Hola a todos!
Nuestro experimento con los pasos en el curso de
Desarrollador Java continúa y, curiosamente, incluso con bastante éxito (más o menos): como resultó, planificar el apalancamiento de un par de meses con la próxima transición a un nuevo paso en cualquier momento conveniente es mucho más conveniente que si Asignar casi seis meses a un curso tan difícil. Por lo tanto, existe la sospecha de que son precisamente los cursos complejos los que pronto comenzaremos a transferir lentamente a dicho sistema.
Pero soy yo por lo nuestro, por otusovsky, lo siento. Como siempre, continuamos estudiando temas interesantes que, aunque no se abordan en nuestro programa, pero que se discuten con nosotros, preparamos una traducción del artículo más interesante en nuestra opinión sobre una de las preguntas que hicieron nuestros maestros.
Vamos!

Las colecciones en el JDK son las implementaciones de biblioteca estándar de listas y mapas. Si observa una instantánea de una aplicación Java grande típica, verá miles o incluso millones de instancias de
java.util.ArrayList ,
java.util.HashMap , etc. Las colecciones son indispensables para almacenar y manipular datos. Pero, ¿alguna vez ha pensado si todas las colecciones de su aplicación hacen un uso óptimo de la memoria? En otras palabras, si su aplicación se bloquea con el vergonzoso
OutOfMemoryError o causa largas pausas en el recolector de basura, ¿alguna vez ha revisado las colecciones usadas en busca de fugas?
En primer lugar, debe tenerse en cuenta que las colecciones internas de JDK no son algún tipo de magia. Están escritos en Java. Su código fuente viene con el JDK, por lo que puede abrirlo en su IDE. Su código también se puede encontrar fácilmente en Internet. Y, como resultado, la mayoría de las colecciones no son muy elegantes en términos de optimización de la cantidad de memoria consumida.
Considere, por ejemplo, una de las colecciones más simples y populares: la clase
java.util.ArrayList . Internamente, cada
ArrayList opera con una matriz de
Object[] elementData . Aquí es donde se almacenan los elementos de la lista. Veamos cómo se procesa esta matriz.
Cuando crea una
ArrayList con el constructor predeterminado, es decir, llame a la
new ArrayList() ,
elementData apunta a una matriz genérica de tamaño cero (
elementData también se puede establecer en
null , pero la matriz proporciona algunos beneficios menores de implementación). Cuando agrega el primer elemento a la lista,
elementData una matriz única real de
elementData y el objeto proporcionado se inserta en él. Para evitar cambiar el tamaño de la matriz cada vez, al agregar un nuevo elemento, se crea con una longitud igual a 10 ("capacidad predeterminada"). Resulta que si ya no agrega elementos a esta
ArrayList , 9 de cada 10 espacios en la matriz
elementData permanecerán vacíos. E incluso si borra la lista, el tamaño de la matriz interna no se reducirá. El siguiente es un diagrama de este ciclo de vida:
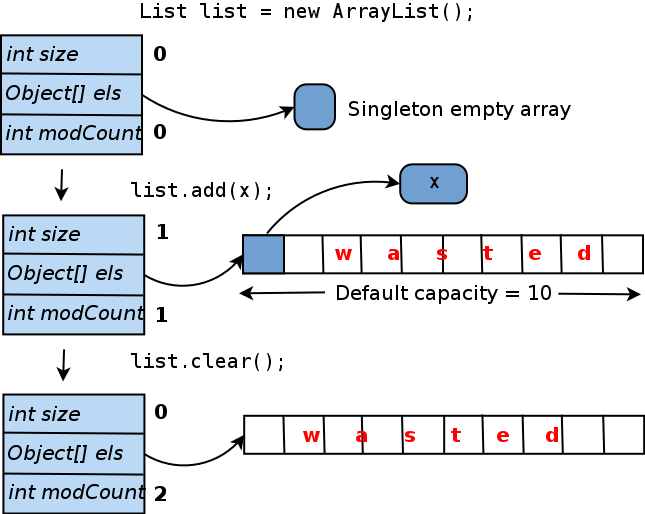
¿Cuánta memoria se desperdicia aquí? En términos absolutos, se calcula como (el tamaño del puntero del objeto). Si usa JVM HotSpot (que viene con Oracle JDK), el tamaño del puntero dependerá del tamaño máximo de almacenamiento dinámico (para obtener más detalles, consulte
https://blog.codecentric.de/en/2014/02/35gb-heap-less- 32 gb-java-jvm-memory-rarezas / ). Normalmente, si especifica
-Xmx menos de 32 gigabytes, el tamaño del puntero será de 4 bytes; para grandes montones - 8 bytes. Por lo tanto, una
ArrayList , inicializada por el constructor predeterminado, con la adición de un solo elemento, desperdicia 36 o 72 bytes.
