
Creo que un poco de tonterías el martes no perjudicará la semana laboral. Tengo un pasatiempo, en mi tiempo libre trato de descubrir cómo hackear el algoritmo de minería de bitcoin, evitar búsquedas estúpidas sin sentido y encontrar una solución al problema de coincidencia de hash con un consumo mínimo de energía. Debo decir de inmediato el resultado, por supuesto, aún no lo he logrado, pero sin embargo, ¿por qué no exponer por escrito las ideas que nacen en la cabeza? En algún lugar necesitan ser puestos ...
A pesar del delirio de las ideas a continuación, creo que este artículo puede ser útil para alguien que está estudiando
- Lenguaje C ++ y sus plantillas
- algunos circuitos digitales
- un poco de teoría de probabilidad y aritmética probabilística
- algoritmo de hash de bitcoin en detalle
Por donde empezamos
¿Quizás del último y más aburrido elemento de esta lista? Paciencia, entonces será más divertido.
Consideremos en detalle el algoritmo para calcular la función hash de bitcoin. Es simple F (x) = sha256 (sha256 (x)), donde x es la entrada de 80 bytes, el encabezado del bloque junto con el número de versión del bloque, hash del bloque anterior, raíz de merkle, marca de tiempo, bits y nonce. Aquí hay ejemplos de encabezados de bloque bastante recientes que se pasan a la función hash:
Este conjunto de bytes es un material bastante valioso, ya que a menudo no es fácil para los mineros averiguar en qué orden deben seguir los bytes al formar el encabezado, a menudo invirtiendo los lugares de los bytes bajos y altos (endianos).
Entonces, desde el encabezado del bloque, 80 bytes se consideran el hash sha256 y luego del resultado otro sha256.
El algoritmo sha256 en sí mismo, si observa diferentes fuentes, generalmente consta de cuatro funciones:
- nulo sha256_init (SHA256_CTX * ctx);
- vacío sha256_transform (SHA256_CTX * ctx, datos BYTE constantes []);
- vacío sha256_update (SHA256_CTX * ctx, const BYTE data [], size_t len);
- nulo sha256_final (SHA256_CTX * ctx, BYTE hash []);
La primera función que se llama al calcular el hash es sha256_init (), que restaura la estructura SHA256_CTX. No hay nada especial allí excepto ocho palabras de estado de 32 bits, que inicialmente se llenan con palabras especiales:
void sha256_init(SHA256_CTX *ctx) { ctx->datalen = 0; ctx->bitlen = 0; ctx->state[0] = 0x6a09e667; ctx->state[1] = 0xbb67ae85; ctx->state[2] = 0x3c6ef372; ctx->state[3] = 0xa54ff53a; ctx->state[4] = 0x510e527f; ctx->state[5] = 0x9b05688c; ctx->state[6] = 0x1f83d9ab; ctx->state[7] = 0x5be0cd19; }
Supongamos que tenemos un archivo cuyo hash necesita ser calculado. Leemos el archivo con bloques de tamaño arbitrario y llamamos a la función sha256_update () donde pasamos el puntero a los datos del bloque y la longitud del bloque. La función acumula el hash en la estructura SHA256_CTX en la matriz de estado:
void sha256_update(SHA256_CTX *ctx, const BYTE data[], size_t len) { uint32_t i; for (i = 0; i < len; ++i) { ctx->data[ctx->datalen] = data[i]; ctx->datalen++; if (ctx->datalen == 64) { sha256_transform(ctx, ctx->data); ctx->bitlen += 512; ctx->datalen = 0; } } }
Por sí solo, sha256_update () llama a la función de caballo de batalla sha256_transform (), que ya acepta bloques de solo una longitud fija de 64 bytes:
