El desarrollo de software se considera un proceso poco medible, y parece que para administrarlo de manera efectiva, se necesita un toque especial. Y si la intuición con inteligencia emocional no está muy desarrollada, inevitablemente los términos cambiarán, la calidad del producto se hundirá y la velocidad de entrega disminuirá.
 Sergei Semenov
Sergei Semenov cree que esto sucede principalmente por dos razones.
- No existen herramientas y estándares para evaluar el trabajo de los programadores. Los gerentes deben recurrir a una evaluación subjetiva, que a su vez conduce a errores.
- No se utilizan medios de control automático de los procesos en el equipo. Sin un control adecuado, los procesos en los equipos de desarrollo dejan de cumplir sus funciones, ya que comienzan a ejecutarse parcialmente o simplemente se ignoran.
Y ofrece un enfoque para la evaluación y control de procesos basado en datos objetivos.
A continuación se muestra una versión en video y texto del informe de Sergey, que, según los resultados de la votación de la audiencia, ocupó el segundo lugar en
Saint TeamLead Conf .
Sobre el orador: Sergey Semenov ( sss0791 ) ha estado trabajando en TI durante 9 años, fue desarrollador, líder de equipo, gerente de producto, ahora CEO de GitLean. GitLean es un producto analítico para gerentes, directores técnicos y líderes de equipo, diseñado para tomar decisiones de gestión objetivas. La mayoría de los ejemplos en esta historia se basan no solo en la experiencia personal, sino también en la experiencia de las empresas clientes con personal de desarrollo de 6 a 200 personas.Ya con mi colega Alexander Kiselev hablamos sobre la
evaluación de los desarrolladores en febrero en la anterior TeamLead Conf. No me detendré en esto en detalle, pero me referiré a un artículo sobre algunas métricas. Hoy hablaremos sobre los procesos y cómo controlarlos y medirlos.
Fuentes de datos
Si hablamos de mediciones, sería bueno entender dónde obtener los datos. En primer lugar, tenemos:
- Git con información de código;
- Jira o cualquier otro rastreador de tareas con información sobre tareas;
- GitHub , Bitbucket, Gitlab con información de revisión de código.
Además, existe un mecanismo tan genial como la recopilación de varias evaluaciones subjetivas. Haré una reserva de que debe usarse sistemáticamente si queremos confiar en estos datos.

Por supuesto, la suciedad y el dolor te esperan en los datos; no hay nada que puedas hacer al respecto, pero esto no da tanto miedo. Lo más desagradable es que simplemente no puede haber datos sobre el trabajo de sus procesos en estas fuentes. Esto puede deberse a que los procesos se crearon para que no dejen ningún artefacto en los datos.
La primera regla que recomendamos seguir al diseñar y construir procesos es hacerlos para que dejen artefactos en los datos. Necesitas construir no solo Agile, sino hacerlo
ágil medible.
Le contaré la historia de horror que conocimos con uno de los clientes que nos llegó con una solicitud para mejorar la calidad del producto. Para que comprenda la escala, unos 30-40 errores de producción pasaron a un equipo de 15 desarrolladores por semana. Comenzaron a comprender los motivos y descubrieron que el 30% de las tareas no entraban en el estado de "prueba". Al principio, pensamos que era solo un error de datos, o los evaluadores no actualizaron el estado de la tarea. Pero resultó que realmente el 30% de las tareas simplemente no se prueban. Una vez que hubo un problema en la infraestructura, debido a que 1-2 tareas en la iteración no cayeron en la prueba. Luego, todos olvidaron este problema, los evaluadores dejaron de hablar sobre él y, con el tiempo, creció hasta llegar al 30%. Como resultado, esto condujo a más problemas globales.
Por lo tanto, la primera métrica importante para cualquier proceso es que deja datos. Asegúrate de seguir esto.

