En la compañía, nuestro equipo para contrarrestar los ataques DDoS se llama "droppers de paquetes". Si bien todos los demás equipos están haciendo cosas interesantes con el tráfico que pasa por nuestra red, nos divertimos encontrando nuevas formas de deshacernos de él.
 Foto: Brian Evans , CC BY-SA 2.0
Foto: Brian Evans , CC BY-SA 2.0La capacidad de descartar paquetes rápidamente es muy importante para oponerse a los ataques DDoS.
Los paquetes descartados que llegan a nuestros servidores se pueden realizar en varios niveles. Cada método tiene sus pros y sus contras. Debajo del corte, miramos todo lo que probamos.
Nota del traductor: en la salida de algunos de los comandos presentados, se eliminaron espacios adicionales para mantener la legibilidad.
Sitio de prueba
Para la conveniencia de comparar los métodos, le proporcionaremos algunos números, sin embargo, no los tome demasiado literalmente, debido a la artificialidad de las pruebas. Utilizaremos una de nuestras tarjetas de red Intel de 10 Gb / s. Las características restantes del servidor no son tan importantes, porque queremos centrarnos en las limitaciones del sistema operativo, no en el hardware.
Nuestras pruebas se verán de la siguiente manera:
- Creamos una carga de una gran cantidad de paquetes UDP pequeños, alcanzando un valor de 14 millones de paquetes por segundo;
- Todo este tráfico se dirige a un núcleo de procesador del servidor seleccionado;
- Medimos el número de paquetes procesados por el núcleo en un solo núcleo de procesador.
El tráfico artificial se genera de tal manera que se crea una carga máxima: se utilizan una dirección IP aleatoria y un puerto del remitente. Así es como se ve en tcpdump:
$ tcpdump -ni vlan100 -c 10 -t udp and dst port 1234 IP 198.18.40.55.32059 > 198.18.0.12.1234: UDP, length 16 IP 198.18.51.16.30852 > 198.18.0.12.1234: UDP, length 16 IP 198.18.35.51.61823 > 198.18.0.12.1234: UDP, length 16 IP 198.18.44.42.30344 > 198.18.0.12.1234: UDP, length 16 IP 198.18.106.227.38592 > 198.18.0.12.1234: UDP, length 16 IP 198.18.48.67.19533 > 198.18.0.12.1234: UDP, length 16 IP 198.18.49.38.40566 > 198.18.0.12.1234: UDP, length 16 IP 198.18.50.73.22989 > 198.18.0.12.1234: UDP, length 16 IP 198.18.43.204.37895 > 198.18.0.12.1234: UDP, length 16 IP 198.18.104.128.1543 > 198.18.0.12.1234: UDP, length 16
En el servidor seleccionado, todos los paquetes se convertirán en una cola RX y, por lo tanto, serán procesados por un núcleo. Logramos esto con el control de flujo de hardware:
ethtool -N ext0 flow-type udp4 dst-ip 198.18.0.12 dst-port 1234 action 2
Las pruebas de rendimiento son un proceso complejo. Cuando preparamos las pruebas, notamos que la presencia de sockets sin procesar activos afecta negativamente el rendimiento, por lo que antes de ejecutar las pruebas, debe asegurarse de que no se esté ejecutando
tcpdump . Hay una manera fácil de verificar si hay procesos incorrectos:
$ ss -A raw,packet_raw -l -p|cat Netid State Recv-Q Send-Q Local Address:Port p_raw UNCONN 525157 0 *:vlan100 users:(("tcpdump",pid=23683,fd=3))
Y finalmente, apagamos Intel Turbo Boost en nuestro servidor:
echo 1 | sudo tee /sys/devices/system/cpu/intel_pstate/no_turbo
A pesar de que Turbo Boost es una gran cosa y aumenta el rendimiento en al menos un 20%, arruina significativamente la desviación estándar en nuestras pruebas. Con turbo encendido, la desviación alcanza ± 1.5%, mientras que sin ella solo 0.25%.
