
Hoy en día, el desarrollo de software de alta calidad es difícil de imaginar sin usar
métodos de análisis de código estático . El análisis estático del código del programa puede integrarse en el entorno de desarrollo (mediante métodos estándar o mediante complementos), puede realizarse mediante software especializado antes de que el código sea puesto en operación comercial, o "manualmente" por un experto regular o externo.
A menudo se argumenta que
el análisis de código dinámico o
las pruebas de penetración pueden reemplazar el análisis estático, ya que estos métodos de verificación revelarán problemas reales y no habrá falsos positivos. Sin embargo, este es un punto discutible, porque el análisis dinámico, a diferencia del análisis estático, no verifica todo el código, sino que solo verifica la resistencia del software a un conjunto de ataques que imitan las acciones de un atacante. Un atacante puede ser más inventivo que el verificador, independientemente de quién realice la verificación: una persona o una máquina.
El análisis dinámico se completará solo si se realiza en una cobertura de prueba completa, que, cuando se aplica a aplicaciones reales, es una tarea difícil. La prueba de la integridad de la cobertura de la prueba es un problema algorítmicamente insoluble.
El análisis estático obligatorio del código del programa es uno de los pasos necesarios al poner en servicio un software con mayores requisitos de seguridad de la información.
En este momento, hay muchos analizadores de código estático diferentes en el mercado, y cada vez aparecen más nuevos. En la práctica, hay casos en que varios analizadores estáticos se usan juntos para mejorar la calidad de la verificación, ya que diferentes analizadores buscan diferentes defectos.
¿Por qué no hay un analizador estático universal que verifique completamente cualquier código y encuentre todos los defectos en él sin falsos positivos y al mismo tiempo funcione rápidamente y no requiera muchos recursos (tiempo de CPU y memoria)?
Un poco sobre la arquitectura de los analizadores estáticos.
La respuesta a esta pregunta radica en la arquitectura de los analizadores estáticos. Casi todos los analizadores estáticos se basan de alguna manera en el principio de los compiladores, es decir, en su trabajo hay etapas de conversión del código fuente, las mismas que las realizadas por el compilador.
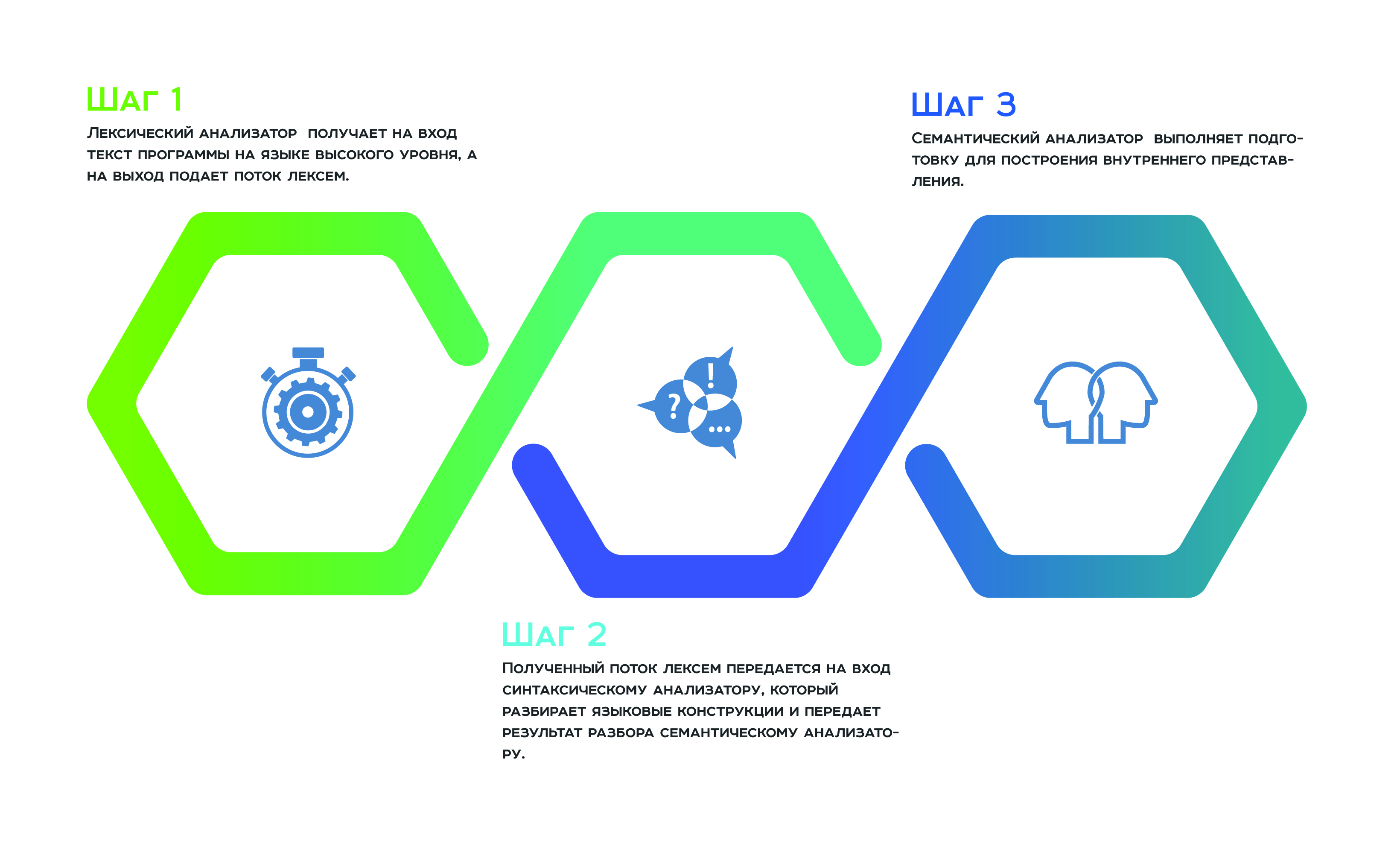
Todo comienza con un
análisis léxico , que recibe el texto del programa en un lenguaje de alto nivel como entrada y una secuencia de lexemas. A continuación, el flujo de token recibido se transmite a la entrada
al analizador , que analiza las construcciones del lenguaje y pasa el resultado del análisis al
analizador semántico , que, como resultado de su trabajo, se prepara para construir la representación interna. Esta representación interna es una característica de cada analizador estático. La eficiencia del analizador depende de cuán exitoso sea.