A veces, en aras de la mensurabilidad, tienes que sacrificar parte de los principios de Agile y, por ejemplo, en algún lugar prefieres la comunicación escrita a la oral.
La práctica de la fecha de vencimiento, que implementamos en varios equipos para mejorar la previsibilidad, demostró ser muy buena. Su esencia es la siguiente: cuando el desarrollador toma la tarea y la arrastra a "en progreso", debe establecer la fecha de vencimiento cuando la tarea se lanzará o estará lista para su lanzamiento. Esta práctica enseña al desarrollador a ser un administrador de microproyectos condicional de sus propias tareas, es decir, tener en cuenta las dependencias externas y comprender que la tarea está lista solo cuando el cliente puede usar su resultado.
Para que la capacitación tenga lugar, después de la fecha de vencimiento, el desarrollador debe ir a Jira y establecer una nueva fecha de vencimiento y dejar comentarios en un formulario especialmente dado, por qué sucedió esto. Parecería por qué se necesita esa burocracia. Pero, de hecho, después de dos semanas de esta práctica, descargamos todos esos comentarios de Jira con un guión simple y realizamos una retrospectiva con esta textura. Resulta una gran cantidad de ideas sobre por qué se rompen los plazos. Funciona muy bien, recomiendo usarlo.
Enfoque del problema
En la medición de procesos, profesamos el siguiente enfoque: debemos proceder de los problemas. Imaginamos algunas prácticas y procesos ideales, y luego somos creativos de qué manera pueden no funcionar.
Es necesario controlar la violación de los procesos , y no cómo seguimos alguna práctica. Los procesos a menudo no funcionan, no porque las personas los violen maliciosamente, sino porque el desarrollador y el administrador no tienen suficiente control y memoria para seguirlos a todos. Al rastrear las violaciones de las regulaciones, podemos recordarle automáticamente a las personas lo que hay que hacer, y obtenemos controles automáticos.
Para comprender qué procesos y prácticas necesita implementar, debe comprender por qué hacer esto en el equipo de desarrollo, qué necesita el negocio del desarrollo. Todos entienden que no se necesita mucho:
- que el producto se entrega por un período de pronóstico adecuado;
- que el producto era de calidad adecuada, no necesariamente perfecto;
- para que todo esto sea lo suficientemente rápido.
Es decir, la
previsibilidad, la calidad y la velocidad son importantes. Por lo tanto, analizaremos todos los problemas y métricas con precisión teniendo en cuenta cómo afectan la previsibilidad y la calidad. Apenas discutiremos la velocidad, debido a los casi 50 equipos con los que trabajamos de una forma u otra, solo dos podrían trabajar con la velocidad. Para aumentar la velocidad, debe poder medirla, de modo que sea al menos un poco predecible, y esto es previsibilidad y calidad.
Además de la previsibilidad y la calidad, presentamos una dirección como la
disciplina . Llamaremos disciplina a todo lo que garantice el funcionamiento básico de los procesos y la recopilación de datos, en base al cual se realiza un análisis de problemas de previsibilidad y calidad.
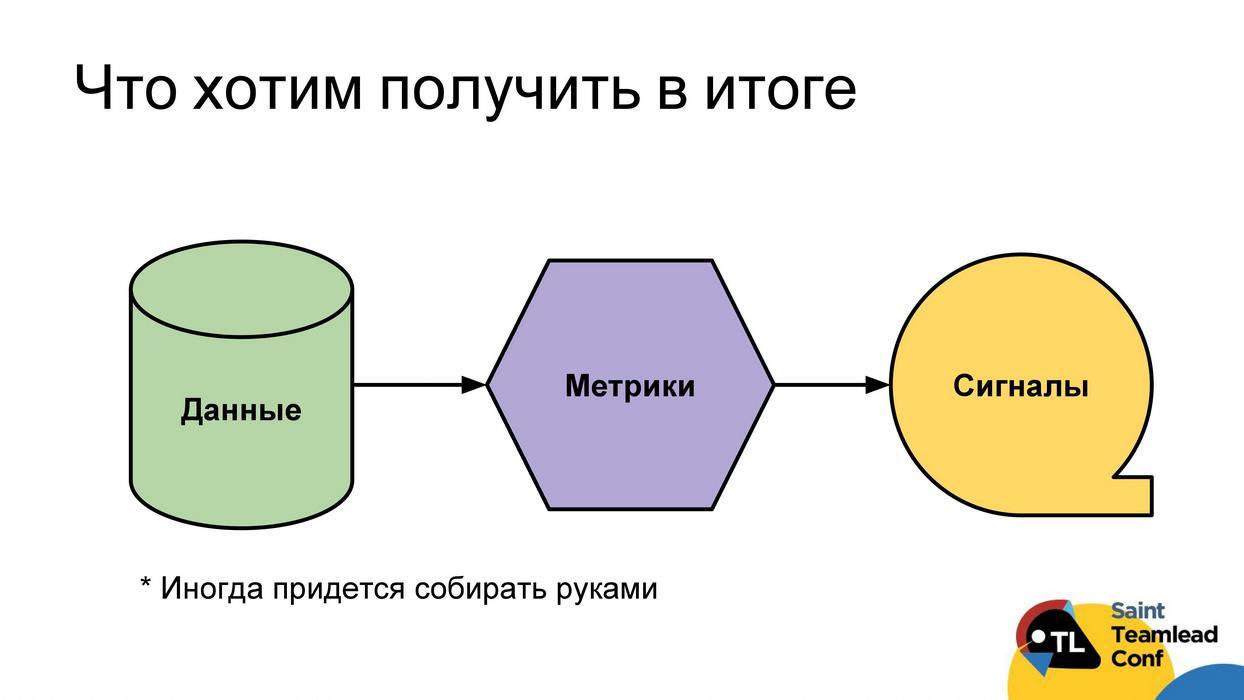
Idealmente, queremos construir el siguiente esquema de trabajo: para que tengamos una recopilación automática de datos; a partir de estos datos podríamos construir métricas; Usando métricas para encontrar problemas Informe los problemas directamente al desarrollador, líder del equipo o equipo. Entonces todos podrán responderles de manera oportuna y enfrentar los problemas encontrados. Debo decir de inmediato que no siempre es posible llegar a señales comprensibles. En ocasiones, las métricas seguirán siendo solo métricas que deberán analizarse, analizar valores, tendencias, etc. Incluso con los datos, a veces habrá un problema, a veces no se pueden recopilar automáticamente y debe hacerlo a mano (aclararé estos casos por separado).
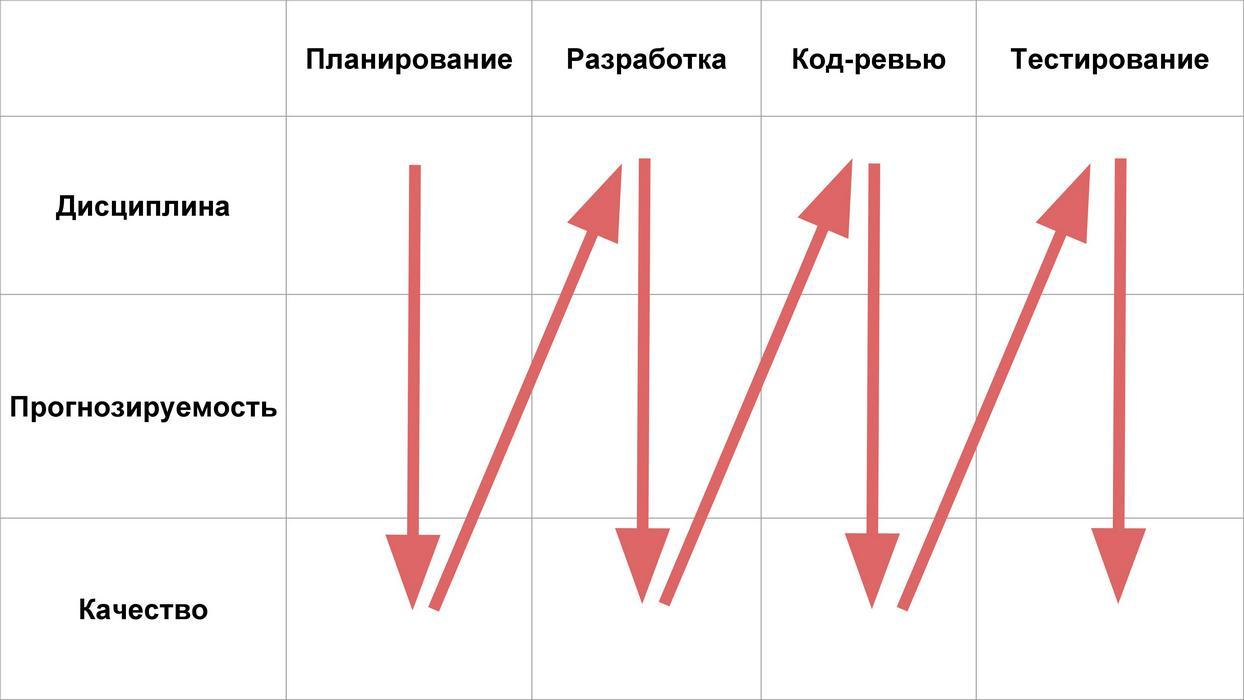
A continuación, consideramos 4 etapas de la vida útil de las características:
Y analizaremos qué problemas de disciplina, previsibilidad y calidad pueden existir en cada una de estas etapas.
Problemas de disciplina en la etapa de planificación.
Hay mucha información, pero presto atención a los puntos más básicos. Puede parecer bastante simple, pero se enfrentan a una gran cantidad de equipos.

