Desde principios de 2017, nuestro pequeño equipo ha estado desarrollando la
biblioteca RESTinio OpenSource para incrustar un servidor HTTP en aplicaciones C ++. Para nuestra gran sorpresa, de vez en cuando recibimos preguntas de la categoría "¿Y por qué podría ser necesario un servidor HTTP C ++ incrustado?" Desafortunadamente, las preguntas simples son las más difíciles de responder. A veces la mejor respuesta es el código de muestra.
Hace un par de meses comenzamos un pequeño
proyecto de demostración, Shrimp , que demuestra claramente un escenario típico, bajo el cual nuestra biblioteca se "afila". El proyecto de demostración es un servicio web simple que recibe solicitudes para escalar imágenes almacenadas en el servidor y que devuelve una imagen del tamaño que necesita el usuario.
Este proyecto de demostración es bueno porque, en primer lugar, requiere integración con código escrito y funcionando correctamente hace mucho tiempo en C o C ++ (en este caso, ImageMagick). Por lo tanto, debe quedar claro por qué tiene sentido incrustar el servidor HTTP en una aplicación C ++.
Y, en segundo lugar, en este caso, se requiere un procesamiento asíncrono de las solicitudes para que el servidor HTTP no se bloquee mientras se escala la imagen (y esto puede llevar cientos de milisegundos o incluso segundos). Y comenzamos el desarrollo de RESTinio precisamente porque no pudimos encontrar un servidor integrado C ++ cuerdo enfocado específicamente en el procesamiento de solicitudes asíncronas.
Construimos el trabajo en camarones de forma iterativa: primero, se hizo y
describió la versión más simple, que solo escalaba las imágenes. Luego arreglamos una serie de deficiencias de la primera versión y lo
describimos en el segundo artículo . Finalmente, pudimos ampliar la funcionalidad de Shrimp una vez más: se agregó la conversión de imágenes de un formato a otro. Sobre cómo se hizo esto y se discutirá en este artículo.
Soporte de formato de destino
Entonces, en la próxima versión de Shrimp, agregamos la capacidad de dar una imagen a escala en un formato diferente. Entonces, si emite una solicitud de camarones del formulario:
curl "http://localhost:8080/my_picture.jpg?op=resize&max=1920"
entonces Shrimp representará la imagen en el mismo formato JPG que la imagen original.
Pero si agrega el parámetro de formato de destino a la URL, entonces Shrimp convierte la imagen al formato de destino especificado. Por ejemplo:
curl "http://localhost:8080/my_picture.jpg?op=resize&max=1920&target-format=webp"
En este caso, Shrimp representará la imagen en formato webp.
Shrimp actualizado admite cinco formatos de imagen: jpg, png, gif, webp y heic (también conocido como HEIF). Puede experimentar con varios formatos
en una página web especial :
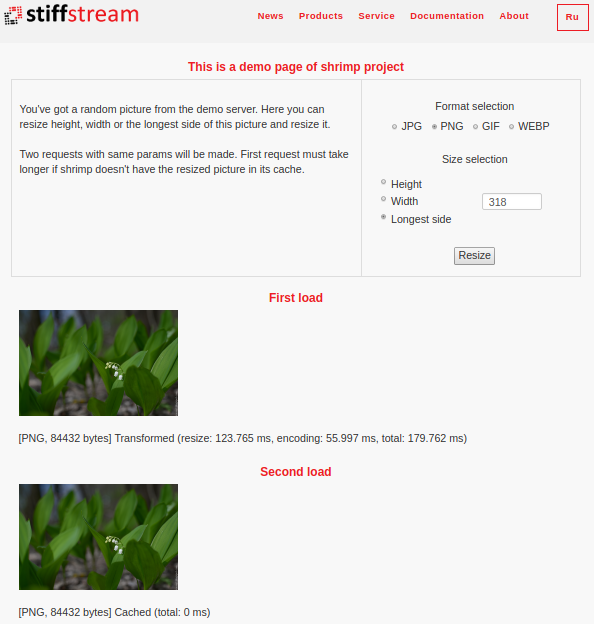
(en esta página no hay forma de seleccionar el formato heic, porque los navegadores de escritorio normales no admiten este formato de forma predeterminada).
