
Recientemente, el phishing ha sido la forma más fácil y popular para los ciberdelincuentes de robar dinero o información. Por ejemplo, no necesita ir muy lejos. El año pasado, las principales empresas rusas se enfrentaron a un ataque a escala sin precedentes: los atacantes registraron masivamente recursos falsos, copias exactas de los sitios de los fabricantes de fertilizantes y petroquímicos para celebrar contratos en su nombre. El daño promedio de tal ataque es de 1.5 millones de rublos, sin mencionar el daño de reputación sufrido por la compañía. En este artículo, hablaremos sobre cómo detectar efectivamente sitios de phishing utilizando análisis de recursos (CSS, imágenes JS, etc.) en lugar de HTML, y cómo un especialista en Data Science puede resolver estos problemas.
Pavel Slipenchuk, Arquitecto de Sistemas de Aprendizaje Automático, Grupo-IB
La epidemia de phishing
Según Group-IB, más de 900 clientes de varios bancos se convierten en víctimas de phishing financiero solo en Rusia todos los días: esta cifra es 3 veces la cantidad diaria de víctimas de malware. El daño de un ataque de phishing en un usuario varía de 2,000 a 50,000 rublos. Los estafadores no solo copian el sitio web de una empresa o un banco, sus logotipos y colores, contenido, datos de contacto de la empresa, registran un nombre de dominio similar, sino que también anuncian activamente sus recursos en redes sociales y motores de búsqueda. Por ejemplo, intentan llevar enlaces a sus sitios de phishing a la parte superior de los resultados de búsqueda para la solicitud "Transferir dinero a una tarjeta". La mayoría de las veces, los sitios falsos se crean precisamente para robar dinero cuando se transfieren de una tarjeta a otra o con un pago instantáneo por los servicios de los operadores móviles.
El phishing (esp. Phishing, de pesca - pesca, pesca) es una forma de fraude en Internet, cuyo propósito es engañar a la víctima para que brinde información confidencial al estafador. La mayoría de las veces, roban contraseñas de acceso a cuentas bancarias para robar dinero, cuentas de redes sociales (para extorsionar dinero o enviar spam en nombre de la víctima), suscribirse a servicios pagos, enviar correo o infectar una computadora, convirtiéndola en un enlace en la red de bots.
Por métodos de ataque, hay 2 tipos de phishing dirigidos a usuarios y empresas:
- Sitios de phishing que copian el recurso original de la víctima (bancos, aerolíneas, tiendas en línea, empresas, agencias gubernamentales, etc.).
- Correos electrónicos, correos electrónicos, sms, mensajes de phishing en redes sociales, etc.
Los usuarios a menudo atacan a las personas, y el umbral para ingresar a este segmento del negocio criminal es tan bajo que una "inversión" mínima y conocimientos básicos son suficientes para implementarlo. La propagación de este tipo de fraude también se ve facilitada por los kits de phishing, los programas de creación de sitios de phishing que se pueden comprar libremente en Darknet en foros de hackers.
Los ataques a empresas o bancos son diferentes. Son llevados a cabo por atacantes técnicamente más inteligentes. Como regla, las grandes empresas industriales, tiendas en línea, aerolíneas y, con mayor frecuencia, bancos, son elegidas como víctimas. En la mayoría de los casos, el phishing se reduce a enviar un correo electrónico con un archivo infectado adjunto. Para que un ataque de este tipo tenga éxito, el "personal" del grupo debe tener especialistas en escribir código malicioso, y programadores para automatizar sus actividades, y personas que puedan llevar a cabo una inteligencia primaria sobre la víctima y encontrar debilidades en ella.
En Rusia, según nuestras estimaciones, hay 15 grupos criminales involucrados en phishing dirigidos a instituciones financieras. La cantidad de daño siempre es pequeña (diez veces menos que la de los troyanos bancarios), pero el número de víctimas que atraen a sus sitios se estima en miles cada día. Alrededor del 10-15% de los visitantes de sitios de phishing financiero ingresan sus datos ellos mismos.