El primer problema que surge a menudo durante la planificación es un
problema organizativo trivial: no todos los que deberían estar presentes están presentes en la reunión de planificación.
Ejemplo: un equipo se queja de que un probador está probando algo mal. Resulta que los probadores de este equipo nunca van a planificar en absoluto. O en lugar de sentarse y planear algo, el equipo busca frenéticamente un lugar para sentarse porque olvidaron reservar una sala de reuniones.
No es necesario configurar las métricas y las señales, solo asegúrese de no tener estos problemas. La reunión fue marcada en el calendario, todos fueron invitados, se tomó el lugar. No importa lo divertido que pueda parecer, esto se encuentra en diferentes equipos.
Ahora discutiremos situaciones en las que se necesitan señales y métricas. En la etapa de planificación, la mayoría de las señales de las que hablaré deben enviarse al equipo aproximadamente una hora después del final de la reunión de planificación, para no distraer al equipo en el proceso, pero aún así mantener el enfoque.
El primer problema disciplinario es
que las tareas no tienen descripción, o están mal descritas. Esto se controla de manera elemental. Hay un formato al que deben corresponder las tareas: verificamos si es así. Por ejemplo, seguimos que se establecen criterios de aceptación, o para tareas de front-end hay un enlace al diseño. También debe realizar un seguimiento de los componentes colocados, porque el formato de descripción a menudo está vinculado al componente. Para una tarea de fondo, una descripción es relevante; para una tarea de interfaz, otra.

