
Para nuestra gran sorpresa, no había una sola pieza de material sobre la maravillosa herramienta de código abierto para la copia de seguridad de datos:
Borg (¡no debe confundirse con el progenitor del mismo nombre Kubernetes!) . Como lo hemos estado utilizando en producción durante más de un año, en este artículo compartiré las "impresiones" que hemos obtenido sobre Borg.
Antecedentes: experiencia con Bacula y Bareos
En 2017, estábamos cansados de Bacula y Bareos, que utilizamos desde el comienzo de nuestra actividad (es decir, alrededor de 9 años en producción en ese momento). Por qué Durante la operación, hemos acumulado mucho descontento:
- SD (Storage Daemon) se congela. Si ha configurado el paralelismo, el mantenimiento de SD se vuelve más complicado y su congelación bloqueará más copias de seguridad según lo programado y la posibilidad de recuperación.
- Es necesario generar configuraciones tanto para el cliente como para el director. Incluso si automatizamos esto (en nuestro caso, Chef, Ansible, y nuestro propio desarrollo se usaron en diferentes momentos), necesitamos monitorear que el director, después de su recarga, realmente recogió la configuración. Esto solo se rastrea en la salida del comando de recarga y en la llamada de mensajes después (para obtener el texto de error en sí).
- Programar copias de seguridad. Los desarrolladores de Bacula decidieron seguir su propio camino y escribieron su propio formato de programación, que no se puede analizar o convertir a otro. Aquí hay ejemplos de programaciones de respaldo estándar en nuestras antiguas instalaciones:
- Copia de seguridad completa diaria los miércoles e incremental en otros días:
Run = Level=Full Pool="Foobar-low7" wed at 18:00
Run = Level=Incremental Pool="Foobar-low7" at 18:00 - Copia de seguridad completa de archivos wal 2 veces al mes e incremente cada hora:
Run = Level=Full FullPool=CustomerWALPool 1st fri at 01:45
Run = Level=Full FullPool=CustomerWALPool 3rd fri at 01:45
Run = Level=Incremental FullPool=CustomerWALPool IncrementalPool=CustomerWALPool on hourly - El
schedule generado para todas las ocasiones (en diferentes días de la semana cada 2 horas) obtuvimos alrededor de 1665 ... debido a lo que Bacula / Bareos periódicamente se volvía loco.
- Bacula-fd (y bareos-fd) tienen directorios con muchos datos (digamos 40 TB, de los cuales 35 TB contienen archivos grandes [100+ MB], y los 5 TB restantes contienen archivos pequeños [1 KB a 100 MB ]) comienza una pérdida lenta de memoria, que es una situación muy desagradable en la producción.
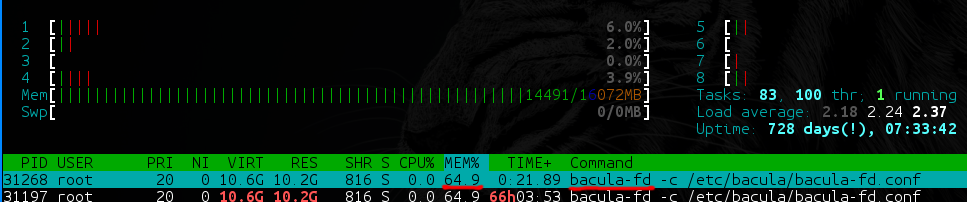
- En las copias de seguridad con una gran cantidad de archivos, Bacula y Bareos dependen mucho del rendimiento del DBMS utilizado. ¿Qué unidades tiene? ¿Cuán hábilmente sabes cómo sintonizarla con estas necesidades específicas? Y en la base de datos, por cierto, se crea una (!) Tabla no particionable con una lista de todos los archivos en todas las copias de seguridad y la segunda, con una lista de todas las rutas en todas las copias de seguridad. Si no está listo para asignar al menos 8 GB de RAM para la base + 40 GB de SSD para su servidor de respaldo, prepárese inmediatamente para los frenos.
- La dependencia de la base de datos merece un punto más. Bacula / Bareos para cada archivo le pregunta al director si ya existía dicho archivo. El director, por supuesto, se arrastra a la base de datos, a esas tablas muy grandes ... Resulta que la copia de seguridad se puede bloquear simplemente por el hecho de que varias copias de seguridad pesadas comenzaron al mismo tiempo, incluso si la diferencia es de varios megabytes allí.