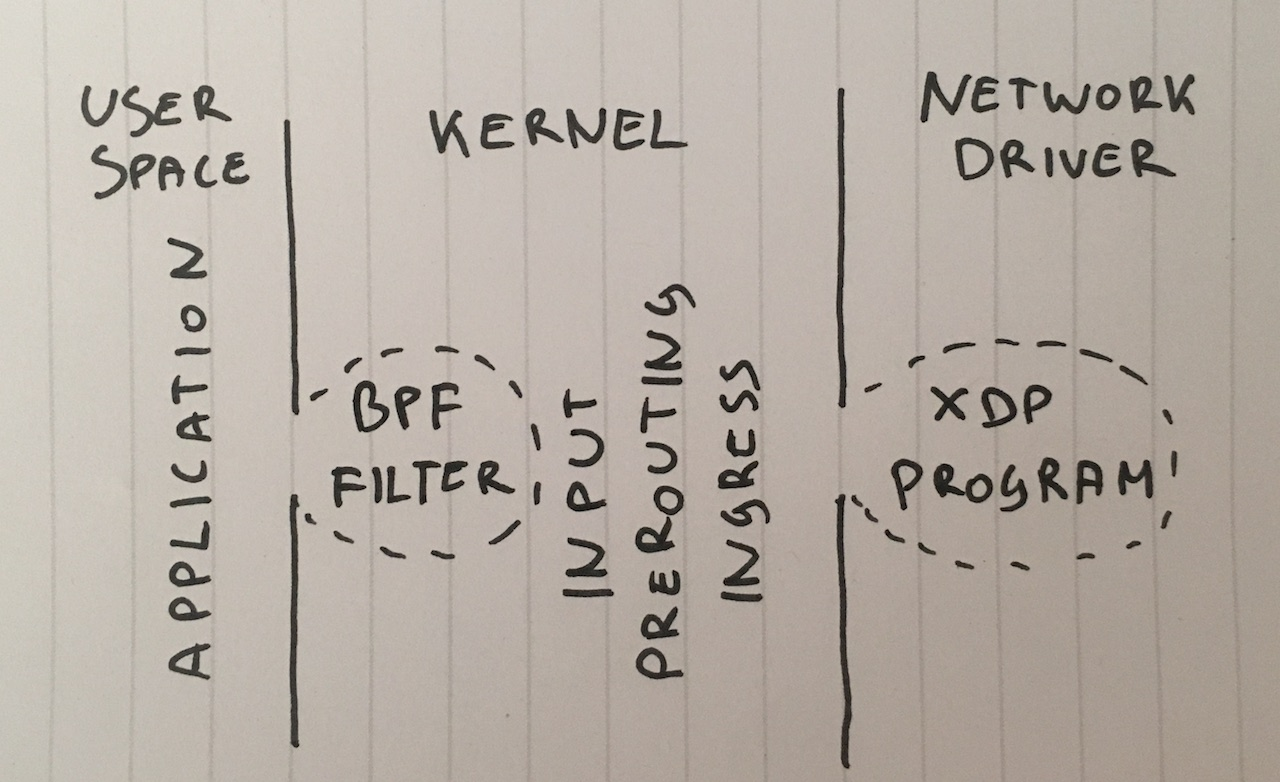
Paso 1. Descarte los paquetes en la aplicación
Comencemos con la idea de entregar todos los paquetes a la aplicación e ignorarlos allí. Para la honestidad del experimento, asegúrese de que iptables no afecte el rendimiento de ninguna manera:
iptables -I PREROUTING -t mangle -d 198.18.0.12 -p udp --dport 1234 -j ACCEPT iptables -I PREROUTING -t raw -d 198.18.0.12 -p udp --dport 1234 -j ACCEPT iptables -I INPUT -t filter -d 198.18.0.12 -p udp --dport 1234 -j ACCEPT
La aplicación es un ciclo simple en el que los datos recibidos se descartan inmediatamente:
s = socket.socket(AF_INET, SOCK_DGRAM) s.bind(("0.0.0.0", 1234)) while True: s.recvmmsg([...])
