Hoy, uno de los principales obstáculos para la introducción del aprendizaje automático en los negocios es la incompatibilidad de las métricas y los indicadores de ML con los que opera la alta dirección. Analista prevé aumento de ganancias? Pero debe comprender en qué casos el aprendizaje automático se convertirá en la causa del aumento y en qué otros factores. Por desgracia, con bastante frecuencia la mejora en las métricas de ML no conduce al crecimiento de las ganancias. Además, a veces la complejidad de los datos es tal que incluso los desarrolladores experimentados pueden elegir métricas incorrectas que no pueden orientarse.
Veamos qué son las métricas de ML y cuándo son apropiadas para usar. Analizaremos errores comunes, y hablaremos sobre qué opciones para resolver el problema pueden ser adecuadas para el aprendizaje automático y los negocios.
Métricas de ML: ¿por qué hay tantas?
Las métricas de aprendizaje automático son muy específicas y, a menudo, engañosas, muestran una
buena cara en un mal juego, un buen resultado para los malos modelos. Para probar modelos y mejorarlos, debe elegir una métrica que refleje adecuadamente la calidad del modelo y cómo medirlo. Por lo general, se utiliza un conjunto de datos de prueba por separado para evaluar la calidad del modelo. Y como saben, elegir la métrica correcta es una tarea difícil.
¿Qué tareas se resuelven con mayor frecuencia con la ayuda del aprendizaje automático? En primer lugar, esto es regresión, clasificación y agrupamiento. Los dos primeros son los llamados entrenamientos con el maestro: hay un conjunto de datos etiquetados, basado en alguna experiencia, necesita predecir el valor establecido. La regresión es una predicción de cierto valor: por ejemplo, cuánto comprará el cliente, cuál es la resistencia al desgaste del material, cuántos kilómetros recorrerá el automóvil antes de la primera avería.
La agrupación es la definición de una estructura de datos al resaltar las agrupaciones (por ejemplo, categorías de clientes), y no tenemos suposiciones acerca de estas agrupaciones. No consideraremos este tipo de problema.
Los algoritmos de aprendizaje automático optimizan (calculando la función de pérdida) la métrica matemática: la diferencia entre la predicción del modelo y el valor verdadero. Pero si la métrica es la suma de las desviaciones, entonces, con el mismo número de desviaciones en ambas direcciones, esta suma será cero, y simplemente no sabremos si hay un error. Por lo tanto, generalmente usan la media absoluta (la suma de los valores absolutos de las desviaciones) o el error cuadrático medio (la suma de los cuadrados de las desviaciones del valor verdadero). A veces la fórmula es complicada: toma el logaritmo o extrae la raíz cuadrada de estas sumas. Gracias a estas métricas, puede evaluar la dinámica de la calidad de los cálculos del modelo, pero para esto necesita comparar el resultado con algo.
Esto no será difícil si ya hay un modelo construido con el que comparar los resultados. Pero, ¿qué pasa si la primera vez que creaste un modelo? En este caso, a menudo se usa el coeficiente de determinación, o R2. El coeficiente de determinación se expresa como:
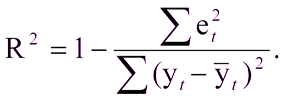
Donde:
R ^ 2 - coeficiente de determinación,
e
t ^ 2 es el error cuadrático medio,
y
t es el valor correcto,
y
t con una cubierta es el valor promedio.
Unidad menos la razón del error cuadrático medio del modelo al error cuadrático medio del valor promedio de la muestra de prueba.Es decir, el coeficiente de determinación nos permite evaluar la mejora de la predicción por el modelo.
A veces sucede que un error en una dirección no es equivalente a un error en la otra. Por ejemplo, si un modelo predice un pedido de productos en el almacén de un almacén, es muy posible cometer un error y pedir un poco más, los productos esperarán en el almacén por su tiempo. Y si el modelo comete un error al revés y ordena menos, puede perder clientes. En tales casos, se usa un error cuantil: las desviaciones positivas y negativas del valor verdadero se tienen en cuenta con diferentes pesos.
En el problema de clasificación, el modelo de aprendizaje automático distribuye objetos en dos clases: el usuario abandona el sitio o no abandona, la pieza está defectuosa o no, etc. La precisión de la predicción a menudo se estima como la relación entre el número de clases definidas correctamente y el número total de predicciones. Sin embargo, esta característica rara vez se puede considerar un parámetro adecuado.