De hecho, un
ArrayList vacío también
ArrayList desperdiciando memoria porque no lleva ninguna carga de trabajo, pero el tamaño del
ArrayList sí no es cero y más grande de lo que probablemente piensas. Esto se debe a que, por un lado, cada objeto administrado por la JVM de HotSpot tiene un encabezado de 12 o 16 bytes, que la JVM utiliza para fines internos. Además, la mayoría de los objetos en la colección contienen un campo de
size , un puntero a una matriz interna u otro objeto de "carga de trabajo", un campo
modCount para rastrear cambios en el contenido, etc. Por lo tanto, incluso el objeto más pequeño posible que representa una colección vacía probablemente necesitará al menos 32 bytes de memoria. Algunos, como
ConcurrentHashMap , ocupan mucho más.
Considere otra colección común: la clase
java.util.HashMap . Su ciclo de vida es similar al ciclo de vida de
ArrayList :

Como puede ver, un
HashMap contiene solo un par clave-valor gasta 15 celdas internas de la matriz, lo que corresponde a 60 o 120 bytes. Estos números son pequeños, pero el grado de pérdida de memoria es importante para todas las colecciones en su aplicación. Y resulta que algunas aplicaciones pueden gastar bastante memoria de esta manera. Por ejemplo, ¡algunos de los componentes de Hadoop de código abierto populares que el autor ha analizado pierden alrededor del 20 por ciento de su montón en algunos casos! Para los productos desarrollados por ingenieros menos experimentados que no se someten a revisiones periódicas de rendimiento, la pérdida de memoria puede ser aún mayor. Hay suficientes casos en los que, por ejemplo, el 90% de los nodos en un árbol enorme contienen solo uno o dos descendientes (o nada en absoluto), y otras situaciones en las que el montón está obstruido con colecciones de 0, 1 o 2 elementos.
Si encuentra colecciones no utilizadas o subutilizadas en su aplicación, ¿cómo solucionarlas? A continuación se presentan algunas recetas comunes. Aquí, se supone que nuestra colección problemática es una
ArrayList referenciada por el campo de datos
Foo.list .
Si la mayoría de las instancias de la lista nunca se usan, intente inicializarla perezosamente. Entonces el código que antes parecía ...
void addToList(Object x) { list.add(x); }
... debería rehacerse en algo como
void addToList(Object x) { getOrCreateList().add(x); } private list getOrCreateList() {
Tenga en cuenta que a veces necesitará tomar medidas adicionales para abordar la competencia potencial. Por ejemplo, si admite
ConcurrentHashMap , que puede actualizarse mediante varios subprocesos simultáneamente, el código que lo inicializa no debe permitir que dos subprocesos creen dos copias de este mapa al azar:
private Map getOrCreateMap() { if (map == null) {
Si la mayoría de las instancias de su lista o mapa contienen solo unos pocos elementos, intente inicializarlos con una capacidad inicial más adecuada, por ejemplo.
list = new ArrayList(4);
Si sus colecciones están vacías o contienen solo un elemento (o un par clave-valor) en la mayoría de los casos, puede considerar una forma extrema de optimización. Funciona solo si la colección está completamente administrada dentro de la clase actual, es decir, otro código no puede acceder a ella directamente. La idea es que cambie el tipo de su campo de datos, por ejemplo, de Lista a un Objeto más general, de modo que ahora pueda apuntar a una lista real o directamente a un único elemento de la lista. Aquí hay un breve bosquejo:
Obviamente, el código con esta optimización es menos claro y más difícil de mantener. Pero esto puede ser útil si está seguro de que ahorrará mucha memoria o eliminará largas pausas del recolector de basura.