Ya hemos preparado el
código , ejecuta:
$ ./dropping-packets/recvmmsg-loop packets=171261 bytes=1940176
Esta solución permite que el núcleo tome solo 175 mil paquetes de la cola de hardware, como lo midió
ethtool y
nuestras mmwatch :
$ mmwatch 'ethtool -S ext0|grep rx_2' rx2_packets: 174.0k/s
Técnicamente, 14 millones de paquetes por segundo llegan al servidor, sin embargo, un núcleo de procesador no puede hacer frente a ese volumen.
mpstat confirma esto:
$ watch 'mpstat -u -I SUM -P ALL 1 1|egrep -v Aver' 01:32:05 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 01:32:06 PM 0 0.00 0.00 0.00 2.94 0.00 3.92 0.00 0.00 0.00 93.14 01:32:06 PM 1 2.17 0.00 27.17 0.00 0.00 0.00 0.00 0.00 0.00 70.65 01:32:06 PM 2 0.00 0.00 0.00 0.00 0.00 100.00 0.00 0.00 0.00 0.00 01:32:06 PM 3 0.95 0.00 1.90 0.95 0.00 3.81 0.00 0.00 0.00 92.38
Como podemos ver, la aplicación no es un cuello de botella: la CPU # 1 se usa al 27.17% + 2.17%, mientras que el manejo de interrupciones ocupa el 100% en la CPU # 2.
Usar
recvmessagge(2) juega un papel importante. Después de que se descubrió la vulnerabilidad de Spectre, las llamadas al sistema se volvieron aún más caras debido al
KPTI y la
retpoline utilizada en el núcleo
$ tail -n +1 /sys/devices/system/cpu/vulnerabilities/* ==> /sys/devices/system/cpu/vulnerabilities/meltdown <== Mitigation: PTI ==> /sys/devices/system/cpu/vulnerabilities/spectre_v1 <== Mitigation: __user pointer sanitization ==> /sys/devices/system/cpu/vulnerabilities/spectre_v2 <== Mitigation: Full generic retpoline, IBPB, IBRS_FW
Paso 2. Matar conntrack
Específicamente, realizamos una carga de este tipo con diferentes puertos IP y de remitente para cargar conntrack tanto como sea posible. El número de entradas en conntrack durante la prueba tiende al máximo posible y podemos verificar esto:
$ conntrack -C 2095202 $ sysctl net.netfilter.nf_conntrack_max net.netfilter.nf_conntrack_max = 2097152
Además, en
dmesg también puedes ver gritos conntrack:
[4029612.456673] nf_conntrack: nf_conntrack: table full, dropping packet [4029612.465787] nf_conntrack: nf_conntrack: table full, dropping packet [4029617.175957] net_ratelimit: 5731 callbacks suppressed
Así que vamos a apagarlo:
iptables -t raw -I PREROUTING -d 198.18.0.12 -p udp -m udp --dport 1234 -j NOTRACK
Y reinicie las pruebas:
$ ./dropping-packets/recvmmsg-loop packets=331008 bytes=5296128
Esto nos permitió alcanzar la marca de 333 mil paquetes por segundo. ¡Hurra!
PD Usando SO_BUSY_POLL podemos alcanzar hasta 470 mil por segundo, sin embargo, este es un tema para una publicación separada.
Paso 3. Filtro de lote Berkeley
Sigamos adelante. ¿Por qué necesitamos entregar paquetes a la aplicación? Aunque esta no es una solución común, podemos vincular el clásico filtro de paquetes de Berkeley al socket llamando a
setsockopt(SO_ATTACH_FILTER) y configurar el filtro para que los paquetes vuelvan a caer en el núcleo.
Prepare el
código , ejecute:
$ ./bpf-drop packets=0 bytes=0
Usando un filtro de paquetes (los filtros Berkeley clásicos y avanzados ofrecen un rendimiento más o menos similar), llegamos a aproximadamente 512 mil paquetes por segundo. Además, dejar caer un paquete durante una interrupción libera al procesador de tener que activar la aplicación.