Cuando aparece una página de phishing, la factura dura horas, y a veces incluso minutos, porque los usuarios incurren en graves daños financieros y, en el caso de las empresas, también en la reputación. Por ejemplo, algunas páginas de phishing exitosas estuvieron disponibles por menos de un día, pero pudieron infligir daños en cantidades de 1,000,000 de rublos.
En este artículo, nos detendremos en el primer tipo de phishing: los sitios de phishing. Los recursos que son "sospechosos" de phishing se pueden detectar fácilmente utilizando varios medios técnicos: honeypots, rastreadores, etc., sin embargo, es problemático asegurarse de que realmente sean phishing e identificar la marca atacada. Veamos cómo resolver este problema.
Pesca
Si una marca no controla su reputación, se convierte en un objetivo fácil. Es necesario tomar la iniciativa de los delincuentes inmediatamente después de registrar sus sitios falsos. En la práctica, la búsqueda de una página de phishing se divide en 4 etapas:
- Formación de muchas direcciones sospechosas (URL) para escaneos de phishing (rastreadores, honeypots, etc.).
- La formación de muchas direcciones de phishing.
- Clasificación de direcciones de phishing ya detectadas por área de actividad y tecnología atacada, por ejemplo, "RBS :: Sberbank Online" o "RBS :: Alfa-Bank".
- Busca una página de donantes.
La implementación de los párrafos 2 y 3 recae sobre los hombros de especialistas en ciencia de datos.
Después de eso, ya puede tomar medidas activas para bloquear la página de phishing. En particular:
- poner en la lista negra los productos del Grupo IB y los productos de nuestros socios;
- envíe cartas de forma automática o manual al propietario de la zona de dominio con una solicitud para eliminar la URL de phishing;
- enviar cartas al servicio de seguridad de la marca atacada;
- etc.

Métodos de análisis HTML
La solución clásica para las tareas de verificar direcciones de phishing sospechosas y detectar automáticamente una marca afectada son varias formas de analizar páginas fuente HTML. Lo más simple es escribir expresiones regulares. Es divertido, pero este truco aún funciona. Y hoy, la mayoría de los phishers novatos simplemente copian contenido del sitio original.
Además, los investigadores pueden desarrollar sistemas anti-phishing muy efectivos. Pero en este caso, debe examinar la página HTML. Además, estas soluciones no son universales: su desarrollo requiere una base de las propias "ballenas". Algunos kits de phishing pueden no ser conocidos por el investigador. Y, por supuesto, el análisis de cada nueva "ballena" es un proceso bastante laborioso y costoso.
Todos los sistemas de detección de phishing basados en el análisis de páginas HTML dejan de funcionar después de la ofuscación de HTML. Y en muchos casos es suficiente simplemente cambiar el marco de la página HTML.
Según el Grupo IB, en este momento no hay más del 10% de dichos sitios de phishing, pero incluso perder uno puede costarle mucho a la víctima.
Por lo tanto, para que un pescador evite el bloqueo, es suficiente simplemente cambiar el marco HTML, con menos frecuencia, para ofuscar la página HTML (confundiendo el marcado y / o cargando el contenido a través de JS).
Declaración del problema. Método basado en recursos
Los métodos basados en el análisis de los recursos utilizados son mucho más efectivos y universales para detectar páginas de phishing. Un recurso es cualquier archivo que se carga al representar una página web (todas las imágenes, hojas de estilo en cascada (CSS), archivos JS, fuentes, etc.).
En este caso, puede construir un gráfico bipartito, donde algunos vértices serán direcciones sospechosas de phishing, mientras que otros serán recursos asociados con ellos.