Sería injusto decir que no se resolvió ningún problema, pero llegamos al punto en el que estábamos realmente cansados de varias soluciones y queríamos una solución confiable "aquí y ahora".
Bacula / Bareos funcionan muy bien con un pequeño número (10-30) de trabajos uniformes. ¿Se rompió una cosita una vez a la semana? Está bien: le dieron la tarea al oficial de servicio (u otro ingeniero), la repararon. Sin embargo, tenemos proyectos en los que la cantidad de trabajos es de cientos y la cantidad de archivos en ellos es de cientos de miles. Como resultado, 5 minutos a la semana para arreglar la copia de seguridad (sin contar varias horas de configuración antes de esto) comenzaron a multiplicarse. Todo esto condujo al hecho de que 2 horas al día era necesario reparar las copias de seguridad en todos los proyectos, porque literalmente en todas partes algo estaba jugando o rompiendo seriamente.
Entonces alguien podría pensar que un ingeniero dedicado dedicado a esto debería hacer copias de seguridad. Ciertamente, será lo más barbudo y severo posible, y por su aspecto, las copias de seguridad se reparan al instante, mientras bebe café con calma. Y esta idea puede ser cierta de alguna manera ... Pero siempre hay un pero. No todos pueden permitirse reparar y monitorear las copias de seguridad las 24 horas, y aún más: un ingeniero asignado para estos fines. Estamos seguros de que es mejor pasar estas 2 horas al día en algo más productivo y útil. Por lo tanto, pasamos a la búsqueda de soluciones alternativas que "simplemente funcionan".
Borg como una nueva forma
La búsqueda de otras opciones de código abierto se extendió a lo largo del tiempo, por lo que es difícil estimar los costos totales, pero en un momento (el año pasado), nuestra atención se dirigió al "
héroe de la ocasión":
BorgBackup (o simplemente Borg). En parte, esto fue facilitado por la experiencia real de su uso por uno de nuestros ingenieros (en el lugar de trabajo anterior).
Borg está escrito en Python (se requiere la versión> = 3.4.0), y el código exigente de rendimiento (compresión, cifrado, etc.) se implementa en C / Cython. Distribuido bajo una licencia BSD gratuita (3 cláusulas). Admite muchas plataformas, incluidas Linux, * BSD, macOS, así como a nivel experimental Cygwin y Linux Subsystem de Windows 10. Para instalar BorgBackup, hay paquetes disponibles para distribuciones populares de Linux y otros sistemas operativos, así como códigos fuente, que también se pueden instalar a través de pip, - Se puede encontrar información más detallada sobre esto en la
documentación del proyecto .
¿Por qué Borg nos sobornó tanto? Estas son sus principales ventajas:
La transición a Borg comenzó lentamente en pequeños proyectos. Al principio, estos eran simples scripts cron que hacían su trabajo todos los días. Esto continuó durante unos seis meses. Durante este tiempo, tuvimos que obtener copias de seguridad muchas veces ... ¡y resultó que Borg no tenía que ser reparado literalmente! Por qué Porque el principio simple funciona aquí: "Cuanto más simple sea el mecanismo, menos lugares se romperá".
Práctica: ¿cómo hacer una copia de seguridad con Borg?