Paso 4. iptables DROP después del enrutamiento
Ahora podemos descartar paquetes agregando la siguiente regla a iptables en la cadena INPUT:
iptables -I INPUT -d 198.18.0.12 -p udp --dport 1234 -j DROP
Permítame recordarle que ya deshabilitamos conntrack con la regla
-j NOTRACK . Estas dos reglas nos dan 608 mil paquetes por segundo.
Veamos los números en iptables:
$ mmwatch 'iptables -L -v -n -x | head' Chain INPUT (policy DROP 0 packets, 0 bytes) pkts bytes target prot opt in out source destination 605.9k/s 26.7m/s DROP udp -- * * 0.0.0.0/0 198.18.0.12 udp dpt:1234
Bueno, no está mal, pero podemos hacerlo mejor.
Paso 5. iptabes DROP en PREROUTING
Una técnica más rápida es descartar paquetes antes de enrutarlos usando esta regla:
iptables -I PREROUTING -t raw -d 198.18.0.12 -p udp --dport 1234 -j DROP
Esto nos permite descartar 1.688 millones de paquetes por segundo.
De hecho, este es un salto ligeramente sorprendente en el rendimiento. Todavía no entiendo las razones, tal vez nuestro enrutamiento es complicado, o tal vez solo un error en la configuración del servidor.
En cualquier caso, las iptables sin procesar son mucho más rápidas.
Paso 6. nftables DROP
La utilidad iptables ahora es un poco vieja. Fue reemplazada por nftables. Mira
esta explicación en video de por qué nftables es el mejor. Nftables promete ser más rápido que el encanecimiento de iptables por una variedad de razones, incluidos los rumores de que las retpolines ralentizan mucho a iptables.
Pero nuestro artículo todavía no se trata de comparar iptables y nftables, así que intentemos lo más rápido que pueda hacer:
nft add table netdev filter nft -- add chain netdev filter input { type filter hook ingress device vlan100 priority -500 \; policy accept \; } nft add rule netdev filter input ip daddr 198.18.0.0/24 udp dport 1234 counter drop nft add rule netdev filter input ip6 daddr fd00::/64 udp dport 1234 counter drop
Los contadores se pueden ver así:
$ mmwatch 'nft --handle list chain netdev filter input' table netdev filter { chain input { type filter hook ingress device vlan100 priority -500; policy accept; ip daddr 198.18.0.0/24 udp dport 1234 counter packets 1.6m/s bytes 69.6m/s drop
El enlace de entrada nftables mostró valores de aproximadamente 1,53 millones de paquetes. Esto es un poco menos que la cadena PREROUTING en iptables. Pero hay un misterio en esto: teóricamente, el enlace nftables va antes que PREROUTING iptables y, por lo tanto, debe procesarse más rápido.
En nuestra prueba, nftables es un poco más lento que iptables, pero de todos modos nftables es más genial. : P
Paso 7. tc DROP
De manera algo inesperada, el enlace tc (control de tráfico) ocurre antes que iptables PREROUTING. tc nos permite seleccionar paquetes de acuerdo con criterios simples y, por supuesto, descartarlos. La sintaxis es un poco inusual, por lo que sugerimos usar
este script para la configuración. Y necesitamos una regla bastante complicada que se vea así:
tc qdisc add dev vlan100 ingress tc filter add dev vlan100 parent ffff: prio 4 protocol ip u32 match ip protocol 17 0xff match ip dport 1234 0xffff match ip dst 198.18.0.0/24 flowid 1:1 action drop tc filter add dev vlan100 parent ffff: protocol ipv6 u32 match ip6 dport 1234 0xffff match ip6 dst fd00::/64 flowid 1:1 action drop
Y podemos comprobarlo en acción:
$ mmwatch 'tc -s filter show dev vlan100 ingress' filter parent ffff: protocol ip pref 4 u32 filter parent ffff: protocol ip pref 4 u32 fh 800: ht divisor 1 filter parent ffff: protocol ip pref 4 u32 fh 800::800 order 2048 key ht 800 bkt 0 flowid 1:1 (rule hit 1.8m/s success 1.8m/s) match 00110000/00ff0000 at 8 (success 1.8m/s ) match 000004d2/0000ffff at 20 (success 1.8m/s ) match c612000c/ffffffff at 16 (success 1.8m/s ) action order 1: gact action drop random type none pass val 0 index 1 ref 1 bind 1 installed 1.0/s sec Action statistics: Sent 79.7m/s bytes 1.8m/s pkt (dropped 1.8m/s, overlimits 0 requeues 0)
El enlace tc nos permitió dejar caer hasta 1.8 millones de paquetes por segundo en un solo núcleo. ¡Esto es genial!