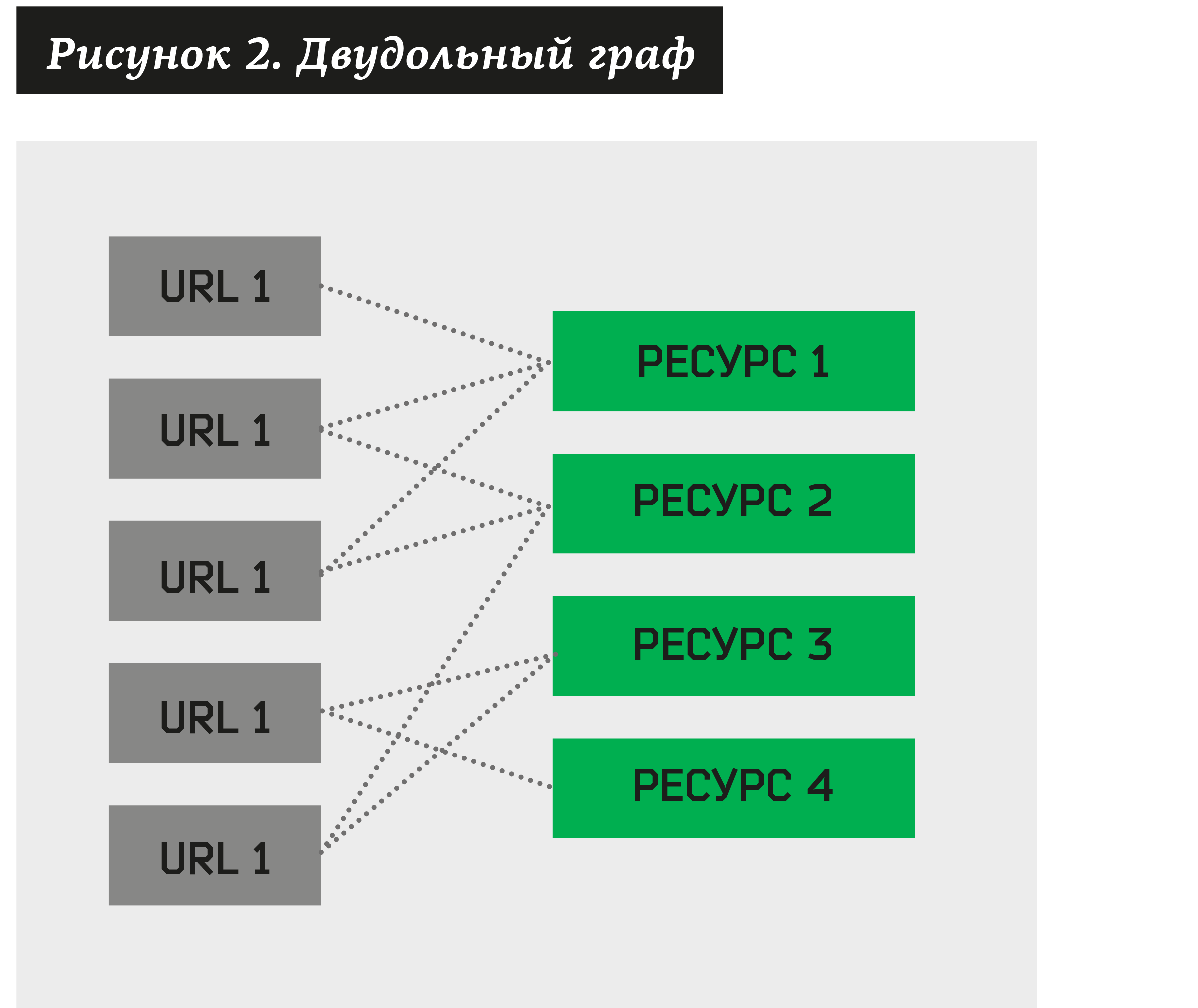
La tarea de agrupamiento surge: encontrar una colección de dichos recursos que posean un número bastante grande de URL diferentes. Al construir dicho algoritmo, podemos descomponer cualquier gráfico bipartito en grupos.
La hipótesis es que, con base en datos reales, con un alto grado de probabilidad, se puede decir que el clúster contiene una colección de URL que pertenecen a la misma marca y son generadas por un kit de phishing. Luego, para probar esta hipótesis, cada grupo puede enviarse para su verificación manual al CERT (Centro de Respuesta a Incidentes de Seguridad de la Información). El analista, a su vez, le daría el estado del clúster: +1 ("aprobado") o –1 (rechazado). Un analista también asignaría una marca atacada a todos los grupos aprobados. Este "trabajo manual" finaliza: el resto del proceso está automatizado. En promedio, un grupo aprobado cuenta con 152 direcciones de suplantación de identidad (datos a junio de 2018) y, a veces, incluso hay grupos de 500 a 1000 direcciones. El analista dedica aproximadamente 1 minuto a aprobar o refutar el grupo.
