Hola Habr! Les presento la traducción del artículo "
Detectando el sarcasmo con redes neuronales convolucionales profundas " por Elvis Saravia.
Una de las cuestiones clave en el procesamiento del lenguaje natural es la detección de sarcasmo. Detectar el sarcasmo es importante en otras áreas, como la computación emocional y el análisis del estado de ánimo, ya que esto puede reflejar la polaridad de la oración.
Este artículo muestra cómo detectar el sarcasmo y también proporciona un enlace a un
detector de sarcasmo de red neuronal .
El sarcasmo se puede ver como una expresión de burla punzante o ironía. Ejemplos de sarcasmo: "Trabajo 40 horas a la semana para mantenerme pobre" o "Si el paciente realmente quiere vivir, los médicos no tienen poder".
Para comprender y detectar el sarcasmo, es importante comprender los hechos asociados con el evento. Esto revela una contradicción entre la polaridad objetiva (generalmente negativa) y las características sarcásticas transmitidas por el autor (generalmente positiva).
Considere el ejemplo: "Me gusta el dolor de la separación".
Es difícil entender el significado si hay sarcasmo en esta declaración. En este ejemplo, "Me gusta el dolor" da conocimiento de los sentimientos expresados por el autor (en este caso, positivo), y "despedida" describe el sentimiento contradictorio (negativo).
Otros problemas que existen en la comprensión de las declaraciones sarcásticas son una referencia a varios eventos y la necesidad de extraer una gran cantidad de hechos, sentido común y razonamiento lógico.
Modelo
Un "cambio de humor" a menudo está presente en la comunicación donde hay sarcasmo; por lo tanto, se propone preparar primero un modelo de estado de ánimo (basado en CNN) para extraer los signos del estado de ánimo. El modelo selecciona entidades locales en las primeras capas, que luego se transforman en entidades globales en niveles superiores. Las expresiones sarcásticas son específicas del usuario: algunos usuarios usan más sarcasmo que otros.
En el modelo propuesto para la detección del sarcasmo se utilizan rasgos de personalidad, signos del estado de ánimo y signos basados en las emociones. Un conjunto de detectores es un marco diseñado para detectar el sarcasmo. Cada conjunto de atributos es estudiado por modelos pre-entrenados separados.
Marco CNN
Las CNN son eficaces para modelar la jerarquía de características locales para resaltar las características globales, lo cual es necesario para examinar el contexto. Los datos de entrada se presentan como vectores de palabras. Para el procesamiento inicial de los datos de entrada, se utiliza word2vec de Google. Los parámetros de los vectores se obtienen en la etapa de entrenamiento. La unión máxima se aplica a los mapas de funciones para crear funciones. Después de la capa completamente unida, hay una capa softmax para obtener la predicción final.
La arquitectura se muestra en la figura a continuación.
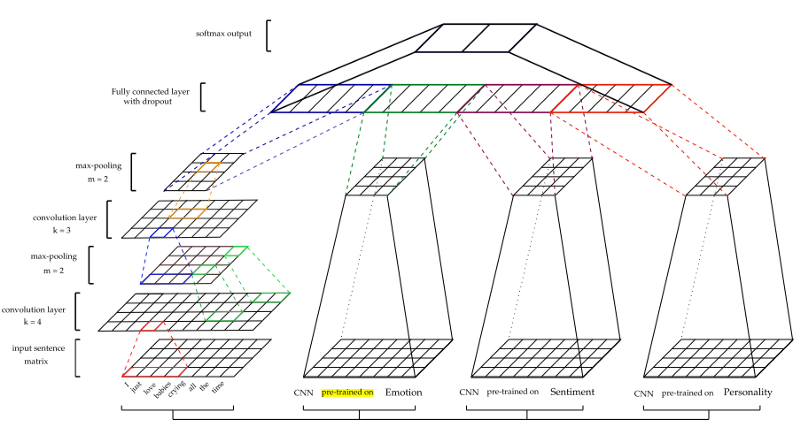
Para obtener otras características (estado de ánimo (S), emoción (E) y personalidad (P)), los modelos CNN se entrenan previamente y se utilizan para extraer rasgos de los conjuntos de datos de sarcasmo. Para entrenar cada modelo, se utilizaron diferentes conjuntos de datos de entrenamiento. (Para más detalles ver el documento)
Se prueban dos clasificadores: el clasificador CNN puro (CNN) y las características extraídas de CNN pasadas al clasificador SVM (CNN-SVM).
También se capacita un clasificador básico separado (B), que consiste solo en el modelo CNN sin la inclusión de otros modelos (por ejemplo, emociones y estados de ánimo).
Los experimentos
Datos. Se obtuvieron conjuntos de datos balanceados y no balanceados de (Ptacek et al., 2014) y
un detector de sarcasmo . Los nombres de usuario, las URL y las etiquetas hash se eliminan, luego se aplica el tokenizer de Twitter NLTK.
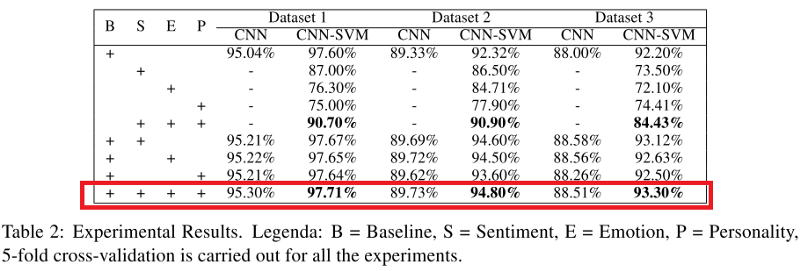
Las métricas de los clasificadores CNN y CNN-SVM aplicados a todos los conjuntos de datos se muestran en la tabla a continuación. Puede notar que cuando un modelo (en particular, CNN-SVM) combina los signos de sarcasmo, los signos de emociones, sentimientos y rasgos de carácter, supera a todos los demás modelos, con la excepción del modelo base (B).
Se probaron las posibilidades de generalización de los modelos, y la conclusión principal fue que si los conjuntos de datos eran de naturaleza diferente, esto influía significativamente en el resultado, que se muestra en la figura a continuación. Por ejemplo, la capacitación se realizó en el conjunto de datos 1 y se probó en el conjunto de datos 2; La puntuación F1 del modelo fue del 33,05%.