En la continuación de la "
reunión informativa " con HighLoad ++ 2017, preparamos una breve revisión de los cinco mejores (según los participantes de la conferencia) informes en inglés.
Se otorgaron las mejores calificaciones a los temas relacionados con el uso de ProxySQL (en el TOP 5 había dos informes sobre esta herramienta), las pruebas de aplicaciones en la nube pública de Amazon, así como los principios de inicio de sesión en una escala cuando esto se convierte en un problema y el monitoreo de Apache Kafka.
Acabamos de publicar videos de todos los informes de HighLoad ++ 2017 para acceso gratuito. Una lista completa de 150 informes en nuestro canal de YouTube en esta lista de reproducción .
Además de esta lista de reproducción, el canal tiene varios cientos de videos sobre bases de datos, arquitecturas, escalado, colas, aprendizaje automático y otra sabiduría de alta carga :)
Medición de la variabilidad del rendimiento de EC2
Henrik Ingo (Arquitecto de soluciones MongoDB, y ahora ingeniero de productividad líder en Mongo DB).El primer informe, señalado por los participantes, argumenta que la nube pública puede usarse para probar sus propios productos, incluidas las pruebas de carga. En este caso, el DBMS MongoDB, que se está probando con la nube de Amazon, fue el "experimental". En total, se gastan alrededor de 400 mil horas en esta tarea por mes, aproximadamente el 5% de este tiempo son solo pruebas de rendimiento, cuya tarea principal ni siquiera es proporcionar optimización, y no permitir la "subsidencia" como resultado de algunas modificaciones.