Pero podemos hacerlo aún más rápido ...
Paso 8. XDP_DROP
Y finalmente, nuestra arma más fuerte: XDP -
eXpress Data Path . Con XDP, podemos ejecutar el código extendido de Berkley Packet Filter (eBPF) directamente en el contexto del controlador de red y, lo más importante, incluso antes de asignar memoria para
skbuff , lo que nos promete un aumento en la velocidad.
Por lo general, un proyecto XDP consta de dos partes:
- código eBPF descargable
- gestor de arranque que coloca el código en la interfaz de red correcta
Escribir su gestor de arranque es una tarea difícil, así que simplemente use el
nuevo chip iproute2 y cargue el código con un comando simple:
ip link set dev ext0 xdp obj xdp-drop-ebpf.o
Ta Dam!
El código fuente del
programa descargable eBPF está disponible aquí . El programa analiza características de los paquetes IP como el protocolo UDP, la subred del remitente y el puerto de destino:
if (h_proto == htons(ETH_P_IP)) { if (iph->protocol == IPPROTO_UDP && (htonl(iph->daddr) & 0xFFFFFF00) == 0xC6120000 // 198.18.0.0/24 && udph->dest == htons(1234)) { return XDP_DROP; } }
El programa XDP debe construirse utilizando el sonido metálico moderno, que puede generar el código de bytes BPF. Después de eso, podemos descargar y probar la funcionalidad del programa BFP:
$ ip link show dev ext0 4: ext0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 xdp qdisc fq state UP mode DEFAULT group default qlen 1000 link/ether 24:8a:07:8a:59:8e brd ff:ff:ff:ff:ff:ff prog/xdp id 5 tag aedc195cc0471f51 jited
