Para continuar el
artículo sobre los peligros de la diversificación excesiva, crearemos herramientas útiles de selección de valores. Después de eso, haremos un reequilibrio simple y agregaremos las condiciones únicas de los indicadores técnicos, que a menudo faltan en los servicios populares. Y luego compare los rendimientos de los activos individuales y las diferentes carteras.
En todo esto usamos Pandas y minimizamos el número de ciclos. Agrupe las series de tiempo y dibuje los gráficos. Conozcamos los índices múltiples y su comportamiento. Y todo esto en Jupyter en Python 3.6.
Si quieres hacer algo bien, hazlo tú mismo.
Fernando Porsche
La herramienta descrita le permitirá seleccionar los activos óptimos para la cartera y excluir las herramientas impuestas por los consultores. Pero solo veremos el panorama general, sin tener en cuenta la liquidez, el tiempo para reclutar puestos, las comisiones de los corredores y el costo de una acción. En general, con un reequilibrio mensual o anual de corredores grandes, serán costos insignificantes. Sin embargo, antes de aplicar, la estrategia elegida aún debe verificarse en el analizador de prueba controlado por eventos, por ejemplo, Quantopian (QP), para eliminar posibles errores.
¿Por qué no inmediatamente en QP? Tiempo Allí, la prueba más simple dura unos 5 minutos. Y la solución actual le permitirá verificar cientos de estrategias diferentes con condiciones únicas en un minuto.
Carga de datos sin procesar
Para cargar los datos, tome el método descrito en este
artículo . Utilizo PostgreSQL para almacenar precios diarios, pero ahora está lleno de fuentes gratuitas desde las que puede crear el DataFrame necesario.
El código para descargar el historial de precios de la base de datos está disponible en el repositorio. El enlace estará al final del artículo.
Estructura del marco de datos
Cuando se trabaja con el historial de precios, para una agrupación conveniente y acceso a todos los datos, la mejor solución es usar un índice múltiple (MultiIndex) con fecha y tickers.
df = df.set_index(['dt', 'symbol'], drop=False).sort_index() df.tail(len(df.index.levels[1]) * 2)
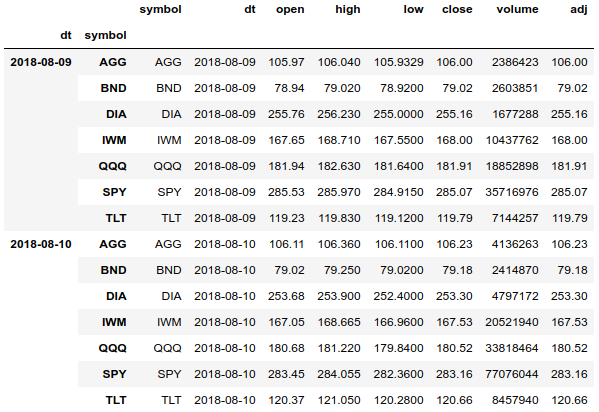
Con un índice múltiple, podemos acceder fácilmente al historial de precios completo de todos los activos y podemos agrupar la matriz por separado por fecha y activo. También podemos obtener el historial de precios de un activo.
Aquí hay un ejemplo de cómo puede agrupar fácilmente el historial por semana, mes y año. Y para mostrar todo esto en gráficos de las fuerzas de Pandas:
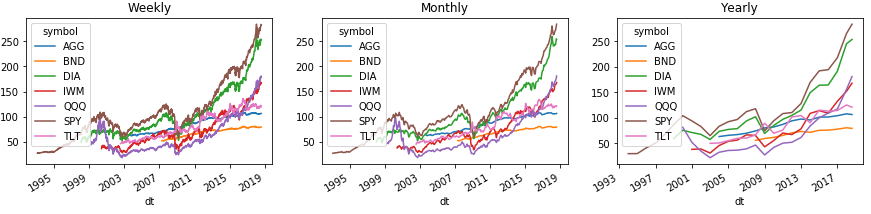
Para mostrar correctamente el área con la leyenda del gráfico, transferimos el nivel de índice con tickers al segundo nivel sobre las columnas usando el comando Series (). Unstack (1). Con DataFrame (), dicho número no funcionará, pero la solución está por debajo.