La pregunta clave de la presentación es cómo obtener resultados de prueba reproducibles en la nube pública.
El informe se basa en el principio del análisis de hipótesis. Inicialmente, Henrik Ingo hace suposiciones sobre qué factores deberían influir en el nivel de "ruido" en las pruebas (el concepto mismo de "ruido" en el informe tiene una definición muy específica). Por ejemplo, el equipo de pruebas expresó la idea de que en las pruebas "pesadas" el "ruido" principal proviene del disco duro, o que en la nube, al distribuir recursos, puede encontrarse con buenos (totalmente asignados) o malos (compartidos con por alguien) instancias que afectan los resultados de la prueba.
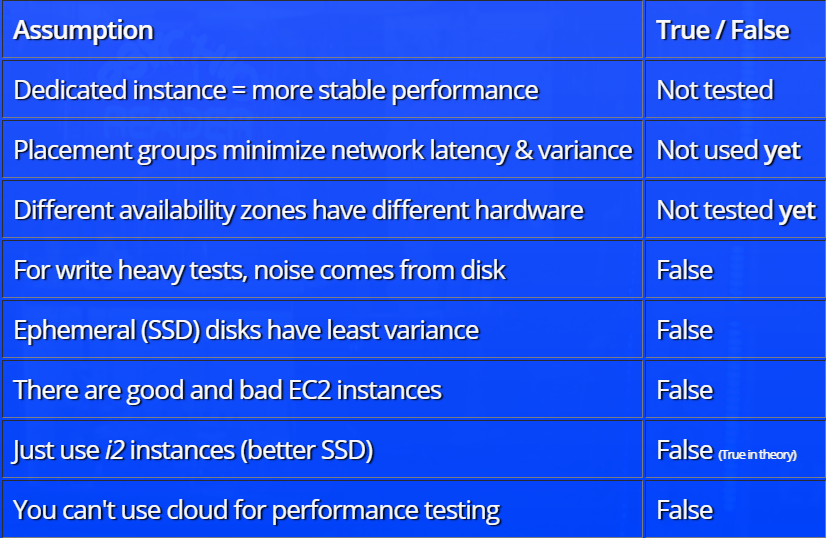
Después de eso, se analizan los resultados de probar cada una de las teorías con una demostración de algunas dependencias interesantes. Por ejemplo, aquí hay un gráfico de la dependencia del nivel de "ruido" (en la terminología del informe) de la configuración de instancia seleccionada:
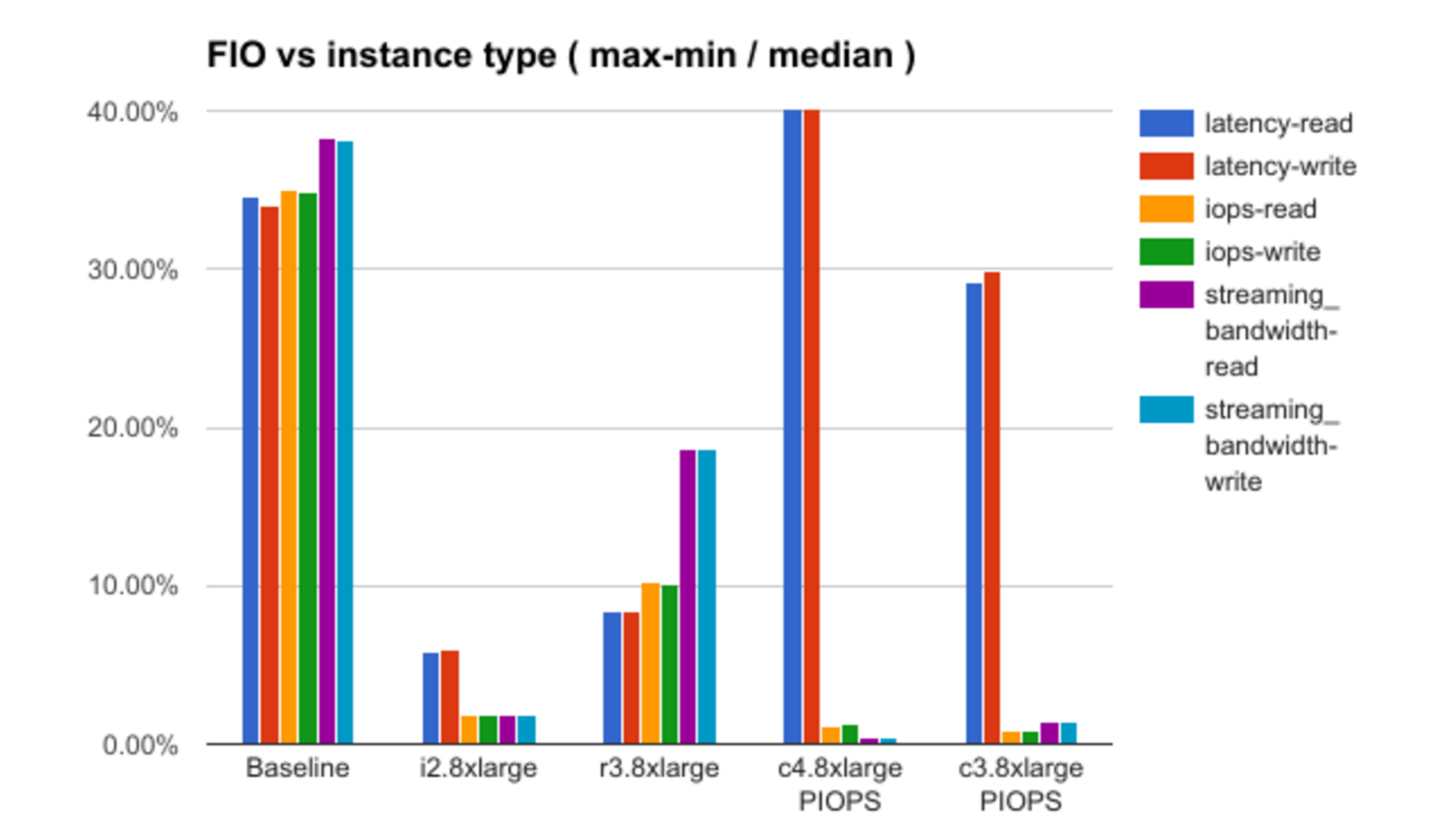
Por falta de información sobre los detalles de la infraestructura de Amazon, el informe no responde a todas las preguntas, en algunos casos solo hace suposiciones, pero hay algo en lo que pensar.
