Todas las organizaciones que tienen al menos algo que ver con los datos tarde o temprano enfrentan el problema de almacenar bases de datos relacionales y no estructuradas. No es fácil encontrar un enfoque conveniente, efectivo y económico para este problema al mismo tiempo. Y para asegurarse de que los científicos de datos puedan trabajar con éxito con modelos de aprendizaje automático. Lo hicimos, y aunque tuve que jugar con ello, el beneficio final fue incluso más de lo esperado. Discutiremos todos los detalles a continuación.

Con el tiempo, se acumulan cantidades increíbles de datos corporativos en cualquier banco. Una cantidad comparable se almacena solo en empresas de Internet y telecomunicaciones. Sucedió debido a los altos requisitos reglamentarios. Estos datos no permanecen inactivos: los jefes de las instituciones financieras han descubierto durante mucho tiempo cómo obtener ganancias de esto.
Todos comenzamos con la gestión y la información financiera. Con base en estos datos, aprendimos cómo tomar decisiones comerciales. A menudo era necesario obtener datos de varios sistemas de información del banco, para lo cual creamos bases de datos consolidadas y sistemas de informes. A partir de esto se formó gradualmente lo que ahora se llama un almacén de datos. Pronto, sobre la base de este almacenamiento, nuestros otros sistemas comenzaron a funcionar:
- CRM analítico, que permite ofrecer al cliente productos más convenientes para él;
- transportadores de préstamos que lo ayudan a tomar una decisión sobre un préstamo de manera rápida y precisa;
- Sistemas de fidelización que calculan reembolsos o puntos de bonificación según mecanismos de diversa complejidad.
Todas estas tareas se resuelven mediante aplicaciones analíticas que utilizan modelos de aprendizaje automático. Cuanta más información puedan obtener los modelos del repositorio, más exactamente funcionarán. Su necesidad de datos está creciendo exponencialmente.
Sobre esta situación llegamos hace dos o tres años. En ese momento, teníamos un almacenamiento basado en el MPP Teradata DBMS usando la herramienta SAS Data Integration Studio ELT. Construimos este almacén desde 2011 junto con Glowbyte Consulting. En él se integraron más de 15 grandes sistemas bancarios y, al mismo tiempo, se acumularon datos suficientes para la implementación y el desarrollo de aplicaciones analíticas. Por cierto, justo en ese momento, la cantidad de datos en las capas principales de la tienda, debido a muchas tareas diferentes, comenzó a crecer de forma no lineal, y el análisis avanzado de clientes se convirtió en una de las principales direcciones del desarrollo del banco. Sí, y nuestros científicos de datos estaban ansiosos por apoyarla. En general, para construir la Plataforma de Investigación de Datos, las estrellas se formaron como deberían.
Planificando una solución
Aquí es necesario explicar: el software industrial y los servidores son un placer costoso incluso para un banco grande. No todas las organizaciones pueden permitirse almacenar una gran cantidad de datos en los principales MPP DBMS. Siempre debe elegir entre precio y velocidad, confiabilidad y volumen.
Para aprovechar al máximo las oportunidades disponibles, decidimos hacer esto:
- La carga ELT y la parte más solicitada de los datos históricos del CD deben dejarse en el DBMS de Teradata;
- envíe la historia completa a Hadoop, que le permite almacenar información mucho más barata.
Alrededor de ese tiempo, el ecosistema de Hadoop no solo se puso de moda, sino también lo suficientemente confiable y conveniente para el uso empresarial. Era necesario elegir un kit de distribución. Puede construir el suyo propio o usar el Apache Hadoop abierto. Pero entre las soluciones empresariales basadas en Hadoop, las distribuciones listas para usar de otros proveedores, Cloudera y Hortonworks, han demostrado ser más. Por lo tanto, también decidimos usar una distribución preparada.
Dado que nuestra tarea principal todavía era almacenar grandes datos estructurados, en la pila de Hadoop estábamos interesados en soluciones que estuvieran lo más cerca posible de los DBMS SQL clásicos. Los líderes aquí son Impala y Hive. Cloudera desarrolla e integra las soluciones Impala, Hortonworks - Hive.
Para un estudio en profundidad, organizamos pruebas de carga para ambos DBMS, teniendo en cuenta la carga de perfil para nosotros. Debo decir que los motores de procesamiento de datos en Impala y Hive son significativamente diferentes: Hive generalmente presenta varias opciones diferentes. Sin embargo, la elección recayó en Impala y, en consecuencia, la distribución de Cloudera.
Lo que me gustó de Impala
- Alta velocidad de ejecución de consultas analíticas debido a un enfoque alternativo en relación con MapReduce. Los resultados intermedios de los cálculos no se pliegan en HDFS, lo que acelera significativamente el procesamiento de datos.