Luego, todos los grupos rechazados se eliminan del sistema y, después de un tiempo, todas sus direcciones y recursos se vuelven a alimentar a la entrada del algoritmo de agrupación. Como resultado, obtenemos nuevos grupos. Y nuevamente los enviamos para verificación, etc.
Por lo tanto, para cada dirección recién recibida, el sistema debe hacer lo siguiente:
- Extraiga muchos de los recursos para el sitio.
- Verifique al menos un clúster previamente aprobado.
- Si la URL pertenece a algún clúster, extraiga automáticamente el nombre de la marca y realice una acción (notifique al cliente, elimine el recurso, etc.).
- Si no se puede asignar un clúster a los recursos, agregue la dirección y los recursos al gráfico bipartito. En el futuro, esta URL y estos recursos participarán en la formación de nuevos grupos.
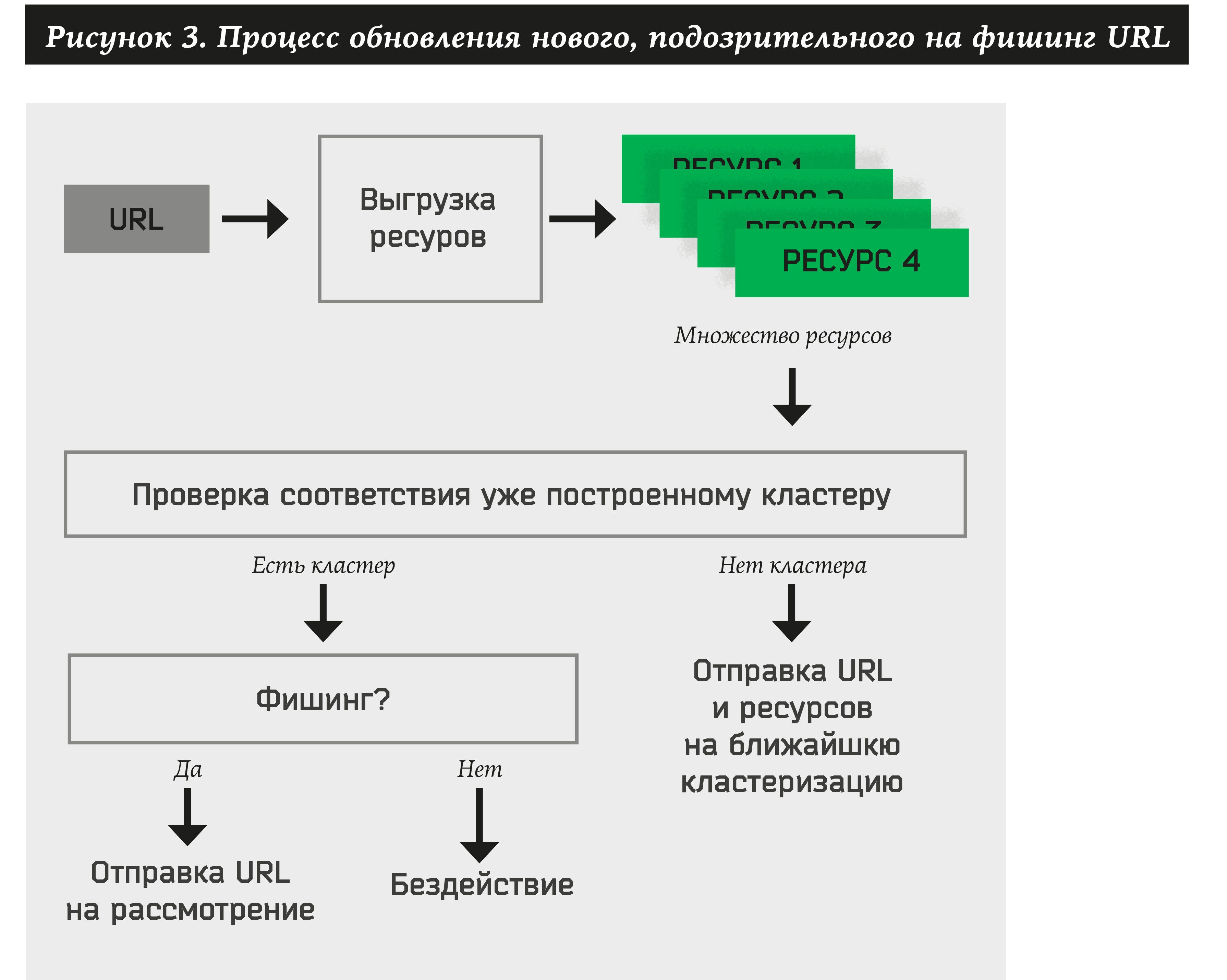
Algoritmo simple de agrupación de recursos
Uno de los matices más importantes que debe tener en cuenta un especialista de Data Science en seguridad de la información es el hecho de que una persona es su oponente. Por esta razón, las condiciones y los datos para el análisis cambian muy rápidamente. Una solución que soluciona notablemente el problema ahora, después de 2-3 meses, puede dejar de funcionar en principio. Por lo tanto, es importante crear mecanismos universales (torpes), si es posible, o los sistemas más flexibles que puedan desarrollarse rápidamente. El especialista en ciencia de datos en seguridad de la información no puede resolver el problema de una vez por todas.