Considere un ejemplo simple de crear una copia de seguridad:
- Descargue el último binario de lanzamiento en el servidor de respaldo y en la máquina que respaldaremos desde el repositorio oficial :
sudo wget https://github.com/borgbackup/borg/releases/download/1.1.6/borg-linux64 -O /usr/local/bin/borg sudo chmod +x /usr/local/bin/borg
Nota : Si utiliza una máquina local para la prueba como fuente y como receptor, la diferencia completa solo estará en el URI, que transmitiremos, pero recordamos que la copia de seguridad debe almacenarse por separado, y no en la misma máquina. - En el servidor de respaldo, cree el usuario
borg :
sudo useradd -m borg
Simple: sin grupos y con un shell estándar, pero siempre con un directorio de inicio. - Se genera una clave SSH en el cliente:
ssh-keygen
- En el servidor, agregue la clave generada al usuario
borg :
mkdir ~borg/.ssh echo 'command="/usr/local/bin/borg serve" ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDNdaDfqUUf/XmSVWfF7PfjGlbKW00MJ63zal/E/mxm+vJIJRBw7GZofe1PeTpKcEUTiBBEsW9XUmTctnWE6p21gU/JNU0jITLx+vg4IlVP62cac71tkx1VJFMYQN6EulT0alYxagNwEs7s5cBlykeKk/QmteOOclzx684t9d6BhMvFE9w9r+c76aVBIdbEyrkloiYd+vzt79nRkFE4CoxkpvptMgrAgbx563fRmNSPH8H5dEad44/Xb5uARiYhdlIl45QuNSpAdcOadp46ftDeQCGLc4CgjMxessam+9ujYcUCjhFDNOoEa4YxVhXF9Tcv8Ttxolece6y+IQM7fbDR' > ~borg/.ssh/authorized_keys chown -R borg:borg ~borg/.ssh / bin locales / Borg servir" ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDNdaDfqUUf / XmSVWfF7PfjGlbKW00MJ63zal / E / MXM + vJIJRBw7GZofe1PeTpKcEUTiBBEsW9XUmTctnWE6p21gU / JNU0jITLx + vg4IlVP62cac71tkx1VJFMYQN6EulT0alYxagNwEs7s5cBlykeKk / QmteOOclzx684t9d6BhMvFE9w9r + + c76aVBIdbEyrkloiYd vzt79nRkFE4CoxkpvptMgrAgbx563fRmNSPH8H5dEad44 / Xb5uARiYhdlIl45QuNSpAdcOadp46ftDeQCGLc4CgjMxessam + + 9ujYcUCjhFDNOoEa4YxVhXF9Tcv8Ttxolece6y IQM7fbDR'> ~ Borg / .ssh mkdir ~borg/.ssh echo 'command="/usr/local/bin/borg serve" ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDNdaDfqUUf/XmSVWfF7PfjGlbKW00MJ63zal/E/mxm+vJIJRBw7GZofe1PeTpKcEUTiBBEsW9XUmTctnWE6p21gU/JNU0jITLx+vg4IlVP62cac71tkx1VJFMYQN6EulT0alYxagNwEs7s5cBlykeKk/QmteOOclzx684t9d6BhMvFE9w9r+c76aVBIdbEyrkloiYd+vzt79nRkFE4CoxkpvptMgrAgbx563fRmNSPH8H5dEad44/Xb5uARiYhdlIl45QuNSpAdcOadp46ftDeQCGLc4CgjMxessam+9ujYcUCjhFDNOoEa4YxVhXF9Tcv8Ttxolece6y+IQM7fbDR' > ~borg/.ssh/authorized_keys chown -R borg:borg ~borg/.ssh
- Inicializamos el repositorio borg en el servidor desde el cliente:
ssh borg@172.17.0.3 hostname
El -e se usa para seleccionar el método de cifrado para el repositorio (sí, ¡también puede cifrar cada repositorio con su contraseña!). En este caso, porque Este es un ejemplo, no utilizamos cifrado. MyBorgRepo es el nombre del directorio en el que estará el borg repo (no es necesario crearlo de antemano; Borg hará todo por sí mismo). - Inicie la primera copia de seguridad con Borg:
borg create --stats --list borg@172.17.0.3:MyBorgRepo::"MyFirstBackup-{now:%Y-%m-%d_%H:%M:%S}" /etc /root
Sobre las llaves:
--stats y --list nos dan estadísticas sobre la copia de seguridad y los archivos que ingresaron;borg@172.17.0.3:MyBorgRepo todo está claro, este es nuestro servidor y directorio. ¿Y qué sigue para la magia? ..::"MyFirstBackup-{now:%Y-%m-%d_%H:%M:%S}" es el nombre del archivo dentro del repositorio. Es arbitrario, pero cumplimos con el formato _-timestamp (marca de tiempo en formato Python).
Que sigue ¡Por supuesto, mira lo que hay en nuestro respaldo! Lista de archivos dentro del repositorio:
borg@b3e51b9ed2c2:~$ borg list MyBorgRepo/ Warning: Attempting to access a previously unknown unencrypted repository! Do you want to continue? [yN] y MyFirstBackup-2018-08-04_16:55:53 Sat, 2018-08-04 16:55:54 [89f7b5bccfb1ed2d72c8b84b1baf477a8220955c72e7fcf0ecc6cd5a9943d78d]
Vemos una copia de seguridad con una marca de tiempo y cómo Borg nos pregunta si realmente queremos acceder a un repositorio sin cifrar al que nunca hemos estado antes.