- Trabajo eficiente con almacenamiento de datos de parquet en Parquet . Para tareas analíticas, a menudo se usan las llamadas tablas anchas con muchas columnas. Raramente se usan todas las columnas: la capacidad de subir desde HDFS solo las que son necesarias para el trabajo le permite ahorrar RAM y acelerar significativamente la solicitud.
- Una solución elegante con filtros de tiempo de ejecución que incluyen filtrado de floración. Tanto Hive como Impala están significativamente limitados en su uso de índices comunes a los DBMS clásicos debido a la naturaleza del sistema de almacenamiento de archivos HDFS. Por lo tanto, para optimizar la ejecución de la consulta SQL, el motor DBMS debería usar efectivamente la partición disponible incluso cuando no se especifique explícitamente en las condiciones de la consulta. Además, debe tratar de predecir qué cantidad mínima de datos de HDFS debe generarse para garantizar el procesamiento de todas las filas. En Impala, esto funciona muy bien.
- Impala utiliza LLVM , un compilador de máquinas virtuales con instrucciones similares a RISC, para generar el código óptimo de ejecución de consultas SQL.
- Las interfaces ODBC y JDBC son compatibles. Esto le permite integrar los datos de Impala con herramientas analíticas y aplicaciones casi listas para usar.
- Es posible usar Kudu para eludir algunas de las limitaciones de HDFS y, en particular, escribir construcciones UPDATE y DELETE en consultas SQL.
Sqoop y el resto de la arquitectura.
La siguiente herramienta más importante en la pila de Hadoop fue Sqoop para nosotros. Le permite transferir datos entre DBMS relacionales (por supuesto, estábamos interesados en Teradata) y HDFS en un clúster Hadoop en varios formatos, incluido Parquet. En las pruebas, Sqoop mostró una gran flexibilidad y rendimiento, por lo que decidimos usarlo, en lugar de desarrollar nuestras propias herramientas para capturar datos a través de ODBC / JDBC y guardarlos en HDFS.
Para los modelos de capacitación y tareas relacionadas de Data Science, que son más convenientes para ejecutar directamente en el clúster Hadoop, utilizamos Apache
Spark . En su campo, se ha convertido en una solución estándar, y hay una razón:
- Bibliotecas de aprendizaje automático de Spark ML
- soporte para cuatro lenguajes de programación (Scala, Java, Python, R);
- integración con herramientas analíticas;
- El procesamiento de datos en memoria proporciona un rendimiento excelente.
El servidor de Oracle Big Data Appliance se compró como una plataforma de hardware. Comenzamos con seis nodos en un circuito productivo con una CPU de 2x24 núcleos y 256 GB de memoria cada uno. La configuración actual contiene 18 de los mismos nodos con hasta 512 GB de memoria expandida.
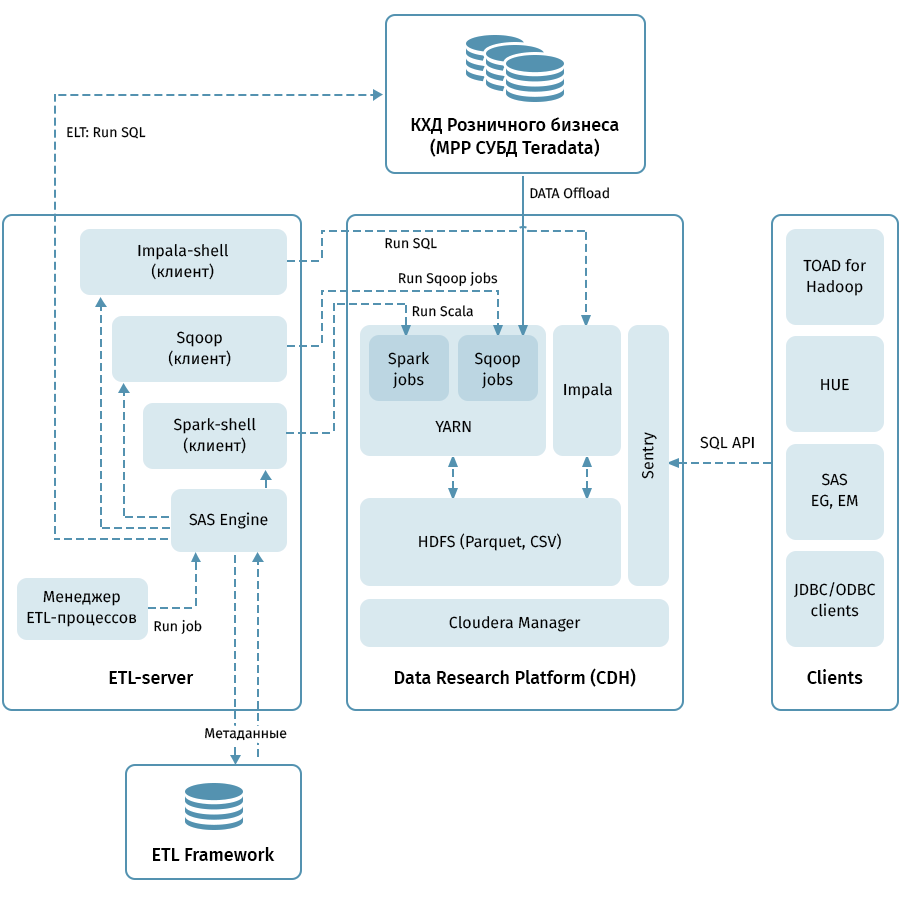
El diagrama muestra la arquitectura de nivel superior de la plataforma de investigación de datos y los sistemas relacionados. El enlace central es el clúster Hadoop basado en la distribución Cloudera (CDH). Se utiliza tanto para recibir con Sqoop como para almacenar datos QCD en HDFS, en formato de parquet, lo que permite el uso de códecs para la compresión, por ejemplo, Snappy. El clúster también procesa datos: Impala se usa para transformaciones similares a ELT, Spark, para tareas de Data Science. Sentry se usa para compartir el acceso a datos.