El siguiente problema común es que las
prioridades se hablan oralmente o no se hablan en absoluto y no se reflejan en los datos . Como resultado, al final de la iteración, resulta que las tareas más importantes no se han realizado. Es necesario asegurarse de que el equipo use las prioridades y las use adecuadamente. Si un equipo tiene el 90% de las tareas en la iteración tienen alta prioridad, es lo mismo que ninguna prioridad.
Intentamos llegar a tal distribución: 20% de tareas de alta prioridad (no puede evitar descargar); 60% - prioridad media; 20% - baja prioridad (no da miedo si no lo lanzamos). Colgamos señales de todo esto.

El último problema con la disciplina, que ocurre en la etapa de planificación,
no hay
suficientes datos , incluidas las métricas posteriores. Las básicas: las tareas no tienen calificaciones (se debe hacer una señal) o los tipos de tareas son inadecuados. Es decir, los errores comienzan como tareas, y las tareas de la deuda técnica no se pueden rastrear en absoluto. Desafortunadamente, no es posible controlar automáticamente el segundo tipo de problemas. Le asesoramos solo una vez cada dos meses, especialmente si es CTO y tiene varios equipos, revise el trabajo atrasado y asegúrese de que las personas inicien errores como errores, historias como historias, tareas de deuda técnica como deuda técnica.
Problemas de previsibilidad en la etapa de planificación
Pasamos a los problemas de previsibilidad.

El problema básico es
que no estamos dentro de los plazos y las estimaciones , estamos
evaluando incorrectamente. Desafortunadamente, es imposible encontrar algún tipo de señal mágica o métrica que resuelva este problema. La única forma es alentar al equipo a aprender mejor, analizar las causas de los errores con una u otra evaluación utilizando ejemplos. Y este proceso de aprendizaje puede facilitarse por medios automáticos.
Lo primero que se puede hacer es ocuparse de tareas obviamente problemáticas con una alta estimación del tiempo de ejecución. Colgamos SLA y controlamos que todas las tareas estén lo suficientemente descompuestas. Recomendamos un máximo de dos días para que comience la ejecución, y luego puede pasar a un día.
El siguiente párrafo puede facilitar la recopilación de artefactos, en los cuales será posible realizar capacitación y analizar con el equipo por qué ocurrió un error con la evaluación. Recomendamos utilizar la práctica de fecha de vencimiento para esto. Ella ha demostrado ser muy buena aquí.
Otra forma es una métrica llamada código Churn como parte de la tarea. Su esencia es que miramos qué porcentaje del código en el marco de la tarea fue escrito, pero no estuvo a la altura del lanzamiento (más en el último
informe ). Esta métrica muestra cuán bien pensadas son las tareas. En consecuencia, sería bueno prestar atención a los problemas con los saltos de Churn y comprenderlos, lo que no tomamos en cuenta y por qué cometimos un error en la evaluación.