#define ROTLEFT(a,b) (((a) << (b)) | ((a) >> (32-(b)))) #define ROTRIGHT(a,b) (((a) >> (b)) | ((a) << (32-(b)))) #define CH(x,y,z) (((x) & (y)) ^ (~(x) & (z))) #define MAJ(x,y,z) (((x) & (y)) ^ ((x) & (z)) ^ ((y) & (z))) #define EP0(x) (ROTRIGHT(x,2) ^ ROTRIGHT(x,13) ^ ROTRIGHT(x,22)) #define EP1(x) (ROTRIGHT(x,6) ^ ROTRIGHT(x,11) ^ ROTRIGHT(x,25)) #define SIG0(x) (ROTRIGHT(x,7) ^ ROTRIGHT(x,18) ^ ((x) >> 3)) #define SIG1(x) (ROTRIGHT(x,17) ^ ROTRIGHT(x,19) ^ ((x) >> 10)) /**************************** VARIABLES *****************************/ static const uint32_t k[64] = { 0x428a2f98,0x71374491,0xb5c0fbcf,0xe9b5dba5,0x3956c25b,0x59f111f1,0x923f82a4,0xab1c5ed5, 0xd807aa98,0x12835b01,0x243185be,0x550c7dc3,0x72be5d74,0x80deb1fe,0x9bdc06a7,0xc19bf174, 0xe49b69c1,0xefbe4786,0x0fc19dc6,0x240ca1cc,0x2de92c6f,0x4a7484aa,0x5cb0a9dc,0x76f988da, 0x983e5152,0xa831c66d,0xb00327c8,0xbf597fc7,0xc6e00bf3,0xd5a79147,0x06ca6351,0x14292967, 0x27b70a85,0x2e1b2138,0x4d2c6dfc,0x53380d13,0x650a7354,0x766a0abb,0x81c2c92e,0x92722c85, 0xa2bfe8a1,0xa81a664b,0xc24b8b70,0xc76c51a3,0xd192e819,0xd6990624,0xf40e3585,0x106aa070, 0x19a4c116,0x1e376c08,0x2748774c,0x34b0bcb5,0x391c0cb3,0x4ed8aa4a,0x5b9cca4f,0x682e6ff3, 0x748f82ee,0x78a5636f,0x84c87814,0x8cc70208,0x90befffa,0xa4506ceb,0xbef9a3f7,0xc67178f2 }; /*********************** FUNCTION DEFINITIONS ***********************/ void sha256_transform(SHA256_CTX *ctx, const BYTE data[]) { uint32_t a, b, c, d, e, f, g, h, i, j, t1, t2, m[64]; for (i = 0, j = 0; i < 16; ++i, j += 4) m[i] = (data[j] << 24) | (data[j + 1] << 16) | (data[j + 2] << 8) | (data[j + 3]); for (; i < 64; ++i) m[i] = SIG1(m[i - 2]) + m[i - 7] + SIG0(m[i - 15]) + m[i - 16]; a = ctx->state[0]; b = ctx->state[1]; c = ctx->state[2]; d = ctx->state[3]; e = ctx->state[4]; f = ctx->state[5]; g = ctx->state[6]; h = ctx->state[7]; for (i = 0; i < 64; ++i) { t1 = h + EP1(e) + CH(e, f, g) + k[i] + m[i]; t2 = EP0(a) + MAJ(a, b, c); h = g; g = f; f = e; e = d + t1; d = c; c = b; b = a; a = t1 + t2; } ctx->state[0] += a; ctx->state[1] += b; ctx->state[2] += c; ctx->state[3] += d; ctx->state[4] += e; ctx->state[5] += f; ctx->state[6] += g; ctx->state[7] += h; }
Cuando se haya leído todo el archivo hash y ya se haya transferido a la función sha256_update (), todo lo que queda es llamar a la función sha256_final () final, que si el tamaño del archivo no era un múltiplo de 64 bytes, agregará bytes de relleno adicionales, escribirá la longitud total de datos al final del último bloque de datos y hará el sha256_transform final ().
El resultado hash permanece en la matriz de estado.
Este es el "alto nivel", por así decirlo.
En relación con el minero de Bitcoin, por supuesto, los desarrolladores piensan cómo considerarlos más pequeños y más eficientes.
Es simple: el encabezado contiene solo 80 bytes, que no es un múltiplo de 64 bytes. Por lo tanto, sería necesario que el primer sha256 hiciera dos sha256_transform () ya. Sin embargo, afortunadamente para los mineros, el nonce del bloque está al final del encabezado, por lo que el primer sha256_transform () solo se puede ejecutar una vez; este será el llamado estado intermedio. A continuación, el minero pasa por todas las opciones sin sentido, que son 4 mil millones, 2 ^ 32 y las sustituye en el campo correspondiente por el segundo sha256_transform (). Esta transformación completa la primera función sha256. Su resultado son ocho palabras de 32 bits, es decir, 32 bytes. Es fácil encontrar sha256 de ellos: se llama al sha256_transform () final y todo está listo. Tenga en cuenta que los datos de entrada son 32 bytes más pequeños que los 64 bytes necesarios para sha256_transform (). Entonces, nuevamente, el bloque se rellenará con ceros y la longitud del bloque se ingresará al final.
En total, solo hay tres llamadas a sha256_transform () de las cuales la primera debe leerse solo una vez para calcular el estado medio.
Traté de expandir todas las manipulaciones de datos que ocurren al calcular el hash del encabezado de un bloque de bitcoin en una sola función, para que quede claro cómo ocurre todo el cálculo específicamente para bitcoin y esto es lo que sucedió:
Implementé esta función como una plantilla de c ++, puede operar no solo con palabras de 32 bits, digamos uint32_t, sino también con palabras de un tipo diferente "T" de la misma manera. Tengo aquí y el estado sha256 se almacena como una matriz de tipo "T" y sha256_transform () se llama con un puntero de parámetro a una matriz de tipo "T" y el resultado se devuelve igual. La función de transformación ahora también tiene la forma de una plantilla de c ++:
template <typename T> T ror32(T word, unsigned int shift) { return (word >> shift) | (word << (32 - shift)); } template <typename T> T Ch(T x, T y, T z) { return z ^ (x & (y ^ z)); } template<typename T> T Maj(T x, T y, T z) { return (x & y) | (z & (x | y)); } #define e0(x) (ror32(x, 2) ^ ror32(x,13) ^ ror32(x,22)) #define e1(x) (ror32(x, 6) ^ ror32(x,11) ^ ror32(x,25)) #define s0(x) (ror32(x, 7) ^ ror32(x,18) ^ (x >> 3)) #define s1(x) (ror32(x,17) ^ ror32(x,19) ^ (x >> 10)) unsigned int ntohl(unsigned int in) { return ((in & 0xff) << 24) | ((in & 0xff00) << 8) | ((in & 0xff0000) >> 8) | ((in & 0xff000000) >> 24); } template <typename T> void LOAD_OP(int I, T *W, const u8 *input) { //W[I] = /*ntohl*/ (((u32*)(input))[I]); W[I] = ntohl(((u32*)(input))[I]); //W[I] = (input[3] << 24) | (input[2] << 16) | (input[1] << 8) | (input[0]); } template <typename T> void BLEND_OP(int I, T *W) { W[I] = s1(W[I - 2]) + W[I - 7] + s0(W[I - 15]) + W[I - 16]; } template <typename T> void sha256_transform(T *state, const T *input) { T a, b, c, d, e, f, g, h, t1, t2; TW[64]; int i; /* load the input */ for (i = 0; i < 16; i++) // MJ input is cast to u32* so this processes 16 DWORDS = 64 bytes W[i] = input[i]; /* now blend */ for (i = 16; i < 64; i++) BLEND_OP(i, W); /* load the state into our registers */ a = state[0]; b = state[1]; c = state[2]; d = state[3]; e = state[4]; f = state[5]; g = state[6]; h = state[7]; // t1 = h + e1(e) + Ch(e, f, g) + 0x428a2f98 + W[0]; t2 = e0(a) + Maj(a, b, c); d += t1; h = t1 + t2; t1 = g + e1(d) + Ch(d, e, f) + 0x71374491 + W[1]; t2 = e0(h) + Maj(h, a, b); c += t1; g = t1 + t2; t1 = f + e1(c) + Ch(c, d, e) + 0xb5c0fbcf + W[2]; t2 = e0(g) + Maj(g, h, a); b += t1; f = t1 + t2; t1 = e + e1(b) + Ch(b, c, d) + 0xe9b5dba5 + W[3]; t2 = e0(f) + Maj(f, g, h); a += t1; e = t1 + t2; t1 = d + e1(a) + Ch(a, b, c) + 0x3956c25b + W[4]; t2 = e0(e) + Maj(e, f, g); h += t1; d = t1 + t2; t1 = c + e1(h) + Ch(h, a, b) + 0x59f111f1 + W[5]; t2 = e0(d) + Maj(d, e, f); g += t1; c = t1 + t2; t1 = b + e1(g) + Ch(g, h, a) + 0x923f82a4 + W[6]; t2 = e0(c) + Maj(c, d, e); f += t1; b = t1 + t2; t1 = a + e1(f) + Ch(f, g, h) + 0xab1c5ed5 + W[7]; t2 = e0(b) + Maj(b, c, d); e += t1; a = t1 + t2; t1 = h + e1(e) + Ch(e, f, g) + 0xd807aa98 + W[8]; t2 = e0(a) + Maj(a, b, c); d += t1; h = t1 + t2; t1 = g + e1(d) + Ch(d, e, f) + 0x12835b01 + W[9]; t2 = e0(h) + Maj(h, a, b); c += t1; g = t1 + t2; t1 = f + e1(c) + Ch(c, d, e) + 0x243185be + W[10]; t2 = e0(g) + Maj(g, h, a); b += t1; f = t1 + t2; t1 = e + e1(b) + Ch(b, c, d) + 0x550c7dc3 + W[11]; t2 = e0(f) + Maj(f, g, h); a += t1; e = t1 + t2; t1 = d + e1(a) + Ch(a, b, c) + 0x72be5d74 + W[12]; t2 = e0(e) + Maj(e, f, g); h += t1; d = t1 + t2; t1 = c + e1(h) + Ch(h, a, b) + 0x80deb1fe + W[13]; t2 = e0(d) + Maj(d, e, f); g += t1; c = t1 + t2; t1 = b + e1(g) + Ch(g, h, a) + 0x9bdc06a7 + W[14]; t2 = e0(c) + Maj(c, d, e); f += t1; b = t1 + t2; t1 = a + e1(f) + Ch(f, g, h) + 0xc19bf174 + W[15]; t2 = e0(b) + Maj(b, c, d); e += t1; a = t1 + t2; t1 = h + e1(e) + Ch(e, f, g) + 0xe49b69c1 + W[16]; t2 = e0(a) + Maj(a, b, c); d += t1; h = t1 + t2; t1 = g + e1(d) + Ch(d, e, f) + 0xefbe4786 + W[17]; t2 = e0(h) + Maj(h, a, b); c += t1; g = t1 + t2; t1 = f + e1(c) + Ch(c, d, e) + 0x0fc19dc6 + W[18]; t2 = e0(g) + Maj(g, h, a); b += t1; f = t1 + t2; t1 = e + e1(b) + Ch(b, c, d) + 0x240ca1cc + W[19]; t2 = e0(f) + Maj(f, g, h); a += t1; e = t1 + t2; t1 = d + e1(a) + Ch(a, b, c) + 0x2de92c6f + W[20]; t2 = e0(e) + Maj(e, f, g); h += t1; d = t1 + t2; t1 = c + e1(h) + Ch(h, a, b) + 0x4a7484aa + W[21]; t2 = e0(d) + Maj(d, e, f); g += t1; c = t1 + t2; t1 = b + e1(g) + Ch(g, h, a) + 0x5cb0a9dc + W[22]; t2 = e0(c) + Maj(c, d, e); f += t1; b = t1 + t2; t1 = a + e1(f) + Ch(f, g, h) + 0x76f988da + W[23]; t2 = e0(b) + Maj(b, c, d); e += t1; a = t1 + t2; t1 = h + e1(e) + Ch(e, f, g) + 0x983e5152 + W[24]; t2 = e0(a) + Maj(a, b, c); d += t1; h = t1 + t2; t1 = g + e1(d) + Ch(d, e, f) + 0xa831c66d + W[25]; t2 = e0(h) + Maj(h, a, b); c += t1; g = t1 + t2; t1 = f + e1(c) + Ch(c, d, e) + 0xb00327c8 + W[26]; t2 = e0(g) + Maj(g, h, a); b += t1; f = t1 + t2; t1 = e + e1(b) + Ch(b, c, d) + 0xbf597fc7 + W[27]; t2 = e0(f) + Maj(f, g, h); a += t1; e = t1 + t2; t1 = d + e1(a) + Ch(a, b, c) + 0xc6e00bf3 + W[28]; t2 = e0(e) + Maj(e, f, g); h += t1; d = t1 + t2; t1 = c + e1(h) + Ch(h, a, b) + 0xd5a79147 + W[29]; t2 = e0(d) + Maj(d, e, f); g += t1; c = t1 + t2; t1 = b + e1(g) + Ch(g, h, a) + 0x06ca6351 + W[30]; t2 = e0(c) + Maj(c, d, e); f += t1; b = t1 + t2; t1 = a + e1(f) + Ch(f, g, h) + 0x14292967 + W[31]; t2 = e0(b) + Maj(b, c, d); e += t1; a = t1 + t2; t1 = h + e1(e) + Ch(e, f, g) + 0x27b70a85 + W[32]; t2 = e0(a) + Maj(a, b, c); d += t1; h = t1 + t2; t1 = g + e1(d) + Ch(d, e, f) + 0x2e1b2138 + W[33]; t2 = e0(h) + Maj(h, a, b); c += t1; g = t1 + t2; t1 = f + e1(c) + Ch(c, d, e) + 0x4d2c6dfc + W[34]; t2 = e0(g) + Maj(g, h, a); b += t1; f = t1 + t2; t1 = e + e1(b) + Ch(b, c, d) + 0x53380d13 + W[35]; t2 = e0(f) + Maj(f, g, h); a += t1; e = t1 + t2; t1 = d + e1(a) + Ch(a, b, c) + 0x650a7354 + W[36]; t2 = e0(e) + Maj(e, f, g); h += t1; d = t1 + t2; t1 = c + e1(h) + Ch(h, a, b) + 0x766a0abb + W[37]; t2 = e0(d) + Maj(d, e, f); g += t1; c = t1 + t2; t1 = b + e1(g) + Ch(g, h, a) + 0x81c2c92e + W[38]; t2 = e0(c) + Maj(c, d, e); f += t1; b = t1 + t2; t1 = a + e1(f) + Ch(f, g, h) + 0x92722c85 + W[39]; t2 = e0(b) + Maj(b, c, d); e += t1; a = t1 + t2; t1 = h + e1(e) + Ch(e, f, g) + 0xa2bfe8a1 + W[40]; t2 = e0(a) + Maj(a, b, c); d += t1; h = t1 + t2; t1 = g + e1(d) + Ch(d, e, f) + 0xa81a664b + W[41]; t2 = e0(h) + Maj(h, a, b); c += t1; g = t1 + t2; t1 = f + e1(c) + Ch(c, d, e) + 0xc24b8b70 + W[42]; t2 = e0(g) + Maj(g, h, a); b += t1; f = t1 + t2; t1 = e + e1(b) + Ch(b, c, d) + 0xc76c51a3 + W[43]; t2 = e0(f) + Maj(f, g, h); a += t1; e = t1 + t2; t1 = d + e1(a) + Ch(a, b, c) + 0xd192e819 + W[44]; t2 = e0(e) + Maj(e, f, g); h += t1; d = t1 + t2; t1 = c + e1(h) + Ch(h, a, b) + 0xd6990624 + W[45]; t2 = e0(d) + Maj(d, e, f); g += t1; c = t1 + t2; t1 = b + e1(g) + Ch(g, h, a) + 0xf40e3585 + W[46]; t2 = e0(c) + Maj(c, d, e); f += t1; b = t1 + t2; t1 = a + e1(f) + Ch(f, g, h) + 0x106aa070 + W[47]; t2 = e0(b) + Maj(b, c, d); e += t1; a = t1 + t2; t1 = h + e1(e) + Ch(e, f, g) + 0x19a4c116 + W[48]; t2 = e0(a) + Maj(a, b, c); d += t1; h = t1 + t2; t1 = g + e1(d) + Ch(d, e, f) + 0x1e376c08 + W[49]; t2 = e0(h) + Maj(h, a, b); c += t1; g = t1 + t2; t1 = f + e1(c) + Ch(c, d, e) + 0x2748774c + W[50]; t2 = e0(g) + Maj(g, h, a); b += t1; f = t1 + t2; t1 = e + e1(b) + Ch(b, c, d) + 0x34b0bcb5 + W[51]; t2 = e0(f) + Maj(f, g, h); a += t1; e = t1 + t2; t1 = d + e1(a) + Ch(a, b, c) + 0x391c0cb3 + W[52]; t2 = e0(e) + Maj(e, f, g); h += t1; d = t1 + t2; t1 = c + e1(h) + Ch(h, a, b) + 0x4ed8aa4a + W[53]; t2 = e0(d) + Maj(d, e, f); g += t1; c = t1 + t2; t1 = b + e1(g) + Ch(g, h, a) + 0x5b9cca4f + W[54]; t2 = e0(c) + Maj(c, d, e); f += t1; b = t1 + t2; t1 = a + e1(f) + Ch(f, g, h) + 0x682e6ff3 + W[55]; t2 = e0(b) + Maj(b, c, d); e += t1; a = t1 + t2; t1 = h + e1(e) + Ch(e, f, g) + 0x748f82ee + W[56]; t2 = e0(a) + Maj(a, b, c); d += t1; h = t1 + t2; t1 = g + e1(d) + Ch(d, e, f) + 0x78a5636f + W[57]; t2 = e0(h) + Maj(h, a, b); c += t1; g = t1 + t2; t1 = f + e1(c) + Ch(c, d, e) + 0x84c87814 + W[58]; t2 = e0(g) + Maj(g, h, a); b += t1; f = t1 + t2; t1 = e + e1(b) + Ch(b, c, d) + 0x8cc70208 + W[59]; t2 = e0(f) + Maj(f, g, h); a += t1; e = t1 + t2; t1 = d + e1(a) + Ch(a, b, c) + 0x90befffa + W[60]; t2 = e0(e) + Maj(e, f, g); h += t1; d = t1 + t2; t1 = c + e1(h) + Ch(h, a, b) + 0xa4506ceb + W[61]; t2 = e0(d) + Maj(d, e, f); g += t1; c = t1 + t2; t1 = b + e1(g) + Ch(g, h, a) + 0xbef9a3f7 + W[62]; t2 = e0(c) + Maj(c, d, e); f += t1; b = t1 + t2; t1 = a + e1(f) + Ch(f, g, h) + 0xc67178f2 + W[63]; t2 = e0(b) + Maj(b, c, d); e += t1; a = t1 + t2; state[0] += a; state[1] += b; state[2] += c; state[3] += d; state[4] += e; state[5] += f; state[6] += g; state[7] += h; }
Usar las funciones de plantilla C ++ es conveniente porque puedo calcular el hash que necesito a partir de datos regulares y obtener el resultado habitual:
const uint8_t header[] = { 0x02,0x00,0x00,0x00, 0x17,0x97,0x5b,0x97,0xc1,0x8e,0xd1,0xf7, 0xe2,0x55,0xad,0xf2,0x97,0x59,0x9b,0x55, 0x33,0x0e,0xda,0xb8,0x78,0x03,0xc8,0x17, 0x01,0x00,0x00,0x00,0x00,0x00,0x00,0x00, 0x8a,0x97,0x29,0x5a,0x27,0x47,0xb4,0xf1, 0xa0,0xb3,0x94,0x8d,0xf3,0x99,0x03,0x44, 0xc0,0xe1,0x9f,0xa6,0xb2,0xb9,0x2b,0x3a, 0x19,0xc8,0xe6,0xba, 0xdc,0x14,0x17,0x87, 0x35,0x8b,0x05,0x53, 0x53,0x5f,0x01,0x19, 0x48,0x75,0x08,0x33 }; uint32_t test_nonce = 0x48750833; uint32_t result[8]; full_btc_hash(header, test_nonce, result); uint8_t* presult = (uint8_t * )result; for (int i = 0; i < 32; i++) printf("%02X ", presult[i]);
Resulta que:
92 98 2A 50 91 FA BD 42 97 8A A5 2D CD C9 36 28 02 4A DD FE E0 67 A4 78 00 00 00 00 00 00 00 00 00
Al final del hash hay muchos ceros, un hermoso hash, bingo, etc.
Y ahora, además, puedo pasar no datos ordinarios de uint32_t a esta función hash, sino mi clase especial de C ++, que redefinirá toda la aritmética.
Si si. Voy a aplicar las matemáticas probabilísticas "alternativas".
Lo inventé yo mismo, me di cuenta, lo experimenté yo mismo. No parece funcionar muy bien. Un chiste Debería funcionar Tal vez no soy el primero que estoy tratando de arrancar.
Ahora pasamos a lo más interesante.
Toda la aritmética en electrónica digital se realiza como operaciones en bits, y está estrictamente definida por las operaciones AND, OR, NOT, EXCLUSIVE OR. Bueno, todos sabemos qué tablas de verdad hay en álgebra booleana.
Sugiero agregar un poco de incertidumbre a los cálculos, haciéndolos probabilísticos.
¡Deje que cada bit de la palabra tenga no solo los valores CERO y UNO posibles, sino también todos los valores intermedios! Propongo considerar el valor de un bit como la probabilidad de un evento que puede ocurrir o no. Si todos los datos iniciales se conocen de manera confiable, entonces el resultado es confiable. Y si faltan algunos datos, entonces el resultado resultará con cierta probabilidad.
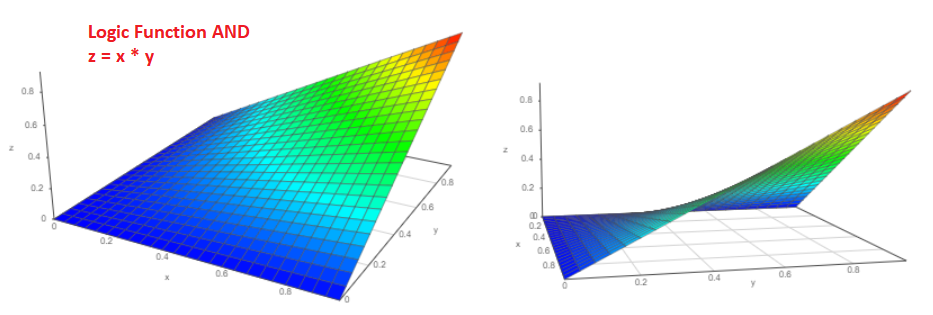
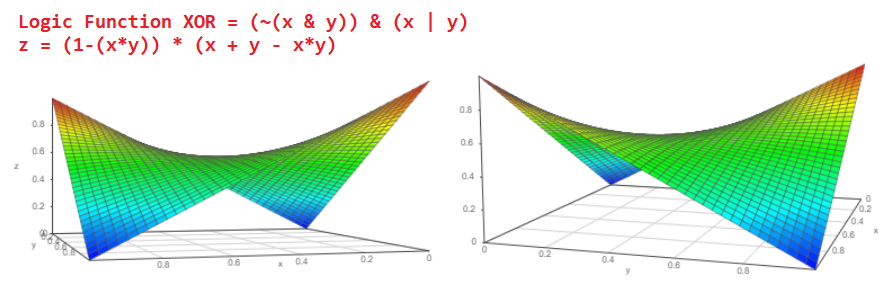
De hecho, suponga que hay dos eventos independientes “a” y “b”, cuya probabilidad de ocurrencia es naturalmente de cero a uno, respectivamente, Pa y Pb. ¿Cuál es la probabilidad de que los eventos sucedan simultáneamente? ¡Estoy seguro de que cada uno de nosotros no dudará en responder P = Pa * Pb y esta es la respuesta correcta!