Los métodos de agrupación estándar no funcionan debido a la gran cantidad de funciones. Cada recurso se puede representar como un atributo booleano. Sin embargo, en la práctica, obtenemos diariamente de 5,000 direcciones de sitios web, y cada una de ellas contiene un promedio de 17.2 recursos (datos de junio de 2018). La maldición de la dimensionalidad ni siquiera permite cargar datos en la memoria, y mucho menos construir algoritmos de agrupamiento.
Otra idea es intentar agruparse en grupos utilizando varios algoritmos de filtrado colaborativos. En este caso, era necesario crear otra característica: pertenecer a una marca en particular. La tarea se reducirá al hecho de que el sistema debe predecir la presencia o ausencia de este signo para las URL restantes. El método dio resultados positivos, pero tenía dos inconvenientes:
- para cada marca era necesario crear sus propias características para el filtrado colaborativo;
- necesitaba una muestra de entrenamiento.
Recientemente, cada vez más empresas quieren proteger su marca en Internet y solicitan automatizar la detección de sitios de phishing. Cada nueva marca tomada bajo protección agregaría un nuevo atributo. Y crear una muestra de capacitación para cada nueva marca es un trabajo manual adicional y tiempo.
Comenzamos a buscar una solución a este problema. Y encontraron una manera muy simple y efectiva.
Para comenzar, crearemos pares de recursos utilizando el siguiente algoritmo:
- Tome todo tipo de recursos (los denotamos como a) para los que hay al menos direcciones N1, denotamos esta relación como # (a) ≥ N1.
- Construimos todo tipo de pares de recursos (a1, a2) y seleccionamos solo aquellos para los que habrá al menos direcciones N2, es decir # (a1, a2) ≥ N2.
Luego, de manera similar, consideramos pares que consisten en pares obtenidos en el párrafo anterior. Como resultado, obtenemos cuatro: (a1, a2) + (a3, a4) → (a1, a2, a3, a4). Además, si al menos un elemento está presente en uno de los pares, en lugar de cuatro, obtendremos triples: (a1, a2) + (a2, a3) → (a1, a2, a3). Del conjunto resultante, dejamos solo los cuatro y triples que corresponden a al menos direcciones N3. Y así sucesivamente ...