Probablemente ya se haya preguntado: ¿cómo puedo saber qué colecciones de mi aplicación usan memoria y cuánto?
En resumen: es difícil de descubrir sin las herramientas adecuadas. Intentar adivinar la cantidad de memoria utilizada o gastada por las estructuras de datos en una aplicación compleja grande casi nunca conducirá a nada. Y, sin saber exactamente a dónde va la memoria, puede pasar mucho tiempo persiguiendo los objetivos equivocados, mientras que su aplicación continúa obstinadamente
OutOfMemoryError con
OutOfMemoryError .
Por lo tanto, debe verificar un montón de aplicaciones utilizando una herramienta especial. Por experiencia, la forma más óptima de analizar la memoria JVM (medida como la cantidad de información disponible en comparación con el efecto de esta herramienta en el rendimiento de la aplicación) es obtener un volcado de almacenamiento dinámico y luego verlo sin conexión. Un volcado de almacenamiento dinámico es esencialmente una instantánea completa del almacenamiento dinámico. Puede obtenerlo en cualquier momento llamando a la utilidad jmap, o puede configurar la JVM para que se
OutOfMemoryError automáticamente si la aplicación falla con
OutOfMemoryError . Si buscas en Google "JVM heap dump", verás de inmediato una gran cantidad de artículos que explican en detalle cómo obtener un volcado.
Un volcado de almacenamiento dinámico es un archivo binario del tamaño de un almacenamiento dinámico JVM, por lo que solo se puede leer y analizar con herramientas especiales. Existen varias herramientas, tanto de código abierto como comerciales. La herramienta de código abierto más popular es el Eclipse MAT; También hay VisualVM y algunas herramientas menos potentes y menos conocidas. Las herramientas comerciales incluyen perfiladores Java de uso general: JProfiler y YourKit, así como una herramienta diseñada específicamente para el análisis de volcado de montón: JXRay (descargo de responsabilidad: desarrollado por última vez por el autor).
A diferencia de otras herramientas, JXRay analiza inmediatamente el volcado del montón en busca de una gran cantidad de problemas comunes, como líneas repetidas y otros objetos, así como estructuras de datos insuficientemente eficientes. Los problemas con las colecciones descritas anteriormente entran en la última categoría. La herramienta genera un informe con toda la información recopilada en formato HTML. La ventaja de este enfoque es que puede ver los resultados del análisis en cualquier lugar en cualquier momento y compartirlos fácilmente con otros. También puede ejecutar la herramienta en cualquier máquina, incluidas máquinas grandes y potentes, pero "sin cabeza" en el centro de datos.
JXRay calcula la sobrecarga (la cantidad de memoria que ahorrará si se deshace de un problema en particular) en bytes y como un porcentaje del montón utilizado. Combina colecciones de la misma clase que tienen el mismo problema ...

... y luego agrupa las colecciones problemáticas a las que se puede acceder desde alguna raíz del recolector de basura a través de la misma cadena de enlace, como en el ejemplo a continuación

Saber qué cadenas de enlaces y / o campos de datos individuales (por ejemplo,
INodeDirectory.children arriba) indican colecciones que gastan la mayor parte de su memoria le permite identificar de forma rápida y precisa el código responsable del problema, y luego hacer los cambios necesarios.
Por lo tanto, las colecciones Java insuficientemente configuradas pueden desperdiciar mucha memoria. En muchas situaciones, este problema es fácil de resolver, pero a veces puede que necesite modificar su código de manera no trivial para lograr una mejora significativa. Es muy difícil adivinar qué colecciones deben optimizarse para tener el mayor impacto. Para no perder el tiempo optimizando las partes incorrectas del código, debe obtener un volcado de almacenamiento dinámico JVM y analizarlo con la herramienta adecuada.
El fin
Nosotros, como siempre, estamos interesados en sus opiniones y preguntas, que puede dejar aquí o pasar por
una lección abierta y preguntar a nuestros
maestros allí.