Al agrupar por períodos estándar, Pandas utiliza la última fecha del calendario del grupo en el índice, que a menudo difiere de las fechas reales. Para solucionar esto, actualice el índice.
monthly = df.groupby([pd.Grouper(freq='M', level=0), level_values(1)]).agg(agg_rules) \ .set_index(['dt', 'symbol'], drop=False)
Un ejemplo de cómo obtener el historial de precios de un activo específico (tomamos todas las fechas, el ticker QQQ y todas las columnas):
monthly.loc[(slice(None), ['QQQ']), :]
Volatilidad mensual de activos
Ahora podemos ver algunas líneas en el gráfico del cambio en el precio de cada activo para el período de interés para nosotros. Para hacer esto, obtenemos el porcentaje de cambios de precios al agrupar el marco de datos por nivel de múltiples índices con un ticker de activos.
monthly = df.groupby([pd.Grouper(freq='M', level=0), level_values(1)]).agg( agg_rules).set_index(['dt', 'symbol'], drop=False)
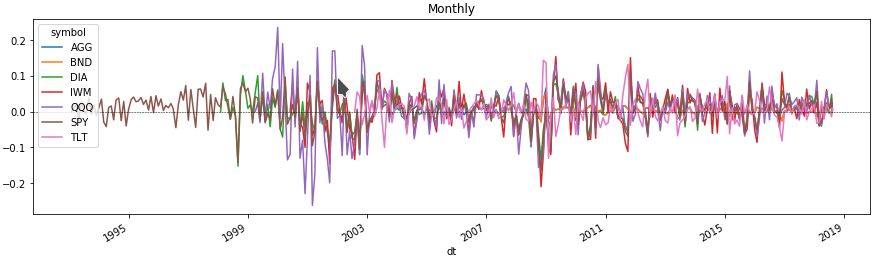
Comparar devoluciones de activos
Ahora usaremos el método de ventana Series (). Rolling () y mostraremos el rendimiento de los activos durante un período determinado:
Código de Python rolling_prod = lambda x: x.rolling(len(x), min_periods=1).apply(np.prod)
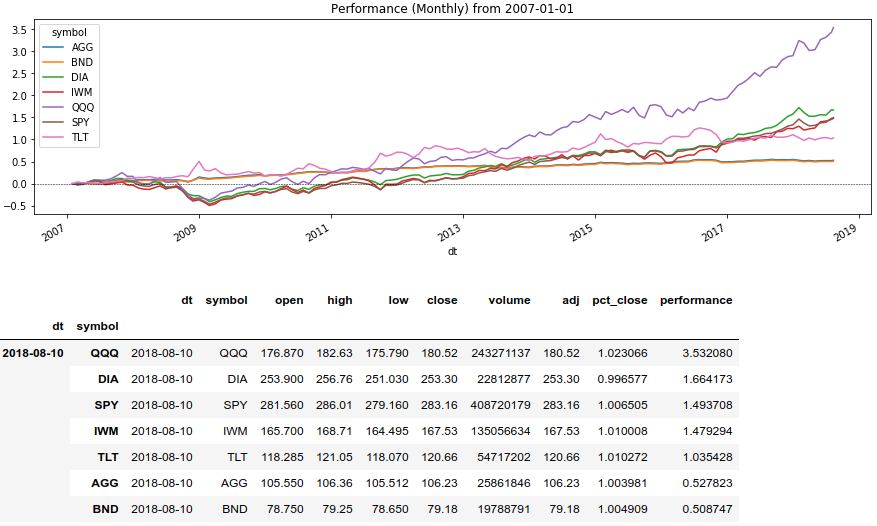
Métodos de reequilibrio de cartera
Así llegamos a lo más delicioso. En los ejemplos, veremos los resultados de la cartera en la asignación de capital a acciones predeterminadas entre varios activos. Y también agreguemos condiciones únicas bajo las cuales abandonaremos algunos activos al momento de la distribución del capital. Si no hay activos adecuados, asumimos que el corredor tiene el capital en el caché.
Para utilizar los métodos de Pandas para reequilibrar, necesitamos almacenar los recursos compartidos de distribución y las condiciones de reequilibrio en un DataFrame con datos agrupados. Ahora considere las funciones de reequilibrio que pasaremos al método DataFrame (). Apply ():
En orden:
- rebalance_simple es la función más simple que distribuirá la rentabilidad de cada activo en acciones.