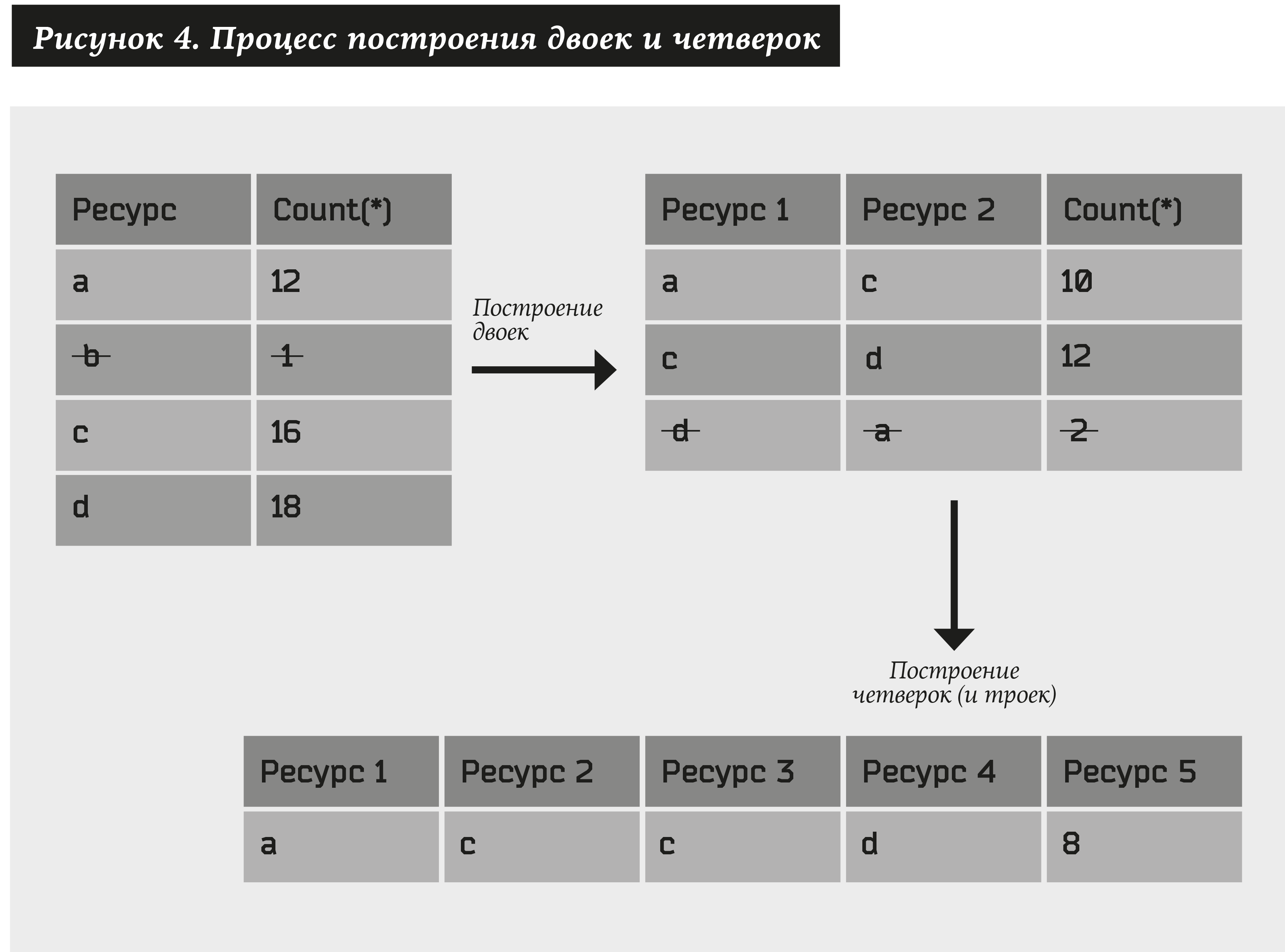
Puede obtener múltiples recursos de longitud arbitraria. Limite el número de pasos a U. Entonces N1, N2 ... NU son los parámetros del sistema.
Los valores N1, N2 ... NU son los parámetros del algoritmo, se configuran manualmente. En el caso general, tenemos CL2 diferentes pares, donde L es el número de recursos, es decir La dificultad para construir pares será O (L2). Luego se crea un quad a partir de cada par. Y en teoría, probablemente obtengamos O (L4). Sin embargo, en la práctica, estos pares son mucho más pequeños, y con un gran número de direcciones, la dependencia O (L2log L) se obtuvo empíricamente. Además, los pasos posteriores (convertir dos en cuatro, cuádruples en ocho, etc.) son insignificantes.
Cabe señalar que L es el número de URL no agrupadas. Todas las URL que ya se pueden atribuir a cualquier clúster aprobado previamente no entran en la selección para la agrupación en clúster.