Para admitir el formato de destino en Shrimp, fue necesario modificar ligeramente el código de Shrimp (lo cual nos sorprendió a nosotros mismos, porque realmente hubo pocos cambios). Pero por otro lado, tuve que jugar con el ensamblaje de ImageMagick, que nos sorprendió aún más, ya que Anteriormente, tuvimos que lidiar con esta cocina, por una afortunada coincidencia. Pero hablemos de todo en orden.
ImageMagick debe comprender diferentes formatos
ImageMagick utiliza bibliotecas externas para codificar / decodificar imágenes: libjpeg, libpng, libgif, etc. Estas bibliotecas deben instalarse en el sistema antes de configurar y construir ImageMagick.
Lo mismo debería suceder para que ImageMagick admita formatos webp y heic: primero debe compilar e instalar libwebp y libheif, luego configurar e instalar ImageMagick. Y si todo es simple con libwebp, entonces alrededor de libheif tuve que bailar con una pandereta. Aunque después de un tiempo, después de que todo finalmente se había reunido y funcionado, ya no estaba claro: ¿por qué tuviste que recurrir a una pandereta, todo parece ser trivial? ;)
En general, si alguien quiere hacerse amigo de heic e ImageMagick, deberá instalar:
Está en este orden (puede que tenga que instalar
nasm para que x265 funcione a la velocidad máxima). Luego, al emitir el comando
./configure , ImageMagick podrá encontrar todo lo que necesita para admitir archivos .heic.
Soporte para formato de destino en la cadena de consulta de solicitudes entrantes
Después de que nos hicimos amigos de ImageMagick con los formatos webp y heic, es hora de modificar el código de Shrimp. En primer lugar, debemos aprender a reconocer el argumento del formato de destino en las solicitudes HTTP entrantes.
Desde el punto de vista RESTinio, esto no es un problema en absoluto. Bueno, otro argumento apareció en la cadena de consulta, ¿y qué? Pero desde el punto de vista de Shrimp, la situación resultó ser algo más complicada, por lo que el código de la función responsable de analizar la solicitud HTTP se volvió más complicado.
El hecho es que antes era necesario distinguir solo dos situaciones:
- vino una solicitud de la forma "/filename.ext" sin ningún otro parámetro. Entonces solo necesita dar al archivo "filename.ext" tal como está;
- Se recibió una solicitud con el formato "/filename.ext?op=resize & ...". En este caso, debe escalar la imagen del archivo "filename.ext".
Pero después de agregar el formato de destino, necesitamos distinguir entre cuatro situaciones:
- vino una solicitud de la forma "/filename.ext" sin ningún otro parámetro. Por lo tanto, solo necesita dar al archivo "filename.ext" tal como está, sin escalar y sin transcodificar a otro formato;
- vino una solicitud de la forma "/filename.ext?target-format=fmt" sin ningún otro parámetro. Significa tomar una imagen del archivo "filename.ext" y transcodificarla al formato "fmt" mientras se conservan los tamaños originales;
- llegó una solicitud de la forma "/filename.ext?op=resize & ..." pero sin formato de destino. En este caso, necesita escalar la imagen del archivo "filename.ext" y darle el formato original;
- Se recibió una solicitud con el formato "/filename.ext?op=resize&...&target-format=fmt". En este caso, debe realizar el escalado y luego transcodificar el resultado al formato "fmt".