El gráfico 3D de dicha función se verá así (desde dos puntos de vista diferentes):
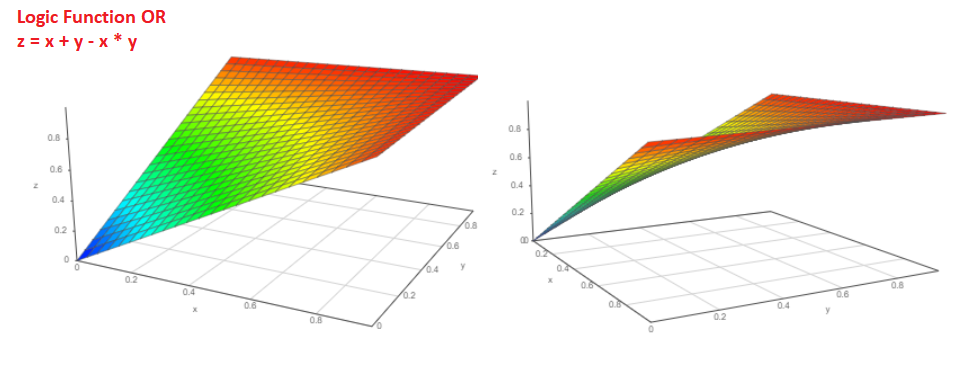
¿Y cuál es la probabilidad de que ocurra el evento Pa o el evento Pb?
Probabilidad P = Pa + Pb-Pa * Pb. El gráfico de funciones es así:
Y si conocemos la probabilidad de que ocurra el evento Pa, ¿cuál es la probabilidad de que el evento no ocurra?
P = 1 - Pa.
Ahora hagamos una suposición. Imagine que tenemos elementos lógicos que calculan la probabilidad de un evento de salida, conociendo la probabilidad de eventos de entrada:
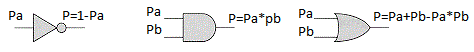
Tener tales elementos lógicos puede hacerlos más complejos, por ejemplo, exclusivos o XOR:
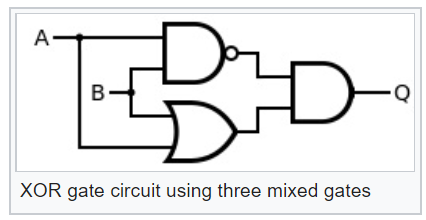
Ahora, mirando el diagrama de este elemento lógico XOR, podemos entender cuál será la probabilidad del evento a la salida del XOR probabilístico:
Pero eso no es todo. Conocemos la lógica típica de un sumador completo y descubrimos cómo se hace un sumador de varios bits a partir de un sumador completo:
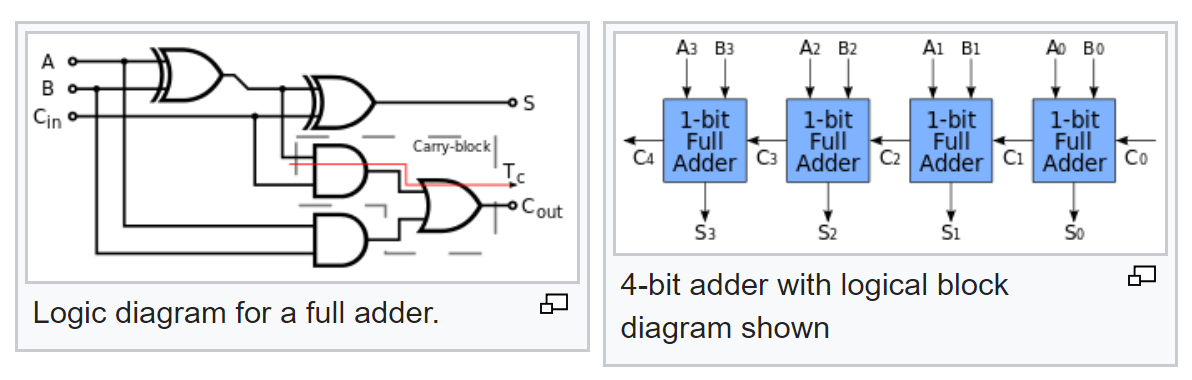
Entonces, de acuerdo con su esquema, ahora podemos calcular las probabilidades de las señales en su salida, con probabilidades conocidas de las señales en la entrada.
Por lo tanto, puedo implementar en c ++ mi propia clase de "32 bits" (la llamaré x32) con aritmética probabilística, anular esta clase para todas las operaciones sha256 como AND, OR, XOR, ADD y turnos. La clase almacenará 32 bits en su interior, pero cada bit es un número de coma flotante. Cada operación lógica o aritmética en dicho número de 32 bits calculará la probabilidad del valor de cada bit con parámetros de entrada conocidos o poco conocidos de una operación lógica o aritmética.