La siguiente historia es estándar: el equipo planeó algo, el sprint se llenó, pero al final
no hizo nada de lo que había planeado . Puede configurar señales para rellenar, cambiar prioridades, pero para la mayoría de los equipos con los que lo hicimos, eran irrelevantes. A menudo, estas son operaciones legales por parte del gerente de producto para lanzar algo al sprint, cambiar la prioridad, por lo que habrá muchos falsos positivos.
¿Qué se puede hacer aquí? Calcule métricas básicas bastante estándar: cierre del sprint scout inicial, número de lanzamientos en el sprint, cierre de los mismos lanzamientos, cambios de prioridad, vea la estructura de los lanzamientos. Después de eso, evalúe cuántas tareas y errores suele incluir en la iteración. Además, utilizando una señal para controlar que
está estableciendo esta cuota en la etapa de planificación .
Problemas de calidad en la etapa de planificación.
El primer problema: el
equipo no piensa en la funcionalidad de las funciones lanzadas . Hablaré de calidad en un sentido general: un problema de calidad es si el cliente dice que existe. Puede ser algún tipo de falla en el supermercado, o puede ser algo técnico.
Con respecto a los defectos de los alimentos, una métrica como la
rotación de 3 semanas funciona bien , revelando que 3 semanas después del lanzamiento de la tarea de rotación está por encima de lo normal. La esencia es simple: la tarea no se lanzó, y luego de tres semanas se eliminó un porcentaje suficientemente alto de su código. Aparentemente, la tarea no estaba muy bien implementada. Detectamos y analizamos estos casos con el equipo.

La segunda métrica es necesaria para los equipos que tienen problemas con errores, fallas y calidad. Proponemos construir un
gráfico del equilibrio de errores y fallas: cuántos errores hay en este momento, cuántos llegaron ayer, cuántos llegaron ayer. Puedes colgar un
monitor en
tiempo real justo en frente del equipo para que lo vea todos los días. Este excelente enfoca al equipo en temas de calidad. Los dos equipos y yo hicimos esto, y realmente comenzaron a pensar mejor en las tareas.

El siguiente problema estándar es
que el equipo no tiene tiempo para deudas técnicas . Esta historia se supervisa fácilmente si sigue el trabajo con tipos, es decir, las tareas de deuda técnica se evalúan y comienzan en Jira como tareas de deuda técnica. Podemos calcular qué tiempo se asignó la cuota de asignación al equipo técnico de deuda durante el trimestre. Si acordamos con el negocio que era del 20%, y gastamos solo el 10%, esto puede tenerse en cuenta y en el próximo trimestre dedicar más tiempo a la deuda técnica.
Problemas con la disciplina en desarrollo.
Ahora pasemos a la etapa de desarrollo. ¿Cuáles son los problemas con la disciplina?
Desafortunadamente, sucede que los
desarrolladores no hacen nada, o no podemos entender si están haciendo algo. Es fácil rastrear esto por dos signos banales:
- frecuencia de confirmaciones, al menos una vez al día;
- al menos una tarea activa en Jira.
Si esto no es así, entonces no es un hecho que deba vencer a las manos del desarrollador, sino que debe saberlo.
El segundo problema que puede derribar incluso a las personas más poderosas y al cerebro de incluso un desarrollador genial es el
procesamiento constante . Sería bueno si usted, como líder del equipo, supiera que una persona procesa: escribe un código o hace una revisión del código después de horas.
Varias reglas de Git también
pueden ser violadas . Lo primero que instamos a que sigan todos los comandos es especificar los prefijos de tareas del rastreador en los mensajes de confirmación, porque solo en este caso podemos vincular la tarea y el código. Aquí es mejor ni siquiera construir señales, sino configurar directamente git hook. Para cualquier regla git adicional que tenga, por ejemplo, no puede confirmar en master, también configuramos ganchos git.
Lo mismo se aplica a las prácticas acordadas. En la etapa de desarrollo, hay muchas prácticas que un desarrollador debe seguir. Por ejemplo, en el caso de la fecha de vencimiento, habrá tres señales:
- tareas para las que no se establece la fecha de vencimiento;
- tareas que han vencido la fecha de vencimiento;
- tareas para las que se ha cambiado la fecha de vencimiento pero no hay comentarios.
Las señales están sintonizadas para todo esto. También se pueden configurar cosas similares para cualquier otra práctica.
Problemas de previsibilidad en la etapa de desarrollo.
Muchas cosas pueden salir mal en los pronósticos en la etapa de desarrollo.
Una tarea puede quedarse en desarrollo durante mucho tiempo. Ya hemos tratado de resolver este problema en la etapa de planificación: descomponga las tareas con bastante precisión. Desafortunadamente, esto no siempre ayuda, y
hay tareas que se congelan . Para empezar, recomendamos simplemente configurar el SLA en “en progreso” para que haya una señal de que este SLA está siendo violado. Esto no le permitirá comenzar a liberar tareas más rápido en este momento, pero nuevamente le permitirá cobrar facturas, responder a esto y discutir con el equipo qué sucedió, por qué la tarea se cuelga durante tanto tiempo.
La previsibilidad puede verse afectada si
hay demasiadas tareas en un desarrollador . Es aconsejable verificar el número de tareas paralelas que el desarrollador realiza por código, y no por Jira, porque Jira no siempre refleja información relevante. Todos somos humanos, y si hacemos muchas tareas paralelas, entonces aumenta el riesgo de que algo salga mal en algún lugar.