Como resultado, la función para determinar los parámetros de consulta tomó la
siguiente forma :
void add_transform_op_handler( const app_params_t & app_params, http_req_router_t & router, so_5::mbox_t req_handler_mbox ) { router.http_get( R"(/:path(.*)\.:ext(.{3,4}))", restinio::path2regex::options_t{}.strict( true ), [req_handler_mbox, &app_params]( auto req, auto params ) { if( has_illegal_path_components( req->header().path() ) ) { // . return do_400_response( std::move( req ) ); } // . const auto qp = restinio::parse_query( req->header().query() ); const auto target_format = qp.get_param( "target-format"sv ); // // . target-format, // . target-format // , , // . const auto image_format = try_detect_target_image_format( params[ "ext" ], target_format ); if( !image_format ) { // . . return do_400_response( std::move( req ) ); } if( !qp.size() ) { // , . return serve_as_regular_file( app_params.m_storage.m_root_dir, std::move( req ), *image_format ); } const auto operation = qp.get_param( "op"sv ); if( operation && "resize"sv != *operation ) { // , resize. return do_400_response( std::move( req ) ); } if( !operation && !target_format ) { // op=resize, // target-format=something. return do_400_response( std::move( req ) ); } handle_resize_op_request( req_handler_mbox, *image_format, qp, std::move( req ) ); return restinio::request_accepted(); } ); }
En la versión anterior de Shrimp, donde no era necesario transcodificar la imagen, trabajar con los parámetros de solicitud
parecía un poco más fácil .
Solicite la cola y la caché de imágenes adaptadas al formato de destino
El siguiente punto en la implementación del soporte de formato de destino fue el trabajo en la cola de solicitudes en espera y un caché de imágenes preparadas en el agente a_transform_manager. Hablamos de estas cosas
con más detalle
en el artículo anterior , pero recordemos un poco de qué se trataba.
Cuando llega una solicitud de conversión de imagen, puede resultar que la imagen terminada con dichos parámetros ya esté en el caché. En este caso, no necesita hacer nada, solo envíe la imagen desde el caché en respuesta. Si la imagen necesita ser transformada, puede resultar que no hay trabajadores libres en este momento y que debe esperar hasta que aparezca. Para hacer esto, la información de la solicitud debe estar en cola. Pero al mismo tiempo, es necesario verificar la unicidad de las solicitudes: si tenemos tres solicitudes idénticas en espera de procesamiento (es decir, necesitamos convertir la misma imagen de la misma manera), entonces solo debemos procesar la imagen una vez y dar el resultado del procesamiento en respuesta a estas tres solicitudes. Es decir En la cola de espera, se deben agrupar solicitudes idénticas.
Anteriormente en Shrimp, utilizamos una clave compuesta simple para buscar en el caché de imágenes y la cola de espera: una
combinación del nombre del archivo original y las opciones de cambio de tamaño de la imagen . Ahora, dos nuevos factores tuvieron que ser tomados en cuenta:
- en primer lugar, el formato de la imagen de destino (es decir, la imagen original puede estar en jpg y la imagen resultante puede estar en png);
- en segundo lugar, el hecho de que escalar la imagen puede no ser necesario. Esto sucede en una situación en la que el cliente solicita solo la conversión de la imagen de un formato a otro, pero con el tamaño original de la imagen preservado.
Debo decir que aquí seguimos el camino más simple, sin tratar de optimizar de alguna manera nada. Por ejemplo, uno podría intentar hacer dos cachés: uno almacenaría imágenes en el formato original, pero escalado al tamaño deseado, y en el segundo, las imágenes escaladas convertidas al formato de destino.
¿Por qué se necesitaría tal doble caché? El hecho es que al transformar imágenes, las dos operaciones más costosas en el tiempo son cambiar el tamaño y serializar la imagen al formato de destino. Por lo tanto, si recibimos una solicitud para escalar la imagen example.jpg a un tamaño de 1920 de ancho y transformarla en formato webp, entonces podríamos almacenar dos imágenes en nuestra memoria: example_1920px_width.jpg y example_1920px_width.webp. Daríamos una imagen example_1920px_width.webp cuando recibimos una segunda solicitud. Pero la imagen example_1920px_width.jpg podría usarse al recibir solicitudes para escalar example.jpg a un tamaño de 1920 de ancho y transformarlo en formato heic. Podríamos omitir la operación de cambio de tamaño y hacer solo la conversión de formato (es decir, la imagen terminada example_1920px_width.jpg se transcodificaría al formato heic).