Tala y despotricar
Vytis Valentinavičius (Lamoda, líder de operaciones)El siguiente informe interesante es el pensamiento de un especialista en una gran tienda en línea de Lamoda sobre el registro y cómo debería ser para que los desarrolladores, por un lado, reciban los datos necesarios en su totalidad y, por otro lado, no se ahoguen en gigabytes de información entrante. Y el orador sabe de lo que está hablando. El problema que comenzó a construir el trabajo con registros en Lamoda es la pérdida del 5% de los informes enviados por los usuarios a través de UDP (en algunos casos, este porcentaje alcanzó el 100%). Esto distorsionó seriamente todas las métricas que podrían construirse sobre su base.
El informe explica cómo no desentrañar tal situación, sino cómo prevenirla, en principio, dado que muchas soluciones obvias tienen sus trampas.
Vytis Valentinavičius se centra en el hecho de que el registro debe tener una estructura. Pero al mismo tiempo no se puede inflar. Debe haber un propósito para recopilar y almacenar cada campo, ya que cualquier información recopilada es dinero. Un ejemplo de Lamoda son 25 mil mensajes de registro de depuración por segundo (32 TB de información por semana, para los cuales el almacenamiento solo cuesta $ 12 mil).
Además, es importante rastrear eventos, no errores específicos. Deben agregarse, identificarse las métricas y basarse en su análisis para crear eventos más complejos para la agregación futura.
Además de las consideraciones teóricas, el informe describe algunos de los trucos que Lamoda utilizó en la producción para trabajar con troncos.
Las métricas no son suficientes: monitoreo de Apache Kafka
Gwen Shapira (Confluente, gerente de producto)El siguiente informe trata sobre el monitoreo de Apache Kafka, o mejor dicho, qué métricas deben seleccionarse de la abundancia de parámetros disponibles para el análisis para comprender el estado del agente de mensajes en cualquier momento.
La oradora comenzó su historia con una broma, en la que, como dicen, solo hay una fracción de la broma: "Incluso si no puede recordar el contenido de todo el informe, recuerde una cosa: si Kafka se usa en la producción, debe ser monitoreado" (bueno, se proporciona la API correspondiente para esto )
¿Es necesario monitorear todo? Depende de la tarea. Es de ellos a quienes Gwen Shapira repele, analizando las métricas recomendadas. El orador describe los casos operativos estándar y recomienda los parámetros que deben agregarse al tablero para responder a lo que sucede a tiempo y cómo no agravar la situación. En particular, una vez más recuerda que no es necesario reiniciar el intermediario en el primer cambio de métricas, porque lleva mucho tiempo y, a veces (debido a errores conocidos) puede tener consecuencias más graves. En definitiva, las métricas son solo datos iniciales. Y para tomar decisiones, uno debe tener hipótesis basadas en estos datos.

Gracias a la vasta experiencia de Gwen Shapira como consultora, toda la presentación se acompaña de vívidos ejemplos de la vida.
Escenarios de casos de uso de ProxySQL
Alkin Tezuysal (Percona, equipo global de DBA)Dos informes inmediatos, que, según las estimaciones de los participantes, estaban en el TOP 5, se relacionan con ProxySQL, un medio de enviar consultas SQL a MySQL (y, más recientemente, ClickHouse).
El primer informe generalmente trata sobre escenarios para usar esta herramienta.
ProxySQL es una solución de código abierto, hasta ahora no hemos encontrado una quinta esencia de experiencia. Sí, muchas compañías descargan esta solución, pero incluso el propio fabricante no siempre comprende quién la usará y en qué escala. Los escenarios recopilados en este informe se identificaron como resultado de la comunicación con los usuarios de ProxySQL y el análisis de sus casos.