Considere un ejemplo muy simple que usa mis matemáticas probabilísticas:
typedef std::numeric_limits< double > dbl; int main(int argc, char *argv[]) { cout.precision(dbl::max_digits10); x32 a = 0xaabbccdd; x32 b = 0x12345678; <b>
En este ejemplo, se agregan dos números de 32 bits.
Mientras que la cadena es b.setBit (4, 0.75); El resultado de la adición se comenta de manera exactamente predecible y predeterminada, porque se conocen todos los datos de entrada para la adición. El programa imprime esto en la consola:
result = 0xbcf02355 bit0 = 1 bit1 = 0 bit2 = 1 bit3 = 0 bit4 = 1 bit5 = 0 bit6 = 1 bit7 = 0 bit8 = 1 bit9 = 1 bit10 = 0 bit11 = 0 bit12 = 0 bit13 = 1 bit14 = 0 bit15 = 0 bit16 = 0 bit17 = 0 bit18 = 0 bit19 = 0 bit20 = 1 bit21 = 1 bit22 = 1 bit23 = 1 bit24 = 0 bit25 = 0 bit26 = 1 bit27 = 1 bit28 = 1 bit29 = 1 bit30 = 0 bit31 = 1
Si descomento la línea b.setBit (4, 0.75); al hacer esto le diría al programa: "agrégame estos dos números, pero no sé realmente el valor del bit 4 del segundo argumento, creo que es uno con una probabilidad de 0,75".
Luego, la adición se produce, como debería ser, con un cálculo completo de las probabilidades de las señales de salida, es decir, bits:
bit not stable bit not stable bit not stable result = 0xbcf02305 bit0 = 1 bit1 = 0 bit2 = 1 bit3 = 0 bit4 = 0.75 bit5 = 0.1875 bit6 = 0.8125 bit7 = 0 bit8 = 1 bit9 = 1 bit10 = 0 bit11 = 0 bit12 = 0 bit13 = 1 bit14 = 0 bit15 = 0 bit16 = 0 bit17 = 0 bit18 = 0 bit19 = 0 bit20 = 1 bit21 = 1 bit22 = 1 bit23 = 1 bit24 = 0 bit25 = 0 bit26 = 1 bit27 = 1 bit28 = 1 bit29 = 1 bit30 = 0 bit31 = 1
Debido al hecho de que los datos de entrada no eran muy conocidos, el resultado no es muy conocido. Además, lo que se puede calcular de manera confiable se considera confiable. Lo que no se puede contar se considera con probabilidad.
Ahora que tengo una clase c ++ de 32 bits tan maravillosa para la aritmética difusa, puedo pasar matrices de variables del tipo x32 a la función full_btc_hash () en la plantilla y obtener un resultado hash estimado probabilístico.
Algunas de las implementaciones de la clase x32 son: #pragma once #include <string> #include <list> #include <iostream> #include <utility> #include <stdint.h> #include <vector> #include <limits> using namespace std; #include <boost/math/constants/constants.hpp> #include <boost/multiprecision/cpp_dec_float.hpp> using boost::multiprecision::cpp_dec_float_50; //typedef double MY_FP; typedef cpp_dec_float_50 MY_FP; class x32 { public: x32(); x32(uint32_t n); void init(MY_FP val); void init(double* pval); void setBit(int i, MY_FP val) { bvi[i] = val; }; ~x32() {}; x32 operator|(const x32& right); x32 operator&(const x32& right); x32 operator^(const x32& right); x32 operator+(const x32& right); x32& x32::operator+=(const x32& right); x32 operator~(); x32 operator<<(const unsigned int& right); x32 operator>>(const unsigned int& right); void print(); uint32_t get32(); MY_FP get_bvi(uint32_t idx) { return bvi[idx]; }; private: MY_FP not(MY_FP a); MY_FP and(MY_FP a, MY_FP b); MY_FP or (MY_FP a, MY_FP b); MY_FP xor(MY_FP a, MY_FP b); MY_FP bvi[32]; //bit values }; #include "stdafx.h" #include "x32.h" x32::x32() { for (int i = 0; i < 32; i++) { bvi[i] = 0.0; } } x32::x32(uint32_t n) { for (int i = 0; i < 32; i++) { bvi[i] = (n&(1 << i)) ? 1.0 : 0.0; } } void x32::init(MY_FP val) { for (int i = 0; i < 32; i++) { bvi[i] = val; } } void x32::init(double* pval) { for (int i = 0; i < 32; i++) { bvi[i] = pval[i]; } } x32 x32::operator<<(const unsigned int& right) { x32 t; for (int i = 31; i >= 0; i--) { if (i < right) { t.bvi[i] = 0.0; } else { t.bvi[i] = bvi[i - right]; } } return t; } x32 x32::operator>>(const unsigned int& right) { x32 t; for (unsigned int i = 0; i < 32; i++) { if (i >= (32 - right)) { t.bvi[i] = 0; } else { t.bvi[i] = bvi[i + right]; } } return t; } MY_FP x32::not(MY_FP a) { return 1.0 - a; } MY_FP x32::and(MY_FP a, MY_FP b) { return a * b; } MY_FP x32::or(MY_FP a, MY_FP b) { return a + b - a * b; } MY_FP x32::xor (MY_FP a, MY_FP b) { //(~(A & B)) & (A | B) return and( not( and(a,b) ) , or(a,b) ); } x32 x32::operator|(const x32& right) { x32 t; for (int i = 0; i < 32; i++) { t.bvi[i] = or ( bvi[i], right.bvi[i] ); } return t; } x32 x32::operator&(const x32& right) { x32 