Otra oportunidad potencial: cuando llega una solicitud para transcodificar una imagen a otro formato sin cambiar el tamaño, puede determinar el tamaño real de la imagen y usar este tamaño dentro de la clave compuesta. Por ejemplo, deje que example.jpg tenga un tamaño de 3000x2000 píxeles. Si luego recibimos una solicitud para escalar example.jpg a 2000px de altura, entonces podemos determinar de inmediato que ya tenemos una imagen de este tamaño.
En teoría, todas estas consideraciones merecen atención. Pero desde un punto de vista práctico, no está claro qué tan alta es la probabilidad de tal desarrollo de eventos. Es decir ¿con qué frecuencia recibiremos una solicitud para escalar example.jpg a 1920px con conversión a webp, y luego una solicitud para la misma escala de la misma imagen, pero con conversión a png? No tener estadísticas reales es difícil de decir. Por lo tanto, decidimos no complicarnos la vida en nuestro proyecto de demostración, sino ir primero por el camino más simple. Con la expectativa de que si alguien necesita esquemas de almacenamiento en caché más avanzados, esto se puede agregar más tarde, a partir de escenarios reales, no ficticios, para usar Shrimp.
Como resultado, en la versión actualizada de Shrimp, expandimos ligeramente la clave, agregando también un parámetro como el formato de destino:
class resize_request_key_t { std::string m_path; image_format_t m_format; resize_params_t m_params; public: resize_request_key_t( std::string path, image_format_t format, resize_params_t params ) : m_path{ std::move(path) } , m_format{ format } , m_params{ params } {} [[nodiscard]] bool operator<(const resize_request_key_t & o ) const noexcept { return std::tie( m_path, m_format, m_params ) < std::tie( o.m_path, o.m_format, o.m_params ); } [[nodiscard]] const std::string & path() const noexcept { return m_path; } [[nodiscard]] image_format_t format() const noexcept { return m_format; } [[nodiscard]] resize_params_t params() const noexcept { return m_params; } };
Es decir solicitud de cambio de tamaño example.jpg hasta 1920px con conversión a png difiere del mismo cambio de tamaño, pero con conversión a webp o heic.
Pero el foco principal se esconde
en la nueva implementación de la clase resize_params_t , que determina los nuevos tamaños de la imagen escalada.
Anteriormente, esta clase admitía tres opciones: solo se configuraba el ancho, solo se ajustaba la altura o se configuraba el lado largo (la altura o el ancho están determinados por el tamaño de imagen actual). En consecuencia, el
método resize_params_t :: value () siempre devolvió algún valor real (qué valor fue determinado por el
método resize_params_t :: mode () ).
Pero en el nuevo Shrimp, se agregó otro modo: keep_original, lo que significa que no se realiza el escalado y la imagen se representa en su tamaño original. Para admitir este modo, resize_params_t tuvo que hacer algunos cambios. En primer lugar, ahora el
método resize_params_t :: make () determina si se usa el modo keep_original (se considera que este modo se usa si no se especifica ninguno de los parámetros ancho, alto y máximo en la cadena de consulta de la solicitud entrante). Esto nos permitió no reescribir la función
handle_resize_op_request () , que empuja la solicitud para escalar la imagen que se ejecutará.
En segundo lugar, el
método resize_params_t :: value () ahora puede llamarse no siempre, sino solo cuando el modo de escala difiere de keep_original.
Pero lo más importante es que
resize_params_t :: operator <() continuó funcionando según lo previsto.
Gracias a todos estos cambios en a_transform_manager, tanto el caché de imágenes escaladas como la cola de solicitudes en espera se han mantenido igual. Pero ahora, la información sobre varias consultas se almacena en estas estructuras de datos. Por lo tanto, la clave {"example.jpg", "jpg", keep_original} diferirá tanto de la clave {"example.jpg", "png", keep_original}, como de la clave {"example.jpg", "jpg", ancho = 1920px}.