Impala tiene interfaces para casi todas las herramientas modernas de análisis empresarial. Además, las herramientas arbitrarias que admiten interfaces ODBC / JDBC se pueden conectar como clientes. Para trabajar con SQL, consideramos que Hue y TOAD para Hadoop son los principales clientes.
Un subsistema ETL que consta de herramientas SAS (Metadata Server, Data Integration Studio) y un marco ETL escrito sobre la base de SAS y scripts de shell que utilizan una base de datos para almacenar metadatos de procesos ETL se utilizan para administrar todos los flujos indicados por flechas en el diagrama. . Guiado por las reglas especificadas en los metadatos, el subsistema ETL lanza procesos de procesamiento de datos tanto en QCD como en la Plataforma de Investigación de Datos. Como resultado, tenemos un sistema de extremo a extremo para monitorear y administrar los flujos de datos independientemente del entorno utilizado (Teradata, Impala, Spark, etc., si es necesario).
A través del rastrillo a las estrellas
Descargar QCD parece ser simple. En la entrada y salida, el DBMS relacional, toma y desborda datos a través de Sqoop. A juzgar por la descripción anterior, todo nos fue muy bien, pero, por supuesto, no fue sin aventuras, y esta es quizás la parte más interesante de todo el proyecto.

Con nuestro volumen, no podríamos esperar transferir todos los datos por completo todos los días. En consecuencia, en cada instalación de almacenamiento era necesario aprender a distinguir un incremento confiable, lo que no siempre es fácil cuando los datos de las fechas comerciales históricas pueden cambiar en la tabla. Para resolver este problema, sistematizamos objetos según los métodos de carga y mantenimiento del historial. Luego, para cada tipo, se determinó el predicado correcto para Sqoop y el método de carga en el receptor. Y finalmente, escribieron instrucciones para desarrolladores de nuevos objetos.
Sqoop es una herramienta de muy alta calidad, pero no en todos los casos y combinaciones de sistemas, funciona de manera absolutamente confiable. En nuestros volúmenes, el conector a Teradata no funcionó de manera óptima. Aprovechamos el código fuente abierto de Sqoop e hicimos cambios en las bibliotecas de conectores. La estabilidad de la conexión al mover datos ha aumentado.
Por alguna razón, cuando Sqoop llama a Teradata, los predicados no se convierten correctamente a las condiciones WHERE. Debido a esto, Sqoop a veces intenta sacar una gran mesa y filtrarla más tarde. No pudimos parchear el conector aquí, pero encontramos otra forma: crear a la fuerza una tabla temporal con un predicado impuesto para cada objeto descargado y pedirle a Sqoop que lo llene en exceso.
Todos los MPP, y Teradata en particular, tienen una característica relacionada con el almacenamiento de datos paralelos y la ejecución de instrucciones. Si esta característica no se tiene en cuenta, puede resultar que todo el trabajo será asumido por un nodo lógico del clúster, lo que hará que la ejecución de la consulta sea mucho más lenta, una vez en 100-200. Por supuesto, no podríamos permitir esto, por lo tanto, escribimos un motor especial que utiliza metadatos ETL de tablas QCD y selecciona el grado óptimo de paralelización de las tareas de Sqoop.