El desarrollador puede tener algunos problemas de los que no habla, pero que son fáciles de identificar en función de los datos. Por ejemplo, ayer el desarrollador tuvo poca actividad de código. Esto no significa necesariamente que haya un problema, pero usted, como líder del equipo, puede venir y descubrirlo. Puede que esté atrapado y necesite ayuda, pero le da vergüenza preguntarle.
Otro ejemplo, el desarrollador, por el contrario, tiene algún tipo de gran tarea que sigue creciendo y creciendo en código. Esto también se puede detectar y posiblemente descomponer para que al final no haya problemas en la revisión del código o en la etapa de prueba.
Tiene sentido configurar la señal para garantizar que el código se reescriba muchas veces durante el trabajo en la tarea. Quizás los requisitos cambian constantemente o el desarrollador no sabe qué solución arquitectónica elegir. En los datos, es fácil de detectar y discutir con el desarrollador.Problemas de calidad durante el desarrollo
. , , .
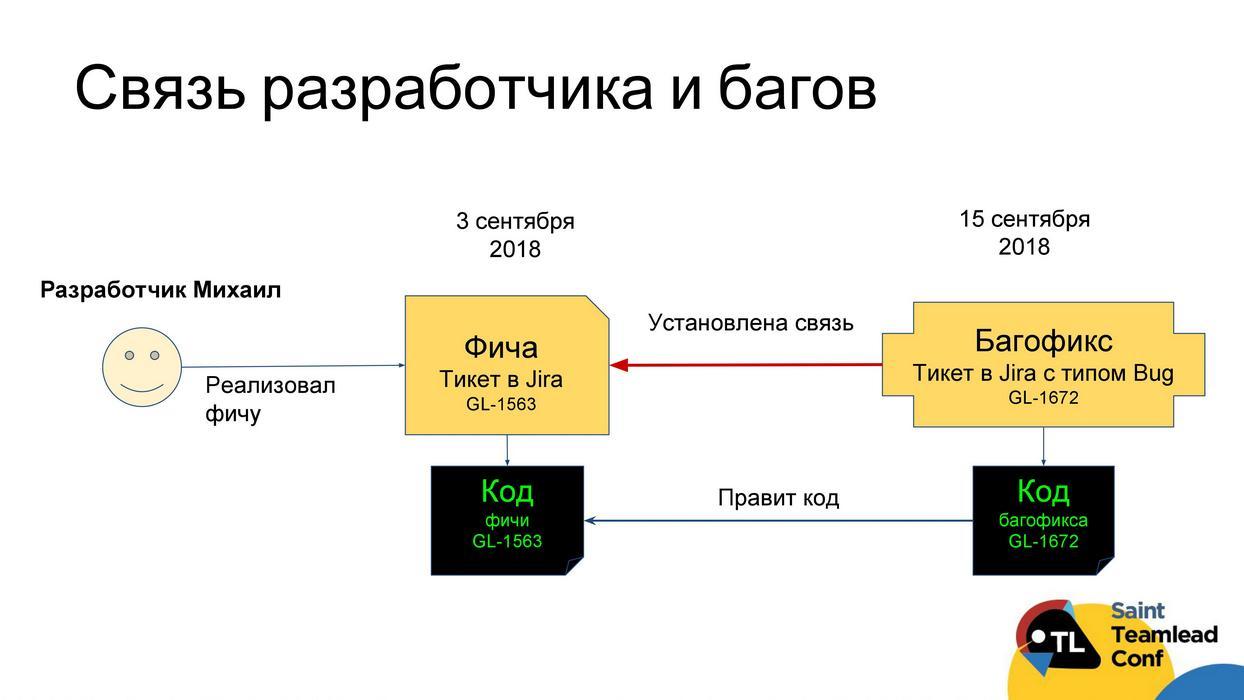
.
«» : , ; «»; «»; , bug fix. , , , , , — « ».
, , , , . , - , .
, , ,
, «» . , . ,
Legacy Refactoring , , , .
, —
SLA high-priority- . , . , , : high-priority critical .
, —
. -, . -, , . , .
-
Code review. ? , , — pull requests. -, pull request, . , , «in review», , Jira. , . , 2-3 , .

, , , pull request, . — , pull request ticket Jira .

, , , . pull requests, . , , : «, , - ». , . pull requests , , Jira.
pull request, , — , , - , - , , . .
, , — , , , , . : , « , ». , .