Y luego vea las estadísticas en
ethtool :
$ mmwatch 'ethtool -S ext0|egrep "rx"|egrep -v ": 0"|egrep -v "cache|csum"' rx_out_of_buffer: 4.4m/s rx_xdp_drop: 10.1m/s rx2_xdp_drop: 10.1m/s
Yoo hoo! ¡Con XDP, podemos soltar hasta 10 millones de paquetes por segundo!
 Foto: Andrew Filer , CC BY-SA 2.0
Foto: Andrew Filer , CC BY-SA 2.0Conclusiones
Repetimos el experimento para IPv4 e IPv6 y preparamos este diagrama:
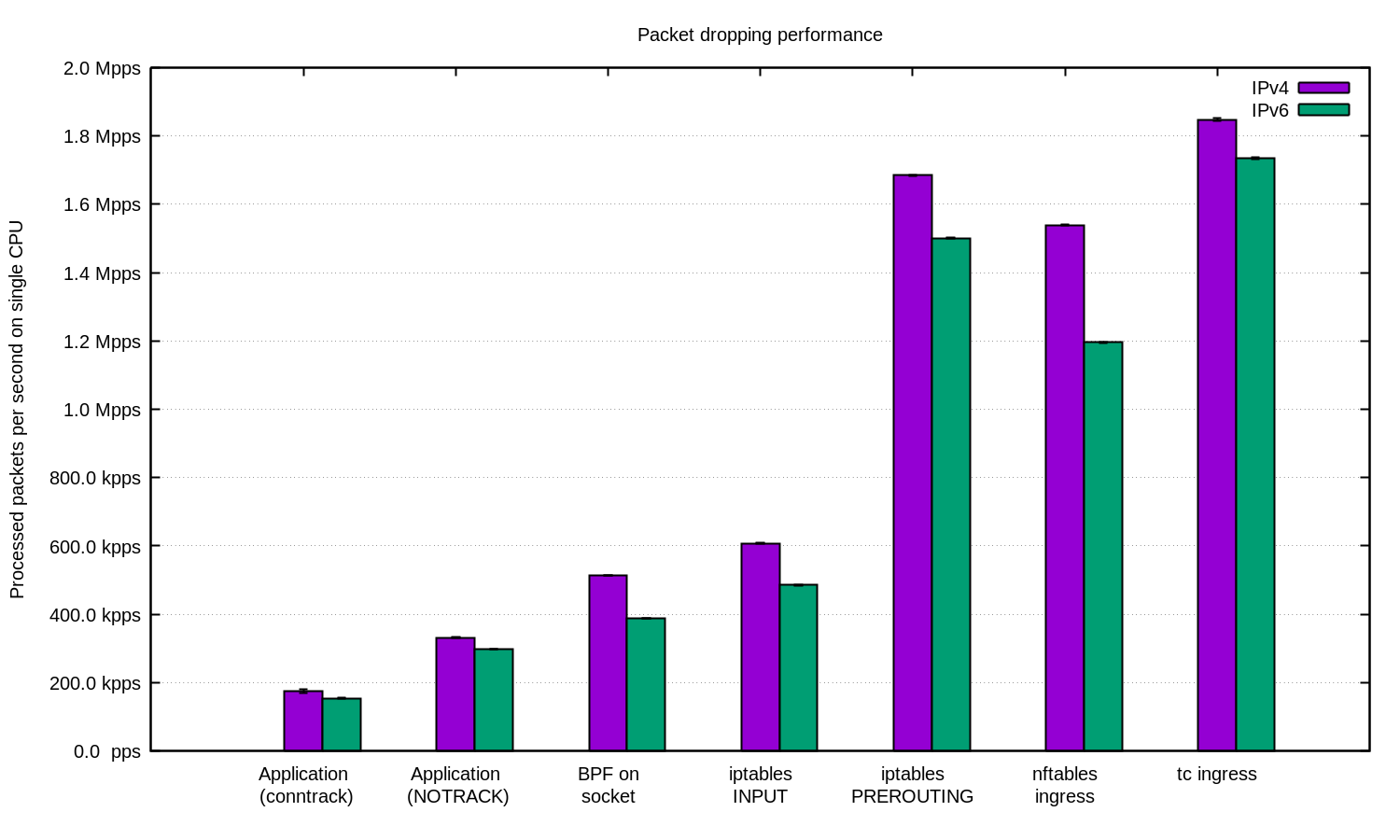
En general, se puede argumentar que nuestra configuración para IPv6 es un poco más lenta. Pero dado que los paquetes IPv6 son algo más grandes, se espera la diferencia de velocidad.
Linux tiene muchas formas de filtrar paquetes, cada una con su propia velocidad y complejidad.
Para protegerse contra DDoS, es bastante razonable entregar paquetes a la aplicación y procesarlos allí. Una aplicación bien ajustada puede mostrar buenos resultados.
Para ataques DDoS con IP aleatoria o falsificada, puede ser útil deshabilitar conntrack para obtener un pequeño aumento de velocidad, pero tenga cuidado: hay ataques contra los cuales conntrack es muy útil.
En otros casos, tiene sentido agregar el firewall de Linux como una de las formas de mitigar el ataque DDoS. En algunos casos, es mejor usar la tabla "-t raw PREROUTING", ya que es mucho más rápida que la tabla de filtro.