Muchos fabricantes de analizadores estáticos afirman utilizar una representación interna universal para todos los lenguajes de programación compatibles con el analizador. Por lo tanto, pueden analizar el código del programa desarrollado en varios idiomas como un todo, y no como componentes separados. Un "enfoque holístico" para el análisis permite evitar la omisión de defectos que surgen en la interfaz entre los componentes individuales de un producto de software.
En teoría, esto es cierto, pero en la práctica, una representación interna universal para todos los lenguajes de programación es difícil e ineficiente. Cada lenguaje de programación es especial. Una vista interna suele ser un árbol cuyos vértices almacenan atributos. Al atravesar dicho árbol, el analizador recopila y convierte información. Por lo tanto, cada vértice del árbol debe contener un conjunto uniforme de atributos. Dado que cada idioma es único, la uniformidad de los atributos solo puede ser soportada por la redundancia de los componentes. Los lenguajes de programación más heterogéneos, los componentes más heterogéneos en las características de cada vértice y, por lo tanto, la representación interna es ineficiente de la memoria. Una gran cantidad de características heterogéneas también afecta la complejidad de los caminantes de árboles, lo que significa que conduce a ineficiencias en el rendimiento.
Conversiones de optimización para analizadores estáticos
Para que el analizador estático funcione de manera eficiente en memoria y tiempo, debe tener una representación interna universal compacta, y esto se puede lograr por el hecho de que la representación interna se divide en varios árboles, cada uno de los cuales está diseñado para lenguajes de programación relacionados.
El trabajo de optimización no se limita a dividir la representación interna en lenguajes de programación relacionados. Además, los fabricantes utilizan varias transformaciones de optimización, lo mismo que en las tecnologías de compilación, en particular,
las transformaciones de optimización de los ciclos . El hecho es que el objetivo del análisis estático es idealmente llevar a cabo la promoción de datos en el programa para evaluar su transformación durante la ejecución del programa. Por lo tanto, los datos deben ser "avanzados" en cada vuelta del ciclo. Por lo tanto, si ahorra en estos giros y los hace mucho más pequeños, obtendremos beneficios significativos tanto en la memoria como en el rendimiento. Es para este propósito que tales transformaciones se usan activamente que, con cierta probabilidad, realizan la extrapolación de la transformación de datos a todas las vueltas del ciclo con el número mínimo de pasadas.
También puede ahorrar en sucursales calculando la probabilidad de que el programa vaya a una u otra sucursal. Si la probabilidad de paso a lo largo de una rama es menor que esta, entonces esta rama del programa no se considera.
Obviamente, cada una de estas transformaciones "pierde" los defectos que el analizador debería detectar, pero esto es una "tarifa" para la eficiencia y el rendimiento de la memoria.
¿Qué busca un analizador de código estático?