En general, ProxySQL le permite resolver una gran cantidad de tareas, desde el equilibrio de carga y la reescritura de consultas (que se discutirán en el próximo informe de nuestra lista), hasta la cola de consultas y el calentamiento de la memoria caché, que no está en MySQL. Cada una de las opciones de Alkin Tezuysal analiza en detalle, mencionando las ventajas y desventajas de la solución, así como los casos especiales en los que puede ser útil.
Aquí mencionamos solo dos ejemplos con respecto a la optimización de la base de datos.
Ejemplo 1: uso de ProxySQL para reducir el número de solicitudes para establecer una conexión de aplicación a la base de datos. La idea se refleja gráficamente en el gráfico dado en el informe:
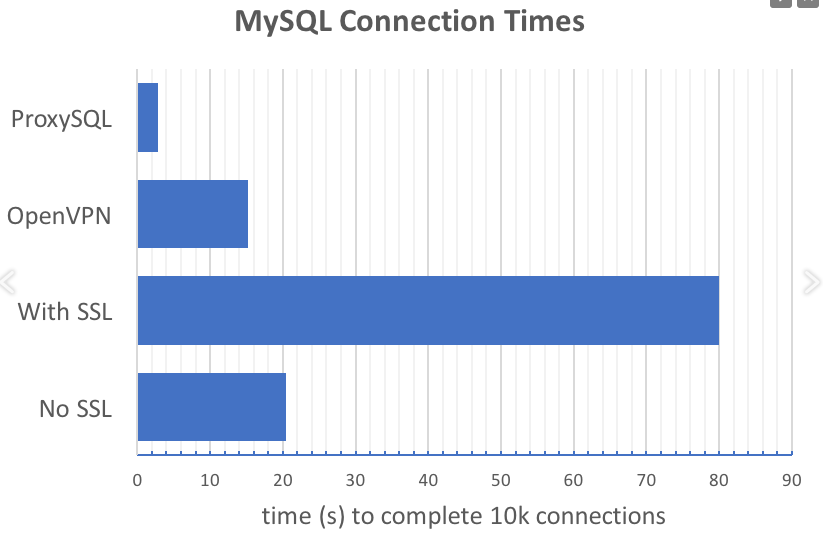
ProxySQL reduce drásticamente la cantidad de solicitudes de conexión, especialmente cuando se usa SSL.
Ejemplo 2: filtrado de consultas inútiles (como SELECT 1, manifestadas en aplicaciones a gran escala) que ralentizan la base de datos. Aquí, el resultado también se evalúa mejor gráficamente:

Enmascaramiento de datos de bajo costo para MySQL con ProxySQL - Anonimización de datos para desarrolladores
Rene Cannao (fundador y propietario del producto ProxySQL)El segundo informe en inglés sobre ProxySQL, que entró en el TOP-5, está dedicado a resolver un problema muy específico: el enmascaramiento de datos.
Después de una breve introducción a ProxySQL para aquellos que no han visto el primer informe, el orador se sumerge en las capacidades de la herramienta para resolver un problema específico: ocultar (reemplazar con asteriscos) parte del nombre o reemplazar la cantidad real de ingresos por uno falso.
Como señala el orador, este problema se puede resolver utilizando sus propios medios de MySQL o productos de terceros. Entre ProxySQL de terceros está lejos de ser la única herramienta. Sin embargo, si bien no existe una solución ideal en el mercado, y ProxySQL no es peor que muchos, lo que permite a los desarrolladores obtener datos válidos para pruebas que no contienen información personal real. Además, tiene código fuente abierto.
Si la primera historia sobre ProxySQL fue más teórica, entonces aquí hay una práctica continua. Incluso se enumeran las reglas configuradas mediante expresiones regulares.

