Captura de pantalla de los datos recopilados:
 Los sistemas de seguridad modernos son MUY glotones con los recursos.
Los sistemas de seguridad modernos son MUY glotones con los recursos. Por qué Porque cuentan más que muchos servidores de producción y sistemas de inteligencia empresarial.
¿Qué piensan ellos? Te lo explicaré ahora. Comencemos con uno simple: por convención, la primera generación de dispositivos de protección era muy simple, a nivel de "arranque" y "no arranque". Por ejemplo, un firewall permitió el tráfico de acuerdo con ciertas reglas y no permitió el tráfico de acuerdo con otras. Naturalmente, no se necesita potencia informática especial para esto.
La próxima generación ha adquirido reglas más complejas. Por lo tanto, había sistemas de reputación que, dependiendo de las acciones extrañas del usuario y los cambios en los procesos comerciales, les asignaban una calificación de confiabilidad de acuerdo con plantillas predefinidas y establecían umbrales de operación manualmente.
Ahora los sistemas UBA (User Behavior Analytics) analizan el comportamiento de los usuarios, comparándolos con otros empleados de la compañía y evalúan la consistencia y la corrección de la acción de cada empleado. Esto se realiza debido a los métodos de Data Lake y al uso intensivo de recursos, pero al procesamiento automatizado mediante algoritmos de aprendizaje automático, principalmente porque lleva varios miles de días-hombre escribir todos los escenarios posibles con sus manos.
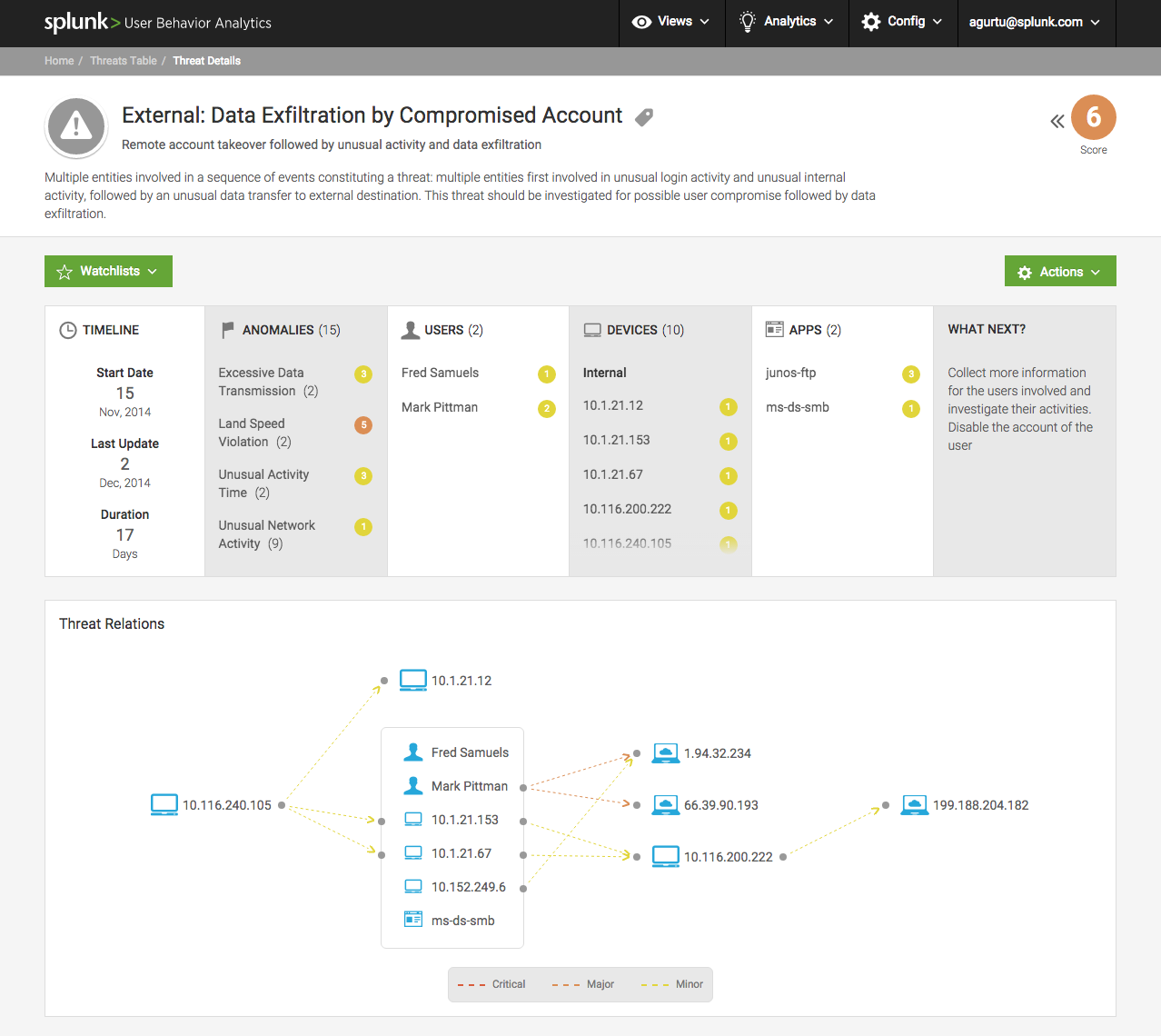
SIEM clásico
Hasta aproximadamente 2016, el enfoque se consideraba progresivo cuando todos los eventos de todos los nodos de la red se recopilan en un lugar donde se encuentra el servidor de análisis. El servidor de análisis puede recopilar, filtrar eventos y asignarlos a reglas de correlación. Por ejemplo, si se inicia una grabación masiva de archivos en alguna estación de trabajo, puede ser un signo de un virus de cifrado o no. Pero por si acaso, el sistema enviará una notificación al administrador. Si hay varias estaciones, aumenta la probabilidad de implementación del malware. Debemos dar la alarma.
Si un usuario llamó a algún dominio extraño registrado hace un par de semanas, y después de un par de minutos se fue toda esta música de color, entonces es casi seguro que se trata de un virus de cifrado. Es necesario apagar la estación de trabajo y aislar el segmento de red, mientras se notifica a los administradores.
SIEM comparó datos de DLP, firewall, antispam, etc., y esto permitió responder muy bien a diferentes amenazas. El punto débil eran estos patrones y factores desencadenantes: qué considerar una situación peligrosa y qué no. Además, como en el caso de los virus y varios DDoS difíciles, los especialistas del centro SOC comenzaron a formar sus bases de signos de ataque. Para cada tipo de ataque, se consideró un escenario, se destacaron los síntomas, se les asignaron acciones adicionales. Todo esto requería un continuo refinamiento y ajuste del sistema en modo 24 por 7.