, , linter. , , - linter, - - , .
-
, SLA , , . , , .
SLA , "
- " — . , -. pull request .

,
- , . , CTO , , , . -. - , 6 50% - . , , 50%, CTO . , CTO - , 100%.
, — , - . :
, -.
-
, -. , .
100 . - 10 , - 1-2 . , .
— , , . , , , .

, , , , .
—
, - , . — churn -, .. pull request , .
,
- , , , . , commit, , -.

, - ( pull request ), - . , commit, . , .
. , — Jira. Jira. , «testing». task-tracker. , , - .

SLA . SLA , .
-, , , — . . , , ,
.

pipeline test- — , , , . build' , , — , . , 1-2 , , . , .
— . , . , , «» , , , , , .
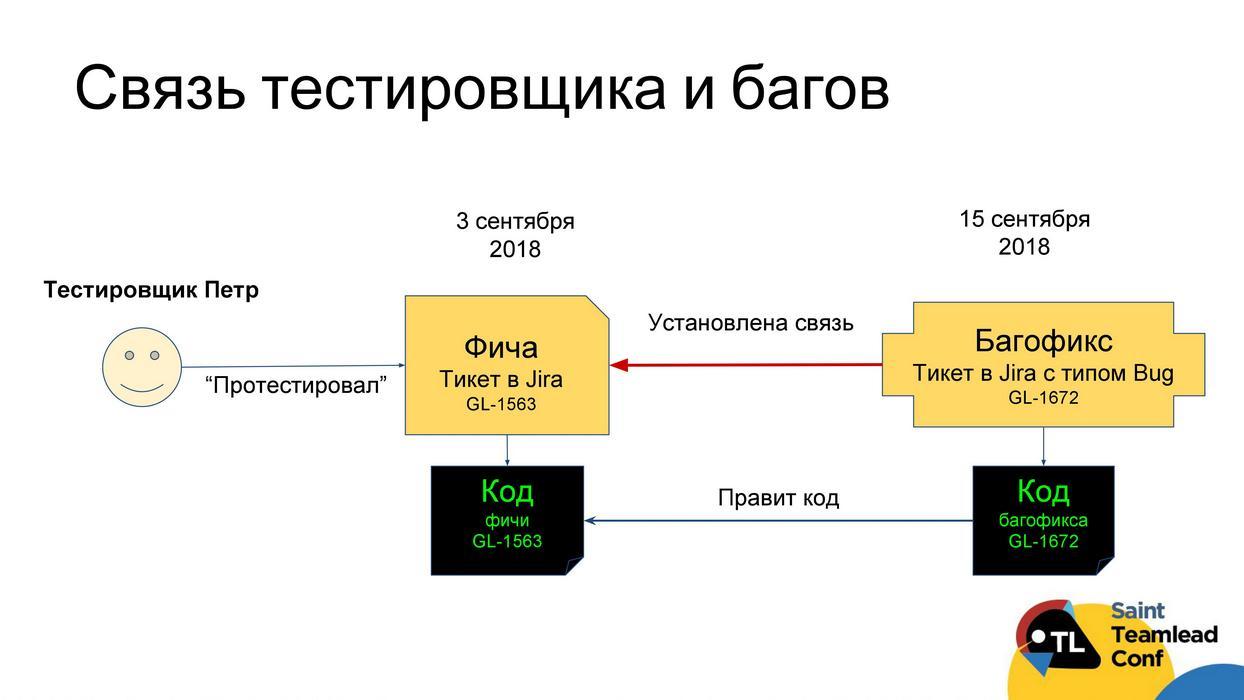
, , ,
. . , , , , . , , , . : , , , .

, «» , , . , , , .
 Otra historia que afecta la calidad de la fase de prueba es un ping-pong tan constante entre la prueba y el desarrollo . El probador simplemente devuelve la tarea al desarrollador, y él, a su vez, sin cambiar nada, la devuelve al probador. Puede verlo como una métrica o configurar la señal para tales tareas y observar de cerca lo que está sucediendo allí y si hay algún problema.
Otra historia que afecta la calidad de la fase de prueba es un ping-pong tan constante entre la prueba y el desarrollo . El probador simplemente devuelve la tarea al desarrollador, y él, a su vez, sin cambiar nada, la devuelve al probador. Puede verlo como una métrica o configurar la señal para tales tareas y observar de cerca lo que está sucediendo allí y si hay algún problema.Metodologia Metrica
Hablamos de métricas, y ahora la pregunta es: ¿cómo trabajar con todo esto? Solo dije las cosas más básicas, pero incluso muchas de ellas. ¿Qué hacer con todo esto y cómo usarlo?
Recomendamos que automatice este proceso al máximo y entregue todas las señales al equipo a través de un bot en mensajería instantánea. Probamos diferentes canales de comunicación: correo electrónico y panel de control, no funciona muy bien. El bot ha demostrado ser el mejor. Puede escribir un bot usted mismo, puede tomar OpenSource de alguien, puede comprarnos.
El punto aquí es muy simple: el equipo reacciona con mucha más calma a las señales del bot que al gerente, quien indica problemas. Si es posible, entregue la mayoría de las señales directamente al desarrollador primero, luego al equipo, si el desarrollador no responde, por ejemplo, dentro de uno o dos días.