Resultó que habiendo estropeado un poco la definición de estructuras de datos tan simples como resize_params_t y resize_params_key_t, evitamos alterar estructuras más complejas como el caché de imágenes resultantes y la cola de solicitudes en espera.
Soporte para formato de destino en a_transformer
Bueno, el paso final para admitir el formato de destino es expandir la lógica del agente a_transformer para que la imagen, posiblemente ya escalada, se convierta al formato de destino.
Resultó ser el más fácil de hacer, todo lo que se necesitaba era expandir el código del
método a_transform_t :: handle_resize_request () :
[[nodiscard]] a_transform_manager_t::resize_result_t::result_t a_transformer_t::handle_resize_request( const transform::resize_request_key_t & key ) { try { m_logger->trace( "transformation started; request_key={}", key ); auto image = load_image( key.path() ); const auto resize_duration = measure_duration( [&]{ // // keep_original. if( transform::resize_params_t::mode_t::keep_original != key.params().mode() ) { transform::resize( key.params(), total_pixel_count, image ); } } ); m_logger->debug( "resize finished; request_key={}, time={}ms", key, std::chrono::duration_cast<std::chrono::milliseconds>( resize_duration).count() ); image.magick( magick_from_image_format( key.format() ) ); datasizable_blob_shared_ptr_t blob; const auto serialize_duration = measure_duration( [&] { blob = make_blob( image ); } ); m_logger->debug( "serialization finished; request_key={}, time={}ms", key, std::chrono::duration_cast<std::chrono::milliseconds>( serialize_duration).count() ); return a_transform_manager_t::successful_resize_t{ std::move(blob), std::chrono::duration_cast<std::chrono::microseconds>( resize_duration), std::chrono::duration_cast<std::chrono::microseconds>( serialize_duration) }; } catch( const std::exception & x ) { return a_transform_manager_t::failed_resize_t{ x.what() }; } }
En comparación
con la versión anterior, hay dos adiciones fundamentales.
En primer lugar, llamar al método image.magick () verdaderamente mágico después de cambiar el tamaño. Este método le dice a ImageMagick el formato de imagen resultante. Al mismo tiempo, la representación de la imagen en la memoria no cambia: ImageMagick continúa almacenándola como le conviene. Pero luego el valor establecido por el método magick () se tendrá en cuenta durante la llamada posterior a Image :: write ().
En segundo lugar, la versión actualizada registra el tiempo que lleva serializar la imagen al formato especificado. La nueva versión de Shrimp ahora repara por separado el tiempo dedicado a escalar y el tiempo dedicado a la conversión al formato de destino.
El resto del agente a_transformer_t no ha sufrido ningún cambio.
Paralelización de ImageMagick
Por defecto, ImageMagic está construido con soporte OpenMP. Es decir Es posible paralelizar operaciones en imágenes que realiza ImageMagick. Puede controlar la cantidad de flujos de trabajo que ImageMagick usa en este caso utilizando la variable de entorno MAGICK_THREAD_LIMIT.
Por ejemplo, en mi máquina de prueba con el valor MAGICK_THREAD_LIMIT = 1 (es decir, sin paralelización real), obtengo los siguientes resultados:
curl "http://localhost:8080/DSC08084.jpg?op=resize&max=2400" -v > /dev/null > GET /DSC08084.jpg?op=resize&max=2400 HTTP/1.1 > Host: localhost:8080 > User-Agent: curl/7.47.0 > Accept: */* > < HTTP/1.1 200 OK < Connection: keep-alive < Content-Length: 2043917 < Server: Shrimp draft server < Date: Wed, 15 Aug 2018 11:51:24 GMT < Last-Modified: Wed, 15 Aug 2018 11:51:24 GMT < Access-Control-Allow-Origin: * < Access-Control-Expose-Headers: Shrimp-Processing-Time, Shrimp-Resize-Time, Shrimp-Encoding-Time, Shrimp-Image-Src < Content-Type: image/jpeg < Shrimp-Image-Src: transform < Shrimp-Processing-Time: 1323 < Shrimp-Resize-Time: 1086.72 < Shrimp-Encoding-Time: 236.276
El tiempo dedicado al cambio de tamaño se indica en el encabezado Shrimp-Resize-Time. En este caso, es 1086.72ms.