Funciona, no lo toques, ¡pero todo funciona bien!
Por eso es imposible prescindir de UBA? El primer problema es que es imposible prescribir con las manos. Porque los diferentes servicios se comportan de manera diferente, y los diferentes usuarios también. Si registra eventos para el usuario promedio dentro de la empresa, el departamento de soporte, contabilidad, licitaciones y administradores serán muy distinguidos. El administrador desde el punto de vista de dicho sistema es claramente un usuario malintencionado, porque hace mucho y se arrastra activamente en él. El soporte es malicioso porque se conecta a todos. La contabilidad transmite datos a través de túneles cifrados. Y el departamento de licitación fusiona constantemente los datos de la empresa al publicar la documentación.
Conclusión: es necesario prescribir escenarios de uso de recursos para cada uno. Entonces más profundo. Entonces aún más profundo. Luego, algo cambia en los procesos (y esto sucede todos los días) y debe prescribirse nuevamente.
Sería lógico usar algo así como un "promedio móvil" cuando la norma para el usuario se determina automáticamente. Volveremos a esto.
El segundo problema fue que los atacantes se volvieron mucho más precisos. Anteriormente, el drenaje de datos, incluso si se perdía el momento de la piratería, era bastante fácil de detectar, por ejemplo, los piratas informáticos podían cargar un archivo de interés para ellos por correo o alojamiento de archivos y, en el mejor de los casos, cifrarlo en un archivo para evitar ser detectado por el sistema DLP.
Ahora todo es más interesante. Esto es lo que hemos visto en nuestros centros SOC durante el año pasado.
- Esteganografía a través del envío de fotos a Facebook. El malware registrado con FB y suscrito al grupo. Cada foto publicada en el grupo estaba equipada con un fragmento de datos incorporado que contenía instrucciones para el malware. Teniendo en cuenta las pérdidas durante la compresión JPEG, resultó transferir unos 100 bytes por imagen. Además, el malware mismo publicó 2-3 fotos al día en la red social, lo que fue suficiente para transferir inicios de sesión / contraseñas fusionadas a través de mimikatz.
- Rellenar formularios en los sitios. El malware ejecutó un simulador de acción del usuario, fue a ciertos sitios, encontró formularios de "comentarios" allí y envió datos a través de ellos, codificando datos binarios en BASE64. Esto ya lo hemos captado en un sistema de nueva generación. En el SIEM clásico, sin saber acerca de tal método de envío, lo más probable es que ni siquiera se den cuenta de nada.