No es necesario intentar construir todas las señales a la vez. La mayoría de ellos simplemente no funcionará, porque no tendrá datos, debido a problemas triviales con la disciplina. Por lo tanto, primero establecemos disciplina y establecemos señales para prácticas disciplinarias. Según la experiencia de los equipos con los que hablamos, tomó un año y medio simplemente desarrollar disciplina en el equipo de desarrollo sin automatización. Con la automatización, con la ayuda de señales constantes, el equipo comienza a trabajar normalmente de manera disciplinada en algún lugar después de un par de meses, es decir, mucho más rápido.
Cualquier señal que haga pública, o directamente al desarrollador, en ningún caso puede simplemente levantarla y encenderla. Primero debe coordinar esto con el desarrollador, hablar con él y el equipo. Es aconsejable ingresar por escrito todos los valores de umbral en un Acuerdo de equipo, los motivos por los que está haciendo esto, cuáles serán los próximos pasos, etc.

Debe tenerse en cuenta que todos los procesos tienen excepciones, y tener esto en cuenta en la etapa de diseño.
No estamos construyendo un campo de concentración para desarrolladores donde sea imposible dar un paso a la derecha, un paso a la izquierda. Todos los procesos tienen una excepción, solo queremos saber sobre ellos. Si el bot constantemente jura sobre alguna tarea que realmente no se puede descomponer, y que lleva 5 días para trabajar, debe colocar una marca de "no seguimiento" para que el bot tenga esto en cuenta. Usted, como gerente, puede monitorear por separado la cantidad de tareas de "no seguimiento" y, por lo tanto, comprender cuán buenos son esos procesos y las señales que genera. Si el número de tareas etiquetadas como "sin seguimiento" está creciendo constantemente, entonces, desafortunadamente, esto significa que las señales y los procesos que usted inventó son difíciles para el equipo, no puede seguirlos y es más fácil evitarlos.
 El control manual aún permanece
El control manual aún permanece . No funcionará encender el bot y marcharse a algún lugar de Bali, aún tiene que lidiar con cada situación. Recibió algún tipo de señal, la persona no respondió; tendrá que averiguar el motivo en un día o dos, hablar sobre el problema y encontrar una solución.
Para optimizar este proceso, recomendamos introducir una práctica como un
asistente de proceso . Esta es una posición de transición de una persona (una vez a la semana) que comprende los problemas que señala el bot. Y usted, como líder del equipo, ayuda al asistente a lidiar con estos problemas, es decir, supervisarlo. Por lo tanto, el desarrollador aumenta la motivación para trabajar con este producto. Entiende sus beneficios, porque ve cómo se pueden resolver estos problemas y cómo reaccionar ante ellos. Por lo tanto, reduce su singularidad al equipo y
acerca el momento en que el equipo se vuelve autónomo , y aún puede ir a Bali.
ConclusionesRecopilar datos. Cree procesos para que tenga datos recopilados. Incluso si no desea crear métricas y señales ahora, puede hacer un análisis retrospectivo en el futuro si comienza a recopilarlas ahora.
Controlar automáticamente los procesos. Al diseñar procesos, siempre piense en cómo puede hackearlos y cómo puede reconocer tales hacks a partir de los datos.
Cuando las señales son pocas durante varias semanas, ¡bien hecho! Nos enfrentamos con el hecho de que cuando el equipo ve que hay menos señales, y parece que la situación está mejorando, comienza a encontrar frenéticamente algunas otras prácticas, comienza a implementar algo para ver estos paquetes de señales nuevamente. Esto no siempre es necesario, tal vez si hay menos señales: todo está bien para usted, el equipo comenzó a trabajar de la manera que quería desde el principio, y ya está :)
Ven y comparte tus hallazgos de Timlid en TeamLead Conf . La conferencia de febrero se llevará a cabo en Moscú y Call for Papers ya está abierta .
¿Quieres experimentar la experiencia de otras personas? Suscríbase a nuestro boletín de gestión para recibir noticias sobre el programa y no se pierda el tiempo de negociar entradas para la conferencia.