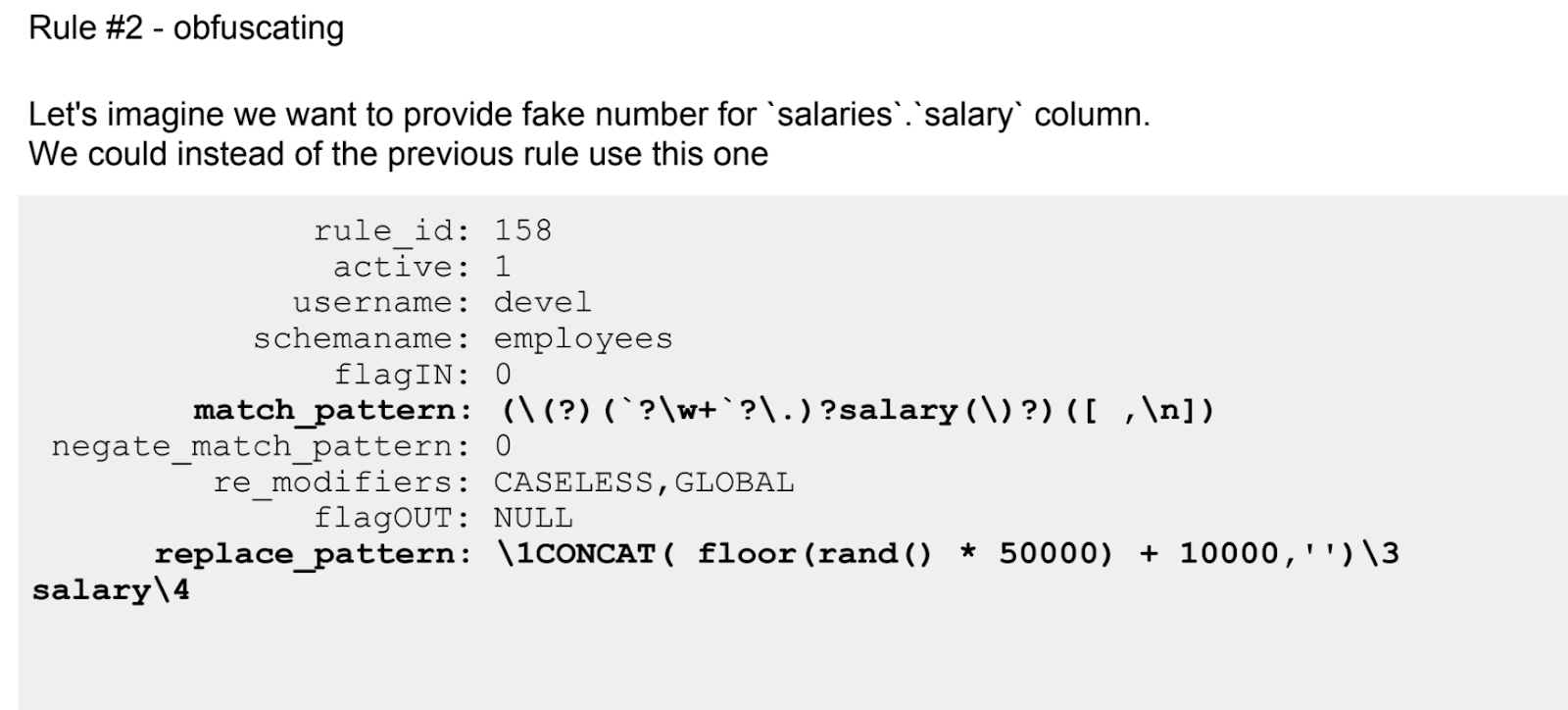
Como cualquier herramienta proxySQL tiene sus limitaciones. Esto también será discutido. En particular, este no es el mejor enfoque para transformaciones complejas.
El informe finalizó con una sección completa de preguntas y respuestas, de la que también puede aprender muchas cosas útiles e interesantes.
Por supuesto, estos cinco de habla inglesa son solo la punta del iceberg que estaba en HighLoad ++ 2017. Por lo tanto, recordamos que acabamos de publicar videos de todos los informes de la conferencia que se pueden encontrar en
esta lista de reproducción .
HighLoad ++ 2018 se llevará a cabo los días 8 y 9 de noviembre en Moscú, en Skolkovo. El trabajo en el programa ya está en marcha, pero el informe puede presentarse antes del 1 de septiembre.