida de quórum. Aquí solo necesita leer la
documentación sobre este tema y comprender por sí mismo lo que está más cerca de un caso de uso específico.
queue_master_locator=min-masters
Determine la selección del asistente para nuevas colas. Con esta configuración, el asistente seleccionará el nodo con el menor número de colas, por lo que las colas se distribuirán de manera uniforme entre los nodos del clúster.
cluster_formation.k8s.service_name = rabbitmq-internal
Nombramos el servicio K8s sin cabeza (creado por nosotros anteriormente) a través del cual los nodos RabbitMQ se comunicarán entre sí.
cluster_formation.k8s.hostname_suffix = .rabbitmq-internal.our-namespace.svc.cluster.local
Una cosa importante para direccionar en un clúster es el nombre de host. El FQDN del hogar K8s se forma como un nombre corto (rabbitmq-0, rabbitmq-1) + sufijo (parte del dominio). Aquí indicamos este sufijo. En K8S, se ve así
. <Nombre del servicio>. <Nombre del espacio de nombres> .svc.cluster.localkube-dns resuelve los nombres de la forma rabbitmq-0.rabbitmq-internal.our-namespace.svc.cluster.local en la dirección IP de un pod específico sin ninguna configuración adicional, lo que hace posible toda la magia de la agrupación por nombre de host.
Configuración StatefulSet RabbitMQ:
rabbitmq_statefulset.yaml apiVersion: apps/v1beta1 kind: StatefulSet metadata: name: rabbitmq spec: serviceName: rabbitmq-internal replicas: 3 template: metadata: labels: app: rabbitmq annotations: scheduler.alpha.kubernetes.io/affinity: > { "podAntiAffinity": { "requiredDuringSchedulingIgnoredDuringExecution": [{ "labelSelector": { "matchExpressions": [{ "key": "app", "operator": "In", "values": ["rabbitmq"] }] }, "topologyKey": "kubernetes.io/hostname" }] } } spec: serviceAccountName: rabbitmq terminationGracePeriodSeconds: 10 containers: - name: rabbitmq-k8s image: rabbitmq:3.7 volumeMounts: - name: config-volume mountPath: /etc/rabbitmq - name: rabbitmq-data mountPath: /var/lib/rabbitmq/mnesia ports: - name: http protocol: TCP containerPort: 15672 - name: amqp protocol: TCP containerPort: 5672 livenessProbe: exec: command: ["rabbitmqctl", "status"] initialDelaySeconds: 60 periodSeconds: 10 timeoutSeconds: 10 readinessProbe: exec: command: ["rabbitmqctl", "status"] initialDelaySeconds: 10 periodSeconds: 10 timeoutSeconds: 10 imagePullPolicy: Always env: - name: MY_POD_IP valueFrom: fieldRef: fieldPath: status.podIP - name: HOSTNAME valueFrom: fieldRef: fieldPath: metadata.name - name: NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace - name: RABBITMQ_USE_LONGNAME value: "true" - name: RABBITMQ_NODENAME value: "rabbit@$(HOSTNAME).rabbitmq-internal.$(NAMESPACE).svc.cluster.local" - name: K8S_SERVICE_NAME value: "rabbitmq-internal" - name: RABBITMQ_ERLANG_COOKIE value: "mycookie" volumes: - name: config-volume configMap: name: rabbitmq-config items: - key: rabbitmq.conf path: rabbitmq.conf - key: enabled_plugins path: enabled_plugins - name: rabbitmq-data persistentVolumeClaim: claimName: rabbitmq-data
En realidad, StatefulSet sí mismo. Tomamos nota de puntos interesantes.
serviceName: rabbitmq-internal
Escribimos el nombre del servicio sin cabeza a través del cual los pods se comunican en StatefulSet.
replicas: 3
Establezca el número de réplicas en el clúster. En nuestro país, es igual al número de nodos de trabajo K8.
annotations: scheduler.alpha.kubernetes.io/affinity: > { "podAntiAffinity": { "requiredDuringSchedulingIgnoredDuringExecution": [{ "labelSelector": { "matchExpressions": [{ "key": "app", "operator": "In", "values": ["rabbitmq"] }] }, "topologyKey": "kubernetes.io/hostname" }] } }
Cuando uno de los nodos K8 cae, el conjunto con estado busca preservar el número de instancias en el conjunto, por lo tanto, crea varios hogares en el mismo nodo K8. Este comportamiento es completamente indeseable y, en principio, no tiene sentido. Por lo tanto, prescribimos una regla antiafinidad para los conjuntos de hogares de setful. Hacemos que la regla sea difícil (obligatorio) para que kube-Scheduler no pueda romperla cuando se planifican pods.