- De manera estándar, por desgracia, de manera estándar, mezclaron datos con el tráfico DNS. Hay muchas tecnologías para la esteganografía en DNS y, en general, la construcción de túneles a través de DNS, aquí el énfasis no estaba en sondear ciertos dominios, sino en los tipos de solicitud. El sistema generó una pequeña alarma sobre el crecimiento del tráfico DNS para el usuario. Los datos se enviaron lentamente y a diferentes intervalos para dificultar el análisis con características de seguridad.
Para la penetración, generalmente usan virus estrictamente personalizados creados directamente bajo los usuarios de la compañía objetivo. Además, los ataques a menudo pasan por un enlace intermedio. Por ejemplo, al principio el contratista se ve comprometido, y luego a través de él se ingresa el malware en la empresa principal.
Los virus de los últimos años casi siempre se encuentran estrictamente en la RAM y se eliminan en la primera perspectiva: énfasis en la ausencia de rastros. El análisis forense en tales condiciones es muy difícil.
Resultado general: SIEM hace un mal trabajo. Mucho de lo que se pierde de vista. Algo como esto, apareció un lugar vacío en el mercado: para que el sistema no tuviera que ajustarse al tipo de ataque, pero ella misma entendió lo que estaba mal.
¿Cómo se "entendió" a sí misma?
Los primeros sistemas de seguridad de reputación fueron los módulos antifraude para la protección contra el lavado de dinero en los bancos. Para el banco, lo principal es identificar todas las transacciones fraudulentas. Es decir, no es una pena retomar un poco, lo principal es que el operador humano entiende qué mirar al principio. Y no estaba abrumado por alarmas muy pequeñas.
Los sistemas funcionan así:
- Construyen un perfil de usuario basado en muchos parámetros. Por ejemplo, cómo suele gastar dinero: lo que compra, cómo compra, qué tan rápido ingresa un código de confirmación, desde qué dispositivos lo hace, etc.
- La capa lógica verifica si es posible llegar a tiempo desde el punto donde se realizó el pago, hasta otro punto en el transporte durante el período entre transacciones. Si la compra se realiza en otra ciudad, se verifica si el usuario viaja a menudo a otras ciudades, si se encuentra en otro país, si el usuario visita con frecuencia otros países, y un boleto de avión comprado recientemente agrega la posibilidad de que la alarma no sea necesaria.
- Módulo de reputación: si el usuario hace todo en el marco de su comportamiento normal, entonces, por sus acciones, se otorgan puntos positivos (muy lentamente) y, en el marco de atípico, negativos.
Hablemos de esto último con más detalle.
Ejemplo 1. Toda tu vida te compraste un pastel y una cola en McDonald's los viernes, y de repente compraste 500 rublos el martes por la mañana. Menos 2 puntos por un tiempo no estándar, menos 3 puntos por una compra no estándar. El umbral de alarma para usted está establecido en –20. No pasa nada
Para aproximadamente 5-6 de tales compras, retirará estos puntos a cero, porque el sistema recordará que es normal que vaya a McDonald's el martes por la mañana. Por supuesto, simplifico enormemente, pero la lógica del trabajo es aproximadamente la misma.
Ejemplo 2. Toda tu vida te compraste varias cosas pequeñas como usuario habitual. Pagará en el supermercado (el sistema ya "sabe" cuánto come habitualmente y dónde compra con más frecuencia, o mejor dicho, no lo sabe, pero simplemente escribe en su perfil), luego compre un boleto para el metro durante un mes u ordene algo pequeño a través de la tienda en línea. Y ahora compras un piano en Hong Kong por 8 mil dólares. Podría? Podría. Veamos los puntos: –15 por lo que parece un fraude estándar, –10 por una cantidad no estándar, –5 por un lugar y tiempo no estándar, –5 por otro país sin comprar un boleto, –7 por no haber usado nada antes se llevaron al extranjero, +5 por su dispositivo estándar, +5 por lo que otros usuarios del banco compraron allí.
El umbral de alarma para usted está establecido en –20. La transacción se "suspende", un empleado del IB del banco comienza a comprender la situación. Este es un caso muy simple. Lo más probable es que, después de 5 minutos, lo llame y le diga: "¿Realmente decidió comprar algo en una tienda de música en Hong Kong a las 4 a.m. por 8 mil dólares?" Si responde que sí, se saltearán la transacción. Los datos caerán en el perfil como una vez que se completa una acción, luego, para acciones similares, se darán menos puntos negativos hasta que se conviertan en la norma.