t; for (int i = 0; i < 32; i++) { t.bvi[i] = and (bvi[i], right.bvi[i]); } return t; } x32 x32::operator~() { x32 t; for (int i = 0; i < 32; i++) { t.bvi[i] = not(bvi[i]); } return t; } x32 x32::operator^(const x32& right) { x32 t; for (int i = 0; i < 32; i++) { t.bvi[i] = xor (bvi[i], right.bvi[i]); } return t; } x32 x32::operator+(const x32& right) { x32 r; r.bvi[0] = xor (bvi[0], right.bvi[0]); MY_FP cout = and (bvi[0], right.bvi[0]); for (unsigned int i = 1; i < 32; i++) { MY_FP xor_a_b = xor (bvi[i], right.bvi[i]); r.bvi[i] = xor( xor_a_b, cout ); MY_FP and1 = and (bvi[i], right.bvi[i]); MY_FP and2 = and (xor_a_b, cout); cout = or (and1,and2); } return r; } x32& x32::operator+=(const x32& right) { MY_FP cout = and (bvi[0], right.bvi[0]); bvi[0] = xor (bvi[0], right.bvi[0]); for (unsigned int i = 1; i < 32; i++) { MY_FP xor_a_b = xor (bvi[i], right.bvi[i]); MY_FP and1 = and (bvi[i], right.bvi[i]); MY_FP and2 = and (xor_a_b, cout); bvi[i] = xor (xor_a_b, cout); cout = or (and1, and2); } return *this; } void x32::print() { for (int i = 0; i < 32; i++) { cout << bvi[i] << "\n"; } } uint32_t x32::get32() { uint32_t r = 0; for (int i = 0; i < 32; i++) { if (bvi[i] == 1.0) r = r | (1 << i); else if (bvi[i] == 0.0) { //ok } else { //oops.. cout << "bit not stable\n"; } } return r; }
¿Para qué es todo esto?
El minero de Bitcoin no sabe de antemano qué valor seleccionar 32x nonce. El minero se ve obligado a iterar sobre los 4 mil millones de ellos para contar el hash hasta que se vuelva "hermoso", hasta que el valor del hash sea menor que el objetivo.
La aritmética probabilística difusa teóricamente te permite deshacerte de la búsqueda exhaustiva.
Sí, inicialmente no sé el significado de todos los bits sin sentido requeridos. Si no los conozco, que no haya mierda, la probabilidad inicial de no bits es 0.5. Incluso en este escenario, puedo calcular la probabilidad de bits hash de salida. En algún lugar, también resultan alrededor de 0,5 más o menos medio centavo.
, 0.5 0.9 0.1 1.0 , . . .
, , , 0.5 , , nonce[0] = 0.9:
typedef std::numeric_limits< double > dbl; int main(int argc, char *argv[]) { cout.precision(dbl::max_digits10);
x32::get_bvi() .
, nonce[0] 0.5 0.9, , :
0.44525679540883948 0.44525679540840074 0.55268174813167364 0.5526817481315932 0.57758654725359399 0.57758654725360606 0.49595026978928474 0.49595026978930477 0.57118578561406703 0.57118578561407746 0.53237003739057907 0.5323700373905661 0.57269859374138096 0.57269859374138162 0.57631236396381141 0.5763123639638157 0.47943176373960149 0.47943176373960219 0.54955992675177704 0.5495599267517755 0.53321116270879686 0.53321116270879733 0.57294025883744952 0.57294025883744984 0.53131857821387693 0.53131857821387655 0.57253530821899101 0.57253530821899102 0.50661432403287194 0.50661432403287198 0.57149419848354913 0.57149419848354916 0.53220327148366491 0.53220327148366487 0.57268927270412251 0.57268927270412251 0.57632130426913003 0.57632130426913005 0.57233970084776142 0.57233970084776143 0.56824728628552812 0.56824728628552813 0.45247155441889921 0.45247155441889922 0.56875940568326509 0.56875940568326509 0.57524323439326321 0.57524323439326321 0.57587726902392535 0.57587726902392535 0.57597043124557292 0.57597043124557292 0.52847748894672118 0.52847748894672118 0.54512141953055808 0.54512141953055808 0.57362254577539695 0.57362254577539695 0.53082194129771177 0.53082194129771177 0.54404489702929382 0.54404489702929382 0.54065386336136847 0.54065386336136847
, 10 . … - . , ?
, , , :
double nonce_bits[32]; for (int i = 0; i < 32; i++) nonce_bits[i] = (real_nonce32&(1 << i)) ? 1.0 : 0.0; x32 nonce_x32; nonce_x32.init(nonce_bits); full_btc_hash(strxx, nonce_x32, result_x32);
luego, al calcular el hash probabilístico, obtenemos el resultado lógico correcto: un hash "hermoso" en la salida, bingo.Entonces, con las matemáticas, todo está aquí.Queda por aprender cómo analizar el aliento de la brisa ... y el hash está roto.Parece una tontería, pero esto es una tontería, y advertí desde el principio.Otros materiales útiles:- Minim Bitcoin con papel y bolígrafo.
- ¿Es posible calcular bitcoins más rápido, más fácil o más fácil?
- ¿Cómo hice blakecoin miner hacer
- FPGA Bitcoin miner en Mars rover board 3
- FPGA Miner con Algoritmo Blake