 Fig. 1. Matriz de error para el problema de predicción de devolución del clienteEjemplo
Fig. 1. Matriz de error para el problema de predicción de devolución del clienteEjemplo : si 7 personas de cada 100 asegurados solicitan una compensación, entonces el modelo que predice la ausencia de un evento asegurado tendrá una precisión del 93% sin ningún poder predictivo.
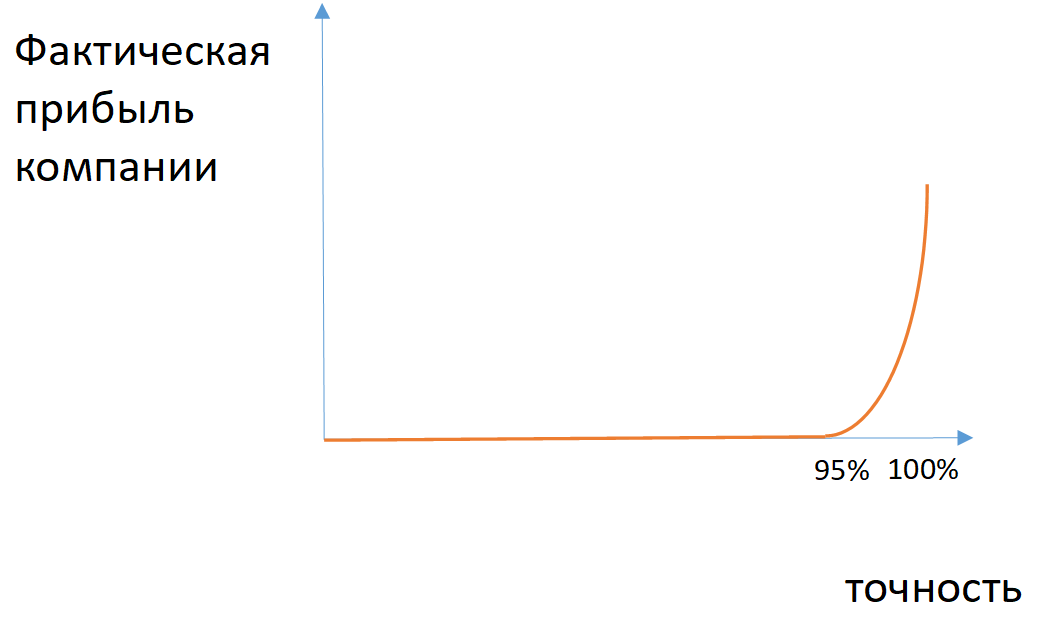 Fig. 2. Un ejemplo de la dependencia del beneficio real de la empresa con la precisión del modelo en el caso de clases desequilibradas
Fig. 2. Un ejemplo de la dependencia del beneficio real de la empresa con la precisión del modelo en el caso de clases desequilibradasPara algunas tareas, puede aplicar las métricas de integridad (el número de objetos de la clase correctamente definidos entre todos los objetos de esta clase) y la precisión (el número de objetos de la clase correctamente definidos entre todos los objetos que el modelo asignó a esta clase). Si es necesario tener en cuenta tanto la integridad como la precisión, aplique la media armónica entre estos valores (medida F1).
Con estas métricas, puede evaluar las clasificaciones realizadas. Sin embargo, muchos modelos predicen la probabilidad de la relación de un modelo con una clase en particular. Desde este punto de vista, es posible cambiar el umbral de probabilidad con respecto al cual se asignarán los elementos a una u otra clase (por ejemplo, si el cliente se va con una probabilidad del 60%, entonces se puede considerar restante). Si no se establece un umbral específico, para evaluar la efectividad del modelo, es posible construir un gráfico de la dependencia de las métricas en diferentes valores de umbral (
curva ROC o curva PR ), tomando como métrica el área bajo la curva seleccionada.
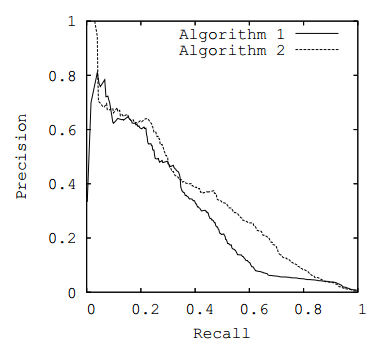 Fig. 3. curva PR
Fig. 3. curva PRMétricas de negocios
Hablando alegóricamente, las métricas comerciales son elefantes: no pueden pasarse por alto, y en uno de esos "elefantes" cabe una gran cantidad de "loros" de aprendizaje automático. La respuesta a la pregunta de qué métricas de ML aumentarán las ganancias depende de la mejora. De hecho, las métricas de negocios están de alguna manera vinculadas al aumento de las ganancias, pero casi nunca logramos asociarlas directamente con ellas. Las métricas intermedias se usan comúnmente, por ejemplo:
- la duración de los bienes en stock y el número de solicitudes de bienes cuando no están disponibles;
- la cantidad de dinero que los clientes están a punto de abandonar;
- La cantidad de material que se guarda en el proceso de fabricación.