Como dije, realmente, realmente simplifico. Los bancos han estado invirtiendo en sistemas de reputación durante años y los han estado perfeccionando durante años. De lo contrario, un montón de mulas retirarían dinero muy rápido.
¿Cómo se transfiere esto a la seguridad de la información empresarial?
Con base en los algoritmos antifraude y antilavado de dinero, aparecen los sistemas de análisis de comportamiento. Se recopila un perfil de usuario completo: qué tan rápido imprime, a qué recursos accede, con quién interactúa, con qué software lanza, en general, todo lo que el usuario hace todos los días.
Un ejemplo El usuario a menudo interactúa con 1C y a menudo ingresa datos allí, y de repente comienza a descargar toda la base de datos en docenas de pequeños informes. Su comportamiento va más allá del comportamiento estándar para un usuario así, pero se puede comparar con el comportamiento de perfiles similares por tipo (lo más probable, estos serán otros contadores): está claro que tienen una semana de informes en ciertos momentos y todos lo hacen. Los números son los mismos, no hay otras diferencias, la alarma no sube.
Otro ejemplo. Un usuario ha trabajado con una bola de archivos toda su vida, grabando un par de docenas de documentos al día, y de repente comenzó a tomar cientos y miles de archivos. Y otro DLP dice que envía algo importante. Tal vez el departamento de licitación ha comenzado los preparativos para la competencia, tal vez la "rata" está filtrando datos a los competidores. El sistema, por supuesto, no lo sabe, sino que simplemente describe su comportamiento y alarma a los guardias de seguridad. Fundamentalmente, el comportamiento de un nuevo empleado, soporte técnico o CEO, puede diferir poco del comportamiento del "cosaco maltratado", y la tarea del personal de seguridad es decirle al sistema que este es un comportamiento normal. El perfil seguirá de todos modos, y si la cuenta del director general se ve comprometida y la reputación salta a los puntos, la alarma aumentará.
Los perfiles de usuario dan lugar a reglas para el sistema UBA. Más precisamente, miles de heurísticas que cambian regularmente. Cada grupo de usuarios tiene sus propios principios. Por ejemplo, los usuarios de este tipo envían 100 MB por día, los usuarios del otro envían 1 GB por día, si no es un fin de semana. Y así sucesivamente. Si el primero envía 5 GB, esto es sospechoso. Y si es el segundo, entonces habrá puntos negativos, pero no romperán el umbral de alarma. Pero si en las cercanías activó el DNS para dominios nuevos sospechosos, entonces habrá un par de puntos negativos más y la alarma ya ocurrirá.
El enfoque es que esta no es la regla "si hubo consultas DNS extrañas y luego el tráfico saltó, entonces ...", y la regla "si la reputación alcanzó –20, entonces ..." - cada fuente individual de puntos para la reputación del usuario o proceso es independiente y determinada exclusivamente la norma de su comportamiento. Automáticamente
Al mismo tiempo, al principio, el departamento de seguridad de la información ayuda a capacitar al sistema y determinar cuál es la norma y qué no, y luego el sistema se adapta, se capacita nuevamente en el tráfico real y los registros de actividad del usuario.
Lo que ponemos
Como integrador de sistemas, brindamos a nuestros clientes un servicio para la gestión operativa de la seguridad de la información (servicio
SOC CROC gestionado). Un componente clave junto con sistemas como Gestión de activos, Gestión de vulnerabilidades, Pruebas de seguridad e Inteligencia de amenazas, disponibles en nuestra infraestructura en la nube, es el vínculo entre el SIEM clásico y la UBA proactiva. Al mismo tiempo, dependiendo de los deseos del cliente, para UBA podemos utilizar soluciones industriales de grandes proveedores y nuestro propio sistema analítico basado en el paquete Hadoop + Hive + Redis + Splunk Analytics para Hadoop (Hunk).