En la salida, puede crear muchos clústeres que consisten en los conjuntos de recursos más grandes posibles. Por ejemplo, si existe (a1, a2, a3, a4, a5) que satisfacen los límites de Ni, se debe eliminar del conjunto de grupos (a1, a2, a3) y (a4, a5).
Luego, cada grupo recibido se envía para verificación manual, donde el analista del CERT le asigna el estado: +1 ("aprobado") o –1 ("rechazado"), y también indica si las URL que caen en el grupo son sitios de phishing o legítimos.
Cuando agrega un nuevo recurso, el número de URL puede disminuir, permanecer igual, pero nunca aumentar. Por lo tanto, para cualquier recurso a1 ... aN la relación es verdadera:
# (a1) ≥ # (a1, a2) ≥ # (a1, a2, a3) ≥ ... ≥ # (a1, a2, ..., aN).
Por lo tanto, es aconsejable establecer los parámetros:
N1 ≥ N2 ≥ N3 ≥ ... ≥ NU.
En la salida, entregamos todo tipo de grupos para verificación. En la fig. 1 al comienzo del artículo presenta grupos reales para los cuales todos los recursos son imágenes.
Usando el algoritmo en la práctica
¡Tenga en cuenta que ahora ya no necesita explorar kits de phishing! El sistema se agrupa automáticamente y encuentra la página de phishing necesaria.
Todos los días, el sistema recibe de 5,000 páginas de phishing y construye un total de 3 a 25 nuevos grupos por día. Para cada clúster, se carga una lista de recursos, se crean muchas capturas de pantalla. Este clúster se envía al análisis CERT para su confirmación o rechazo.
Al inicio, la precisión del algoritmo era baja: solo el 5%. Sin embargo, después de 3 meses, el sistema mantuvo la precisión del 50 al 85%. De hecho, la precisión no importa! Lo principal es que los analistas tienen tiempo para ver los grupos. Por lo tanto, si el sistema, por ejemplo, genera alrededor de 10,000 clústeres por día y solo tiene un analista, deberá cambiar los parámetros del sistema. Si no más de 200 por día, esta es una tarea factible para una persona. Como muestra la práctica, el análisis visual en promedio toma aproximadamente 1 minuto.
La integridad del sistema es de aproximadamente el 82%. El 18% restante son casos únicos de phishing (por lo tanto, no se pueden agrupar), o phishing, que tiene una pequeña cantidad de recursos (no hay nada para agrupar), o páginas de phishing que fueron más allá de los límites de los parámetros N1, N2 ... NU.
Un punto importante: ¿con qué frecuencia comenzar una nueva agrupación en URL nuevas y no entregadas? Hacemos esto cada 15 minutos. Además, dependiendo de la cantidad de datos, el tiempo de agrupamiento en sí toma de 10 a 15 minutos. Esto significa que después de la aparición de la URL de phishing hay un retraso de 30 minutos.
A continuación se muestran 2 capturas de pantalla del sistema GUI: firmas para detectar el phishing en las redes sociales VKontakte y Bank Of America.