La esencia es simple: está prohibido que el planificador coloque (dentro del espacio de nombres) más de un pod con la
aplicación: etiqueta rabbitmq en cada nodo. Distinguimos los
nodos por el valor de la etiqueta
kubernetes.io/hostname . Ahora, si por alguna razón la cantidad de nodos K8S en funcionamiento es menor que la cantidad requerida de réplicas en StatefulSet, no se crearán nuevas réplicas hasta que aparezca un nodo libre nuevamente.
serviceAccountName: rabbitmq
Registramos ServiceAccount, bajo el cual funcionan nuestros pods.
image: rabbitmq:3.7
La imagen de RabbitMQ es completamente estándar y se toma del docker hub; no requiere ninguna reconstrucción ni revisión de archivos.
- name: rabbitmq-data mountPath: /var/lib/rabbitmq/mnesia
Los datos persistentes de RabbitMQ se almacenan en / var / lib / rabbitmq / mnesia. Aquí montamos nuestro Reclamo de volumen persistente en esta carpeta para que al reiniciar los hogares / nodos o incluso todo el StatefulSet, los datos (tanto el servicio, incluido el clúster ensamblado y los datos del usuario) estén sanos y salvos. Hay algunos ejemplos en los que toda la carpeta / var / lib / rabbitmq / se hace persistente. Llegamos a la conclusión de que esta no es la mejor idea, ya que al mismo tiempo toda la información establecida por las configuraciones de Rabbit comienza a ser recordada. Es decir, para cambiar algo en el archivo de configuración, debe limpiar el almacenamiento persistente, lo cual es muy inconveniente en la operación.
- name: HOSTNAME valueFrom: fieldRef: fieldPath: metadata.name - name: NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace - name: RABBITMQ_USE_LONGNAME value: "true" - name: RABBITMQ_NODENAME value: "rabbit@$(HOSTNAME).rabbitmq-internal.$(NAMESPACE).svc.cluster.local"
Con este conjunto de variables de entorno, primero le decimos a RabbitMQ que use el nombre FQDN como identificador para los miembros del clúster y, en segundo lugar, establecemos el formato de este nombre. El formato se describió anteriormente al analizar la configuración.
- name: K8S_SERVICE_NAME value: "rabbitmq-internal"
El nombre del servicio sin cabeza para la comunicación entre los miembros del clúster.
- name: RABBITMQ_ERLANG_COOKIE value: "mycookie"
El contenido de la cookie Erlang debe ser el mismo en todos los nodos del clúster, debe registrar su propio valor. Un nodo con una cookie diferente no puede ingresar al clúster.
volumes: - name: rabbitmq-data persistentVolumeClaim: claimName: rabbitmq-data
Defina el volumen asignado a partir del Reclamo de volumen persistente creado anteriormente.
Aquí es donde hemos terminado con la configuración en los K8. El resultado es un clúster RabbitMQ, que distribuye uniformemente las colas entre los nodos y es resistente a problemas en el entorno de tiempo de ejecución.
Si uno de los nodos del clúster no está disponible, las colas contenidas en él dejarán de ser accesibles, todo lo demás seguirá funcionando. Tan pronto como el nodo regrese a la operación, volverá al clúster, y las colas para las cuales era un Maestro volverán a estar operativas, preservando todos los datos contenidos en ellas (si el almacenamiento persistente no se ha roto, por supuesto). Todos estos procesos son completamente automáticos y no requieren intervención.
Bono: personalizar HA
Uno de los proyectos fue un matiz. Los requisitos sonaron como un reflejo completo de todos los datos contenidos en el clúster. Esto es necesario para que en una situación en la que al menos un nodo del clúster esté operativo, todo continúe funcionando desde el punto de vista de la aplicación. Este momento no tiene nada que ver con los K8, lo describimos simplemente como un mini tutorial.