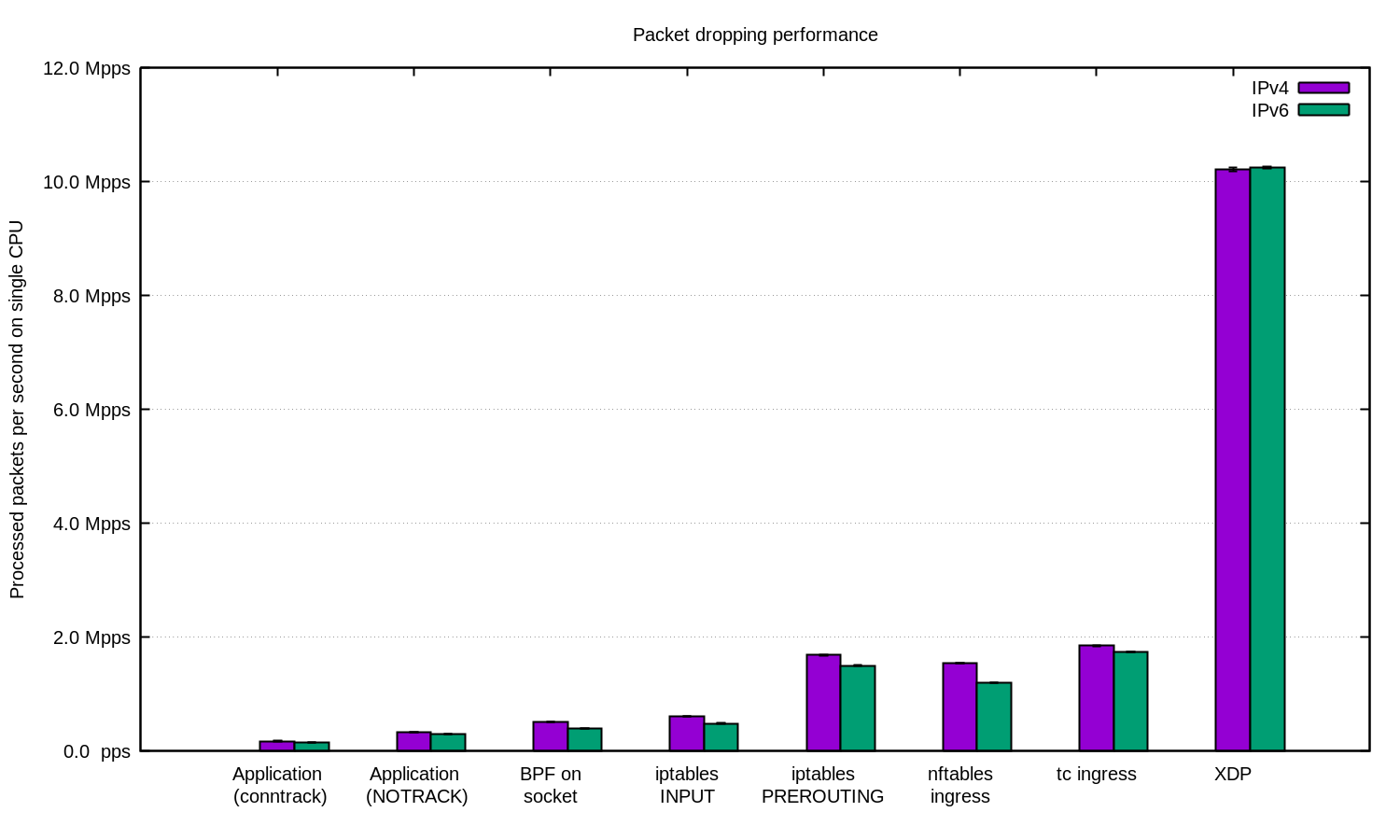
Para los casos más avanzados, siempre usamos XDP. Y sí, esto es algo muy poderoso. Aquí hay un gráfico como el anterior, solo con XDP:
Si desea repetir el experimento, aquí está
README, en el que documentamos todo .
En CloudFlare usamos ... casi todas estas técnicas. Algunos trucos en el espacio del usuario están integrados en nuestras aplicaciones. La técnica de iptables se encuentra en nuestro
Gatebot . Finalmente, reemplazamos nuestra propia solución central con XDP.
Muchas gracias a
Jesper Dangaard Brouer por su ayuda.