Condicionalmente, los defectos que de alguna manera están interesados en intrusos y, por lo tanto, en auditores, se pueden dividir en los siguientes grupos:
- errores de validación
- errores de fuga de información,
- errores de autenticación
Los errores de validación ocurren como resultado del hecho de que los datos de entrada no se verifican adecuadamente para su corrección. Un atacante puede deslizar como entrada lo que no es lo que el programa espera y, por lo tanto, obtener acceso no autorizado al control. Los errores de validación de datos más comunes son las inyecciones y
XSS . En lugar de datos válidos, el atacante envía a la entrada del programa datos especialmente preparados que llevan un pequeño programa. Este programa, que se procesa, se ejecuta. El resultado de su implementación puede ser la transferencia de control a otro programa, la corrupción de datos y mucho, mucho más. Además, como resultado de errores de validación, el sitio con el que el usuario está trabajando puede ser reemplazado. Los errores de validación pueden detectarse cualitativamente mediante métodos de análisis de código estático.
Los errores de
fuga de información son errores relacionados con el hecho de que la información confidencial del usuario como resultado del procesamiento fue interceptada y transmitida al atacante. Puede ser al revés: la información confidencial almacenada en el sistema es interceptada y transmitida al atacante a medida que se traslada al usuario.
Tales vulnerabilidades son tan difíciles de detectar como los errores de validación. La detección de este tipo de error requiere el seguimiento en las estadísticas del progreso y la conversión de datos en todo el código del programa. Esto requiere la implementación de métodos como el
análisis de contaminación y
el análisis de datos interprocediales . La precisión del análisis depende en gran medida de qué tan bien se desarrollen estos métodos, es decir, minimizar los falsos positivos y los errores perdidos.
La biblioteca de reglas para detectar defectos, en particular, el formato para describir estas reglas, también juega un papel importante en la precisión del analizador estático. Todo esto es una ventaja competitiva de cada analizador y está cuidadosamente protegido de los competidores.
Los errores de autenticación son los
errores más interesantes para un atacante, ya que son difíciles de detectar porque surgen en la unión de componentes y son difíciles de formalizar. Los atacantes explotan este tipo de error para escalar los derechos de acceso. Los errores de autenticación no se detectan automáticamente, ya que no está claro qué buscar: estos son errores en la lógica de compilación del programa.
Errores de memoria
Son difíciles de detectar porque la identificación precisa requiere resolver un complicado sistema de ecuaciones, que es costoso tanto en memoria como en rendimiento. Por lo tanto, el sistema de ecuaciones se reduce, lo que significa que se pierde precisión.
Los errores de memoria típicos incluyen el
uso después de libre ,
doble libre ,
nulo-puntero-desreferencia y sus variedades, por ejemplo,
fuera de los límites de lectura y
fuera de los límites de escritura .
Cuando el siguiente analizador no pudo detectar una pérdida de memoria, puede escuchar que tales defectos son difíciles de explotar. Un atacante debe estar altamente calificado y aplicar mucha habilidad para, en primer lugar, descubrir la presencia de dicho defecto en el código y, en segundo lugar, hacer una explotación. Bueno, el argumento continúa: "¿Está seguro de que su producto de software es interesante para un gurú de ese nivel?" ... Sin embargo, la historia conoce los casos en que los errores de memoria fueron explotados con éxito y causaron daños considerables. Como ejemplos, puede citar situaciones tan conocidas como:
- CVE-2014-0160 : un error en la biblioteca openssl: un posible compromiso de las claves privadas requería la reemisión de todos los certificados y la regeneración de la contraseña.
- CVE-2015-2712 - error en la implementación de js en mozilla firefox - verificación de límites.
- CVE-2010-1117 : uso gratuito en Internet Explorer, explotable de forma remota.
- CVE-2018-4913 - uso después gratuito en Acrobat Reader - ejecución de código.
Además, a los atacantes les gusta explotar los defectos asociados con la sincronización inadecuada de subprocesos o procesos. Dichos defectos son difíciles de identificar en estática, porque simular el estado de una máquina sin el concepto de "tiempo" no es una tarea fácil. Esto se refiere a errores como
la condición de carrera . Y hoy, la concurrencia se usa en todas partes, incluso en aplicaciones muy pequeñas.
Resumiendo lo anterior, debe tenerse en cuenta que un analizador estático es útil en el proceso de desarrollo, si se usa correctamente. Durante el funcionamiento, es necesario comprender qué esperar de él y qué hacer con esos defectos que el analizador estático no puede identificar en principio. Si dicen que no se necesita un analizador estático durante el proceso de desarrollo, significa que simplemente no saben cómo operarlo.
Cómo operar correctamente el analizador estático, para trabajar de manera correcta y eficiente con la información que proporciona, lea en nuestro blog.