Cuando se trata de optimizar un negocio utilizando el aprendizaje automático, la creación de dos modelos siempre está implícita: predictiva y de optimización.
El primero es más complicado, el segundo usa sus resultados. Los errores en el modelo de predicción nos obligan a colocar un margen mayor en el modelo de optimización, por lo que se reduce la cantidad optimizada.
Ejemplo : cuanto menor es la precisión de predecir el comportamiento del cliente o la probabilidad de defectos industriales, menos clientes pueden conservar y menor es la cantidad de materiales ahorrados.
Las métricas generalmente aceptadas del éxito empresarial (EBITDA, etc.) rara vez se obtienen al establecer tareas de LD. Por lo general, debe estudiar a fondo los detalles y aplicar las métricas aceptadas en el campo en el que presentamos el aprendizaje automático (verificación promedio, asistencia, etc.).
Dificultades de traducción
Irónicamente, es más conveniente optimizar los modelos utilizando métricas que son difíciles de entender para los representantes comerciales. ¿Cómo se relaciona el área bajo la curva ROC en el modelo de tonalidad de comentarios con un tamaño de ingresos específico? Desde este punto de vista, el negocio enfrenta dos tareas: ¿cómo medir y cómo maximizar el efecto de introducir el aprendizaje automático?
La primera tarea es más fácil de resolver si tiene datos retrospectivos y al mismo tiempo se pueden nivelar o medir otros factores. Entonces nada le impide comparar los valores obtenidos con datos retrospectivos similares. Pero hay una complicación: la muestra debe ser representativa y al mismo tiempo similar a la que probamos con el modelo.
Ejemplo : necesita encontrar los clientes más similares para saber si su cheque promedio ha aumentado. Pero al mismo tiempo, la muestra de clientes debe ser lo suficientemente grande como para evitar sobretensiones debido a un comportamiento inusual. Este problema se puede resolver creando primero una selección suficientemente grande de clientes similares y utilizándolo para verificar el resultado de sus esfuerzos.
Sin embargo, puede preguntar: cómo traducir la métrica seleccionada a una función de pérdida (que el modelo está minimizando) para el aprendizaje automático. Esta tarea no se puede resolver de inmediato: los desarrolladores del modelo tendrán que profundizar en los procesos empresariales. Pero si utiliza una métrica que depende de la empresa cuando entrena el modelo, la calidad de los modelos aumenta de inmediato. Digamos, si el modelo predice qué clientes se irán, entonces, en el papel de una métrica comercial, puede usar un gráfico donde el número de clientes que se van, según el modelo, se representa en un eje, y la cantidad total de fondos para estos clientes se representa en el otro eje. Con la ayuda de dicho horario, un cliente comercial puede elegir un punto conveniente para él y trabajar con él. Si, usando transformaciones lineales, reducimos el gráfico a una curva PR (precisión en un eje, segundo completo), entonces podemos optimizar el área bajo esta curva simultáneamente con la métrica comercial.
 Fig. 4. Curva de efecto monetario
Fig. 4. Curva de efecto monetarioConclusión
Antes de configurar la tarea para el aprendizaje automático y crear un modelo, debe elegir una métrica razonable. Si va a optimizar el modelo, puede usar una de las métricas estándar como una función de error. Asegúrese de coordinar con el cliente la métrica seleccionada, sus pesos y otros parámetros, convirtiendo las métricas comerciales en modelos ML. En términos de duración, esto se puede comparar con el desarrollo del modelo en sí, pero sin esto no tiene sentido comenzar a trabajar. Si involucra a matemáticos en el estudio de los procesos comerciales, puede reducir en gran medida la probabilidad de errores en las métricas. La optimización efectiva del modelo es imposible sin una comprensión del área temática y una declaración conjunta del problema a nivel de negocios y estadísticas. Y después de todos los cálculos, podrá evaluar las ganancias (o ahorros), dependiendo de cada mejora del modelo.
Nikolay Knyazev ( iRumata ), jefe del grupo de aprendizaje automático, Jet Infosystems