- rebalance_sma es una función que distribuye capital entre activos cuyo promedio móvil es 50 días mayor que 200 días al momento del reequilibrio.
- rebalance_rsi: una función que distribuye capital entre los activos para los cuales el valor del indicador RSI durante 100 días es superior a 50.
- rebalance_custom es la función más lenta y universal, donde calcularemos los valores del indicador a partir del historial diario de precios de activos en el momento del reequilibrio. Aquí puede usar cualquier condición y datos. Incluso descargue cada vez de fuentes externas. Pero no puedes prescindir de un ciclo.
- drawdown - función auxiliar, que muestra la reducción máxima en la cartera.
En las funciones de reequilibrio, necesitamos una matriz de todos los datos para la fecha desglosada por activos. El método DataFrame (). Apply (), mediante el cual calcularemos los resultados de las carteras, pasará una matriz a nuestra función, donde las columnas se convertirán en el índice de la fila. Y si hacemos un índice múltiple, donde los tickers serán el nivel cero, entonces nos llegará un índice múltiple. Podemos expandir este índice múltiple en una matriz bidimensional y obtener los datos del activo correspondiente en cada línea.

Reequilibrio de cartera
Ahora es suficiente preparar las condiciones necesarias y hacer un cálculo para cada cartera en el ciclo. En primer lugar, calculamos los indicadores en el historial diario de precios:
Ahora agruparemos la historia para el período de reequilibrio deseado utilizando los métodos descritos anteriormente. Al mismo tiempo, tomaremos los valores de los indicadores al comienzo del período para excluir mirar hacia el futuro.
Describimos la estructura de las carteras e indicamos el reequilibrio deseado. Calcularemos las carteras en un ciclo, ya que necesitamos especificar acciones y condiciones únicas:
Esta vez necesitamos hacer un truco con los índices de columna y fila para obtener el índice múltiple deseado en la función de reequilibrio. Lo conseguiremos llamando a los métodos DataFrame (). Stack (). Unstack ([1, 2]) en secuencia. Este código transferirá las columnas a un índice múltiple en minúsculas y luego devolverá el índice múltiple con tickers y columnas en el orden deseado.
Maletines confeccionados para cartas
Ahora queda por dibujar todo. Para hacer esto, vuelva a ejecutar el ciclo de cartera, que muestra los datos en los gráficos. Al final dibujaremos SPY como punto de referencia para la comparación.
Código de Python fig = plt.figure(figsize=(15, 4), facecolor='white') ax_perf = fig.add_subplot(121) ax_dd = fig.add_subplot(122) for p in portfolios: p['performance'].rename(p['name']).plot(ax=ax_perf, legend=True, title='Performance') p['drawdown'].rename(p['name']).plot(ax=ax_dd, legend=True, title='Max drawdown')
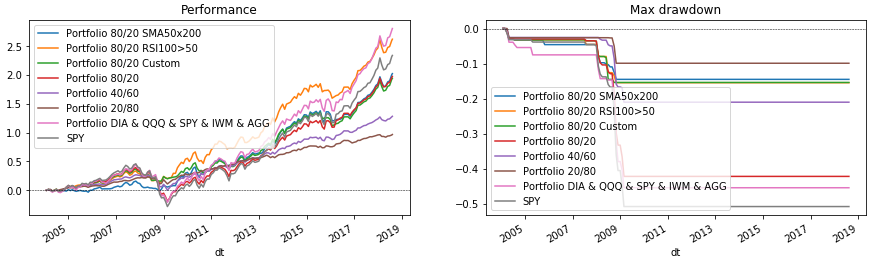
Conclusión
El código considerado le permite seleccionar varias estructuras de cartera y condiciones de reequilibrio. Con su ayuda, puede verificar rápidamente si, por ejemplo, vale la pena tener oro (GLD) o mercados emergentes (EEM) en una cartera. Pruébelo usted mismo, agregue sus propias condiciones para los indicadores o seleccione los parámetros ya descritos. (Pero recuerde el error del sobreviviente y que ajustarse a datos pasados puede no estar a la altura de las expectativas en el futuro). Y luego decidir en quién confía su cartera: ¿Python o consultores financieros?
Repositorio:
rebalance.portfolio