Nos fijamos en la lista de archivos:
borg list MyBorgRepo::MyFirstBackup-2018-08-04_16:55:53
Obtenemos el archivo de la copia de seguridad (también puede hacer todo el directorio):
borg@b3e51b9ed2c2:~$ borg extract MyBorgRepo::MyFirstBackup-2018-08-04_16:55:53 etc/hostname borg@b3e51b9ed2c2:~$ ll etc/hostname -rw-r--r-- 1 borg borg 13 Aug 4 16:27 etc/hostname
¡Felicitaciones, su primera copia de seguridad Borg está lista!
Práctica: ¡automatiza esto [con GitLab]!
Habiendo envuelto todo esto en scripts, configuramos manualmente las copias de seguridad de manera similar en aproximadamente 40 hosts. Al darse cuenta de que Borg realmente funciona, comenzaron a transferirle proyectos cada vez más grandes ...
¡Y aquí nos enfrentamos con lo que hay en Bareos, pero no en Borg! A saber: WebUI o algún tipo de lugar centralizado para configurar copias de seguridad. Y realmente esperamos que este sea un fenómeno temporal, pero hasta ahora tuvimos que resolver algo. Buscando en Google las herramientas terminadas y reuniéndonos en una video conferencia, nos pusimos manos a la obra. Fue una gran idea integrar Borg con nuestros servicios internos, como lo hicimos antes con Bacula (Bacula misma eliminó la lista de trabajos de nuestra API centralizada, a la que teníamos nuestra propia interfaz integrada con otras configuraciones del proyecto). Pensamos en cómo hacerlo, describimos un plan de cómo y dónde construirlo, pero ... Ahora se necesitan copias de seguridad normales, pero no hay lugares para tomar planes de tiempo grandiosos. Que hacer
Las preguntas y los requisitos fueron aproximadamente los siguientes:
- ¿Qué usar como gestión centralizada de copias de seguridad?
- ¿Qué puede hacer cualquier administrador de Linux?
- ¿Qué puede incluso entender y configurar un gerente que muestra un cronograma de respaldo a los clientes?
- ¿Qué hace una tarea programada en su sistema todos los días?
- ¿Qué no será difícil de configurar y no se romperá?
La respuesta fue obvia: este es el viejo amigo, que heroicamente cumple con su deber todos los días. Simple No se congela. Incluso el administrador que es de Unix a "usted" puede arreglarlo.
Entonces crontab, pero ¿dónde guardas todo esto? ¿Es cada vez que va a la máquina del proyecto y edita el archivo con las manos? Por supuesto que no. Podemos poner nuestro horario en el repositorio de Git y configurar GitLab Runner, que mediante commit lo actualizará en el host.
Nota : Fue GitLab el que se eligió como herramienta de automatización, porque es conveniente para la tarea y en nuestro caso está en casi todas partes. Pero debo decir que de ninguna manera es una necesidad.Puede expandir crontab para copias de seguridad mediante una herramienta de automatización familiar o generalmente de forma manual (en proyectos pequeños o instalaciones domésticas).
Entonces, esto es lo que necesita para una automatización simple:
1.
GitLab y un repositorio , en el que, para empezar, habrá dos archivos:
schedule - horario de respaldoborg_backup_files.sh : un script simple para hacer una copia de seguridad de los archivos (como en el ejemplo anterior).
Ejemplo de
schedule :
Las variables de CI se usan para verificar que la actualización de crontab fue exitosa, y
CI_PROJECT_DIR es el directorio en el que estará el repositorio después de clonar el corredor. La última línea indica que la copia de seguridad se realiza todos los días a medianoche.
Ejemplo
borg_backup_files.sh :
El primer argumento aquí es el nombre de la copia de seguridad, y el
segundo es la lista de directorios para la copia de seguridad, separados por comas. Estrictamente hablando, una lista también puede ser un conjunto de archivos separados.
2.
GitLab Runner , que se ejecuta en la máquina que necesita una copia de seguridad y se bloquea solo para los trabajos de este repositorio.