Las siguientes soluciones están disponibles para el análisis de comportamiento de nuestro SOC CROC en la nube o de acuerdo con el modelo local:
- Exabeam: quizás el sistema UBA más fácil de usar que le permite investigar rápidamente un incidente a través de la tecnología de seguimiento de usuarios, que conecta la actividad en la infraestructura de TI (por ejemplo, inicio de sesión de la base de datos local en una cuenta SA) con un usuario real. Incluye alrededor de 400 modelos de calificación de riesgo que agregan puntos de penalización al usuario por cada acción extraña o sospechosa;
- Securonix: un sistema de análisis de comportamiento muy hambriento de recursos pero extremadamente efectivo. El sistema se coloca en la parte superior de la plataforma Big Data, casi 1000 modelos están disponibles de fábrica. La mayoría de ellos utilizan tecnología de agrupamiento patentada para la actividad del usuario. El motor es muy flexible, puede rastrear y agrupar cualquier campo del formato CEF, comenzando por la desviación del número promedio de solicitudes por día por los registros del servidor web y terminando con la identificación de nuevas interacciones de red para el tráfico de usuarios;
- Splunk UBA: una buena adición a Splunk ES. La base de reglas lista para usar es pequeña, pero con referencia a la Cadena de asesinatos, que le permite no distraerse con incidentes menores y centrarse en un pirata informático real. Y, por supuesto, tenemos a nuestra disposición todo el poder del procesamiento de datos estadísticos en Splunk Machine Learning Toolkit y un análisis retrospectivo de todo el volumen de datos acumulados.
Y para segmentos críticos, ya sea un sistema de control de procesos automatizado o una aplicación comercial clave, colocamos sensores adicionales para recopilar análisis forenses y hanitospes avanzados para desviar la atención del pirata informático de los sistemas productivos.
¿Por qué un mar de recursos?
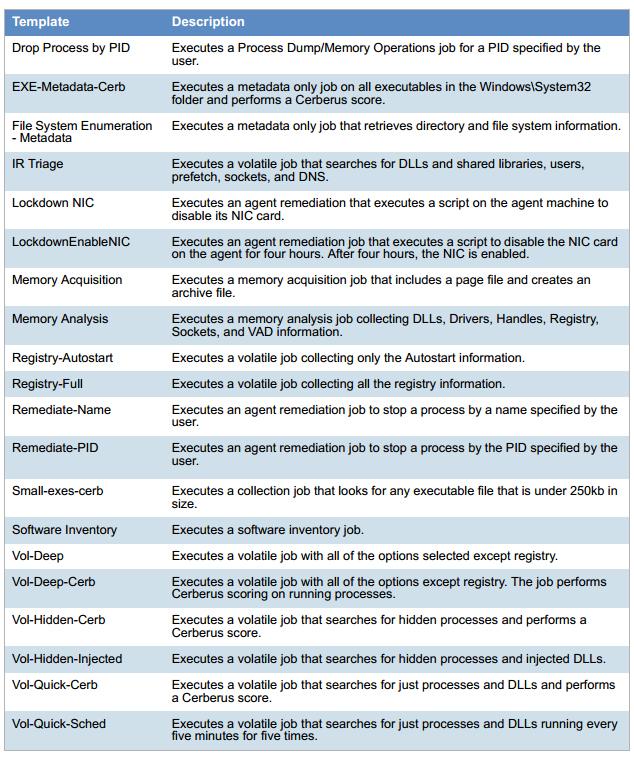
Porque todos los eventos están escritos. Esto es como Google Analytics, solo en la estación de trabajo local. En la red local, los eventos se envían a Data Lake a través de los metadatos de Internet sobre estadísticas y eventos clave, pero si el operador de SOC desea investigar el incidente, también hay un registro completo registrado. Todo se recopila: archivos temporales, claves de registro, todos los procesos en ejecución y sus sumas de verificación, que se escriben en el inicio, acciones, screencast, lo que sea. A continuación se muestra un ejemplo de los datos recopilados.
Lista de parámetros de la estación de trabajo:


Los sistemas en términos de almacenamiento y RAM se vuelven mucho más complicados. El SIEM clásico comienza con 64 GB de RAM, un par de procesadores y medio terabyte de almacenamiento. UBA es de un terabyte de RAM y superior. Por ejemplo, nuestra última implementación fue en 33 servidores físicos (28 nodos informáticos para el procesamiento de datos + 5 nodos de control para el equilibrio de carga), lagos de 150 TB (600 TB en hardware, incluyendo caché rápido en instancias) y 384 GB de RAM cada uno.
¿Quién necesita esto?
En primer lugar, los que se encuentran en la "zona de riesgo" y son constantemente atacados son los bancos, las instituciones financieras, el sector del petróleo y el gas, las grandes tiendas minoristas y muchos otros.
Para tales empresas, el costo de pérdida o pérdida de datos puede ascender a decenas o incluso cientos de millones de dólares. Pero instalar un sistema UBA costará mucho menos. Y, por supuesto, las empresas estatales y las telecomunicaciones, porque nadie quiere en algún momento que los datos de millones de pacientes o la correspondencia de decenas de millones de personas se distribuyan en acceso abierto.
Referencias