Pero si configura MAGICK_THREAD_LIMIT = 3 en la misma máquina y ejecuta Shrimp, obtenemos valores diferentes:
curl "http://localhost:8080/DSC08084.jpg?op=resize&max=2400" -v > /dev/null > GET /DSC08084.jpg?op=resize&max=2400 HTTP/1.1 > Host: localhost:8080 > User-Agent: curl/7.47.0 > Accept: */* > < HTTP/1.1 200 OK < Connection: keep-alive < Content-Length: 2043917 < Server: Shrimp draft server < Date: Wed, 15 Aug 2018 11:53:49 GMT < Last-Modified: Wed, 15 Aug 2018 11:53:49 GMT < Access-Control-Allow-Origin: * < Access-Control-Expose-Headers: Shrimp-Processing-Time, Shrimp-Resize-Time, Shrimp-Encoding-Time, Shrimp-Image-Src < Content-Type: image/jpeg < Shrimp-Image-Src: transform < Shrimp-Processing-Time: 779.901 < Shrimp-Resize-Time: 558.246 < Shrimp-Encoding-Time: 221.655
Es decir El tiempo de cambio de tamaño se redujo a 558.25ms.
En consecuencia, dado que ImageMagick brinda la capacidad de paralelizar los cálculos, puede aprovechar esta oportunidad. Pero al mismo tiempo, es deseable poder controlar cuántos hilos de trabajo toma Shrimp para sí mismo. En versiones anteriores de Shrimp, no era posible influir en cuántos flujos de trabajo crea Shrimp. Y en la versión actualizada de Shrimp, esto se puede hacer. O a través de variables de entorno, por ejemplo:
SHRIMP_IO_THREADS=1 \ SHRIMP_WORKER_THREADS=3 \ MAGICK_THREAD_LIMIT=4 \ shrimp.app -p 8080 -i ...
O a través de argumentos de línea de comando, por ejemplo:
MAGICK_THREAD_LIMIT=4 \ shrimp.app -p 8080 -i ... --io-threads 1 --worker-threads 4
Los valores especificados a través de la línea de comando tienen una prioridad más alta.
Cabe destacar que MAGICK_THREAD_LIMIT afecta solo a aquellas operaciones que ImageMagick realiza por sí mismo. Por ejemplo, el cambio de tamaño lo realiza ImageMagick. Pero la conversión de un formato a otro ImageMagick delega a bibliotecas externas. Y cómo se paralelizan las operaciones en estas bibliotecas externas es un tema separado que no entendimos.
Conclusión
Quizás, en esta versión de Shrimp, llevamos nuestro proyecto de demostración a un estado aceptable. Aquellos que quieran ver y experimentar pueden encontrar los textos fuente de Shrimp en
BitBucket o
GitHub . También puede encontrar el Dockerfile allí para construir camarones para sus experimentos.
En general, hemos logrado nuestros objetivos que nos propusimos al comenzar este proyecto de demostración. Aparecieron varias ideas para el desarrollo posterior de RESTinio y SObjectizer, y algunas de ellas ya han encontrado su forma de realización. Por lo tanto, si el camarón se desarrollará en algún lugar más completamente depende de preguntas y deseos. Si los hay, entonces los camarones pueden expandirse. De lo contrario, Shrimp seguirá siendo un proyecto de demostración y un campo de entrenamiento para experimentar con nuevas versiones de RESTinio y SObjectizer.
En conclusión, me gustaría expresar un agradecimiento especial a
aensidhe por su ayuda y asesoramiento, sin los cuales nuestros bailes con pandereta serían mucho más largos y tristes.