La historicidad en el almacenamiento es un asunto delicado, especialmente si usa
SCD2 , mientras que Impala no admite ACTUALIZAR y ELIMINAR. Por supuesto, queremos que las tablas históricas en la Plataforma de investigación de datos tengan exactamente el mismo aspecto que en Teradata. Esto se puede lograr combinando el incremento de recepción a través de Sqoop, resaltando claves comerciales actualizadas y eliminando particiones en Impala. Para que esta lógica elaborada no tenga que ser escrita por cada desarrollador, la empaquetamos en una biblioteca especial (en nuestro "cargador" de jerga ETL).
Finalmente, una pregunta con tipos de datos. Impala es bastante libre de escribir conversión, por lo que encontramos algunas dificultades solo en los tipos TIMESTAMP y CHAR / VARCHAR. Para la fecha y hora, decidimos almacenar datos en Impala en el formato de texto (STRING) AAAA-MM-DD HH: MM: SS. Como resultado, este enfoque permite utilizar las funciones de transformación de fecha y hora. Para los datos de cadena de una longitud dada, resultó que el almacenamiento en formato STRING en Impala no es inferior a ellos, por lo tanto, también lo usamos.
Por lo general, para organizar Data Lake, copian datos de origen en formatos semiestructurados en un área de escenario especial en Hadoop, después de lo cual Hive o Impala configuran un esquema de deserialización para estos datos para su uso en consultas SQL. Nosotros fuimos por el mismo camino. Es importante tener en cuenta que no todo y que no siempre tiene sentido arrastrar al almacén de datos, ya que el desarrollo de procesos de copia de archivos y la instalación del esquema es mucho más barato que cargar atributos comerciales en el modelo QCD utilizando procesos ETL. Cuando todavía no está claro cuánto, por cuánto tiempo y con qué frecuencia se necesitan los datos de origen, Data Lake en el enfoque descrito es una solución simple y barata. Ahora cargamos regularmente a Data Lake principalmente fuentes que generan eventos de usuario: datos de análisis de aplicaciones, registros y escenarios de transición para marcador automático y contestador automático Avaya, transacciones con tarjeta.
Kit de herramientas para analistas
No nos hemos olvidado de otro objetivo de todo el proyecto: permitir a los analistas utilizar toda esta riqueza. Aquí están los principios básicos que nos guiaron aquí:
- Conveniencia de la herramienta en uso y soporte
- Aplicabilidad en tareas de ciencia de datos
- La posibilidad máxima de utilizar los recursos informáticos del clúster Hadoop, y no los servidores de aplicaciones o la computadora del investigador
Y esto es lo que paramos en:
- Python + Anaconda. El entorno utilizado es iPython / Jupyter.
- R + brillante. El investigador trabaja en la versión de escritorio o web de R Studio, Shiny se utiliza para desarrollar aplicaciones web que se agudizan mediante el uso de algoritmos desarrollados en R.
- Chispa Para trabajar con datos, se utilizan las interfaces para Python (pyspark) y R, que se configuran en los entornos de desarrollo especificados en los párrafos anteriores. Ambas interfaces le permiten utilizar la biblioteca Spark ML, lo que permite entrenar modelos ML en el clúster Hadoop / Spark.
- Se puede acceder a los datos de Impala a través de Hue, Spark y desde entornos de desarrollo utilizando la interfaz estándar ODBC y bibliotecas especiales como implyr
Actualmente, Data Lake contiene aproximadamente 100 TB de datos del almacenamiento minorista, además de aproximadamente 50 TB de varias fuentes OLTP. El lago se actualiza diariamente de forma incremental. En el futuro, vamos a aumentar la conveniencia del usuario, introducir una carga ELT en Impala, aumentar el número de fuentes cargadas en Data Lake y ampliar las oportunidades para análisis avanzados.
En conclusión, me gustaría dar algunos consejos generales a colegas que recién comienzan su viaje en la creación de grandes repositorios:
- Utiliza las mejores prácticas. Si no tuviéramos un subsistema ETL, metadatos, almacenamiento versionado y una arquitectura comprensible, no habríamos dominado esta tarea. Las mejores prácticas se pagan por sí mismas, aunque no de inmediato.
- Recuerda la cantidad de datos. Big data puede crear dificultades técnicas en lugares muy inesperados.
- Estén atentos a las nuevas tecnologías. A menudo aparecen nuevas soluciones, no todas son útiles, pero a veces se encuentran gemas reales.
- Experimenta más. No confíe solo en las descripciones de marketing de las soluciones, pruébelo usted mismo.
Por cierto, puede leer sobre cómo nuestros analistas utilizaron el aprendizaje automático y los datos bancarios para trabajar con los riesgos de crédito en una publicación separada.