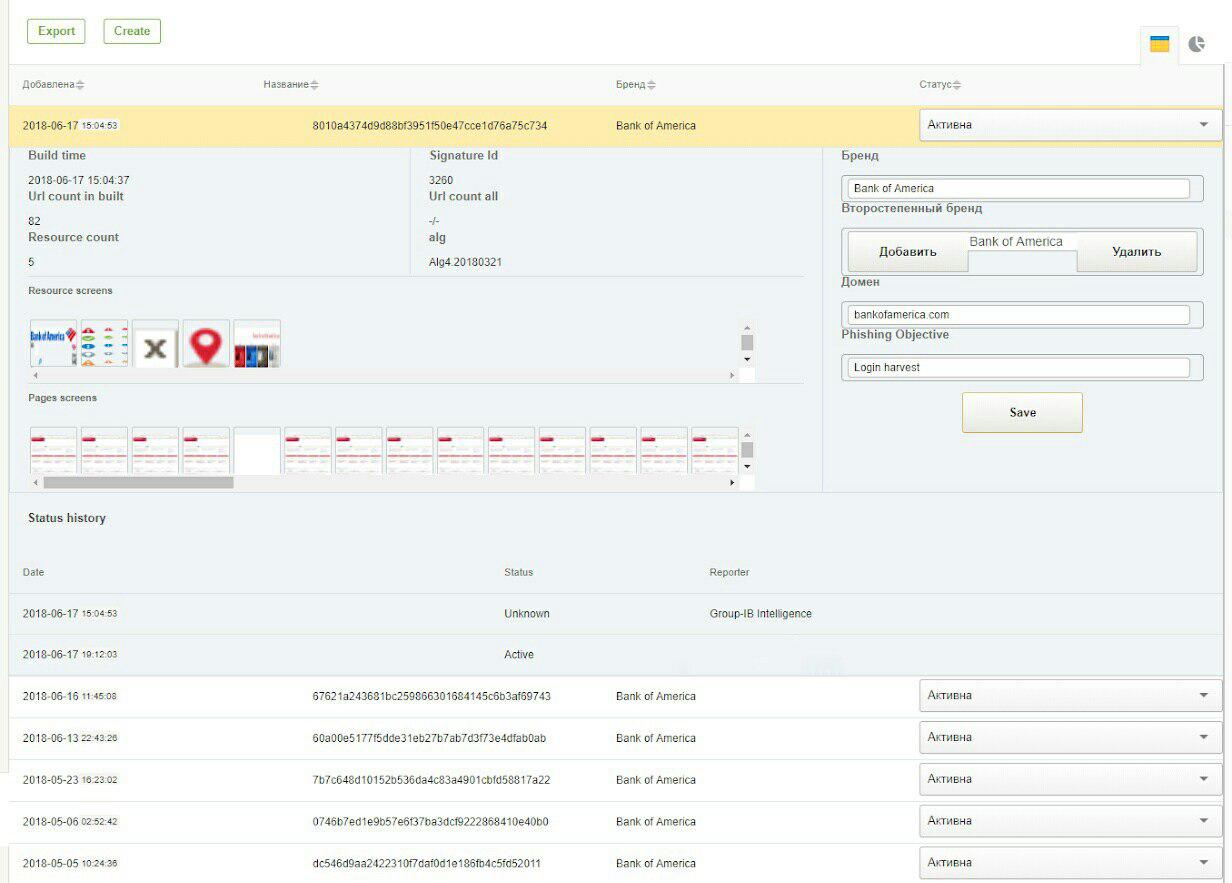
Cuando el algoritmo no funciona
Como se mencionó anteriormente, el algoritmo no funciona en principio si no se alcanzan los límites especificados por los parámetros N1, N2, N3 ... NU, o si el número de recursos es demasiado pequeño para formar el grupo necesario.
Un phisher puede omitir el algoritmo creando recursos únicos para cada sitio de phishing. Por ejemplo, en cada imagen puede cambiar un píxel, y para las bibliotecas JS y CSS cargadas use ofuscación. En este caso, es necesario desarrollar un algoritmo hash comparable (hash perceptual) para cada tipo de documentos cargados. Sin embargo, estos problemas están más allá del alcance de este artículo.
Poniendo todo junto
Conectamos nuestro módulo con los habituales reguladores HTML, los datos obtenidos de Threat Intelligence (sistema de inteligencia cibernética), y obtenemos una plenitud del 99,4%. Por supuesto, esta es la integridad de los datos que Threat Intelligence ya ha clasificado previamente como phishing sospechosos.
Nadie conoce la integridad de todos los datos posibles, ya que es imposible cubrir toda Darknet en principio, sin embargo, según los informes de Gartner, IDC y Forrester, Group-IB es uno de los principales proveedores internacionales de soluciones de Inteligencia de amenazas en sus capacidades.
¿Qué pasa con las páginas de phishing sin clasificar? Alrededor de 25-50 de ellos al día. Se pueden verificar manualmente. En general, siempre hay trabajo manual en cualquier tarea que sea bastante difícil para Data Sciense en el campo de la seguridad de la información, y cualquier denuncia de 100 por ciento de automatización es una ficción de marketing. La tarea de un especialista de Data Sciense es reducir el trabajo manual en 2–3 órdenes de magnitud, haciendo que el trabajo del analista sea lo más eficiente posible.
Artículo publicado en
JETINFO