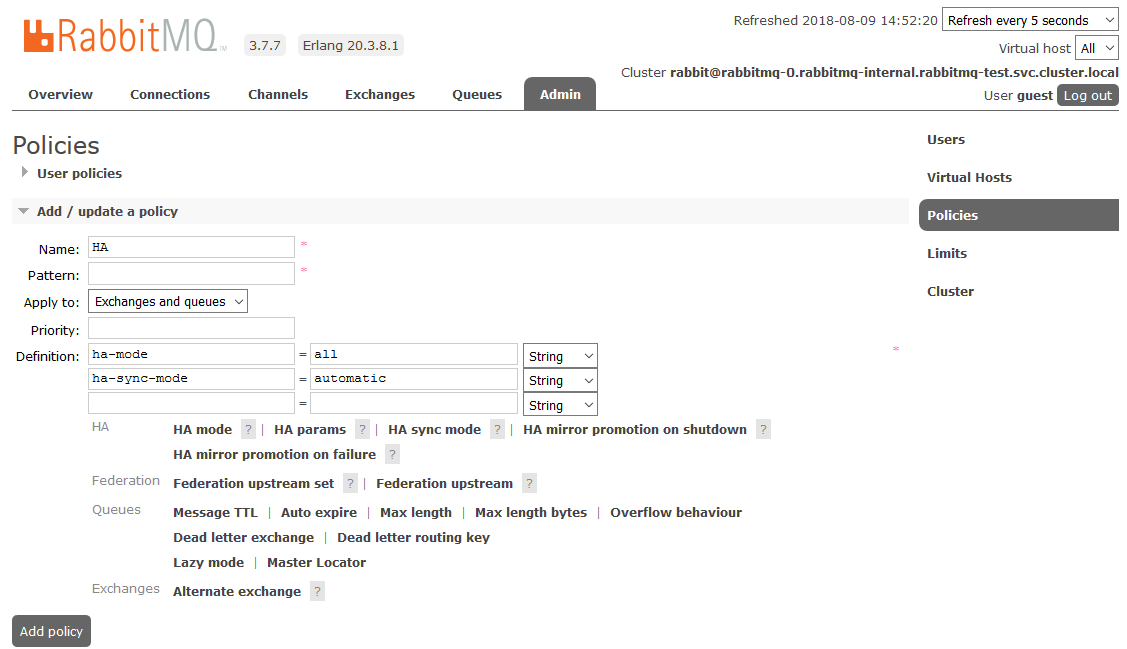
Para habilitar la HA completa, debe crear una Política en el panel de RabbitMQ en la pestaña
Admin -> Políticas . El nombre es arbitrario, el Patrón está vacío (todas las colas), en las Definiciones agregue dos parámetros:
ha-mode: all ,
ha-sync-mode: automatic .
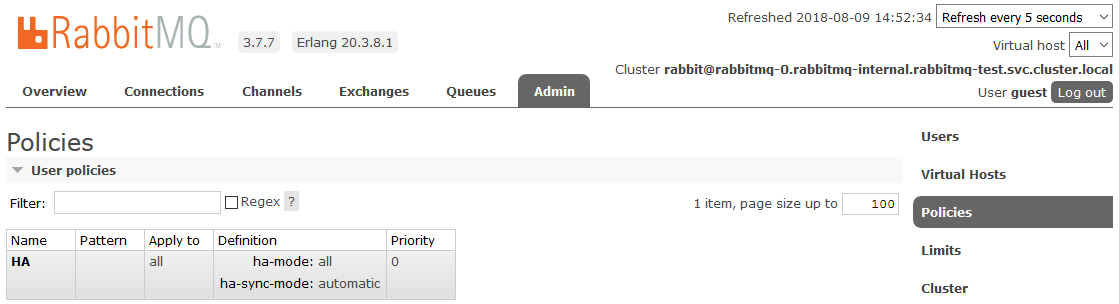
Después de eso, todas las colas creadas en el clúster estarán en modo de alta disponibilidad: si el nodo maestro no está disponible, uno de los esclavos será seleccionado automáticamente por el nuevo asistente. Y los datos que entran en la cola se reflejarán en todos los nodos del clúster. Que, de hecho, se requería para recibir.
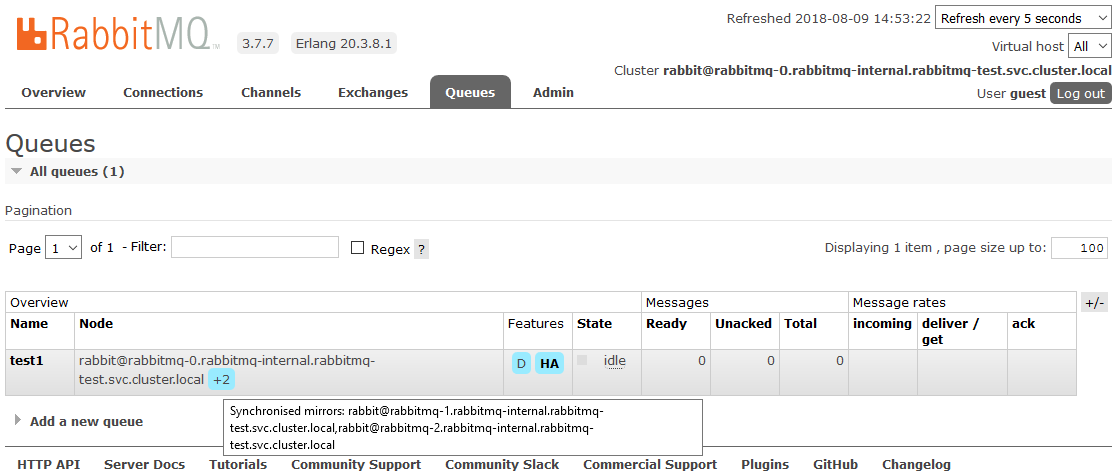
Lea más sobre HA en RabbitMQ
aquíLiteratura útil:
Buena suerte