3.
El script de CI en sí , implementado por el
.gitlab-ci.yml :
stages: - deploy Deploy: stage: deploy script: - export TIMESTAMP=$(date '+%Y.%m.%d %H:%M:%S') - cat schedule | envsubst | crontab - tags: - borg-backup
4. La
clave SSH para el usuario
gitlab-runner con acceso al servidor de
gitlab-runner (en el ejemplo, es 10.100.1.1). Por defecto, debe estar en el
.ssh/id_rsa (
gitlab-runner ).
5.
El usuario borg en el mismo 10.100.1.1 con acceso solo al comando
borg serve :
$ cat .ssh/authorized_keys command="/usr/bin/borg serve" ssh-rsa AAAAB3NzaC1yc2EAA...
Ahora, cuando se compromete con el repositorio Runner, rellenará el contenido de crontab. Y cuando llegue el tiempo de respuesta del cron, se realizará una copia de seguridad de los directorios
/etc y
/opt , que estará en el servidor de copia de seguridad en el directorio
MyHostname-SYSTEM del servidor 10.100.1.1.

En lugar de una conclusión: ¿qué más puedes hacer?
El uso de Borg en esto, por supuesto, no termina ahí. Aquí hay algunas ideas para una mayor implementación, algunas de las cuales ya hemos implementado en casa:
- Agregue scripts universales para diferentes copias de seguridad, que al final de la ejecución ejecutan
borg_backup_files.sh , dirigidas al directorio con el resultado de su trabajo. Por ejemplo, puede hacer una copia de seguridad de PostgreSQL (pg_basebackup), MySQL (innobackupex), GitLab (trabajo de rastrillo incorporado, crear un archivo). - Host central con horario de respaldo . ¿No configurar en cada host GitLab Runner? Deje que esté solo en el servidor de respaldo, y crontab al inicio transfiere el script de respaldo a la máquina y lo ejecuta allí. Para esto, por supuesto, necesitará el usuario
borg en la máquina del cliente y ssh-agent , para no diseñar la clave del servidor de respaldo en cada máquina. - Monitoreo Donde sin el! Las alertas sobre una copia de seguridad completada incorrectamente deben ser.
- Borrando el repositorio borg de archivos antiguos. A pesar de una buena deduplicación, las copias de seguridad antiguas aún deben limpiarse. Para hacer esto, puede hacer una llamada para
borg prune las borg prune al final del script de copia de seguridad. - Interfaz web para el horario. Te resultará útil si editar crontab a mano o en la interfaz web no te parece sólido / incómodo.
- Gráficos circulares Unos gráficos para una representación visual del porcentaje de copias de seguridad completadas con éxito, su tiempo de ejecución, el ancho del canal "comido". No es de extrañar que escribí que no hay suficiente WebUI, como en Bareos ...
- Acciones simples que me gustaría recibir mediante un botón: iniciar una copia de seguridad a pedido, restaurar en una máquina, etc.
Y al final, me gustaría agregar un ejemplo de la efectividad de la deduplicación en una copia de seguridad real de los archivos WAL de PostgreSQL en un entorno de producción:
borg@backup ~ $ borg info PROJECT-PG-WAL Repository ID: 177eeb28056a60487bdfce96cfb33af1c186cb2a337226bc3d5380a78a6aeeb6 Location: /mnt/borg/PROJECT-PG-WAL Encrypted: No Cache: /mnt/borg/.cache/borg/177eeb28056a60487bdfce96cfb33af1c186cb2a337226bc3d5380a78a6aeeb6 Security dir: /mnt/borg/.config/borg/security/177eeb28056a60487bdfce96cfb33af1c186cb2a337226bc3d5380a78a6aeeb6 ------------------------------------------------------------------------------ Original size Compressed size Deduplicated size All archives: 6.68 TB 6.70 TB 19.74 GB Unique chunks Total chunks Chunk index: 11708 3230099
Estos son 65 días de respaldo de los archivos WAL que se realizan cada hora. Al usar Bacula / Bareos, es decir sin deduplicación, obtendríamos 6,7 TB de datos. Solo piense: podemos permitirnos almacenar casi 7 terabytes de datos pasados a través de PostgreSQL, solo 20 GB de espacio realmente ocupado.
PS
Lea también en nuestro blog: